
Les contenus liés aux tags Nvidia et CUDA
Afficher sous forme de : Titre | FluxCUDA 5.0 final est disponible
Nvidia, PGI et Cray dévoilent OpenACC
Passerelle CUDA pour le kernel linux
Dossier: Encodage H.264 - CPU vs GPU : Nvidia CUDA, AMD Stream, Intel MediaSDK et x264 en test
Focus: Nvidia annonce CUDA 4.0
GTC: CUDA on ARM: Tegra 3 + Tesla K20



En plus des plateformes CUDA on ARM destinées à simuler de futurs SoC que ce soit pour une utilisation de type périphérique mobile grand public ou de type micro-serveur, des développements se font également autour d'accélérateurs très puissants tels que les Tesla K20.
C'est le cas chez l'européen PRACE qui développe des systèmes dédiés au supercomputing et s'intéresse à CUDA on ARM depuis quelques temps. En collaboration avec le Barcelona Supercomputing Center, PRACE est en train de mettre au point une plateforme ARM équipée en GK110 : Pedraforca v2. Celle-ci est composée d'une carte mini-ITX sur laquelle prend place un module Q7 Tegra 3 dont 4 des lignes PCI Express 2.0 sont connectées à un switch PLX PCI Express 3.0 sur lequel vont venir se greffer un accélérateur Tesla K20 et une carte contrôleur InfiniBand 40 Gbps.

Cette plateforme a la particularité de ne pas rechercher la complémentarité entre les cores CPU et GPU. Grossièrement, le but est d'utiliser le SoC ARM uniquement pour activer un système CUDA plus ou moins indépendant. C'est la raison pour laquelle le Tesla K20 est associé à un contrôleur InfiniBand sur un même switch PCI Express 3.0 : ils peuvent ainsi communiquer très rapidement avec les accélérateurs d'autres nuds en ignorant autant que possible la communication avec les SoC et leurs mémoires.
Les développeurs de Pedraforca v2 sont bien conscients qu'une telle approche n'est pas une solution de remplacement générale à un système CUDA classique et se contentera de répondre avantageusement à un sous-ensemble de problématiques : si un problème massivement parallèle peut être résolu sans CPU, autant réduire l'encombrement et la consommation de celui-ci.
Une telle solution permet par ailleurs de simuler le comportement de futurs GPU haut de gamme qui pourraient intégrer un ou plusieurs cores ARMv8 Denver pour gagner en indépendance. De quoi commencer à préparer des algorithmes qui leur seront adaptés ?
GTC: CUDA on ARM: Kayla, Tegra 3 et GK208
Nvidia l'a enfin confirmé, CUDA arrivera enfin dans les SoC Tegra avec Logan. Cela ne veut pas dire pour autant que CUDA sur plateforme ARM doit attendre. Il s'agit d'un point important de la stratégie de Nvidia pour son futur autant dans le monde professionnel que grand public. C'est la raison pour laquelle, depuis quelques temps déjà, Nvidia s'est associé à SECO pour proposer un kit de développement dénommé CARMA. Pour 529, la plateforme propose un connecteur Q7 qui reçoit un SoC Tegra 3 (T30 à 1.3 GHz) et un connecteur MXM sur lequel prend place une Quadro 1000M de génération Fermi (GF108 avec 96 cores).

Tout cela va évoluer à partir du mois de mai, d'une part avec une couche logicielle qui supportera Ubuntu 12.04 et CUDA 5.0, et d'autre part avec la plateforme KAYLA, toujours développée en partenariat avec SECO, et qui existera en 2 versions : connecteur MXM ou PCI Express (câblés en 4x dans les 2 cas). Si nous aurions pu supposer que le SoC passerait en version Tegra 4, c'est bel et bien le Tegra 3 T30 qui reste exploité pour la simple et bonne raison que ses successeurs ne disposent plus de liens PCI Express. La différence (unique ?) entre les 2 cartes concerne les GPU supportés. La version PCI Express en supporte un large choix et la version MXM est annoncée être équipée d'un GPU Kepler de next generation.
Nvidia indique à ce sujet que ce GPU dispose de 2 SMX (384 cores), supporte les compute capabilities 3.5 (Dynamic Parallelism etc.) et est très proche du niveau de fonctionnalité du futur SoC Logan. Nous apprenons ainsi que le GPU de cette plateforme et celui de Logan disposent d'un processeur de commande plus évolué que sur les premiers GPU de la génération Kepler, dérivé de celui du GK110 (Tesla K20 et GTX Titan).
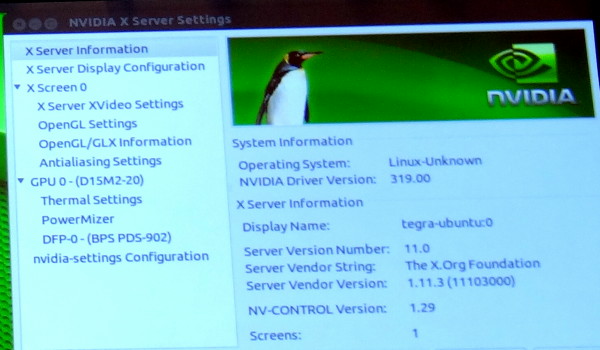
De toute évidence ce GPU est ainsi le GK208 qui prendra place dans les GeForce 700 d'entrée de gamme. Une supposition renforcée par un panneau de contrôle des pilotes Linux que Nvidia a malencontreusement oublié de masquer pendant quelques secondes et qui fait référence à un nom de code produit : D15M2-20. Cela correspond à la famille GeForce 700 desktop (D12 = GeForce 400, D13 = GeForce 500, D14 = GeForce 600 ).

Cette plateforme CUDA on ARM continuera bien entendu à évoluer, tout d'abord avec CUDA 5.5 qui intégrera un compilateur CUDA pour l'architecture ARM, et plus tard avec l'arrivée de Logan et de Parker.
Correction du 01/07/2013: le nom du GPU que nous pensions être GK117 est en réalité GK208.
GTC: Le futur de Tegra: CUDA, Logan, Parker
Après la roadmap GeForce, Nvidia nous en a dit un peu plus sur la roadmap des SoC Tegra. Si certains ont été quelque peu déçus de ne pas retrouver un GPU plus moderne dans Tegra 4, cela est en passe de changer. Jen-Hsun Huang a ainsi confirmé que la prochaine architecture Tegra, Logan, intégrerait enfin une évolution GPU majeure qui fera le pont avec les technologies qui nous retrouvons dans la gamme GeForce traditionnelles.
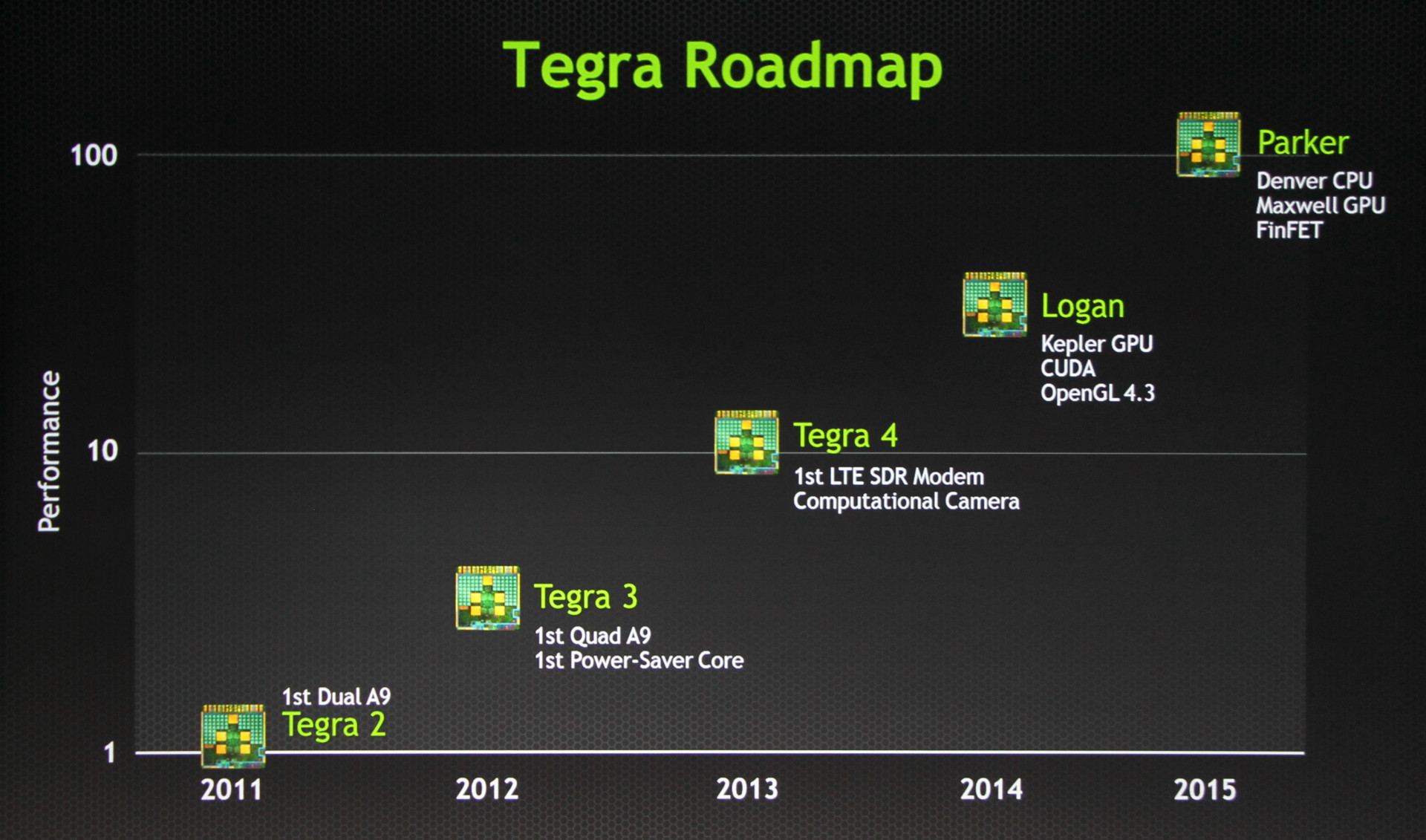
Ainsi, le GPU de Logan sera dérivé de l'architecture Kepler avec un support complet d'OpenGL 4.3 et surtout de CUDA 5 pour permettre d'exploiter la puissance de calcul du GPU d'une manière plus flexible, par exemple pour le traitement d'images. En plus de sa plateforme propriétaire CUDA, nul doute que Nvidia supportera également la plateforme ouverte OpenCL, qui, dernièrement, a enfin reçu un support clair de la part de Google en ce qui concerne Android.
Pour le reste, il est probable que Logan reprenne les mêmes cores Cortex-A15 que Tegra 4 et soit fabriqué en 20 nanomètres. Jen-Hsun Huang a précisé que si Tegra 4 est arrivé en retard, Tegra 4i est de son côté arrivé légèrement en avance alors que Logan devrait être à l'heure avec des premiers prototypes à la fin de l'année et une production qui débutera début 2014. Vous pouvez donc vous attendre à une annonce de Tegra 5 au CES 2014.
Tout ceci n'est cependant qu'une confirmation de ce que nous supposions déjà. La nouveauté est l'arrivée de quelques premières informations sur le successeur de Logan : Parker. Ce dernier arrivera en 2015 et intègrera les premiers cores ARM conçus en interne par Nvidia et basés sur l'architecture ARMv8 qui supporte le 64-bit, nom de code Denver. Au niveau du GPU, Parker passera à la génération Maxwell, avec seulement une année de décalage par rapport aux gros GPU dekstop, les architectures GPU étant dorénavant unifiées entre les différentes divisions de Nvidia.
Parker devrait également être la première puce conçue par Nvidia en vue de l'utilisation d'un procédé de fabrication de type FinFET ("transistors 3D) et nous pouvons supposer qu'il s'agira alors du 14nm.
GTC: CUDA s'ouvre officiellement à Python
Après le C, Fortran et le C++, c'est Python qui devient le quatrième langage officiel pour CUDA. Contrairement aux trois premiers langages, ce support ne provient pas directement de Nvidia mais profite de LLVM, une infrastructure de compilateur open source qui a été adoptée pour les compilateurs CUDA il y a un peu plus d'un an. Grossièrement, LLVM expose une représentation interne qui fait office d'intermédiaire entre l'architecture CUDA et les compilateurs, ce qui facilite l'ajout du support de l'accélération via GPU à la plupart des langages.
Si plusieurs variantes plus ou moins complètes de compilateurs Python pour CUDA existent depuis quelques temps, c'est le nouveau compilateur NumbaPro développé par Continuum Analytics qui a atteint le premier un niveau suffisamment avancé pour que Nvidia puisse annoncer Python en tant que quatrième langage officiel pour CUDA
Bien que la suite Anaconda Accelerate qui intègre NumbaPro ne soit pas disponible librement, elle coûte 129$ (mais devrait passer en open source à terme), le fait que Nvidia puisse valider de la sorte un compilateur Python mis au point par un développeur externe témoigne de l'intérêt de la stratégie qui a dicté le passage à LLVM.

Ce support de Python, très répandu dans l'industrie et le monde scientifique, devrait permettre à Nvidia de convaincre quelques développeurs réticents de plus de passer au GPU computing ou tout du moins de jeter un coup d'il aux possibilités qu'il pourrait offrir.
GK110 : Nvidia lance les Tesla K20 et K20X
A l'occasion de la conférence SC12, dédiée aux supercalculateurs et technologies liées, Nvidia annonce la disponibilité commerciale de l'accélérateur Tesla K20 dont nous vous avions déjà parlé. Cette carte embarque un GPU GK110 qui reprend l'architecture Kepler déjà en place sur les GeForce GTX 600 mais légèrement retouchée pour faciliter l'exploitation du GPU en tant qu'accélérateur.

Le GPU GK110 et ses 7.1 milliards de transistors.
Parmi les avancées citons une capacité de traitement en double précision très élevée, un texture cache plus flexible et surtout un processeur de commande plus évolué. Il est capable de gérer jusqu'à 32 files d'attente d'exécution pour mieux exploiter la capacité du GPU à exécuter plusieurs tâches concurrentes, ce que les GPU Nvidia précédents avaient du mal à faire en pratique. Il est également capable d'auto-générer des tâches, ce qui évite des allers-retours incessants avec le CPU qui réduisent l'efficacité réelle de l'accélérateur.
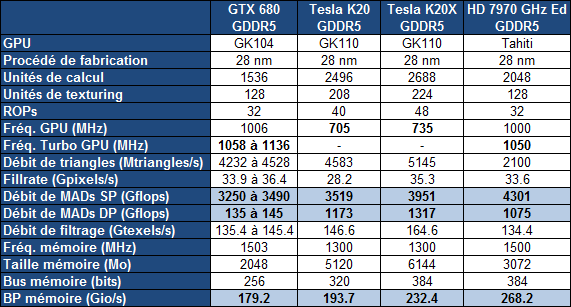
Par rapport à nos précédentes informations, les spécifications de la Tesla K20 sont confirmées, si ce n'est au niveau de la mémoire où elles évoluent très légèrement. Elle est donc bien basée sur un GK110 castré qui se contente de 13 blocs d'unités de calcul, SMX, sur les 15 physiquement présents sur la puce. Il en va de même pour les contrôleurs mémoire dont seulement 5 des 6 sont exploités, ce qui limite la mémoire de la Tesla K20 à 5 Go (4.38 Go avec ECC actif).
Petite surprise, Nvidia lance également une Tesla K20X. Le GK110 qu'elle embarque profite cette fois bien de 14 SMX, pour se rapprocher des 4 Tflops, ainsi que de ses 6 contrôleurs mémoire qui disposent donc de 6 Go de GDDR5 (5.25 Go avec ECC actif). C'est en réalité cette Tesla K20X qui prend place dans le supercalculateur Titan et nous pouvons imaginer que Nvidia a dû sortir 2 variantes de la K20 d'une part pour respecter le cahier de charge au niveau de ce supercalculateur et d'autre part pour disposer d'une production suffisante. Fabriquer un GPU de 7.1 milliards de transistors en 28 nanomètres reste un défi !
Avec plus d'unités de calcul et une fréquence légèrement supérieure, la Tesla K20X ne peut se contenter du TDP de 225W de la Tesla K20. Nvidia a cependant pu le limiter à une valeur proche : 235W. Il nous a par ailleurs été confirmé qu'une technologie de contrôle de la consommation similaire au GPU Boost des GeForce GTX 600 était bien présente sur cette carte et qu'elle pourrait éventuellement être personnalisée par certains fabricants de stations de travail et de serveurs, soit pour adapter la limite de consommation, soit pour activer sa composante turbo.

La Tesla K20 sera disponible en version workstation (refroidissement actif) ainsi qu'en version serveur (refroidissement passif) alors que la Tesla K20X n'existera que dans cette dernière version. Au moins deux formats serveurs sont proposés par Nvidia : carte PCI Express "classique" telle qu'illustrée ici ou SXM, similaire au MXM des cartes graphiques mobiles.

La disponibilité des Tesla K20 et K20X est annoncée pour la fin de ce mois avec un tarif de 3200$ pour la première alors qu'il faudra compter 5000$ pour la seconde. Des tarifs nettement plus élevés que sur la génération précédente qui laissent penser que, pour Nvidia, l'adhésion de l'industrie du calcul haute performance à ces accélérateurs massivement parallèles est désormais inéluctable. Nvidia compte sur un écosystème CUDA relativement répandu et réputé pour faire face à la concurrence des FirePro S d'AMD et des Xeon Phi d'Intel.