
Actualités informatiques du 08-04-2016
- GTC: 200 mm² pour le petit GPU Pascal ?
- GTC: Supermicro premier sur le Tesla P100 ?
- GTC: Tesla P100: débits PCIe et NVLink mesurés
- GTC: HBM 2 SK Hynix : quelques détails
| Avril 2016 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | |
GTC: 200 mm² pour le petit GPU Pascal ?



Il y 3 mois, lors du CES, Jen-Hsun Huang avait présenté le Drive PX 2, le nouveau boîtier dédié à la conduite autonome de Nvidia qui embarque entre autre deux GPU Pascal. Seul petit problème c'est alors un prototype équipé de GM204 Maxwell et non de GPU Pascal qu'avait présenté Jen-Hsun Huang, en oubliant de préciser ce détail, ce qui n'avait pas manqué de susciter la polémique.

Le CEO de Nvidia a profité de la GTC pour rectifier cela en affichant cette fois le "vrai" Drive PX 2 équipé des nouvelles puces Pascal. Le module était ensuite visible dans la zone d'exposition de la GTC mais Nvidia avait malheureusement pris soin de le positionner de manière à ce que les GPU ne soient pas clairement visibles. Nous pouvions cependant les apercevoir suffisamment pour obtenir un second angle de vue pour confirmer la taille de la puce.


Sur la photo où Jen-Hsun Huang présente le Drive PX 2, nous mesurons à peu près 200 mm², alors que sur les autres photos nous sommes plutôt à 205 mm². Suffisamment proche pour pouvoir estimer la taille de ce GPU Pascal (GP106 ?) à +/- 200 mm² en 16nm.
Les spécifications de ce GPU ne sont pas encore connues, tout ce que nous savons est qu'il atteint 4 TFlops dans la configuration qui a été retenue pour le Drive PX 2 et qu'il semble équipé d'un bus mémoire de 128-bit vu la bande passante annoncée de 80 Go /s et malgré la présence de 8 puces 32 bits. De quoi imaginer par exemple un plus gros GPU Pascal grand public (GP102 ? GP104 ?) qui pourrait doubler tout cela. 350 à 400 mm² en 16nm, 8 TFlops et un bus mémoire GDDR5X 256-bit pourrait correspondre à ce que nous prépare Nvidia.
GTC: Supermicro premier sur le Tesla P100 ?
Supermicro exposait à la GTC un prototype non fonctionnel de serveur 1U à base de Tesla P100. Celui-ci est prévu pour embarquer 4 de ces accélérateurs ainsi qu'une configuration bi-Xeon et une carte graphique ou un autre accélérateur au format PCI Express 16x. Le fabricant taiwanais explique que le nouveau format de type mezzanine et les liens NVLink ont demandé pas mal de travail lors de la conception du serveur.

C'est notamment le cas au niveau du refroidissement qui est un challenge évident compte tenu de la consommation qui monte à 300W par Tesla P100 alors que la densité progresse compte tenu de la compacité de cette solution. Supermicro a ainsi décidé de placer ces 4 accélérateurs, surmontés d'imposants radiateurs, côte à côte juste après l'entrée d'air frais, ce qui permet de les refroidir tous de la même manière.

Supermicro précise que certains concurrents ont opté pour une autre organisation, avec par exemple un "carré" de Tesla P100, et que d'après ses essais, il y a beaucoup de risques que les GPU les plus éloignés de l'entrée d'air en souffrent, par exemple en atteignant plus rapidement leur limite de température.
Malgré l'état de la solution exposée, Supermicro nous a confirmé être très proche de la finalisation de ce serveur et s'attendre à être le premier sur le marché, tout du moins si Nvidia ne tarde pas à livrer les Tesla P100.
GTC: Tesla P100: débits PCIe et NVLink mesurés
Lors d'une session de la GTC consacrée à GPUDirect, qui regroupe les techniques de communications entre GPU et avec d'autres éléments d'un système, nous avons pu en apprendre un peu plus sur les performances du GP100 au niveau de ses voies de communication.
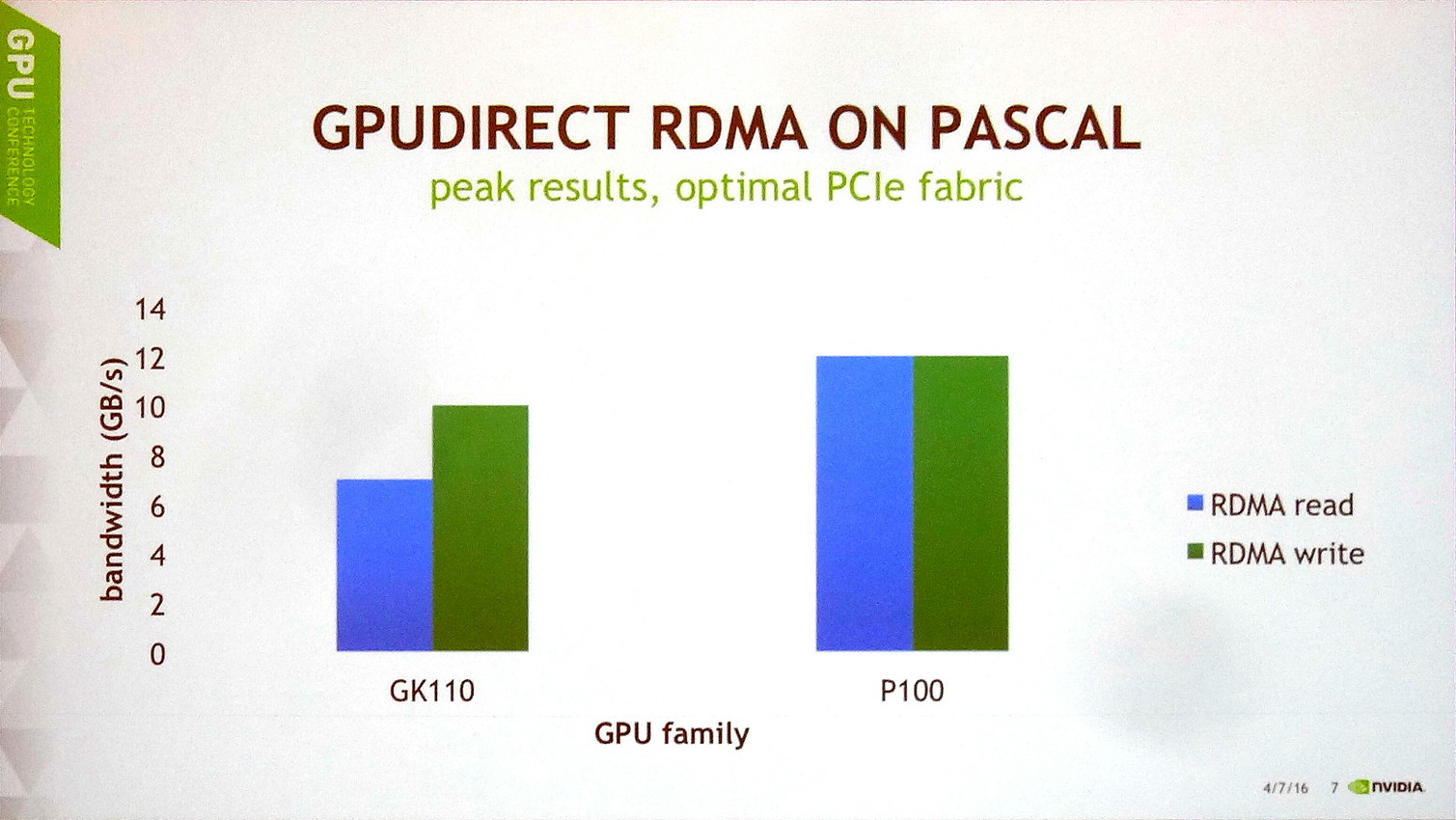
Il y a tout d'abord des progrès au niveau du PCI Express. Nvidia explique que les GPU Kepler et Maxwell souffraient de quelques limitations et devaient se contenter d'à peu près 10 Go/s en écriture et de 7 Go/s en lecture. Cela change avec Pascal dont le tissu PCI Express est dorénavant optimal pour une interface 16x 3.0, ce qui lui permet d'atteindre 12 Go/s dans les deux sens, soit à peu près le maximum théorique.
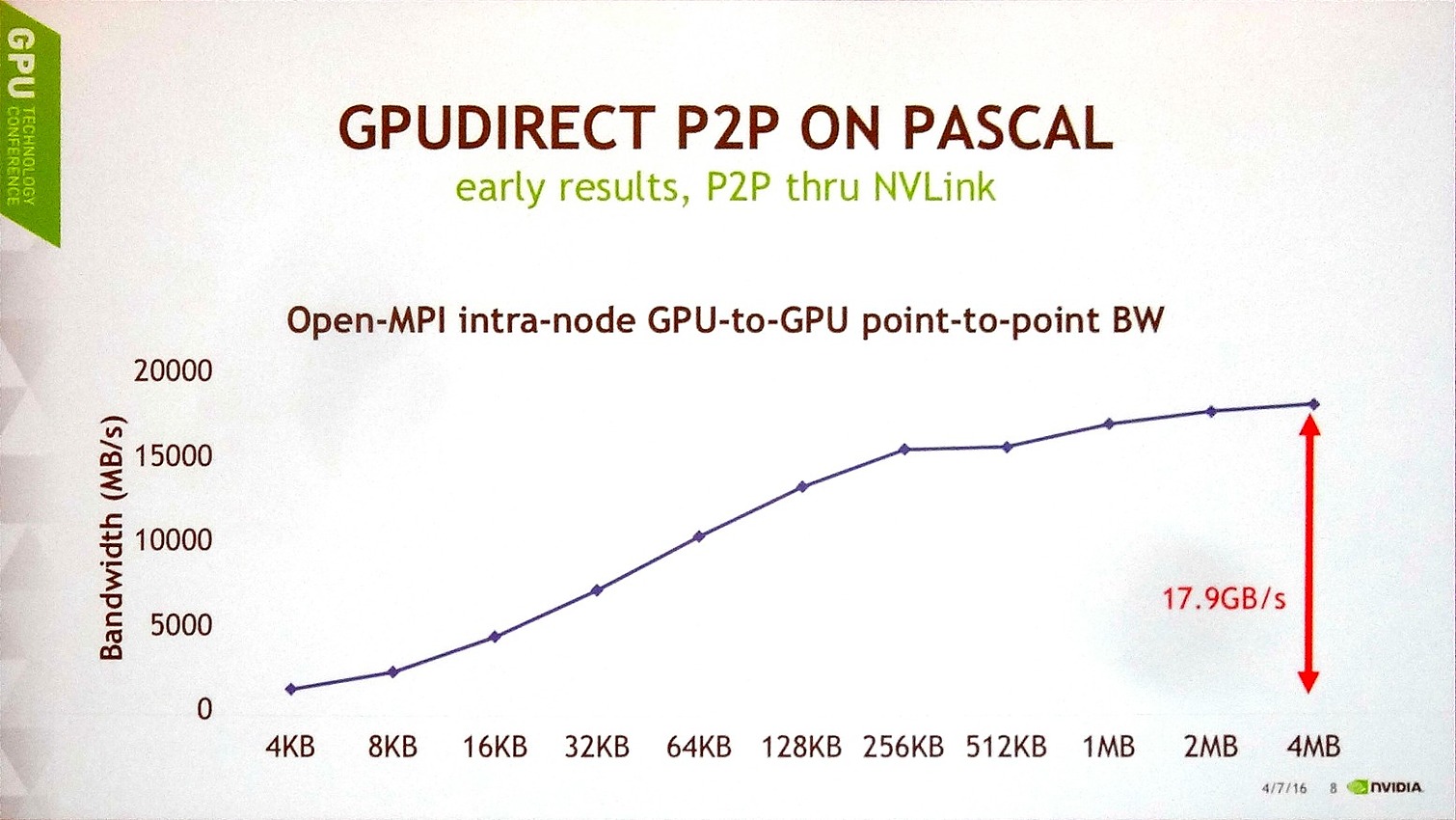
Ensuite, Nvidia a publié les premiers chiffres de débits obtenus pour les liens NVLink en communication point-à-point entre 2 GP100, tout en précisant que toutes les optimisations n'avaient pas encore été mises en place. Pour ce test, un seul lien NVLink est ici exploité et le transfert est unidirectionnel.
Avec des blocs de 4 Mo, le GP100 parvient à monter à 17.9 Go/s, ce qui est plutôt pas mal compte tenu du fait que l'interface est spécifiée à 20 Go/s dans chaque direction. Le débit reste supérieur à 15 Go/s avec des blocs de 256 Ko, mais plonge rapidement sous cette valeur, ce qui est un résultat attendu pour toute voie de communication compte tenu du surcoût par transfert. Ces premiers résultats sont donc plutôt encourageants et Nvidia explique qu'ils sont obtenus grâce à l'intégration de moteurs de copies pour chaque lien NVLink.
GTC: HBM 2 SK Hynix : quelques détails
Bien que Nvidia ait dans un premier temps opté pour la mémoire HBM 2 de Samsung, de toute évidence parce qu'elle est la première disponible, SK Hynix avait comme chaque année fait le déplacement à la GTC. L'occasion de poser quelques questions au fabricant.

Concernant l'estimation de la disponibilité de cette mémoire, nous n'en saurons pas plus par rapport aux dernières rumeurs qui parlent du troisième trimestre. SK Hynix nous a par contre confirmé que ce serait bien le module 4Hi de 4 Go qui serait lancé en premier lieu, suivi par la version 8Hi de 8 Go et enfin par la version 2Hi de 2 Go. Le fabricant nous a expliqué que cette organisation de la production n'est par contre en rien liée à des challenges supplémentaires pour passer à 8 couches de DRAM ou pour condenser les canaux dans le cas de la version 2Hi. Ces choix auraient été effectués uniquement par rapport aux commandes fermes qui lui ont été passées.
Cette arrivée tardive de la version 2 Go, que l'on pourrait plutôt imaginer pour les solutions d'entrée de gamme démontre une fois de plus que ce type de technologie va prendre du temps à apparaître sur ce segment.
A noter que concernant la différence de consommation en passant d'un module 4Hi à 8Hi, SK Hynix n'a pas voulu communiquer de nombre précis mais après insistance nous a indiqué qu'il s'agissait d'un nombre à un chiffre, et que la différence n'aurait ainsi qu'un impact limité au vu de la consommation des GPU haut de gamme qui y seront associés. Ce ne serait donc pas un frein pour doubler la mémoire d'un Tesla P100 par exemple.
La mémoire HBM 2 Samsung exploitée par Nvidia sur le Tesla P100 a la particularité d'être de hauteur identique à celle du GPU GP100, ce qui facilite le refroidissement de l'ensemble. Pour cela, l'épaisseur de la dernière couche de DRAM a été adaptée à celle du GPU en prenant en compte tous les éléments de la chaîne d'assemblage, comme vous pouvez l'observer ci-dessous (le spacer est en fait la dernière couche de DRAM) :

Pour la mémoire HBM 2, et contrairement à la HBM 1, SK Hynix fait de même et propose une production personnalisée avec épaisseur variable des modules. Pour le fabricant ce n'est pas un souci dans un premier temps puisque cette mémoire correspond de toute manière à des commandes spécifiques. Par contre à l'avenir, SK Hynix s'attend à ce que le JEDEC standardise ce point ou tout du moins en limite les variantes à 2 ou 3 chaînes de production.