
Actualités processeurs
32 coeurs et 8 canaux DDR4 pour l'Opteron Zen ?
Microcode anti OC chez Intel
Samsung présente sa SRAM 10nm
Excavator FM2+ et nouveaux ventirads AMD
Skylake 4+4e BGA débarque en Core i7 et Xeon E3
Skylake gagne un an de support W7 / 8.1



En janvier dernier, Microsoft indiquait que le support complet des futurs processeurs ne serait assuré que sous Windows 10. Il était dans le même temps précisé que concernant Skylake le support Windows 7 et 8.1 ne serait total que jusqu'en juillet 2017.

Au-delà seules les failles les plus critiques concernant ces configurations seront comblées, à condition que la mise à jour n'entrave pas la fiabilité ou la compatibilité sur d'autres plates-formes, ce jusqu'en janvier 2020 pour 7 et janvier 2023 pour 8.1.
Comme l'indique cette page cette date a été repoussée d'un an puisqu'il est désormais question de juillet 2018.
AMD lance l'A10-7890K et l'Athlon X4 880K
Annoncé lors du CES en janvier, ce n'est finalement que hier que l'APU A10-7890K a officiellement été lancé. Il se distingue de l'A10-7870K par des fréquences CPU 200 MHz supérieures et atteint ainsi 4.1 à 4.3 GHz, mais le prix passe de 140 à 165$.

[ 1 ] [ 2 ]
Il sera livré avec le ventirad AMD Wraith, mais l'A10-7870K ne démériteras pas de ce côté puisqu'il va désormais être livré avec un ventirad similaire si ce n'est qu'il ne dispose pas du logo AMD illuminé. Ce ventirad accompagnera également le tout nouveau Athlon X4 880K dont la partie CPU fonctionne à 4.0-4.2 GHz, contre 3.7-4.0 GHz pour le X4 860K. Il faudra compter 95$ pour cette nouvelle référence contre 80$ pour le X4 860K.
Plus de deux ans après les premiers Kaveri, il est probable que ces références soient les dernières lancées en attendant Bristol Ridge en AM4 prévu pour l'été.
L'EUV possiblement pour le 7nm ?
Le site SemiWiki nous rapporte quelques informations sur l'état de la fabrication EUV, en provenance de la conférence SPIE Advanced Lithography qui se tient actuellement à San José.
Lors de la même conférence l'année dernière, les nouvelles étaient pour rappel plutôt bonnes (voir le lien pour un rappel complet sur la fabrication des processeurs et l'importance capitale de l'EUV !) et l'on espérait une introduction en cours de process pour le 10nm, et une introduction complète à 7nm. Malheureusement, on le rappelait en janvier, TSMC avait calmé les ardeurs en indiquant qu'il faudrait attendre le 5nm pour une éventuelle introduction de cette technologie.

SemiWiki confirme certains chiffres donnés lors de la dernière conférence aux investisseurs de TSMC, à savoir que la machine avait atteint sur une période de quatre semaines une production de 518 wafers/jour, un niveau encore largement insuffisant. Intel a partagé également quelques chiffres, un peu inférieurs à ceux de TSMC, à savoir entre 2000 et 3000 wafers par semaine (285-428 par jour).
On notera quand même que le taux de disponibilité des scanners de la société ASML a augmenté, passant de 55 à 70% chez TSMC (Intel rapportant une disponibilité identique) ! On notera que s'il est question d'une introduction en début de node à 5nm, TSMC laisse la porte ouverte pour le 7nm si jamais des progrès étaient effectués. Intel de son côté n'a pas donné d'information. Samsung envisagerait l'introduction à 7nm selon les présentations, sans plus de précisions.
Si la question de la disponibilité est importante, celle de la puissance de la source lumineuse l'est encore plus. Après avoir été limité à 40 watts l'année dernière, les machines actuellement en évaluation chez TSMC disposent désormais de sources 80 watts. C'est mieux, mais cela reste loin des 250 watts promis par ASML pour fin 2015. Les dernières prédictions sont désormais de 250 watts en 2016-2017, et au delà en 2018-2019, des plages particulièrement larges.
Atteindre les 250 watts de puissance permettrait d'augmenter significativement la cadence de production, atteignant 170 wafers/heure en théorie. ASML a effectué des démonstrations que TSMC et Intel semblent juger prometteuses de 185 et 200 watts. Reste à les voir en production, bien évidemment. Les challenges de cette technologie restent complexes et ne se limitent pas à ces deux points cruciaux, la question des défauts dans les masques est elle aussi importante même si là aussi TSMC et Intel ont visiblement noté quelques progrès. Vous pouvez retrouver plus de détails sur ces points dans l'article de SemiWiki .
Accélération SHA pour Cannonlake
 Quelques petites informations et confirmations sont apparues ce week-end à propos de Cannonlake, la future architecture processeur d'Intel prévue pour la seconde moitié de 2017, et qui sera la première du constructeur à être produite dans un procédé de fabrication 10nm.
Quelques petites informations et confirmations sont apparues ce week-end à propos de Cannonlake, la future architecture processeur d'Intel prévue pour la seconde moitié de 2017, et qui sera la première du constructeur à être produite dans un procédé de fabrication 10nm.
C'est par la publication d'un patch pour Clang, le compilateur C/C++/Obj-C de LLVM que l'on aura obtenu d'abord quelques confirmations sur le support d'AVX-512. Le patch en question que vous pouvez retrouver ici concerne l'énumération des fonctionnalités des familles de processeur. L'intérêt de ce code est de permettre aux développeurs, indépendamment de la machine qu'ils utilisent, de compiler des versions optimisées de leurs programmes pour une architecture donnée (par exemple, optimisée pour Skylake en ajoutant -march=skylake, plus de détails sur le sujet dans cet article).

Le patch, en développement depuis début février , indique le support spécifique de certains jeux d'instructions en fonction des familles. On retrouve ainsi les deux déclinaisons de Skylake, la version "client" (celle disponible pour les PC portables et de bureau) et la version "serveur" pour les Xeon. Cette dernière se différencie pour rappel par son support d'une partie du jeu d'instruction AVX-512.

Pour ce patch, Intel ne spécifie qu'une seule version de Cannonlake et l'on retrouve, comme promis, le support des instructions AVX-512. De manière plus précise, en plus des instructions déjà supportées par la version Xeon de Skylake, deux autres extensions sont présentes, avx512ifma et avx512vbmi (une information que nous avions notée l'année dernière). L'extension avx512ifma concerne les instructions dites fused multiply add (par exemple A x B + C), appliquées cette fois ci à des nombres entiers (sur une précision de 52 bits). avx512vbmi rajoute des instructions de manipulation/permutations vectorielles d'octets (Vector Byte Manipulation Instructions).
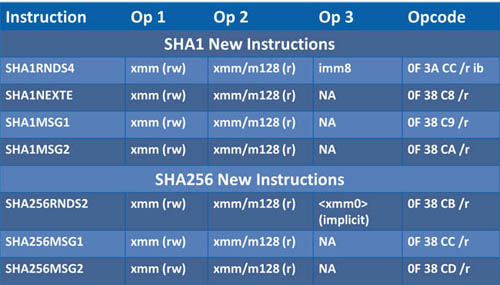
L'autre information est la confirmation de l'arrivée d'instructions dédiées aux calculs de hash cryptographiques. Les instructions sha font, sans trop de doute, référence à ces instructions présentées en 2013 par Intel , capables d'accélérer le calcul de hash aux formats SHA-1 et SHA-256 . Elles devraient être donc introduites pour la première fois sur Cannonlake.
On notera également dans le patch la mention d'une autre extension, umip pour laquelle nous n'avons pas encore trouvé de référence dans la documentation d'Intel !
L'ITRS prépare l'après loi de Moore
C'est la section actualité de la très sérieuse revue scientifique Nature qui l'affirme : la loi de Moore est arrivée à son terme. Énoncée en 1965 par Gordon Moore, l'un des cofondateurs d'Intel, il s'agit d'une observation par laquelle la quantité de transistors dans les circuits intégrés doublait à peu près tous les ans. Une observation transformée en loi pour prédire que cette cadence pouvait être extrapolée pour les années à venir.
En 1975, la loi avait été révisée pour prendre la forme que l'on connaît actuellement, à savoir un doublement des transistors tous les deux ans. L'importance de la loi de Moore allait cependant au-delà de la simple prédiction puisqu'elle prenait en compte les coûts de fabrication : l'observation se fait sur les puces ayant le coût par transistor le plus faible (tentant donc de prendre en compte les questions de yields et de défauts en fonction de la taille des puces).
Plus qu'une prédiction, la loi de Moore a servie, particulièrement chez Intel, de guide au fil des années, prédisant à l'avance les budgets en nombre de transistors alloués aux ingénieurs, et poussant vers l'avant la nécessité d'investir dans de nouveaux process de fabrications, la fameuse stratégie du Tick-Tock poussée d'abord en interne par Pat Gelsinger au début des années 2000 avant d'être utilisée publiquement pour décrire les générations à venir.
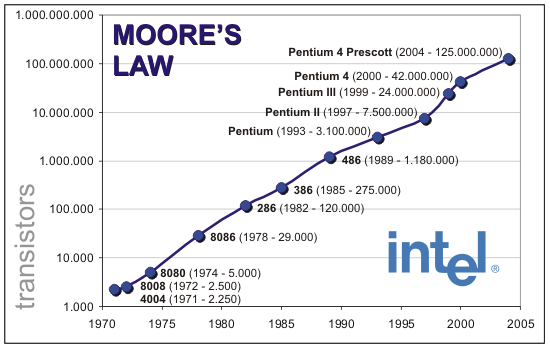
De manière intéressante, au-delà d'Intel, c'est toute l'industrie du semi-conducteur qui s'est mise d'accord autour de la loi de Moore, à savoir non seulement les fondeurs, mais aussi et surtout les fournisseurs d'outils. Le besoin de coordination entre tous les acteurs aura conduit à l'élaboration d'une roadmap, d'abord appelée National Technology Roadmap for Semiconductors dès 1993, avant d'être renommée sous sa forme actuelle, l'International Technology Roadmap for Semiconductors (ITRS).
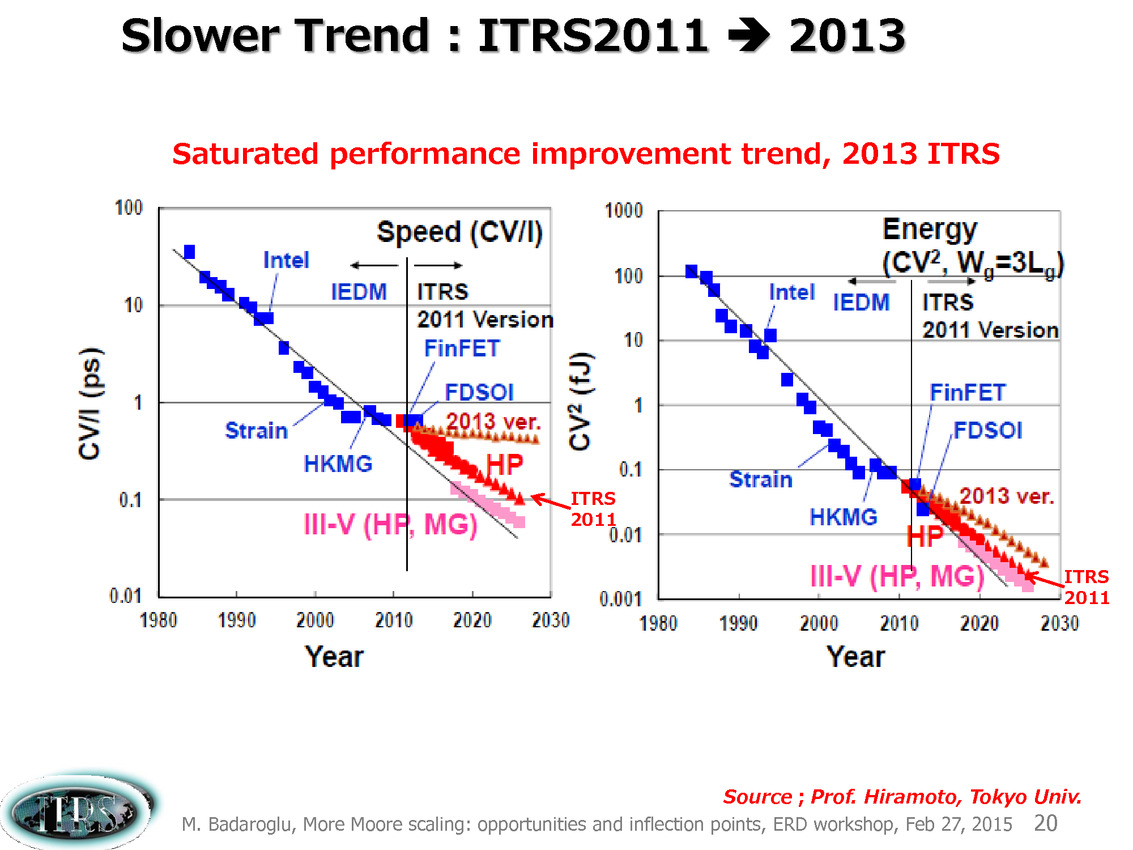
Le rôle joué par cette roadmap, dont la dernière version a été publiée en 2013 aura été particulièrement important ces dernières années où, passé le 90nm, les challenges techniques ont contraint à des changements d'approches importants. L'augmentation des performances par la fréquence, méthode classique aura atteint un plateau à cause de l'augmentation de la consommation, poussant dans le commerce les stratégies de multiplication des coeurs que l'on connaît. Le rôle de la roadmap, au-delà de la concertation, est de s'assurer de trouver des pistes pour continuer la cadence de réduction des coûts/augmentation des transistors de la loi de Moore.
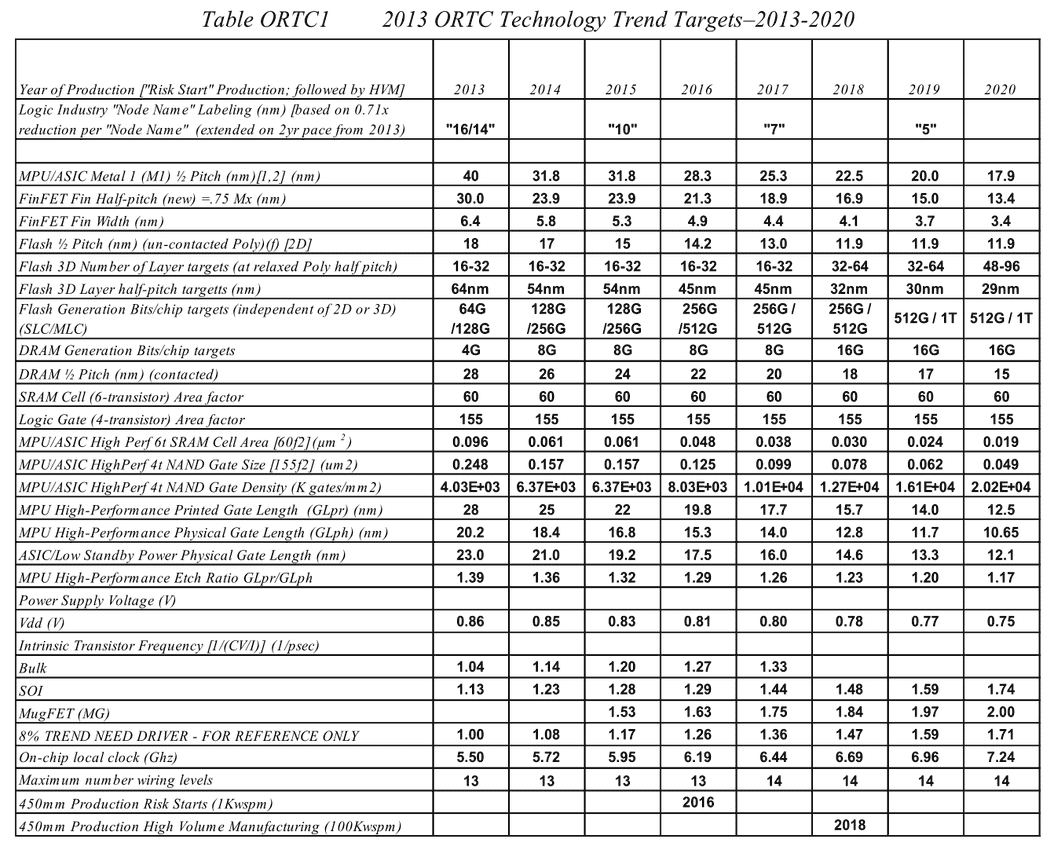
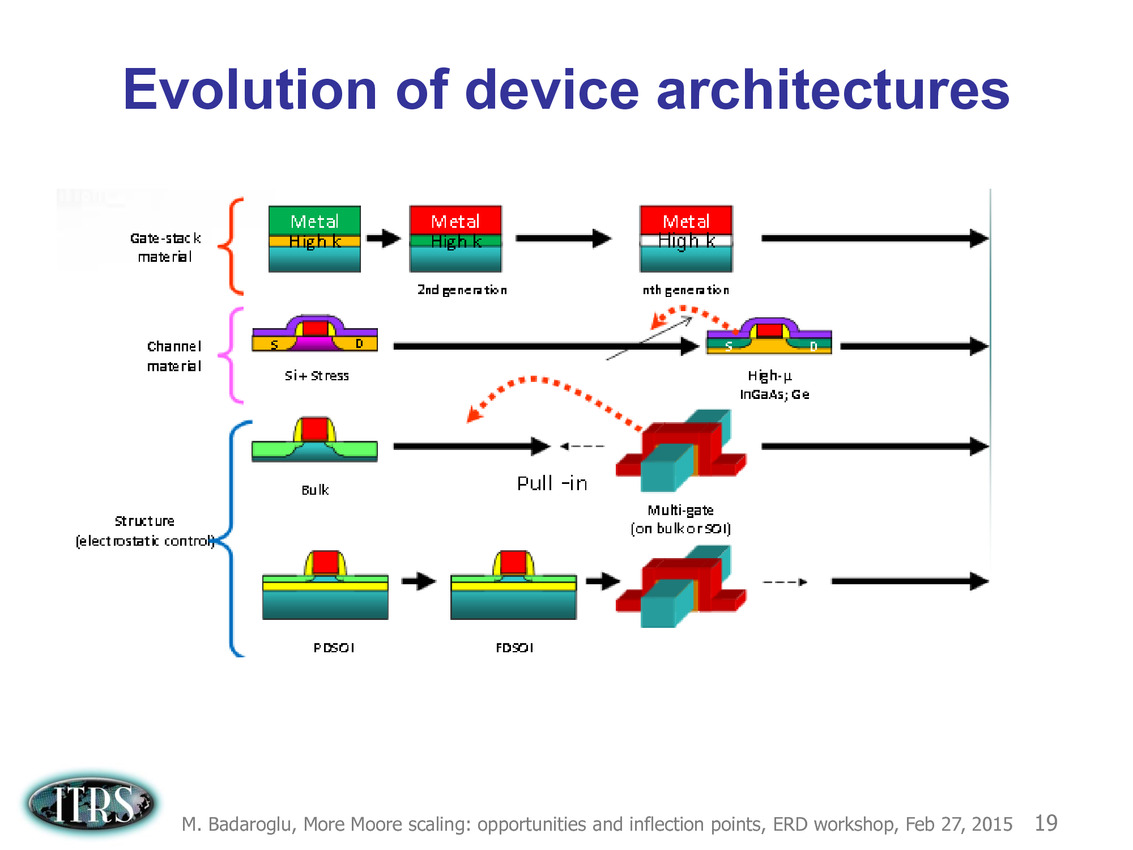
La dernière roadmap ci-dessus donnait des grandes lignes sur la manière de mettre à l'échelle les différents composants des transistors. Après les difficultés autour du 90nm, l'industrie est passé progressivement de la règle dite de la mise à l'échelle géométrique (on réduit tout dans des proportions identiques, le nom du node indiquant en général la taille de la porte) à celle de la mise à échelle par équivalence (equivalent scaling).
Etant donné que différentes parties composant les puces posent des problèmes différents, des règles d'équivalences ont été mises au point pour permettre de continuer a atteindre les buts de réduction des coûts/augmentation de densité imposé par la loi de Moore (on peut voir sur le tableau la couche d'interconnexion M1 et l'écart minimal entre deux transistors FinFET, en passant par des estimations des tailles de blocs fondamentaux comme la SRAM).
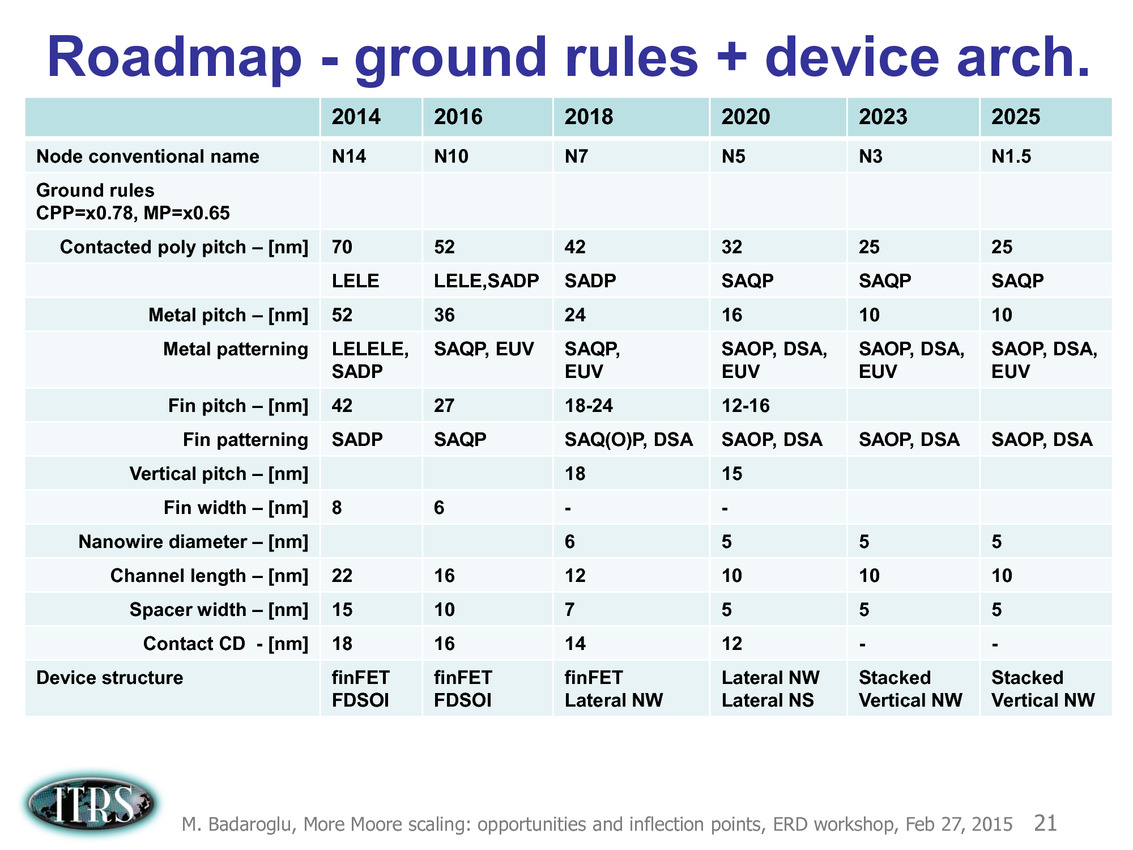
Pour 2016, la roadmap annonçait par exemple de la SRAM 6 transistors (6T) haute performance en 10nm autour de 0.048 µm2, ce qui n'est pas très éloigné de ce que présentait Samsung il y a une dizaine de jours de cela. En pratique cependant, on notera qu'on est globalement assez en retard sur la roadmap qui prévoyait des débuts de production à petite échelle en 10nm en 2015 (Risk Start dans la roadmap, suivi de HVM, fabrication en volume). Chez TSMC par exemple, la production risque est prévue pour la fin 2016 avec une production en volume pour 2017. Intel prévoit ses puces en volume pour 2017 également.
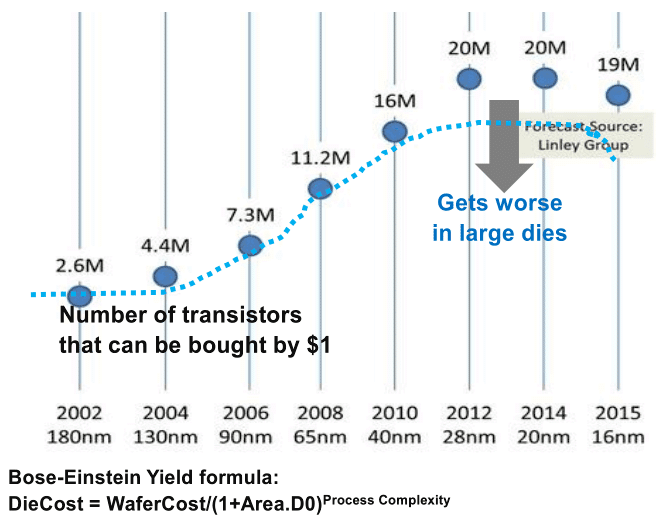
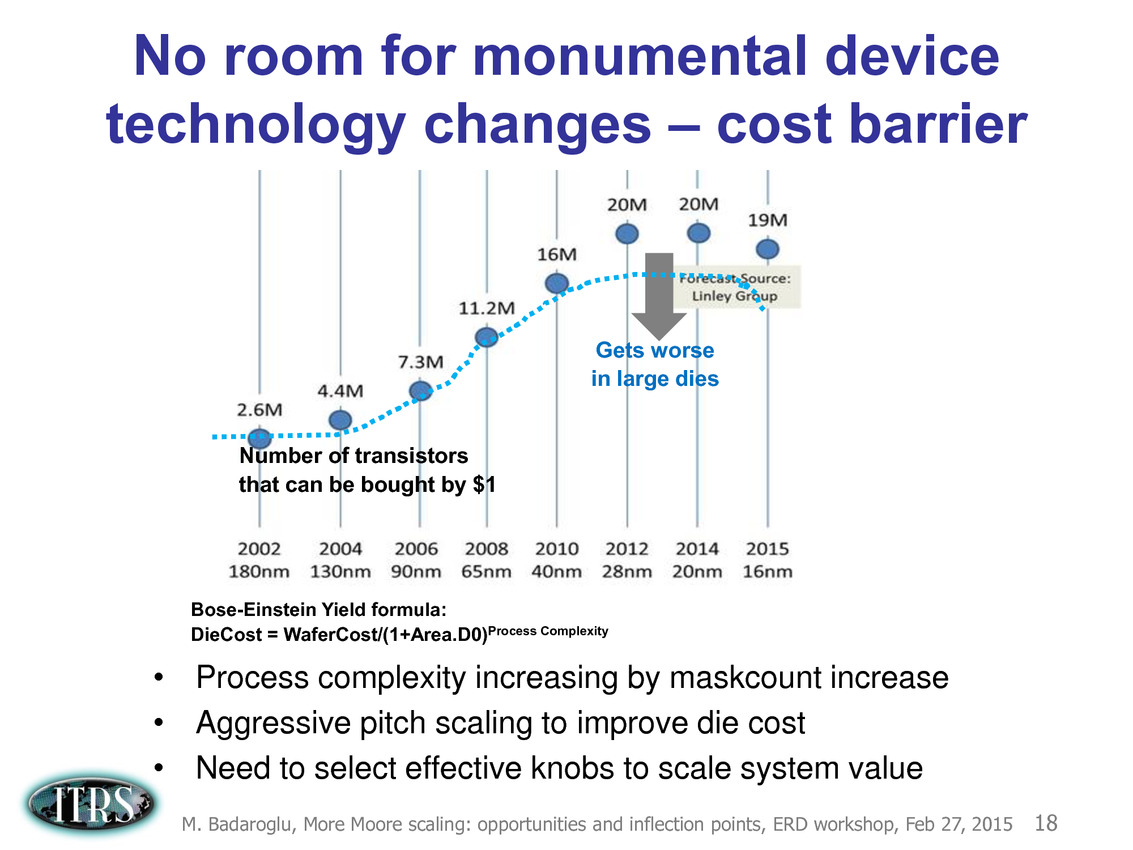
Évidemment depuis 2013 les choses se sont un peu plus compliquées et l'absence de roadmap en provenance de l'ITRS n'a pas forcément aidé. En pratique, la réduction des coûts s'est arrêtée, avec même un retour en arrière à 16nm signant de facto la fin de la loi de Moore, comme on peut le voir sur cette estimation ci-dessus tirée d'une présentation de l'ITRS en février 2015.
L'absence de nouvelle roadmap en provenance de l'ITRS aura même donné lieu à des divergences d'interprétations fortes, Intel titillant ses concurrents sur la question de la densité théorique. TSMC et Samsung ont fait pour rappel le choix de conserver un BEOL (Back End of Line, la partie basse d'une puce qui sert à l'interconnexion des transistors) commun entre le 20 et le 16nm pour accélérer la cadence de mise en production. En pratique chez TSMC, malgré le BEOL commun, le half pitch M1 reste tout de même dans les clous à 32nm (entre 40 et 31.8 sur la roadmap).
La densité pratique reste de toute manière très différente de ce que peuvent proposer des formules grossières comme celle utilisée par Intel (qui multipliait le pitch M1 par le pitch entre deux portes), qui pour exploiter les FinFET aura fait le choix d'utiliser pour certains de ses transistors critiques des structures plus larges composées de plusieurs fins (dans des proportions non négligeables même si la proportion exacte est rarement évoquée de manière précise par Intel).
Cumulé a de multiples autres détails (différents types de blocs sont présents avec des densités différentes, de la SRAM aux blocs plus ou moins critiques) il est impossible de tirer grand-chose de la théorie. L'écart entre un Core M Broadwell 14nm fabriqué par Intel (82mm2 pour 1.3 milliards de transistors) et un A8 fabriqué par TSMC en 20nm (89 mm2 pour 2 milliards de transistors) montre qu'il est difficile de comparer quoique ce soit à moins de prendre deux puces strictement identiques. Cela aura été possible pour l'A9 d'Apple, dont la superficie atteint 96mm2 chez Samsung contre 104.5mm2 chez TSMC.

Le mois prochain, l'ITRS devrait donc enfin communiquer une nouvelle roadmap qui d'après Nature tirera définitivement un trait sur la question de la loi de Moore comme moteur d'évolution unique. D'après Nature, la prochaine roadmap se concentrera sur les applications pratiques, allant du smartphones aux puces serveurs et regardera les applications pratiques, que ce soit au niveau circuits d'alimentations, des capteurs nécessaires, ou d'autres blocs de siliciums répondant à des besoins particuliers.
La véritable question est de savoir ce que comportera réellement cette roadmap qui serait rebaptisée d'après Nature International Roadmap for Devices and Systems, abandonnant même le mot transistor !
Ce que l'on sait, c'est que la réorganisation de l'ITRS en 2014 s'est faite autour de groupes de travaux, avec notamment un groupe baptisé « More Moore » pour évoquer les pistes techniques pour les prochains nodes, dont vous pouvez retrouver ci-dessous la dernière présentation datant de février 2015.



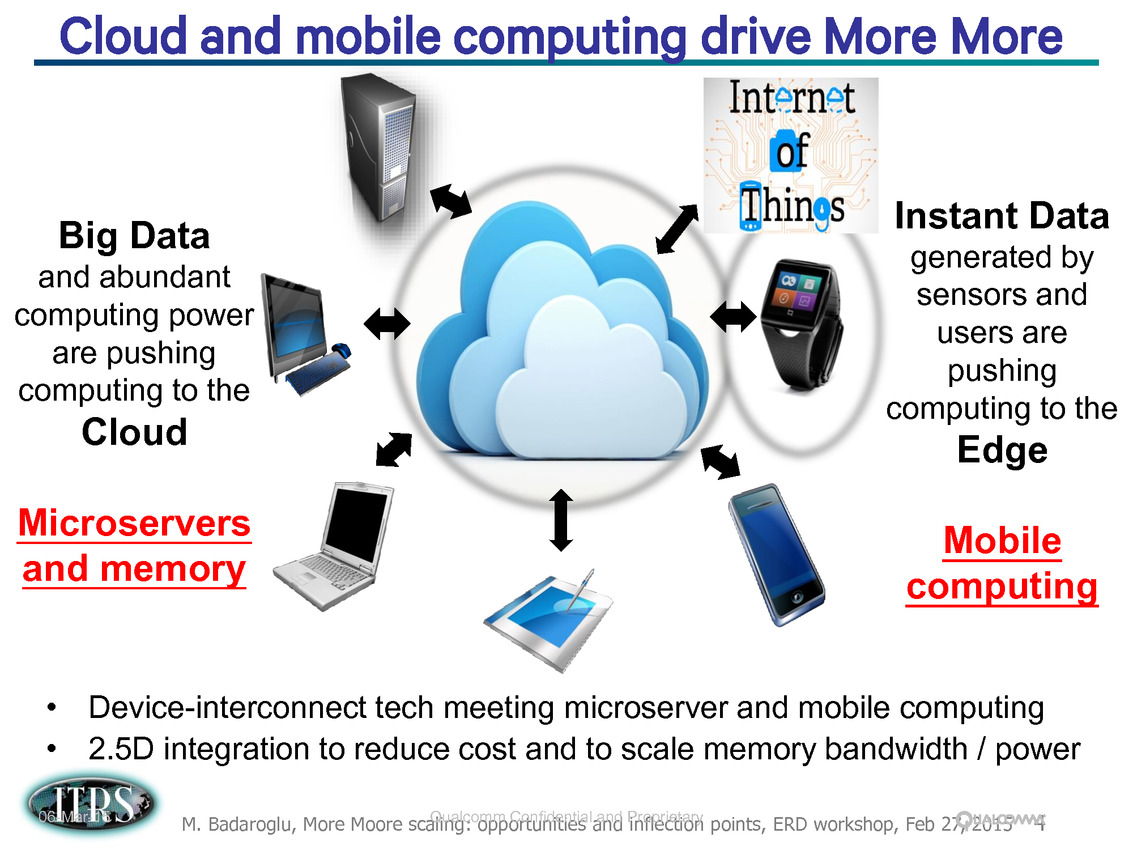
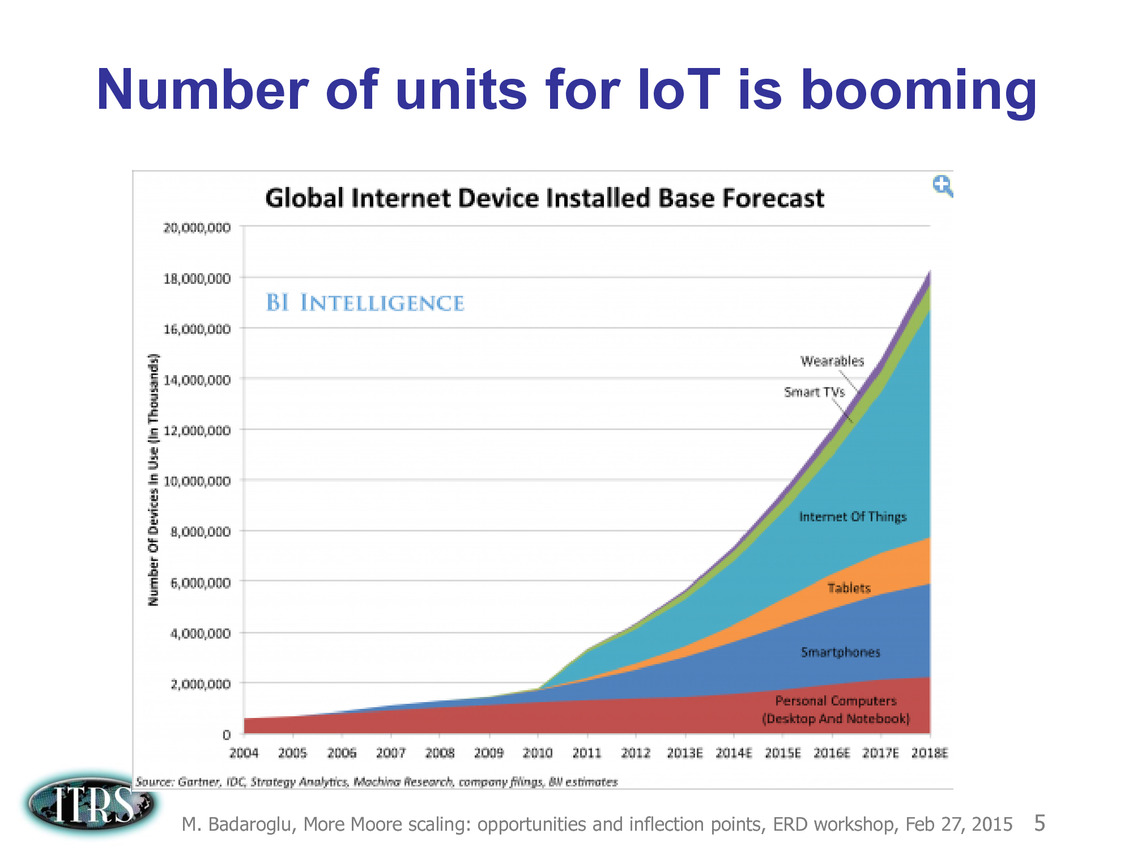

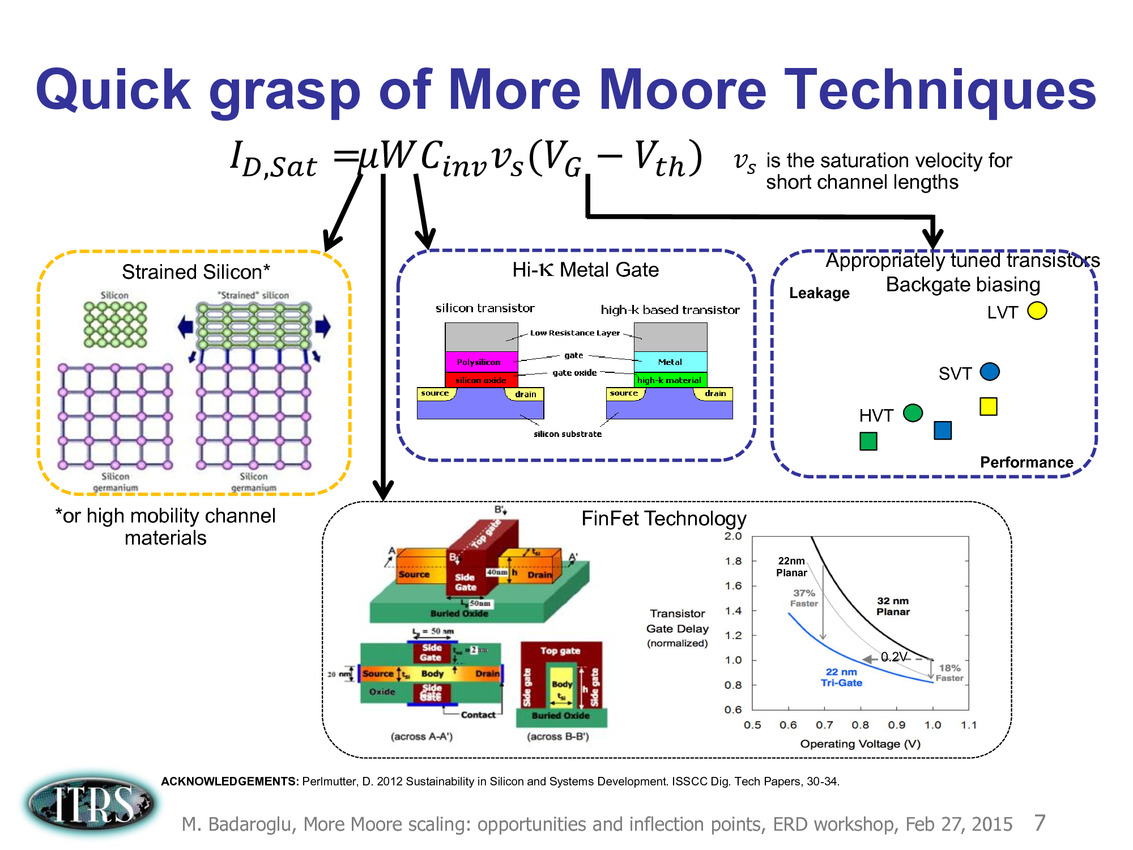
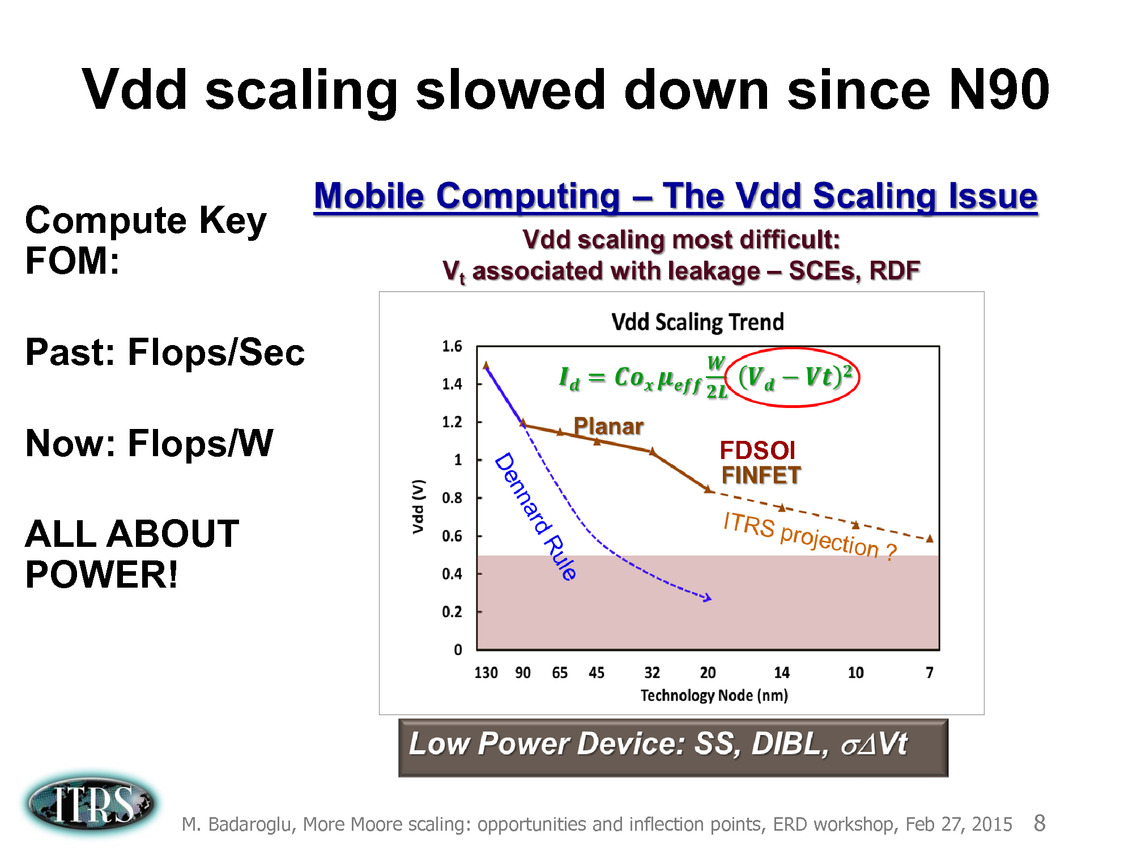
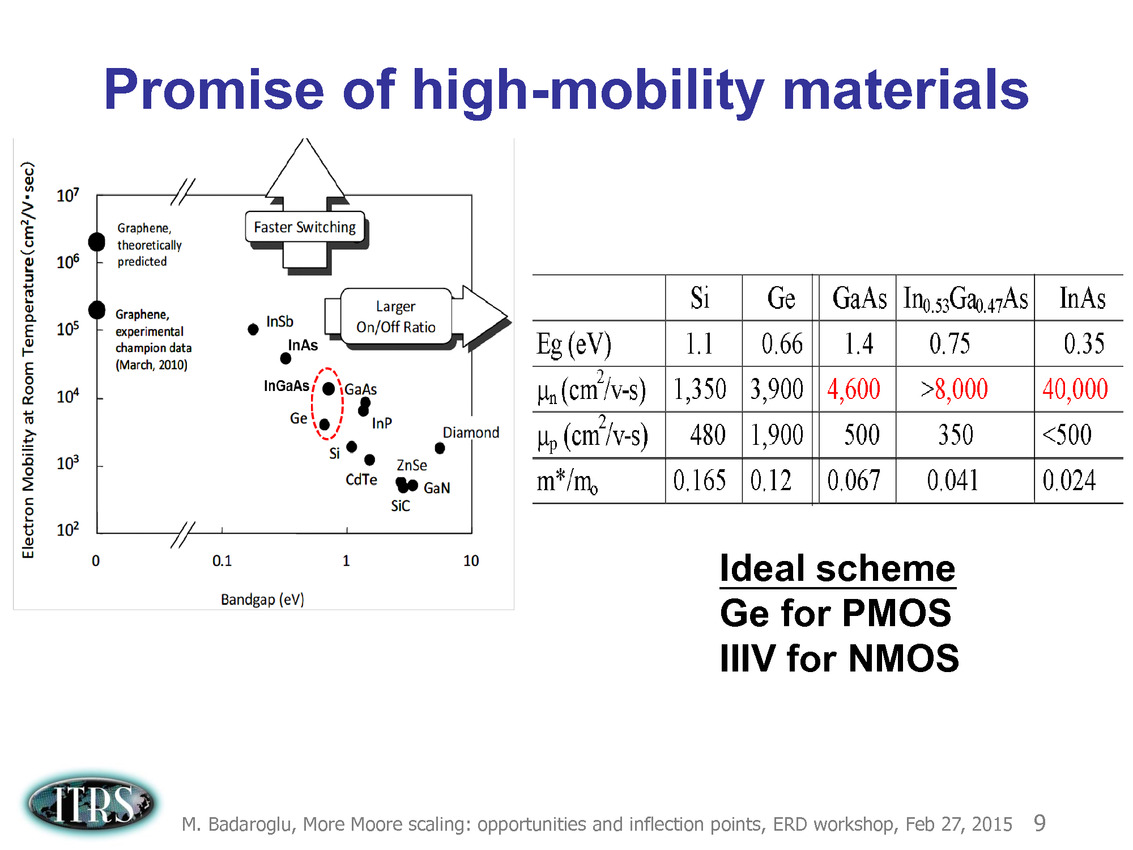
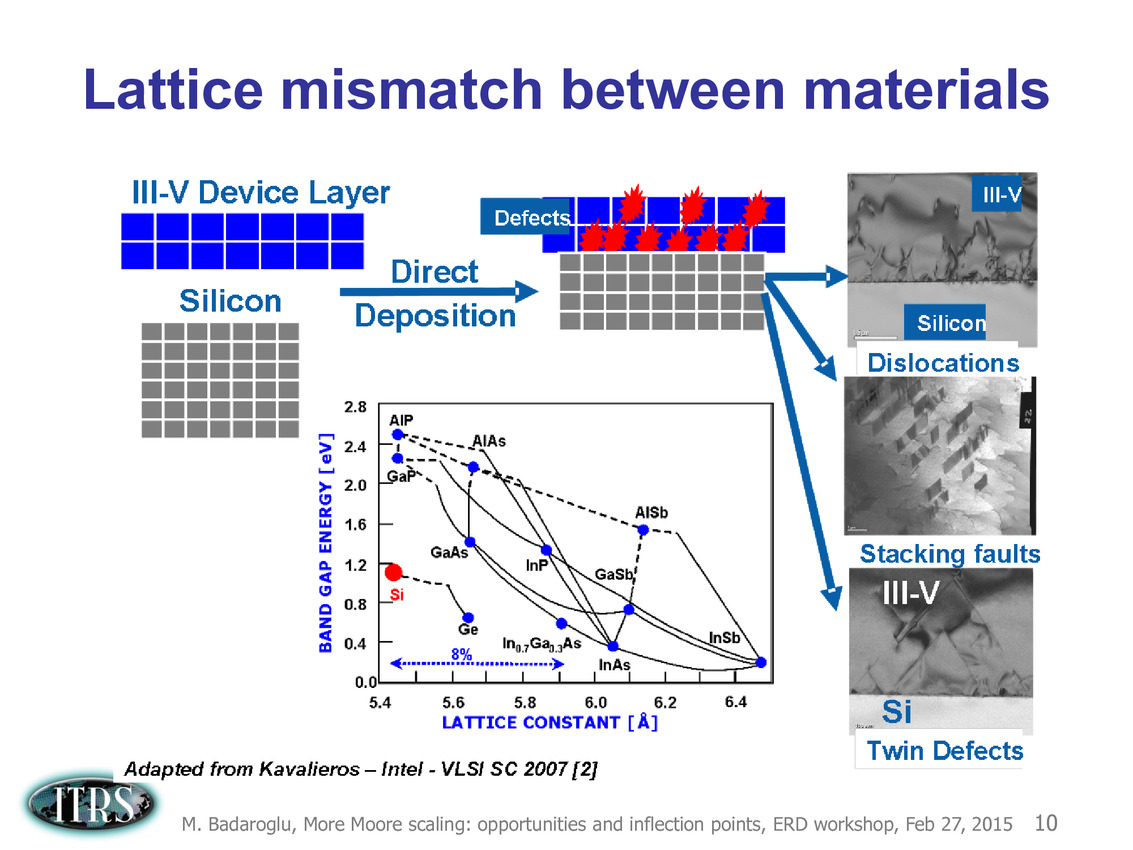
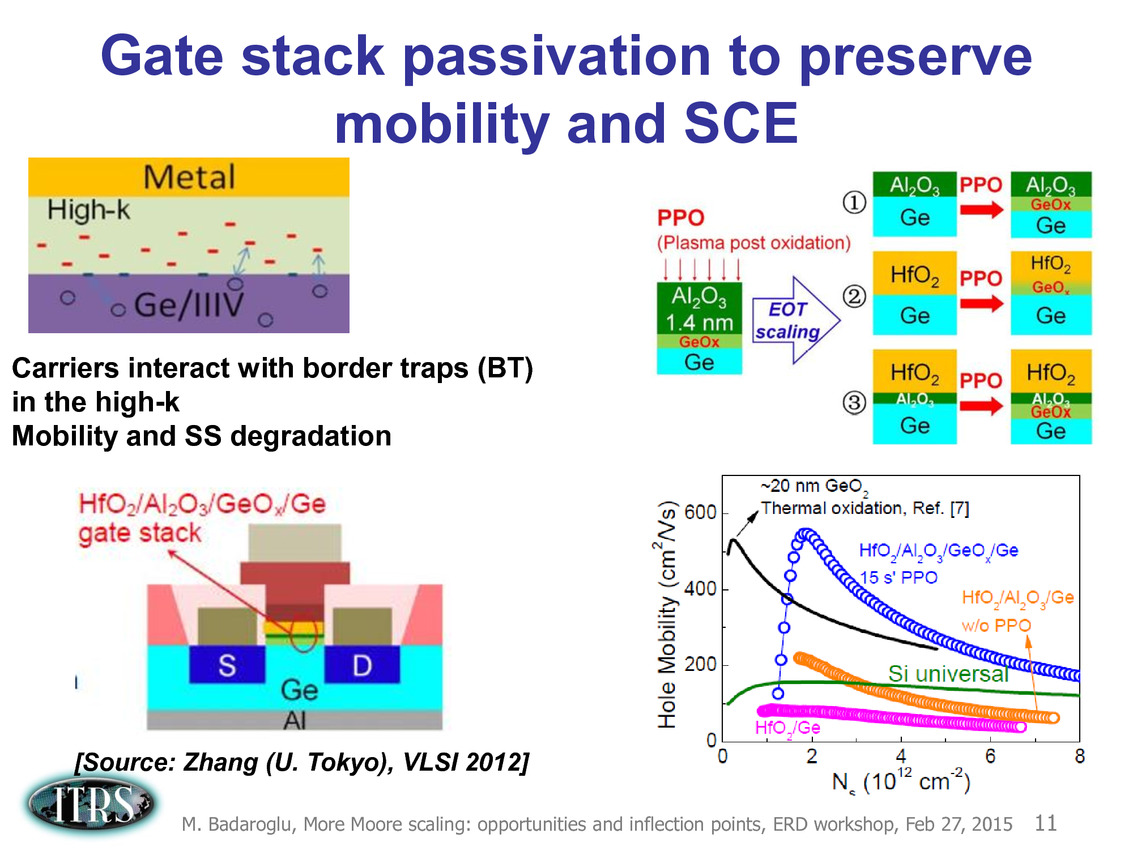
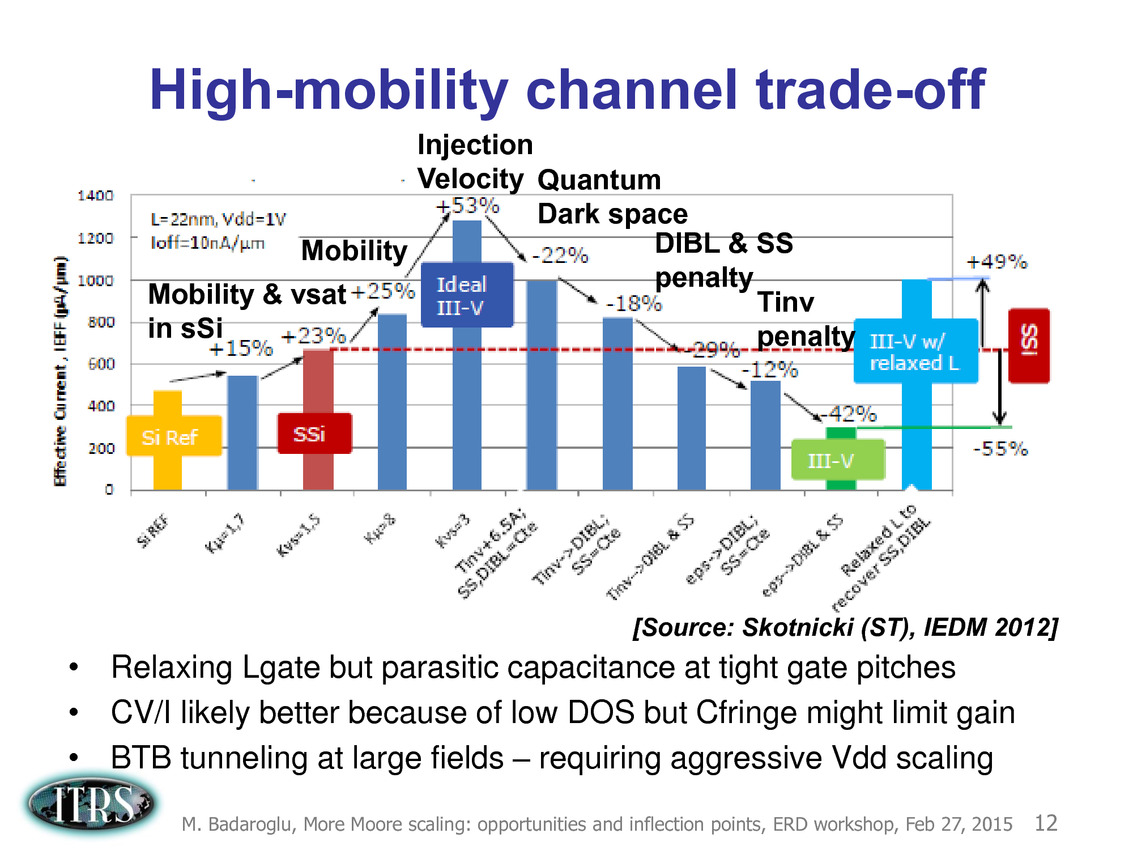
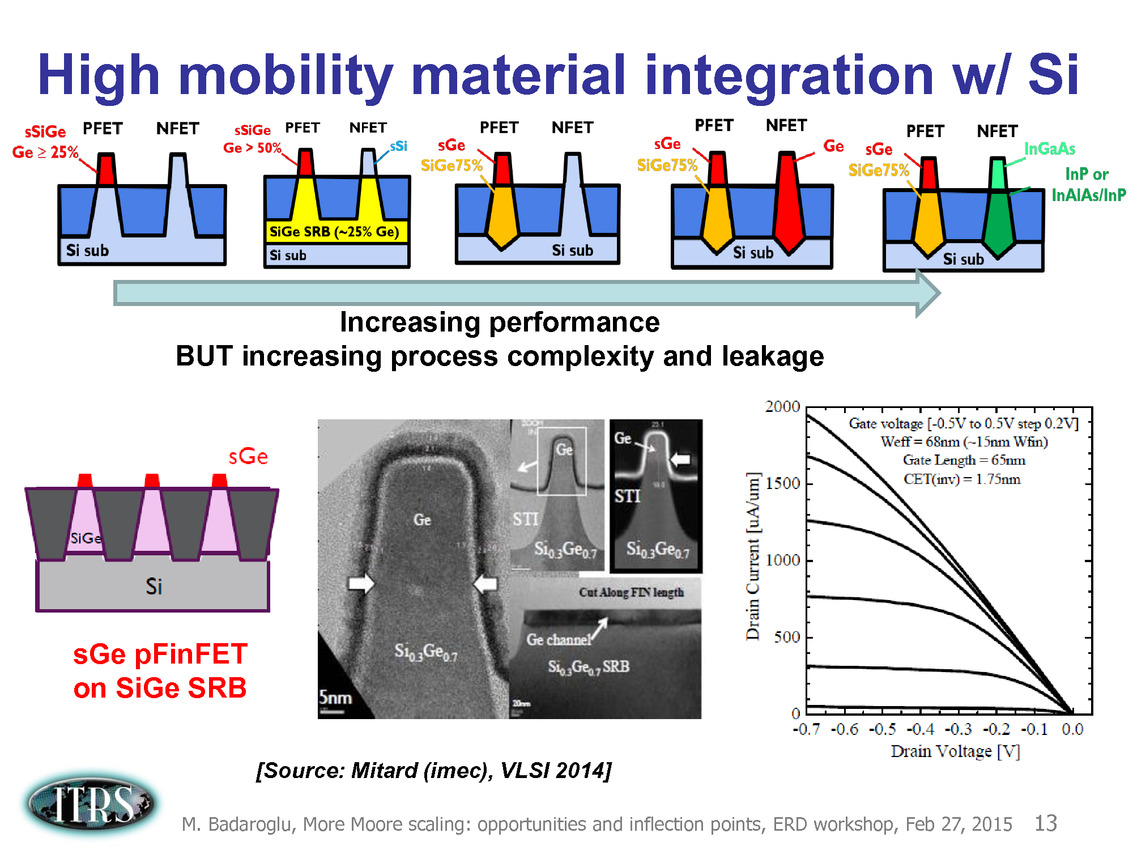

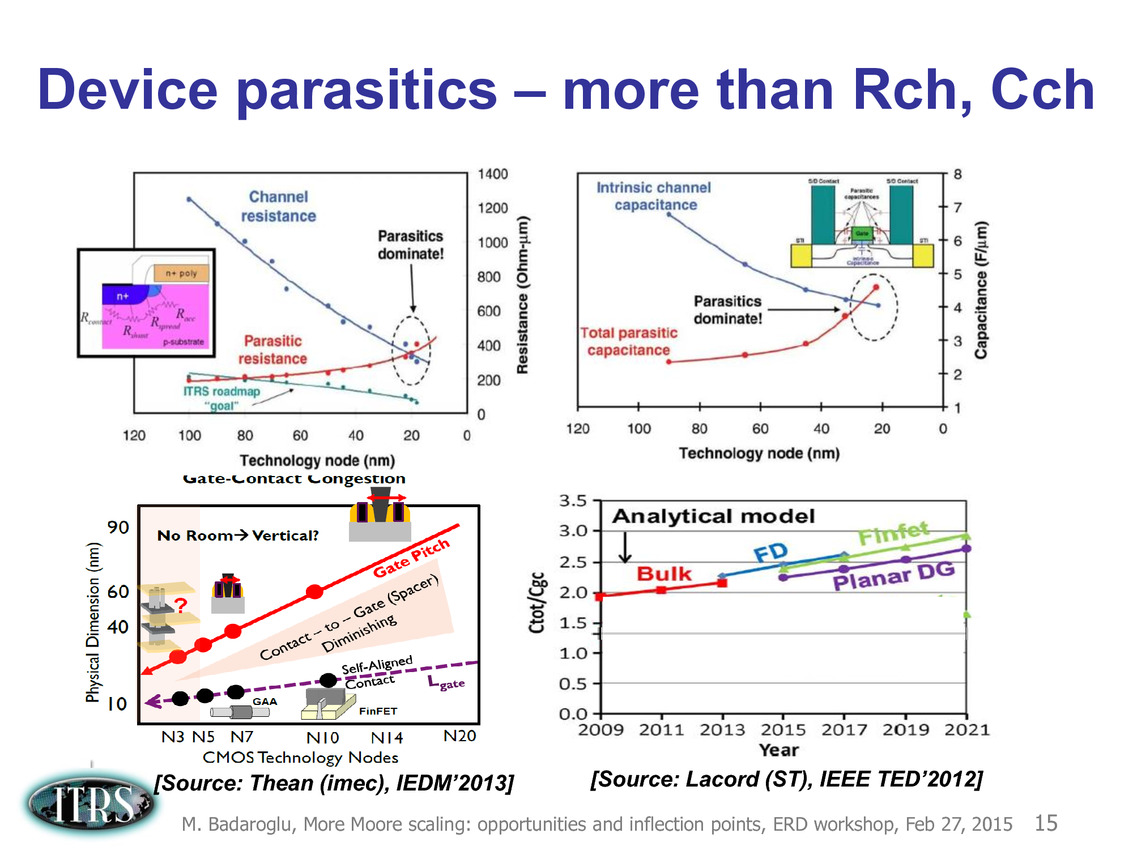
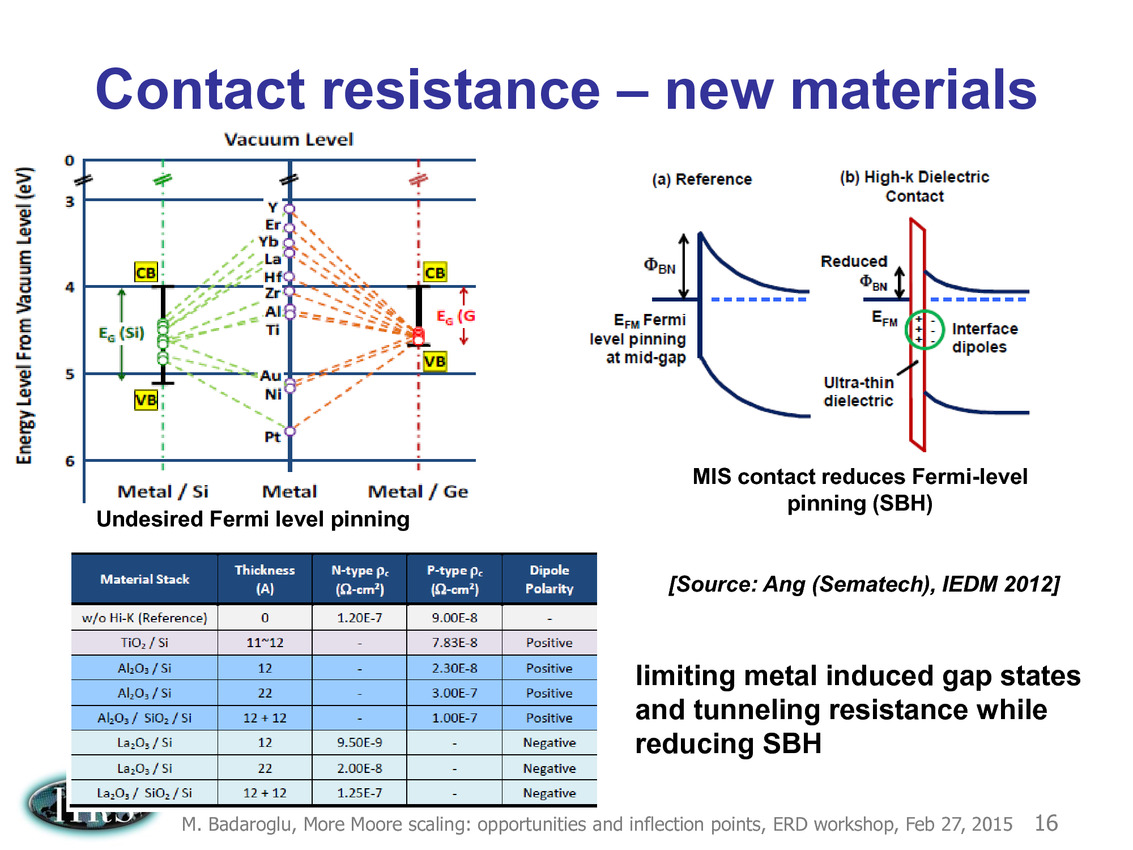
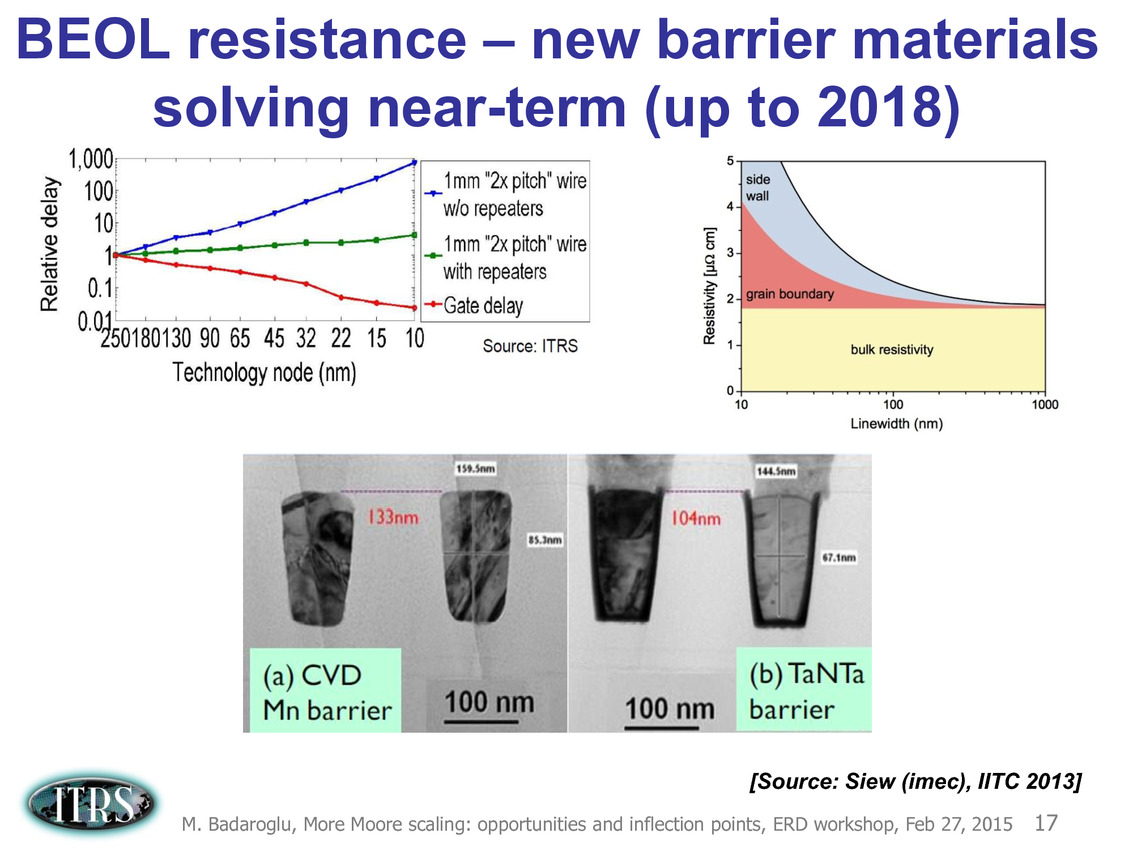
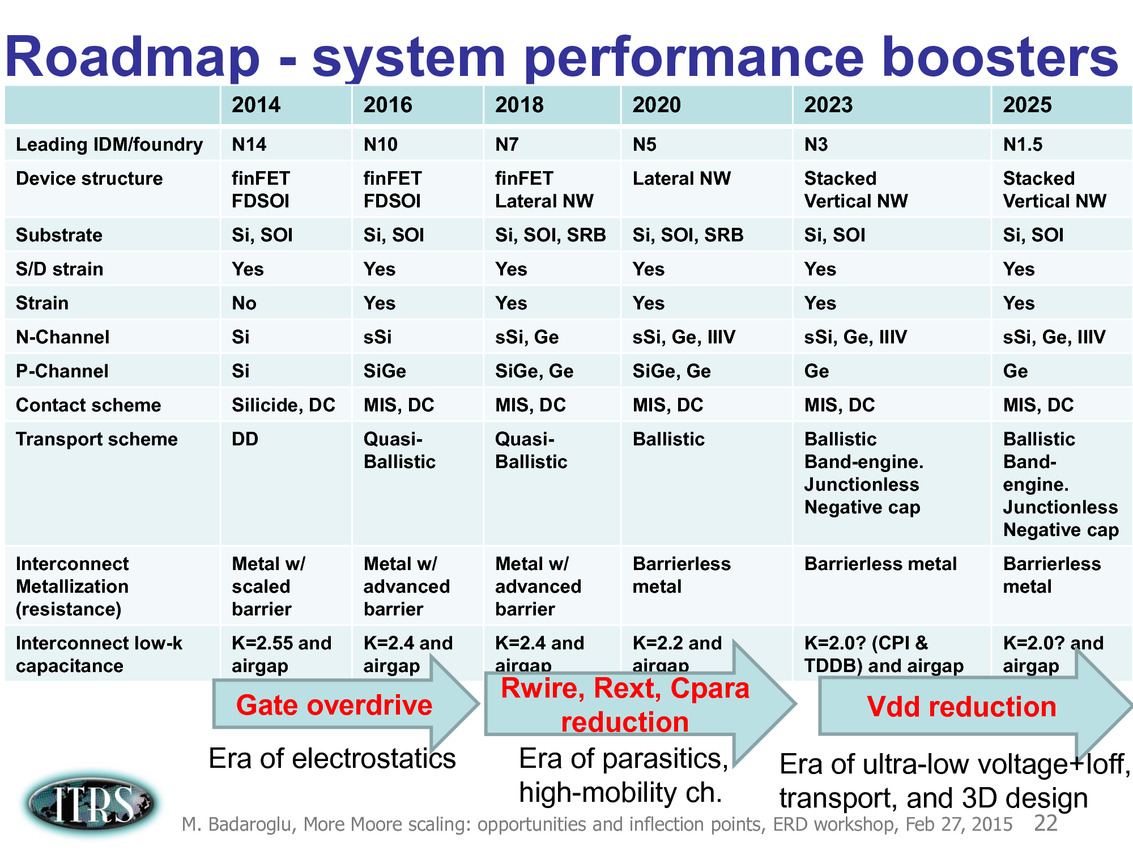
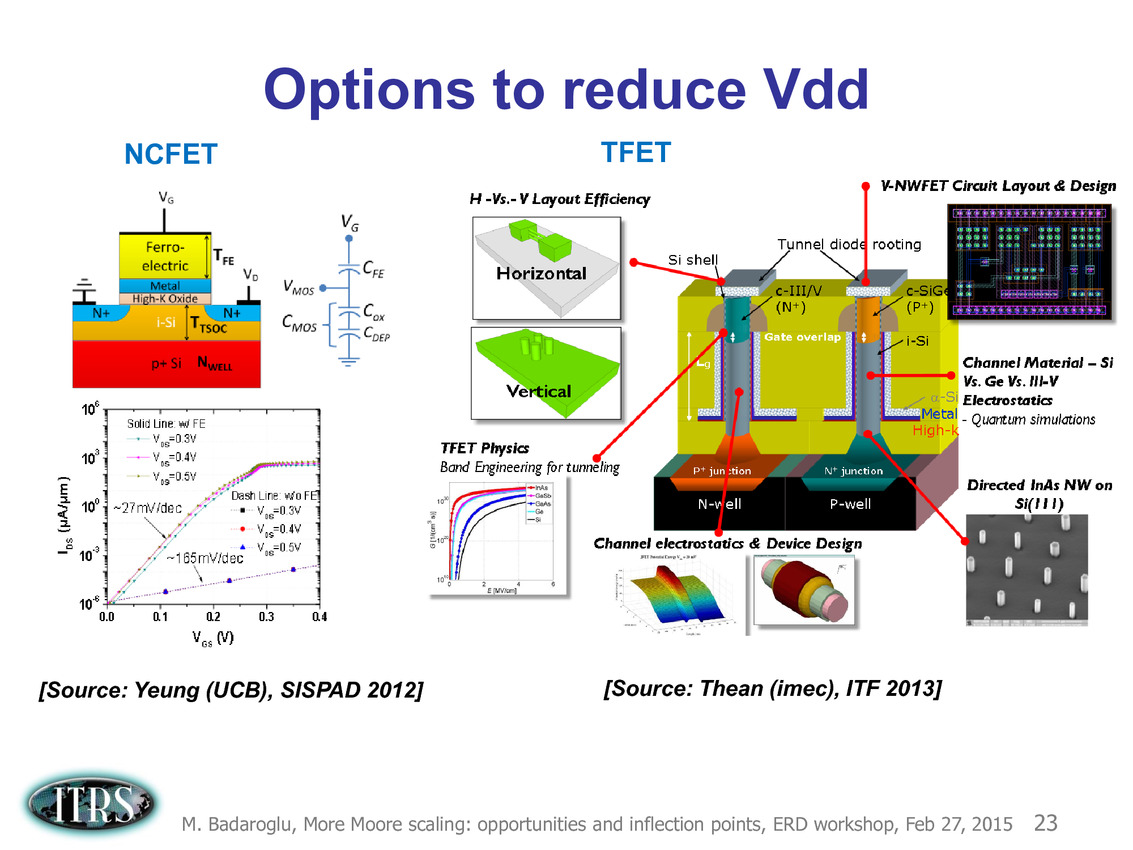
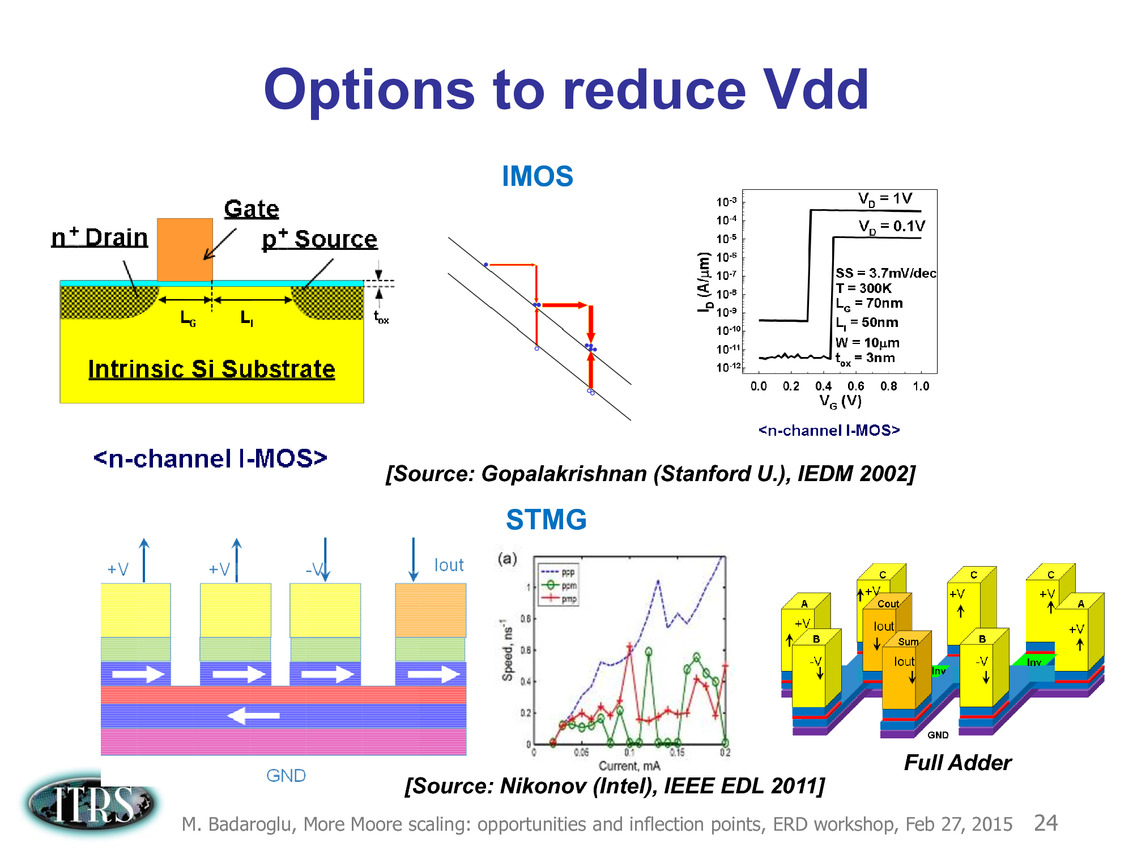
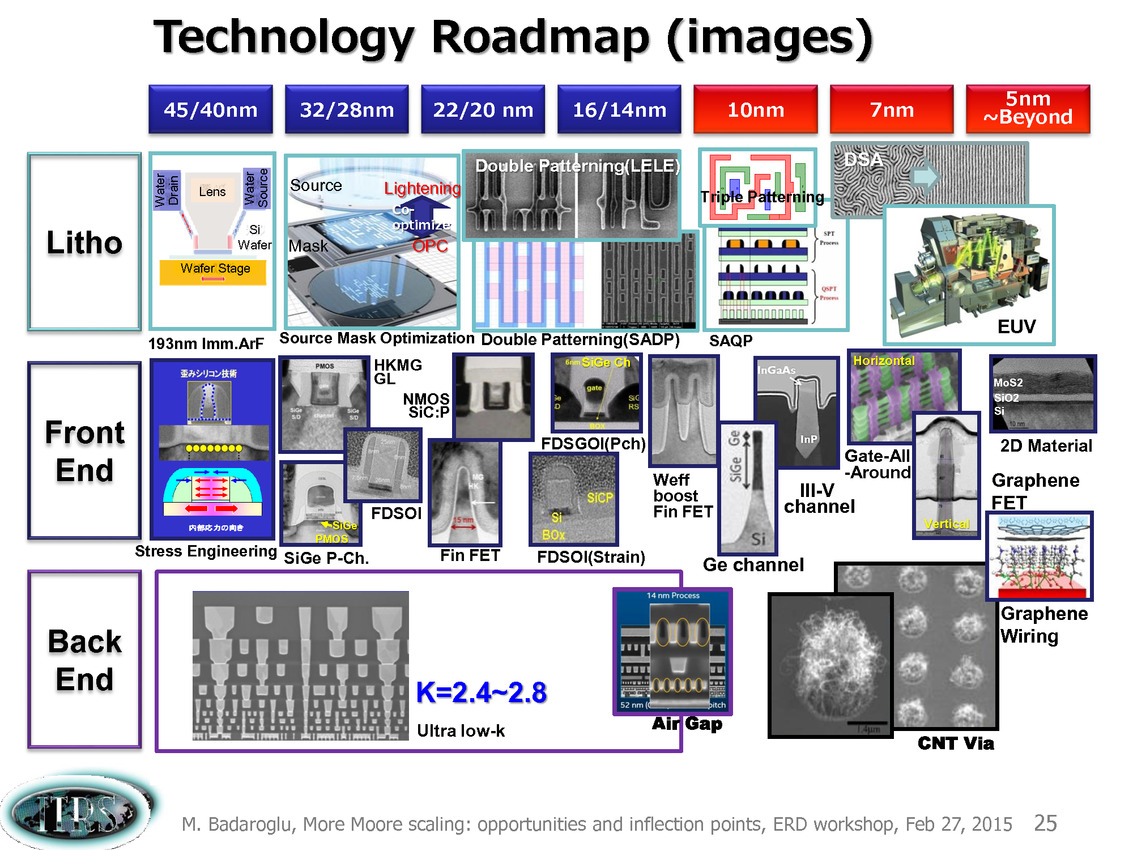

Une présentation intéressante qui évoque de multiples pistes et où l'on trouve un début de roadmap que nous avons remis ci-dessous :
En pratique, après l'ère de la mise à l'échelle géométrique, et l'ère des équivalences, l'ITRS évoque l'ère du "3D Power Scaling" dont les meilleurs représentants sont la NAND 3D ou des technologies comme la mémoire HBM. Des techniques complexes à appliquer aux puces logiques même si la présentation évoque quelques pistes et alternatives.
On attendra donc le mois prochain pour en savoir un peu plus !