Actualités informatiques du 24-03-2016
- Quelques nouvelles du 10 et 7nm chez TSMC
- GDC: VR: Nvidia Multi-Res Shading en pratique
- GDC: Zotac MAGNUS EN980 avec GTX 980 et watercooling
- GDC: Vers de nouveaux types de shaders ?
| Mars 2016 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 | |||
Quelques nouvelles du 10 et 7nm chez TSMC



TSMC tenait la semaine dernière à San José son symposium, une conférence au cours de laquelle le fondeur taiwanais a partagé des détails inédits sur ses prochains process de fabrication de puces. Des détails rapportés par nos confrères d'EETimes et de Semiwiki (partie 1 et partie 2 ).
16FF+ et 16FFC
Pour le 16nm, si Apple l'utilise depuis de longs mois, les autres clients semblent peiner à lancer leur production, probablement à cause des coûts importants engendrés par la nouvelle technologie et aussi de quelques limites de capacité. TSMC s'est contenté de confirmer que son 16FF+ est en production "volume" (c'est à dire dédiée à des produits finis) depuis le troisième trimestre 2015 et qu'il s'attend à ce que son volume de wafers 16nm augmente significativement entre juin et octobre avec pour but d'atteindre 300 000 wafers par trimestre d'ici à la fin de l'année. Plusieurs produits 16FF+ sont déjà en production, comme les FPGA de Xilinx.
En parallèle TSMC propose également une version "compacte" (16FFC) de son process qui tente de réduire les coûts en diminuant par exemple le nombre de masques nécessaires. Cette version FFC sera celle qui sera privilégiée pour les usages non haut de gamme, même si elle propose plusieurs avantages intéressants, par exemple pour les usages très basse consommation (tension d'alimentation de 0.5V), mais aussi pour une version spécifique aux usages automobiles (une variante qui attendra mi 2017). TSMC avait annoncé cette variante publiquement en janvier, mais la production en volume sera entamée dès le mois d'avril. 70 tapeout 16FFC sont attendus cette année (à titre de comparaison, il y a déjà eu 70 tapeout 16FF+ en 2016), il sera intéressant de voir quels produits l'utiliseront !
10nm
TSMC est confiant sur l'arrivée du 10nm, même s'il s'agira vraisemblablement d'un node qui ne sera pas utilisé par tout le monde. La production en volume prendra place dans la Fab 15, dans deux nouvelles tranches construites pour l'occasion (les autres tranches produisent en 28nm). Le constructeur s'attend à produire 200 000 wafers par trimestres d'ici la fin de l'année 2017. Un premier tapeout 10nm pour un produit d'un de ses clients aurait été réalisé et la qualification est attendue au troisième trimestre cette année.
Malgré tout le 10nm reste un node qui sera limité côté clients, Xilinx ayant par exemple indiqué publiquement qu'ils attendraient le 7nm. Étant donné les délais suspicieusement courts entre le 10 et le 7nm, on peut les comprendre (productions en volume respectives annoncées pour 2017 et 2018) !
7nm
L'attente autour du 7nm est importante, et TSMC a commencé a donner quelques réponses à nos interrogations. D'abord, le fondeur proposera dès le début deux versions distinctes de son process 7nm, une version dédiée au mobile, et une autre aux produits hautes performances (+10 à 15% de performances en plus, avec pour but d'atteindre 4 GHz).
Les deux variantes devraient entrer en qualification en simultané au premier trimestre 2017. Pour expliquer le délai court entre le 10 et le 7nm, nous avions spéculé que le constructeur utiliserait une stratégie identique à celle utilisée entre le 20 et le 16nm, à savoir utiliser un BEOL (la partie basse de la puce qui contient les couches métalliques d'interconnexion) commun ce qui limiterait les gains de densité.
Après avoir évité a plusieurs reprises de répondre à la question dans ses conférences aux investisseurs, TSMC a confirmé que ce ne sera pas le cas : la variante mobile du 7nm apportera une densité 1.63x supérieure à celle de son 10nm ! C'est certes moins que le passage 28 à 20nm (1.9x) mais largement au dessus de la transition 20 à 16nm (1.15x, obtenu principalement par des optimisations des règles de design). Par rapport au 10nm, le 7nm devrait apporter 15 à 20% de performances en plus, ou 35 à 40% de consommation en moins selon les usages.
TSMC utilisera un matériel commun à 95% entre le 10 et le 7, facilitant la transition. La différence tiendra sur l'utilisation plus massive à 7nm du quadruple patterning (on ne sait pas encore exactement ou il sera utilisé, il semblait entendu sur les dernières roadmaps ITRS que le quadruple patterning - SAQP - serait utilisé pour les couches métal à 10 et 7 par exemple).
Le développement du 7nm avance puisque TSMC a indiqué avoir déjà produit des modules de SRAM de 128 Mbit, atteignant déjà des yields de 30% pour des dies pleinement fonctionnels. Il est toujours difficile de comparer ces chiffres tant les constructeurs les gardent secrets. En février 2010, soit une vingtaine de mois avant le lancement des premiers GPU 28HP (les Radeon 7970), TSMC annonçait cependant des yields sur sa SRAM de 26% . Atteindre 30% sur des puces pleinement fonctionnelles semble donc particulièrement encourageant à ce stade.
Si l'on considère les difficultés attendues par tous à 10 et à 7nm, la roadmap de TSMC semble particulièrement agressive et il faudra voir si le fondeur arrive a l'exécuter. On comprendra en tout cas qu'il ne faudra pas s'attendre à voir de 10nm ailleurs que chez Apple, ou possiblement Qualcomm étant donné les délais.
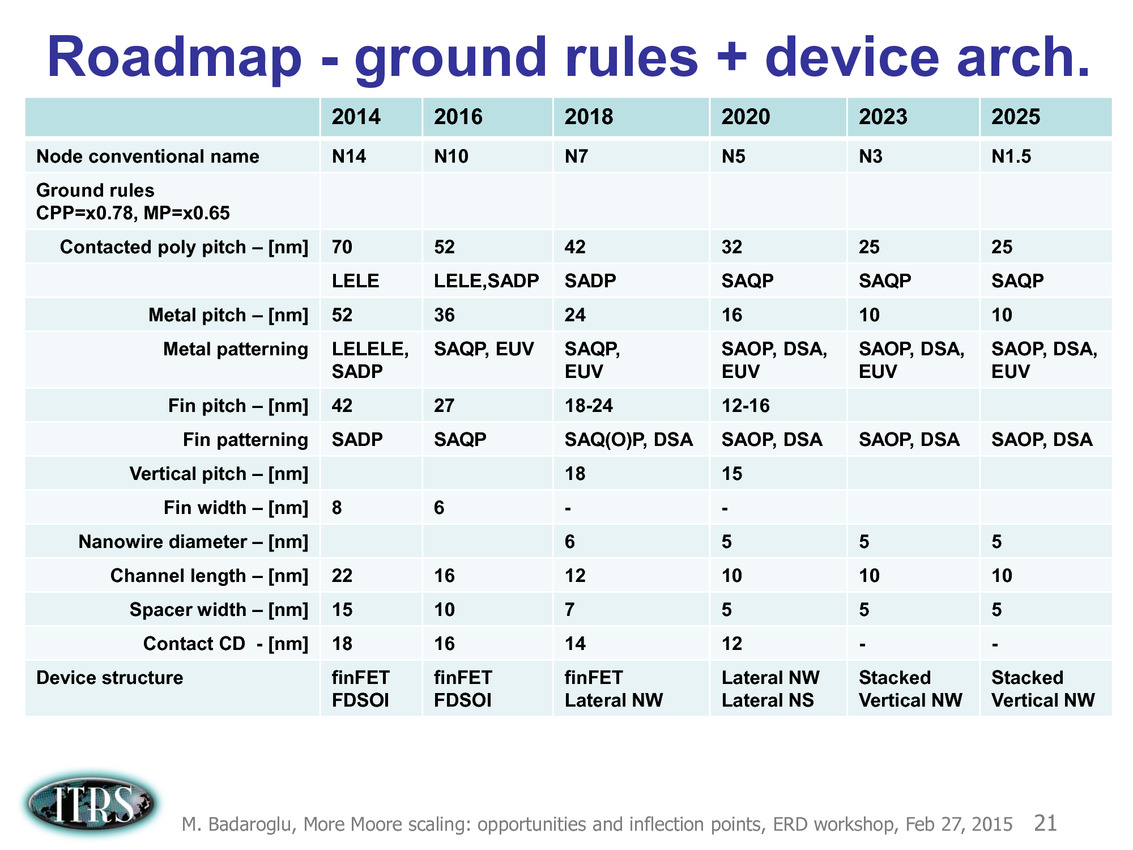
On conclura sur quelques informations données côté packaging, TSMC pense que c'est de ce côté que l'on réalisera des gains "faciles" et importants. D'abord pour la version haute performance CoWoS (Chip on Wafer on Substrate) qui consiste à utiliser un interposer en silicium pour relier des puces, le fondeur indique que l'on pourra atteindre des tailles plus importantes à 7nm dépassant les 1200mm2 (l'interposer utilisé par AMD sur les Fury X mesure un peu plus de 1000mm2) ce qui devrait donner un peu plus de marge. TSMC a également indiqué avoir réalisé le tapeout le mois dernier d'un "CPU" accompagné de deux piles de mémoire HBM2.
Côté mobile, c'est l'InFO WLP (Integrated FanOut Wafer Level Packaging) qui devrait apporter des gains intéressants. Par rapport au CoWoS, il s'agit d'une version beaucoup plus fine qui réduit voir élimine le substrat en "moulant" un ou plusieurs dies pour reconstituer un package très fin. TSMC annonce 20% de performances en plus pour une consommation 10% inférieure.
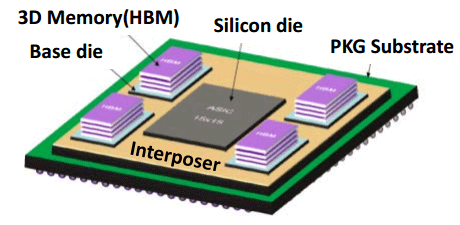
Exemple d'InFO POP
TSMC a rajouté une variante POP qui ajoute la possibilité de superposer un autre package (par exemple mémoire) par dessus un package InFO. TSMC utilise des fils dans les parties neutres du die pour relier la puce du dessus (des TIV, un concept identique aux TSV - through silicon Vias - si ce n'est que les fils traversent cette fois ci le package InFO et non un interposer). La production des InFO POP devrait débuter au second trimestre, ce qui coïncide côté timing avec le début de production attendu du prochain SoC d'Apple qui devrait utiliser ces technologies de packaging.
GDC: VR: Nvidia Multi-Res Shading en pratique
Nous avons profité de la GDC pour revenir sur une technique introduite par Nvidia il y a quelques mois pour booster les performances de la réalité virtuelle. Baptisée Multi-Resolution Shading, elle consiste à réduire la résolution au niveau des zones visuelles périphériques et donc le nombre de pixels réellement rendus. Un subterfuge plutôt convainquant en pratique.




Pour pouvoir afficher une image sur un casque de réalité virtuelle, elle doit être déformée pour permettre, avec la lentille, de proposer l'angle de vue correct. Ce procédé, appelé warping et illustré ci-dessus, implique que seul le centre de l'image conserve la pleine résolution. Les zones périphériques représentent au final moins de pixels que le GPU n'en a calculés. En d'autres termes, elles reçoivent automatiquement une dose plus ou moins élevée de supersampling alors que ce n'est pas là que se pose notre regard. Un gaspillage de ressources que Nvidia tente de réduire avec le Multi-Res Shading.

La démonstration de Nvidia permet d'activer et désactiver le Multi-Res Shading à loisir, de quoi pouvoir essayer de discerner les différences éventuelles. Et force est de constater que même en ayant conscience de l'activation de cette optimisation il est difficile d'en discerner les effets. Il faut savoir exactement où regarder et déplacer le regard vers les coins de l'image (ce que nous ne sommes pas censés faire avec un casque de VR) pour observer une légère différence.
Comme vous pouvez l'observer sur les illustrations ci-dessus, Nvidia a recours à 9 viewports de résolutions différentes. Par exemple, la résolution peut être réduite à 1/2 sur les côtés et à 1/4 dans les coins. Mais si le principe est simple, l'exécution est un peu plus complexe et profite du multi-projection engine des GPU Maxwell 2 pour projeter rapidement, en une seule passe, tous les triangles dans chacun des 9 viewports. Sans cette capacité matérielle (également exploitée pour le VXGI et le VXAO), le coût sur les performances serait important à prohibitif suivant la complexité de la scène. AMD nous a d'ailleurs confirmé que cette technique n'était pas réaliste pour ses GPU, tout en précisant essayer d'obtenir un résultat similaire via d'autres approches.
Le Multi-Res Shasing est proposé par Nvidia aux développeurs à travers le SDK VR Works mais a également été implémenté dans l'Unreal Engine il y a quelques mois et, à l'occasion de la GDC, Unity a suivi le mouvement en annonçant son intégration, avec le reste de la suite VR de Nvidia.
GDC: Zotac MAGNUS EN980 avec GTX 980 et watercooling
Zotac était présent à la GDC sur le stand de Valve pour exposer sa Steam Machine, mais également pour présenter un prototype du MAGNUS EN980, son futur mini-PC haut de gamme. Plus volumineux que les autres mini-PC de la marque (+/- 22x20x13cm), il est également bien plus véloce, notamment pour pouvoir prendre en charge la VR.





Le MAGNUS EN980 embarque en effet un Core i5-6400 mais surtout, comme son nom l'indique, une GeForce GTX 980 mobile. Pas une GTX 980M mais bien une GTX 980 mobile qui correspond à une GeForce GTX 980 desktop mais au format MXM et avec une limite de consommation plus stricte.
Pour refroidir l'ensemble CPU et GPU, Zotac a recours à un système de watercooling spécifiquement conçu pour le format du boîtier dont la partie supérieure accueille le radiateur et le ventilateur de 120mm. Ce système de watercooling est toujours à l'état de prototype et reste l'élément sur lequel Zotac a le plus de travail à effectuer. Zotac nous a par ailleurs précisé viser une limite de consommation de 150 à 175W pour la carte graphique, qui pourrait donc être très proche des 180W de la GTX 980 de bureau.
Zotac envisage également plusieurs options à d'autres niveaux, par exemple le nombre de ports USB en façade (actuellement 2 ports dont un type C) ou encore le type de mémoire supporté. Par ailleurs, le prototype est à base de DDR3L, meilleure marché, mais la DDR4 n'est pas encore exclue à ce point.
Ce mini PC sera commercialisé en tant que barebone et pourra accueillir un disque ou SSD ou format 2.5" ainsi qu'un SSD au format M.2. La tarification sera à priori haut de gamme et Zotac prévoit de présenter la version finale du MAGNUS EN980 lors du Computex qui se tiendra à Taipei du 31 mai au 4 juin.
GDC: Vers de nouveaux types de shaders ?
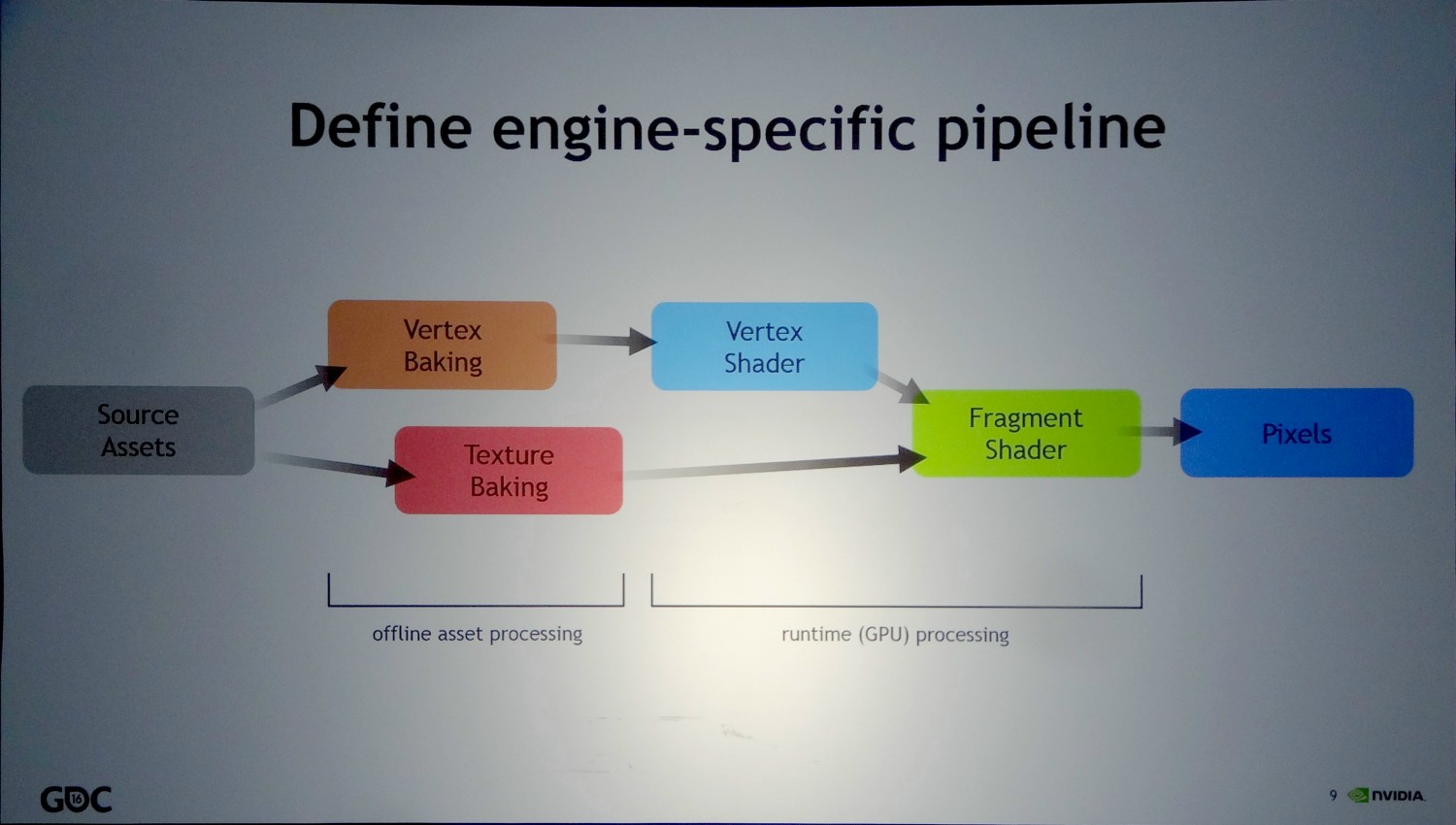
Comme vous le savez, le rendu en 3D temps réel moderne fait appel à différentes phases programmables lors desquelles sont exécutés de petits programmes appelés shaders. Après les pixel/fragment et vertex shaders qui exécutent des opérations sur les pixels/fragments et les vertices, ont été progressivement introduits les geometry shaders qui travaillent sur les primitives, les compute shaders pour du calcul plus généraliste ainsi que les hull et domain shaders dédiés à la tessellation. D'autres pourraient débarquer dans le futur.
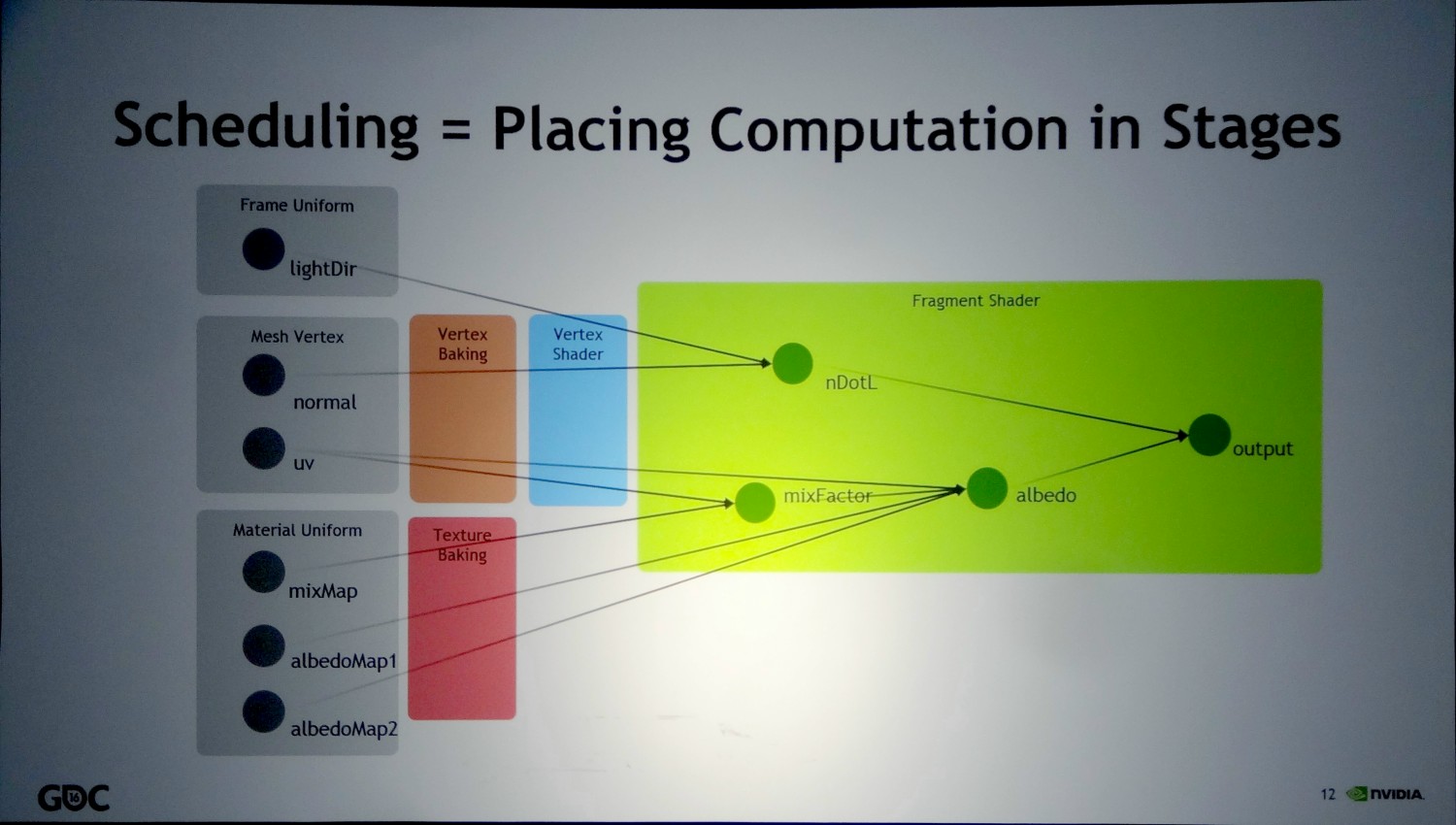
Au détour d'une présentation de Nvidia Research, une section consacrée à la programmation des shaders a attiré notre attention. Lors de celle-ci, Nvidia a encouragé les développeurs à mettre en place leurs propres outils de compilation de manière à ce qu'ils puissent répondre à leurs besoins précis, à faciliter la gestion de plusieurs niveaux de détails (LOD), à supporter différentes plateformes ainsi que de futurs pipelines de rendu qui pourraient avoir recours à de nouveaux types de shaders.

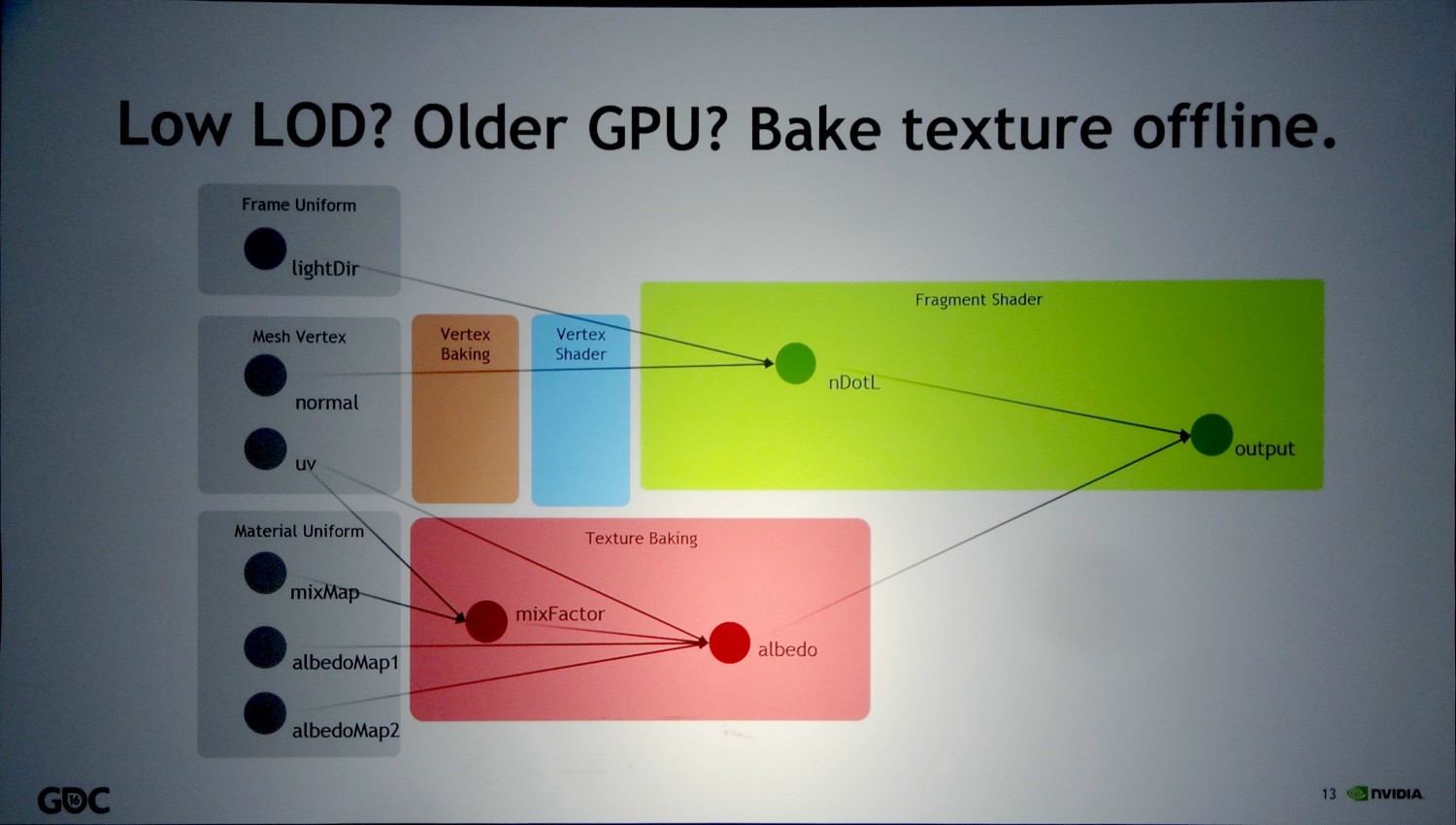
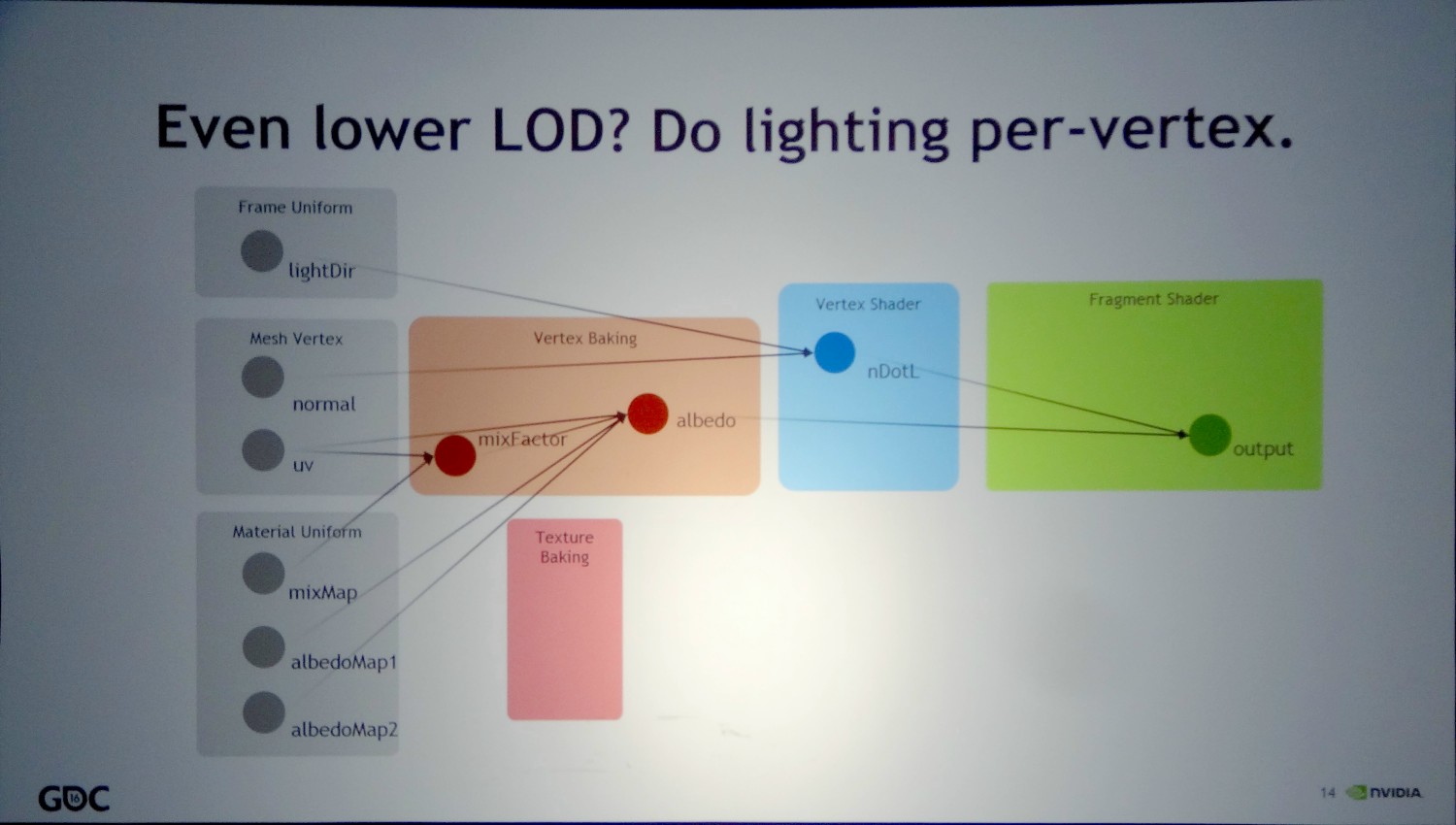
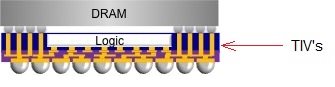
Nvidia cite deux exemples. Le premier, appelé génériquement Coarse-Rate Shader, représente différente possibilité d'exécution d'un shader dans une résolution et/ou un espace différents de ceux du framebuffer. De quoi par exemple traiter certains effets dans une résolution moindre, en appliquer dans l'espace propre aux textures ou encore en adapter au champ de vision propre à la VR. Passer par ce type de shaders intermédiaires serait plus efficace sur le plan du compromis qualité/performances que de se contenter de pixels shaders.
Le second exemple est dédié à optimiser les performances de la VR (ou de la 3D stéréo) et consisterait à scinder les pixels shaders en programmes correspondant aux tâches partagées par les deux yeux (Eye-Shared Shader) et spécifiques à chaque oeil (Per-Eye Shader). Une partie des éléments du rendu ne seraient ainsi calculés qu'une seule fois pour les deux yeux, une approximation qui pourrait offrir un résultat satisfaisant dans certains cas.
Nvidia explique que tout cela est déjà possible à travers la mise en place d'un pipeline de rendu software, c'est-à-dire à base de compute shaders. Il y a d'ailleurs pas mal d'expérimentations autour du remplacement d'une partie ou de la totalité du pipeline hardware classique par des compute shaders. Mais il est en général bien plus efficace de faire en sorte de profiter des différentes étapes non programmables du pipeline hardware ainsi que des différents mécanismes voués à rendre plus performante l'exécution de shaders spécifiques.
Nvidia précise alors que de futurs pipelines hardware pourraient proposer un support pour ces nouveaux types de shaders et conseille aux développeurs de préparer leurs outils à cet effet. Si cela ne correspond à aucune annonce spécifique, en terme de support précis ou de timing, il semble évident que Nvidia travaille déjà à la prise en charge de nouveaux types de shaders pour ses futures générations de GPU.
Vous pourrez retrouver l'intégralité de la présentation de Nvidia ci-dessous :