
Les contenus liés aux tags GDC et GDC 2016
Afficher sous forme de : Titre | FluxGDC: Autre exemple DX12 avec Quantum Break
GDC: Nvidia lance le SDK GameWorks 3.1
GDC: Hitman et le portage DirectX 12
GDC: AMD annonce la Radeon Pro Duo
GDC: AMD dévoile sa roadmap GPU : Polaris, Vega, Navi
GDC: Vers de nouveaux types de shaders ?



Comme vous le savez, le rendu en 3D temps réel moderne fait appel à différentes phases programmables lors desquelles sont exécutés de petits programmes appelés shaders. Après les pixel/fragment et vertex shaders qui exécutent des opérations sur les pixels/fragments et les vertices, ont été progressivement introduits les geometry shaders qui travaillent sur les primitives, les compute shaders pour du calcul plus généraliste ainsi que les hull et domain shaders dédiés à la tessellation. D'autres pourraient débarquer dans le futur.
Au détour d'une présentation de Nvidia Research, une section consacrée à la programmation des shaders a attiré notre attention. Lors de celle-ci, Nvidia a encouragé les développeurs à mettre en place leurs propres outils de compilation de manière à ce qu'ils puissent répondre à leurs besoins précis, à faciliter la gestion de plusieurs niveaux de détails (LOD), à supporter différentes plateformes ainsi que de futurs pipelines de rendu qui pourraient avoir recours à de nouveaux types de shaders.

Nvidia cite deux exemples. Le premier, appelé génériquement Coarse-Rate Shader, représente différente possibilité d'exécution d'un shader dans une résolution et/ou un espace différents de ceux du framebuffer. De quoi par exemple traiter certains effets dans une résolution moindre, en appliquer dans l'espace propre aux textures ou encore en adapter au champ de vision propre à la VR. Passer par ce type de shaders intermédiaires serait plus efficace sur le plan du compromis qualité/performances que de se contenter de pixels shaders.
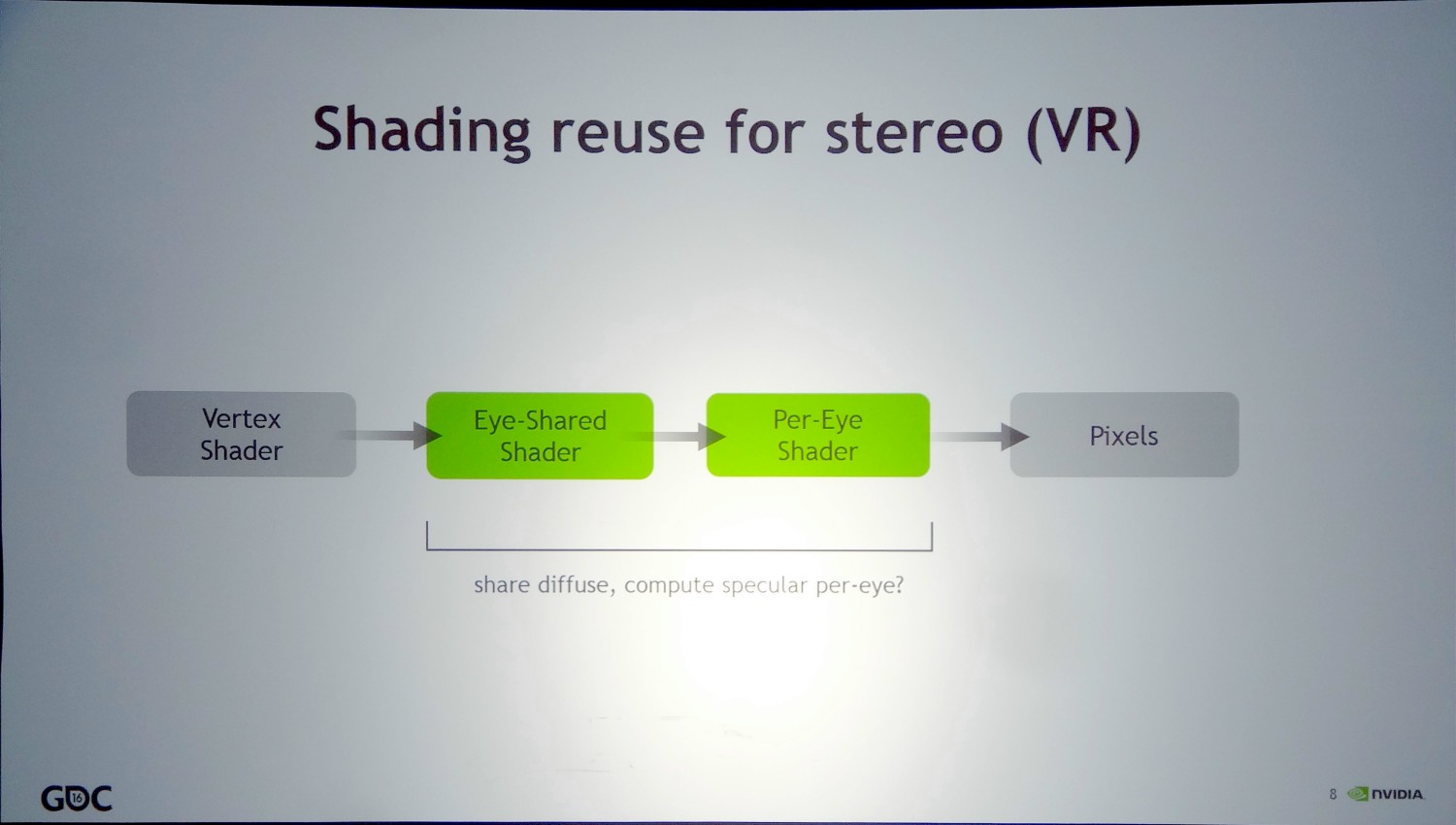
Le second exemple est dédié à optimiser les performances de la VR (ou de la 3D stéréo) et consisterait à scinder les pixels shaders en programmes correspondant aux tâches partagées par les deux yeux (Eye-Shared Shader) et spécifiques à chaque oeil (Per-Eye Shader). Une partie des éléments du rendu ne seraient ainsi calculés qu'une seule fois pour les deux yeux, une approximation qui pourrait offrir un résultat satisfaisant dans certains cas.
Nvidia explique que tout cela est déjà possible à travers la mise en place d'un pipeline de rendu software, c'est-à-dire à base de compute shaders. Il y a d'ailleurs pas mal d'expérimentations autour du remplacement d'une partie ou de la totalité du pipeline hardware classique par des compute shaders. Mais il est en général bien plus efficace de faire en sorte de profiter des différentes étapes non programmables du pipeline hardware ainsi que des différents mécanismes voués à rendre plus performante l'exécution de shaders spécifiques.
Nvidia précise alors que de futurs pipelines hardware pourraient proposer un support pour ces nouveaux types de shaders et conseille aux développeurs de préparer leurs outils à cet effet. Si cela ne correspond à aucune annonce spécifique, en terme de support précis ou de timing, il semble évident que Nvidia travaille déjà à la prise en charge de nouveaux types de shaders pour ses futures générations de GPU.
Vous pourrez retrouver l'intégralité de la présentation de Nvidia ci-dessous :








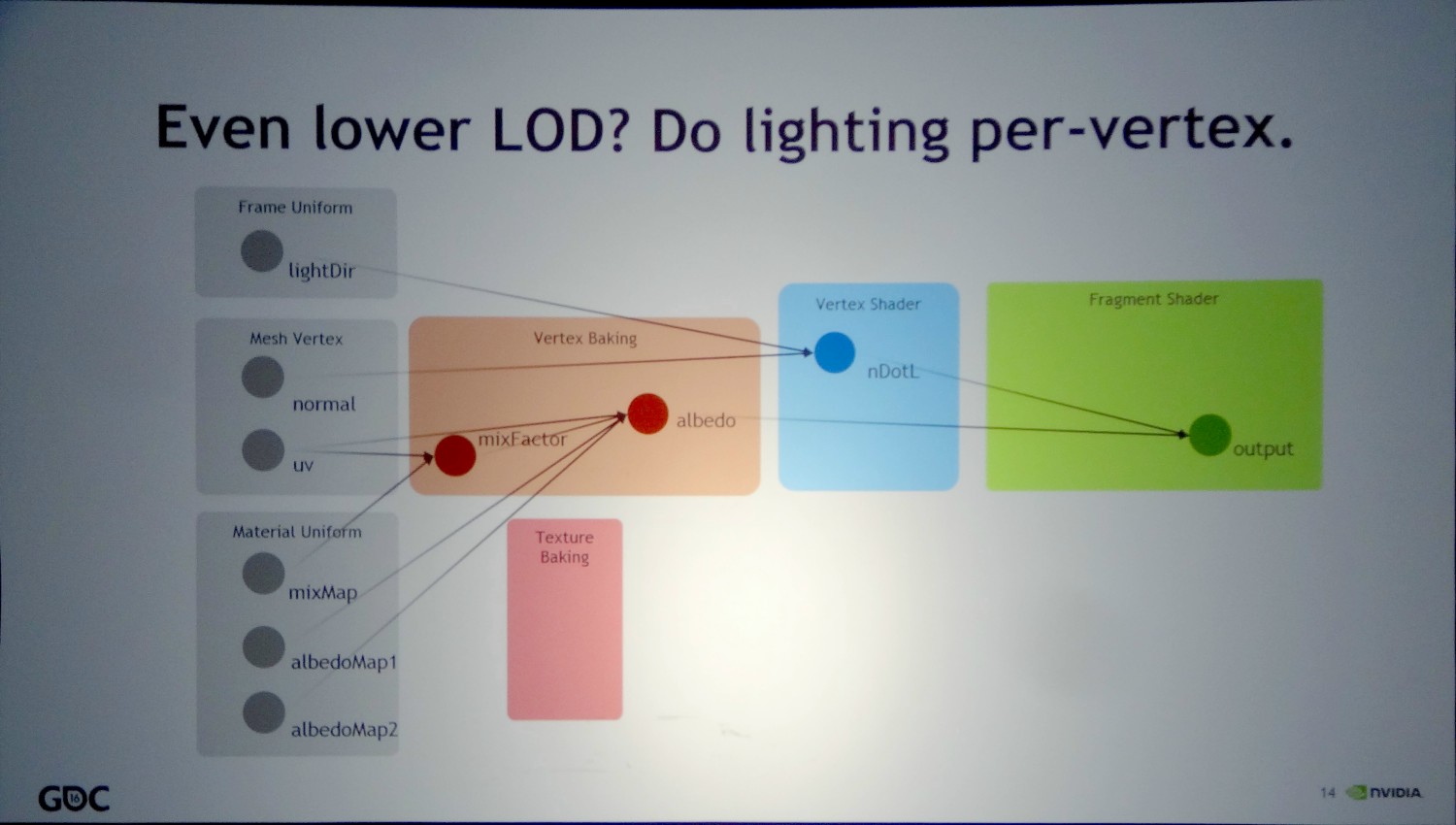








GDC: Async Compute : ce qu'en dit Nvidia
Nous avons bien entendu profité de la GDC pour questionner Nvidia en vue d'en apprendre plus sur ce dont sont capables ses GPU en terme de prise en charge du multi engine de DirectX 12 sans réel succès ?
Au coeur de DirectX 12, cette fonctionnalité permet de décomposer le rendu en plusieurs files de commandes, qui peuvent être de type copy, compute ou graphics, et de gérer la synchronisation entre ces files. De quoi permettre aux développeurs de prendre le contrôle sur l'ordre dans lequel les tâches sont exécutées ou encore de piloter directement le multi-GPU. Cette décomposition permet également dans certains cas de profiter de la capacité des GPU à traiter plusieurs tâches en parallèle pour booster les performances.

Illustration du Multi Engine de DirectX 12, qui permet de traiter plusieurs files de commandes en parallèle.
C'est ce qu'AMD appelle Async Compute, bien que le terme ne soit pas correct. En effet, l'exécution asynchrone d'une tâche n'implique pas qu'elle soit traitée en concomitance d'une autre, or c'est ce dernier point qui est crucial et permet un gain de performances. Les GPU AMD profitent de multiples processeurs de commandes capables d'alimenter les unités de calcul du GPU à partir de plusieurs files différentes. Un traitement en simultané des tâches qui permet de maximiser l'utilisation de toutes les ressources du GPU : unités de calcul, bande passante mémoire etc.
Du côté de Nvidia c'est plus compliqué. Si les GeForce sont capables de prendre en charge les files copy en parallèle des files compute et graphics, traiter ces deux dernières en concomitance semble poser problème. Théoriquement les GPU Maxwell 2 (GTX 900) disposent d'un processeur de commandes capables de prendre en charge 32 files dont une peut être de type graphics. Et pourtant ce support n'est toujours pas fonctionnel en pratique, comme le démontrent par exemple les performances des GeForce dans Ashes of the Singularity.
Pourquoi ? Jusqu'ici, nous n'avons pu obtenir de réelle réponse de Nvidia. Alors bien entendu nous avons voulu profiter de la GDC pour tenter d'en savoir plus et avons questionné Nvidia lors d'un meeting organisé avec Rev Lebaredian, Senior Director GameWorks. Malheureusement pour nous, cet ingénieur qui fait partie du groupe de support technique aux développeurs de jeux vidéo avait été très bien préparé à ces questions qui concernent les spécificités du support du multi engine. Ses réponses ont au départ été mot pour mot celles de la brève déclaration officielle de Nvidia communiquée à la presse technique depuis quelques mois. A savoir "les GeForce Maxwell peuvent prendre en charge l'exécution en concomitance au niveau des SM (groupes d'unités de calcul)", "ce n'est pas encore actif dans les pilotes", "Ashes of the Singularity n'est qu'un seul jeu (pas trop important) parmi d'autres".
Une langue de bois inhabituelle qui démontre, si cela était encore nécessaire, que cette question dérange chez Nvidia. Nous avons donc changé d'approche et pour sortir de l'impasse nous avons abordé le sujet sous un angle différent : est-ce que l'Async Compute est important (pour les GPU Maxwell) ? De quoi détendre Rev Lebaredian et ouvrir la voie à une discussion bien plus intéressante. Deux arguments sont alors avancés par Nvidia.
D'une part, si Async Compute est un moyen d'augmenter les performances, ce qui compte au final ce sont les performances globales. Si les GPU GeForce sont à la base plus performants que les GPU Radeon, le recours au multi engine pour tenter de booster leurs performances n'est pas une priorité absolue.
D'autre part, si le taux d'utilisation des différents blocs des GPU GeForce est relativement élevé à la base, le gain potentiel lié à Async Compute est moins important. Nvidia précise sur ce point que globalement il y a beaucoup moins de trous (bubbles en langage GPU) au niveau de l'activité des unités de ses GPU que chez son concurrent. Or le but de l'exécution concomitante est d'exploiter une synergie dans le traitement de différentes tâches pour remplir ces "trous".
Derrière ces deux arguments avancés par Nvidia se cachent en fait celui de la bonne planification d'une architecture GPU. Intégrer dans les puces un ou des processeurs de commandes plus évolué a un coût, un coût qui peut par exemple être exploité différemment pour proposer plus d'unités de calcul et booster les performances directement et dans un maximum de jeux.

Lors du développement d'une architecture GPU, une bonne partie du travail consiste à prévoir le profil des tâches qui seront prises en charge quand les nouvelles puces seront commercialisées. L'équilibre de l'architecture entre ses différents types d'unités, entre la puissance de calcul et la bande passante mémoire, entre le débit de triangles et le débit de pixels, etc., est un point crucial qui demande une bonne visibilité, beaucoup de pragmatisme et une vision stratégique. Force est de constater que Nvidia s'en tire plutôt bien à ce niveau depuis quelques générations de GPU.
Pour illustrer cela, faisons quelques petites comparaisons entre le GM200 et Fiji sur base des résultats obtenus dans Ashes of the Singularity sans Async Compute. La comparaison est grossière et approximative (le GM200 exploité est tiré de la GTX 980 Ti qui en exploite une version légèrement castrée), mais reste intéressante :
- GM200 (GTX 980 Ti) : 6.0 fps / Gtransistors, 7.8 fps / Tflops, 142.1 fps / To/s
- Fiji (R9 Fury X) : 5.6 fps / Gtransistors, 5.8 fps / Tflops, 97.9 fps / To/s
Nous pourrions faire de même avec de nombreux jeux et le résultat serait similaire, voire encore plus marqué (AotS est particulièrement efficace sur Radeon) : le GM200 exploite mieux les ressources à sa disposition que Fiji. C'est un choix d'architecture, ce qui n'implique pas directement qu'il est meilleur qu'un autre. Augmenter le rendement de certaines unités peut avoir un coût supérieur à l'augmentation de leur nombre dans une mesure plus importante. Le travail des architectes consiste à trouver le meilleur équilibre à ce niveau.
De toute évidence, AMD a plutôt misé sur les débits bruts de ses GPU, ce qui implique en général un rendement inférieur et plus d'opportunité d'optimisation au niveau de celui-ci. Ajoutez à cela que l'organisation de l'Async Compute dans AotS semble plutôt optimiser l'utilisation du surplus de bande passante mémoire et vous comprendrez aisément qu'il y a moins à gagner du côté de Nvidia. D'autant plus que les commandes de synchronisation liées à Async Compute ont un coût qui ne sera masqué que par un gain significatif.
Si notre propre réflexion nous amène à être plutôt d'accord avec ces arguments de Nvidia, il reste un autre point important pour les joueurs et c'est probablement ce qui fait que le numéro un du GPU aborde le sujet du bout des lèvres : Async Compute apporte un gain gratuit aux utilisateurs de Radeon. Alors que cette possibilité a été prévue dans les GPU AMD depuis plus de 4 ans, ils n'ont pas pu en tirer un bénéfice commercial, ils n'ont pas été vendus plus chers pour la cause. Cela change quelque peu avec la dernière gamme d'AMD qui mise fortement sur ce point, mais, en terme de perception, les joueurs apprécient d'obtenir gratuitement un tel petit coup de boost, même s'il ne concerne qu'une poignée de jeux. A l'inverse, le rendement globalement plus élevé des GPU Nvidia a pu avoir un bénéfice immédiat dans un maximum de jeux, et a pu être pris en compte directement dans le tarif des GeForce. Et du point de vue d'une société dont le but n'est pas d'afficher des pertes, il est évident qu'une approche a plus de sens qu'une autre.
Reste que nous sommes en 2016 et que l'exploitation de l'Async Compute devrait progressivement se généraliser, notamment grâce à la similitude entre l'architecture des GPU des consoles et celle des Radeon. Nvidia ne peut donc pas totalement ignorer cette possibilité qui pourrait réduire voire supprimer son avance en termes de performances. Sans rentrer dans le moindre détail, Rev Lebaredian a ainsi tenu à réaffirmer qu'il y avait bel et bien des possibilités au niveau des pilotes pour implémenter un support qui permette de profiter dans certains cas d'un gain de performances avec l'Async Compute. Des possibilités que Nvidia réévalue en permanence, non sans oublier que ses futurs GPU pourraient changer la donne à ce niveau.
GDC: Async Compute et AotS : des détails
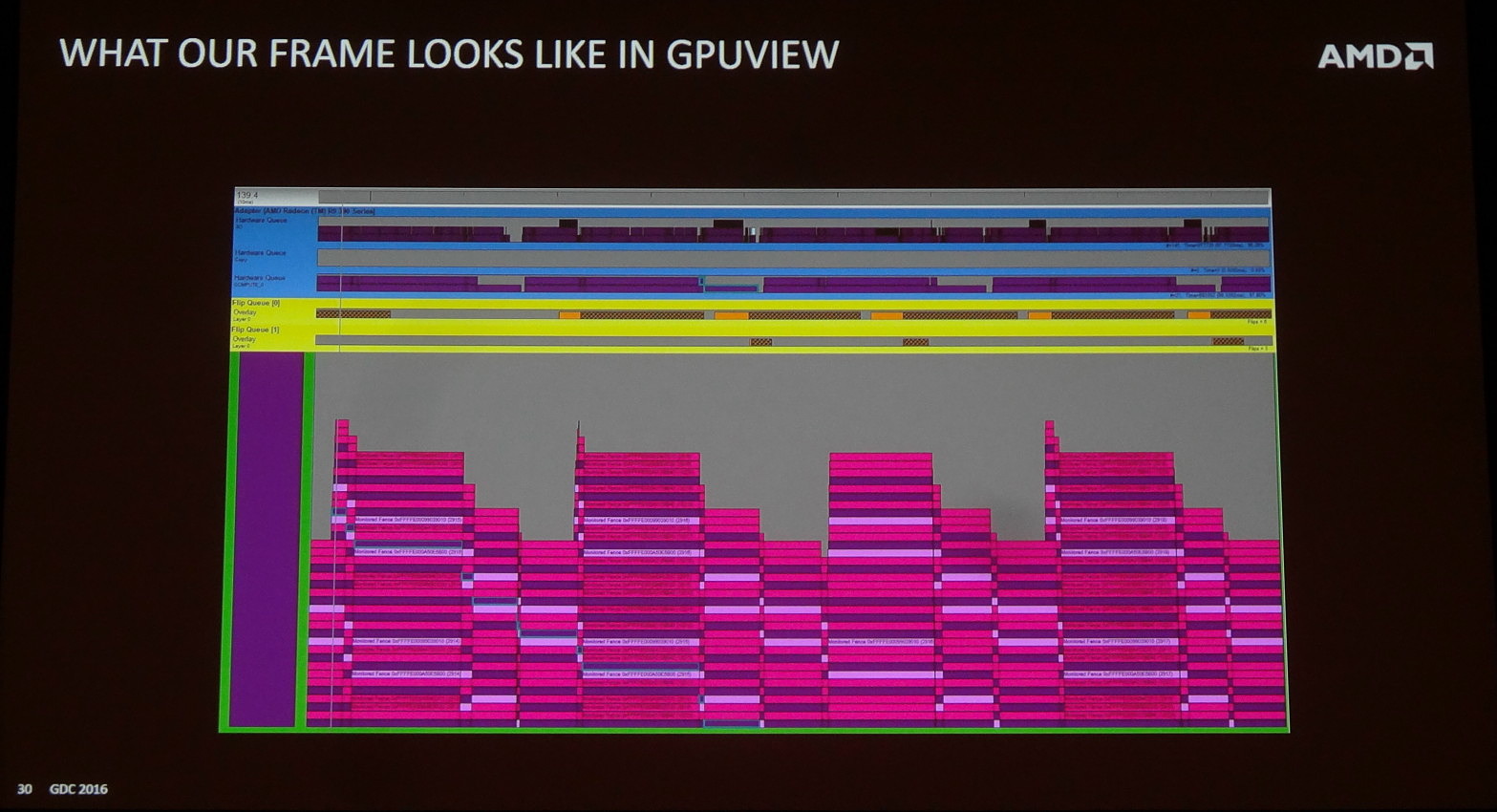
Lors d'une session d'AMD dédiée à DirectX 12, Oxide est revenu sur son implémentation du multi engine ("Async Compute") dans Ashes of the Singularity. L'occasion de comprendre comment cette fonctionnalité est exploitée pour booster les performances sur les GPU qui sont capables de prendre en charge plusieurs files de commandes.
Exploiter le multi engine pour booster les performances implique de traiter simultanément différentes tâches. Aucun GPU n'étant actuellement capable de traiter plusieurs files de type graphiques en parallèle (mais cela pourrait changer dans le futur), il y a deux groupes de tâches qui peuvent profiter d'un boost de performances dans DirectX 12 : les copies et les compute shaders. Les premières auront surtout de l'intérêt dans le cadre du multi-GPU et ce sont donc les seconds auxquels les développeurs vont devoir s'intéresser. La première étape est alors de déterminer quels sont ces compute shaders qui peuvent être isolés du reste du rendu et exécutés simultanément via une file dédiée.
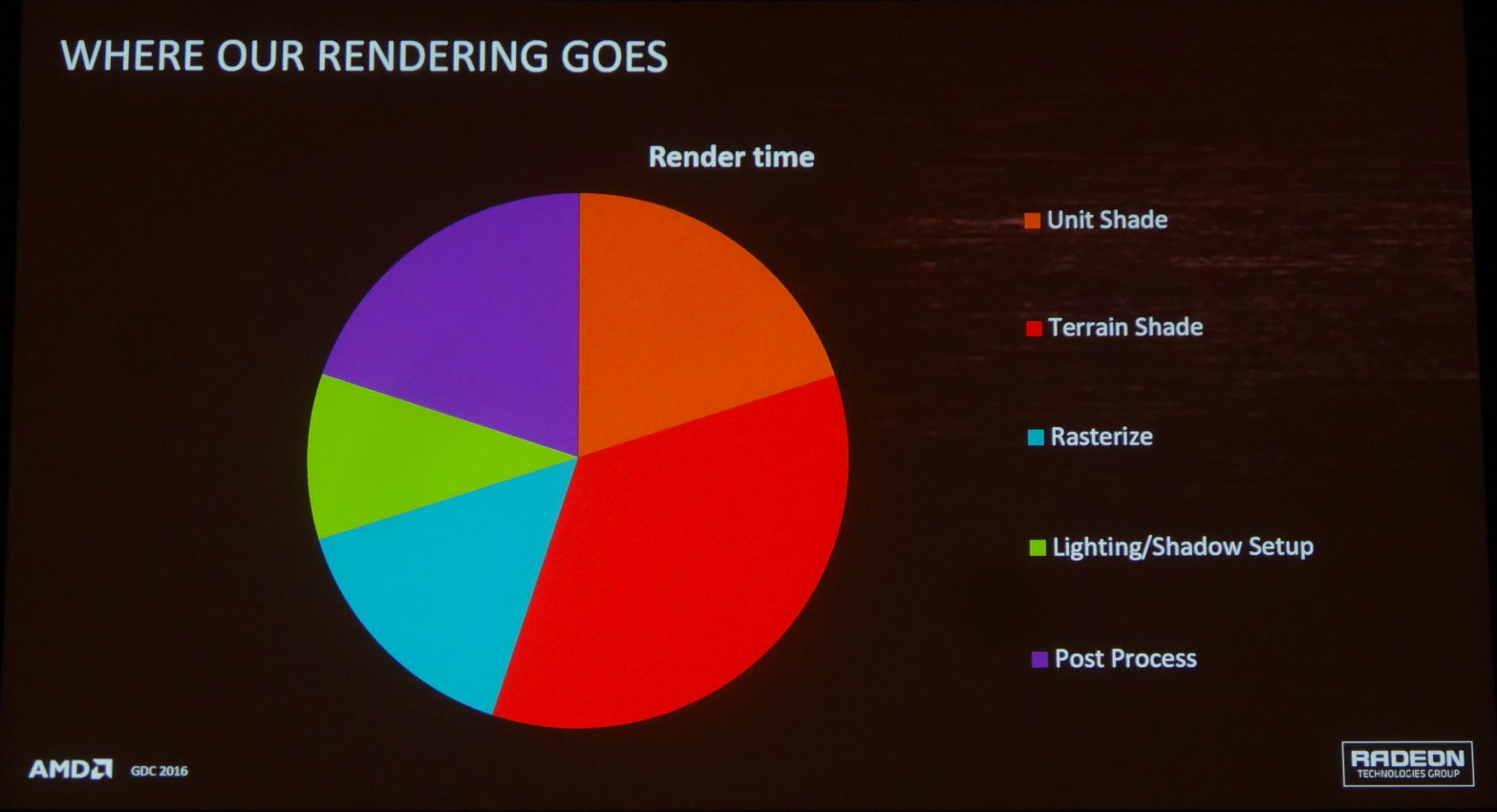
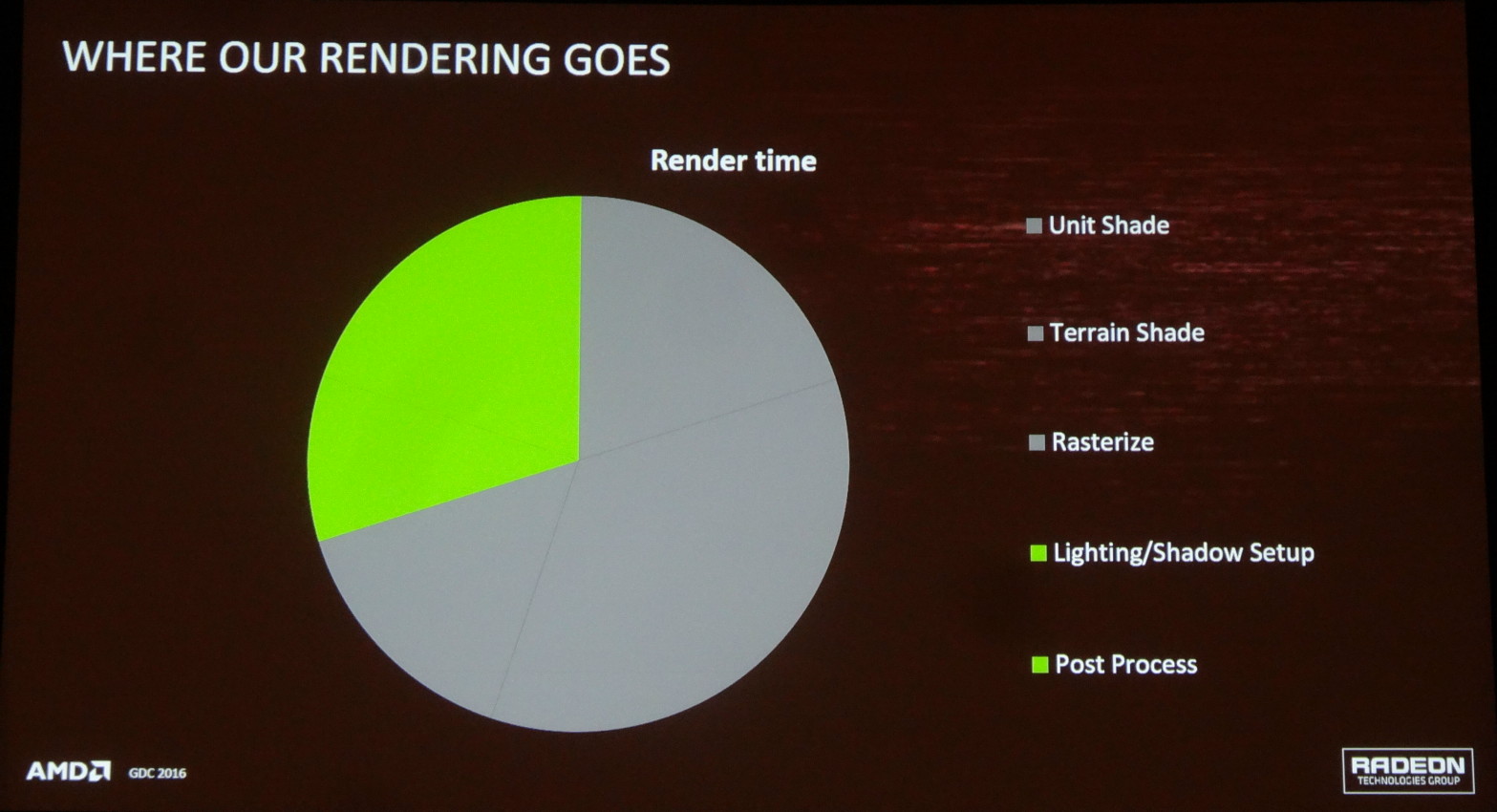
Dans le cas du moteur d'Ashes of the Singularity (AotS) il y a 2 larges pans du rendu qui sont traités via des computes shaders : l'éclairage et les ombres d'une part et le post processing d'autre part. Ils représentent à peu près 30% du temps de rendu d'une image typique et semblent donc être de bons candidats. C'est particulièrement le cas pour le post processing qui intervient en fin de rendu et peut sans problème être traité pendant que le travail commence sur une nouvelle image.
Tout du moins c'est la théorie basique. En pratique la prise en compte par le moteur graphique du rendu de plusieurs images en parallèle est un peu plus complexe. Seules les files graphiques peuvent présenter l'image au moteur d'affichage, les files compute en sont incapables. Or il est compliqué, voire impossible suivant le moteur, d'alterner des commandes liées à des images différentes à l'intérieur d'une même file. En d'autres termes, de demander l'affichage de l'image 1 au milieu des commandes de rendu de l'image 2 n'est pas si simple.
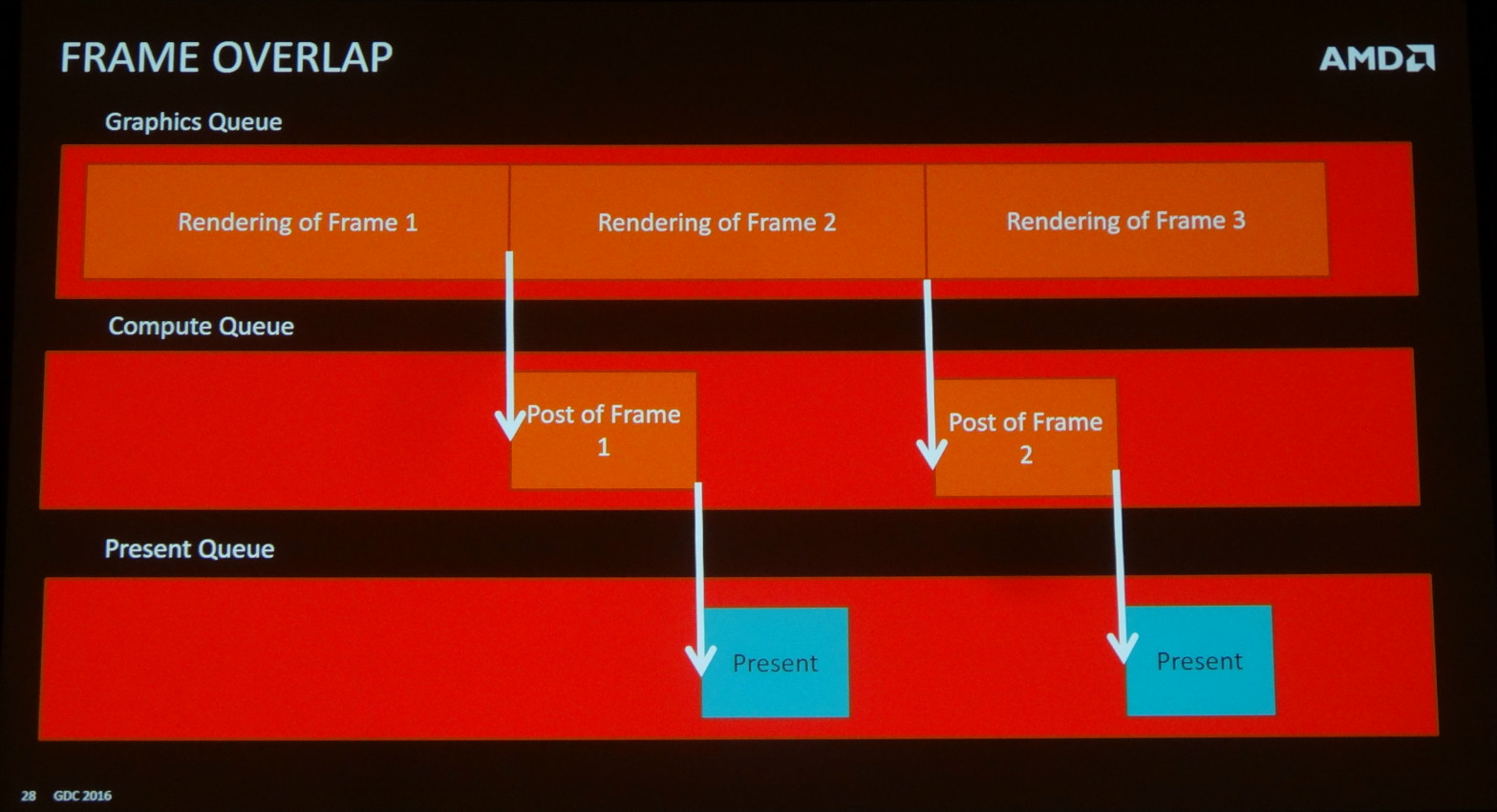
La solution est d'exploiter une seconde file graphique qui servira exclusivement à présenter les images en vue de leur affichage. Reste que si les pilotes n'ont aucun problème avec cette possibilité, les GPU actuels ne sont pas capables de gérer deux files graphiques en parallèle. Or si la file secondaire doit attendre que la principale soit traitée avant d'être exécutée, cela entraîne une image de latence supplémentaire.
Oxide a cherché à éviter ce désagrément en faisant en sorte créer un maximum d'opportunités d'alternance entre les deux files graphiques via une décomposition du rendu principal de l'image en suffisamment de groupes de commandes. C'est peut-être légèrement moins efficace sur le plan des performances mais entre l'exécution de ces plus petits groupes de commandes, Windows pourra alterner entre les files graphiques et ainsi insérer la commande de présentation de l'image. Au lieu d'une image de latence supplémentaire, Oxide parvient ainsi à ne l'augmenter que de 1/3 à 1/2 image.
Reste le second point qui peut potentiellement être traité en parallèle via une file compute : l'éclairage et les ombres. Il est plus délicat à aborder et Oxide rentre moins dans les détails. Notre compréhension est que seule une partie passe dans une file compute : le filtrage des ombres qui a un coût élevé. Le problème est que cette phase ne peut pas être traitée en parallèle du reste du rendu qui en a besoin. Pour pouvoir malgré tout la paralléliser, Oxide a recours à une approximation : pour chaque image, les ombres sont issues de l'image précédente. Dans un jeu tel qu'AotS, cela passe presqu'inaperçu, mais cette approche ne pourrait probablement pas être utilisée dans un fps par exemple.
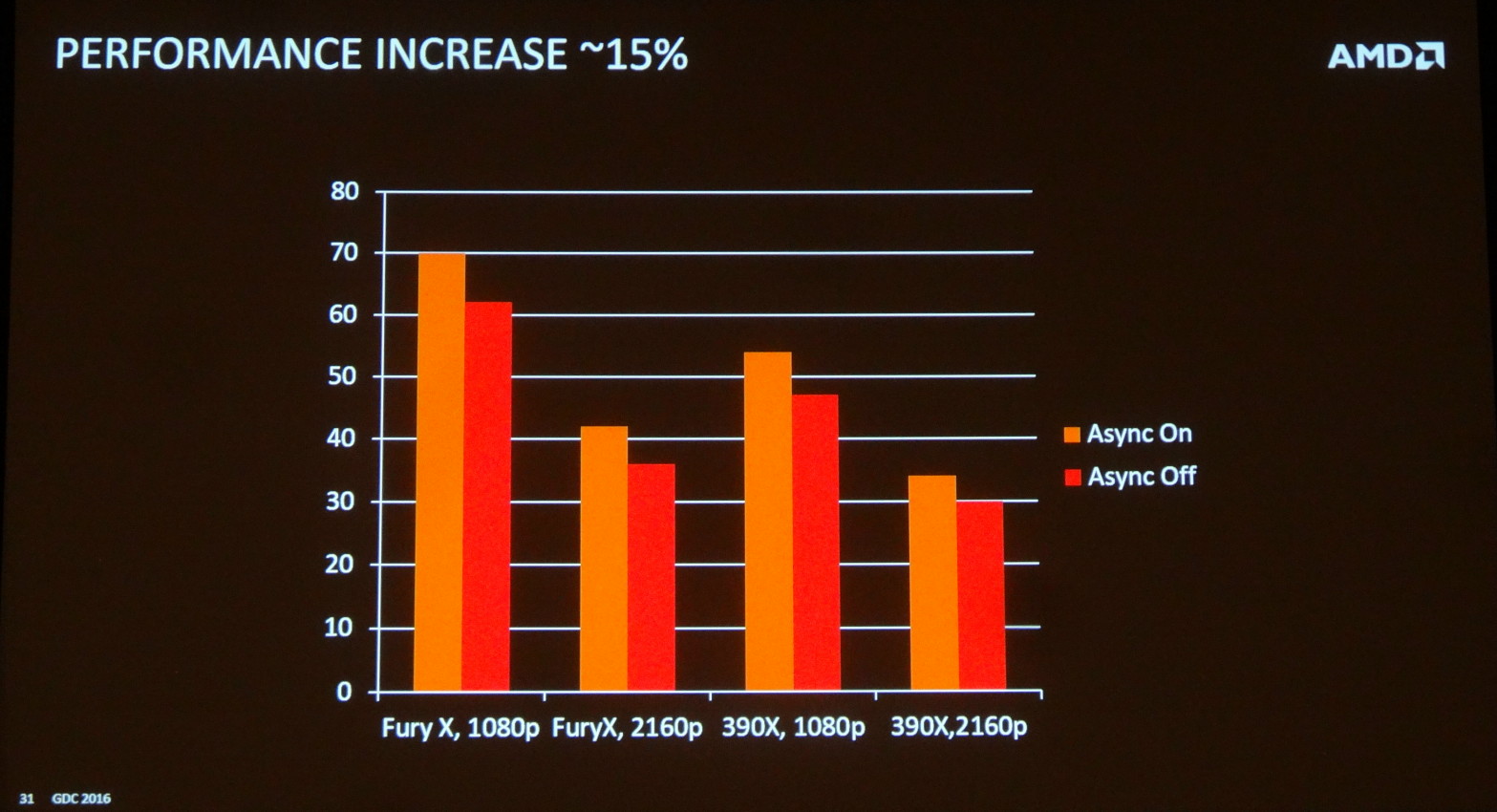
Au final, ce recours au multi engine dans AotS permet de gagner environ 15% de performances (voire un peu plus) au prix d'une demi-image de latence supplémentaire (voire un peu moins), ce qui représente un bon compromis. Tout du moins pour les Radeon qui profitent des avantages, contrairement aux GeForce qui actuellement se contentent des désavantages de cette approche.
Vous pourrez retrouver l'intégralité de la présentation d'Oxide ci-dessous :








GDC: Futuremark en dit plus sur VRMark
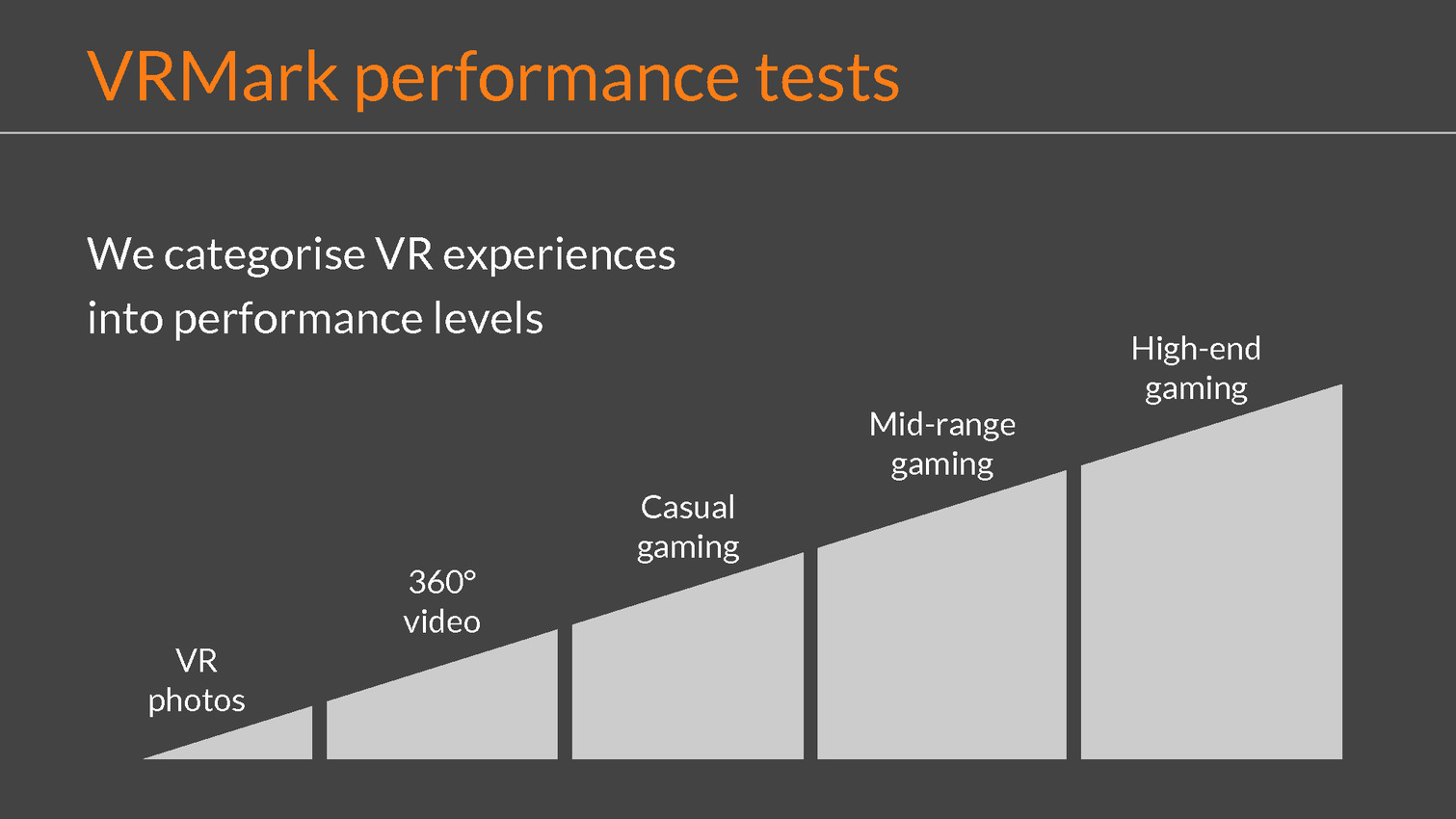
Futuremark, dont le produit le plus célèbre est sans aucun doute 3DMark, a décidé de mettre les bouchées doubles sur le développement d'une nouvelle suite de tests dédiée à la réalité virtuelle (VR). La GDC était l'occasion pour le finlandais de détailler ses plans et d'essayer de convaincre l'industrie de l'utilité de sa solution baptisée VRMark.

Les investissements conséquents opérés récemment par les différents acteurs de l'industrie envers le développement de la réalité virtuelle entretiennent l'idée du développement d'un large marché et donc de la multiplication des casques dédiés et des systèmes exploités à cet effet. Ce type d'environnement est idéal pour les spécialistes du benchmark qui tirent la majorité de leurs revenus de l'exploitation professionnelle de leurs outils d'évaluation.
Tout comme Basemark, Futuremark travaille ainsi depuis quelques temps à la mise au point d'un benchmark dédié à la VR en essayant d'en prendre en compte un maximum d'éléments. Contrairement à la 3D temps réel classique, la VR n'a pas simplement besoin d'un certain niveau de performances, mais a également des exigences en termes de régularité et de latence. Des aspects qui en fait sont importants pour tout type d'affichage, même si dans une moindre mesure, mais c'est l'arrivée de la VR et du marché potentiellement énorme qu'elle représente qui pousse Futuremark et Basemark à aller plus loin que précédemment.
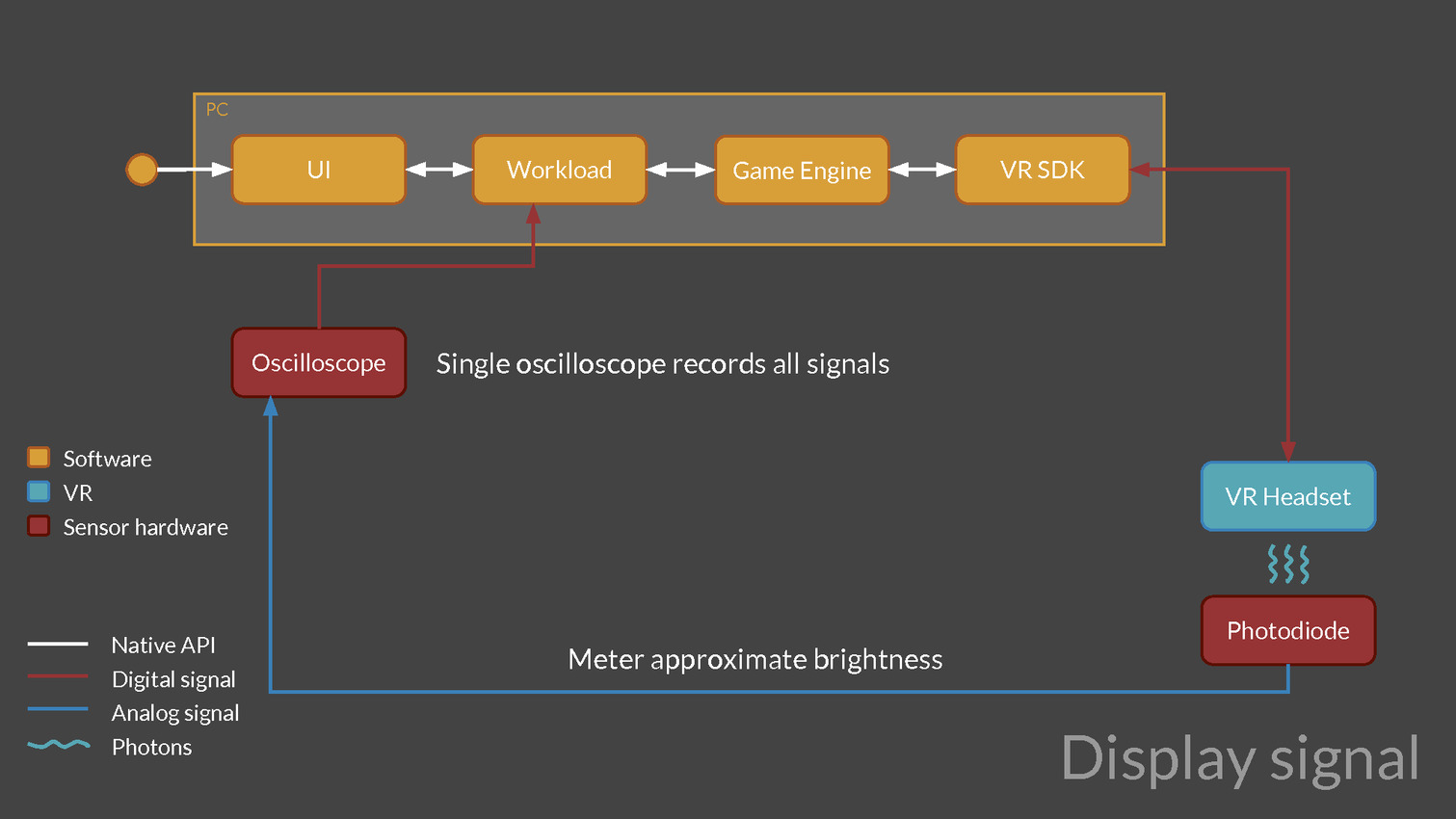
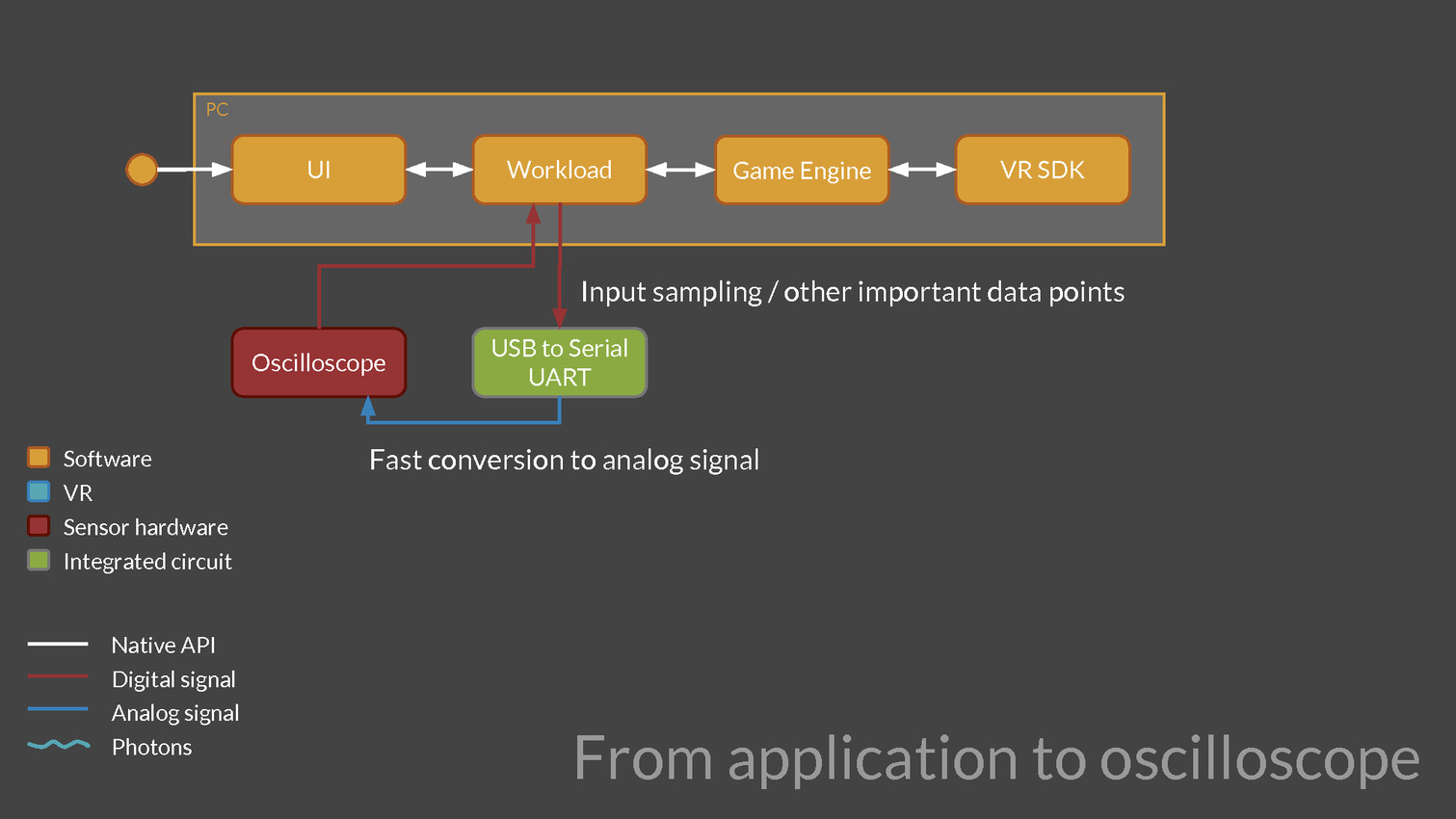
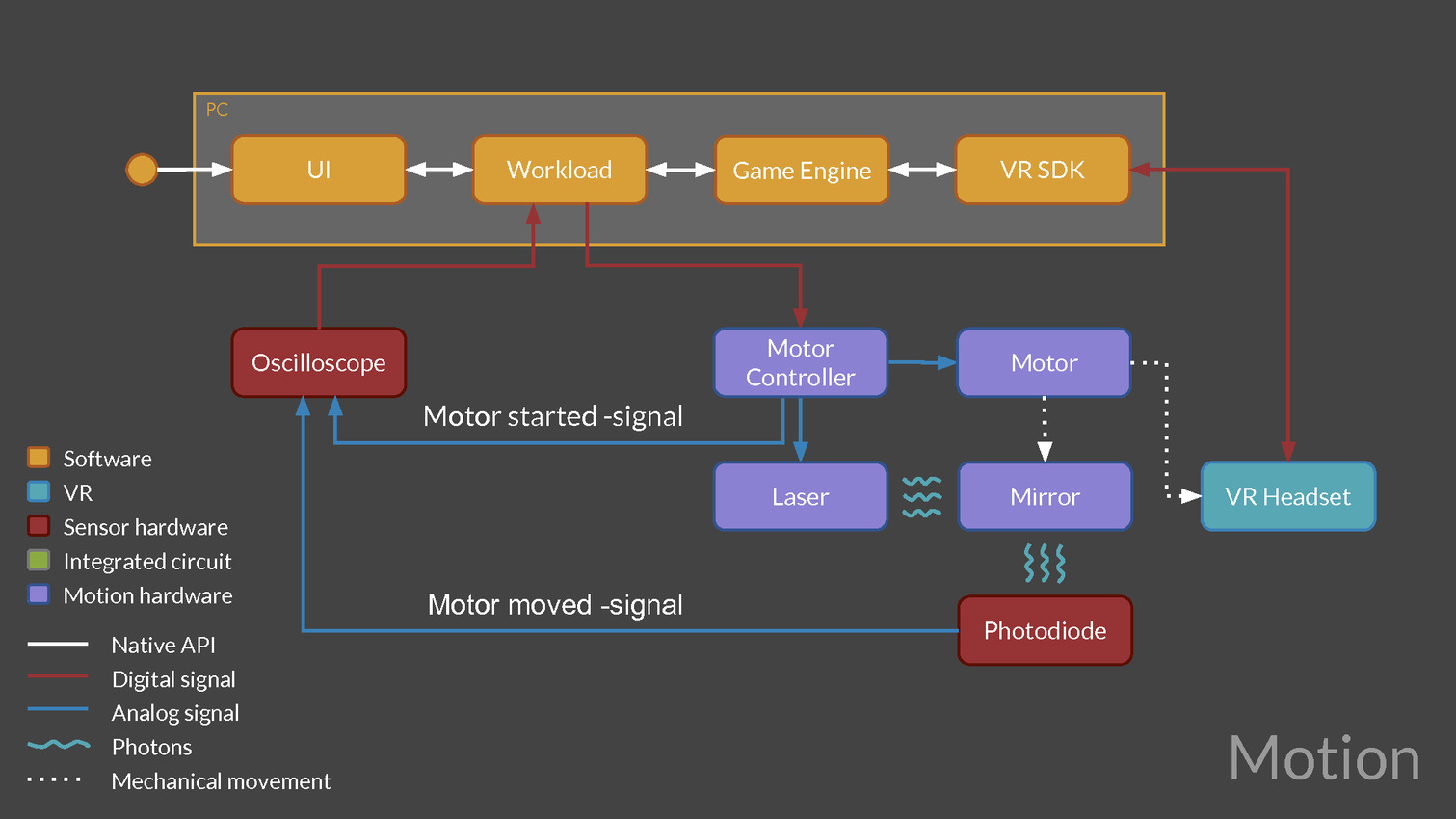
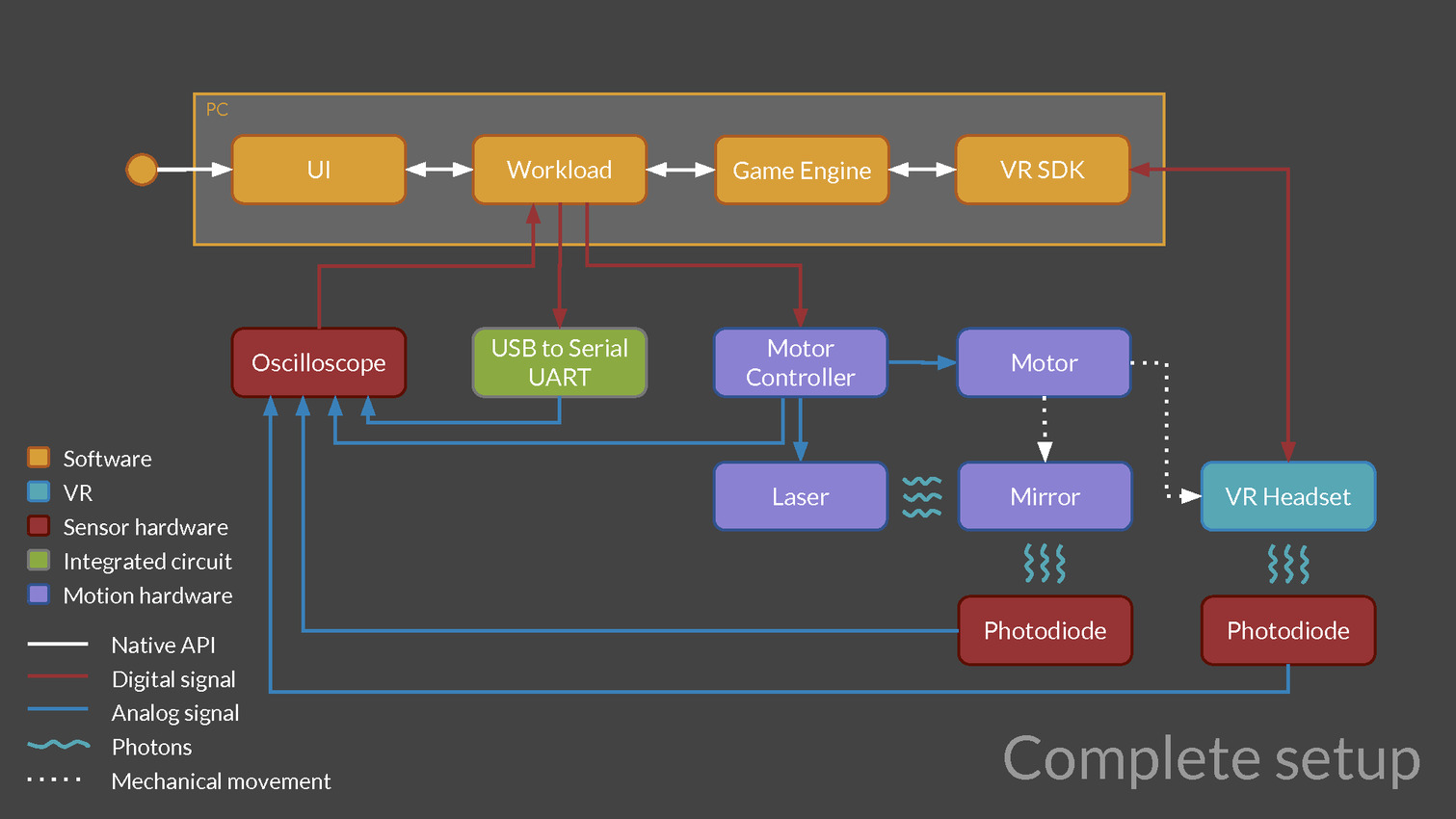
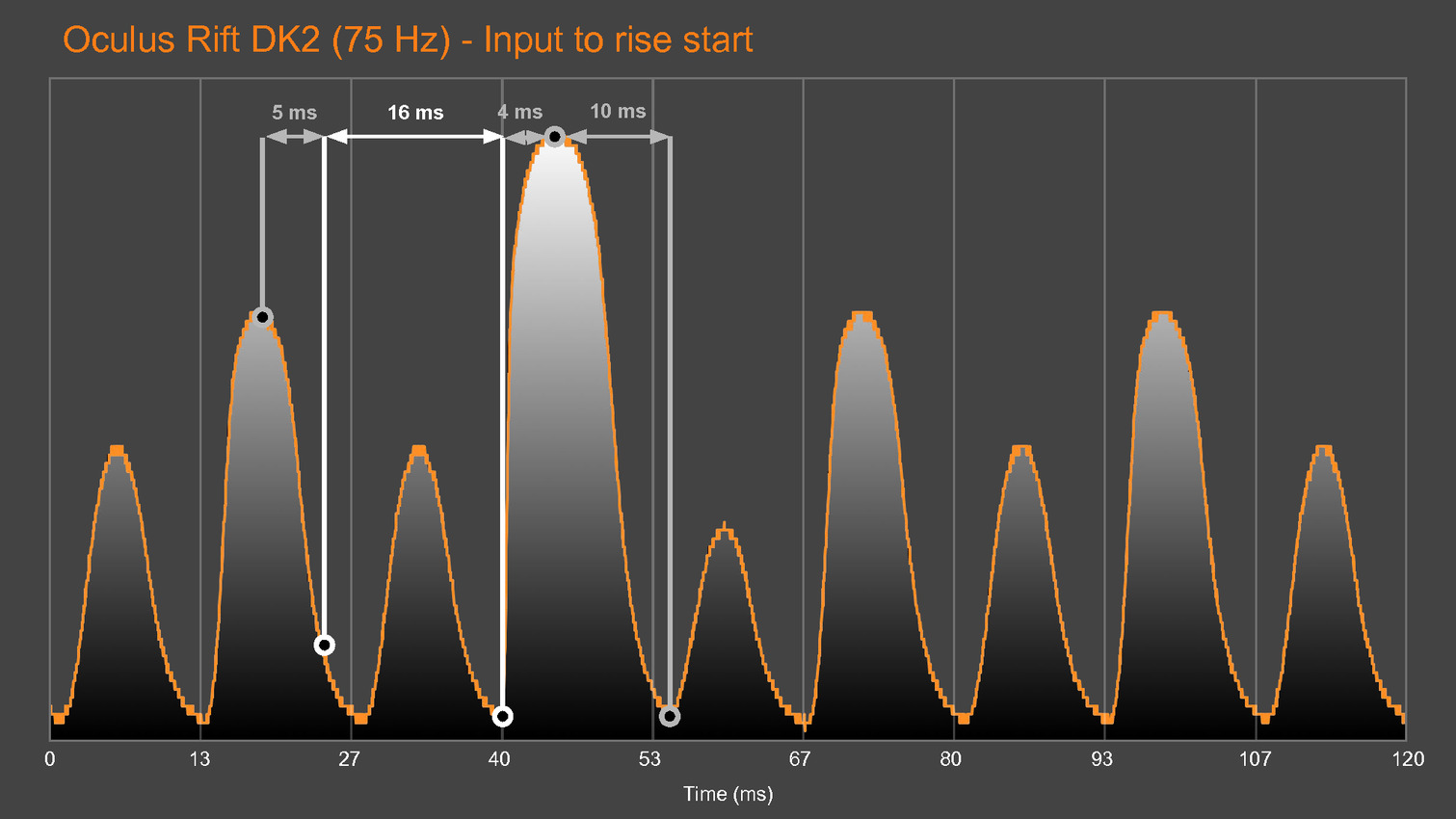
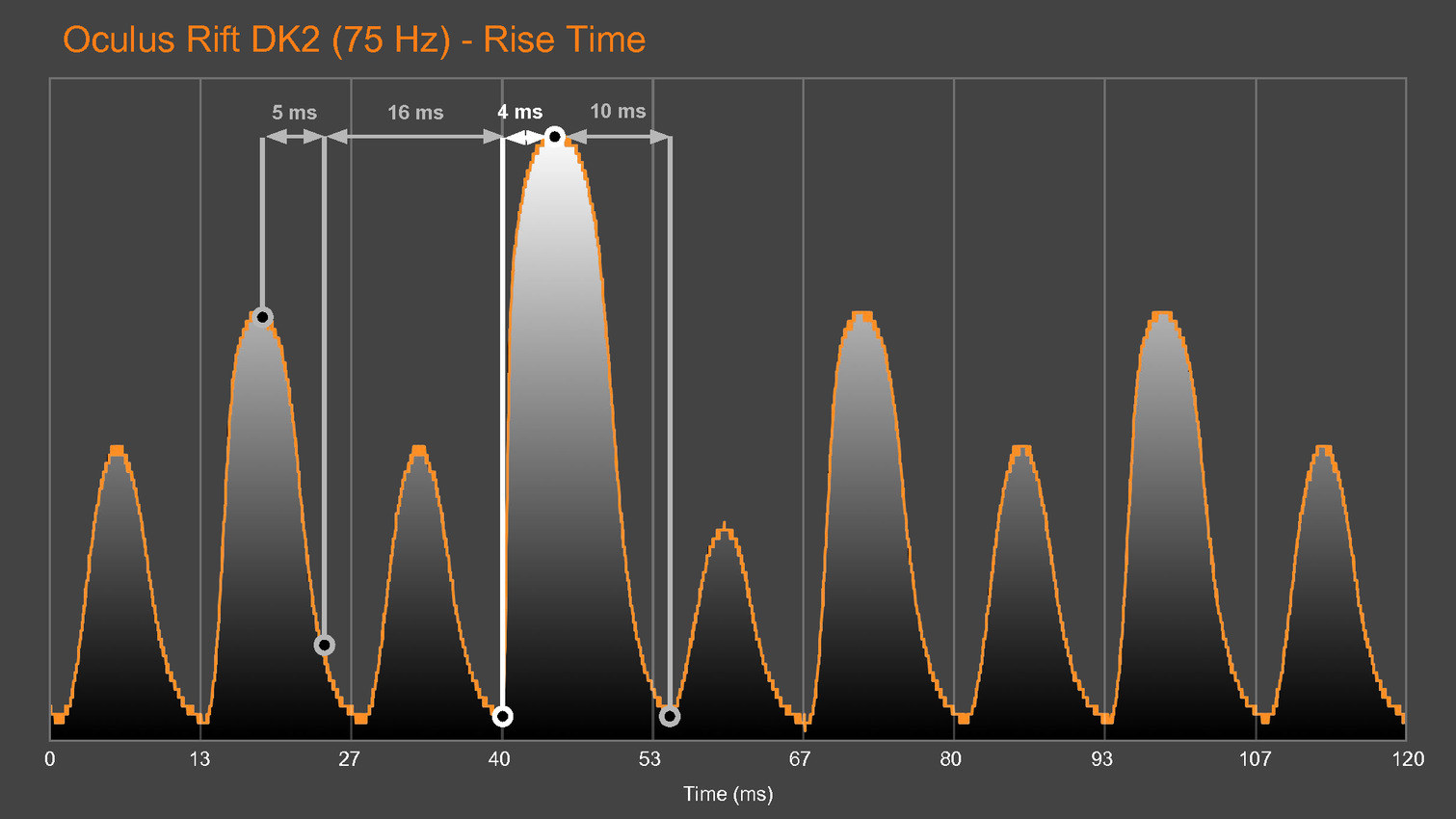
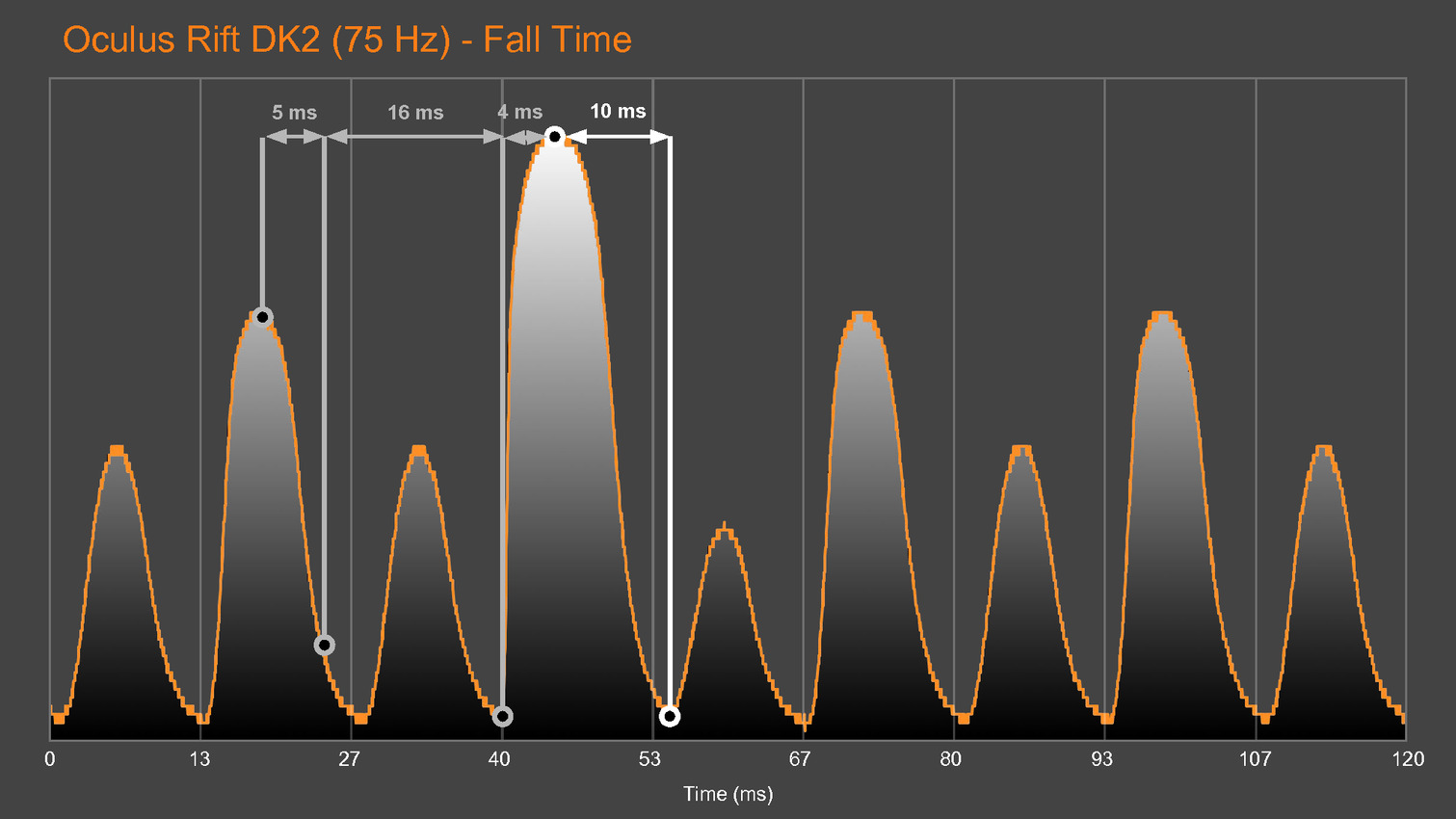
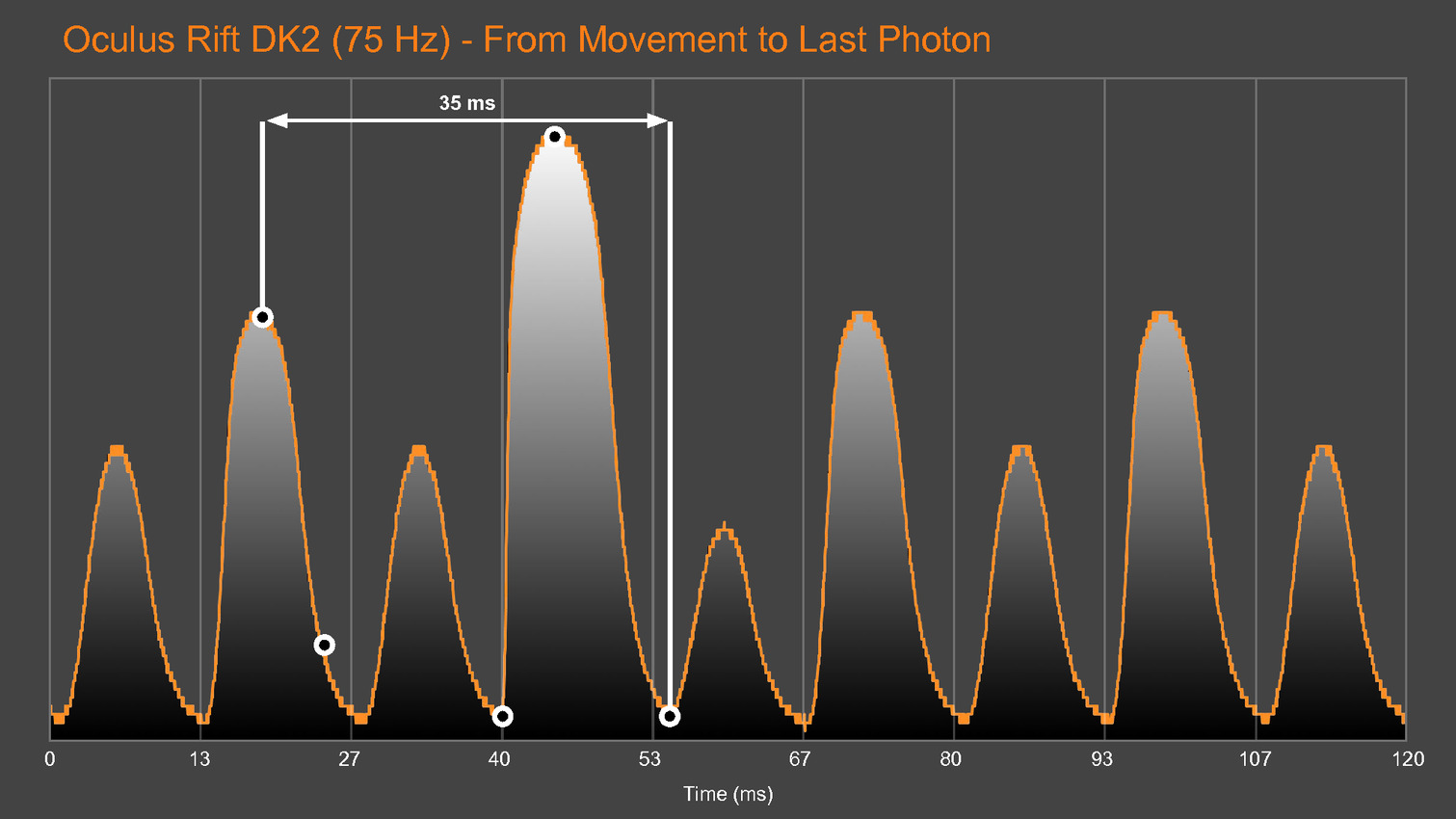
Une version preview de VRMark est proposée depuis quelques temps déjà, mais la version finale va aller beaucoup plus loin, c'est d'ailleurs déjà en partie le cas pour les versions beta que nous évaluons et qui sont fournies avec un équipement externe chargé d'observer la latence. Cet équipement est constitué d'un oscilloscope et d'une photodiode pilotés par VRMark pour mesurer la latence de l'application au photon, que ce soit pour un casque de réalité virtuelle (HMD - Head Mounted Display) ou pour un moniteur classique.

Futuremark développe également un équipement supplémentaire équipé d'un moteur qui va faire bouger les HMD de manière contrôlée pour aller plus loin et mesurer la latence de la prise en compte du mouvement de la tête. D'autres tests sont prévus par exemple pour mesurer la précision du système de positionnement ou encore la qualité du time warping, cette technique qui consiste à reprojeter l'image rendue pour simuler un angle de vue légèrement différent. Abuser du time warping peut réduire la latence et améliorer les performances mais conduire à des défauts visuels importants.
Mais évidemment à la base de VRMark nous retrouvons un benchmark 3D qui reprend d'ailleurs des scènes aperçues dans les précédents 3DMark. Des modifications plus ou moins importantes ont cependant dû être apportées pour la VR, par exemple l'abandon de certains effets de post processing tels que la simulation de la profondeur de champ ou les réflexions liées aux lentilles.

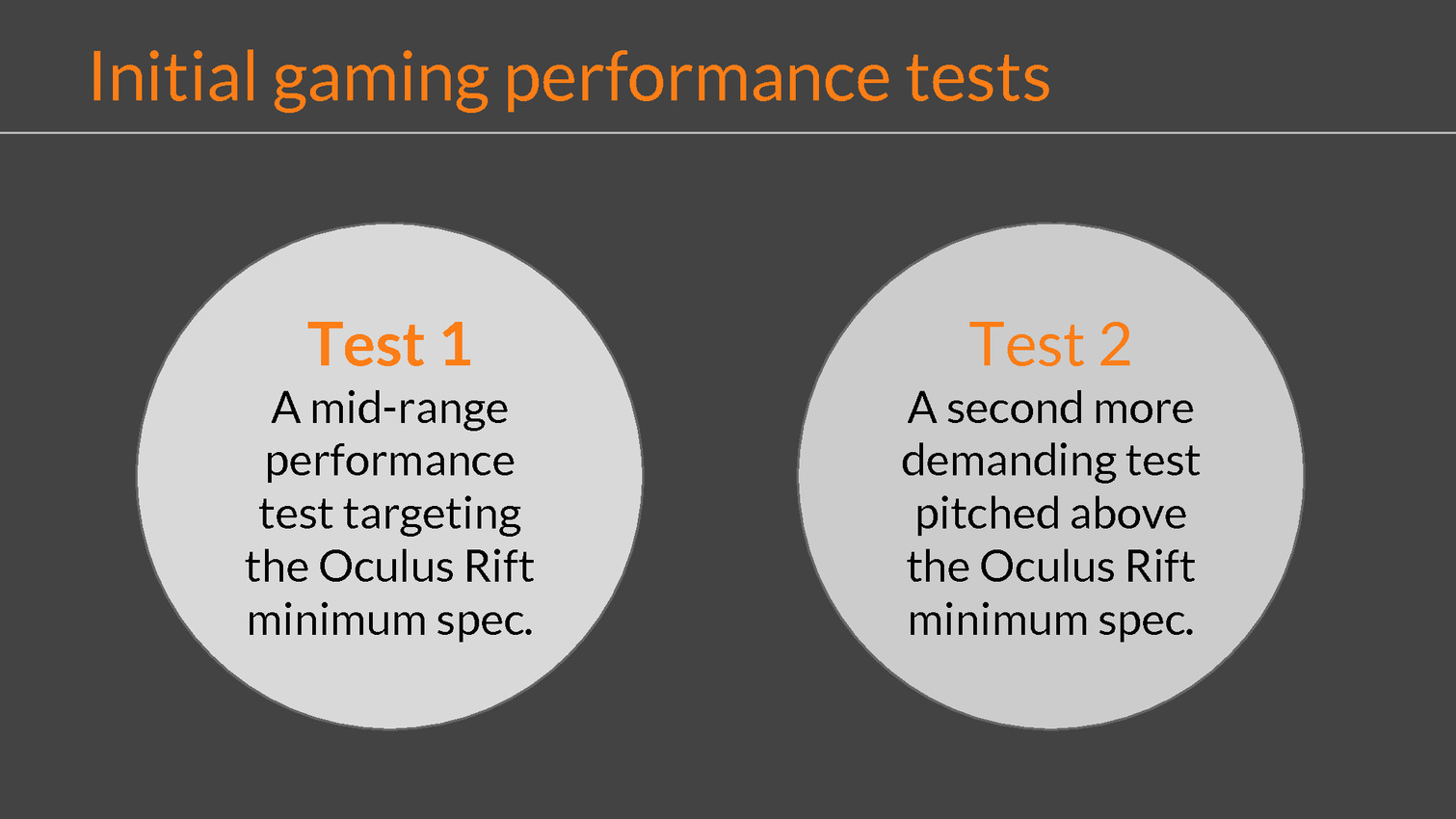
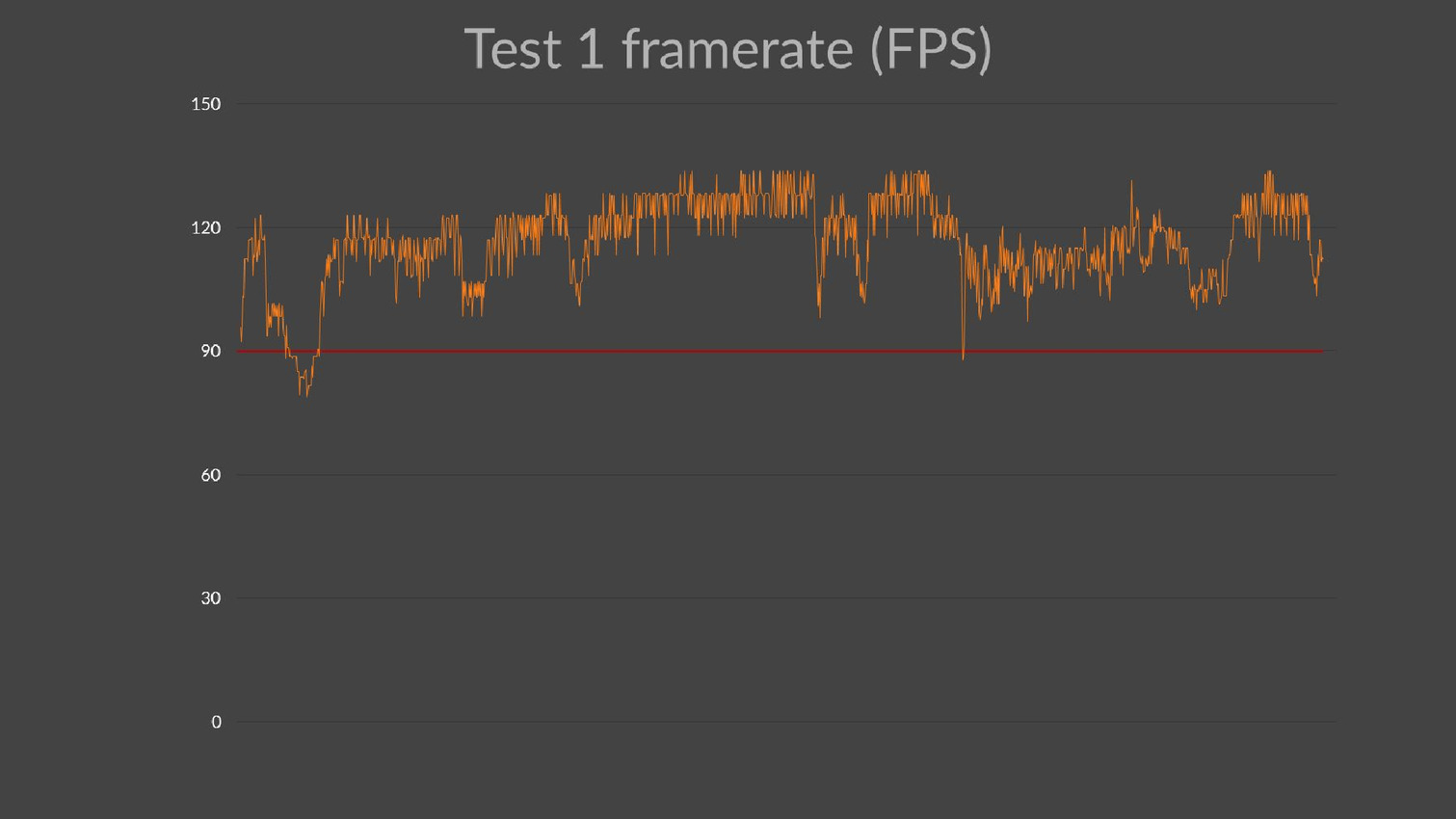
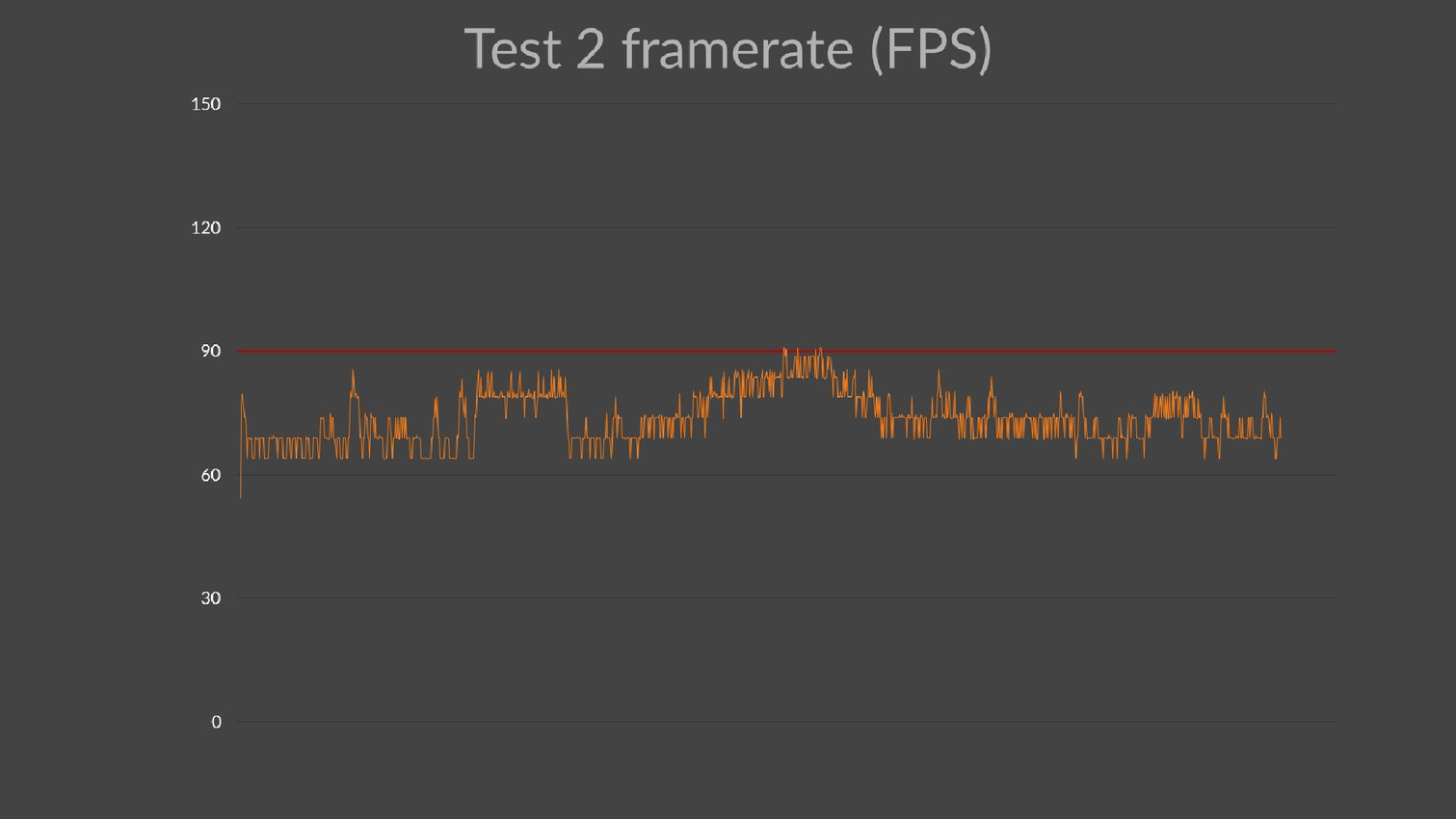
La modification principale concerne cependant le niveau de performances visé. Traditionnellement un 3DMark va chercher à pousser les cartes graphiques dans leurs derniers retranchements quitte à faire appel à des effets graphiques au coût disproportionné. Pour VRMark le but est d'obtenir une expérience réaliste. Deux niveaux de qualité sont proposés. Le premier cherche à obtenir au moins 90 fps en permanence sur les systèmes recommandés par Oculus et HTC (GTX 970 ou R9 290, alors que le second augmente quelque peu la charge et a plutôt besoin d'une GTX 980 Ti pour maintenir les 90 fps. Pour atteindre ce niveau de performances avec un contenu relativement riche, Futuremark a simplifié la géométrie ou encore réduit le nombre de particules. Deux aspects qui permettent des gains conséquents sans trop nuire au résultat final.
Une version encore plus simple est par ailleurs envisagée pour la VR sur mobile. Enfin, Futuremark développe une version haut de gamme de VRMark qui fera appel à DirectX 12 et Vulkan ainsi qu'un test spécifique à la réalité augmentée. Si aucune date n'est fixée pour l'arrivée de tous ces outils, il est évident que Futuremark fait le maximum pour les sortir le plus rapidement et profiter de l'exposition liée au lancement des premiers HMD.
Vous pourrez retrouver l'intégralité de la présentation de Futuremark ci-dessous :












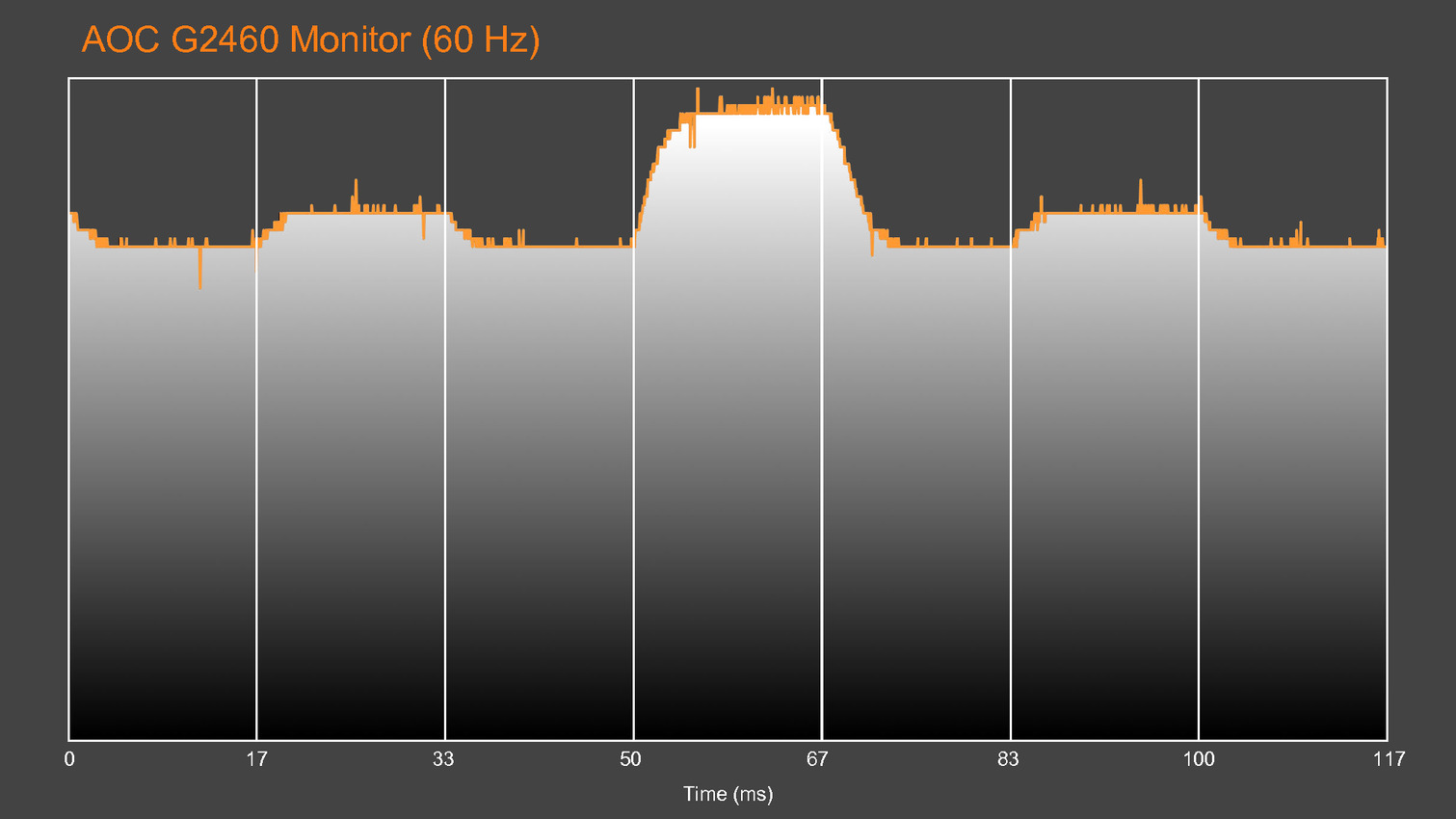
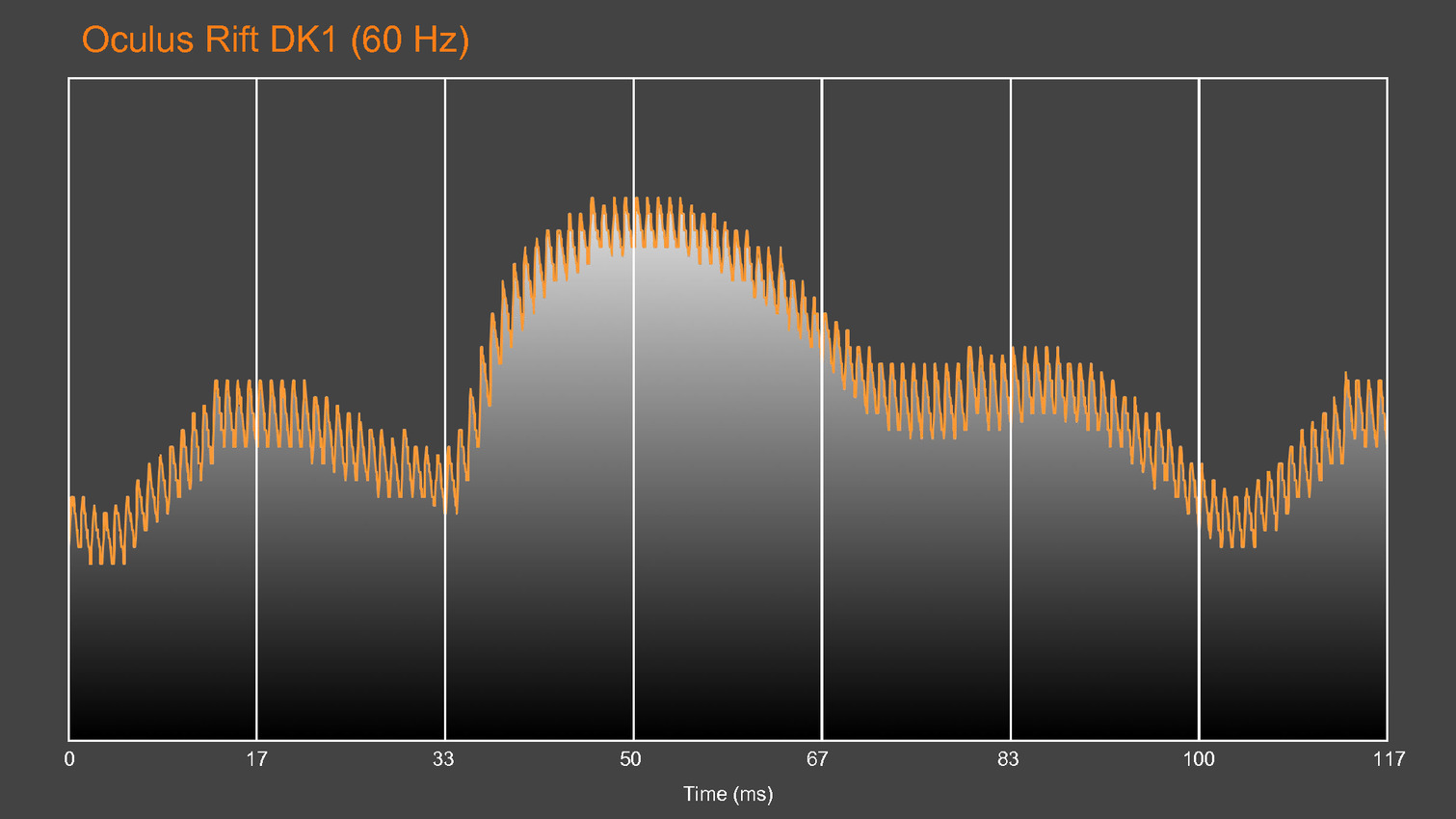
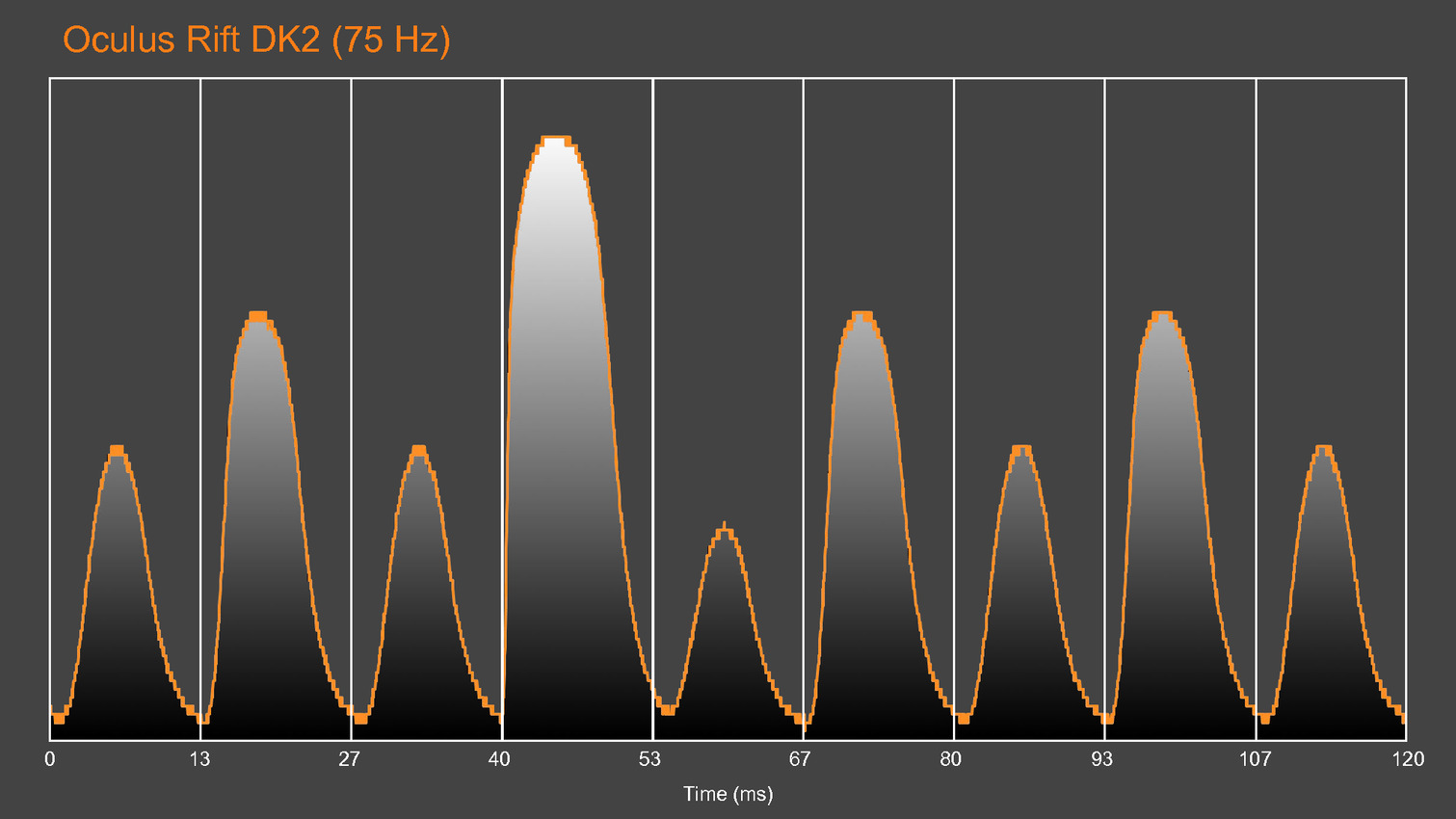
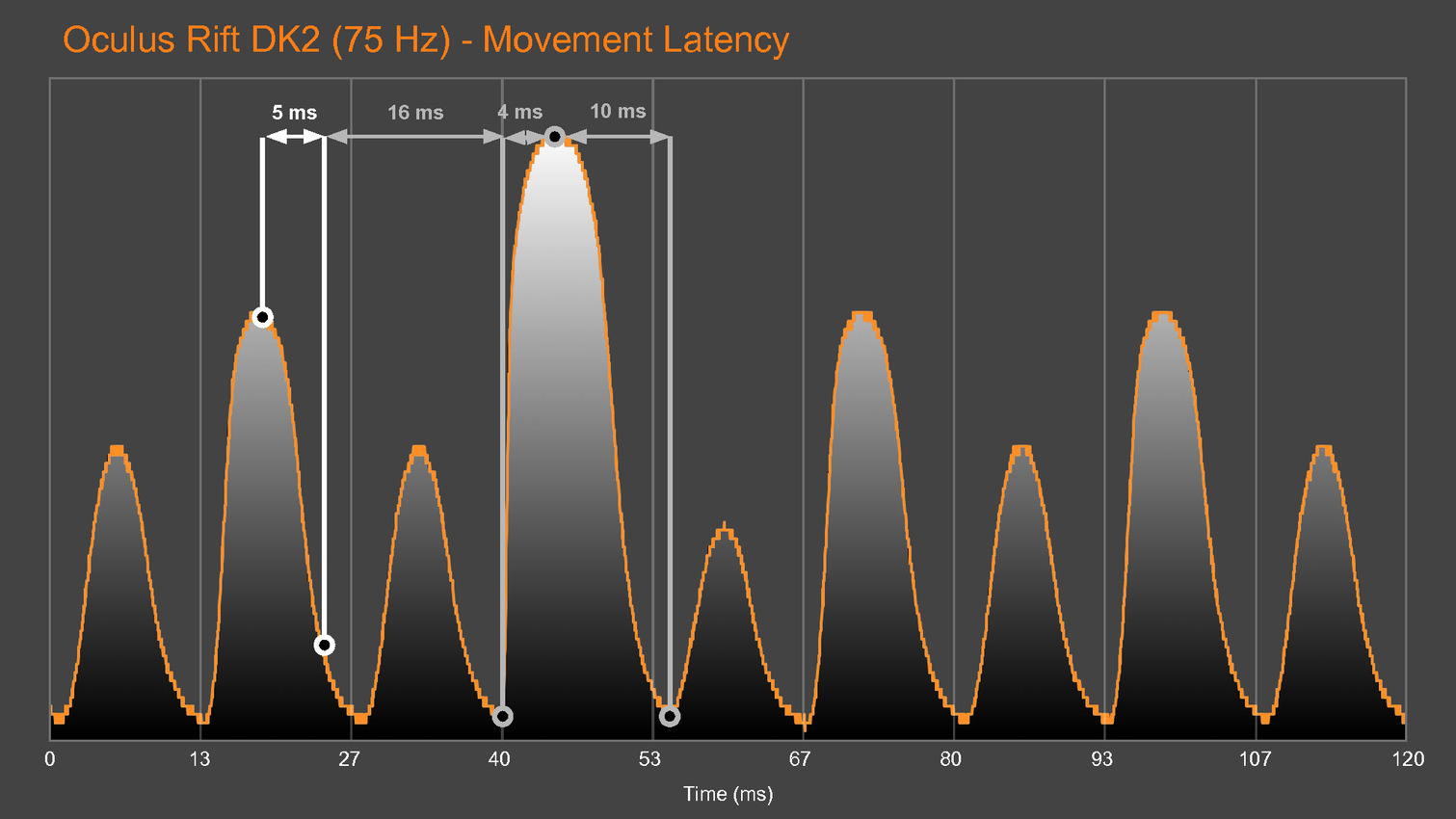



















GDC: Basemark et Crytek annoncent VRScore
Basemark et Crytek ont annoncé à la GDC un nouveau benchmark destiné principalement à la réalité virtuelle. VRScore, c'est son nom, est issu d'un partenariat stratégique mis en place l'an passé entre les deux sociétés. Comme vous pouvez vous en douter, il est basé sur le CryENGINE accompagné par le framework de Basemark pour mesurer et reporter les performances.



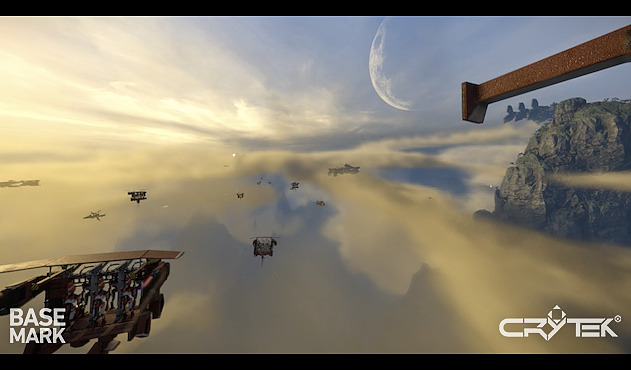
VRScore, proposé exclusivement sur PC, supporte DirectX 11 et DirectX 12 et exploite une scène de complexité moyenne, nom de code Sky Harbor, représentative de ce qui peut se faire en jeu. C'est assez différent de ce que peuvent proposer les benchmarks graphiques classiques qui en général poussent la qualité graphique à un niveau plus élevé, quitte à faire appel à des options au coût disproportionné. Dans le cadre de la réalité virtuelle le but est de proposer un benchmark capable de tourner à 90 fps. La présence d'un HMD (Head Mounted Device) sur le système est optionnelle pour la mesure des performances. Trois tests principaux seront proposés : VR interactive, VR non-interactive et VR audio.
Mais réalité virtuelle oblige, VRScore ne se contente pas de mesurer les performances. Il note la capacité à maintenir une expérience aussi confortable que possible, ce qui inclut la latence d'affichage. Pour cela, Basemark a dû développer un matériel spécifique, le VRScore Trek. L'objectif était de pouvoir proposer un système simple et bon marché. Après différents essais, Basemark estime avoir mis au point une solution plutôt élégante basée sur 2 photodiodes dont le signal est transmis au PC via l'entrée micro. De quoi pouvoir mesurer la latence de l'application au photon, les frames passées ou dédoublées et observer la latence pour chaque oeil, qui pourrait être différente sur certains HMD avec certaines techniques de rendu.

Il suffit de placer les diodes à proximité d'une dalle ou des lentilles d'un HMD pour permettre au système de juger de la latence via l'affichage d'images de couleurs spécifiques. Basemark n'a pas pu nous en dire plus à ce sujet, l'aspect logiciel n'ayant pas encore été finalisé. Il sera cependant possible d'exploiter ce matériel pour juger de la latence des écrans classiques et des options spécifiques aux écrans FreeSync / G-Sync sont actuellement prises en considération.
VRScore est actuellement proposé en version beta aux partenaires de Basemark en vue de son évaluation. La disponibilité publique est annoncée pour juin 2016 avec des options gratuites et payantes. Il faudra passer par la version corporate pour bénéficier du Trek, pour un tarif qui reste à définir.