
Intel Core i7 et Core i5 LGA 1155 Sandy Bridge



Un anneau pour les gouverner tousNotre étude de Nehalem avait soulevé les problèmes engendrés par la présence d'un cache L3 partagé entre plusieurs cores, notamment :
- la difficulté à répondre aux requêtes simultanées de quatre cores. Nous avions vu que les caches L2 permettaient d'intercepter une bonne partie de ces requêtes, soulageant d'autant le cache partagé ;
- laugmentation avec le nombre de cores du temps nécessaire au maintien de la cohérence entre le LLC et les caches intermédiaires, appelée « cache snooping ».
Sur Sandy Bridge, le problème est aggravé par le partage supplémentaire avec le GPU, sans compter l'annonce de modèles 8 coeurs prévus pour le second semestre 2011 (les Sandy Bridge-EP).
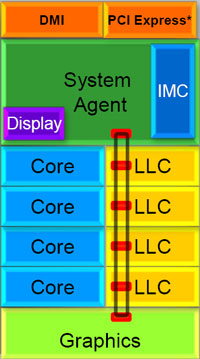
La solution imaginée par les ingénieurs d'Intel consiste en l'implémentation d'une interconnexion de type bus en anneau (ring bus) entre les agents susceptibles d'accéder au cache partagé. L'anneau joue un rôle d'arbitre au design simple et aux avantages multiples : chemins courts, et augmentation facile du nombre d'agents qui peuvent s'y connecter.
Un arbitrage de ce type se rencontre parfois sur les processeurs graphiques, dont certaines ressources sont partagées entre beaucoup d'unités. L'avantage du système de ne pas se complexifier avec l'augmentation du nombre d'acteurs promet ainsi de futurs modèles avec un cache partagé entre plus que 4 cores et un GPU, et le rend parfaitement adapté aux plateformes multiprocesseurs.
L'anneau relie les quatre principaux éléments du processeur : les cores, le GPU, le cache LLC, et l'agent système qui regroupe la partie uncore du processeur (contrôleur mémoire, contrôleur PCI-Express, interface DMI et moteur graphique). Etant donné que chaque étape davancement dans le bus nécessite un cycle, le GPU, peu sensible à la latence des accès mémoire, est positionné à lopposé de lagent système. L'anneau est composé de quatre voies, qui se distinguent par la nature des informations qui y transitent : données, requêtes, validation, et snoop.
En pratique, bien quIntel mentionne spécifiquement un bus en anneau unidirectionnel, celui-ci se comporte plutôt comme un bus linéaire bi-directionnel. Ceci est dû à deux points : dune part, les cores CPU disposent chacun de deux accès au bus en anneau et dautre part, les transferts empruntent toujours le chemin le plus court.
Au niveau de limplémentation physique, Intel profite de sa maîtrise du procédé de fabrication pour câbler lanneau par-dessus le cache LLC. Ce positionnement qui demande quelques petites optimisations au niveau des interconnexions, permet déviter daugmenter la taille de la puce.
Le sous-système de cachesLa hiérarchie des caches de Sandy Bridge est directement héritée de celle de Nehalem, tout en apportant son lot d'améliorations. La plus notable est, comme nous l'avons vu précédemment, l'ajout du uop cache de 1,5 Ko, épaulant les 32 Ko du cache L1 d'instructions. Celui-ci voit son associativité passer à 8 voies (4 sur Nehalem). Lors de notre étude du Nehalem, nous avons expliqué que l'associativité à 4 voies permettait au L1I de garder une faible latence (car la gestion des voies consomme des cycles). La présence du uop cache tire la latence globale de l'ensemble du cache code vers le bas, ce qui a permis d'augmenter l'associativité du L1I sans impact négatif sur la latence constatée. Les caches L1 de données et L2 du Sandy Bridge, de 32 et 256 Ko, sont quant à eux identiques à ceux du Nehalem.

En ce qui concerne le cache L3 / LLC, celui-ci voit son organisation bouleversée. Les contraintes de partage ont conduit à la présence de l'anneau qui modifie la communication entre le L3 et les différents éléments du processeur (cores et GPU). La gestion par l'anneau simplifiant les contraintes de maintien de cohérence entre les caches, le L3 est désormais découpé en sous blocs (4 sous blocs de 2 Mo pour les versions à 8 Mo de L3). Les avantages sont multiples :
- les sous-blocs étant accessibles en même temps, le L3 offre une bande passante accrue ;
- la latence d'accès aux blocs de taille réduite est inférieure à celle du L3 monobloc du Nehalem ;
A noter que le L3 appartient désormais aux mêmes domaines de fréquence et de tension que les cores, à la différence de celui de Nehalem qui tournait à la fréquence uncore.
Toutes ces améliorations rendent le L3 de SandyBridge significativement plus performant que celui de Nehalem. Les mesures de latence révèlent une latence moyenne de 31 cycles, à comparer aux 42 cycles de celui du Nehalem. La latence varie bien entendu suivant la position des données par rapport au core CPU qui y accède puisque chaque étape sur lanneau nécessite un cycle.
Sommaire
1 - L'architecture Sandy Bridge
2 - Les améliorations du core
3 - Les améliorations du core, suite
4 - Advanced Vector Extension (AVX)
5 - Turbo Boost version 2
6 - Socket LGA 1155, P67 et H67, LGA 2011
7 - Les Core i7 & i5 Sandy Bridge
8 - Intel HD Graphics 2000 & 3000
9 - Intel HD Graphics, conso, oc, perfs
10 - Intel HD Graphics, CPU vs IGP
11 - Intel HD Graphics, Vidéo et Quick Sync
12 - Consommation
2 - Les améliorations du core
3 - Les améliorations du core, suite
4 - Advanced Vector Extension (AVX)
5 - Turbo Boost version 2
6 - Socket LGA 1155, P67 et H67, LGA 2011
7 - Les Core i7 & i5 Sandy Bridge
8 - Intel HD Graphics 2000 & 3000
9 - Intel HD Graphics, conso, oc, perfs
10 - Intel HD Graphics, CPU vs IGP
11 - Intel HD Graphics, Vidéo et Quick Sync
12 - Consommation
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 03/04: Intel lance la 2ème vague de sa 8èm...
- [+] 05/10: Intel Core i7-8700K, Core i5-8600K,...
- [+] 12/09: Core i7-7820X : Un Skylake-X mieux ...
- [+] 07/09: Les Skylake en fin de vie chez Inte...
- [+] 23/08: Coffee Lake incompatible avec les L...
- [+] 29/06: Intel Core i9-7900X et Core i7-7740...
- [+] 03/01: Core i5-7600K et i7-7700K : pour qu...
- [+] 28/12: Gigabyte BRIX Gaming GT