
Les contenus liés aux tags Nvidia et CUDA
Afficher sous forme de : Titre | FluxComputex : Nvidia mise sur GPU Computing
Dossier: Nvidia CUDA : l'heure de la concrétisation ?
Premier Centre d'Excellence CUDA
CUDA : version 2.0 beta et concours
Dossier: Nvidia CUDA : plus en pratique
CUDA 5.0 final est disponible
Après une release candidate, Nvidia vient de rendre disponible la version finale de CUDA 5.0 . Rappelons que CUDA représente l'écosystème de programmation massivement parallèle qui englobe l'architecture de ses GPU et tout l'environnement logiciel dédié à leur bonne exploitation.
CUDA 5.0 apporte tout d'abord, enfin, un environnement de développement intégré (IDE) dédié à Eclipse, la plateforme ouverte qui, en plus de Windows, supporte également Linux et Mac OS. Nsight Eclipse Edition se limite par contre à CUDA alors que Nsight Visual Studio Edition se charge également de la partie graphique.
Le but premier de CUDA 5.0 est cependant de supporter le GK110 de manière à préparer son arrivée. Ce GPU, et peut-être d'autres dérivés, reprend la base de l'architecture Kepler mais l'améliore sur certains petits détails. Des détails qui pourront faire la différence dans le monde du calcul haute performance.
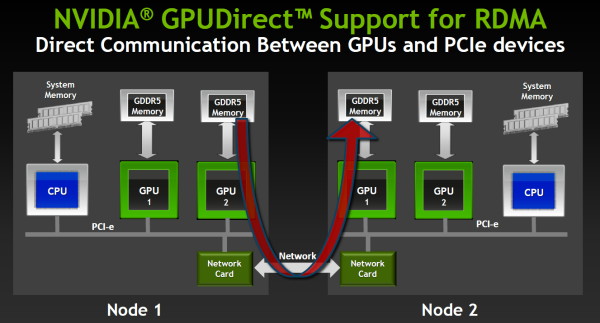
Ainsi la capacité de communication inter-GPU, dénommée GPUDirect chez Nvidia, évolue pour supporter le RDMA. Ce protocole permet à un GPU d'accéder à la mémoire d'un autre GPU même quand celui-ci est situé dans un nud différent, sans devoir organiser ces transferts depuis le CPU, ce qui a un coût beaucoup plus important. Les interfaces réseaux doivent également supporter cette technologie pour qu'elle soit fonctionnelle et Nvidia précise travailler activement avec les principaux fournisseurs à ce niveau.
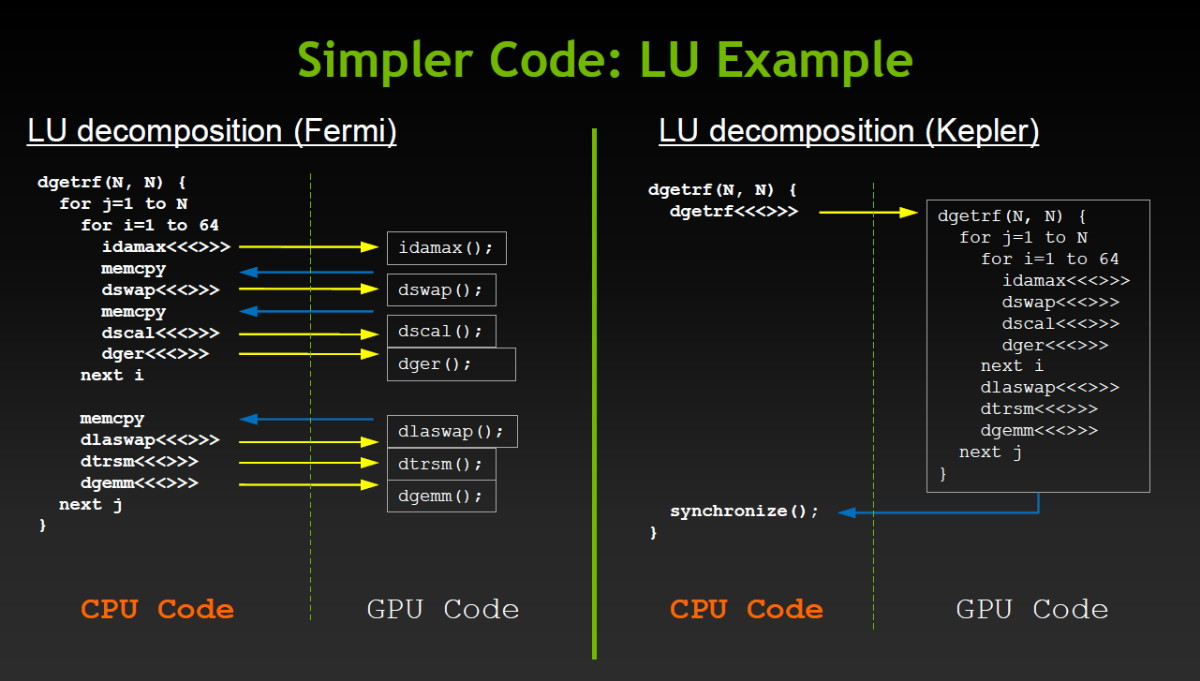
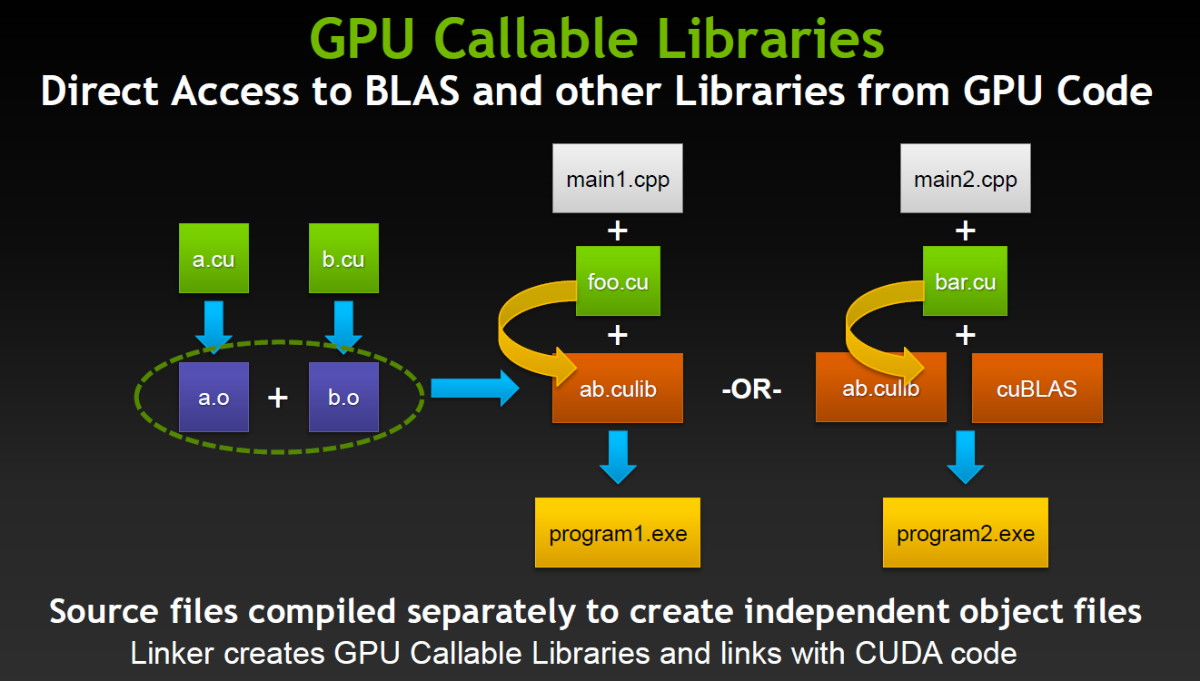
CUDA 5.0 supporte également la capacité du GK110 à lancer de lui-même des fonctions CUDA, une avancée très importante pour faciliter la bonne exploitation du GPU. Dénommée Dynamic Parallelism, cette possibilité permet également au GPU d'appeler directement des librairies, de quoi faciliter leur utilisation, réduire les temps de compilation mais également permettre l'arrivée de librairies propriétaires hyper optimisées.
Nvidia profite de l'arrivée de CUDA 5.0 pour lancer une version en ligne de ses documentations auparavant limitées pour la plupart à des documents PDF. Vous pourrez ainsi retrouver la guide de programmation complet pour CUDA 5.0 par ici dans lequel sont exposées les petites différences apportées par le GK110 (CUDA device 3.5).
Nvidia, PGI et Cray dévoilent OpenACC
Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
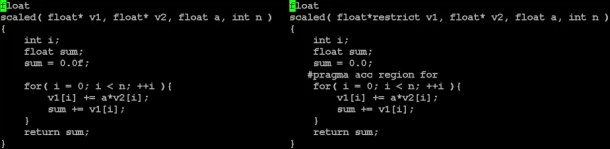
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .
Passerelle CUDA pour le kernel linux



 Luniversité dUtah, en partenariat avec Nvidia , vient de rendre disponible un projet original pour Linux baptisé kgpu . Lidée est de proposer une passerelle pour le noyau Linux sous la forme dun mini pilote capable de communiquer avec des modules CUDA, qui continueront tout de même de sexécuter en mode utilisateur. Sur le papier lidée nest pas inintéressante puisque cela permet de décharger certaines tâches systèmes des pilotes du noyau vers la carte graphique et son GPU. Pour mettre en avant lintérêt du concept, les auteurs ont réecrit un module de cryptage pour eCryptfs en version GPU. Dans ce test que vous pouvez voir ici . Si les résultats sont convaincants en lecture, en écriture les gains dépendent massivement de la taille des données écrites.
Luniversité dUtah, en partenariat avec Nvidia , vient de rendre disponible un projet original pour Linux baptisé kgpu . Lidée est de proposer une passerelle pour le noyau Linux sous la forme dun mini pilote capable de communiquer avec des modules CUDA, qui continueront tout de même de sexécuter en mode utilisateur. Sur le papier lidée nest pas inintéressante puisque cela permet de décharger certaines tâches systèmes des pilotes du noyau vers la carte graphique et son GPU. Pour mettre en avant lintérêt du concept, les auteurs ont réecrit un module de cryptage pour eCryptfs en version GPU. Dans ce test que vous pouvez voir ici . Si les résultats sont convaincants en lecture, en écriture les gains dépendent massivement de la taille des données écrites.
Kgpu reste pour linstant un exercice de style plus quautre chose, en grande partie à cause de lalgorithme de cryptage implémenté actuellement (ECB) qui nest pas considéré comme sécurisé. Dans labsolu, on peut également se poser la question de lintérêt dun cryptage qui nécessite de faire transiter les données dans un espace mémoire utilisateur à cause de la passerelle. En prime, si la méthode qui consiste à utiliser un mini driver côté kernel et un pilote en mode utilisateur est bonne pour la majorité des tâches, dans le cas de tâches critiques comme les accès disques, la gestion de la mémoire peut devenir problématique.
Dans tout les cas, linitiative nest pas inintéressante et devrait peut être inciter toute lindustrie qui pousse actuellement le GPGPU à proposer des pilotes OpenCL qui puissent exécuter également du code côté noyau.
Dossier : Encodage H.264 - CPU vs GPU : Nvidia CUDA, AMD Stream, Intel MediaSDK et x264 en test
L'encodage de vidéos est souvent considéré comme la première application grand public du GPGPU. Performances, rapidité, qualité, faisons le point sur l'intérêt de ces solutions !
[+] Lire la suite

Focus : Nvidia annonce CUDA 4.0
Pour fêter les 4 ans d’anniversaire de CUDA, Nvidia vient de lever le voile sur la version 4.0 du kit de développement qui permet de profiter de la puissance de calcul des GPUs dans de nombreux domaines. C’est en effet début février 2007 que Nvidia nous fournissait la première version bêta de son kit de développement, avant d’en sortir une version 1.0 au mois de juin de la même année.
Si, à l’origine, CUDA représentait le nom de l’architecture introduite par Nvidia pour faciliter...
[+] Lire la suite
