
Actualités divers
CES: Quatre écrans DisplayHDR en démo
CES: 7 écrans sur un portable via DisplayPort
CES: USB-PD via HDMI Alt-Mode
Samsung grave de la DRAM en ''1ynm''
Vesa lance un standard pour les écrans PC HDR
La GDDR6 annoncée disponible chez SK Hynix



Alors que Samsung vient d'annoncer le lancement de la production en volume de sa GDDR6, la dernière version du catalogue mémoire de SK Hynix indique que sa GDDR6 est désormais disponible même s'il faut bien dire que le constructeur a tendance à être optimiste sur ce genre de document.
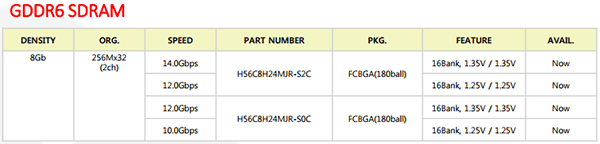
Il s'agit cette fois non pas de puces de 2 mais 1 Go, avec des vitesses de 10, 12 ou 14 Gbps là ou Samsung annonce 18 Gbps. Les 10 Gbps sont atteint en 1.25V et les 14 Gbps en 1.35V, les 12 Gbps étant disponibles dans les deux versions.
Les puces SK Hynix permettront de faire des cartes graphiques en GDDR6 256-bit avec 8 Go de mémoire alors qu'avec les puces 2 Go Samsung on est à 16 Go. Le gain en vitesse est par contre mesuré par rapport à la GDDR5X Micron qui atteint à ce jour 12 Gbps, on est donc que 16,7% au-dessus chez SK Hynix.
Samsung atteint 2.4 Gbps en HBM2
Samsung annonce le début de la production en volume d'une puce HBM2 de 8 Go fonctionnant à 2.4 Gbps et atteignant donc une bande passante de 307 Go/s via son bus 1024-bit ! Ce débit est atteint avec une tension de 1.2v, alors que la première génération de HBM2 nécessitait 1.35V à 2.0 Gbps.

Jusqu'alors on était au mieux à 2.0 Gbps, ce qui correspond d'ailleurs au maximum définit par la norme JEDEC HBM2, et en pratique AMD se contente de faire fonctionner la HBM2 à 1.9 Gbps et Nvidia à 1.75 Gbps.
CES: Un écran OLED 4K 21.6 pouces chez Asus !
Le stand d'Asus était l'occasion de voir quelques nouveautés originales, particulièrement du côté des écrans et du réseau. C'est aussi l'occasion pour nous de revenir sur certains produits entrevus un peu plus tôt dans la semaine. En aparté, vous aurez peut être remarqué que les cartes mères de prochaine génération (chez AMD ou Intel) ne sont pas montrées sur le salon, ou uniquement sous NDA, il faudra donc être un peu patient sur ce terrain.

Du côté des produits réseaux, Asus se lance dans la mode des routeurs "mesh" (un routeur accompagné de plusieurs modules pour étendre la portée WiFi) avec son Lyra Trio. Asus dit avoir travaillé sur la simplicité de configuration avec des applications mobiles (un critère sur lesquels les concurrents se battent déjà). Ce produit devrait être lancé au premier semestre, le prix n'étant pas encore déterminé. Ce qui est intéressant, c'est que les anciens routeurs du constructeur (certains modèles au moins) ont reçu une mise à jour pour les rendre compatibles avec ce mode mesh. Vous pouvez trouver la liste des modèles supportés en bas de cette page .

On notera que dans la même gamme, Asus montrait un routeur intégrant l'assistant Alexa d'Amazon. Ce Lyra Voice sera compatible avec les modules du kit Trio pour une utilisation mesh (ils devraient être vendus également de manière individuelle). La disponibilité de ce produit semble pour la fin de l'année. Notez qu'Asus montrait également un routeur 802.11ax avec WiFi "6 Gbps".

Nous avions mentionné un peu plus tôt qu'Asus est l'un des trois OEM qui proposera un PC portable ARM équipé du Qualcomm 835, le NovaGo. Sur ce sujet le constructeur nous a confirmé qu'il espère le lancer avant la fin du premier trimestre.
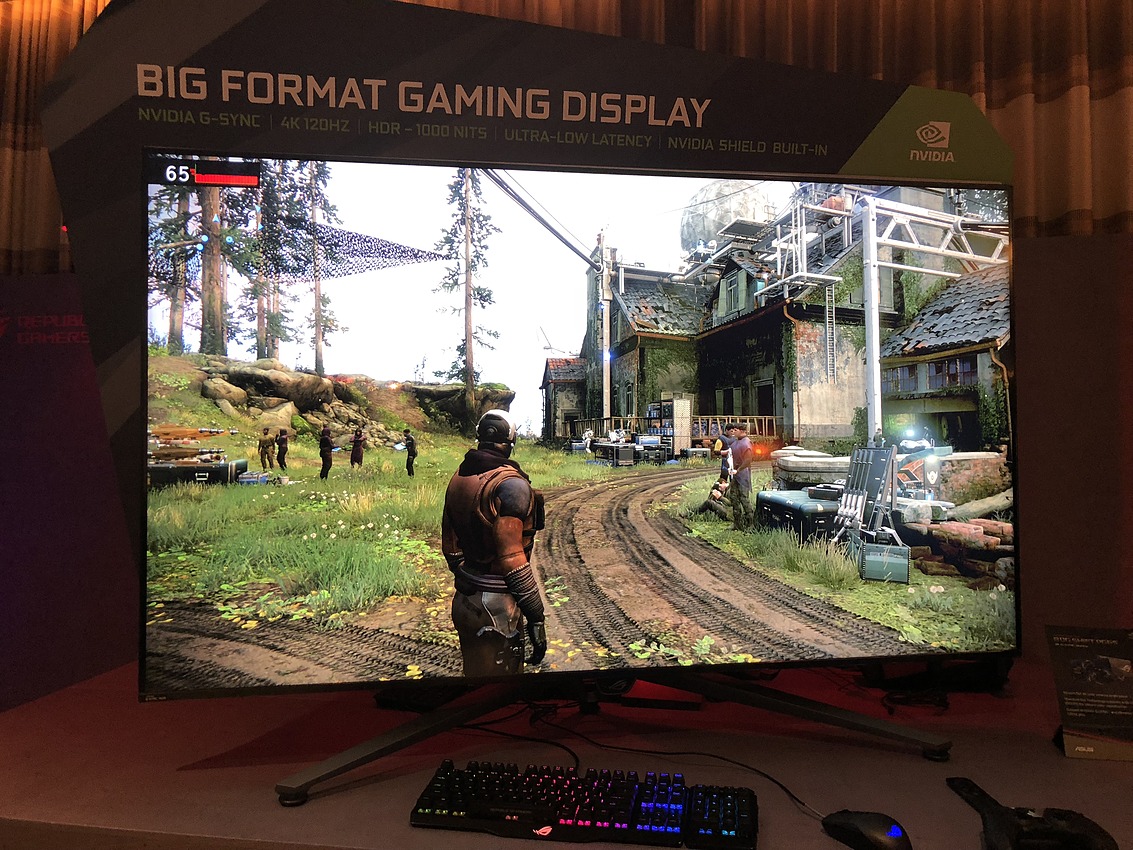
Sur le sujet des BFGD de Nvidia, nous avons pu voir le modèle 65 pouces d'Asus. Il s'agit d'un écran 4K (selon les constructeurs des dalles 4K ou 3440x1440 sont utilisées) 120 Hz HDR (1000 nits, on ne sait pas si il est conforme a la spécification DisplayHDR 1000), incluant G-Sync, optimisé pour une latente minimale, et incluant également une Shield du constructeur. Bien que cela ressemble à un téléviseur, il n'y a pas de tuner TV intégré (on pourra tout de même regarder des vidéos via divers services en ligne avec la Shield).
Techniquement la qualité de la dalle LCD choisie par Asus parait très bonne, et la latence, pour le peu que nous ayons pu tester, est effectivement basse. Les questions de prix et de disponibilité restent ouvertes cependant et risquent d'être ce qui pose problème au concept. Aucun prix n'est officiellement donné mais l'on parle officieusement de plus de 3000$. Si cela se confirme, cela limitera fortement le public potentiellement visé par ces écrans qui devront entrer en concurrence qui plus est avec le marché des TV, excessivement concurrentiel et il n'est pas certain que les améliorations techniques apportées suffisent à compenser l'écart de prix (et la versatilité des TV) pour les éventuels intéressés. Pour ce qui est de la disponibilité, nous avons entendu qu'elle se ferait au second semestre (entre cet été et la fin de l'année selon les interlocuteurs).

Pour terminer, deux écrans "portables" ont retenu notre intérêt. Le premier est un écran LCD 15.6 pouces, le ZenScreen Go. Il s'agit d'un écran 1080p portable, d'une épaisseur de 8mm et pesant 900g. Il inclut sa propre batterie 7800 mAh et se connecte en USB Type-C à ses sources. Il est livré avec une protection d'écran qui se replie pour servir de support (à l'image de ce qui existe pour les iPad).

Le second modèle était une variante ZenScreen Go. Mais pour ce PQ22UC, nous avons droit cette fois ci à un écran 4K 21.6 pouces... OLED ! Asus parle de DCI-P3 et de HDR pour l'écran qui, visuellement, était tout simplement impressionnant. Asus annonce un temps de réponse de 0.1ms. La marque insiste sur le fait qu'il ne s'agit pas d'un prototype mais qu'il proposera bien ce produit à la vente (le prix risque, OLED oblige, d'être élevé).
Notez que la dalle est fournie par J-OLED, société qui fusionnait les initiatives OLED de Sony et Panasonic. Le communiqué de presse de cette joint venture indique qu'ils travaillent spécifiquement à produire en volume (et réduire le coût) des dalles OLED 21.6 pouces et qu'ils auraient réalisés leur première livraison de composants prêts à la vente le mois dernier.
On ne peut qu'espérer que ce soit le cas (sur le volume et le prix), la disponibilité de ces deux écrans mobiles étant annoncée au premier semestre même si Asus était assez prudent sur la date du modèle OLED.
CES: Thermaltake annonce son Level 20
Pour fêter son vingtième anniversaire, la marque Thermaltake montrait au CES un énorme boîtier baptisé Level 20. Le nom rappellera peut être à certains d'entre vous le très original Level 10 lancé en 2009.

Il s'agit cette fois ci d'une (très) grande tour en aluminium, découpée en trois chambres : une pour la carte mère en bas, une au dessus pour l'alimentation, et une en avant pour le stockage. La mode étant aux LEDs RGB, on retrouvera trois grand panneaux en verre (4mm d'épaisseur) sur le côté.

La chambre dédiée au stockage peut accueillir onze (!) disques durs 3.5 ainsi qu'un système de watercooling. Coté cartes mères, on pourra aller jusqu'au format E-ATX mais le découpage en bloc fait que l'on sera "limité" à 310mm de longueur pour les cartes graphiques (ce qui, au delà de rares modèles custom comme les Vega Nitro+ de Sapphire, devrait être suffisant !).
Côté connectivité, on retrouve en haut a l'avant un port USB Type-C, et quatre ports USB 3.0 en plus des connecteurs audio.
Un second boîtier original était présenté sur le stand de la marque, le Core P90. Il s'agit cette fois ci d'un boîtier ouvert construit autour d'un triangle rectangle. On a donc accès a deux surfaces à angle droit pour placer ses composants :

Le système est modulaire et l'on pourra y placer jusque sept disques (5 disques 3.5 pouces + 2 disques 2.5 pouces).

Un câble PCI Express x16 est également fourni pour changer l'orientation/déporter sa carte graphique. Dans les deux cas, aucun prix et aucune date de disponibilité n'ont été évoqués.
CES: Un hybride laptop/smartphone chez Razer
La marque Razer profite toujours du CES pour montrer un "projet" original, pour ne pas dire parfois un peu décalé. On se souvient par exemple l'année dernière du "Projet Valerie", un prototype de PC portable 17" disposant de trois écrans 4K...

Cette année, Razer récidive mais le concept est un peu moins farfelu. Portant le nom de "Project Linda", il reprend l'idée de transformer un smartphone en PC portable. En pratique, on insère son smartphone dans une coque, à l'emplacement ou l'on trouve habituellement un trackpad et le smartphone se transforme en "PC".
C'est au moins la théorie. Côté smartphone, Razer utilise évidemment son Razer Phone . Il s'agit d'un modèle Android équipé d'un écran 5.7 pouces 120 Hz. Il utilise un SoC Snapdragon 835 et est accompagné de 8 Go de RAM. Il dispose d'un connecteur USB Type-C, et c'est ce dernier qui officie dans ce concept de Razer.

Une fois inséré dans la coque (un système mécanique insère et rétracte le connecteur Type-C), c'est par l'USB que la communication s'effectue. La coque est relativement compacte et intègre un écran tactile lui aussi en 120 Hz. Outre le clavier, on retrouve à l'intérieur de la coque une batterie (qui peut recharger le smartphone via USB-PD, la taille de la batterie dans le prototype n'est pas précisée) et un SSD de 200 Go pour le stockage.
Le concept a le mérite d'être particulièrement soigné côté hardware, même si l'idée d'utiliser un smartphone comme trackpad n'est pas le summum du confort niveau friction. A l'essai, le toucher était peu agréable pour ne pas dire autre chose. Razer en est conscient et propose un second mode de fonctionnement pour le smartphone qui peut se transformer en écran secondaire lorsque l'on branche une souris.
C'est plutôt côté logiciel que l'on déchantera un peu puisque l'on restera bloqué sous Android en mode PC, qui n'est pas particulièrement optimisé pour une utilisation de la sorte. Razer met en avant la possibilité de jouer aux jeux Android comme argument principal derrière son concept.
Bien entendu, comme la plupart des concepts réalisés pour les salons, on ne sait pas si Razer transformera ce prototype en un véritable produit. Vous pouvez retrouver au dessus une petite vidéo de présentation de la marque.