
Les derniers contenus liés aux tags CUDA et GK110
Nvidia annonce la Tesla K40 et CUDA 6
GTC: CUDA on ARM: Tegra 3 + Tesla K20
GK110 : Nvidia lance les Tesla K20 et K20X
CUDA 5.0 final est disponible
Nvidia annonce la Tesla K40 et CUDA 6



La semaine passée, à l'occasion du SC13 (Supercomputing 2013), Nvidia a annoncé deux nouveautés liées au calcul haute performance : l'accélérateur Tesla K40 et la version 6 de CUDA.
Pour rappel, c'est la gamme Tesla qui a été la première à profiter du plus gros GPU de la famille Kepler, le GK110. Contrairement aux Quadro K6000 et GeForce GTX 780 Ti plus récentes, cette gamme Tesla n'accueillait cependant toujours pas de version complète du GK110, c'est-à-dire avec l'ensemble de ses unités d'exécution actives. Une configuration facilitée par l'arrivée de la révision B1 du GPU.
La Tesla K40 profite ainsi de 15 SMX, de 2880 unités de calcul FMA 32-bit et de 960 unités FMA 64-bit pour afficher une puissance de calcul en hausse de près de 10% par rapport à la Tesla K20X. Par ailleurs, comme pour le Quadro K6000, Nvidia profite de la disponibilité effective de la GDDR5 4 Gbits pour faire passer la mémoire dédiée de son accélérateur de 6 à 12 Go. Sa fréquence est par ailleurs revue à la hausse ce qui profite à la bande passante mémoire en hausse de 15%.

Si la fréquence GPU ne progresse que très peu pour la Tesla K40, c'est uniquement pour garantir que l'enveloppe thermique ne soit pas atteinte dans les tâches de type calcul, sachant que, contrairement aux GeForce, Nvidia ne propose pas de turbo pour ces cartes afin d'éviter que leurs performances soient variables. Par contre, pour la Tesla K40, Nvidia propose 2 modes avec des fréquences GPU différentes : optionnellement, il sera ainsi possible de passer le GPU de 745 à 810 ou 875 MHz. Il ne s'agit pas d'un overclocking dans le sens où ces fréquences sont validées par Nvidia, ni d'un turbo automatique, même si Nvidia place cette possibilité sous l'appellation GPU Boost, marque du turbo des GeForce... Si la personne qui exploite ces Tesla K40 constate qu'elles restent loin de leur TDP dans une certaine situation, elle aura la possibilité de passer à un de ces modes de fréquence supérieure. De quoi profiter 9% voire 17% de puissance supplémentaire.
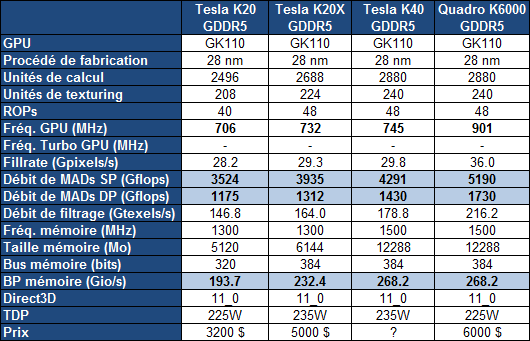
A noter que la Tesla K40 sera proposée autant avec un refroidissement actif, comme la K20, qu'avec un refroidissement passif en vue d'intégration dans un serveur, comme la K20X. Enfin, le PCI Express 3.0 est activé sur la K40 contrairement aux K20/X.
Nvidia ne communique pas au niveau de la tarification, mais elle devrait rester inférieure à celle de la Quadro K6000, probablement passer à 5000$ alors que les K20/X devraient voir leur tarif baisser. Il faut cependant garder en tête que sur ce marché de niche, les prix sont fortement variables, les grossistes n'hésitant pas à se réserver des marges conséquentes. Ainsi pour des tarifs annoncés par Nvidia de 3200$ et de 5000$ pour les K20 et K20X, en pratique, il fallait en général compter plutôt 4000$ et 7500$, la même chose en euros.
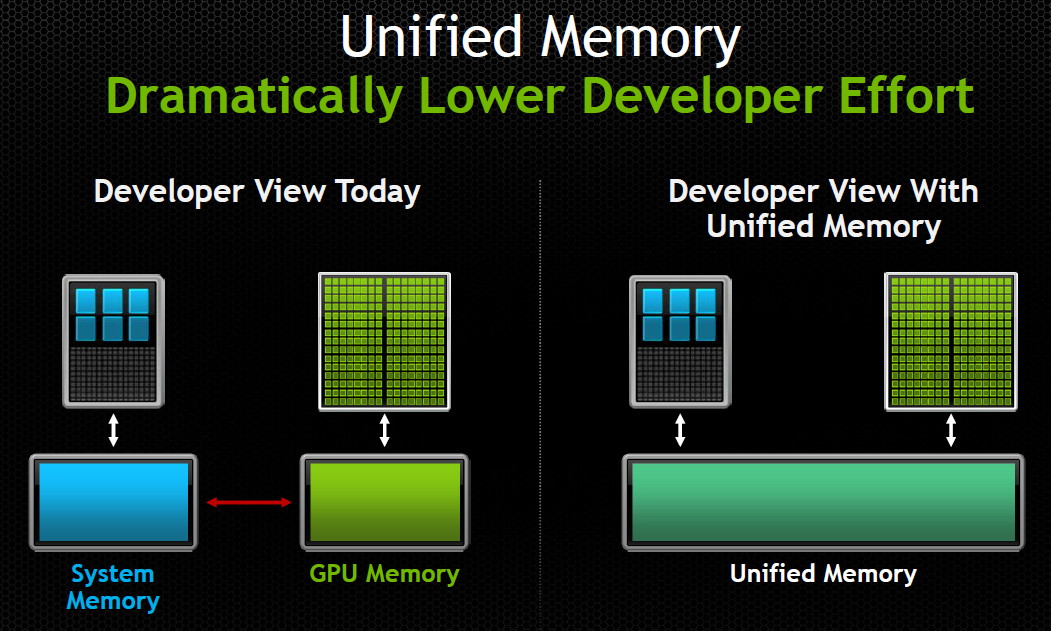
Parallèlement à l'arrivée de cette nouvelle Tesla, Nvidia a annoncé CUDA 6 qui apporte une nouveauté majeure et très attendue : la prise en charge d'une mémoire unifiée. Une fonctionnalité qui donne l'impression d'être annoncée et réannoncée régulièrement, AMD et Nvidia ayant régulièrement joué sur les mots à ce niveau. Pour rappel, depuis quelques temps, CUDA supporte un adressage de mémoire virtuelle unifié, qui facilite quelque peu le développement mais n'était qu'un premier pas. La mémoire unifiée, représente cette fois une abstraction totale de la gestion de la mémoire : il n'est plus nécessaire que le développeur gère les transferts de données de la mémoire centrale vers la mémoire de l'accélérateur.
Une gestion manuelle de la mémoire restera possible, étant donné qu'aussi bénéfique soit cette simplification, elle peut avoir un coût sur le plan des performances et de l'efficacité puisqu'il reviendra aux pilotes et/ou aux compilateurs d'essayer de placer automatiquement les données au bon endroit.

Confiant dans l'avenir, Nvidia termine par annoncer que l'ouverture par IBM, cet été, de sa plateforme serveur POWERn, va permettre d'y intégrer des accélérateurs Tesla dès 2014. Des accélérateurs qui seront ainsi exploités non plus uniquement sur x86 mais également sur architectures POWER et ARMv8.
GTC: CUDA on ARM: Tegra 3 + Tesla K20
En plus des plateformes CUDA on ARM destinées à simuler de futurs SoC que ce soit pour une utilisation de type périphérique mobile grand public ou de type micro-serveur, des développements se font également autour d'accélérateurs très puissants tels que les Tesla K20.
C'est le cas chez l'européen PRACE qui développe des systèmes dédiés au supercomputing et s'intéresse à CUDA on ARM depuis quelques temps. En collaboration avec le Barcelona Supercomputing Center, PRACE est en train de mettre au point une plateforme ARM équipée en GK110 : Pedraforca v2. Celle-ci est composée d'une carte mini-ITX sur laquelle prend place un module Q7 Tegra 3 dont 4 des lignes PCI Express 2.0 sont connectées à un switch PLX PCI Express 3.0 sur lequel vont venir se greffer un accélérateur Tesla K20 et une carte contrôleur InfiniBand 40 Gbps.

Cette plateforme a la particularité de ne pas rechercher la complémentarité entre les cores CPU et GPU. Grossièrement, le but est d'utiliser le SoC ARM uniquement pour activer un système CUDA plus ou moins indépendant. C'est la raison pour laquelle le Tesla K20 est associé à un contrôleur InfiniBand sur un même switch PCI Express 3.0 : ils peuvent ainsi communiquer très rapidement avec les accélérateurs d'autres nuds en ignorant autant que possible la communication avec les SoC et leurs mémoires.
Les développeurs de Pedraforca v2 sont bien conscients qu'une telle approche n'est pas une solution de remplacement générale à un système CUDA classique et se contentera de répondre avantageusement à un sous-ensemble de problématiques : si un problème massivement parallèle peut être résolu sans CPU, autant réduire l'encombrement et la consommation de celui-ci.
Une telle solution permet par ailleurs de simuler le comportement de futurs GPU haut de gamme qui pourraient intégrer un ou plusieurs cores ARMv8 Denver pour gagner en indépendance. De quoi commencer à préparer des algorithmes qui leur seront adaptés ?
GK110 : Nvidia lance les Tesla K20 et K20X
A l'occasion de la conférence SC12, dédiée aux supercalculateurs et technologies liées, Nvidia annonce la disponibilité commerciale de l'accélérateur Tesla K20 dont nous vous avions déjà parlé. Cette carte embarque un GPU GK110 qui reprend l'architecture Kepler déjà en place sur les GeForce GTX 600 mais légèrement retouchée pour faciliter l'exploitation du GPU en tant qu'accélérateur.

Le GPU GK110 et ses 7.1 milliards de transistors.
Parmi les avancées citons une capacité de traitement en double précision très élevée, un texture cache plus flexible et surtout un processeur de commande plus évolué. Il est capable de gérer jusqu'à 32 files d'attente d'exécution pour mieux exploiter la capacité du GPU à exécuter plusieurs tâches concurrentes, ce que les GPU Nvidia précédents avaient du mal à faire en pratique. Il est également capable d'auto-générer des tâches, ce qui évite des allers-retours incessants avec le CPU qui réduisent l'efficacité réelle de l'accélérateur.
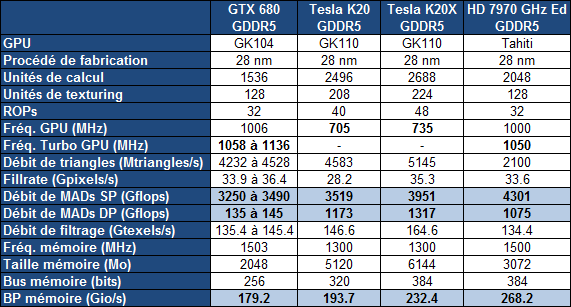
Par rapport à nos précédentes informations, les spécifications de la Tesla K20 sont confirmées, si ce n'est au niveau de la mémoire où elles évoluent très légèrement. Elle est donc bien basée sur un GK110 castré qui se contente de 13 blocs d'unités de calcul, SMX, sur les 15 physiquement présents sur la puce. Il en va de même pour les contrôleurs mémoire dont seulement 5 des 6 sont exploités, ce qui limite la mémoire de la Tesla K20 à 5 Go (4.38 Go avec ECC actif).
Petite surprise, Nvidia lance également une Tesla K20X. Le GK110 qu'elle embarque profite cette fois bien de 14 SMX, pour se rapprocher des 4 Tflops, ainsi que de ses 6 contrôleurs mémoire qui disposent donc de 6 Go de GDDR5 (5.25 Go avec ECC actif). C'est en réalité cette Tesla K20X qui prend place dans le supercalculateur Titan et nous pouvons imaginer que Nvidia a dû sortir 2 variantes de la K20 d'une part pour respecter le cahier de charge au niveau de ce supercalculateur et d'autre part pour disposer d'une production suffisante. Fabriquer un GPU de 7.1 milliards de transistors en 28 nanomètres reste un défi !
Avec plus d'unités de calcul et une fréquence légèrement supérieure, la Tesla K20X ne peut se contenter du TDP de 225W de la Tesla K20. Nvidia a cependant pu le limiter à une valeur proche : 235W. Il nous a par ailleurs été confirmé qu'une technologie de contrôle de la consommation similaire au GPU Boost des GeForce GTX 600 était bien présente sur cette carte et qu'elle pourrait éventuellement être personnalisée par certains fabricants de stations de travail et de serveurs, soit pour adapter la limite de consommation, soit pour activer sa composante turbo.

La Tesla K20 sera disponible en version workstation (refroidissement actif) ainsi qu'en version serveur (refroidissement passif) alors que la Tesla K20X n'existera que dans cette dernière version. Au moins deux formats serveurs sont proposés par Nvidia : carte PCI Express "classique" telle qu'illustrée ici ou SXM, similaire au MXM des cartes graphiques mobiles.

La disponibilité des Tesla K20 et K20X est annoncée pour la fin de ce mois avec un tarif de 3200$ pour la première alors qu'il faudra compter 5000$ pour la seconde. Des tarifs nettement plus élevés que sur la génération précédente qui laissent penser que, pour Nvidia, l'adhésion de l'industrie du calcul haute performance à ces accélérateurs massivement parallèles est désormais inéluctable. Nvidia compte sur un écosystème CUDA relativement répandu et réputé pour faire face à la concurrence des FirePro S d'AMD et des Xeon Phi d'Intel.
CUDA 5.0 final est disponible
Après une release candidate, Nvidia vient de rendre disponible la version finale de CUDA 5.0 . Rappelons que CUDA représente l'écosystème de programmation massivement parallèle qui englobe l'architecture de ses GPU et tout l'environnement logiciel dédié à leur bonne exploitation.
CUDA 5.0 apporte tout d'abord, enfin, un environnement de développement intégré (IDE) dédié à Eclipse, la plateforme ouverte qui, en plus de Windows, supporte également Linux et Mac OS. Nsight Eclipse Edition se limite par contre à CUDA alors que Nsight Visual Studio Edition se charge également de la partie graphique.
Le but premier de CUDA 5.0 est cependant de supporter le GK110 de manière à préparer son arrivée. Ce GPU, et peut-être d'autres dérivés, reprend la base de l'architecture Kepler mais l'améliore sur certains petits détails. Des détails qui pourront faire la différence dans le monde du calcul haute performance.
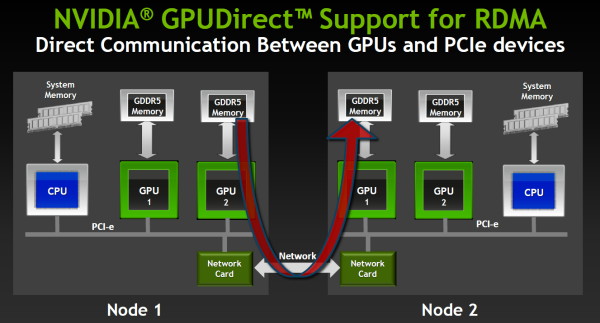
Ainsi la capacité de communication inter-GPU, dénommée GPUDirect chez Nvidia, évolue pour supporter le RDMA. Ce protocole permet à un GPU d'accéder à la mémoire d'un autre GPU même quand celui-ci est situé dans un nud différent, sans devoir organiser ces transferts depuis le CPU, ce qui a un coût beaucoup plus important. Les interfaces réseaux doivent également supporter cette technologie pour qu'elle soit fonctionnelle et Nvidia précise travailler activement avec les principaux fournisseurs à ce niveau.
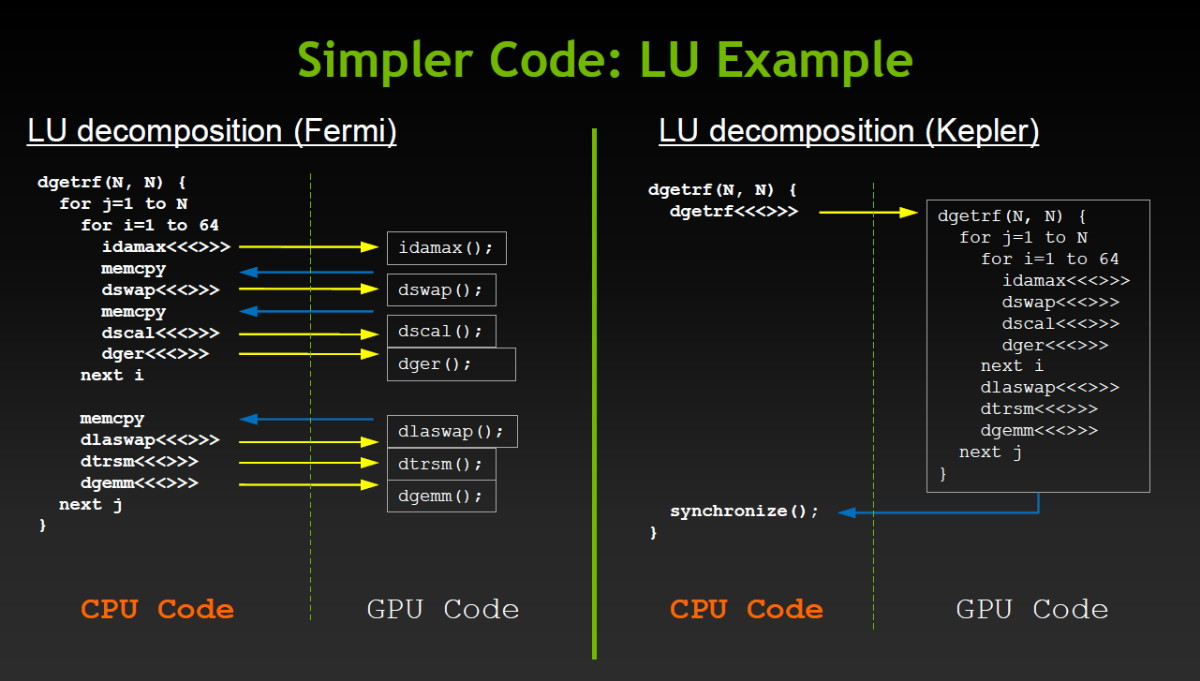
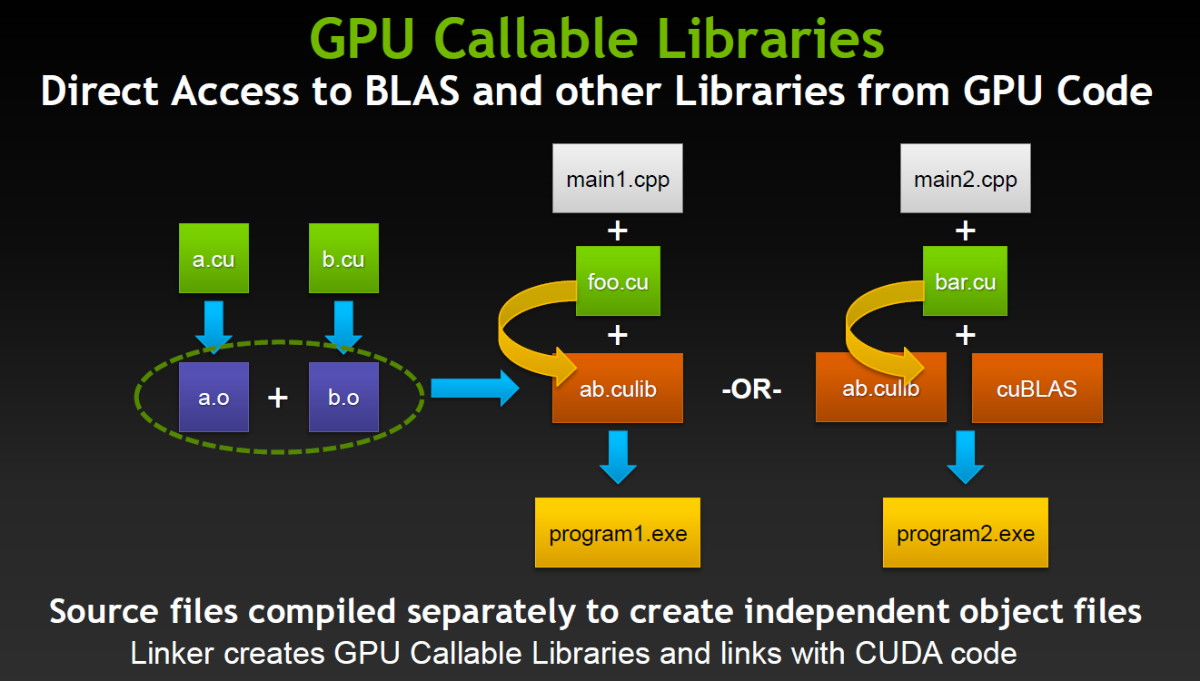
CUDA 5.0 supporte également la capacité du GK110 à lancer de lui-même des fonctions CUDA, une avancée très importante pour faciliter la bonne exploitation du GPU. Dénommée Dynamic Parallelism, cette possibilité permet également au GPU d'appeler directement des librairies, de quoi faciliter leur utilisation, réduire les temps de compilation mais également permettre l'arrivée de librairies propriétaires hyper optimisées.
Nvidia profite de l'arrivée de CUDA 5.0 pour lancer une version en ligne de ses documentations auparavant limitées pour la plupart à des documents PDF. Vous pourrez ainsi retrouver la guide de programmation complet pour CUDA 5.0 par ici dans lequel sont exposées les petites différences apportées par le GK110 (CUDA device 3.5).