
Actualités informatiques du 12-08-2014
- Intel désactive TSX suite à un bug
- AMD annonce 4 FirePro Wx100, dont la W7100
- Intel précise son process 14nm
- AMD dévoile le GPU milieu de gamme Tonga
- FreeSync limité sur GCN 1.0
- Intel Broadwell : +5% d'IPC et TDP de 5 watts
| Août 2014 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Intel désactive TSX suite à un bug



TechReport rapporte qu'Intel va déployer via de nouveaux firmware pour les cartes mères un nouveau microcode pour les processeurs Haswell visant à désactiver les instructions TSX que nous avions décrites ici.

Un développeur a en effet remonté à Intel un bug dans l'implémentation TSX au sein de Haswell pouvant entraîner des "défaillances logicielles critique". Ce bug a été confirmé par Intel qui n'a donc que d'autre choix de désactiver TSX.
Les premiers processeurs Broadwell seront également concernés par ce bug et auront donc le TSX désactivé en attendant un prochain stepping en cours de développement. Ce sera également le cas sur les Haswell-E/EP qui seront prochainement lancés sur la gamme Xeon, ce qui est assez dommageable vu que l'utilité de TSX se situe dans le monde professionnel. Selon AnandTech , Intel recommande dans ce cas d'attendre Haswell-EX, ce qui sous entend qu'aucun stepping correctif n'est prévu pour Haswell-E et qu'il faudra donc attendre Broadwell-E/EP dans un an pour disposer d'un correctif sur cette gamme de puce.
AMD annonce 4 FirePro Wx100, dont la W7100
Après les FirePro W9100 et W8100 en haut de gamme, AMD profite du Siggraph pour compléter la famille avec l'ajout de 4 nouveaux modèles.

La nouveauté la plus intéressante est la FirePro W7100 qui embarque un nouveau GPU nommé Tonga que nous venons de décrire ici sur base des premières informations disponibles. Comme pour l'ensemble des autres solutions annoncées aujourd'hui, AMD ne communique pas les spécifications exactes. Contrairement aux FirePro W9100 et W8100 dont c'est le point fort, le reste de la gamme n'est pas adapté au calcul en double précision.



La FirePro W7100 embarque donc un GPU Tonga interfacé en 256-bit. Il est équipé de 4 processeurs géométriques et de 1792 unités de calcul, de quoi atteindre 3.5 Tflops s'il est cadencé à 1 GHz, fréquence estimée mais non précisée par AMD. Ses 8 Go de GDDR5 sont par contre annoncés à 1250 MHz pour une bande passante de 160 Go/s ou 149 Gio/s. Par rapport à la FirePro W7000, dont le GPU Pitcairn affiche 2 triangles par cycle, 2.4 Tflops et 153.6 Go/s au compteur, la puissance de calcul et le débit des triangles progressent nettement. AMD met également en avant le passage de 4 à 8 Go et l'exploitation d'un moteur vidéo plus performant capable d'encoder en 1080p à plus de 300 fps. Au niveau des sorties, AMD a opté pour 4 DP 1.2 mais le GPU est capable de prendre en charge jusqu'à 6 écrans si un hub est exploité. Au niveau des écrans 4K, jusqu'à 3 pourront être exploités en SST 60 Hz.

Plus bas dans la gamme, la FirePro W5100 passe au GPU Bonaire alors que la W5000 était équipée d'un GPU Pitcairn fortement castré. Le nombre d'unité de calcul et le bus mémoire restent identiques mais la fréquence GPU progresse quelque peu, ce qui permet de passer de 1.3 à 1.4 Tflops. Bonaire se contente d'un bus mémoire de 128-bit contre 256-bit pour Pitcairn et la W5000, mais les 4 Go de mémoire GDDR5 de la W5100 passent par contre de 800 à 1500 MHz, ce qui permet d'afficher une bande passante presque identique (96 Go/s contre 102.4 Go/s). La FirePro propose 4 sorties DP 1.2 mais est capable de prendre en charge jusqu'à 6 écrans si un hub est exploité.


L'entrée de gamme passe enfin à la génération GCN avec les FirePro W4100 et W2100 qui remplacent avantageusement les très vieillissantes V3900 et V4900. La FirePro W4100 embarque un GPU Cape Verde équipé de 512 unités de calcul et associé à 2 Go de GDDR5 interfacés en 128-bit. Pour sa part, la FirePro W2100 repose sur le GPU Oland avec 384 unités de calcul et 2 Go de mémoire en 64-bit. La FirePro W4100 propose 4 sorties DP 1.2 alors que la FirePro W2100 s'en contente de 2.
La disponibilité des FirePro W5100, W4100 et W2100 est annoncée pour la rentrée alors qu'il faudra attendre un petit peu plus longtemps, probablement le 4ème trimestre, pour la FirePro W7100. A ce jour, AMD n'a communiqué aucun tarif pour ces cartes.
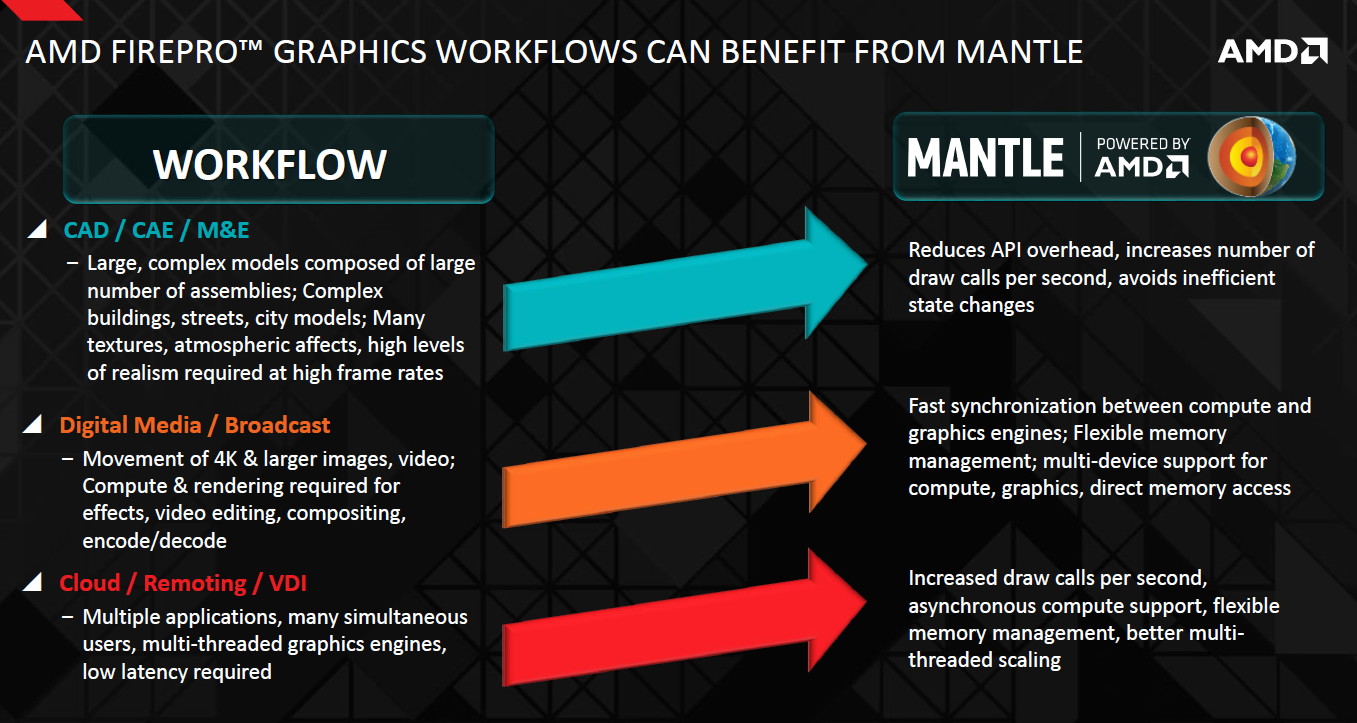
Enfin, AMD indique avoir entrepris les premières démarches en vue de l'exploitation de Mantle dans le domaine professionnel qui pourrait bien entendu profiter de cette API de bas niveau pour réduire le coût CPU, rendre la cohabitation des tâches de types graphique et calcul plus efficace et optimiser la gestion de la mémoire. Reste à voir si cette initiative se concrétisera
Intel précise son process 14nm
En marge de son annonce sur Broadwell-Y, Intel a partagé quelques détails sur son process 14nm. Comme vous le savez, le process 14nm d'Intel souffre de retards. Le constructeur avait annoncé qu'il décalerait la mise en production d'un trimestre en novembre dernier, tout en publiant des indications autour de ses yields qui laissaient entendre un retard de 6 mois.
En pratique, il est difficile de mesurer réellement le retard du process même si Intel a partagé ce nouveau graphique de yields :
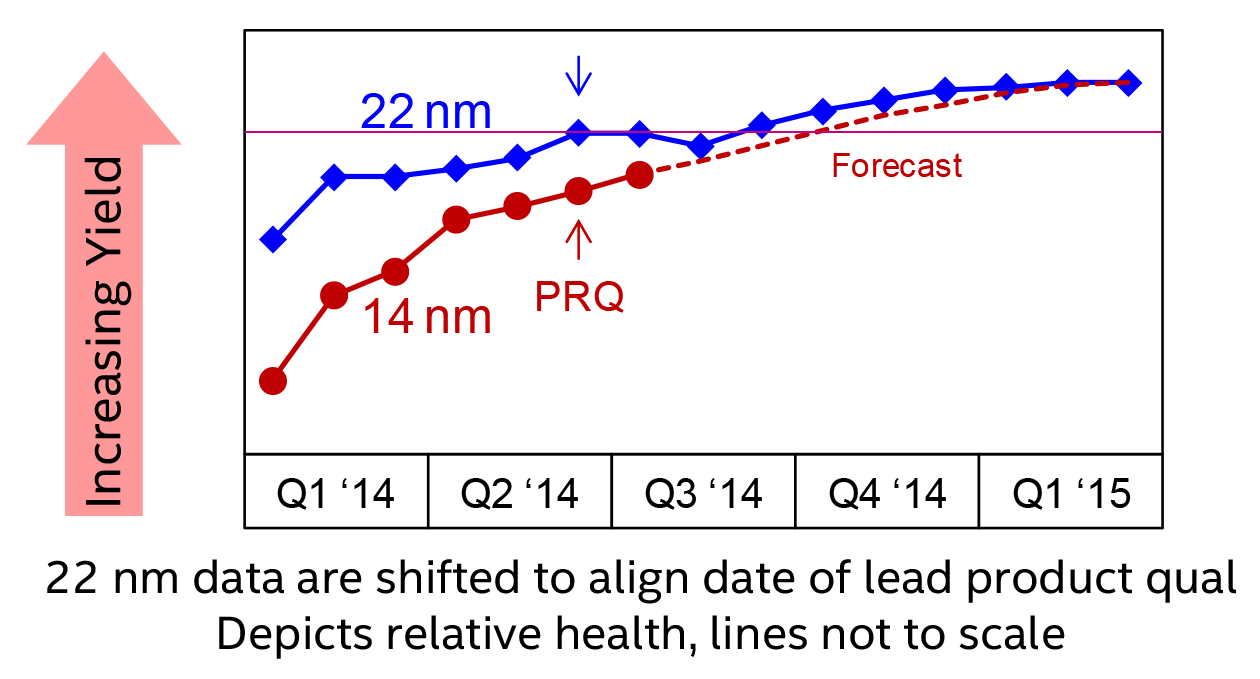
Plusieurs choses à voir sur ce graph, d'abord, si vous vous souvenez du dernier graphique de yields présenté par Intel, celui-ci diffère fortement. Là où le premier était aligné par rapport au début du développement du process, les graphiques sont désormais alignés sur la qualification du premier produit (Ivy Bridge en 22nm, Broadwell-Y en 14nm), étape préalable à la mise en production. Intel indique sur ce graphique que la qualification de Broadwell-Y a eu lieu en fin de second trimestre et qu'il est actuellement en production en volume. Si l'on ne connait pas la date précise de qualification d'Ivy Bridge, on sait que la production en volume avait débuté au troisième trimestre 2011, ce qui met donc au minimum deux ans et neuf mois entre la mise en production en volume du 22nm et celle du 14nm.
L'autre point le plus important concerne (on passera sur l'échelle absente une fois de plus) l'écart de yields entre la mise en production d'Ivy Bridge et celle de Broadwell-Y. Le constructeur a choisi, comme nous le supposions en novembre dernier, de lancer la production avec des niveaux de yields inférieurs. En pratique, le décalage de yields pour la mise en production, si l'on prend en compte la prédiction pour les prochains mois est de quatre mois (voir la ligne violette que nous avons rajouté au graphique). Ce qui ne signifie pas quatre mois de retard pour ce process rappelez-vous que les graphiques ne sont plus alignés ! mais qu'Intel a anticipé la mise en production de quatre mois par rapport à celle d'Ivy Bridge. Il est probable que, plus que le niveau de yields, ce soit une date butoir qui ait été utilisée pour déterminer la mise en production afin de s'assurer qu'un produit soit « livré » cette année.
En soit, ce choix est logique : le constructeur peut ainsi proposer un peu plus tôt des produits quitte à sacrifier sur ses marges, tout en honorant - on l'imagine - des contrats auprès de ses partenaires et en pouvant montrer aux investisseurs qu'un produit en 14nm a bel et bien été lancé en 2014. En pratique, si Intel pourra effectivement « lancer » un premier produit cette année, le gros du volume en 14nm devra attendre. Le constructeur ne le cache pas en indiquant que ses yields devraient être acceptables au premier semestre 2015 pour la production en volume de produits vendus en plus larges quantités que les Broadwell-Y.
Intel est également revenu sur la compétition en proposant une nouvelle version de son graphique à propos de la densité qui avait largement fait débat :

Cette fois ci, le constructeur mélange IBM et TSMC parmi ses concurrents, et met de côté Samsung (pour rappel, Samsung et GlobalFoundries ont annoncé un partenariat sur le 14nm autour du process 14nm développé par Samsung, hors de la Common Platform l'alliance qui liait Samsung et GlobalFoundries à IBM). Le constructeur a le mérite d'indiquer la formule qu'il utilise pour mesurer la densité ce qui n'était pas le cas auparavant.
La densité des puces est un sujet pour le moins complexe et si la formule annoncée par Intel (gate pitch l'écart entre deux transistors multiplié par metal pitch l'écart de la couche métallique la plus basse qui sert à l'interconnexion des transistors) est correcte, elle ne prend en compte qu'en partie la question de la densité.
Intel a par exemple toujours été en retard sur ses concurrents sur la question du metal pitch. Le 22nm d'Intel disposait d'un metal pitch de 90nm tout comme le 28nm de TSMC. En pratique, pour le 14/16nm, voici les chiffres qui sont annoncés :
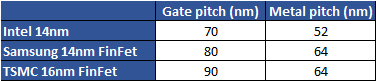
C'est sur cette formule (90x64 comparé à 70x52) qu'Intel annonçait un gain de 35% par rapport à TSMC. Bien sur, la densité finale d'une puce ne dépend pas que de cette formule, les règles de design, la taille des SRAM, et d'autres facteurs jouent de manière importante sur la densité « réelle » de transistors obtenus au mm2 sur une puce, la formule metal pitch x gate pitch n'indiquant que le cas « idéal ». C'est sur ces autres facteurs que TSMC estime gagner 15% de densité « réelle » au total entre son process 20 et 16nm. Si l'on ne peut pas reprocher à Intel de choisir la formule qui l'arrange le plus pour mettre ses produits en avant, on peut apprécier que cette fois ci, la formule choisie soit au moins précisée !
On notera par contre qu'Intel continue d'ignorer Samsung qui devrait pourtant être son plus sérieux concurrent sur le 14nm. Samsung pour rappel avait annoncé une production en volume de son process 14nm pour la fin de l'année 2014.
Sur le papier et comme indiqué plus tôt, le process d'Intel semble être supérieur aux autres process 16/14nm de première génération annoncés (on se souviendra que et TSMC, et Samsung ont annoncés une seconde version de leurs process), en partie par le choix fait d'obtenir une réduction forte sur la taille des interconnections atteignant un metal pitch de 52nm qui sera en avance pour la première fois depuis plusieurs process sur ce que proposeront ses concurrents.
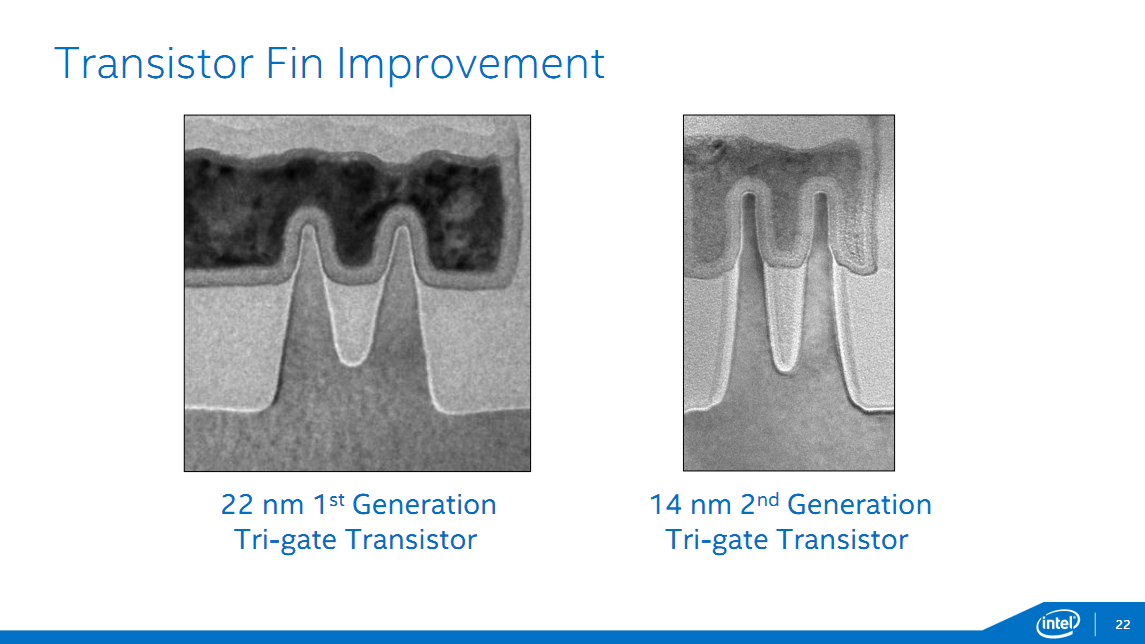
Il s'agira également de la seconde génération de FinFet pour Intel. Outre l'apprentissage effectué par le premier, on peut noter sur les photos fournies par le constructeur quelques changements dans la forme des Fin. Là ou en 22nm les gates avaient une forme trapézoidale, les fins ont désormais une forme rectangulaire plus proche de la forme idéale attendue. On se souviendra qu'IBM et la Common Platform avaient soulevés les questions de forme et de variabilité du process d'Intel :
Il sera intéressant de voir si Samsung (et TSMC) aura comme le laissait entendre IBM à l'époque appris de la première version du process d'Intel.
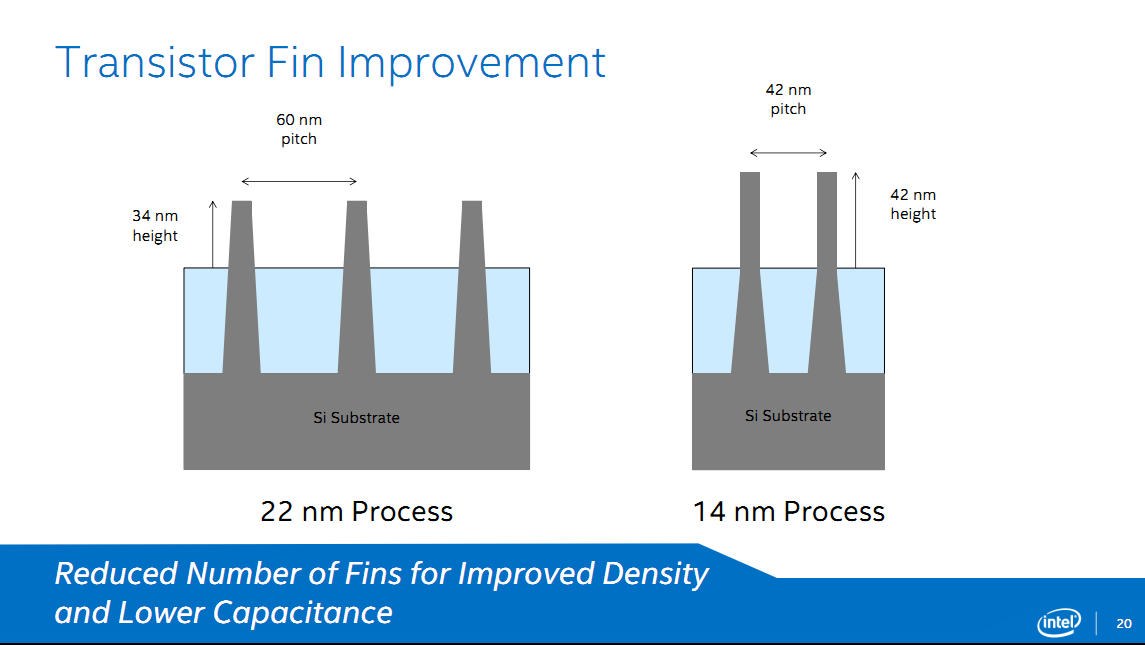
On notera également une augmentation de la hauteur des fins (de 34nm à 42nm) qui devrait permettre une amélioration des performances, quelque chose qui devrait être très utile notamment sur les usages SoC pour limiter la consommation. Si Intel ne donne pas de chiffre de performances concernant les transistors, le constructeur donne quelques chiffres concernant Broadwell-Y. Sur cette puce, et par rapport à son équivalent Haswell, les courants de fuites seraient réduits par deux, avec un rapport performance par watt de 2x.
Pour résumer, Intel semble avoir fortement optimisé son process pour les usages mobiles qui sont aujourd'hui les marchés les plus porteurs (qu'il s'agisse des PC portables ou des tablettes/smartphones) et il sera intéressant de voir comment les gains (forts) annoncés sur Broadwell-Y se traduiront sur le reste des produits 14nm du constructeur. Si le retard d'Intel dans la mise au point de son process est conséquent, et que le lancement de Broadwell-Y se fait dans des conditions non optimales (yields plus faibles qu'attendus, et produits à fort volumes repoussés en 2015), le constructeur semble disposer sur le papier d'un process solide et ambitieux, qui semble corriger les problèmes de sa première génération FinFet. Reste que les délais dans sa mise au point ont permis à la concurrence de se rapprocher - au moins dans les annonces avec un Samsung qui devrait être particulièrement agressif. L'avantage technique apporté par ses process de fabrication reste toujours réel et important pour Intel, et sur le papier son 14nm devrait permettre à Broadwell-Y des avancées notables. Mais la domination d'Intel sur le sujet des process ne semble plus - si l'on s'en tient aux annonces respectives des uns des autres - aussi hégémonique qu'elle le fut ces dernières années.
AMD dévoile le GPU milieu de gamme Tonga
C'est d'une manière inhabituelle, à travers le lancement d'une FirePro, qu'AMD vient de dévoiler un nouveau GPU : Tonga. Ce dernier, toujours fabriqué en 28nm, est destiné à remplacer à terme le GPU Tahiti avec une organisation interne remise au goût du jour, en "GCN 1.1" ou supérieure, et plus en accord avec son positionnement milieu de gamme.

En dehors des spécifications très basiques, AMD n'a communiqué que très peu de détails si ce n'est le passage à un débit géométrique de 4 triangles par cycle et l'intégration d'un moteur vidéo boosté. De quoi doubler les performances en tessellation par exemple, pour atteindre un même niveau que le plus gros GPU de la famille, Hawaii (R9 290). De toute évidence, AMD en a profité pour mettre à jour le processeur de commandes du GPU de manière à offrir le même niveau de fonctionnalités que celui de Bonaire et Hawaii avec notamment l'inclusion de 8 ACE pour gérer plusieurs flux de commandes en parallèle. Par ailleurs, l'absence de connecteur CrossFire pointe vers le support de la technologie XDMA introduite pour le multi-GPU avec Hawaii.

Le moteur vidéo maison, VCE, a été boosté. Il est désormais annoncé comme capable d'encoder du 1080p à 315 fps, soit à peu près 13x le débit nécessaire à l'encodage en temps réel en 24 fps. Le DPS audio TrueAudio est bien entendu intégré également.
La FirePro W7100 qui embarque le GPU Tonga est équipée de 1792 unités de calcul, ce qui correspond à 28 Compute Units, comme pour la version castrée du GPU Tahiti qui équipe les Radeon HD 7950 et R9 280. Il n'est cependant pas impossible que Tonga embarque quelques CU de plus. Par exemple 32 CU au total ? L'ensemble doit cependant se contenter d'un bus mémoire de 256-bit, contre 384-bit pour Tahiti, un point qui semble être le plus gros compromis fait par AMD pour réduire les coûts. Voici, sur base des informations actuelles et de suppositions logiques pour Tonga, un résumé de tous les GPU de la famille GCN :
Oland : GCN 1.0, 6 CU, 1 triangle par cycle, 8 ROP, L2 256 Ko, 128 bits
Cape Verde : GCN 1.0, 10 CU, 1 triangle par cycle, 16 ROP, L2 512 Ko, 128 bits
Bonaire : GCN 1.1, 14 CU, 2 triangles par cycle, 16 ROP, L2 512 Ko, 128 bits
Pitcairn : GCN 1.0, 20 CU, 2 triangles par cycle, 32 ROP, L2 512 Ko, 256 bits
Tonga : GCN 1.1, 28 ou 32 CU, 4 triangles par cycle, 32 ROP, L2 512 ou 1024 Ko, 256 bits
Tahiti : GCN 1.0, 32 CU, 2 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
Hawaii : GCN 1.1, 44 CU, 4 triangles par cycle, 64 ROP, L2 1024 Ko, 512 bits
Et en image pour les plus gros d'entre eux (dans le cas de Tonga nous avons représenté la possibilité qu'il intègre physiquement 28 CU ou 32 CU) :
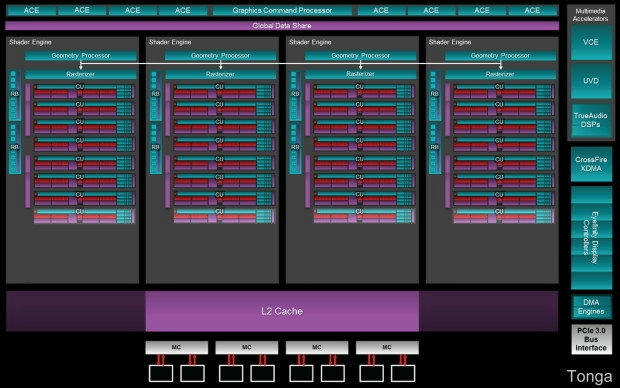
[ Bonaire ] [ Pitcairn ] [ Tahiti ] [ Tonga ] [ Hawaii ]
AMD ne devrait de toute évidence plus tarder à annoncer une ou plusieurs Radeon équipée(s) de ce nouveau GPU Tonga (R9 285 ?). Si le GPU est lancé aujourd'hui en version FirePro, c'est d'une part parce que la disponibilité de celle-ci ne sera probablement pas immédiate et d'autre part probablement parce qu'AMD préfère ne pas se précipiter et écouler calmement les stocks des GPU Tahiti / Pitcairn qui sont voués à disparaître alors que Tonga devrait survivre lors du passage à la famille Radeon 300.
FreeSync limité sur GCN 1.0
Alors que le premier écran "nativement" G-Sync, l'onéreux ASUS ROG Swift PG278Q, a fait son apparition en boutique en début de mois, AMD a mis en ligne une FAQ consacrée à son projet FreeSync utilisant la norme VESA Adaptive-Sync.
Elle apporte notamment des précisions par rapport au support côté carte graphique que nous avions déjà évoqué dans une actualité précédente. Ainsi, seuls les GPU de type "GCN 1.1" seront pleinement compatibles avec FreeSync, à savoir les Radeon R9 290X, 290, R7 260X et 260, ainsi que les APU Kaveri, Kabini, Temash, Beema et Mullins. Les GPU antérieurs en GCN 1.0 devront pour leur part se contenter de FreeSync durant la lecture vidéo ou pour l'aspect économie d'énergie (lors des phases inactives sur le bureau).
Du côté de la disponibilité des écrans, AMD avait indiqué en mai prévoir leur arrivée dans 6 à 12 mois. AMD vise désormais une arrivée dans l'intervalle 4è trimestre 2014 / 1er trimestre 2015.
Intel Broadwell : +5% d'IPC et TDP de 5 watts
Intel a livré des détails supplémentaires sur son architecture Broadwell et les processeurs Core M qui seront les premiers à en bénéficier d'ici à la fin de l'année.
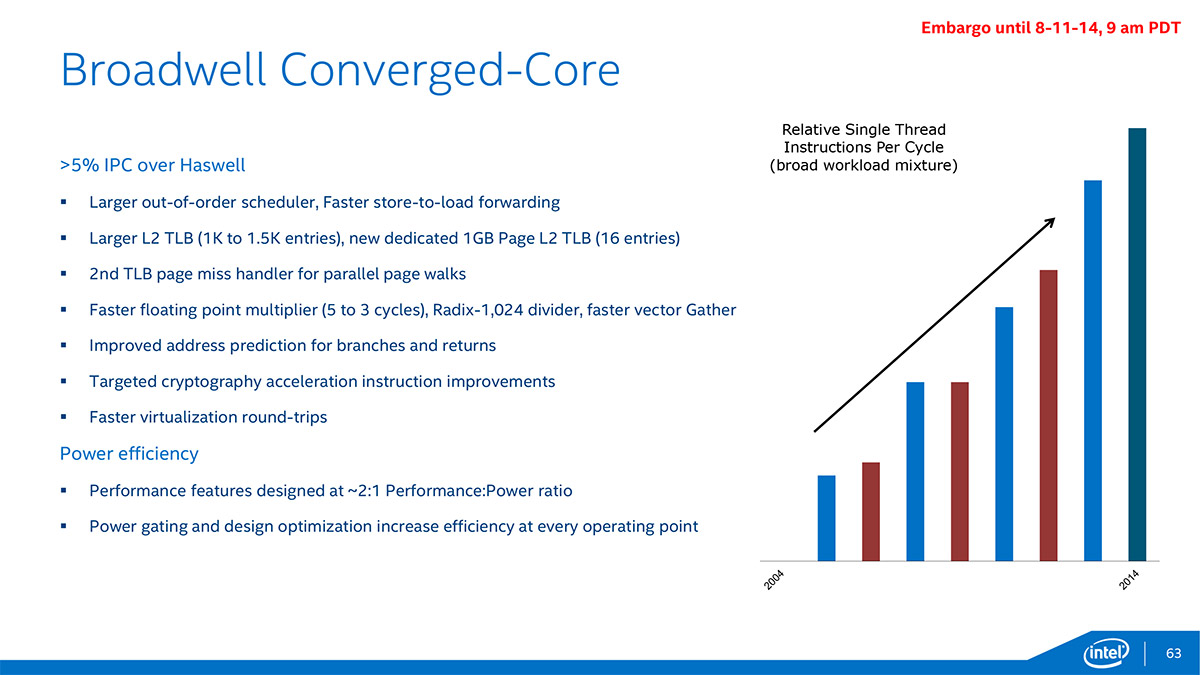
Côté architectural tout d'abord, Intel a détaillé les diverses améliorations intégrées lui permettant au final d'annoncer une hausse d'IPC supérieur à 5% par rapport à Haswell. Comme souvent, la prédiction de branchement a été améliorée, tout comme le TLB mais aussi la multiplication en virgule flottante ou encore la division. Intel précise que ces améliorations ont été introduites sur la base d'un rapport Performance:Puissance de 2:1, c'est-à-dire qu'un gain de 2% de performance ne devait pas entraîner plus d'1% de hausse de consommation, contre 1:1 pour les améliorations intégrées dans Haswell.
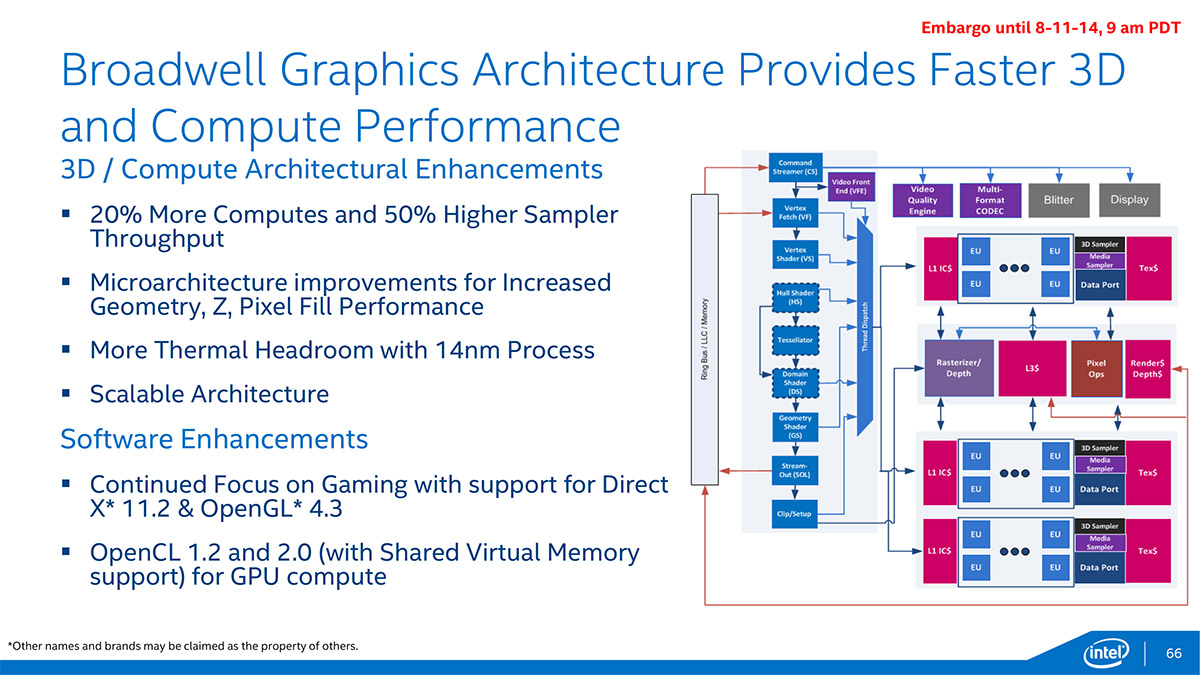
L'iGPU a également droit à ses améliorations, avec 20% d'unités d'exécutions mais aussi 50% d'unités de texturing supplémentaire. Intel saupoudre par-dessus des améliorations micro architecturales qui devraient permettre une efficacité accrue, pour peu que l'iGPU ne soit bien sûr pas limité par la bande passante mémoire.
Concernant le Core M, il s'agit de Broadwell-Y c'est-à-dire une version intégrant au sein d'un même packaging un Broadwell 2 curs 14nm, un HD Graphics avec 24 EUs ainsi que le chipset Broadwell PCH-LP, qui reste lui gravé en 32nm mais avec des optimisations permettant de réduire sa consommation au repos de 25% et en charge de 20%.

Pour cette déclinaison de Broadwell, Intel vise clairement la basse consommation via son process 14nm et met même en avant son intégration au sein de tablettes fanless d'une épaisseur de 9mm. Il est question d'une réduction supérieur à 2x du TDP, malgré un niveau de performance supérieur, vis-à-vis de Haswell-Y dont le TDP est de 11.5 watts et par ailleurs Intel indique qu'il faut atteindre les 5 watts pour son objectif fanless dès lors le TDP des Core M les plus économes, si il n'est pas mentionné, semble clairement de 5 watts.


Toujours dans le but d'une intégration plus poussée, Intel a nettement réduit la taille de la puce. Au niveau du die tout d'abord, cette version de Broadwell fait 0.63x son équivalent Haswell grâce au passage en 14nm et malgré les fonctionnalités supplémentaires (on serait à 0.51x sans ces dernières). Mais le packaging a également été amélioré puisqu'un Broadwell-Y mesure 30x16.5x1.04mm, contre 40x24x1.5mm pour un Haswell-Y. La surface est donc quasiment divisée par 2, alors que la hauteur est réduite de 30%. Selon Intel il serait possible de faire des cartes mères 25% plus petites avec Broadwell-Y.
Voilà donc des avancées qui semblent prometteuses sur le papier pour Broadwell-Y. Reste à savoir si elles permettront à Intel de percer sur les marchés qui seront désormais ouvert à la gamme Core, et si le 14nm se montrera aussi efficace lorsqu'il sera décliné sur des puces plus performantes. Pour celles-ci il faudra malheureusement attendre l'an prochain !