
Quelques détails sur Xeon Phi
Publié le 31/08/2012 à 17:14 par Guillaume Louel



Intel participait également à la conférence Hot Chips 24 (voir la présentation d'AMD), durant laquelle le constructeur a dévoilé quelques détails techniques sur Xeon Phi. Pour rappel, Xeon Phi était connu jusqu'il y a peu sous le nom de Knight's Corner, lui-même faisant suite à ce qui était le projet Larrabee (un projet d'accélérateur et de carte graphique).
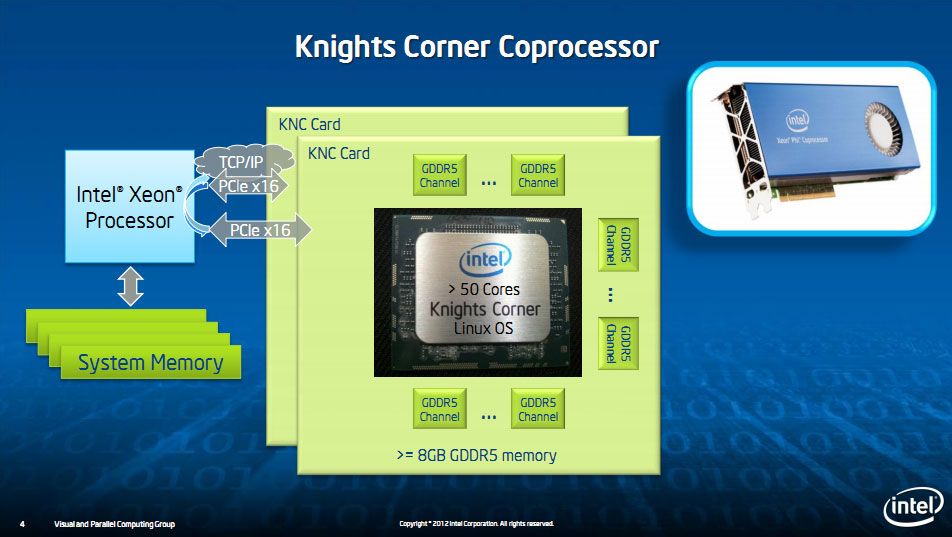
Intel caractérise Xeon Phi comme un coprocesseur destiné aux calculs massivement parallèles (le segment HPC), situé sur une carte PCI Express. D'un point de vue technique on pourrait même parler d'un système complet. Là ou les cartes graphiques et les cartes d'accélération dont elles sont dérivées (type Nvidia Tesla ou AMD FireStream) fonctionnent effectivement comme un périphérique du système principal, communiquant via le port PCI Express par des API (par exemple OpenCL), Xeon Phi se comporte comme un système indépendant. A défaut d'un simple firmware, la carte démarre son propre système d'exploitation, un Linux, sur lequel on pourra faire tourner des programmes. Un système complet, puisqu'on pourra même effectuer une session Telnet/SSH vers sa carte Xeon Phi !
Un "programme" Xeon Phi sera donc en deux parties, une (maitre) qui s'exécute sur le processeur principal, et un autre programme distinct (esclave) qui sera exécuté sur la carte. Le programme maitre pilotant à distance le programme esclave, par le biais du protocole réseau TCP/IP. Cela peut paraitre quelque peu alambiqué mais en pratique, Intel ne fait qu'imiter la manière dont se programment les clusters de serveurs (notez tout de même que le transfert du programme esclave vers la carte sera effectué automatiquement et géré par le kit de développement d'Intel, pas besoin d'envoyer manuellement son programme manuellement via SSH, même si cela reste une possibilité pour ceux qui le souhaitent).
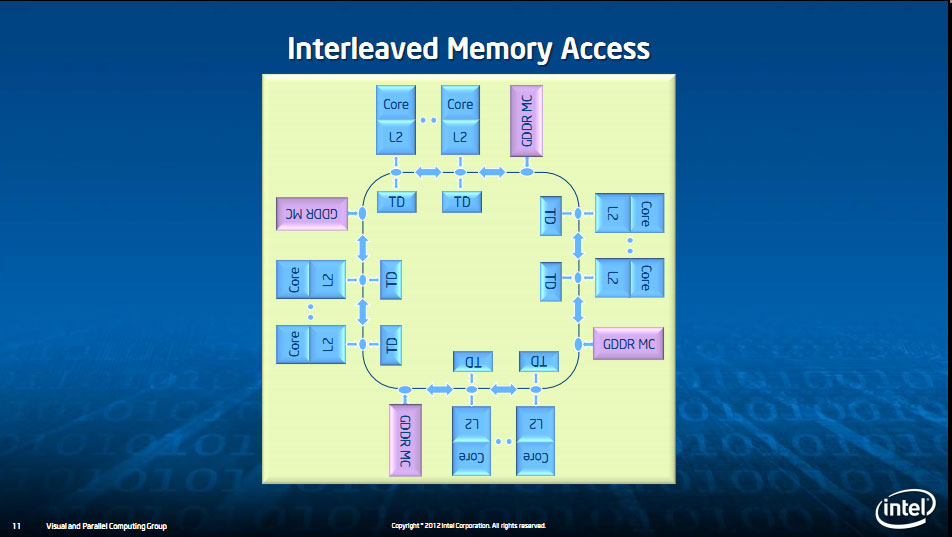
L'architecture de Xeon Phi n'est pas sans rappeler certaines puces graphiques, on retrouve en effet une série de curs (aumoins 50) disposant chacun de leur propre cache de niveau 2 (avec un Tag Directory, TD sur le schéma qui traque l'état des lignes de caches dans tous les autres L2), tous reliés autour d'un ring bus bidirectionnel (512 bits dans chaque sens effectif pour les données). Des contrôleurs mémoires sont également insérés sur le ring bus, placés de manières espacées.
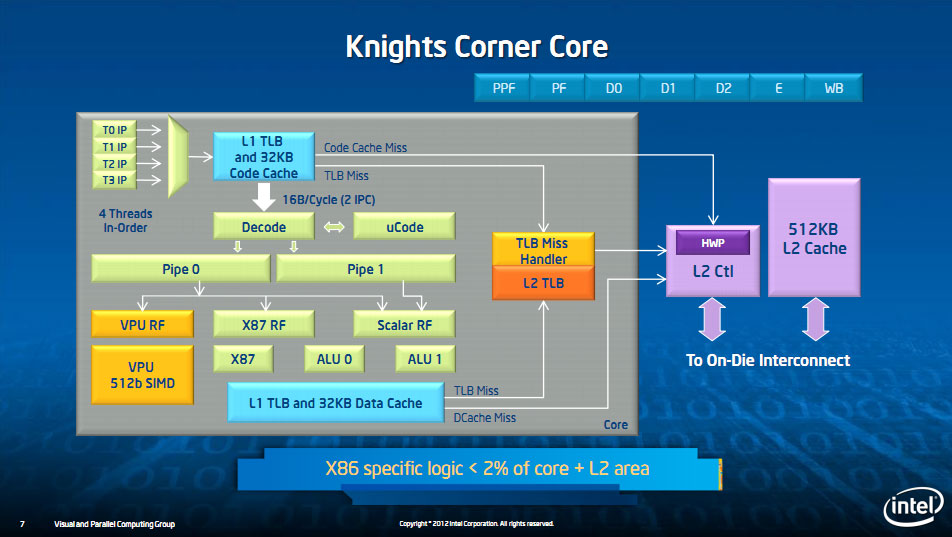
Du côté des curs, Knight's Corner continue de reposer sur un P54C (les curs in-order du Pentium) auquel on a greffé une énorme unité vectorielle 512 bits. Intel indique qu'en pratique, la partie x86 d'un core ne représente que 2% de sa surface (le reste étant utilisé par l'unité vectorielle et le cache L2 !).
Intel a effectué un grand nombre de changements par rapport à la première version de Larrabee, même s'ils ne sont pas tous détaillés. La grande majorité concerne le système mémoire, le cache L2 voit sa taille doublée de 256 à 512 Ko par cur et dispose désormais d'un TLB de 64 entrées (voir ici).
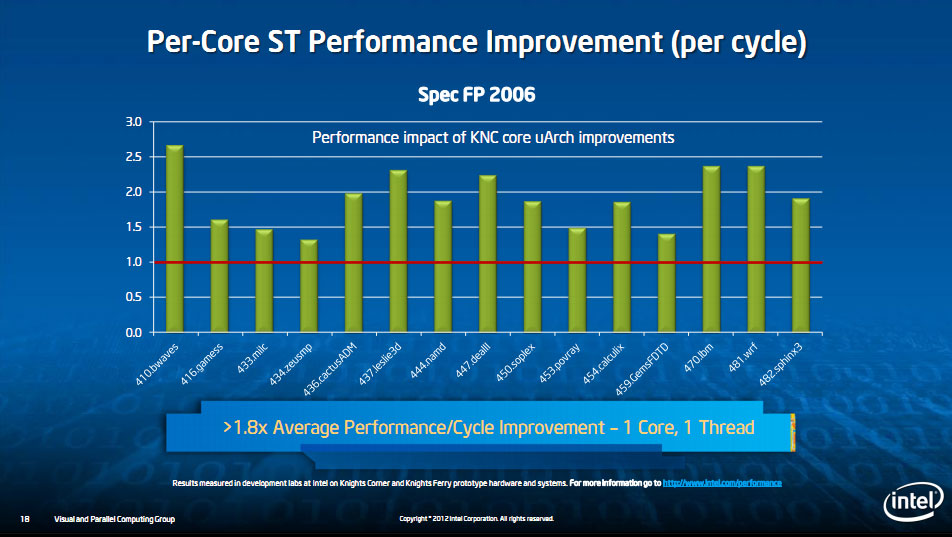
Côté performances, Intel indique avoir augmenté de 80% les performances par curs à fréquence égale par rapport à Larrabee sous SpecFP, plutôt intéressant même si le niveau de performances réel de Larrabee était inconnu, et à ce que l'on sait, en dessous des attentes du constructeur. Intel indique également avoir particulièrement optimisé l'aspect consommation avec la possibilité pour l'hôte de forcer un mode "Package C6" pour minimiser au maximum la consommation, le processeur hôte devant alors redémarrer la carte lorsqu'il souhaite l'utiliser de nouveau. Un avantage intéressant qu'il faudra mesurer en pratique. Intel insiste beaucoup sur l'aspect consommation, le constructeur mettant en avant le fait qu'il dispose d'un node d'avance au minimum (22nm) avec les solutions concurrentes.
Pour le reste des détails techniques - il manque par exemple le nombre total de contrôleurs mémoires - il faudra attendre encore un peu. La pile de développement logicielle jouera également un rôle extrêmement important. Intel met en avant la flexibilité apportée par les curs x86 par rapport aux solutions propriétaires de ses concurrents et la possibilité de compiler très facilement un code existant pour le faire tourner sur Xeon Phi. Arriver à exploiter correctement les unités 512 bits étant le vrai cur du problème. Sur ce point, il est probable que la marque en dévoile plus dans deux semaines lors son Intel Developer Forum qui se tiendra à San Francisco du 11 au 13 septembre, les coprocesseurs Xeon Phi devant être lancés avant la fin de l'année.
Vos réactions
Contenus relatifs
- [+] 27/04: Xeon Platinum pour accompagner les ...
- [+] 22/08: HMC, DDR5 et 3D XPoint pour Micron
- [+] 17/11: 76 coeurs sur le die de Knights Lan...
- [+] 24/06: Micron en charge de la mémoire des ...
- [+] 26/11: Des détails sur les (monstrueux) Xe...
- [+] 24/07: Intel dévoile l'AVX-512
- [+] 04/07: AVX3 et PCI Express 4.0 chez Intel
- [+] 26/03: GTC: Les Tesla K20X dans le Piz Dai...
- [+] 12/11: Intel lance les Xeon Phi 5110P
- [+] 08/11: Cray XC30 avec processeurs Intel