Actualités informatiques du 09-07-2015
- OCZ annonce les SSD Trion 100
- Phanteks lance l'Enthoo Pro M
- Premières puces en 7nm pour IBM !
- Pilotes AMD Catalyst 15.7 WHQL
- AMD lance la FirePro S9170: Hawaii et 32 Go
| Juillet 2015 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||
OCZ annonce les SSD Trion 100



La marque de SSD OCZ, qui appartient désormais à Toshiba, vient d'annoncer le lancement d'une nouvelle série de SSD destinés à l'entrée de gamme, les Trion 100. D'après nos confrères d'Anandtech qui ont pu s'entretenir avec le constructeur, le design a été entièrement conçu chez Toshiba, OCZ n'étant intervenu que sur la fin pour les étapes de validation. Aucun ingénieur firmware d'OCZ ne serait intervenu à ce que disent nos confrères. Il s'agit donc clairement d'une nouvelle étape dans les relations entre OCZ et sa maison mère, l'avenir nous dira si il s'agit uniquement d'un effet d'aubaine ou d'une volonté de prendre la main sur la partie la plus critique du développement des SSD.

A l'intérieur, on retrouvera sans surprise de la mémoire NAND Toshiba A19nm 128 Gbit (16 dies par package), de type TLC, entrée de gamme oblige ! Pour le contrôleur, exit les Indilinx, il s'agit d'un contrôleur marqué Toshiba qui serait très probablement, selon nos confrères, un Phison S10 avec un firmware possiblement customisé par Toshiba.
Quatre capacités sont annoncées 120, 240, 480 et 960 Go, voici les performances théoriques annoncées, en notant que le constructeur utilise une partie (4.5% en TLC soit 1.5% en SLC) de sa mémoire NAND comme de la SLC afin d'améliorer les performances théoriques :
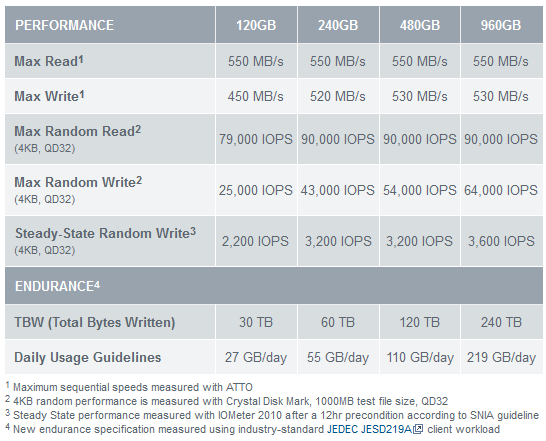
En pratique les performances constatées par nos confrères semblent cependant en retrait, y compris par rapport aux autres modèles d'entrée de gamme existant, avec notamment moins de 150 Mo/s en ecriture une fois le petit cache SLC remplit sur la version 480 Go. OCZ essaye donc de se démarquer avec des prix annoncés agressifs, respectivement 55, 85, 175 et 310 euros environ. Malgré la garantie ShieldPlus de 3 ans (prise en charge des frais de retout et envoi anticipé du SSD) cela risque de ne pas suffire pour convaincre.
Phanteks lance l'Enthoo Pro M
Après son modèle haut de gamme Primo et un modèle ITX, la marque Phanteks, plutôt connue pour ses ventirads, continue d'étendre sa gamme de boitiers avec cet Enthoo Pro M. De type moyen tour, il mesure 235 x 480 x 500 mm (L x H x P) pour un poids de 7.4 kg. A l'intérieur on pourra fixer une carte mère ATX, voir une E-ATX courte puisqu'il autorise jusqu'à 26.4 cm de largeur pour la carte mère (pour rappel, l'ATX est à 24.4 et l'E-ATX pleine taille à 33 cm). Côté stockage par défaut on pourra fixer deux disques durs 3.5 pouces dans le bas du boitier, fixés dans des cages amovibles dans le sens de la largeur, ainsi qu'un slot 2.5 pouces. Au total le boitier accepte (via l'ajout de cages supplémentaires) huit disques 3.5 pouces et trois disques 2.5 pouces.
Côté refroidissement il est fourni avec un ventilateur 140mm à l'arrière (PH-F140SP). En pratique il peut accueillir en prime deux 140mm à l'avant (ou trois 120mm en sacrifiant la cage pour lecteur optique) et deux 140mm sur le dessus (ou trois 120mm). On pourra préférer mettre à ces emplacements des radiateurs pour watercooling, jusque 360mm pour les modèles de 120 de large, et jusque 280mm pour les 140 de large.








Côté carte graphique on tiendra jusque 420mm de longueur sans cage disque durs en face, et 300mm si l'on en installe une. On pourra aller jusqu'à 318mm pour les alimentations également, et 19.4cm de hauteur pour les ventilateurs processeurs. Pour le reste on retrouvera trois filtres à poussière (avant, arrière, haut) ainsi que le système de gestion de câble du constructeur.
Vous pourrez retrouver plus de détails sur le site du constructeur, comptez 80 euros environ pour ce boitier qui devrait être disponible vers la fin du mois de juillet.
Premières puces en 7nm pour IBM !
Alors qu'IBM a revendu son activité fabrication de semi-conducteurs à Global Foundries en octobre dernier (un rachat qui s'est finalisé le premier juillet de cette année), IBM vient annoncer avoir produit une puce de test fonctionnelle en 7nm, une première que rapportent nos confrères d'EETimes .
Si IBM réalise l'annonce, en pratique la puce a été fabriquée dans un centre de recherche du SUNY Polytechnic Institute financé en partie par l'état de New York et divers partenariats privés. Virtuellement toutes les sociétés du milieu participent puisque l'on retrouve dans la liste des sociétés, outre IBM, Intel, TSMC, Samsung, GlobalFoundries ou encore ASML. C'est à cet endroit que l'on retrouve par exemple l'effort de recherche du Global 450mm Consortium qui travaille sur la future transition aux wafers de 450mm (contre 300 actuellement, un mouvement qui a pris un coup d'arrêt ces dernières années).
Avant son rachat, IBM avait annoncé participer à hauteur de 3 milliards (sur 5 années) au développement de futures puces, tandis qu'en début d'année, suite au rachat par GloFo, IBM avait regroupé ses 220 ingénieurs restants sur le site de SUNY sous l'égide « IBM Research ».
Historiquement, IBM a toujours aimé jouer au jeu des annonces et continue ici dans sa tradition. En pratique il s'agit d'une première puce de test qui inclut transistors, cellules SRAM et interconnexions, les blocs essentiels même si, évidemment, on reste cependant très loin de la production en volume.

Les transistors FinFet 7nm vus au microscope
Au-delà de l'effort, on s'intéressera surtout aux choix réalisés par IBM pour son process, qui repose cette fois sur l'EUV. Nous avions eu l'occasion d'en parler, l'EUV va mieux et si une introduction est possible en cours de node pour le 10nm, TSMC et les autres visent une introduction ferme pour le 7nm et de ce côté IBM ne déroge pas.
Plus surprenant, les choix réalisés autour des structures et des matériaux. Alors que l'on s'attend probablement à voir d'autres structures que le FinFet introduites à 10 ou 7nm par Intel, IBM utilise ici des structures FinFet également, la différence s'effectuant sur les matériaux avec le retour du silicium-germanium (SiGe) étiré pour le canal, sur substrat en silicium. Ce n'est pas la première fois que le germanium apparait dans les process, même si aujourd'hui on le trouve principalement dans les process analogiques/radio . L'utilisation du SiGe étiré dans les semi-conducteurs est une innovation d'IBM et il est assez surprenant de le retrouver sur un process si avancé, qui plus est en EUV. D'autant que côté densité, les transistors peuvent être espacés de 30nm ce qui permettrait, par rapport au 10nm qui était en développement par IBM, d'augmenter la densité de 50%.

Développer un process « clef en main » - c'est comme cela qu'il est décrit par IBM qui dit avoir optimisé non seulement l'EUV, le dépôt du SiGe mais aussi les autres étapes du process comme l'interconnexion (BEOL) ne manque évidemment pas d'ironie mais nos confrères d'EEtimes notent qu'IBM fera profiter logiquement de ses travaux de recherche à GlobalFoundries qui pour rappel dispose d'une exclusivité de 10 années pour la production des processeurs serveurs d'IBM. Nos confrères sous entendent que Samsung pourrait également profiter de ces travaux, en se rappelant aux bons souvenirs de l'abandonnée Common Platform qui liait les trois sociétés.
Rien n'en est cependant moins sur puisque pour rappel, Samsung avait développé son propre process 14 nm sans IBM qui aura au final sauté ce node. Le fondeur coréen avait ensuite partagé son 14nm en intégralité avec GlobalFoundries. Pour le 10nm, IBM avait travaillé également sur son propre process que l'on retrouvera vraisemblablement tel quel chez GlobalFoundries. Les trois sociétés semblent cependant être restées en bons termes et l'on imagine que si la solution 7nm d'IBM est plus intéressante que les efforts développés en internes, ces sociétés continueront de mutualiser leurs efforts pour une éventuelle mise en production, que l'on n'attend pas de toute manière avant 2018 ou 2019. Ce que fera Samsung en 10 nm nous donnera peut-être un indice. Pour l'instant, si le constructeur a montré un wafer 10 nm, et indiqué qu'il s'attend à lancer la production en volume fin 2016, il n'a rien dévoilé sur la technique
Pilotes AMD Catalyst 15.7 WHQL
 Après une longue série de pilotes beta, AMD lance aujourd'hui, en juillet, ses premiers pilotes graphiques WHQL de l'année. Ces pilotes 15.7 apportent un support de toute la gamme du constructeur, le tout avec la certification WHQL de Microsoft.
Après une longue série de pilotes beta, AMD lance aujourd'hui, en juillet, ses premiers pilotes graphiques WHQL de l'année. Ces pilotes 15.7 apportent un support de toute la gamme du constructeur, le tout avec la certification WHQL de Microsoft.
Au-delà d'améliorations de performances habituelles, le constructeur annonce quelques nouveautés comme le support de Freesync en Crossfire notamment, et également le support de la Virtual Super Resolution sur les GPU plus anciens (HD 7000) et les APU. La gestion des seuils de frame rate (FRTC) qui était disponible uniquement sur les Fury/R300/R700 avec leur pilote spécifique est désormais disponible pour un plus grand nombre, allant jusqu'aux HD 7790.
On notera enfin la présence d'une version dédiée à Windows 10, supportant WDDM 2.0. Vous trouverez plsu de détails sur le site du constructeur ou vous pourrez télécharger les pilotes . Notez que, si au moment où nous écrivons ces lignes la colonne de droite propose des liens séparés pour la Fury X des autres cartes, les liens sont bien identiques.
AMD lance la FirePro S9170: Hawaii et 32 Go
AMD profite de l'été pour annoncer l'arrivée d'une nouvelle carte accélératrice dédiée aux serveurs : la FirePro S9170. Outre une puissance de calcul importante, celle-ci a la particularité d'embarquer pas moins de 32 Go de mémoire.

AMD propose pour rappel deux gammes principales de cartes professionnelles hautes performances. D'un côté la série W dédiée aux workstations et d'un autre la série S dédiée aux serveurs. AMD ne différencie par contre pas directement ses solutions en fonctions des usages comme peut le faire Nvidia avec les Quadro dédiées au graphisme professionnel et les Tesla au calcul haute performance (HPC).
Au niveau logiciel, les FirePro S peuvent ainsi profiter de toutes les optimisations logicielles et autres validations spécifiques aux applications graphiques. Les FirePro S se distinguent par contre au niveau du format. Elles sont refroidies passivement et dépourvues de sorties vidéo et sont donc en pratique plutôt orientées vers le HPC bien qu'elles puisse également être exploitées pour fournir des stations de travail virtuelles à travers le cloud ou un réseau interne.
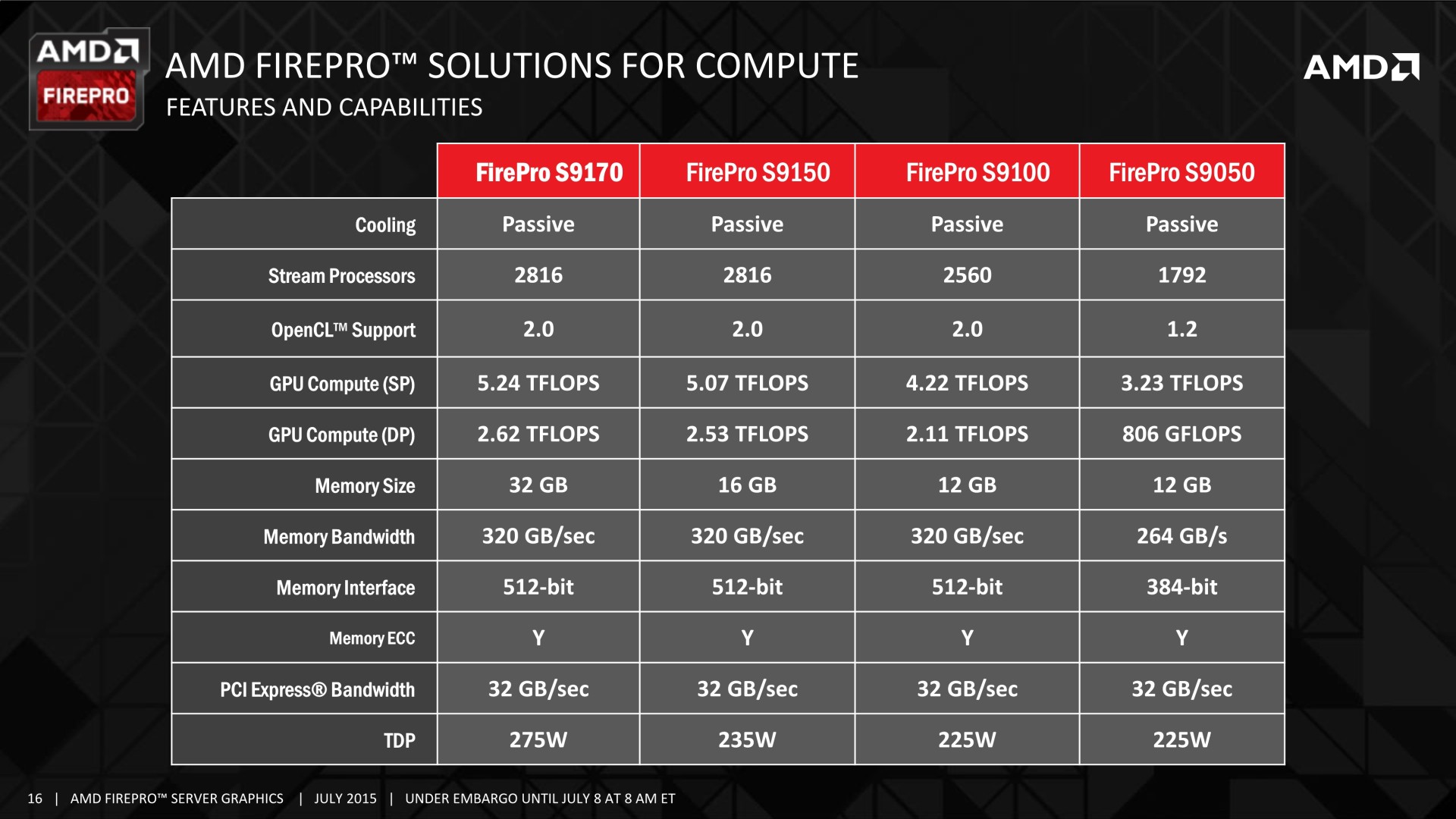
Après la FirePro S9150 16 Go lancée l'été passé, AMD propose aujourd'hui une FirePro S9170 similaire si ce n'est qu'elle est cette fois équipée de plus de mémoire :
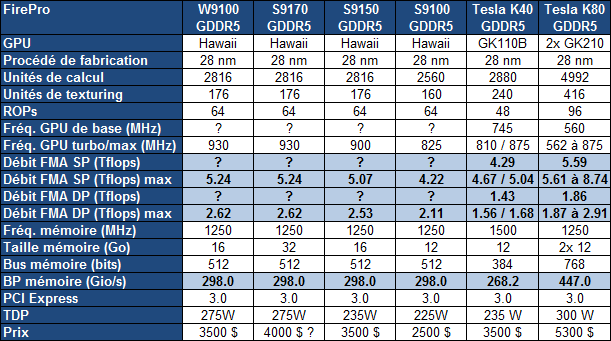
Avec une petite hausse de la fréquence du GPU Hawaii (exploité sur les Radeon R9 290X/390X), la puissance de calcul progresse de 3% et s'aligne sur celle de la FirePro W9100. Un changement plus pour la forme qu'autre chose, la seule réelle nouveauté étant à chercher du côté de l'espace mémoire qui est doublé. AMD profite pour cela de l'arrivée de la mémoire GDDR5 avec une densité de 8 Gb, soit 1 Go par puce. Un bus 512-bit couplé au mode clamshell de la GDDR5 (association de puces mémoire par paires) permet d'adresser 32 de ces puces pour un total de 32 Go, un nouveau record.
Nvidia annoncera probablement une évolution similaire avec la mémoire 8 Gb, mais ne pourra pas aller au-delà de 24 Go, son gros GPU actuel dédié au monde professionnel, le GK210 devant se contenter d'un bus 384-bit.
Si AMD ne fait pas appel à son dernier GPU en date, Fiji, c'est parce que celui-ci est actuellement limité à 4 Go de mémoire HBM, insuffisant sur le marché professionnel. Par ailleurs, le GPU Fiji est relativement lent en calcul double précision (1/16ème de la simple précision), un point qui est la force du GPU Hawaii, capable de traiter ces calculs à demi vitesse. De quoi proposer plus de 2.5 Tflops là où la Tesla K40 de Nvidia se contente plutôt de +/- 1.5 Tflops suivant le mode de Turbo qui a été activé (manuellement sur cette carte).
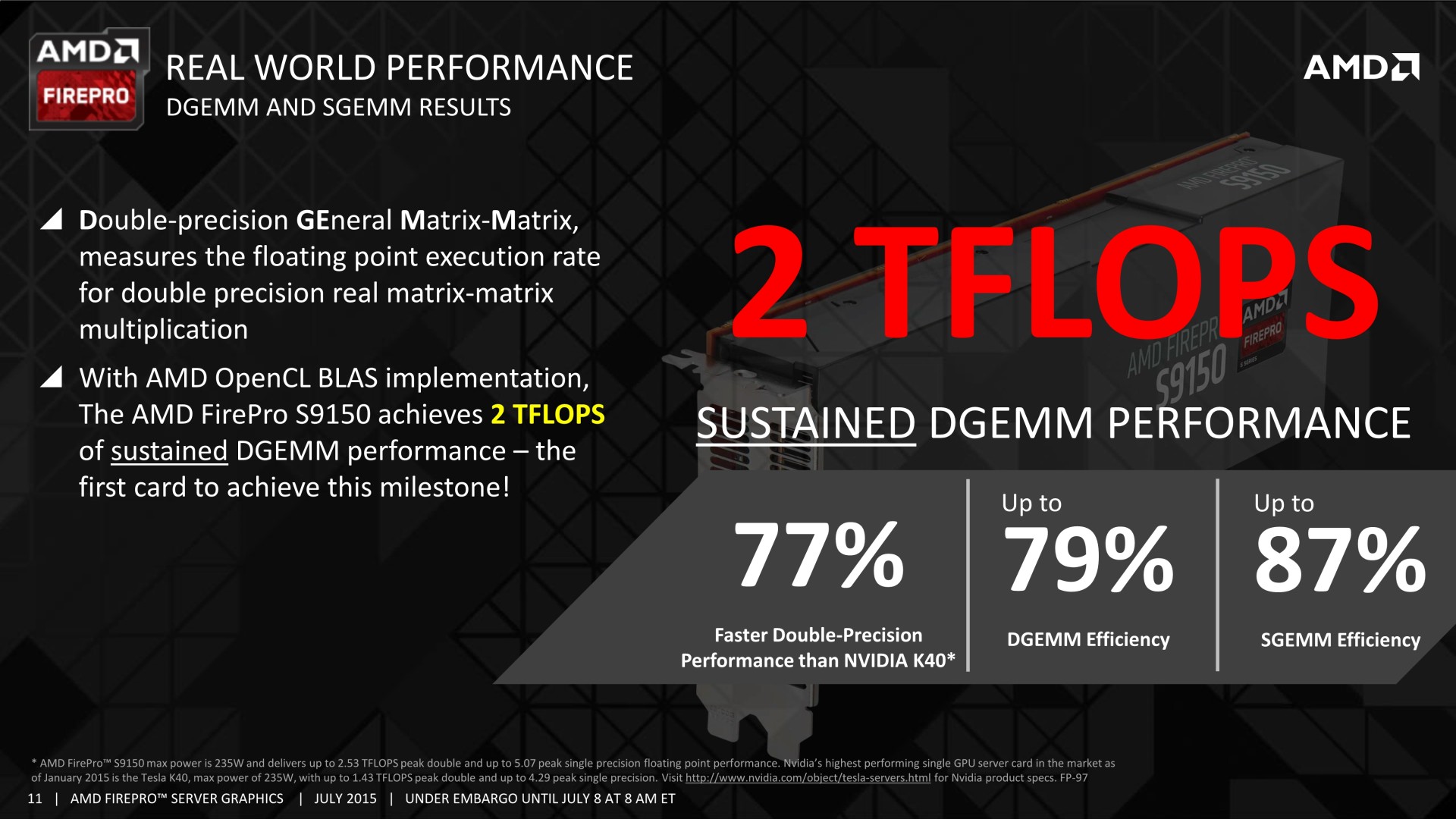
AMD précise par ailleurs qu'il ne s'agit pas que de gros chiffres théoriques et que le rendement est assez élevé avec 79% en DGEMM (multiplication de matrices), ce qui permet d'atteindre 2 Tflops sur les FirePro S9150 et S9170.
Ces débits soutenus sont également autorisés par un TDP très élevé. Il passe d'ailleurs de 235W pour la S9150 à 275W pour la S9170, ce qui demandera une capacité de refroidissement importante au niveau du serveur. Si cela pose problème, ou tout simplement pour gagner en efficacité énergétique, la S9170 pourra être configurée en mode 235W mais aura alors plus de mal à maintenir sa fréquence maximale lors du traitement de tâches lourdes.
Outre la puissance de calcul et la quantité de mémoire embarquée, AMD met en avant son support des standards ouverts tels qu'OpenCL 2.0 ou encore OpenMP 4.0 et OpenACC à travers un partenariat avec PathScale.
AMD annonce une disponibilité de la FirePro S9170 pour cet été avec une tarification proche de celle de la FirePro S9150 qui devrait donc tourner autour de 4000$. En plus de s'opposer aux solutions de Nvidia, elle devra également lutter contre les Xeon Phi d'Intel dont le prometteur Knights Landing ne devrait plus tarder.