
Les contenus liés au tag CUDA
Afficher sous forme de : Titre | FluxPasserelle CUDA pour le kernel linux
Dossier: Encodage H.264 - CPU vs GPU : Nvidia CUDA, AMD Stream, Intel MediaSDK et x264 en test
Focus: Nvidia annonce CUDA 4.0
Computex : Nvidia mise sur GPU Computing
Dossier: Nvidia CUDA : l'heure de la concrétisation ?
Intel lance les Xeon Phi 5110P



Après AMD et Nvidia, c'est ce soir au tour d'Intel d'annoncer officiellement ses cartes accélératrices pour calculs parallèles dédiées au marché HPC (Hautes Performances) : les Xeon Phi.
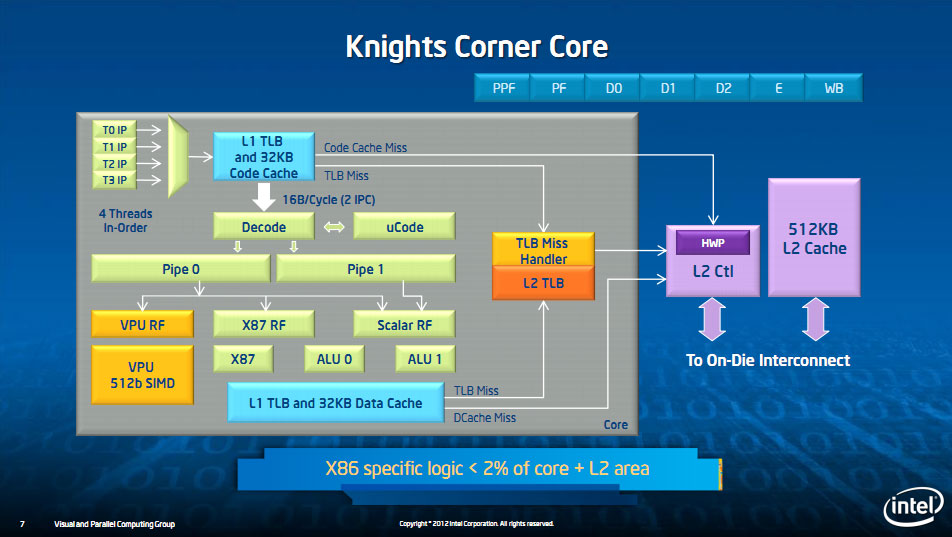
Nous avions présenté précédemment l'architecture de ces puces. Il s'agit pour rappel d'un processeur x86 très particulier où l'on retrouve sur le die 64 cores x86 de type P54C (Pentium) sur lesquels sont accolés un cache de niveau 2 ainsi qu'une large unité de calcul vectorielle (le P54C servant de chef d'orchestre en quelque sorte). Tous ces curs sont reliés autour d'un large ring bus (512 bits dans chaque sens) qui relie également ces curs à des contrôleurs mémoires GDDR5. Pour terminer ce rappel, terminons en indiquant qu'une des particularités du design de Xeon Phi est que les cartes font tourner leur propre système d'exploitation (un Linux) dans lequel s'exécutent les programmes.

Intel annonce donc aujourd'hui sa première carte, le coprocesseur Xeon Phi 5110P. Fabriqué en 22nm, on retrouve 60 curs actifs sur le die cadencés à une fréquence de 1.053 GHz. Xeon Phi est fabriqué en 22nm et chaque cur dispose de 512 Ko de cache de niveau 2.
Côté performances, le constructeur annonce 1010 Gigaflops en double précision, soit légèrement moins que les produits concurrents annoncés ce matin (1173, 1317 et 1478 respectivement pour les Tesla K20, K20X et Firepro S10000). Xeon Phi se distingue cependant côté mémoire avec 8 Go de mémoire GDDR5 (2.5 GHz) embarquée (5, 6 et 3 Go pour les Tesla K20, K20X et Firepro S10000 toujours) et une bande passante de 320 Go/secondes (contre 193.7, 232.4 et 447 Gio/s pour les modèles cités précédemment).

Côté tarifaire Intel est cependant plus agressif puisque sa carte est annoncée à 2649$ (3200, 5000 et 3600$ pour les cartes de Nvidia et d'AMD). Une position qui n'est pas surprenante, Intel étant un nouvel entrant sur ce type de marchés.
Petit tacle en passant à la concurrence
En ce qui concerne le développement d'application, Intel se repose avant tout sur ses propres compilateurs (avec des jeux d'extensions propriétaires) et ses bibliothèques comme MKL (Math Kernel Library) qui ont été portés pour l'architecture Xeon Phi.

Intel indique cependant qu'il s'agit d'une approche "pré-standard" et que l'avenir, aussi bien pour Nvidia que pour Intel est à la version 4.0 d'OpenMP qui - selon Intel - devrait représenter l'avenir de toutes les solutions de développement parallèles. Intel indique s'engager à fournir un compilateur OpenMP 4.0 pour le mois de janvier.

Notez que si les cartes Xeon Phi sont officiellement lancées aujourd'hui (Intel indique commencer les livraisons aujourd'hui à ses partenaires), la disponibilité générale des 5110P ne se fera que le 28 janvier 2013. D'autres déclinaisons sont également prévues avec la famille Xeon Phi 3100 annoncés pour la première moitié 2013 (et qui devraient reposer sur une nouvelle version de la puce). Disponibles en versions actives et passives pour un TDP de 300 watts, les cartes viseront au-delà d'un téraflop DP pour un prix inférieur à 2000$. Le nombre de curs actifs sur ces cartes n'est pas officiellement annoncé, mais avec 28.5 Mo de mémoire cache L2 sur les 3100 Series, il devrait être de 57. Les cartes embarqueront également moins de mémoire avec seulement 6 Go, la bande passante tombant à 240 Go/s.
GK110 : Nvidia lance les Tesla K20 et K20X
A l'occasion de la conférence SC12, dédiée aux supercalculateurs et technologies liées, Nvidia annonce la disponibilité commerciale de l'accélérateur Tesla K20 dont nous vous avions déjà parlé. Cette carte embarque un GPU GK110 qui reprend l'architecture Kepler déjà en place sur les GeForce GTX 600 mais légèrement retouchée pour faciliter l'exploitation du GPU en tant qu'accélérateur.

Le GPU GK110 et ses 7.1 milliards de transistors.
Parmi les avancées citons une capacité de traitement en double précision très élevée, un texture cache plus flexible et surtout un processeur de commande plus évolué. Il est capable de gérer jusqu'à 32 files d'attente d'exécution pour mieux exploiter la capacité du GPU à exécuter plusieurs tâches concurrentes, ce que les GPU Nvidia précédents avaient du mal à faire en pratique. Il est également capable d'auto-générer des tâches, ce qui évite des allers-retours incessants avec le CPU qui réduisent l'efficacité réelle de l'accélérateur.
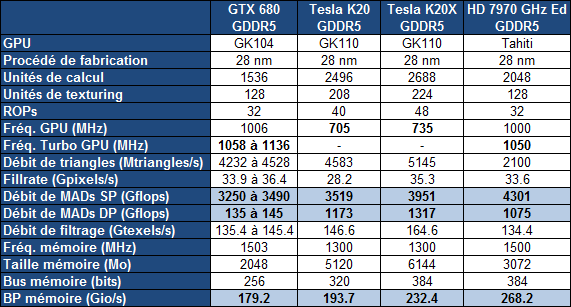
Par rapport à nos précédentes informations, les spécifications de la Tesla K20 sont confirmées, si ce n'est au niveau de la mémoire où elles évoluent très légèrement. Elle est donc bien basée sur un GK110 castré qui se contente de 13 blocs d'unités de calcul, SMX, sur les 15 physiquement présents sur la puce. Il en va de même pour les contrôleurs mémoire dont seulement 5 des 6 sont exploités, ce qui limite la mémoire de la Tesla K20 à 5 Go (4.38 Go avec ECC actif).
Petite surprise, Nvidia lance également une Tesla K20X. Le GK110 qu'elle embarque profite cette fois bien de 14 SMX, pour se rapprocher des 4 Tflops, ainsi que de ses 6 contrôleurs mémoire qui disposent donc de 6 Go de GDDR5 (5.25 Go avec ECC actif). C'est en réalité cette Tesla K20X qui prend place dans le supercalculateur Titan et nous pouvons imaginer que Nvidia a dû sortir 2 variantes de la K20 d'une part pour respecter le cahier de charge au niveau de ce supercalculateur et d'autre part pour disposer d'une production suffisante. Fabriquer un GPU de 7.1 milliards de transistors en 28 nanomètres reste un défi !
Avec plus d'unités de calcul et une fréquence légèrement supérieure, la Tesla K20X ne peut se contenter du TDP de 225W de la Tesla K20. Nvidia a cependant pu le limiter à une valeur proche : 235W. Il nous a par ailleurs été confirmé qu'une technologie de contrôle de la consommation similaire au GPU Boost des GeForce GTX 600 était bien présente sur cette carte et qu'elle pourrait éventuellement être personnalisée par certains fabricants de stations de travail et de serveurs, soit pour adapter la limite de consommation, soit pour activer sa composante turbo.

La Tesla K20 sera disponible en version workstation (refroidissement actif) ainsi qu'en version serveur (refroidissement passif) alors que la Tesla K20X n'existera que dans cette dernière version. Au moins deux formats serveurs sont proposés par Nvidia : carte PCI Express "classique" telle qu'illustrée ici ou SXM, similaire au MXM des cartes graphiques mobiles.

La disponibilité des Tesla K20 et K20X est annoncée pour la fin de ce mois avec un tarif de 3200$ pour la première alors qu'il faudra compter 5000$ pour la seconde. Des tarifs nettement plus élevés que sur la génération précédente qui laissent penser que, pour Nvidia, l'adhésion de l'industrie du calcul haute performance à ces accélérateurs massivement parallèles est désormais inéluctable. Nvidia compte sur un écosystème CUDA relativement répandu et réputé pour faire face à la concurrence des FirePro S d'AMD et des Xeon Phi d'Intel.
CUDA 5.0 final est disponible
Après une release candidate, Nvidia vient de rendre disponible la version finale de CUDA 5.0 . Rappelons que CUDA représente l'écosystème de programmation massivement parallèle qui englobe l'architecture de ses GPU et tout l'environnement logiciel dédié à leur bonne exploitation.
CUDA 5.0 apporte tout d'abord, enfin, un environnement de développement intégré (IDE) dédié à Eclipse, la plateforme ouverte qui, en plus de Windows, supporte également Linux et Mac OS. Nsight Eclipse Edition se limite par contre à CUDA alors que Nsight Visual Studio Edition se charge également de la partie graphique.
Le but premier de CUDA 5.0 est cependant de supporter le GK110 de manière à préparer son arrivée. Ce GPU, et peut-être d'autres dérivés, reprend la base de l'architecture Kepler mais l'améliore sur certains petits détails. Des détails qui pourront faire la différence dans le monde du calcul haute performance.
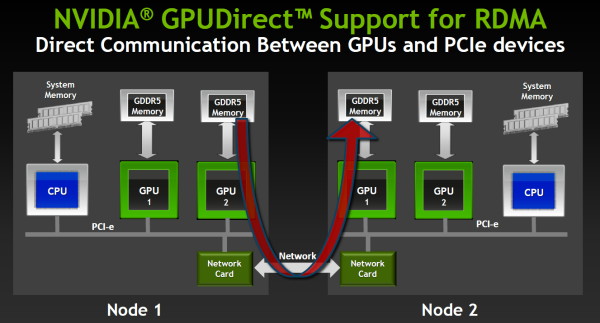
Ainsi la capacité de communication inter-GPU, dénommée GPUDirect chez Nvidia, évolue pour supporter le RDMA. Ce protocole permet à un GPU d'accéder à la mémoire d'un autre GPU même quand celui-ci est situé dans un nud différent, sans devoir organiser ces transferts depuis le CPU, ce qui a un coût beaucoup plus important. Les interfaces réseaux doivent également supporter cette technologie pour qu'elle soit fonctionnelle et Nvidia précise travailler activement avec les principaux fournisseurs à ce niveau.
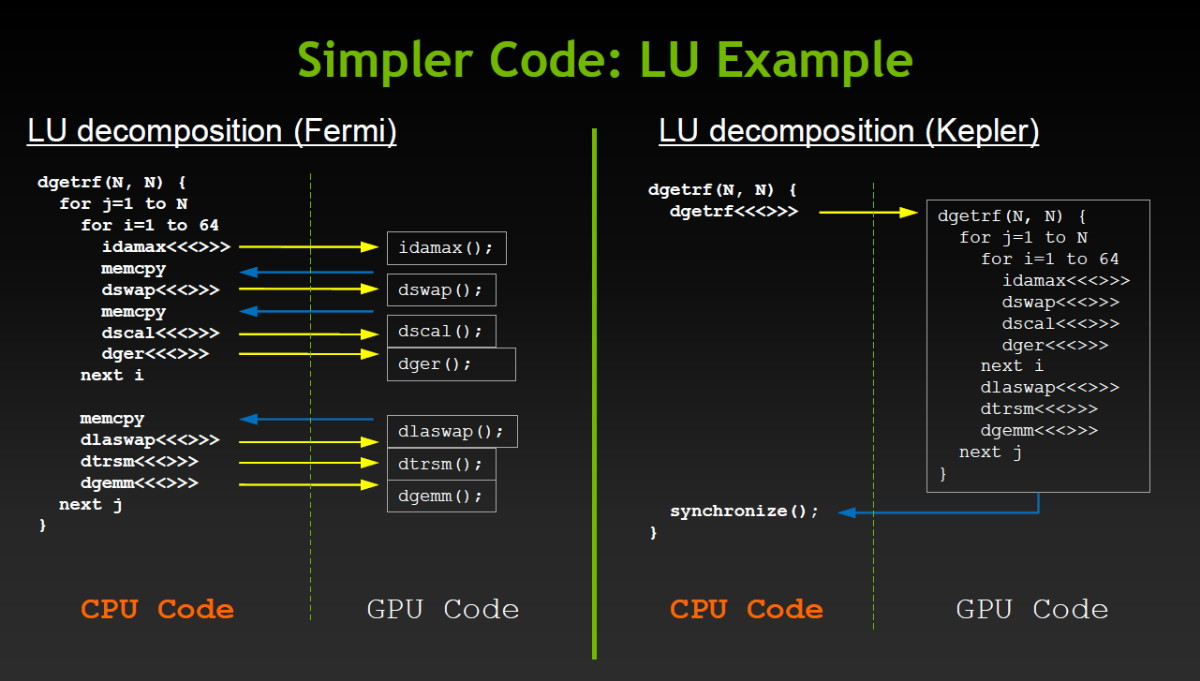
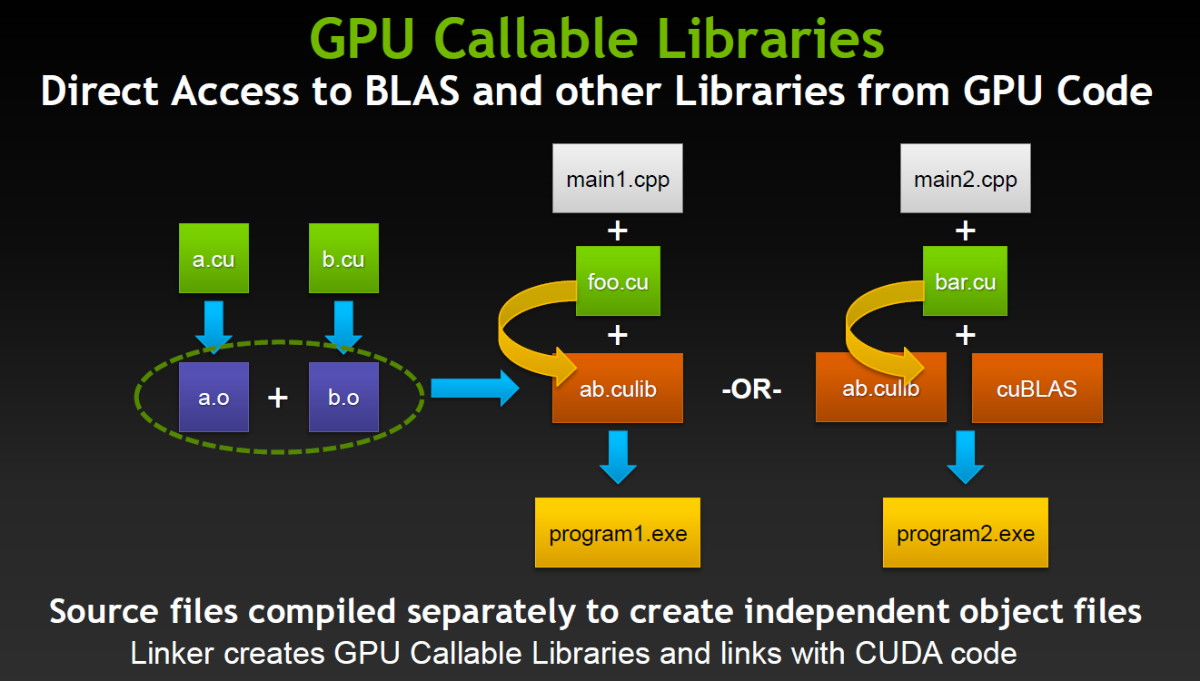
CUDA 5.0 supporte également la capacité du GK110 à lancer de lui-même des fonctions CUDA, une avancée très importante pour faciliter la bonne exploitation du GPU. Dénommée Dynamic Parallelism, cette possibilité permet également au GPU d'appeler directement des librairies, de quoi faciliter leur utilisation, réduire les temps de compilation mais également permettre l'arrivée de librairies propriétaires hyper optimisées.
Nvidia profite de l'arrivée de CUDA 5.0 pour lancer une version en ligne de ses documentations auparavant limitées pour la plupart à des documents PDF. Vous pourrez ainsi retrouver la guide de programmation complet pour CUDA 5.0 par ici dans lequel sont exposées les petites différences apportées par le GK110 (CUDA device 3.5).
Nvidia, PGI et Cray dévoilent OpenACC
Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
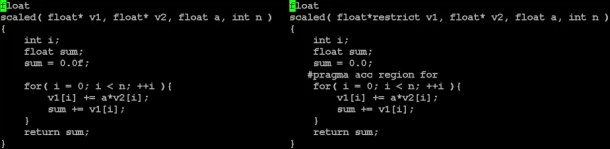
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .
AFDS: OpenCL gagne du terrain ?
Selon les résultats d'une étude que nous a présentés AMD, OpenCL est en train de gagner du terrain, notamment par rapport à C pour CUDA, l'API similaire mais propriétaire proposée par Nvidia depuis 2007. Plus récent, mais ouvert, OpenCL est prévu pour supporter tout type de processeurs, qu'ils soient CPU ou GPU, ce qui permet aux développeurs de s'assurer un support, même si peu performant, sur un maximum de systèmes.

Le sondage présenté à plus de 500 développeurs d'une part en Amérique du Nord et d'autre part en EMEA a fait ressortir une préférence pour OpenCL par rapport à CUDA. OpenMP d'une part et les outils Intel d'autre part conservent cependant la première place. Reste bien entendu à voir quand cette progression chez les développeurs portera ses fruits en pratique pour les utilisateurs