
Nvidia dévoile le GV100: 15 Tflops, 900 Go/s



Nvidia profite de sa GPU Technology Conference pour dévoiler quelques détails sur le GV100, le premier GPU de la génération Volta qui sera dédié au monde du calcul et en particulier de l'intelligence artificielle.

Comme c'est à peu près le cas chaque année, le CEO de Nvidia Jen Hsun Huang vient de profiter de la GTC pour dévoiler les grandes lignes du premier GPU de sa future génération Volta. Ce sera un monstre clairement orienté vers l'intelligence artificielle, un débouché qui monte en puissance pour les GPU Nvidia.
Le GV100 est le successeur direct du GP100 et reprend un format similaire : il s'agit d'une puce énorme placée sur un interposer avec 4 modules HBM2. Grossièrement c'est la même chose en mieux : plus gros et plus évolué.
Plus gros tout d'abord avec un GV100 qui profite de la gravure en 12 nm FFN de TSMC (personnalisé pour Nvidia) pour passer à 21.1 milliards de transistors, plus de 30% de plus que les 15.3 milliards du GP100. Malgré le passage au 12 nm, la densité ne progresse presque pas et le GV100 est énorme avec 815 mm² contre 610 mm² pour le GP100. Le 12 nm permet ici avant tout de pouvoir monter en puissance à consommation similaire.

Tout comme le GP100, le GV100 utilise des "demi SM" par rapport aux GPU grand public. Leur nombre passe de 60 à 84, ce qui représente 5376 unités de calcul. Ils restent répartis dans 6 blocs principaux, les GPC, ce qui laisse penser que Nvidia a tout misé sur un gain de puissance de calcul, sans trop toucher au débit de triangles ou de pixels qui étaient déjà à un niveau très élevé sur GP100.
Comme sur le GP100, ces SM sont capables de traiter différents niveau de précision : FP16 (x2), FP32 et FP64 (/2). Par ailleurs, Nvidia a ajouté quelques instructions spécifiques au deep learning et y fait référence en tant que tensor cores. Ils permettent aux algorithmes qui y feront appel de doubler la mise par rapport aux instructions 8-bits (produit scalaire avec accumulation) des GPU Pascal (sauf GP100) et du futur Vega d'AMD. A voir évidemment dans quelle mesure les différents algorithmes de deep learning pourront profiter de ces nouvelles instructions.
Nvidia en a profité pour améliorer le sous-système mémoire qui sera plus flexible pour demander moins d'efforts d'optimisation de la part des développeurs. Le cache L2 passe de 4 à 6 Mo et de la HBM2 Samsung plus rapide est exploitée mais qui restera au départ limitée à 4 Go par module soit 16 Go au total. Par ailleurs, le GV100 profite de 6 liens NV-Link de seconde génération (25 Go/s dans chaque direction) pour offrir une interface qui peut monter à 300 Go/s.

Le premier accélérateur qui profitera du GV100 est comme nous pouvions nous y attendre le Tesla GV100 qui sera initialement proposé dans un format de type mezzanine. Un tel module sera bien entendu gourmand mais Nvidia parle d'une enveloppe thermique maximale qui reste à 300W. Par ailleurs, deux modes énergétique seront proposé : Maximum Performance et Maximum Efficiency. Le premier autorise le GV100 à profiter de toute son enveloppe de 300W alors que le second limite probablement la tension maximale pour maintenir le GPU au meilleur rendement possible, ce qui a évidemment du sens pour de très gros serveurs.
Sur le Tesla GV100, le GPU sera amputé de quelques unités de calcul, pour faciliter la production seuls 80 des 84 SM seront actifs. Voici ce que cela donne :
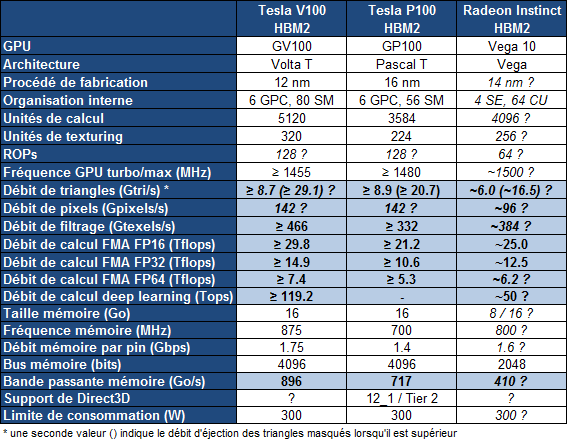
Le Tesla GV100 augmente la puissance brute de 40% par rapport au Tesla GP100, mais ses différentes optimisations feraient progresser les performances en pratique de +/- 60% dans le cadre du deep learning selon Nvidia. La bande passante mémoire progresse un peu moins avec "seulement" +25%, mais le cache L2 plus important et diverses améliorations compensent quelque peu cela.
Le GV100 devrait devancer assez facilement le Vega 10 d'AMD, mais ce dernier devrait être commercialisé en version Radeon Instinct à un tarif nettement moindre que le Tesla GV100 et en principe plus tôt. Nvidia parle de son côté du troisième trimestre et de 150.000$ pour les premiers serveurs DGX-1 équipés en GV100 et de la fin de l'année pour les accélérateurs au format PCI Express. Nvidia proposera évidemment d'ici-là des versions mises à jour de ses logiciels, compilateurs et autres librairies dédiées au deep learning.
Contenus relatifs
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 21/06: Tesla V100 décliné en PCIe
- [+] 10/05: Nvidia dévoile le GV100: 15 Tflops,...
- [+] 13/04: GTC: Nvidia annonce CUDA 8, prêt po...
- [+] 08/04: GTC: Supermicro premier sur le Tesl...
- [+] 08/04: GTC: Tesla P100: débits PCIe et NVL...
- [+] 06/04: GTC: Nvidia DGX-1: 8 Tesla P100 pou...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 06/08: Nvidia rachète PGI, The Portland Gr...