
L'architecture AMD K10
Publié le 13/09/2007 par Franck Delattre



Les caches du K10Les latences induites par les accès mémoire représentent une des principales sources de ralentissement d'un pipeline de traitement. L'arme principale du processeur pour masquer ces latences réside dans son sous-système de caches. On mesure dès lors toute l'importance que revêt la hiérarchie de caches dans les spécifications d'une architecture, et à ce titre l'Athlon 64 repose sur une hiérachie de caches qui a prouvé son efficacité.
Il semble donc naturel que le K10 s'en inspire fortement, pour ne pas dire totalement pour les niveaux de cache L1 et L2 dont l'influence est la plus notable sur les performances. Nous ne ferons donc ici qu'énumérer des paramètres bien connus de tous : chacun des quatre cores intègre ainsi un gros cache L1 splitté en 64 Ko pour les instructions et 64 Ko pour les données, secondé d'un cache L2 unifié exclusif de 512 Ko.
Les performances de ce sous-système largement éprouvé reposent majoritairement sur le choix d'un cache L1 de très grande capacité (la plus grande toutes architectures confondues) et rapide. Chacun des L1 de 64 Ko est associatif à deux voies, ce qui signifie qu'il est (de façon schématique) organisé en deux blocs de 32 Ko chacun. Ces caches jouent donc la carte de la localité : un bloc d'une telle taille est capable de contenir une grande quantité de données ou d'instructions contigües. Cette propension à la localité est logiquement au détriment de la spatialité, le L1 ne peut ainsi couvrir que deux régions en mémoire à un instant donnée. Le cache L2 compense cette relative faiblesse en offrant à l'inverse une associativité élevée eu-égard à sa taille (512 Ko et associatif à 16 voies). L'association de ces deux niveaux assure ainsi un bon niveau de performance en toutes circonstances.

Cette efficacité en association est une des raisons pour lesquelles AMD a gardé un cache L2 dédié à chacun des quatre cores de son K10, en comparaison à une solution de cache L2 partagé. C'est donc presque tout naturellement qu'un troisième niveau de cache a été introduit sur le K10. Partagé entre les quatre cores, le L3 n'a pas pour vocation première d'augmenter la performance de chaque core pris individuellement, mais plutôt d'assurer la performance des quatre cores travaillant de concert. Ce L3 participe pour une grande part au caractère "natif" de l'architecture à quatre cores du K10, assurant une voie de communication "on-die" entre les cores.
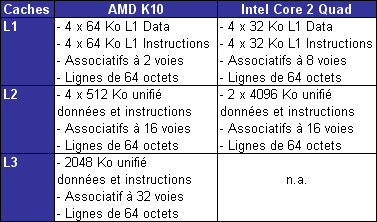
Le partage du cache entre quatre cores est une première. La mise au point d'un tel mécanisme est complexe, car les conflits entre les threads peuvent anéantir tout le bénéfice du cache, voire devenir une source de ralentissement. Afin de réduire les conflits, le L3 du K10 offre 32 voies d'associativité, soit la plus grande valeur observée jusqu'ici sur un cache de processeur x86.
Il faut noter que comme sur K8, les hiérarchies de cache des processeurs AMD K10 se distinguent par la relation exclusive qui lie les niveaux successifs. A titre de rappel, un cache exclusif de niveau 2 par exemple reçoit les données évincées du cache L1, mais ne contient pas de copie des données ou des instructions remontées depuis la mémoire vers le L1. Ainsi, données et instructions sont exclusivement présentes dans un des deux niveaux de cache, mais jamais dans les deux à la fois. En comparaison à une relation de type inclusif, dans laquelle le L2 contient une copie du L1, la relation exclusive offre des performances légèrement en retrait (la mise en cache nécessite une étape supplémentaire afin de sauvegarder la ligne évincée, opération inutile en relation inclusive), à la faveur d'une quantité de cache utile plus importante (égale à la somme des tailles) et d'un souplesse dans l'implémentation (pas de contraintes sur les tailles).
Bien que fortement inspirés du K8, les caches du K10 ont été adaptés aux nouvelles capacités du processeur, en particulier de la LSU (Load-Store Unit). La LSU du K10 est capable d'effectuer deux opérations de lecture / écriture 128 bits par cycle, là où le K8 est limité à deux opérations 64 bits. Afin de ne pas ralentir la LSU ainsi dopée, les L1 du K10 ont été retouchés afin de fournir une bande passante double en comparaison à celle fournie par les caches du K8. Même traitement pour le bus reliant les caches L2 au contrôleur mémoire, doublé de 64 à 128 bits. Ce dernier point devrait combler la relative faiblesse de la bande passante offerte par le cache L2 des K8, assez en retrait par rapport aux L2 hyper performants des processeurs Intel.
Sommaire
1 - Rester dans la course
2 - Quatre cores, enfin
3 - Un IPC boosté
4 - Les caches du K10
5 - Les caches, suite
2 - Quatre cores, enfin
3 - Un IPC boosté
4 - Les caches du K10
5 - Les caches, suite
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !