
Actualités informatiques du 06-04-2016
- GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
- Plextor passe à la TLC avec le M7V
- AMD pré-annonce Bristol Ridge
- Rise of the Tomb Raider avec les GTX 960
- GTC: N'attendez pas de GeForce en GP100 !
| Avril 2016 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | |
GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$



Lors de la keynote d'ouverture de la GTC, Jen-Hsun Huang ne s'est pas contenté d'annoncer l'accélérateur Tesla P100, mais a également dévoilé un nouveau serveur qui sera commercialisé sous sa propre marque : le DGX-1. Orienté deep learning, ce supercalculateur embarque pas moins de 8 Tesla P100 pour un tarif de 129.000$ HTVA.

On n'est jamais aussi bien servi que par soi-même. C'est probablement ce qu'a dû se dire Nvidia pour accélérer la disponibilité du Tesla P100 sur un marché qui peut prendre du temps à bouger de lui-même, d'autant plus quand la compétition est rude et quand la plateforme change significativement. Après quelques expériences avec les serveurs GRID VCA (Visual Computing Appliance) et Quadro VCA, Nvidia propose ainsi un supercalculateur orienté vers le deep learning, un domaine en pleine explosion et pour lequel l'architecture Pascal a été optimisée.
Le DGX-1 est un serveur 3U capable d'atteindre 170 Tflops FP16, mode de calcul basse précision qui peut être exploité par les algorithmes de deep learning. Il atteint également 85 Tflops en FP32 et 42 Tflops en FP64 grâce à l'intégration de GPU Pascal. De quoi permettre à Nvidia de mettre en avant un gain de 75x au niveau de la vitesse d'entrainement d'un réseau de neurones artificiels par rapport à un serveur qui se conterait de CPU classiques.

Ce supercalculateur très dense embarque pas moins de 8 accélérateurs Tesla P100, chacun équipé de 16 Go de mémoire HBM2. Ceux-ci sont pilotés par 2 Xeon E5-2698 v3 (16 coeurs à 2.3 GHz), chacun associé à 256 Go de DDR4 2133. Nvidia a également opté pour un stockage plutôt costaud avec 4 SSD de 1.92 To en RAID 0. De quoi pouvoir prendre en charge de larges datasets. Si le DGX-1 est relativement compact au vu de la puissance de calcul qu'il embarque, il n'est par contre pas léger avec 60 kg sur la balance, ce qui s'explique en partie par l'alimentation et le refroidissement qui sont prévus pour encaisser 3200W, dont 2400W rien que pour les 8 Tesla P100.
Nvidia a bien entendu prévu le DGX-1 pour profiter pleinement de la connectique NVLink. Pour rappel, chaque GPU GP100 intègre 4 de ces liens qui offrent chacun une bande passante bidirectionnelle de 40 Go/s . Voici la topologie qui a été retenue et que Nvidia nomme NVLink Hybrid Cube Mesh :
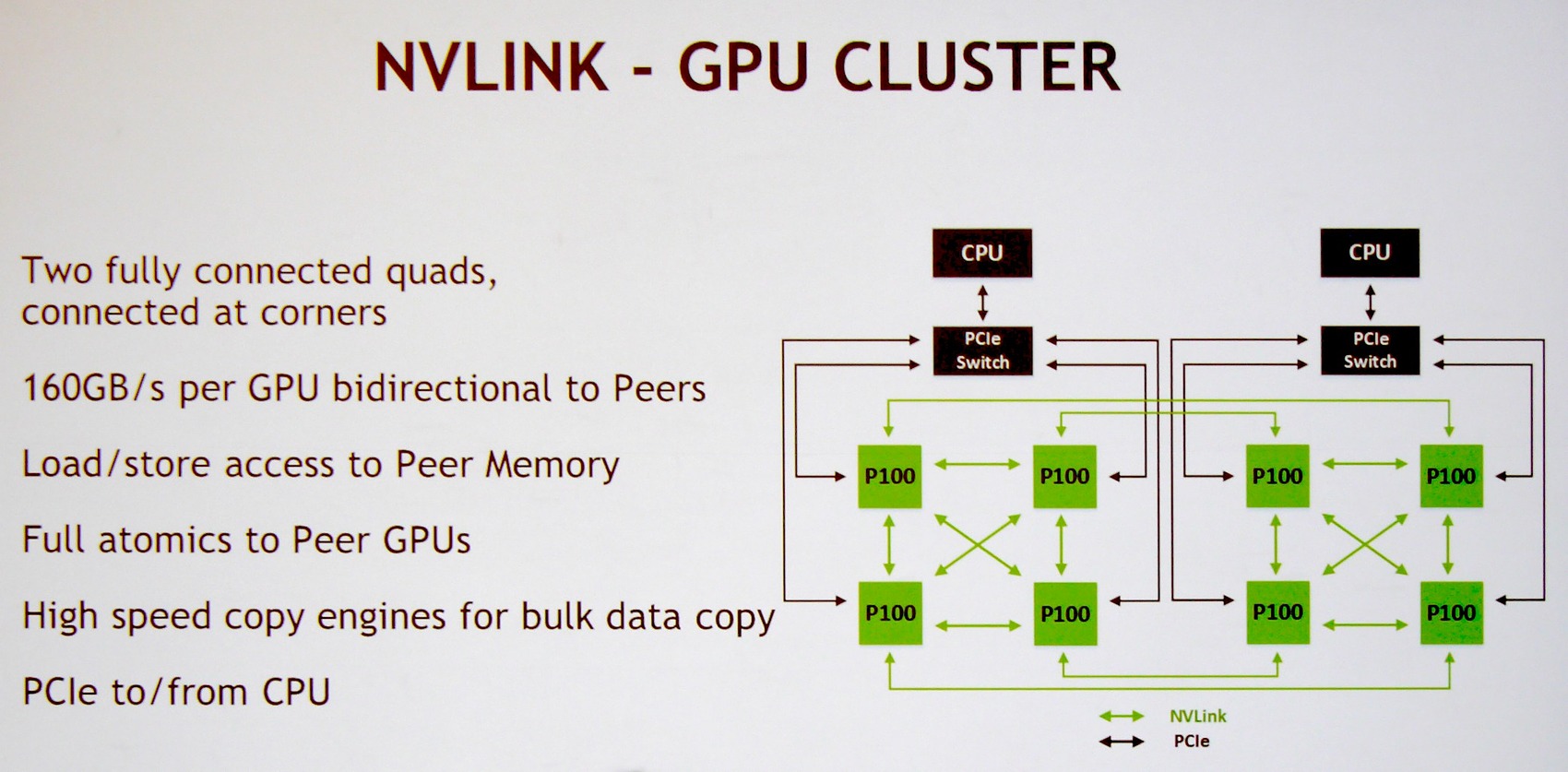
Assez logiquement 4 Tesla P100 sont reliés à chaque CPU via des liens PCI Express qui passent par un switch. Ensuite ces 4 GPU sont reliés entre eux via 3 de leurs liens NVLink. Enfin, leur quatrième lien est exploité pour les relier à l'un des GPU du second groupe de 4 Tesla P100. Il y aura donc quelques limitations au niveau de la communication entre ces 2 groupes de Tesla P100, mais elle est maintenue possible par cette topologie.
Nvidia annonce une disponibilité dès le mois de juin pour le DGX-1, ce qui semble très rapide, même si dans un premier temps cela ne concernera que les Etats-Unis. Il faudra en effet attendre le troisième trimestre pour une disponibilité plus globale.
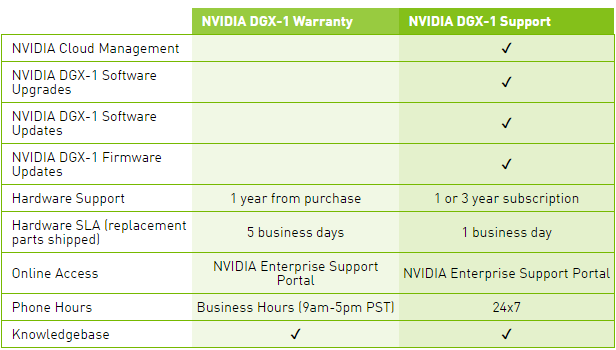
Le tarif communiqué par Nvidia monte à pas moins de 129.000$ HTVA, et ce pour le package basique, Warranty, qui n'inclus aucune mise à jour pour la suite logicielle, ce qui est étrange compte tenu de l'évolution très rapide et continuelle de ses outils dédiés au deep learning. Pour avoir accès à ces mises à jour, il faudra ajouter une cotisation annuelle pour passer au package Support.
Une politique tarifaire qui nous laissent penser que l'accélérateur Tesla P100 seul sera commercialisé à un prix très élevé. Nous ne serions pas étonnés de voir Nvidia atteindre la barre symbolique des 10.000$.
Plextor passe à la TLC avec le M7V
Plextor vient d'annoncer sa première gamme de produit utilisant de la NAND TLC, les M7V. Déclinés à la fois en format M.2 et 2.5", ils sont disponibles en versions 128, 256 et 512 Go. Les performances annoncées sont aux limites de l'interface SATA en séquentiel, avec 560 Mo /s en lecture et 500 à 530 Mo /s en écriture. En accès 4K aléatoires on est 97K-98K IOPS en lecture et 51K IOPS en écriture sur le 128 Go contre 84K IOPS en 256 et 512 Go.

Pour atteindre un tel niveau de performance Plextor fait appel à l'habituel mode "Turbo" ici dénommé PlexNitro et qui permet d'utiliser la mémoire TLC en mode SLC. Les détails de ce mode ne sont toutefois pas communiqués et on ne sait donc pas, comme c'est malheureusement systématiquement le cas sur les SSD d'entrée de gamme, quelle est la durée durant laquelle la vitesse Turbo peut être supportée ni les performances obtenues une fois sortie de cette zone.

Plextor annonce par contre qu'il est capable de supporter 2000 cycles d'écritures sur la Flash TLC utilisée comme c'est le cas sur un 850 EVO pourtant équipé de V-NAND, alors que sur les autres SSD concurrents utilisant de la TLC "2D" on est habituellement à 500 ou 1000 cycles et 3000 cycles en MLC. Les détails permettant d'atteindre ce chiffre ne sont par contre pas précisés, si ce n'est l'appel à une correction d'erreur de type LDPC et non plus BCH.
Côté contrôleur Plextor a fait confiance à un Marvell 88SS1074B1 qui est associé à de la TLC Toshiba 15nm ainsi qu'à 256, 512 Mo ou 1 Go de cache DRAM. L'endurance évolue également avec la capacité et est annoncée à 80, 160 ou 320 To alors que la garantie est de 3 ans. A titre de comparaison en TLC chez Crucial le BX200 est annoncée à 72 To quelle que soit la capacité, OCZ parle de 30/60/120/240 To en versions 120/240/480/960 Go pour le Trion 150, alors que pour le 850 EVO en TLC 3D Samsung annonce 75 To en 120/250 Go et 150 To en 500 Go/1 To tandis que Sandisk se garde d'annoncer un chiffre pour l'Ultra II.
On notera au passage que le M7V arrive au terme d'un processus très long chez Plextor concernant la TLC. Au CES 2013, Plextor faisait déjà la démonstration d'un prototype qui devait être lancé mi-2013. Il aura donc fallu plus de trois ans pour finaliser un premier produit en TLC, mais vu les chiffres d'endurance annoncés ce n'est pas forcément une mauvaise chose... au contraire des performances annoncées qui se limitent au mode Turbo !
AMD pré-annonce Bristol Ridge
AMD vient d'annoncer l'arrivée, en avance sur le planning initial, de ses AMD A-Series de 7è génération, un décompte que nous avions déjà eu l'occasion de critiquer lors du lancement de Carrizo.
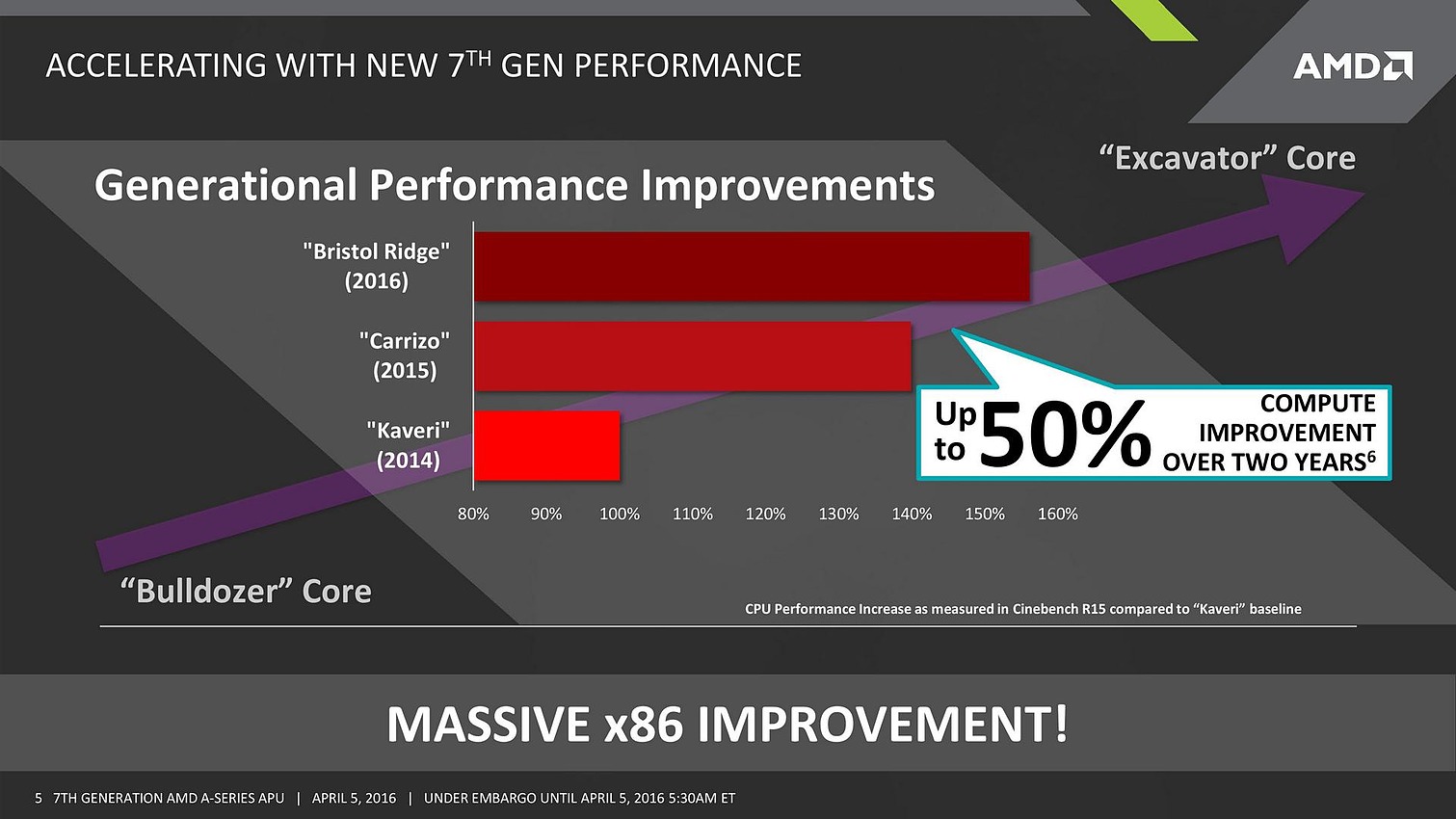
Derrière cette dénomination se cache Bristol Ridge, qui prend donc la suite de Carrizo et qui aura la particularité d'être également décliné sur desktop en version AM4, un socket commun avec les futurs AMD FX basés sur l'architecture Zen. Si la "vraie" annonce de ces APU doit toujours se faire au Computex début juin, HP a eu l'exclusivité des premières livraisons pour son nouvel HP ENVY x360 qui vient d'être lancé d'où cette "pré-annonce" assez avare en détails puisque le communiqué de presse se limite à parler d'un gain en calcul pouvant dépasser les 50% par rapport au APU d'il y a deux ans. La génération précédente d'ENVY x360 étant basé sur des Broadwell, il s'agit donc d'un design win significatif pour AMD.

La présentation ci-dessous permet toutefois d'en apprendre plus. Si Carrizo gérait déjà la DDR4 comme le prouve son support dans certaines versions embarquées, sur les CPU destinés aux portables il se limitait officiellement à la DDR3. En comparant un FX-8800P dit de 6è génération avec un AMD A12 de 7è génération disposant lui-aussi d'un TDP de 15 watts, AMD arrive à un gain de 18% sous 3DMark 11, 5% sous PCMark 8 v2 et 11,59% sous Cinebench 1T. Le gain du communiqué sous Cinebench 1T également, cette-fois en comparant à un AMD FX-7500 en Kaveri. Côté Intel, AMD utilise comme base de comparaison un Core i7-6500U et annonce des performances 5% inférieures sous PC Mark 8 v2 mais 50% supérieures sous 3D Mark 11.
Sachant que la partie x86 se base toujours Excavator, le gain de 11,59% sous Cinebench doit être lié à une hausse notable de la fréquence Turbo alors que la partie graphique profitera probablement également d'un petit gain en fréquence mais aussi du passage dans le test de la DDR3-1600 à la DDR4-1866. Des choix étonnant puisque Carrizo supporte normalement jusqu'à la DDR3-2133 et, dans sa version embarquée, la DDR4-2400. En attendant d'en savoir plus nous sommes donc assez sceptiques sur les véritables nouveautés apportées par Bristol Ridge qui permettent à AMD de parler d'une nouvelle génération !






Rise of the Tomb Raider avec les GTX 960
Après l'avoir offert en début d'année sur les gammes supérieures, Nvidia offre désormais Rise of the Tomb Raider avec les GTX 960. Pour rappels les GTX 970, 980 et 980 Ti profitent à l'heure actuelle du titre The Division.

Comme d'habitude cette offre n'est valable que chez les revendeurs partenaires affichant l'offre. Ils vous fourniront généralement après le délai de rétractation un premier code qui permettra d'obtenir auprès de Nvidia un second code pour télécharger le jeu sur Steam.
GTC: N'attendez pas de GeForce en GP100 !
Si le GP100 a fait les gros titres de la GTC, il est désormais presque certain en ce qui nous concerne qu'il n'y aura pas de GeForce l'utilisant, hormis peut-être une Titan mais même à ce niveau rien n'est moins sûr. Ce GPU de plus de 15 milliards de transistors fait de nombreux compromis totalement orientés vers le calcul haute performance et qui n'ont pas spécialement d'intérêt dans le cadre du rendu temps réel pour les jeux vidéo. C'est par exemple le cas de la double précision ou encore des liens NVLink.
Par ailleurs, le marché du GPU computing et surtout le potentiel énorme du deep learning sont des éléments suffisamment importants pour justifier de la part de Nvidia d'enfin investir dans la production d'une puce spécifique au marché professionnel.

Sur la GTC, Nvidia a systématiquement refusé de répondre à toute question concernant les dérivés grand public du GP100 et de la Tesla P100. Même au niveau des cartes Quadro. De quoi donner du poids à l'impression que le GP100 pourrait être dédié au GPU computing, voire même n'offrir aucune sortie vidéo pour se concentrer sur la connectique NVLink.
C'est en fait une supposition que nous faisons depuis quelques temps et qui de toute évidence est en train de se concrétiser. Bien que nous n'ayons pas pu en avoir la confirmation officielle de Nvidia, plusieurs sources externes nous ont confirmé que notre intuition était correcte et qu'il n'y aura donc pas de GeForce basée sur le premier gros GPU Pascal.
Cela ne veut pas dire que Nvidia abandonne les joueurs, bien au contraire ! Un GPU dédié, clairement orienté haut de gamme serait en cours de finalisation et devrait être annoncé sous peu d'après nos informations. Celui-ci devrait se contenter de GDDR5 ou de GDDR5X et exploiter la totalité de ses transistors pour les besoins du rendu temps réel.
Face au coût très élevé de la mémoire HBM et de son interposer, ainsi que de la production limitée qui en découle, Nvidia aurait fait le choix pragmatique de développer deux solutions haut de gamme en parallèle. Affaire à suivre.