
Actualités informatiques du 13-04-2016
- GTC: Nvidia annonce CUDA 8, prêt pour Pascal
- ASRock annonce les i7 Broadwell-E et ses bios
- La 3D NAND arrive chez Micron, MX300 en vue ?
| Avril 2016 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | |
GTC: Nvidia annonce CUDA 8, prêt pour Pascal



Comme souvent, l'arrivée d'une nouvelle architecture est associée à une révision majeure de CUDA, l'environnement logiciel de Nvidia destiné au calcul massivement parallèle. Ce sera évidemment le cas pour les GPU Pascal qui pourront profiter dès cet été d'un CUDA 8 taillé sur mesure. Au menu : un support plus évolué de la mémoire unifiée, un profilage plus efficace et un compilateur plus rapide.

La principale nouveauté de CUDA 8 sera le support complet de l'architecture Pascal et particulièrement du GP100 qui équipe l'accélérateur Tesla P100. Déjà introduit avec CUDA 7.5 pour permettre aux développeurs de s'y préparer, le support de la demi-précision (FP16) sera finalisé et pourra permettre des gains conséquents pour les algorithmes qui peuvent s'en contenter. Dans le cas du GP100, CUDA 8 ajoutera évidemment le pilotage des accès mémoire à travers les liens NVLink.
La plus grosse évolution est cependant à chercher du côté de la mémoire unifiée qui va faire un bond en avant avec Pascal, ou tout du moins avec le GP100 puisque nous ne sommes pas certains que les autres GPU Pascal en proposeront un même niveau de support. Si vous avez l'impression qu'on vous a annoncé le support de cette mémoire unifiée avec chaque nouveau GPU, ne vous inquiétez pas, vous n'avez pas rêvé, nous avons la même impression.
Elle est en fait supportée depuis CUDA 6 pour les GPU Kepler et Maxwell mais de façon limitée, que nous pourrions qualifier d'émulée. Pour ces GPU, l'espace de mémoire unifié est en fait dédoublé dans la mémoire centrale et dans la mémoire physiquement associée au GPU. L'ensemble logiciel CUDA se charge de piloter et de synchroniser ces deux espaces mémoires pour qu'ils n'en représentent qu'un seul du point de vue du développeur. De quoi faciliter sa tâche mais au prix de sérieuses limitations : la zone de mémoire unifiée ne peut dépasser la quantité de mémoire rattachée au GPU, le CPU et le GPU ne peuvent y accéder simultanément et de nombreuses synchronisations systématiques sont nécessaires pour forcer la cohérence entre les copies CPU et GPU de cette mémoire.
Pour proposer un support plus avancé de la mémoire unifiée, des modifications matérielles étaient nécessaires au niveau du GPU, ce qui explique pourquoi nous estimons possible que cela soit spécifique au GP100. Tout d'abord l'extension de l'espace mémoire adressable à 49-bit pour permettre de couvrir l'espace de 48-bit des CPU ainsi que la mémoire propre à chaque GPU du système. Ensuite la prise en charge des erreurs de page qui permet d'éviter les coûteuses synchronisations systématiques. Si un kernel essaye d'accéder à une page qui ne réside pas dans la mémoire physique du GPU, il va produire une erreur qui va permettre suivant les cas soit de rapatrier localement la page en question, soit d'y accéder directement à travers le bus PCI Express ou un lien NVLink.
La cohérence peut ainsi être garantie automatiquement, ce qui permet aux CPU et aux GPU d'accéder simultanément à la zone de mémoire unifiée. Sur certaines plateformes, la mémoire allouée par l'allocateur de l'OS sera par défaut de la mémoire unifiée, et il ne sera plus nécessaire d'allouer une zone mémoire spécifique. Nvidia indique travailler à l'intégration de ce support avec Red Hat et la communauté Linux. Par ailleurs, CUDA 8 étend également le support de la mémoire unifiée à Mac OS X.

Ce support plus avancé de la mémoire unifiée va faciliter le travail des développeurs et surtout rendre plus abordable leurs premiers pas sur les GPU tout en maintenant un relativement bon niveau de performances. Tout du moins si le pilote et le runtime CUDA font leur travail correctement puisque c'est à ce niveau que tout va se jouer. A noter que les développeurs plus expérimentés conservent la possibilité de gérer explicitement la mémoire.
Parmi les autres nouveautés, Nvidia introduit une première version de la librairie nvGRAPH (limitée au mono GPU) qui fournit des routines destinées à accélérer certains algorithmes spécifiques au traitement des graphes. Traiter rapidement les opérations sur ces structures mathématique prend de plus en plus d'importance, que ce soit pour les moteurs de recherche, la publicité ciblée, l'analyse des réseaux ou encore la génomique. Faciliter l'exécution de ces opérations sur le GPU est donc important pour leur ouvrir la porte à de nouveaux marchés potentiels.
Une autre évolution importante est à chercher du côté des outils de profilages qui vont dorénavant fournir une analyse des dépendances. De quoi par exemple permettre de mieux détecter que les performances sont limitées par un kernel qui bloque le CPU trop longtemps. Ces outils revus prennent également en compte NVLink et la bande passante utilisée à ce niveau.
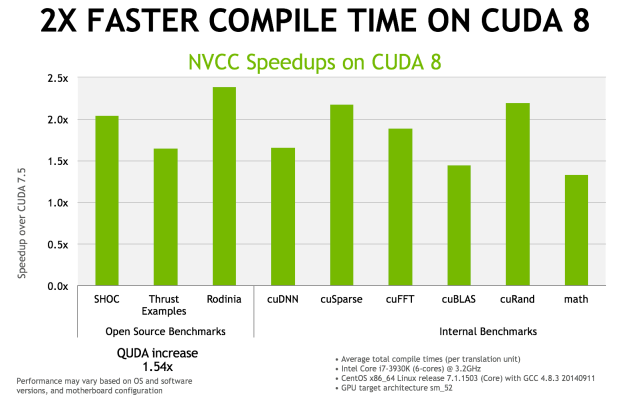
Enfin, le compilateur NVCC 8.0 a reçu de nombreuses optimisations pour réduire le temps de compilation. Nvidia annonce qu'il serait réduit de moitié, voire plus, dans de nombreux cas. Ce compilateur étend également le support expérimental des expressions lambda de C++11.
La sortie de CUDA 8.0 est prévue pour le mois d'août mais une release candidate devrait être proposée dès le mois de juin.
ASRock annonce les i7 Broadwell-E et ses bios

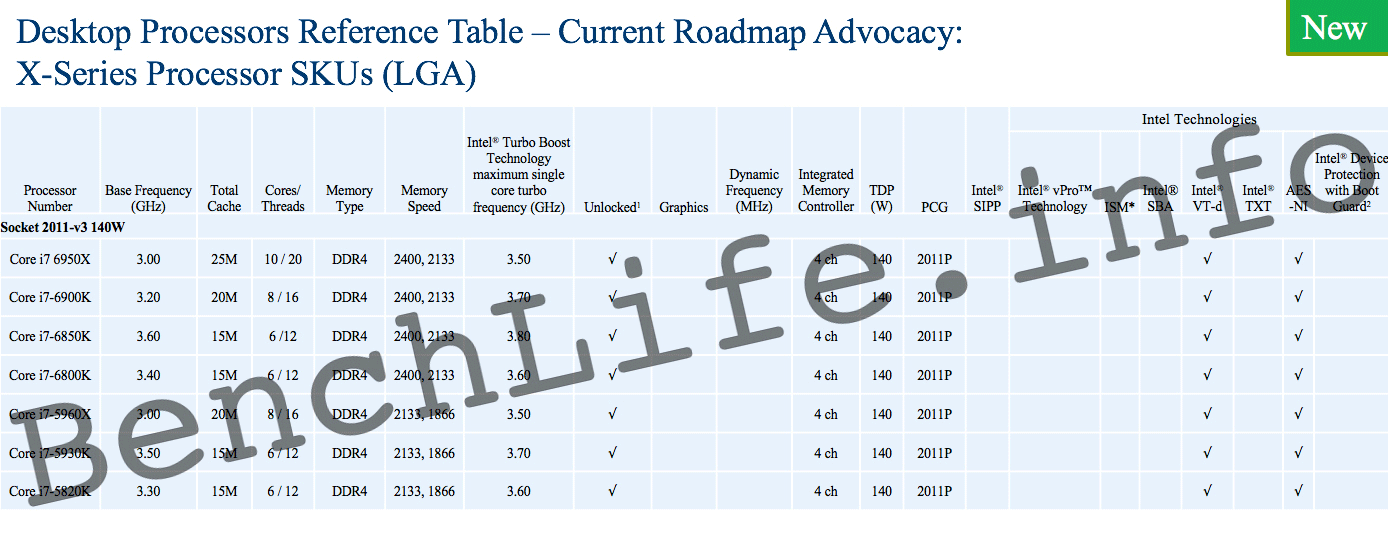
Tout comme MSI il y a quelques jours et Gigabyte en janvier, ASRock vient de publier de nouveaux bios compatibles Broadwell-E pour ses cartes mères X99. Au passage, le constructeur a grillé la politesse à Intel en confirmant l'existence de quatre références : Core i7-6950X, i7-6900K, i7-6850K et i7-6800K. Il en profite pour préciser que le Core i7-6950X dispose de 10 coeurs, comme l'indiquent les rumeurs depuis novembre dernier. Pour la date de disponibilité et les tarifs ASRock ne précise rien et il faudra donc pour cette partie attendre la véritable annonce d'Intel !
La 3D NAND arrive chez Micron, MX300 en vue ?
Nous l'indiquions il y a peu, la 3D NAND IMFT (Micron / Intel) semble prête puisque Intel a dégainé le premier avec une gamme de SSD professionnels l'utilisant. Micron affute également ses armes puisqu'il a indiqué hier lors d'un webcast qu'un nouveau SSD 2.5" grand public utilisant la 3D NAND arriverait en avril, probablement sous la dénomination Crucial MX300. La 3D NAND sera également déclinée en juin sur une gamme de SSD OEM en 2.5", M.2 et mSATA.

Par ailleurs Micron a annoncé ses premiers SSD PCIe NVMe, les Micron 9100 et 7100 qui sont destinés aux professionnels. Tous deux sont basés sur de la NAND MLC 16nm et sont destinés au monde professionnel. Le 9100 sera disponible en versions carte fille et 2.5", pour le 7100 ce sera 2.5" et m.2. Pour le 7100 Micron a précisé que le contrôleur utilisé serait un Marvell 88SS1093 et que les capacités iraient de 400 Go à 1,92 To en 2.5", 400 à 960 Go en m.2. La 3D NAND devrait pour sa part être intégrée dans des solutions professionnelles à compter du second semestre.
Concernant la PRAM 3D Xpoint annoncée en juillet 2015, Micron a précisé qu'on devrait la "voir" cette année, ce qui n'est pas forcément très clair. Rappelons que lors de l'annonce Intel et Micron avaient indiqués qu'elle était en production, avant que Micron ne précise en janvier dernier qu'il faudrait encore 12 à 18 mois pour lancer la production en volume.