
Hercules 3D Prophet 4500
Publié le 02/04/2001 par Marc Prieur



Le Kyro II
 15 Millions de transistors gravés en 0.18 Micron, voilà qui semble peu comparé aux autres chips graphiques sensés évoluer dans la même catégorie : en effet, le GeForce2 GTS est composé de 25 Millions de transistors, contre 30 pour le Radeon. Reste qu´une bonne partie de ces transistors sont utilisés pour des fonctions DX7 que ne supportent pas le Kyro II, tel le Transformation & Lighting.
15 Millions de transistors gravés en 0.18 Micron, voilà qui semble peu comparé aux autres chips graphiques sensés évoluer dans la même catégorie : en effet, le GeForce2 GTS est composé de 25 Millions de transistors, contre 30 pour le Radeon. Reste qu´une bonne partie de ces transistors sont utilisés pour des fonctions DX7 que ne supportent pas le Kyro II, tel le Transformation & Lighting.Son fillrate tout comme sa bande passante mémoire semblent ridicules. En effet, cadencé à 175 MHz, il offre grâce à ces deux pixel pipeline un fillrate de 350 Mpixels/s - 350 Mtexels/s. Coté mémoire, il dispose d´un bus 128 bits SDR pouvant gérer 16, 32 ou 64 Mo de mémoire. A 175 MHz, cela correspond à une bande passante mémoire de 2.6 Go/s. A titre de comparaison, un Radeon DDR offre un fillrate théorique de 333 Mpixels/s - 1 Gtexels/s et une bande passante mémoire de 4.94 Go/s, contre 800 Mpixels/s - 1.6 Gtexels/s et 4.94 Go/s pour un GeForce2 GTS.
Dans ce cas, comment ce chip offrant sur le papier des performances brutes dignes d´un TNT2 est il annoncé comme concurrent des GeForce2 GTS et autres Radeon DDR ? La réponse se trouve dans le Tile Rendering ...
Le Tile RenderingLancé il y´a 5 ans avec le PowerVR PCX1, l´idée du Tile Rendering part d´un concept tout simple. Comme vous le savez déjà, dans une architecture graphique traditionnelle, le rendu de tous les pixels est effectué, qu´il soient visibles ou non. C´est la valeur Z qui déterminera ensuite si ce pixel sera visible, et s´il faut donc l´écrire ou pas dans le frame buffer.

Le but du Tile Rendering est tout simplement de déterminer si un pixel est visible ou pas AVANT d´en effectuer le rendu et non pas APRES, afin d´économiser en bande passante mémoire et en puissance de rendu. Le gain en performances est très important, puisque dans une scène qui a une ´depth complexity´ de 3 (en moyenne trois pixels de mêmes coordonnées X,Y mais de coordonnées Z différentes pour chaque point à l´écran), on peut économiser jusqu´a 66% de la puissance de rendu et de la bande passante mémoire. Dans une telle scène, un Kyro II offrira en théorie des performances équivalentes à un chip ´traditionnel´ disposant d´un fillrate de 1050 Mpixels /s.
Je vous entends déjà dire que ATI et NVIDIA disposent de technologies similaires dans le Radeon (Hierachical Z) et le GeForce3 (Z-Occlusion Culling). S´il est vrai que ces deux techniques ont le même but que le Tile Rendering, c´est à dire économiser en bande passante et en fillrate en ne rendant que les pixels visibles, elles sont toutefois moins poussées.
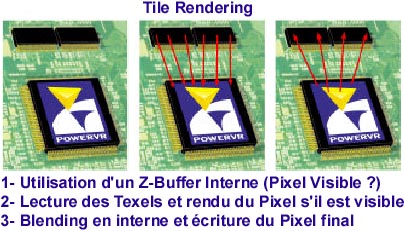
En effet, le Tile Rendering, s´il économise de la puissance en permettant d´effectuer uniquement le rendu des pixels visibles, permet également d´économiser en bande passante mémoire puisque l´architecture PowerVR dispose d´un Z-Buffer interne. Comment est ce possible ? C´est simple, avant d´effectuer le rendu d´une scène, le Kyro II la découpe en blocs de 16x32 pixels. Chacun de ces blocs (tile) étant rendu indépendamment les un des autres, il n´est pas nécessaire de disposer d´un Z-Buffer de taille important.
Du coup, le Kyro II intègre un Z-Buffer 24 bits interne d´une taille de 12 Ko, ce qui est suffisant pour déterminer les pixels visibles ou non dans chacun des blocs. L´intérêt de disposer d´un Z-Buffer interne au chip est double : d´une part, il est plus rapide (jusqu´a 32 calculs Z par cycle d´horloge) et d´autre part, il permet d´économiser en bande passante mémoire. En effet, dans une scène en 1024*768 dotée d´une Depth Complexity de 3, la lecture de la donnée Z (en 24 bits) requiert 1.58 Go/s à 30 images/s !
Pour finir, le blending (mélange) se fait en interne dans le Tile Buffer. Du coup, le Kyro II peut appliquer jusqu´a 8 textures sur un seul pixel sans avoir besoin d´accéder au frame buffer. Avec une architecture traditionnelle, si vous devez appliquer quatre textures sur un pixel mais que votre accélérateur graphique ne peut en plaquer que deux par cycle, il faudra le faire en deux fois ce qui nécessitera une écriture en frame buffer supplémentaire ainsi qu´une relecture des données géométriques relatives au pixel à texturer.
Sommaire
1 - Introduction, l'historique
2 - Le Kyro II, le Tile Rendering
3 - Autres fonctions, La carte
4 - Le test
5 - Quake III : Arena, FSAA
6 - Serious Sam, MDK2
2 - Le Kyro II, le Tile Rendering
3 - Autres fonctions, La carte
4 - Le test
5 - Quake III : Arena, FSAA
6 - Serious Sam, MDK2
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...