
AMD Radeon R9 380X : les cartes Asus Strix et Sapphire Nitro en test
Publié le 30/11/2015 par Damien Triolet



GPU Tonga : 5 milliards de transistorsTonga est l'avant dernier GPU de la famille GCN et en dehors du support de la mémoire HBM, il partage avec le GPU Fiji (Radeon R9 Fury) toutes les dernières évolutions en date de l'architecture d'AMD, mais avec un nombre d'unités de calcul qui reste au niveau du premier GPU GCN, Tahiti (HD 7970).

Le GPU Tonga accompagné de sa mémoire GDDR5.
Alors que Tahiti est annoncé avec 4.3 milliards de transistors, qui occupent une surface de 352 mm², Tonga passe à 5.0 milliards de transistors pour 368 mm², selon nos mesures. Vous noterez au passage que la densité de transistors progresse quelque peu, ce qui est en partie lié à l'utilisation de contrôleurs mémoires plus denses.
Si Tonga est bien fabriqué en 28 nm, tout porte à croire qu'il en exploite, tout comme Fiji, une variante particulière. Synapse Design, qui fournit différents services autour de la conception de puces, et qui compte AMD parmi ses clients, a dévoilé dans une présentation que l'un de ses clients avait développé 2 GPU en 28 nm HPM, l'un de plus de 350 mm² et l'autre de plus de 500 mm², ce qui correspond de toute évidence à Tonga et Fiji.
Le 28nm HPM est la variante la plus avancée du 28 nm de TSMC et, sur le papier tout du moins, elle peut offrir un meilleur compromis que le 28 nm HP (utilisé par les autres GPU GCN ainsi que par les GPU Nvidia) au niveau du rendement énergétique tout en maintenant un haut niveau de performances (fréquence). La prestation de Tonga, que ce soit en terme de rendement énergétique ou de fréquence, ne montre cependant aucun avantage et au contraire ces deux points semblent légèrement en retrait en pratique.
Un bus mémoire 384-bit ?Si tous les dérivés actuellement commercialisés du GPU Tonga se contentent d'un bus mémoire de 256-bit,un doute subsiste quant à la possibilité que la puce embarque en fait une interface mémoire de 384-bit, comme le GPU Tahiti.
AMD n'a jamais répondu clairement aux questions concernant ce point important, nous indiquant un coup que la configuration de Tonga est identique à celle de Tahiti, un autre que les dérivés de Tonga ont été configuré suivant la demande supposée du marché. De quoi nous laisser penser qu'AMD a peut-être sacrifié un tiers de la bande passante mémoire pour proposer des variantes 4 Go 256-bit avec un coût moindre que ne l'auraient été des variantes 3 Go 384-bit.
Rien ne nous permet cependant de confirmer cette théorie et il est possible que Tonga n'intègre réellement qu'un bus de 256-bit ou qu'une autre raison ait poussé AMD à limiter la largeur de ce bus. La théorie énergétique liée à des résultats moins bons que prévus avec le 28nm HPM ne serait alors pas délirante puisque Tonga en 256-bit est au moins aussi gourmand que Tahiti en 384-bit.
Par rapport à nos précédentes interrogations concernant Tonga, à savoir le nombre d'unités de calcul et la quantité de cache L2 présents, AMD a cette fois confirmé qu'il s'agit bien de 32 CU (2048 unités FP32) et de 512 Ko pour les cartes 256-bit.
Voici un résumé des caractéristiques de tous les GPU de la famille GCN :
Oland : GCN 1.0, 6 CU, 1 triangle par cycle, 8 ROP, L2 256 Ko, 128 bits
Cape Verde : GCN 1.0, 10 CU, 1 triangle par cycle, 16 ROP, L2 512 Ko, 128 bits
Bonaire : GCN 1.1, 14 CU, 2 triangles par cycle, 16 ROP, L2 512 Ko, 128 bits
Pitcairn : GCN 1.0, 20 CU, 2 triangles par cycle, 32 ROP, L2 512 Ko, 256 bits
Tahiti : GCN 1.0, 32 CU, 2 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
Tonga : GCN 1.2, 32 CU, 4 triangles par cycle, 32 ROP, L2 512 Ko (768 Ko?), 256 bits (384 bits?)
Hawaii : GCN 1.1, 44 CU, 4 triangles par cycle, 64 ROP, L2 1024 Ko, 512 bits
Fiji : GCN 1.2, 64 CU, 4 triangles par cycle, 64 ROP, L2 2048 Ko, 4096 bits HBM
Et en image pour Tonga et Tahiti (dans le cas de Tonga nous avons représenté la possibilité qu'il intègre physiquement un bus 384-bit et 768 Ko de L2) :
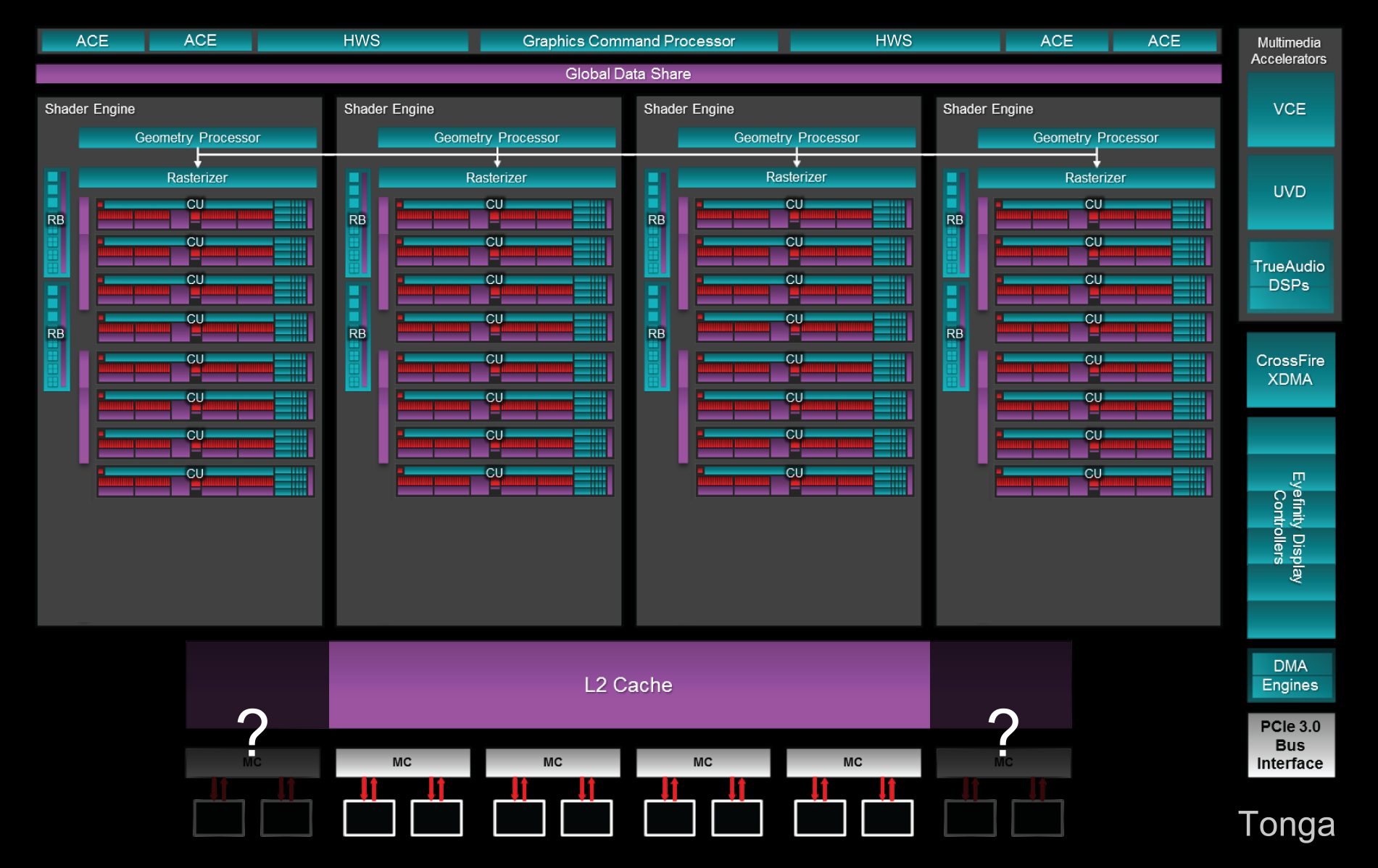
[ Tonga ] [ Tahiti ]
Par rapport à Tahiti, Tonga voit certes son bus mémoire amputé, mais AMD a mis en place des mécanismes pour en réduire l'impact (compression) et a doublé le nombre de processeurs géométriques chargés de la prise en charge des primitives, de leur découpe en pixels et de la tessellation.
AMD a également modifié le front-end du GPU dans le cadre du calcul haute performance. Alors que Tahiti se contente de 2 ACE (Asynchronous Compute Engine) pour assister le processeur de commande principal au niveau des tâches de type compute, Tonga passe à 4 ACE. Ces processeurs de commandes multitâches se chargent de la sélection/préemption des tâches à travers leurs files d'attente, de la distribution des tâches vers les unités de calcul et de l'exécution des commandes de synchronisation. Ils sont eux-mêmes assistés par 2 HWS (Hardware Scheduler) chargés de soulager le CPU dans la gestion de l'ordonnancement des files d'attentes et des tâches.
A noter que l'intégration d'ACE dans les GPU AMD leur permet de supporter le traitement concomitant de tâches graphiques et compute, ce qui autorise des gains de performances dans certaines situations sous Direct3D 12. L'architecture Maxwell de Nvidia souffre de certaines limitations à ce niveau comme nous l'avions expliqué ici.
Tonga : GCN 1.2Officiellement, AMD ne différencie pas les différentes itérations de son architecture GCN. Il y a du GCN, du GCN un peu vieux et du GCN un peu nouveau. Pas très pratique pour s'y retrouver Même s'il ne s'agit pas d'une forme sous laquelle communique AMD, nous préférons de notre côté parler de GCN 1.0 pour les premiers GPU de la famille, de GCN 1.1 pour Hawaii et Bonaire et de GCN 1.2 pour Tonga et Fiji.

AMD donne très peu de détails sur les nouveautés liées à GCN 1.2. Il est tout d'abord question d'une amélioration des performances en tessellation, un argument qui semble devenu obligatoire dans toutes les présentations de GPU. De notre côté nous n'avons pas remarqué d'évolution marquante. Ces optimisations ont probablement été mises en place pour limiter l'engorgement du GPU dans des cas spécifiques.
Ensuite, pour faire face à la réduction de la bande passante mémoire, AMD a mis en place de nouveaux algorithmes de compression sans perte du framebuffer. Plus spécifiquement, il s'agit de codage différentiel pour les couleurs, également appelé compression delta. Nvidia exploite également cette technique sur ses GPU Maxwell 2. Le principe de base consiste à ne pas enregistrer directement la couleur mais sa différence par rapport à une autre. Ce n'est bien entendu utile que quand l'écart entre deux couleurs est suffisamment faible, de manière à ce que cette information représente moins de bits que la couleur en elle-même. Ce support a dû être intégré au niveau des ROP et peut-être au niveau des unités de texturing, de manière à ce qu'elles soient capables de lires ces nouveaux formats de données.
A noter que comme Nvidia avec les GPU Maxwell, AMD a fait l'impasse sur la compression des textures ASTC pour ses GPU GCN 1.2. Nvidia nous avait expliqué que le coût de cette technologie était encore trop élevé au niveau des unités de texturing et n'avait pas de sens dans le cadre de gros GPU.
Avec GCN 1.2, AMD a mis à jour le jeu d'instruction du GPU. Il est question de nouvelles instructions 16-bit, autant en entier qu'en flottants. Une précision moindre qui permet potentiellement des gains d'énergie, suivant son implémentation. La précision 16-bit est avant tout exploitée dans le monde mobile mais elle pourrait également permettre de rendre plus efficaces certains algorithmes de traitement vidéo. D'autres instructions ont été ajoutées, dédiées aux échanges de données entre threads, pour réduire les accès à la mémoire partagée, ce que Nvidia fait également sur ses derniers GPU.
De notre côté, en observant le code compilé, nous avons pu remarquer que le support de quelques instructions semble avoir été supprimé (les fmac sont par exemple remplacés par des fmad), probablement parce qu'elles ne sont plus très utiles. Le code compilé est dans bien des cas constitué de légèrement moins d'instructions, ce qui peut potentiellement le rendre plus performant sur Tonga.
Comme toutes les puces GCN "1.1 et 1.2", Fiji support le niveau de fonctionnalité matérielle 12_0 de Direct3D, mais fait l'impasse sur le niveau 12_1 supporté par les GPU Nvidia Maxwell de seconde génération. Par contre, au niveau de l'autre niveau de spécification important de Direct3D12, les "Binding Resources" (le nombre de ressources à dispositions des développeurs), Fiji est au niveau maximum, Tier 3, là où les GPU Nvidia sont limités au niveau Tier 2. Autant AMD que Nvidia ont ainsi l'opportunité de proposer aux développeurs des effets graphiques qui seraient incompatibles avec le matériel de l'autre.
Pas de HDMI 2.0 ni de décodage H.265Lors de la sortie de Tonga, AMD avait annoncé avoir revu toute la partie vidéo. Tout d'abord avec un scaler de meilleure qualité, ensuite avec des mises à jour de ses moteurs d'encodage et de décodage.


Petite différence par rapport à Fiji, AMD n'a pas eu le temps d'intégrer le support du décodage H.265 (HEVC) à Tonga.
Enfin, tout comme Fiji cette fois, Tonga ne supporte pas le HDMI 2.0, une connectique nécessaire pour jouer confortablement sur une TV 4K en 60 Hz, peu de modèles intégrant une entrée DisplayPort. Cette absence n'est cependant pas un gros problème pour les dérivés de Tonga dont la puissance n'est pas réellement adaptée au jeu en 4K. La plupart des vidéos 4K pourront être affichées en 30 ou 24 Hz, mais certaines vidéos en 60 ou 48 Hz et/ou en HDR pourraient poser problème. Face à la concurrence dont les derniers produits supportent tous cette connectique, il ne s'agit malheureusement pas d'une absence anecdotique.
Sommaire
1 - Introduction, spécifications
2 - Tonga : 5 milliards de transistors, bus 384-bit?
3 - Asus Radeon R9 380X Strix OC
4 - Sapphire Radeon R9 380X Nitro
5 - Protocole de test
6 - Consommation et efficacité énergétique
7 - Bruit, température GPU et thermographie
8 - Benchmark : 3DMark Fire Strike
9 - Benchmark : Anno 2070
10 - Benchmark : Batman Arkham Origins
11 - Benchmark : Battlefield 4
12 - Benchmark : Crysis 3
13 - Benchmark : Dying Light
2 - Tonga : 5 milliards de transistors, bus 384-bit?
3 - Asus Radeon R9 380X Strix OC
4 - Sapphire Radeon R9 380X Nitro
5 - Protocole de test
6 - Consommation et efficacité énergétique
7 - Bruit, température GPU et thermographie
8 - Benchmark : 3DMark Fire Strike
9 - Benchmark : Anno 2070
10 - Benchmark : Batman Arkham Origins
11 - Benchmark : Battlefield 4
12 - Benchmark : Crysis 3
13 - Benchmark : Dying Light
14 - Benchmark : Evolve
15 - Benchmark : Fallout 4
16 - Benchmark : Far Cry 4
17 - Benchmark : GRID 2
18 - Benchmark : Hitman Absolution
19 - Benchmark : Project Cars
20 - Benchmark : Star Wars Battlefront
21 - Benchmark : The Witcher 3 Wild Hunt
22 - Benchmark : Tomb Raider
23 - Récapitulatif des performances
24 - Tonga vs Tahiti : round 2
25 - Conclusion
15 - Benchmark : Fallout 4
16 - Benchmark : Far Cry 4
17 - Benchmark : GRID 2
18 - Benchmark : Hitman Absolution
19 - Benchmark : Project Cars
20 - Benchmark : Star Wars Battlefront
21 - Benchmark : The Witcher 3 Wild Hunt
22 - Benchmark : Tomb Raider
23 - Récapitulatif des performances
24 - Tonga vs Tahiti : round 2
25 - Conclusion
Vos réactions
Contenus relatifs
- [+] 04/12: Tonga a bien un bus 384-bit
- [+] 30/11: AMD Radeon R9 380X : les cartes Asu...
- [+] 19/11: AMD lance la Radeon R9 380X
- [+] 18/06: AMD lance les Radeon R300 : vaste r...
- [+] 04/09: AMD Radeon R9 285 : Tonga, la Sapph...
- [+] 26/08: R9 285 compacte chez Sapphire
- [+] 23/08: AMD annonce la Radeon R9 285 et fêt...
- [+] 12/08: AMD dévoile le GPU milieu de gamme ...