
Les derniers contenus liés au tag Carrizo-L
2 puces pour les APU de 7è génération
Les SoC Carrizo-L débarquent sur FP4 BGA
Zen, Socket AM4 et HBM : AMD parle d'avenir
AMD lève le voile sur Carrizo côté technique
AMD Carrizo et Carrizo-L pour mi-2015
2 puces pour les APU de 7è génération



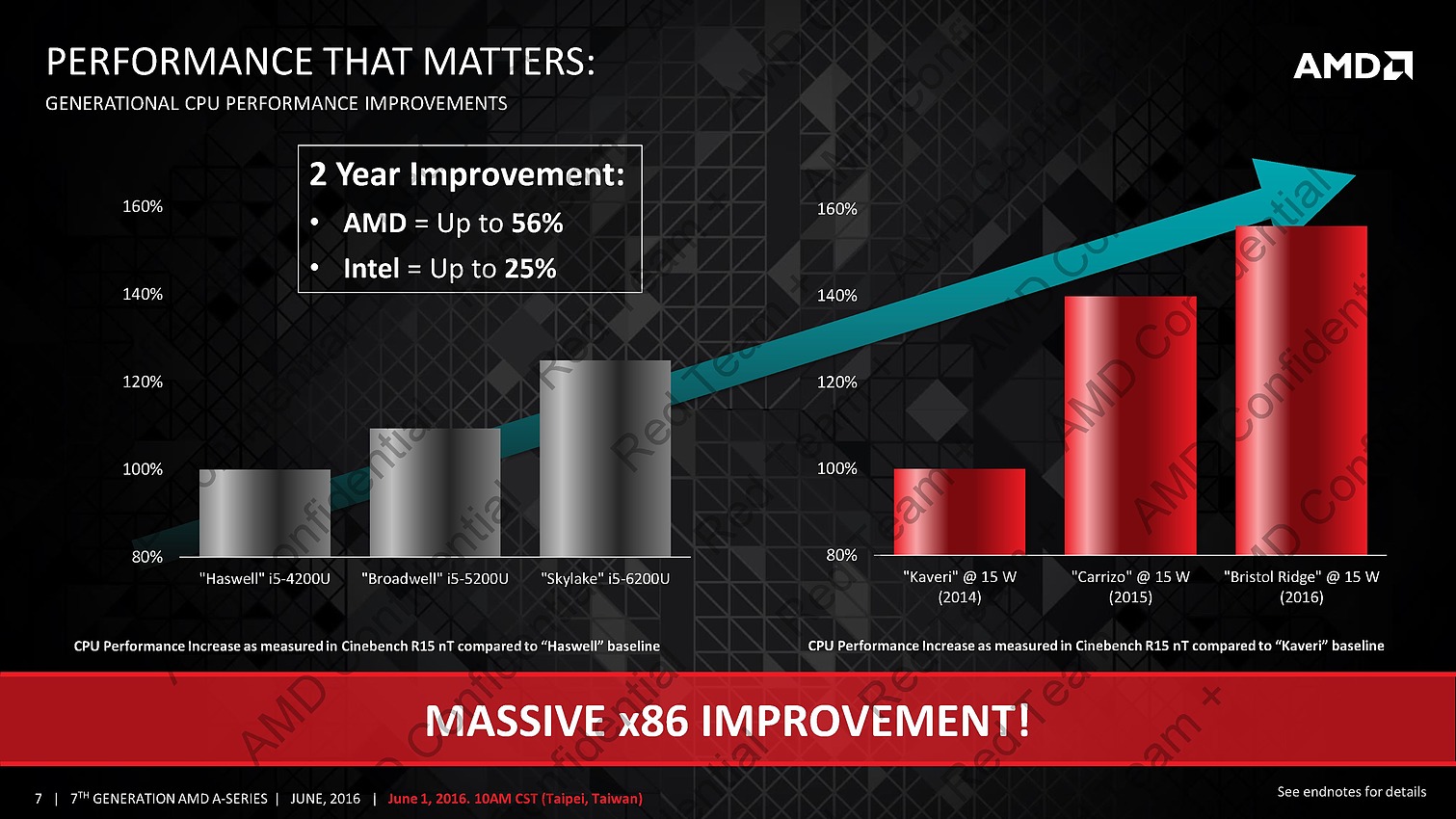
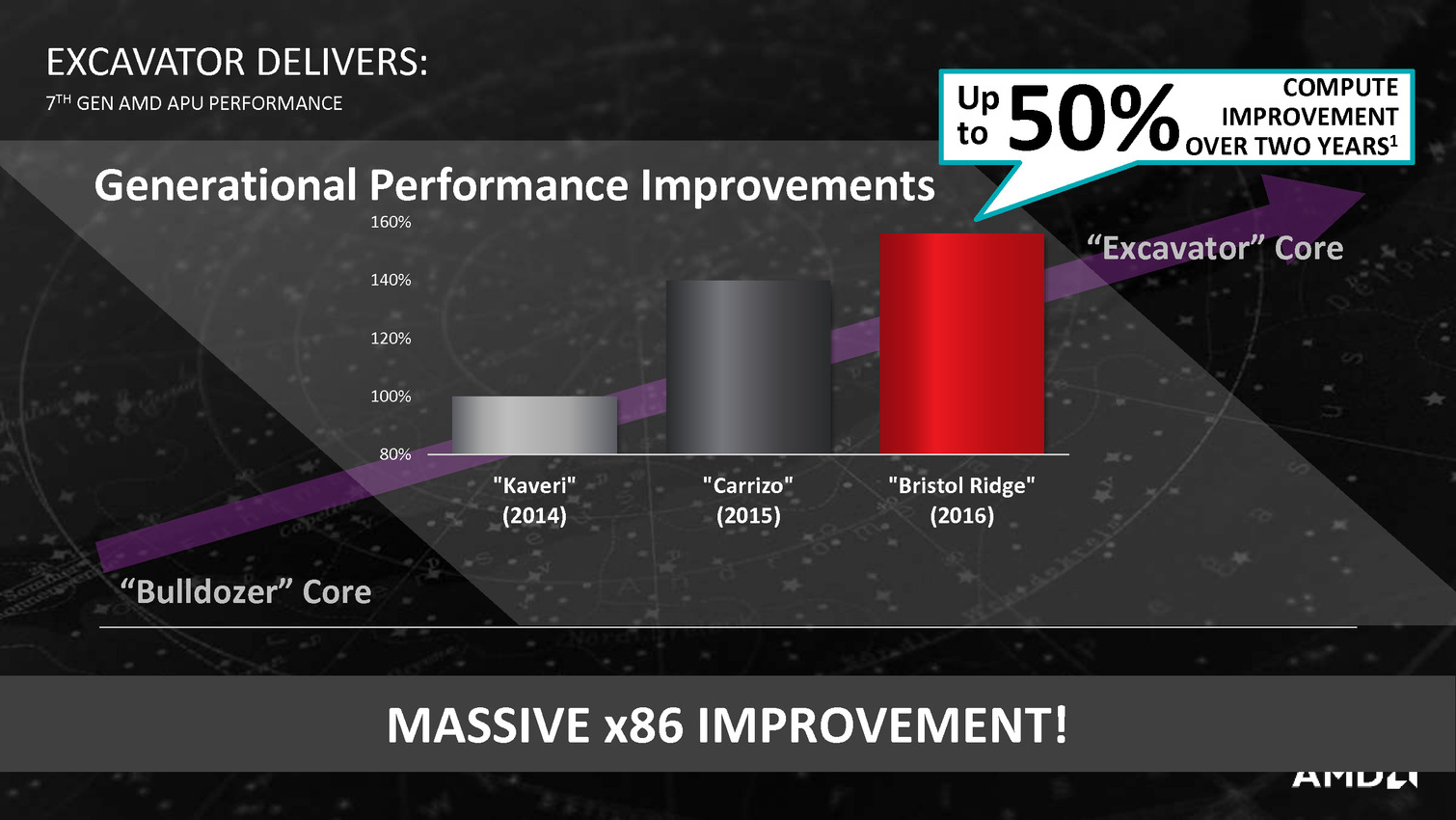
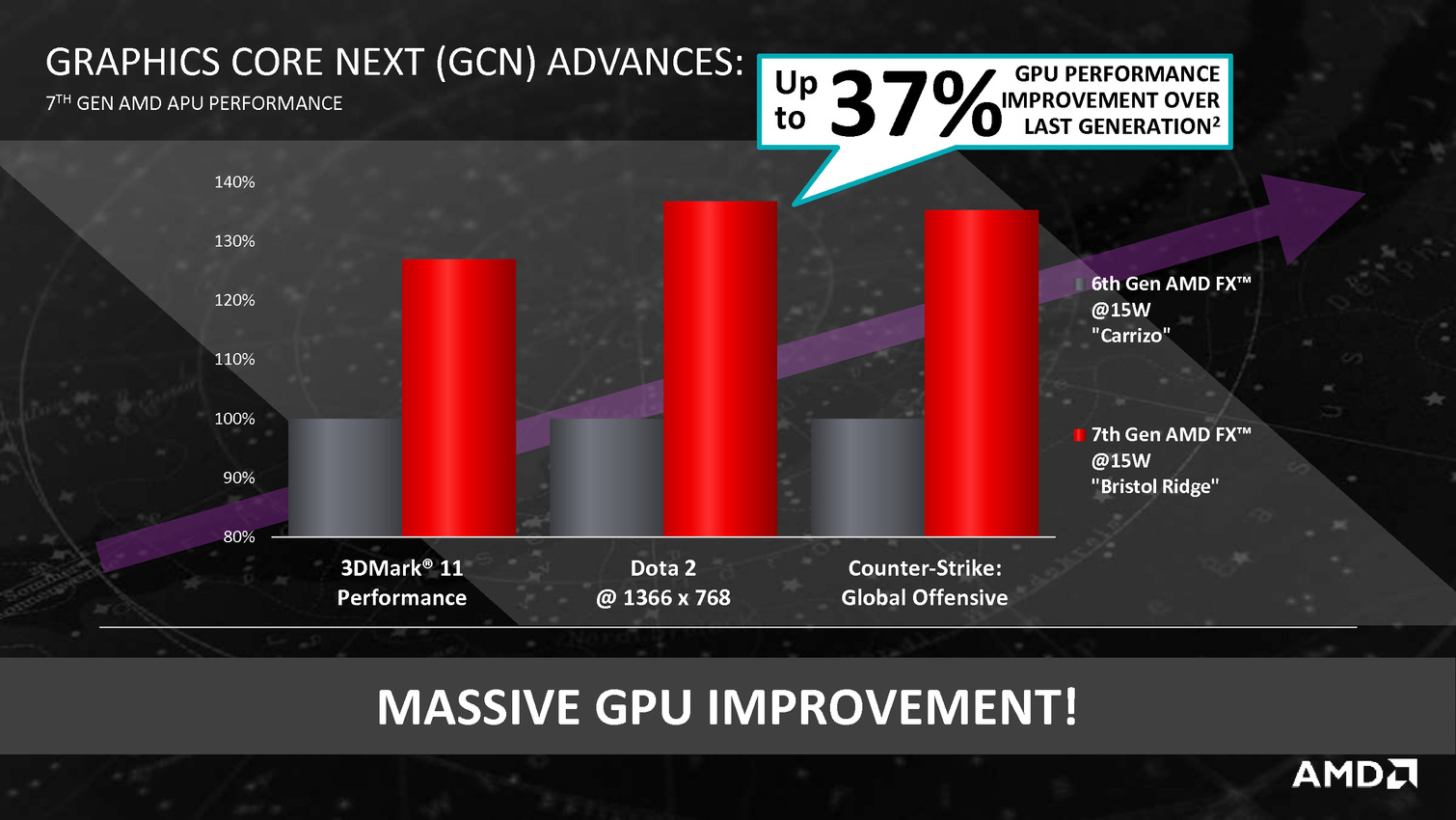
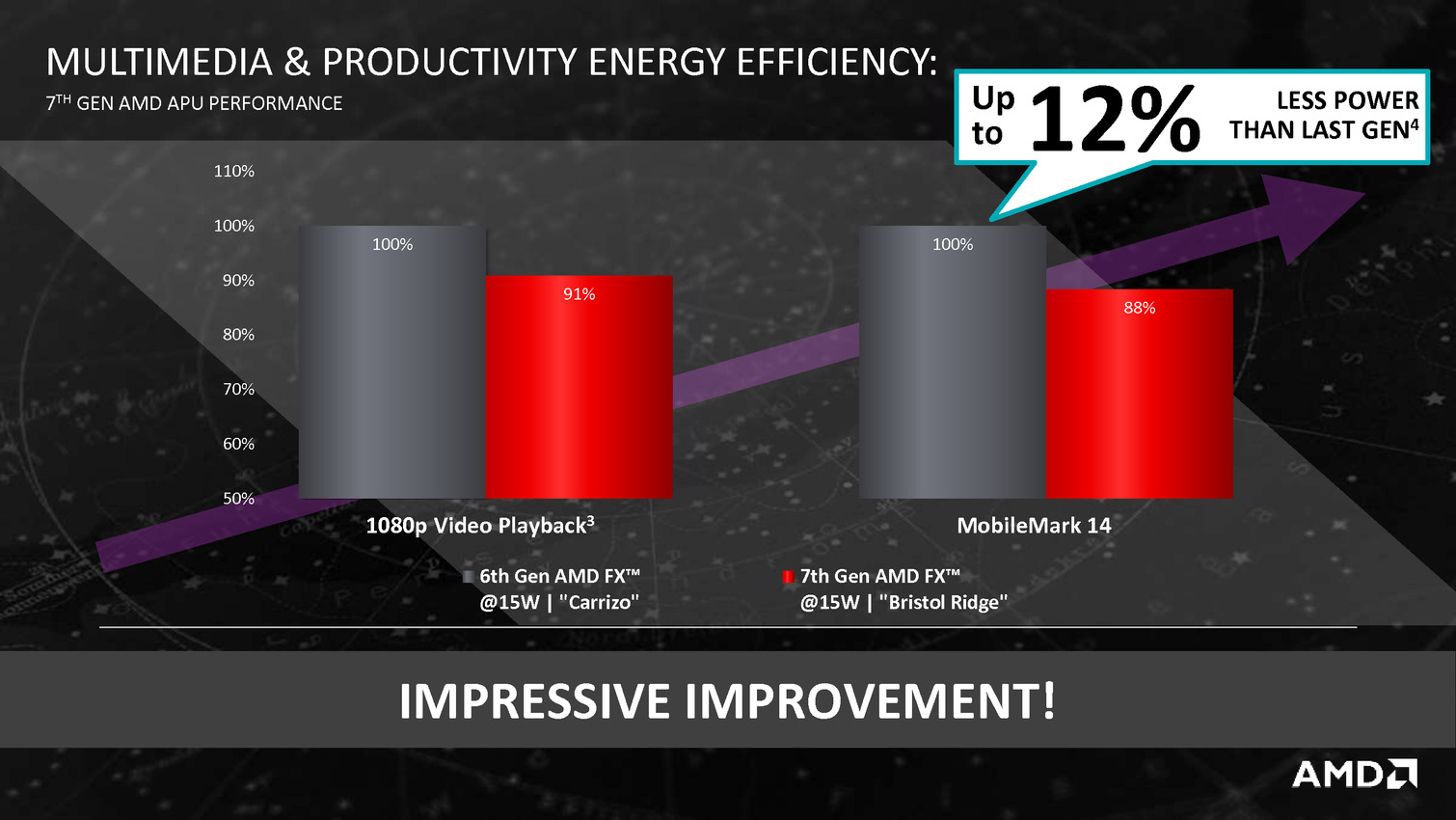
AMD profite du Computex pour annoncer ce qu'il appelle sa 7è génération d'APU, composée de deux puces : Bristol Ridge et Stoney Ridge.
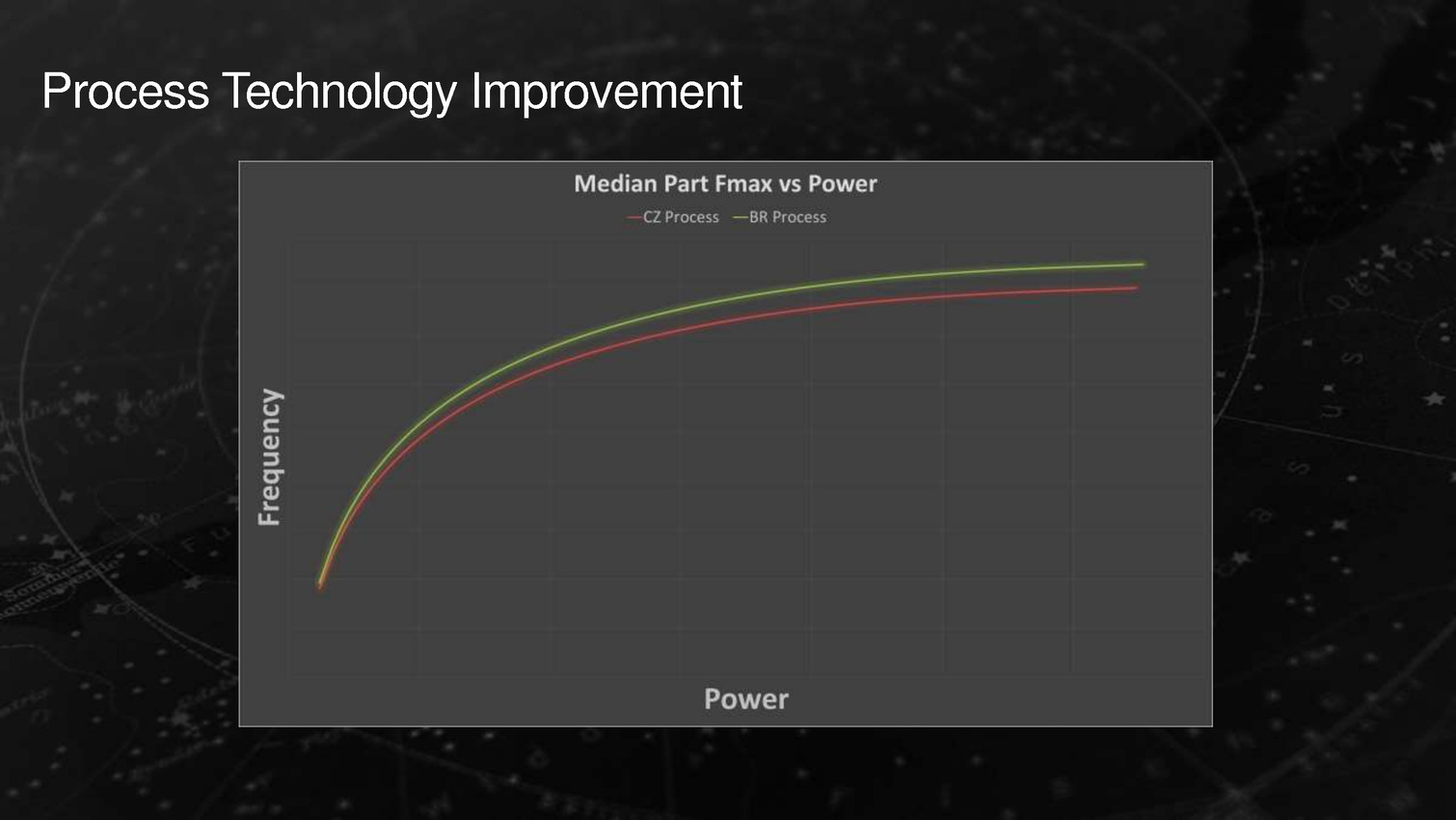
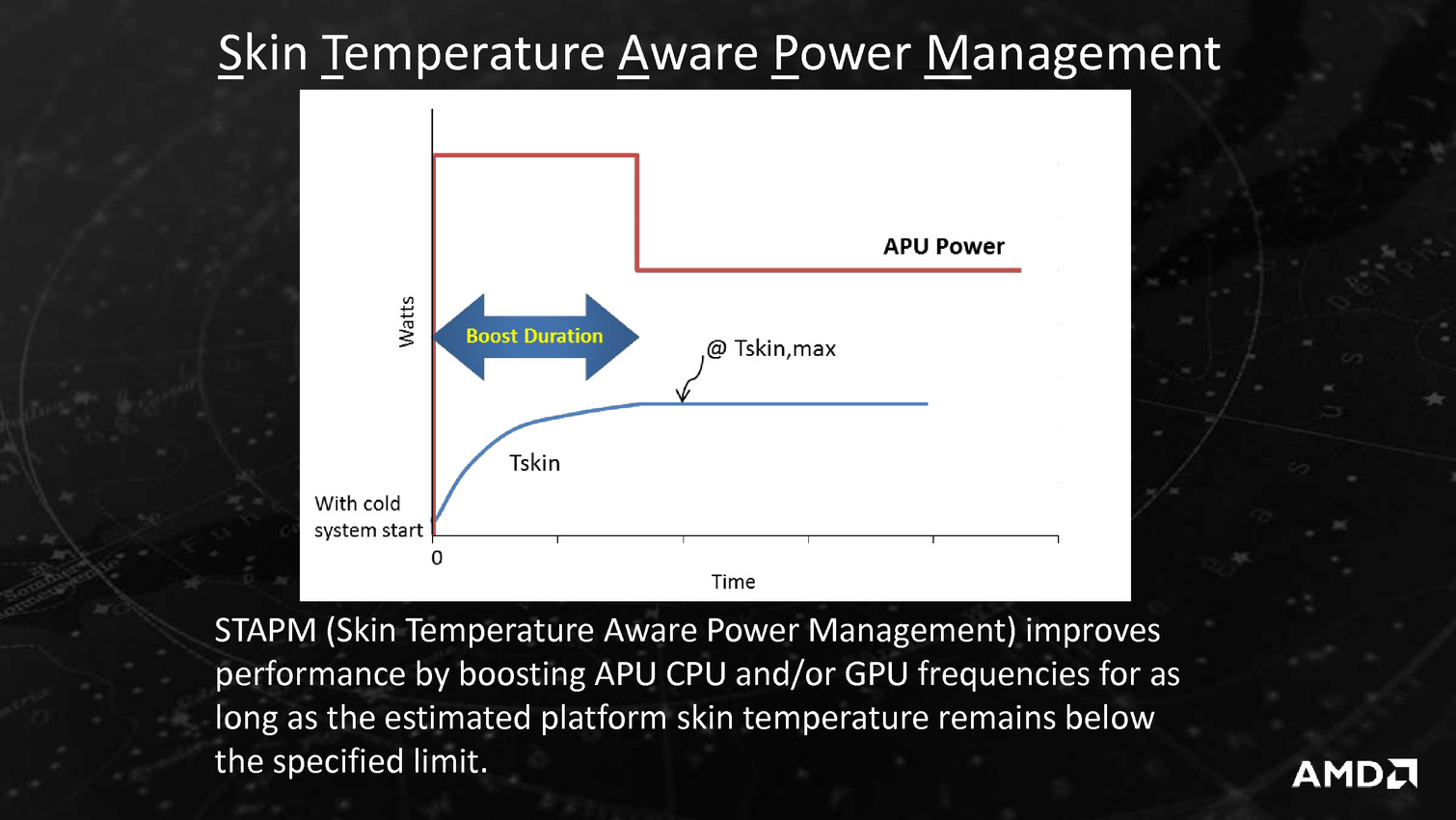
Derrière ces puces se cache en fait la combinaison Excavator et GCN 1.2 déjà utilisée sur Carrizo, avec de menues améliorations destinées à tirer encore plus de ces puces malgré une gravure toujours en 28nm. La moitié des gains viendraient ainsi de modification de l'architecture des transistors chez GlobalFoundries, l'autre de modification permettant de mieux coller aux capacités individuelles de chaque puce ainsi que de la gestion, comme chez Intel depuis les Core M, de la température du système en sus de la température processeur afin d'allonger si possible la durée pendant laquelle l'APU peut aller au-delà de sa consommation de base.


















Bristol Ridge est très (très) proche de Carrizo, d'ailleurs le nombre de transistor est identique à 3,1 milliards alors que la surface varie légèrement (250.4mm² au lieu de 244.6mm²). On trouve 2 modules x86 Excavator associés à 8 Compute Units GCN 1.2 et un soutbhridge gérant 4 USB 3.0, 4 USB 2.0 et 2 SATA 6 Gbs. La mémoire est gérée sur deux canaux et peut être de type DDR3-2133 ou DDR4-2400, alors que le nombre de ports PCIe Gen3 est de 12 (dont 8 pour un GPU externe). Il est décliné en gammes FX, A12 et A10, avec des variations au niveau des fréquences et du TDP mais aussi du nombre de CUs actives (6 à 8). Les puces les plus haut de gamme sont le FX 9830P qui avec un TDP de 35w fonctionne à 3/3.7 GHz côté CPU et 900 MHz au mieux côté GPU (en Carrizo on était au mieux à 3.4 GHz et 900 MHz), et d'autre part le FX 9800P qui est à 2.7/3.6 GHz et 758 MHz.
Stoney Ridge est pour sa part composé de 1.2 milliards de transistor sur 124.5mm², cette puce remplace Carrizo-L et permet à AMD d'unifier les architectures de sa gamme APU, chose qu'on ne pensait pas voir venir avant Zen. Cette fois on a droit à un module x86 Excavator et 3 Compute Units GCN 1.2 alors que la mémoire est gérée sur un canal permettant au mieux d'atteindre la DDR4-2133. On troque donc entre autre 4 petits coeurs x86 pour 2 plus performants, et le nombre d'unités GCN augmente de 50% alors qu'on dispose d'un moteur vidéo plus à jour capable de décoder le H.265 et de disposer d'une sortie HDMI 2.0. Cette puce est déclinée en tant que A9, A6 et E2, avec toujours un TDP de 15 watts mais des fréquences CPU et GPU qui varient ainsi qu'un nombre de CUs limité à 2 en E2.
Le premier produit utilisant ces APU sera l'HP ENVY x360 déjà annoncé il y a quelques semaines, il utilisera selon les versions l'une ou l'autre des puces.










Les SoC Carrizo-L débarquent sur FP4 BGA
AMD a officiellement lancé ses Carrizo-L, qui sont déjà disponibles en Chine et devraient l'être mondialement dans les semaines à venir. Pour faire court, ces SoC sont une nouvelle version des Beema utilisant un format FP4 BGA au lieu de FT3 BGA. L'avantage du FP4 BGA est qu'il sera commun avec les Carrizo qui seront lancés en juin, ce qui permettra aux OEM d'avoir des châssis accueillant toute la gamme AMD.
On retrouve donc au sein de ce SoC 2 à 4 curs x86 basse conso de type Puma+ associés à 2 Compute Units GCN ainsi qu'un ARM Cortex-A5 incluant un coprocesseur cryptographique pour l'implémentation de TPM 2.0. A titre de comparaison Carrizo devrait pour sa part intégrer 4 curs x86 Excavator offrant un IPC environ deux fois plus élevé et jusqu'à 8 Compute Units GCN, mais il sera plus cher et dans ses versions les plus avancées atteindra 35W là ou Carrizo-L se limite à 25W.
5 versions sont lancées (A8-7410, A6-7310, A4-7210, E2-7110 et E1-7010) mais AMD est plutôt avare côté spécifications :
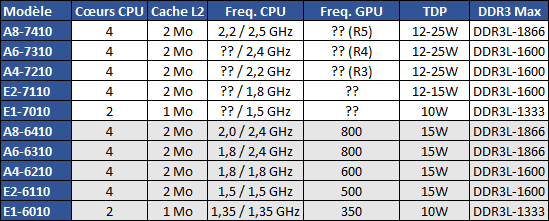
On passe de la série 6000 pour les Beema, en gris, à la série 7000 pour les Carrizo-L, comme Kaveri ce qui ne va pas simplifier la lecture de la gamme...un A8-7100 Kaveri étant 2 fois plus véloce qu'un A8-7410 Carrizo-L !
On note une légèrement augmentation des fréquences processeurs alors que la fréquence GPU n'est pas précisée. AMD jouera probablement fortement dessus comme c'est le cas sur Beema, d'où les différentes dénominations (Radeon tout court, Radeon R3, R4 et R5). Côté TDP celui-ci semble configurable et peut atteindre 25W, ce qui est peut-être une contrepartie aux fréquences maximales en hausse par rapport à Beema qui se limitait à 15W.
Zen, Socket AM4 et HBM : AMD parle d'avenir
A l'occasion de sa conférence dédiée aux analystes financiers, AMD a dévoilé un certain nombre d'informations sur ses produits à venir pour cette année mais également pour 2016. Si l'on pourra toujours regretter le manque de détails sur certains sujets, on aura trouvé la confirmation d'un grand nombre d'informations, ainsi que plusieurs nouvelles.
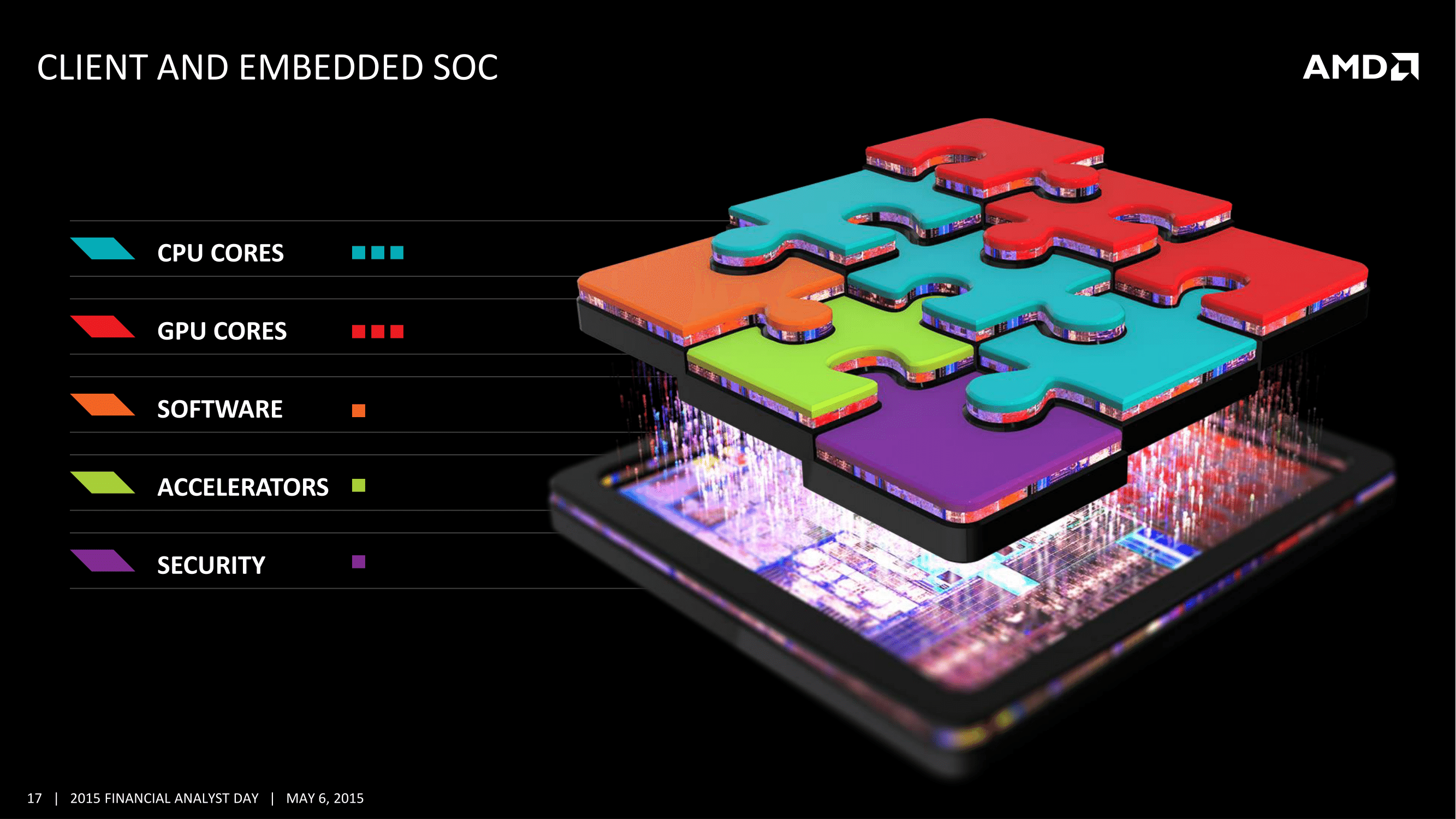
Carrizo : APU Mobile 6ème générationPour ce qui est de l'avenir proche, AMD a tout d'abord confirmé l'arrivée de sa nouvelle génération d'APU baptisée Carrizo pour les plateformes portables, qui sera connue sous l'appellation marketing d'APU « 6th generation ». Un comptage assez « libre » puisque les Kaveri qu'elle remplace représentaient la troisième génération d'APU (après Llano et Trinity, quatrième en comptant Richland qui n'était pas une vraie génération). Toute ressemblance avec la ligne marketing actuelle d'un autre constructeur qui lancerait cette année lui aussi « sa » sixième génération est évidemment fortuite !
Si techniquement Carrizo remplacera les Kaveri en version mobile, il peut être vu comme le fils spirituel de Kaveri et de Kabini. Côté processeur on retrouve en effet la dernière évolution du concept des modules Bulldozer d'AMD, avec Excavator, mais à la différence de Kaveri il s'agit, tout comme Kabini, d'un SoC qui inclut son chipset gérant USB 2.0, USB 3.0 et SATA 6Gbps. Le fait qu'il s'agisse d'un SoC nous vaut probablement le non-lancement de cette puce en version desktop, AMD n'ayant pas développé de SKU dépourvu de la partie chipset pour le rendre compatible avec sa plateforme FM2+. Cette dernière se contentera des Godavari à l'été.
Côté nouveautés, le GPU est annoncé comme 40% plus rapide que celui d'un « Core i5 » ce qui ne veut pas dire grand-chose. On notera des évolutions côté décodage puisque AMD indique avoir doublé a taille de batterie égale le temps de lecture de vidéos 1080p stockées localement. On notera enfin l'arrivée du décodage HEVC (H.265, le prochain standard de compression vidéo), comme évoqué en février.
Le lancement des Carrizo s'effectuera « ce trimestre » même si en général les plateformes mobiles sont annoncées plusieurs semaines en amont de leur disponibilité effective dans le commerce.
Radeon Mobile M300 et GPU HBM
En parallèle de Carrizo, AMD annonce dès aujourd'hui l'arrivée de sa gamme de GPU M300 dédiées aux plateformes portables. On regrettera que le constructeur soit passé trop rapidement sur le sujet puisqu'il n'a donné aucune information concrète sur les modèles lancés, des informations qui devraient suivre sous peu.
Le constructeur a par contre confirmé, côté desktop, l'arrivée ce trimestre de nouveaux GPU desktop. Le nom de ces puces n'est pas indiqué même si l'on devine qu'il s'agit des R300, et plus particulièrement de Fiji.
Ce qu'AMD a confirmé, par contre, c'est la présence de mémoire HBM pour remplacer la mémoire GDDR5 ! L'information avait déjà filtrée la semaine dernière et comme noté à l'époque, AMD utilisera un silicon interposer pour interfacer la mémoire et le GPU. AMD n'a pas encore dévoilé la fréquence de la HBM utilisée mais a indiqué obtenir un rapport performances/watts multiplié par trois par rapport à la GDDR5, et 50% d'économie d'énergie par rapport à la GDDR5. Des chiffres qui devraient se révéler sous peu !
AMD a insisté fortement sur l'autre intérêt de la HBM, outre ses performances et sa consommation, la possibilité de créer des cartes plus compactes. On s'attend donc à voir des cartes moins longues pour la génération R300 utilisant de la mémoire HBM. On notera enfin qu'a plusieurs reprises AMD a parlé de « on package cache » pour décrire la mémoire HBM, plutôt que de GPU RAM. Un point qui n'est surement pas anodin.











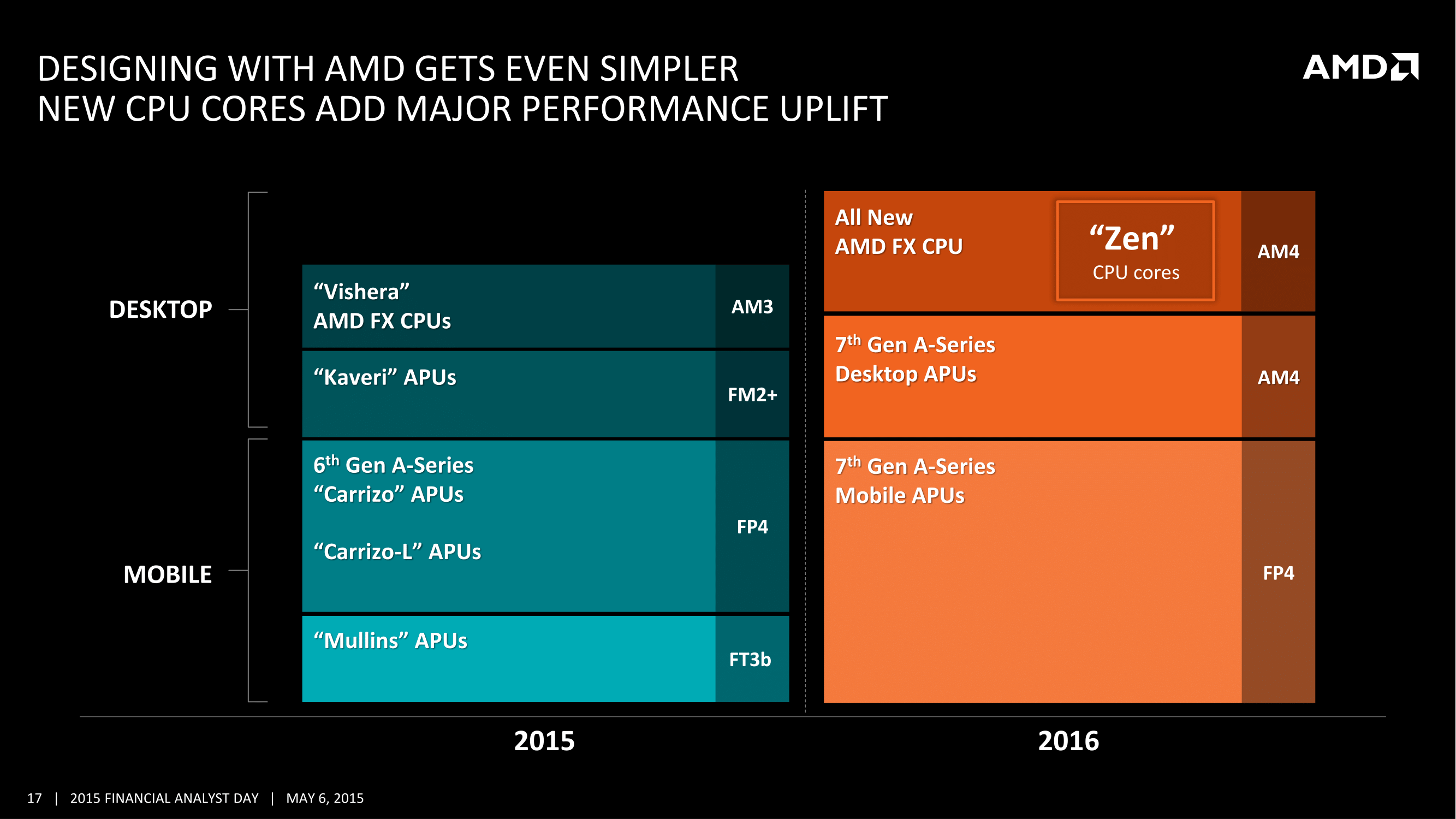



2016 sera l'année du FinFETRestons sur le sujet des GPU pour évoquer 2016. Sur ce point AMD est clair, on verra arriver en 2016 des GPU « FinFET », comprendre fabriqués en 14/16nm. AMD annonce une efficacité de son architecture GCN doublée en matières de performances par watts par rapport à l'actuel (ce qui, vu le passage du 28nm au 14/16nm parait dans la lignée des gains que l'on peut attendre). Ces puces accueilleront une seconde génération de mémoire HBM ainsi qu'une « accélération » pour la réalité virtuelle/réalité augmentée.
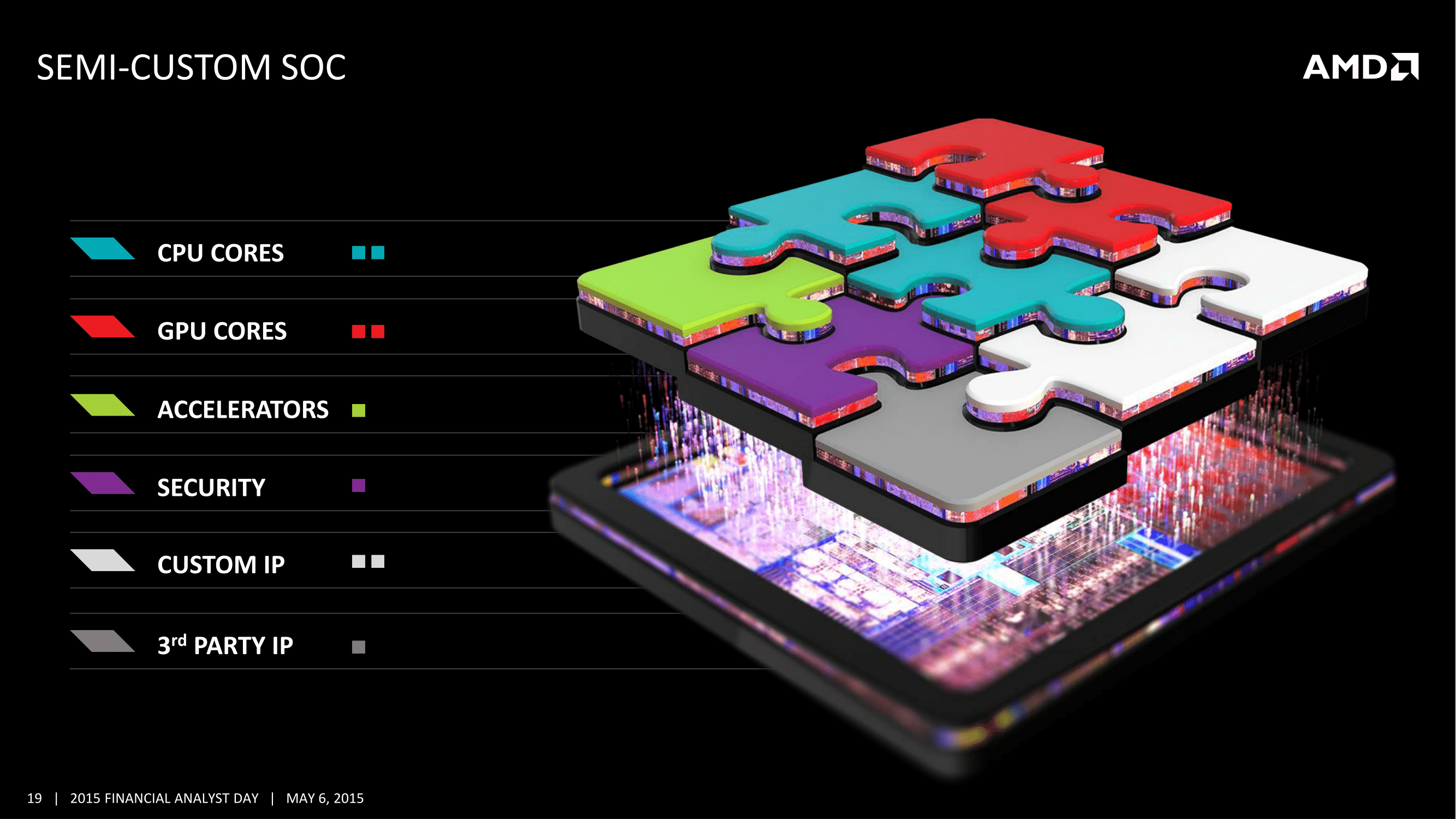
Retour au Zen ?Mais bien évidemment, l'un des points les plus intéressants de la présentation d'AMD concerne le futur de ses gammes processeurs et APU. AMD a officiellement annoncé sa nouvelle architecture x86 baptisée Zen. Il s'agit de la première « nouvelle » architecture x86 produite par AMD depuis le retour de Jim Keller chez AMD après son passage remarqué chez Apple ou il a dirigé les équipes qui ont produit notamment le SoC armv8 64 bit A7. AMD est resté assez vague sur les détails, nous promettant pour bientôt un « deep dive » dans les détails de l'architecture, mais a tout de même confirmé les grandes lignes, et ses ambitions, là encore grandes.
Comme on pouvait s'y attendre, le concept de modules disparait et l'on retrouve des curs plus classiques sans partages de ressources utilisant un design totalement neuf et taillé « pour les hautes performances ». Les curs Zen utilisent également le SMT qui permet à chaque cur de disposer de deux threads hardware (à l'image de l'HyperThreading d'Intel). Un processeur Zen 8 curs aurait donc 16 threads logiques. Le constructeur annonce de facto un gain d'IPC de 40% pour un core Zen par rapport à un core de son architecture Excavator. Autre point sur lequel AMD est passé très rapidement, la question des caches, décrits comme nouveaux, à bande passante élevée et à latence basse.






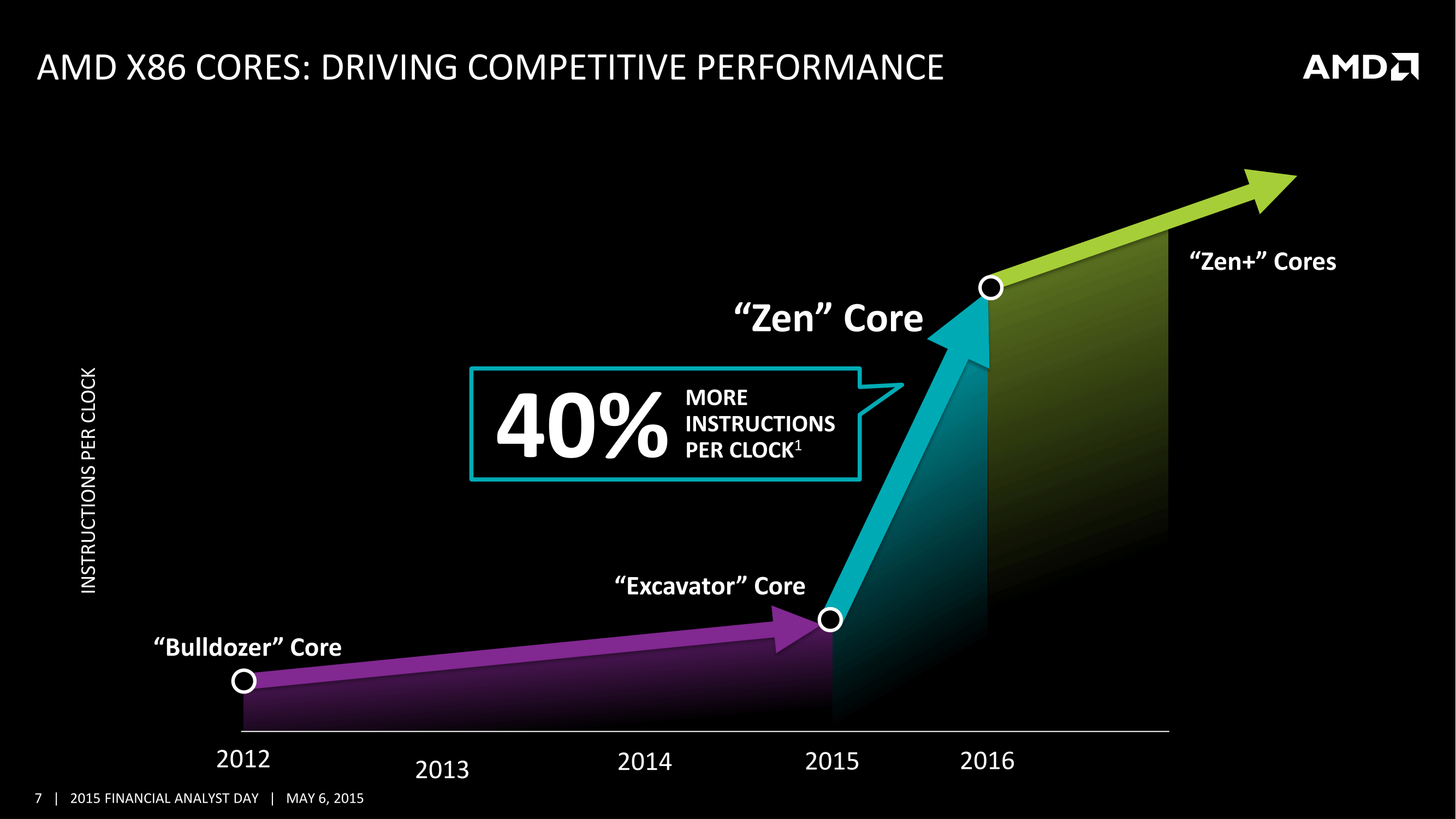




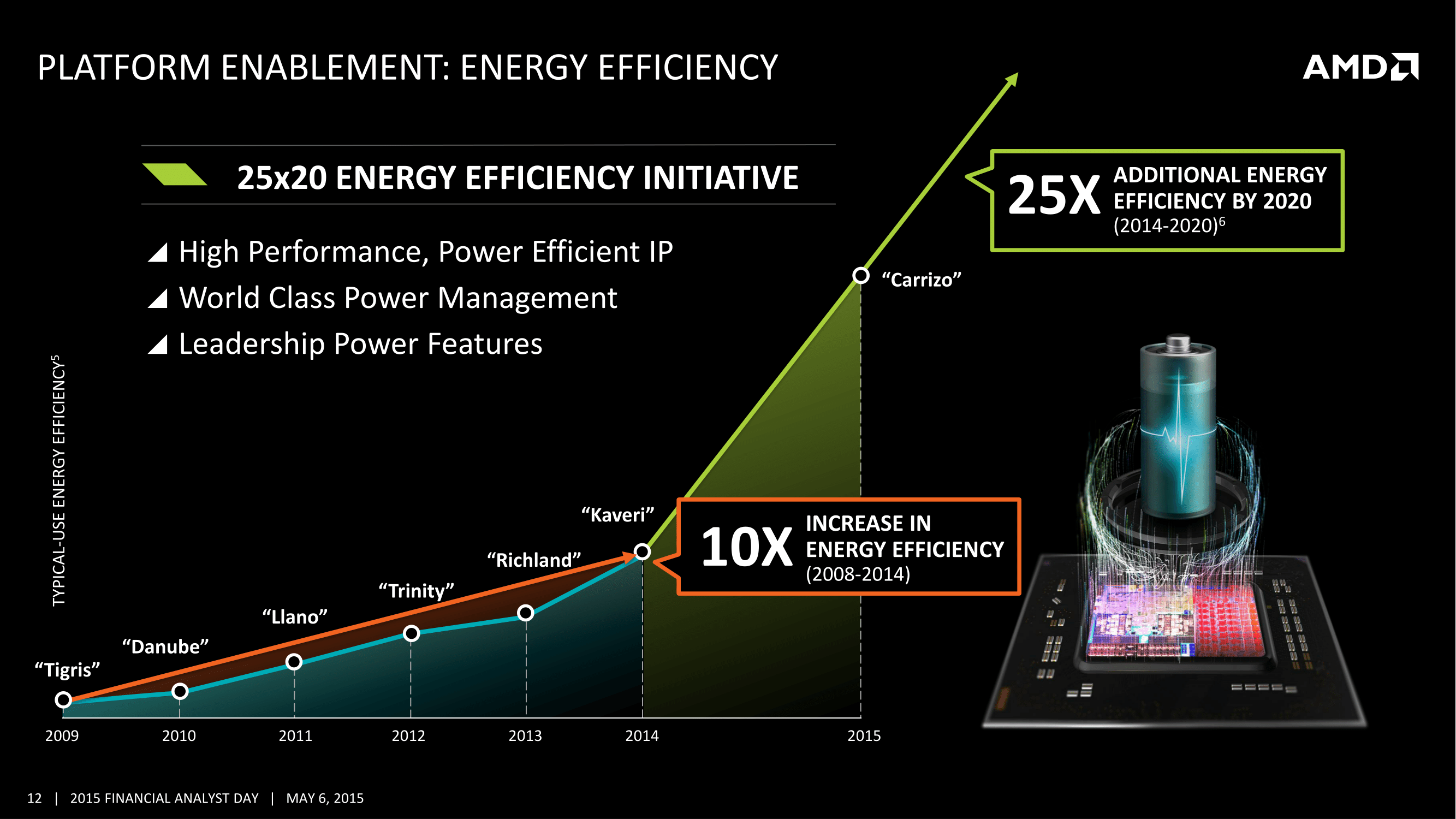




La stratégie du constructeur pour le lancement de ces puces est là encore intéressante puisque le constructeur reconnait avoir mis de côté ces dernières années ses gammes CPU pures (FX). L'architecture Zen sera donc déployée, en premier, sur une nouvelle génération de processeurs FX dépourvus de GPU intégrés et disposant d'un nombre de curs « élevé ». AMD est ambitieux pour ces nouveaux FX puisque le constructeur parle à plusieurs reprises dans ses présentations de « compute leadership ». AMD n'a pas précisé de date pour l'instant pour le lancement de ces puces, se contentant d'un large 2016.
Dans un second temps, AMD lancera également une « 7ème génération » d'APU qui utilisera elle aussi des curs Zen. Des APU qui seront lancées à la fois en version mobile et en version desktop, mais l'on retiendra surtout qu'AMD profite de Zen pour unifier ses sockets : APU et CPU utiliseront tous deux un nouveau socket baptisé AM4 pour une plateforme unique qui supportera à la fois la mémoire DDR3 et la mémoire DDR4.
AMD lancera également des puces Zen sous la forme d'Opteron pour les plateformes serveurs haute performances ou le constructeur évoque une « bande passante mémoire disruptive » qui peut laisser penser que le constructeur pourrait, pour certaines versions serveurs, proposer quelque chose d'original pourquoi pas de la mémoire HBM.


















Seattle et K12 : ARM en retardUn mot pour terminer sur l'autre volet de l'activité serveur d'AMD, annoncé il y a un an de cela, l'arrivée chez la marque de puces ARM. Ce sera finalement le cas pour la seconde moitié de l'année avec le lancement des SoC Opteron A1100 « Seattle » basés sur des curs génériques ARM Cortex A57 64 bit.
En ce qui concerne la génération suivante, les K12 qui représenteront la première architecture ARM « custom » d'AMD, il faudra attendre un peu. Annoncé pour 2016, cette architecture ne débarquera finalement qu'en 2017 tandis que le projet Skybridge qui devait proposer au choix des curs Puma+ ou Cortex A57 semble avoir été mis de côté.
Dans une situation financière difficile, AMD utilise cette opportunité pour présenter aux investisseurs on peut le comprendre - une vision optimiste de ses projets. On ne peut s'empêcher d'apprécier le fait qu'une nouvelle architecture x86 soit présentée, et qu'elle ne semble pas uniquement réservée aux APU sur lesquels le constructeur avait tout misé ces dernières années. Les ambitions autour de CPU « hautes performances », marché longtemps délaissé, semblent également aller dans le bon sens, tout comme on se félicitera de l'arrivée d'une unification des plateformes desktop.

Se posera cependant la douloureuse question de l'exécution qui a jusqu'ici souvent fait défaut à AMD. Il suffit de regarder la roadmap ARM ci-dessus, dévoilée l'année dernière là encore aux investisseurs, et qui en pratique a été décalée d'un an avec le lancement de Seattle cette année, et du K12 uniquement en 2017. La roadmap AMD telle que présentée aujourd'hui aussi bien côté APU que CPU ne laisse que peu de marge à la marque pour rater son coup. Un retard identique sur la roadmap Zen placerait AMD dans une situation extrêmement compliquée. Si par contre le constructeur arrive à atteindre réellement ses objectifs, on pourrait voir enfin, en 2016, un retour de la compétition dans un monde du x86 en stagnation ces dernières années.
AMD lève le voile sur Carrizo côté technique
AMD dévoile de nombreux détails sur son APU Carrizo à l'occasion de l'ISSCC 2015, une conférence annuelle dédiée aux circuits intégrés se déroulant à San Francisco cette semaine. Pour rappel, les grandes lignes des informations dévoilées ici avaient déjà fuité en novembre dernier. Une partie des informations de la présentation est contenue dans la présentation AMD ci-jointe, d'autres détails sont exclusifs à la présentation faite lors de l'ISSCC.



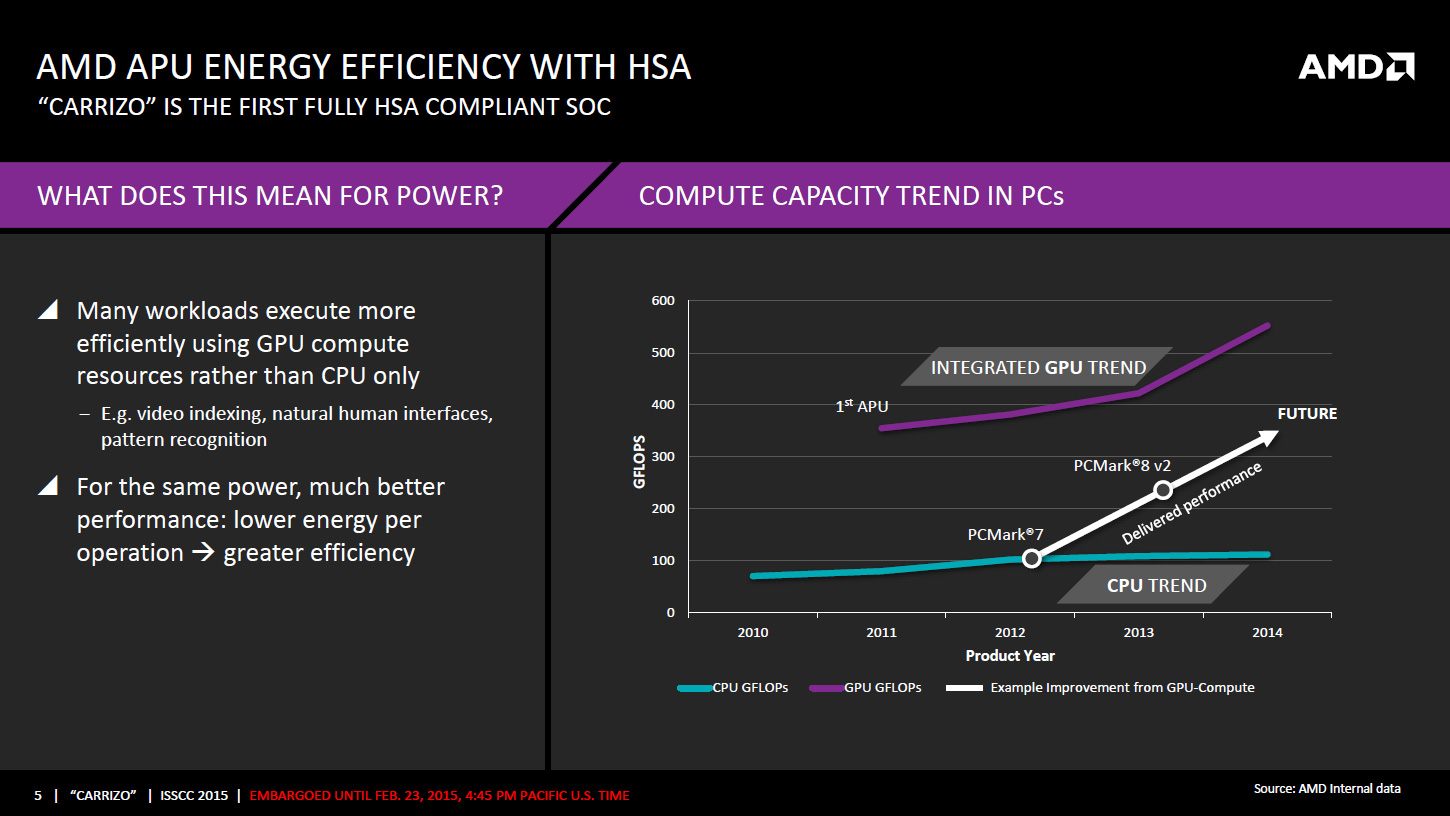
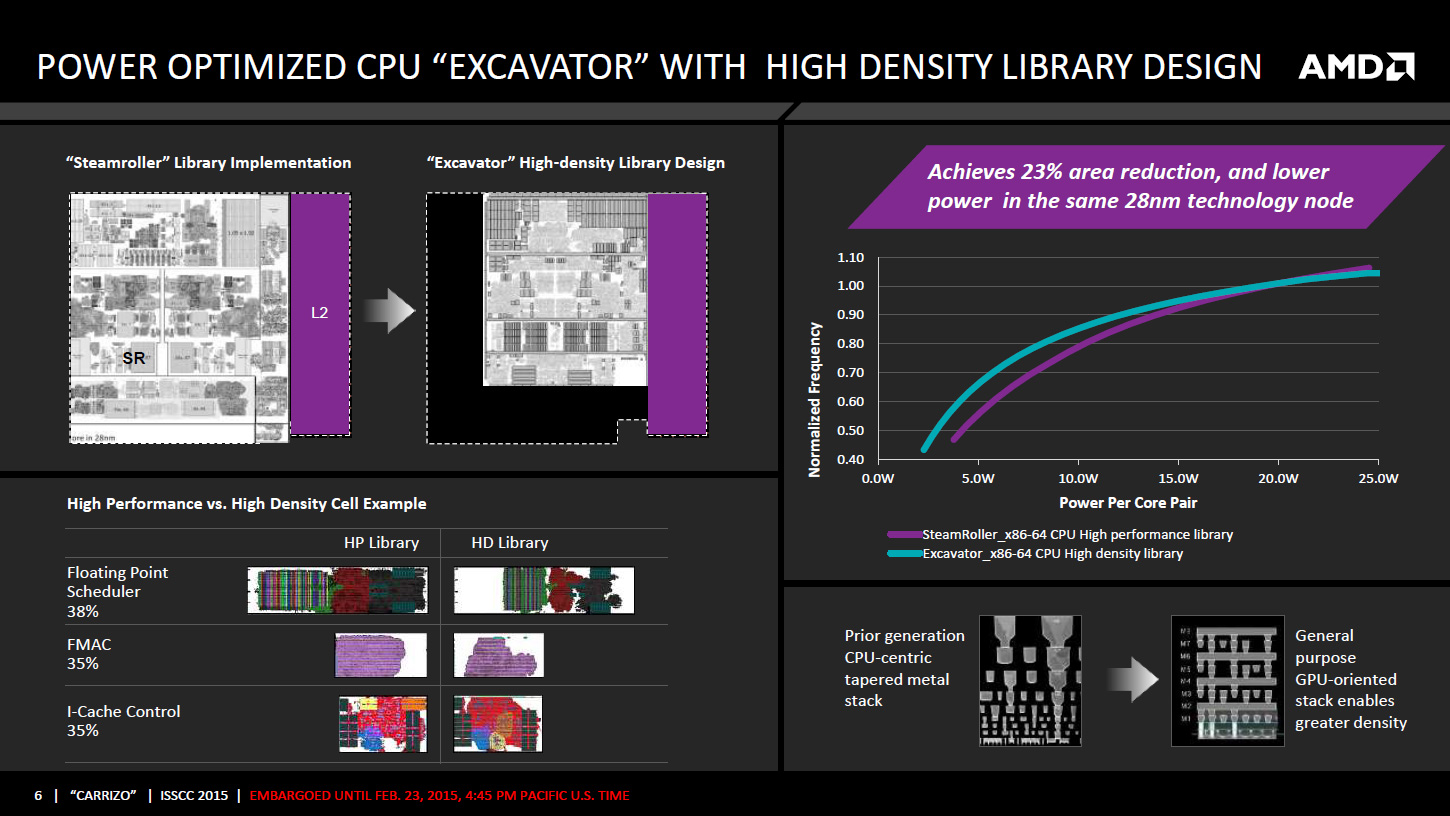
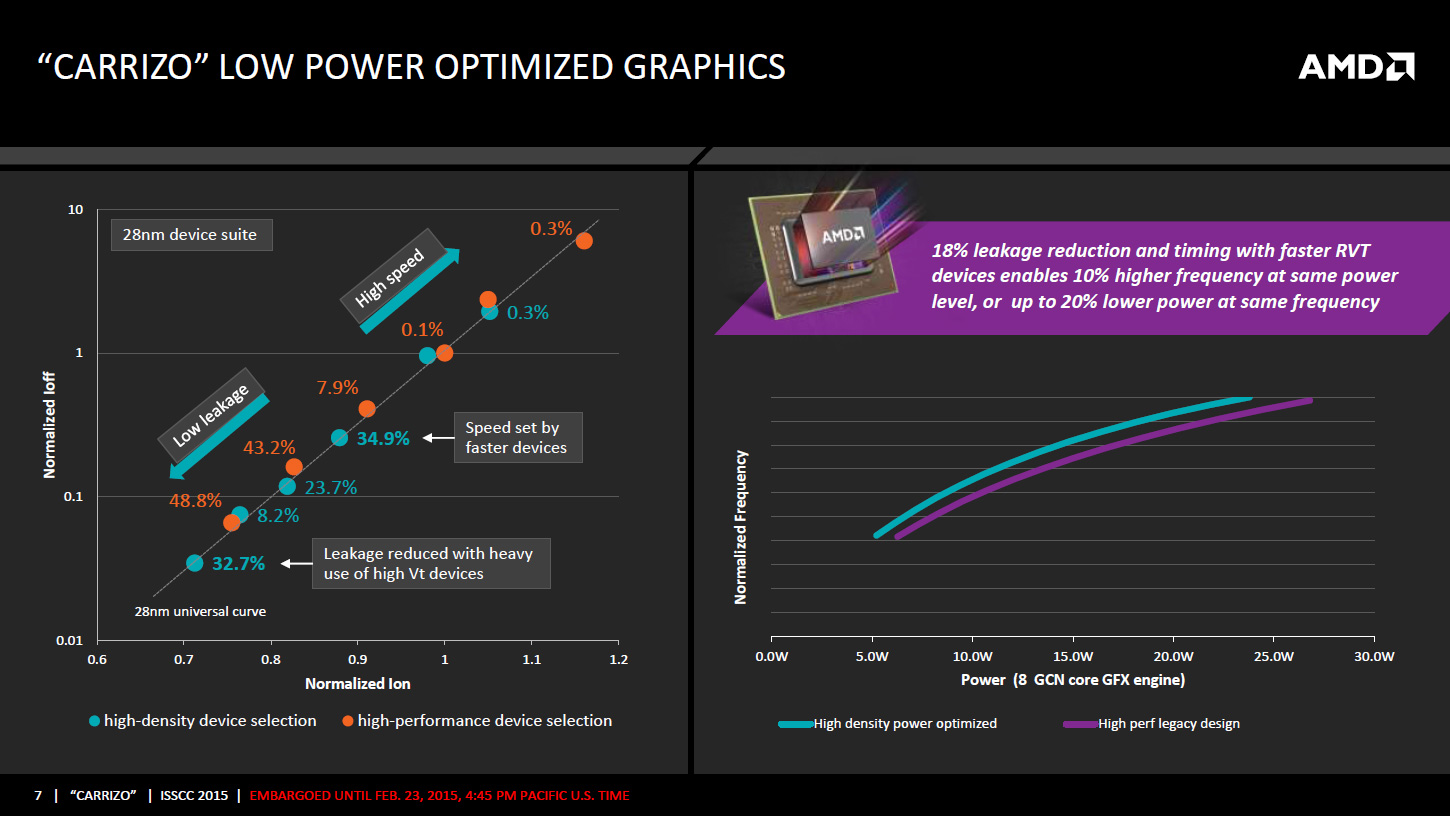

Carrizo est ainsi une puce de 244,62mm² intégrant 3,1 milliards de transistors gravés en 28nm, un gain en densité important puisque Kaveri n'était qu'à 2,41 milliards de transistors pour 245mm². Ce gain en densité est entre-autre lié au gain de place sur la partie x86 du fait de l'utilisation de règles de design inspirées du monde GPU et destinées à prioriser la densité et la consommation, quitte à avoir une montée en fréquence moins optimale.
Le gain est énorme en terme d'espace puisque de l'ordre de 35% à 38% sur certaines zones. Au final, et hors cache L2, un module Excavator (2 curs) occupe 23% moins d'espace qu'un module Steamroller avec seulement 14,48mm² alors qu'il passe de 86 à 102 millions de transistors. Cette hausse est liée à des modifications permettant d'augmenter l'IPC, AMD faisant état d'un gain de 5%, notamment avec un doublement du cache L1 data qui passe de 16 à 32 Ko par cur. Qui dit hausse de la densité dit également hausse de la densité thermique, pour contrecarrer ce phénomène AMD à intercalé entre les deux modules Excavator le contrôleur mémoire qui a tendance à moins s'échauffer.
La partie GPU n'est pas dénuée d'amélioration puisque AMD utilise désormais le 28nm de manière à obtenir des transistors avec des courants de fuite plus faibles, quitte à atteindre des fréquences moins importantes. Cela permet à AMD d'annoncer une fréquence 10% supérieure au sein de la même enveloppe thermique ou une consommation inférieure de 20% à la même fréquence. Le GPU dispose de plus d'une alimentation dédiée (VDDGFX), qui vient s'ajouter à VDDCPU et VDDNB qui sont respectivement pour les modules x86 et le chipset intégré.

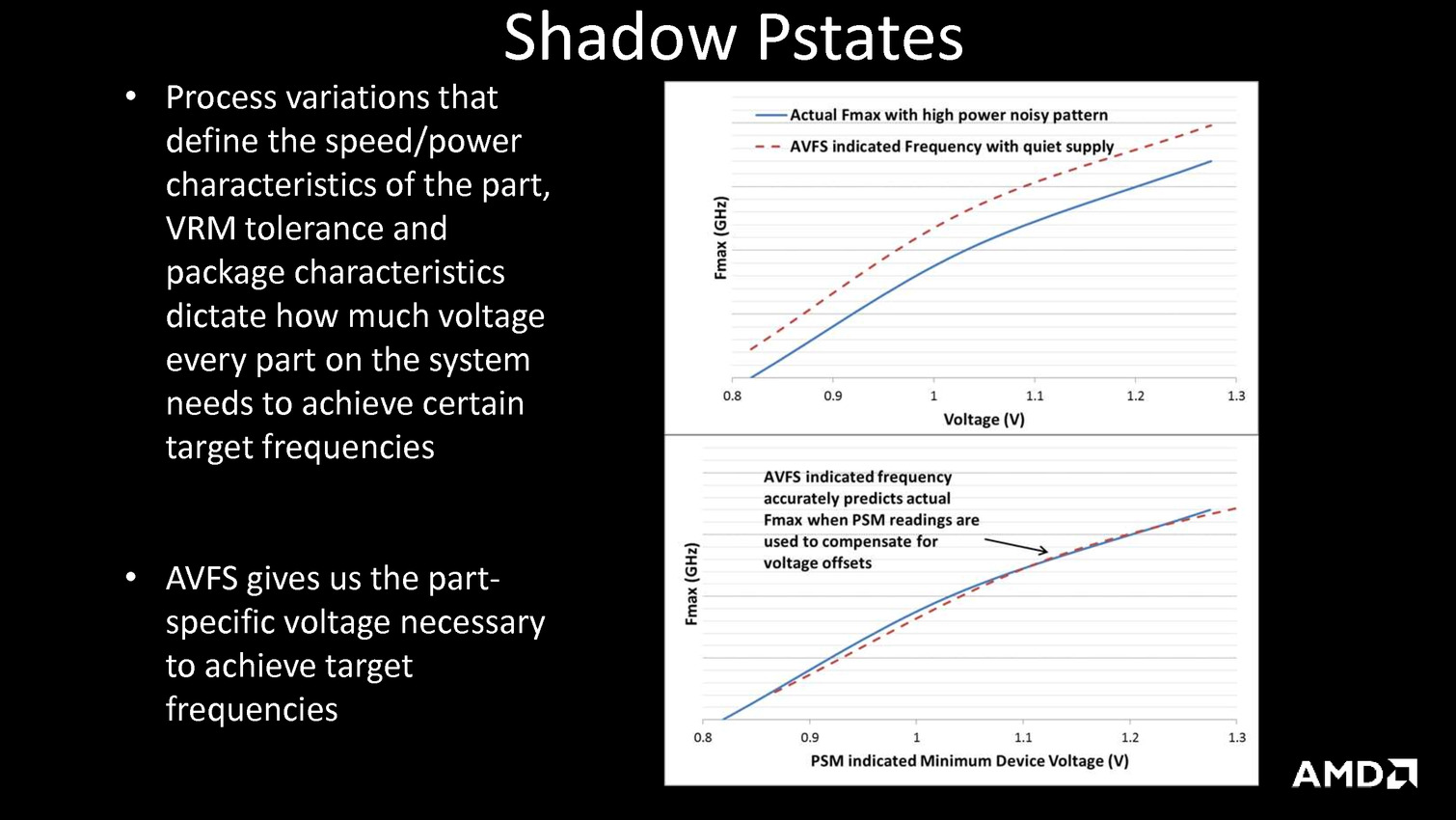
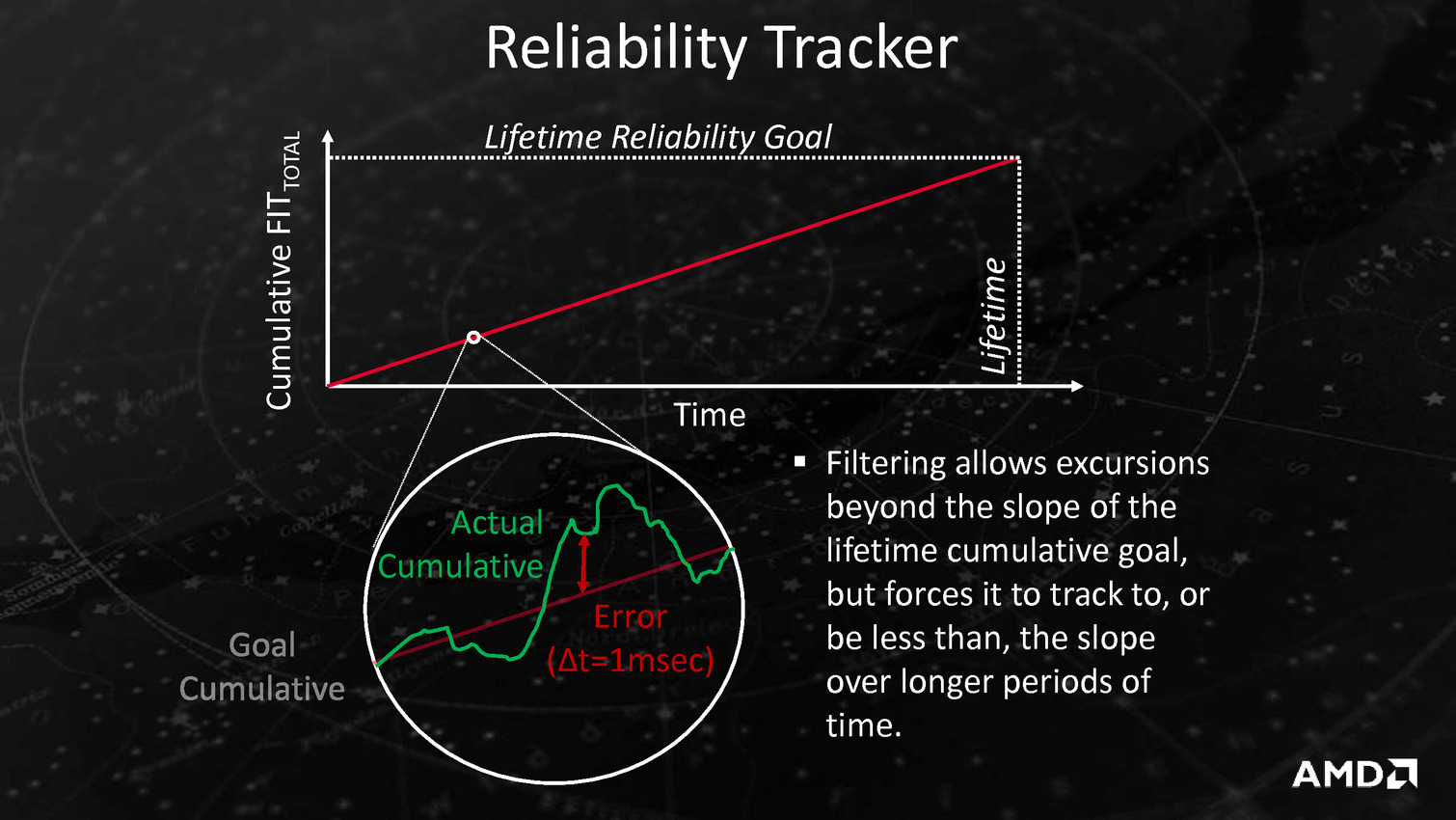
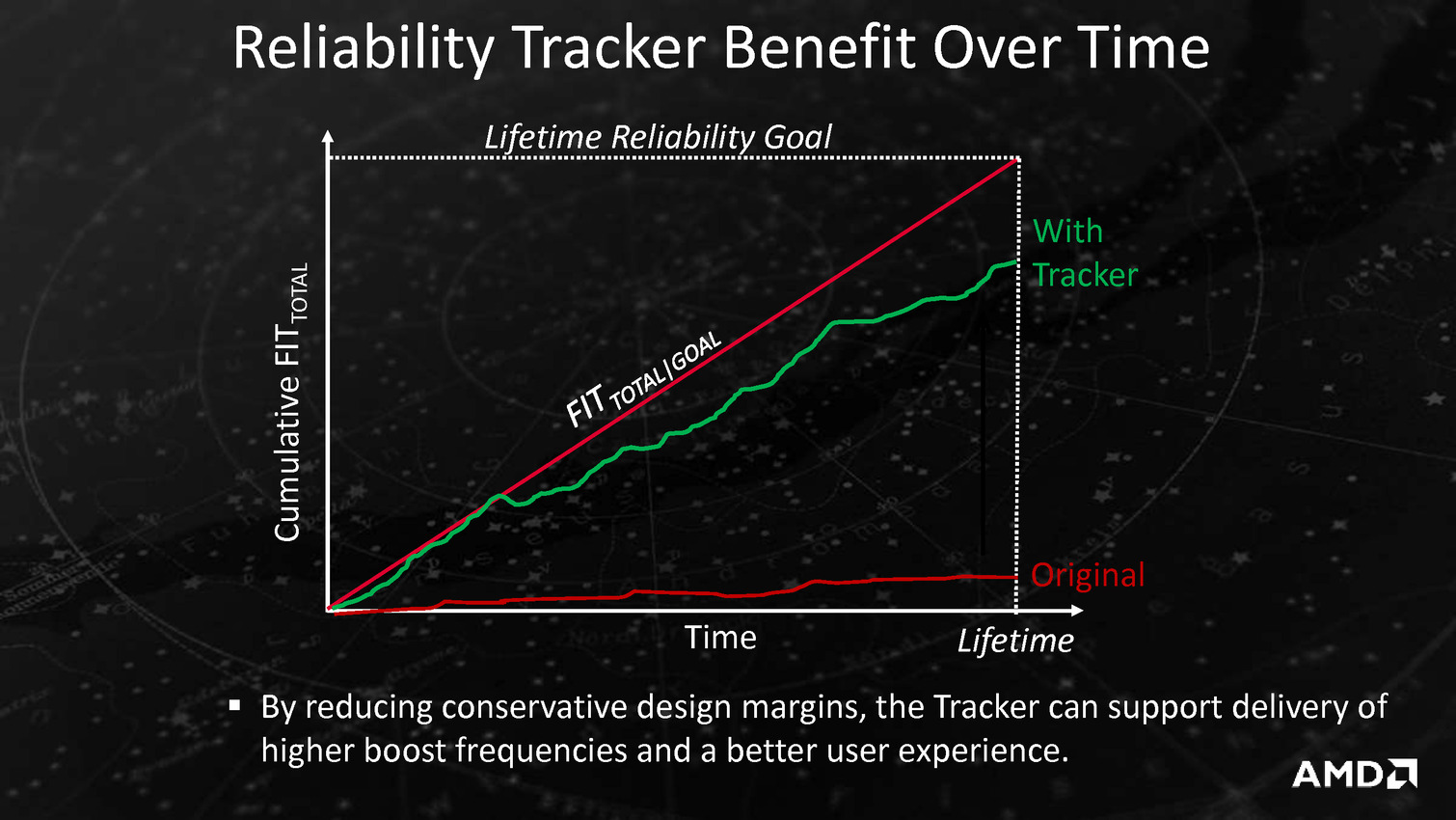
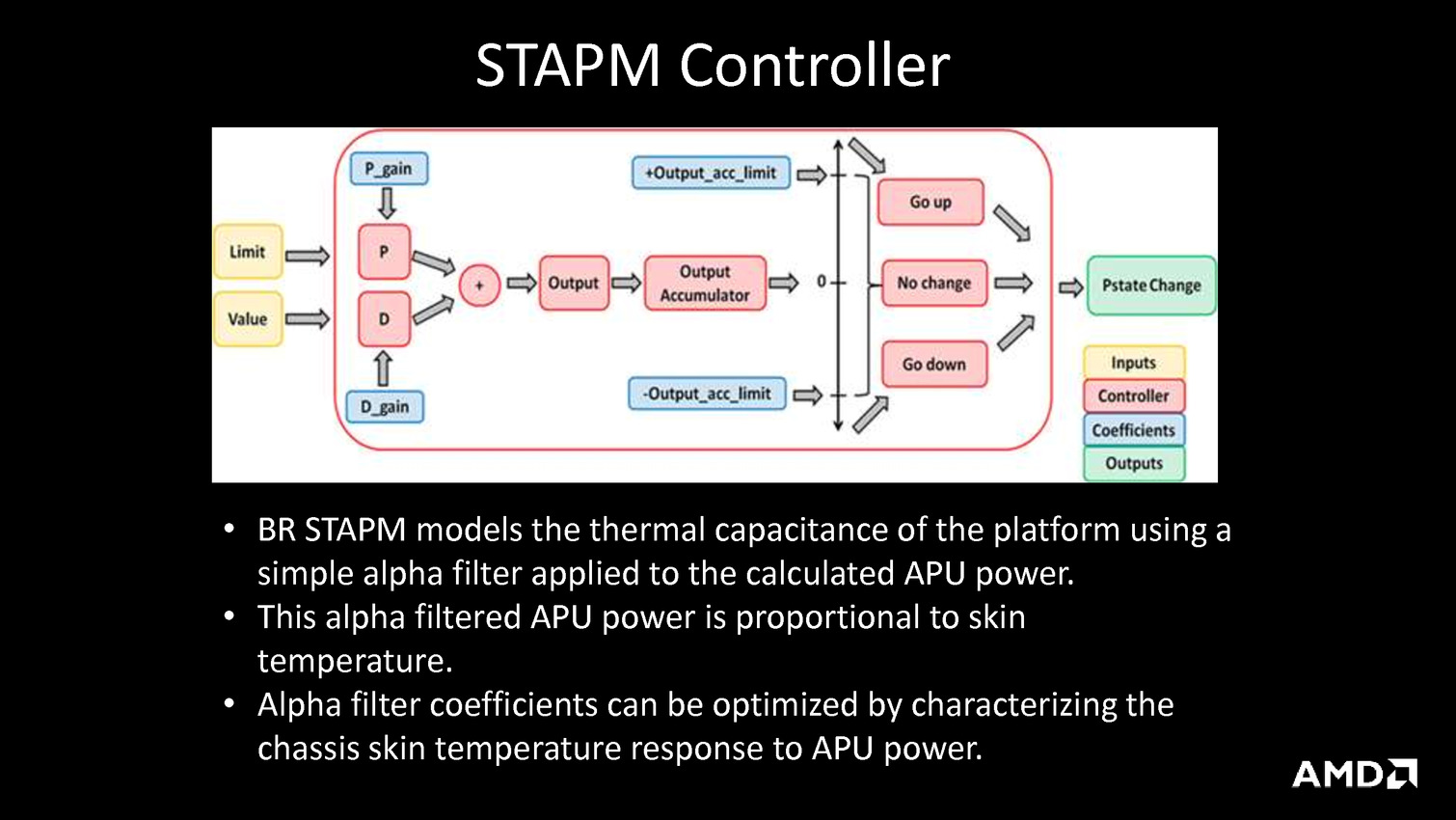
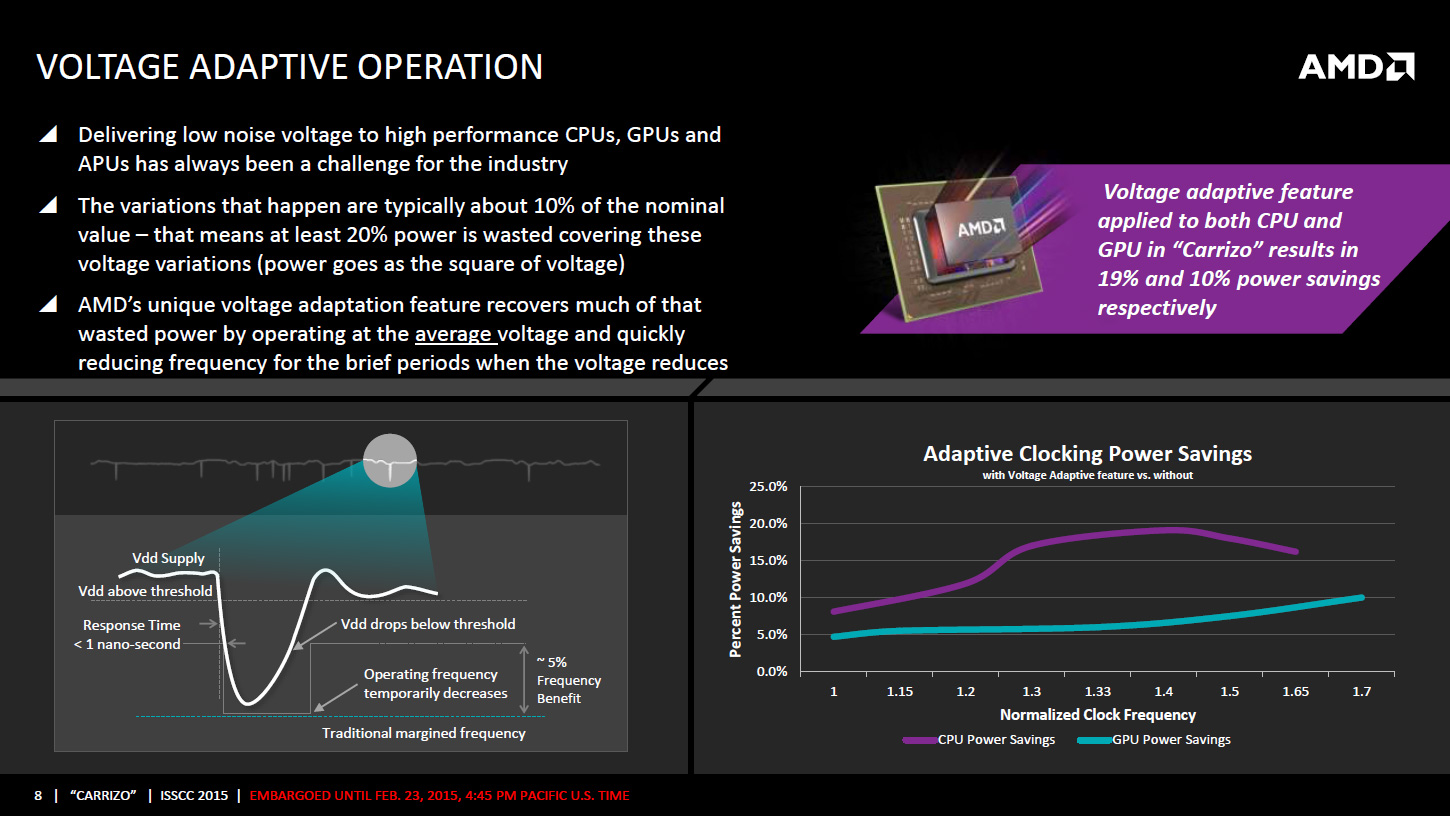
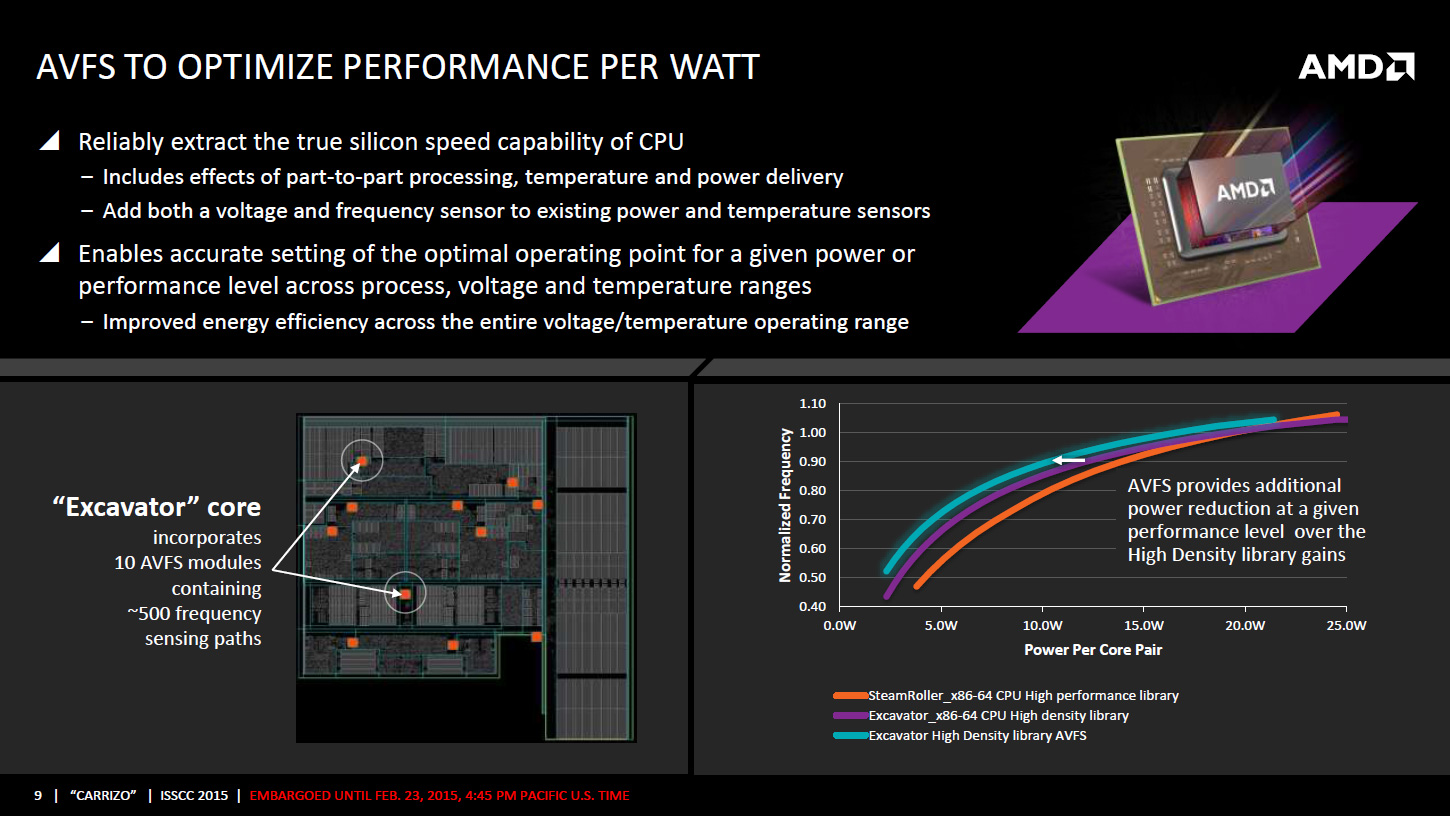
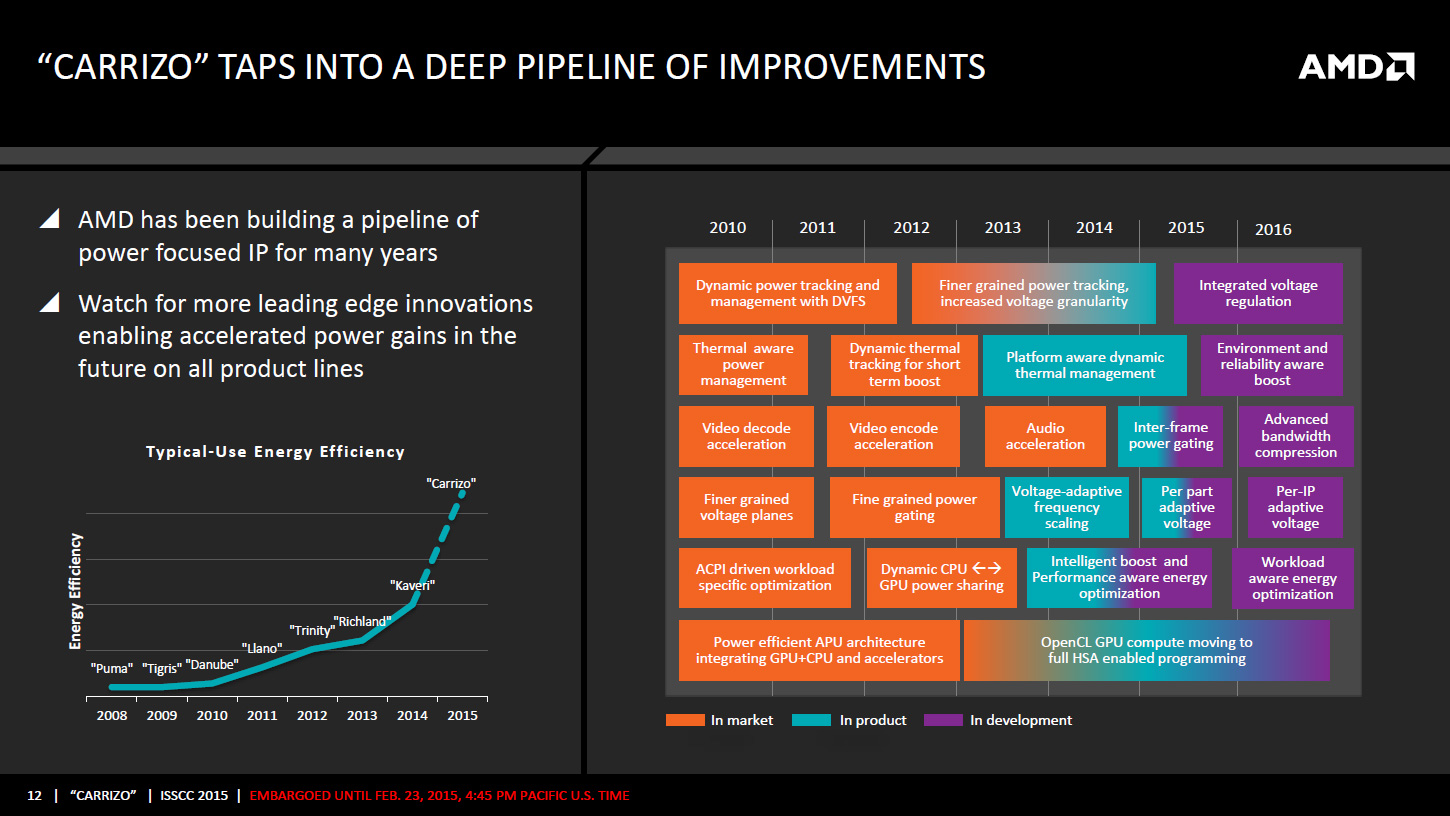
Puisqu'on parle de la tension, AMD intègre un mécanisme visant à adapter très rapidement, en moins de 1ns, la fréquence CPU ou GPU en cas de chute de la tension d'alimentation. Ceci permettrait d'utiliser une marge de sécurité moins importante vis à vis de la tension et de gagner environ 5% de fréquence à tension égale, AMD annonçant des gains de consommation pouvant atteindre 19% côté CPU et 10% côté GPU. Ce n'est pas la seule amélioration dans la consommation puisque les curs Excavator intègrent la technologie AVFS (adaptive voltage-frequency scaling). Il s'agit d'une dizaine de capteurs qui sont capables de détecter quand le processeur est proche de faire des erreurs de calcul, sans en être encore à ce stade, et qui remontent alors à une unité dénommée SMU (pour system-management unit) des informations sur la tension, la fréquence et la température. Sur la base de ces statistiques, cette unité se charge alors de créer et maintenir une table de fréquence / tension optimale pour chaque exemplaire de Carrizo.
Si 32 des 690 millions de transistors supplémentaires sont utilisés côté x86, le reste est dédié à des améliorations sur les curs GCN pour le HSA, un décodeur vidéo amélioré supportant le H.265 (mais AMD ne précise pas encore si le 10-bit est pris en charge), un doublement de l'encodeur vidéo ce qui permet d'aller 3.5x plus vite que sur Kaveri (il est question de 9 flux 1080p à 30 fps en H.264). Enfin Carrizo est désormais un SoC complet et intègre un FCH (southbridge) qui n'est pas détaillé officiellement ici mais qui devrait entre autre gérer 4 USB 3.0, 4 USB 2.0 et 2 SATA 6 Gbs. Son intégration dans la puce fait que sa consommation est probablement incluse dans le TDP et qu'il est gravé en 28nm alors que ces puces ont traditionnellement plusieurs process de retard. Pour rappel Intel utilise sur Broadwell 14nm en version BGA une puce PCH séparée gravée en 32nm, au contraire de Bay Trail-D et son successeur Braswell qui sont eux des SoC à l'instar de Carrizo.
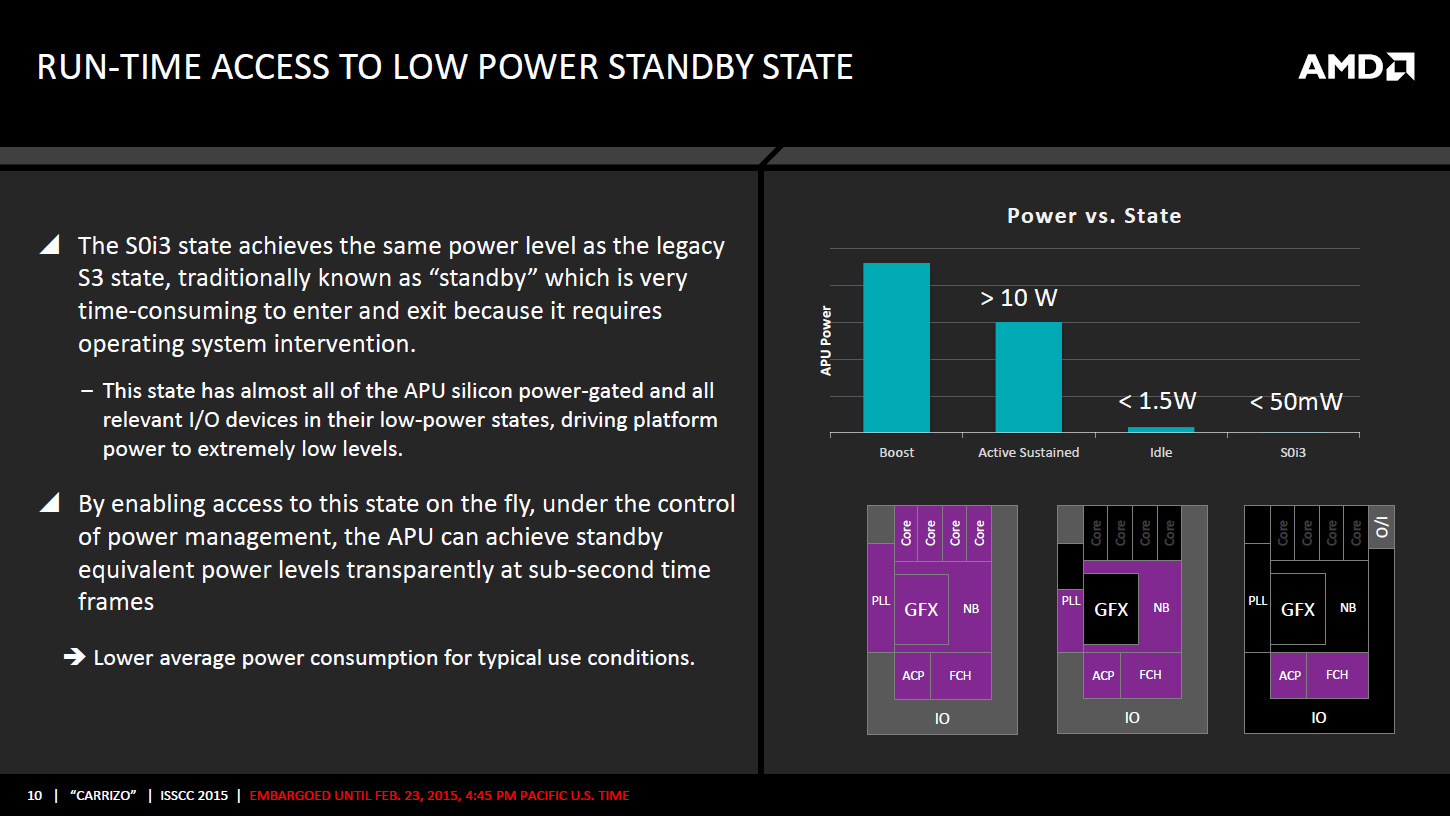
L'A70M utilisé avec Kaveri était gravé en 65nm et avait un TDP de 4,7w pour une consommation au repos de 750mW, cette intégration devrait donc nettement améliorer la consommation en charge comme au repos. AMD ajoute d'ailleurs sur ce SoC la gestion d'un nouveau mode de veille qui permet d'avoir une consommation très basse, proche du S3 (suspend to ram) avec moins de 50 mW sur l'APU mais avec une sortie de veille encore plus rapide ce qui permet au système d'utiliser ce mode plus régulièrement, par exemple pour le Connected Standby. La sortie de ce mode S0i3 est par contre bien plus lente que chez Intel, moins de 500ms contre 3.1ms sur Haswell notamment grâce au régulateur de tension intégré, ce qui empêchera le système d'exploitation d'utiliser aussi souvent que sur Haswell.
Au final les diverses améliorations permettent à AMD d'annoncer que son SoC Carrizo, qui sera décliné dans des versions 12 à 35 watts alors que Kaveri allait de 17 à 35 watts, disposera de curs x86 avec une consommation en baisse de 40% par rapport à Kaveri, contre 20% de mieux pour les unités GCN, ce qui devrait permettre d'avoir des fréquences et donc des performances en hausse avec ces enveloppes thermiques réduite, ce malgré les gains modérés côté IPC... et la finesse de gravure qui reste en 28nm ! Les équipes n'ont pas manqué d'ingéniosité pour arriver à un tel tour de force, tout en intégrant des nouveautés telles que le FCH intégré sans augmenter la taille et donc le coût de la puce. Afin de pouvoir continuer de lutter contre un Intel qui dispose désormais de deux générations de process d'avance, de telles avancées étaient absolument nécessaires et l'avenir nous dira si elles sont suffisantes en pratique. Les portables Carrizo devraient pour rappel débarquer aux alentours de la mi-2015, nous avions pu observer un prototype lors du CES en début d'année.
Nous finirons par une petite digression sur Carrizo et le FM2+. Comme indiqué il y a un mois, cette version n'est plus à l'ordre du jour, et cette présentation donne des détails sur ce sujet puisqu'on voit bien que les optimisations visent la plage de consommation du SoC BGA, au dépend de celle utilisée sur FM2+, si bien que la décision de ne pas décliner Carrizo sur FM2+ ne semble pas dater d'hier. Ainsi si Excavator apporte des gains à 5, 10 ou 15 watts de consommation par module, arrivé à 20 watts l'écart se réduit à peau de chagrin et l'avantage repasse probablement à Steamroller au delà de 25 watts. Même avec le gain d'IPC de 5% le compte ne doit pas y être lorsqu'on est à 30 ou 40 watts par module comme c'est le cas sur les Kaveri FM2+. Au-delà de ça, Carrizo tel qu'il nous est présenté n'aurait pas forcément pu fonctionner sur FM2+ puisque l'intégration d'une tension spécifique pour le GPU implique des modifications au niveau de l'étage d'alimentation des cartes mères. Peut-être qu'AMD aurait pu passer outre, mais se pose alors le problème d'utiliser un FCH externe au lieu du FCH interne, sans parler des lignes PCIe Gen3 moins nombreuses puisqu'elles sont a priori de 8 sur Carrizo. Pour les vraies nouveautés en desktop (passons sur Godavari) il faudra donc attendre 2016 et la prochaine architecture x86 AMD dénommée Zen. Vivement !
AMD Carrizo et Carrizo-L pour mi-2015
Après la fuite d'hier concernant le nombre de transistors de Carrizo, AMD vient de dévoiler que les Carrizo et Carrizo-L seront lancés au premier semestre 2015. Ces puces sont censées apporter un "saut important dans le domaine de la performance et de l'efficacité énergétique", sans plus de précisions.

Première image de Carrizo, ici en version BGA
AMD confirme que Carrizo sera un SoC intégrant des curs x86 Excavator, alors que le petit nouveau Carrizo-L utilisera des curs x86 Puma+, comme les Beema annoncés en avril. AMD précise que les deux puces utiliseront un même packaging FP4, ce qui simplifiera la vie des OEMs, et fait mention de la disponibilité des portables et all in one les utilisant pour mi-2015.

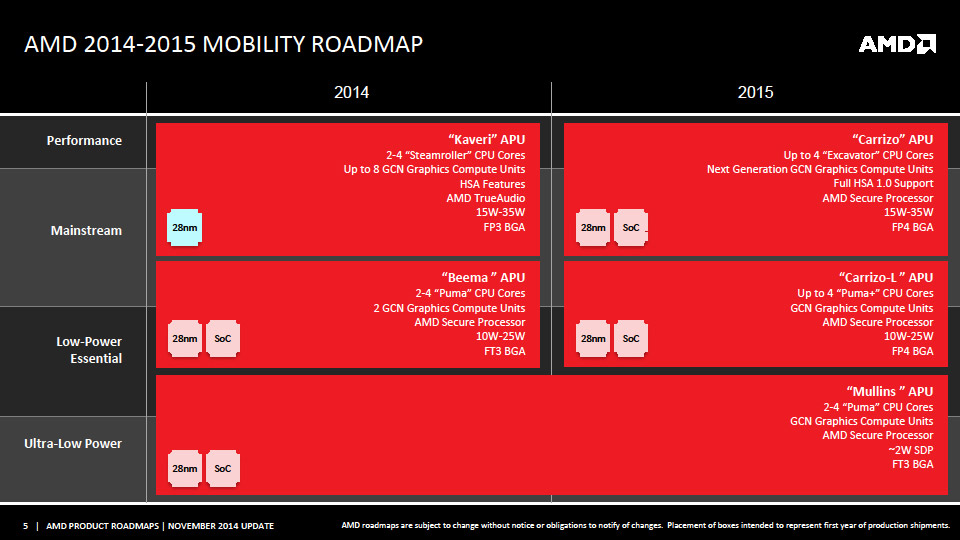
Il est ici question des versions BGA, aucune indication n'étant donné pour ce qui est d'éventuelles versions Socket FM2+ ou AM1.