
Intel Core i7-4770K et i5-4670K : Haswell en test
Publié le 01/06/2013 par Guillaume Louel et Marc Prieur



Au-delà des extensions apportées au niveau du jeu d'instruction, l'architecture même d'Haswell évolue, à peu près à tous les niveaux de la puce. Nous allons donc passer en revue ces changements avec pour l'occasion quelques rappels sur le fonctionnement interne des processeurs modernes.
En amont du processeur, on retrouve toujours ce que l'on appelle le front-end, la partie du processeur qui s'occupe de récupérer et décoder les instructions x86 (macro-op) des programmes qui tournent sur nos machines.
Ces dernières sont transformées pour rappel en micro-opérations (micro-op)par les décodeurs, des opérations compréhensibles directement par les unités d'exécution. Cela permet de garder un jeu d'instruction large et extensible (on l'a vu page précédente avec AVX2 et TSX), tout en proposant des unités d'instructions plus simples qui n'ont pas à comprendre toutes les variantes des dernières instructions à la mode. D'un point de vue externe, un processeur x86 est donc considéré comme un processeur de type CISC (Complex Instruction Set Computing) mais fonctionne, en interne, comme un processeur RISC (Reduced Instruction Set Computing).
Le rôle du front-end est donc primordial pour une architecture qui dispose d'un très grand nombre d'instructions comme x86 (plus d'un millier !) aussi bien sur les performances que sur la consommation.
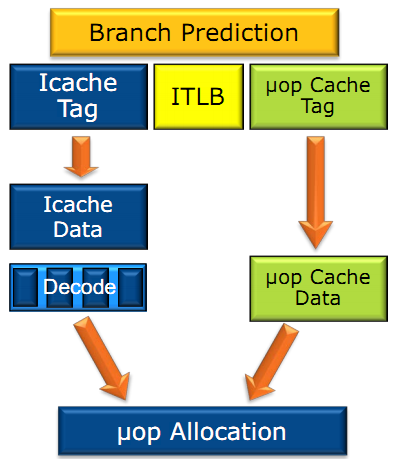
Dans les grandes lignes, on retrouve un front-end identique à celui de Sandy Bridge. Le cache d'instruction L1 de 32 Ko alimente cette partie du pipeline qui se termine toujours par quatre décodeurs. Le premier est capable de décoder des instructions plus complexes qui peuvent générer jusqu'à 4 micro-ops, tandis que les trois autres décodeurs s'occupent des instructions plus simples. En pratique, quatre micro-ops par cycle peuvent être générées par le front end (on parle d'architecture 4-way), avec un cas particulier pour les comparaisons et les sauts qui peuvent être fusionnés en une micro-op (ce qu'Intel appelle une fusion de macro-ops, deux instructions x86 transformées en une micro-op). Notez qu'un cache de 1500 micro-ops est également présent pour gérer le cas particulier des boucles, là encore il ne change pas par rapport à Sandy Bridge. Le code d'une boucle courte peut ainsi rester dans ce cache sans repasser par le début du front-end. Cela permet de gagner un peu en performance (pas besoin de décoder de nouveau, on gagne cinq étapes sur le pipeline) et surtout en consommation.
Une fois décodées, les micro-ops sont placées dans une file de 56 instructions. Elle était sous Sandy Bridge partitionnée en deux files de 28 micro-ops, une par thread. Chaque cur gère pour rappel l'HyperThreading : deux files d'instructions se partagent les ressources des unités d'exécution que l'on verra ci-dessous. Depuis Ivy Bridge, cette file peut être utilisée entièrement par un seul des threads matériel si l'autre est inactif. Haswell reprend lui aussi ce changement qui permet de booster les performances sur les applications peu threadées.
En parallèle à tout cela, le front-end contient également une unité de prédiction de branchements. Cette dernière évolue, même si Intel est assez peu loquace sur le sujet. On pense au minimum que les modifications apportées servent à gérer TSX. En effet les transactions peuvent être gérées côté processeur comme des branchements et profiter de tous les mécanismes déjà existants.
Les micro-ops à ce stade restent dans l'ordre de celui du programme original. Une série d'étapes arrive alors pour allouer, renommer et réordonnancer les instructions et leurs registres (des cases mémoires internes sur lesquelles s'appliquent les opérations, en opposition aux adresses mémoires qui font référence à des emplacements en RAM). Pour rappel, x86 dispose d'un nombre de registres accessibles pour les programmeurs en assembleur particulièrement limité : seulement 8 en mode 32 bits et 16 en mode x86-64. Un nombre restreint, certes, et qui limite les compilateurs, mais pour les processeurs la problématique est autre.
En effet comme nous l'avons vu, les unités d'exécution ne travaillent pas directement sur les instructions x86 (macro-ops) mais sur un format interne, les micro-ops. Libre donc auw processeurs d'utiliser plus de registres s'ils le souhaitent, et c'est exactement ce qu'ils font avec les PRF (Physical Register File). Il faut alors renommer/remapper les registres présents dans les instructions x86 vers ceux du processeur. On trouve ici un des premiers changements majeurs d'Haswell par rapport à Sandy Bridge sur le nombre de registres internes, on passe de 160 registres entiers et 144 registres AVX à 168 dans les deux cas pour Haswell.
La taille du ROB (Reorder Buffer) qui trace l'ordre initial dans lequel les instructions devait être exécuté dans le programme original augmente également passant de 169 à 192 (en clair, on rallonge le nombre d'instructions qui pourront être mélangées par la suite) et les buffers pour les opérations de lecture passent de 64 à 72 entrées, et les buffers pour les opérations d'écriture passent de 36 à 42 entrées.
On notera que c'est ici également qu'Intel effectue certaines optimisations, par exemple les instructions x86 MOV qui déplacent une donnée d'un registre vers un autre peuvent être supprimées. Cette optimisation avait déjà été ajoutée dans Ivy Bridge.
Les instructions sont ensuite placées dans le scheduler qui va décider de l'ordre dans lequel seront exécutées les instructions. Son rôle est double, en premier lieu il se doit de déterminer les opérations non dépendantes. Par exemple si le programme original contient ces deux instructions :
La seconde addition ne pourra pas être exécutée avant que la première l'ait été, le scheduler doit donc prendre ceci en considération avant d'envoyer les instructions aux unités d'exécution. Le second problème est de s'assurer que les données nécessaires à la réalisation des opérations soient bel et bien présentes et à jour. Le contenu de A est il correct ? Vient-il d'une information chargée en mémoire (auquel cas, cette lecture est elle terminée ?) ou d'une autre instruction ? Le scheduler doit s'assurer que les instructions soient exécutables avant de se lancer, la taille de son buffer d'instructions (le nombre de micro-op disponible pour augmente légèrement passant de 54 entrées à 60.
Ces augmentations du côté du scheduler et de ses ressources associées ont pour but de compléter l'arrivée d'un changement assez majeur dans Haswell : l'ajout de deux nouveaux ports d'exécution (des files pour les unités d'exécution qui vont effectuer le calcul, un port regroupant plusieurs unités de calcul). Ce nombre fixé à 6 depuis la première architecture Core varie pour la première fois avec Haswell, passant à 8.
On retrouve pour rappel deux grands types de ports, d'un côté ceux qui calculent, et de l'autre les unités qui travaillent avec la mémoire (lecture/écriture de données en mémoire). On commence d'abord par les ports de calcul. A l'image de Sandy Bridge, on retrouve toujours sur les ports 0 et 1 les "grosses" unités de calcul capables d'effectuer les opérations sur les entier, mais aussi sur les flottants via les unités AVX. Ces dernières sont bien entendues compatibles AVX2 et capables de traiter des opérandes sur 256 bits.
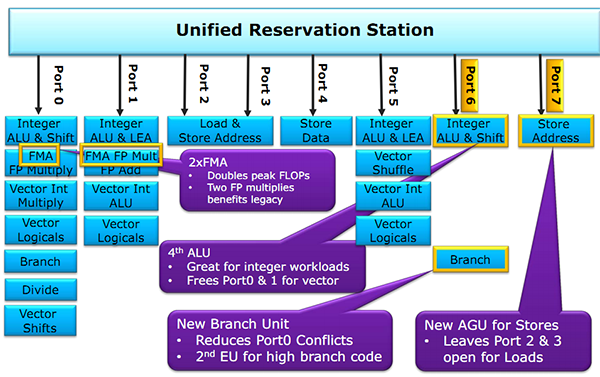
Sur le port 5, on retrouve toujours une unité de calcul sur les entiers simple, qui permet de garder les ports 0 et 1 libres pour les opérations les plus complexes. Intel dédouble ce port avec Haswell, le nouveau port 6 dispose lui aussi d'une unité.
Notez que les branchements étaient gérés uniquement sur le port 5 auparavant, il y a désormais deux options, une sur le port 6 et l'autre sur le port 0. De quoi améliorer possiblement les performances dans certaines situations ou le port 5 se retrouvait précédemment bloqué.
Du côté des ports mémoires, Sandy Bridge proposait deux ports capables d'effectuer des opérations de lecture et d'écritures en mémoire, et un troisième capable de stocker des données temporaires en cache L1 (port 4). Intel rajoute en sus au port 7 une unité dédiée uniquement aux écritures mémoire.
Le choix peut paraitre contre intuitif étant donné que les applications contiennent en général une proportion plus importante de lectures mémoires que d'écritures. Cet ajout permet indirectement d'effectuer deux loads en plus d'un store ce qui représente tout de même un progrès important, tout en améliorant les très rares cas des applications qui reposent fortement sur les écritures mémoires.
Intel a apporté une série d'optimisations intéressantes du côté des systèmes de mémoire cache. Pour rappel, si le processeur à besoin de récupérer des données en mémoire, les ports "addresse" mentionnés plus haut vont interroger le cache de niveau 1 pour voir si l'information est déjà présente. Si ce n'est pas le cas, le cache de niveau 2 sera interrogé, puis le cache de niveau 3 jusqu'à aller en mémoire centrale si nécessaire.
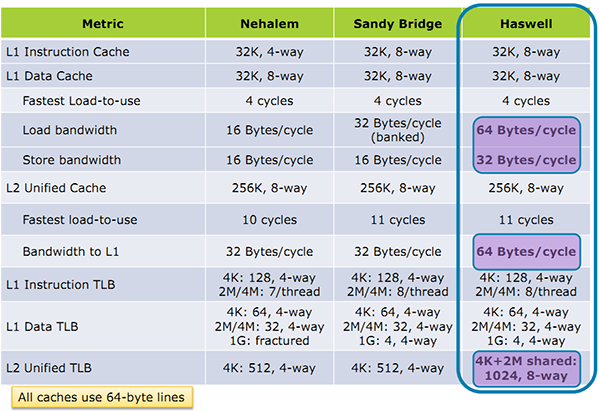
Concernant le cache de niveau 1, Intel annonce que son débit à été doublé. En pratique c'est même un peu mieux que cela. Chaque port peut en effet lire ou écrire 32 octets par cycles sur Haswell, contre 16 sur Sandy Bridge. Avec l'ajout du troisième port en écriture cependant, le cache est capable de lire 64 octets en simultanée d'une écriture de 32 octets et ce de manière continue. Un progrès particulièrement important.
Si les données demandées ne se trouvent pas dans le cache L1, c'est le L2 qui est interrogé. Pas de changement sur la latence de ce dernier mais lui aussi voit son débit doubler de 32 à 64 octets par cycle.
Si les caches L1/L2 sont lies à chaque core, le cache L3 (également appelé LLC, Last Level Cache) est commun pour tous les curs sur Haswell comme cela était déjà le cas avec Sandy Bridge. Ces processeurs intègrent un bus de communication circulaire (ring bus) qui relie chaque core aux blocs de LLC (il est partitionné en 4 sur les versions de Haswell testées aujourd'hui). Ce ring bus relie également la partie chipset (System Agent) et le GPU intégré.
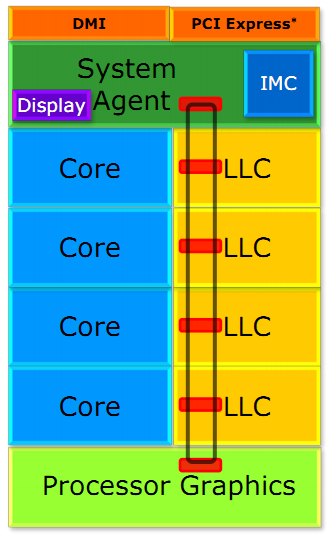
Un premier changement important concerne la fréquence du ring bus et du LLC. Ces derniers se retrouvent désormais dans un domaine de fréquence séparé des cores contrairement à Sandy Bridge. Outre l'aspect consommation, cela permet d'augmenter les performances des applications qui n'utilisent que le GPU et très peu le CPU. Seule conséquence négative, une légère augmentation de la latence du L3.
Intel effectue plusieurs autres améliorations en rajoutant en séparant en deux les accès données et instructions dans le LLC pour améliorer la bande passante. Le débit théorique des LLC et du bus n'augmente pas, mais leur efficacité augmente. Notez enfin qu'en bout de chaine, le contrôleur mémoire (qui accède en dernier recours à la mémoire quand les caches ne proposent pas l'information demandée) a été optimisé pour mieux gérer les écritures simultanées avec un meilleur découplage des accès.
 Les améliorations du jeu d'instruction x86 : TSX et AVX2
Les améliorations côté GPU
Les améliorations du jeu d'instruction x86 : TSX et AVX2
Les améliorations côté GPU

Front End
En amont du processeur, on retrouve toujours ce que l'on appelle le front-end, la partie du processeur qui s'occupe de récupérer et décoder les instructions x86 (macro-op) des programmes qui tournent sur nos machines.
Ces dernières sont transformées pour rappel en micro-opérations (micro-op)par les décodeurs, des opérations compréhensibles directement par les unités d'exécution. Cela permet de garder un jeu d'instruction large et extensible (on l'a vu page précédente avec AVX2 et TSX), tout en proposant des unités d'instructions plus simples qui n'ont pas à comprendre toutes les variantes des dernières instructions à la mode. D'un point de vue externe, un processeur x86 est donc considéré comme un processeur de type CISC (Complex Instruction Set Computing) mais fonctionne, en interne, comme un processeur RISC (Reduced Instruction Set Computing).
Le rôle du front-end est donc primordial pour une architecture qui dispose d'un très grand nombre d'instructions comme x86 (plus d'un millier !) aussi bien sur les performances que sur la consommation.
Dans les grandes lignes, on retrouve un front-end identique à celui de Sandy Bridge. Le cache d'instruction L1 de 32 Ko alimente cette partie du pipeline qui se termine toujours par quatre décodeurs. Le premier est capable de décoder des instructions plus complexes qui peuvent générer jusqu'à 4 micro-ops, tandis que les trois autres décodeurs s'occupent des instructions plus simples. En pratique, quatre micro-ops par cycle peuvent être générées par le front end (on parle d'architecture 4-way), avec un cas particulier pour les comparaisons et les sauts qui peuvent être fusionnés en une micro-op (ce qu'Intel appelle une fusion de macro-ops, deux instructions x86 transformées en une micro-op). Notez qu'un cache de 1500 micro-ops est également présent pour gérer le cas particulier des boucles, là encore il ne change pas par rapport à Sandy Bridge. Le code d'une boucle courte peut ainsi rester dans ce cache sans repasser par le début du front-end. Cela permet de gagner un peu en performance (pas besoin de décoder de nouveau, on gagne cinq étapes sur le pipeline) et surtout en consommation.
Une fois décodées, les micro-ops sont placées dans une file de 56 instructions. Elle était sous Sandy Bridge partitionnée en deux files de 28 micro-ops, une par thread. Chaque cur gère pour rappel l'HyperThreading : deux files d'instructions se partagent les ressources des unités d'exécution que l'on verra ci-dessous. Depuis Ivy Bridge, cette file peut être utilisée entièrement par un seul des threads matériel si l'autre est inactif. Haswell reprend lui aussi ce changement qui permet de booster les performances sur les applications peu threadées.
En parallèle à tout cela, le front-end contient également une unité de prédiction de branchements. Cette dernière évolue, même si Intel est assez peu loquace sur le sujet. On pense au minimum que les modifications apportées servent à gérer TSX. En effet les transactions peuvent être gérées côté processeur comme des branchements et profiter de tous les mécanismes déjà existants.
Scheduler
Les micro-ops à ce stade restent dans l'ordre de celui du programme original. Une série d'étapes arrive alors pour allouer, renommer et réordonnancer les instructions et leurs registres (des cases mémoires internes sur lesquelles s'appliquent les opérations, en opposition aux adresses mémoires qui font référence à des emplacements en RAM). Pour rappel, x86 dispose d'un nombre de registres accessibles pour les programmeurs en assembleur particulièrement limité : seulement 8 en mode 32 bits et 16 en mode x86-64. Un nombre restreint, certes, et qui limite les compilateurs, mais pour les processeurs la problématique est autre.
En effet comme nous l'avons vu, les unités d'exécution ne travaillent pas directement sur les instructions x86 (macro-ops) mais sur un format interne, les micro-ops. Libre donc auw processeurs d'utiliser plus de registres s'ils le souhaitent, et c'est exactement ce qu'ils font avec les PRF (Physical Register File). Il faut alors renommer/remapper les registres présents dans les instructions x86 vers ceux du processeur. On trouve ici un des premiers changements majeurs d'Haswell par rapport à Sandy Bridge sur le nombre de registres internes, on passe de 160 registres entiers et 144 registres AVX à 168 dans les deux cas pour Haswell.
La taille du ROB (Reorder Buffer) qui trace l'ordre initial dans lequel les instructions devait être exécuté dans le programme original augmente également passant de 169 à 192 (en clair, on rallonge le nombre d'instructions qui pourront être mélangées par la suite) et les buffers pour les opérations de lecture passent de 64 à 72 entrées, et les buffers pour les opérations d'écriture passent de 36 à 42 entrées.
On notera que c'est ici également qu'Intel effectue certaines optimisations, par exemple les instructions x86 MOV qui déplacent une donnée d'un registre vers un autre peuvent être supprimées. Cette optimisation avait déjà été ajoutée dans Ivy Bridge.
Les instructions sont ensuite placées dans le scheduler qui va décider de l'ordre dans lequel seront exécutées les instructions. Son rôle est double, en premier lieu il se doit de déterminer les opérations non dépendantes. Par exemple si le programme original contient ces deux instructions :
C = A + B
D = C + E
La seconde addition ne pourra pas être exécutée avant que la première l'ait été, le scheduler doit donc prendre ceci en considération avant d'envoyer les instructions aux unités d'exécution. Le second problème est de s'assurer que les données nécessaires à la réalisation des opérations soient bel et bien présentes et à jour. Le contenu de A est il correct ? Vient-il d'une information chargée en mémoire (auquel cas, cette lecture est elle terminée ?) ou d'une autre instruction ? Le scheduler doit s'assurer que les instructions soient exécutables avant de se lancer, la taille de son buffer d'instructions (le nombre de micro-op disponible pour augmente légèrement passant de 54 entrées à 60.
Unités d'exécutions
Ces augmentations du côté du scheduler et de ses ressources associées ont pour but de compléter l'arrivée d'un changement assez majeur dans Haswell : l'ajout de deux nouveaux ports d'exécution (des files pour les unités d'exécution qui vont effectuer le calcul, un port regroupant plusieurs unités de calcul). Ce nombre fixé à 6 depuis la première architecture Core varie pour la première fois avec Haswell, passant à 8.
On retrouve pour rappel deux grands types de ports, d'un côté ceux qui calculent, et de l'autre les unités qui travaillent avec la mémoire (lecture/écriture de données en mémoire). On commence d'abord par les ports de calcul. A l'image de Sandy Bridge, on retrouve toujours sur les ports 0 et 1 les "grosses" unités de calcul capables d'effectuer les opérations sur les entier, mais aussi sur les flottants via les unités AVX. Ces dernières sont bien entendues compatibles AVX2 et capables de traiter des opérandes sur 256 bits.
Sur le port 5, on retrouve toujours une unité de calcul sur les entiers simple, qui permet de garder les ports 0 et 1 libres pour les opérations les plus complexes. Intel dédouble ce port avec Haswell, le nouveau port 6 dispose lui aussi d'une unité.
Notez que les branchements étaient gérés uniquement sur le port 5 auparavant, il y a désormais deux options, une sur le port 6 et l'autre sur le port 0. De quoi améliorer possiblement les performances dans certaines situations ou le port 5 se retrouvait précédemment bloqué.
Du côté des ports mémoires, Sandy Bridge proposait deux ports capables d'effectuer des opérations de lecture et d'écritures en mémoire, et un troisième capable de stocker des données temporaires en cache L1 (port 4). Intel rajoute en sus au port 7 une unité dédiée uniquement aux écritures mémoire.
Le choix peut paraitre contre intuitif étant donné que les applications contiennent en général une proportion plus importante de lectures mémoires que d'écritures. Cet ajout permet indirectement d'effectuer deux loads en plus d'un store ce qui représente tout de même un progrès important, tout en améliorant les très rares cas des applications qui reposent fortement sur les écritures mémoires.
Mémoire cache
Intel a apporté une série d'optimisations intéressantes du côté des systèmes de mémoire cache. Pour rappel, si le processeur à besoin de récupérer des données en mémoire, les ports "addresse" mentionnés plus haut vont interroger le cache de niveau 1 pour voir si l'information est déjà présente. Si ce n'est pas le cas, le cache de niveau 2 sera interrogé, puis le cache de niveau 3 jusqu'à aller en mémoire centrale si nécessaire.
Concernant le cache de niveau 1, Intel annonce que son débit à été doublé. En pratique c'est même un peu mieux que cela. Chaque port peut en effet lire ou écrire 32 octets par cycles sur Haswell, contre 16 sur Sandy Bridge. Avec l'ajout du troisième port en écriture cependant, le cache est capable de lire 64 octets en simultanée d'une écriture de 32 octets et ce de manière continue. Un progrès particulièrement important.
Si les données demandées ne se trouvent pas dans le cache L1, c'est le L2 qui est interrogé. Pas de changement sur la latence de ce dernier mais lui aussi voit son débit doubler de 32 à 64 octets par cycle.
Ring bus, LLC
Si les caches L1/L2 sont lies à chaque core, le cache L3 (également appelé LLC, Last Level Cache) est commun pour tous les curs sur Haswell comme cela était déjà le cas avec Sandy Bridge. Ces processeurs intègrent un bus de communication circulaire (ring bus) qui relie chaque core aux blocs de LLC (il est partitionné en 4 sur les versions de Haswell testées aujourd'hui). Ce ring bus relie également la partie chipset (System Agent) et le GPU intégré.
Un premier changement important concerne la fréquence du ring bus et du LLC. Ces derniers se retrouvent désormais dans un domaine de fréquence séparé des cores contrairement à Sandy Bridge. Outre l'aspect consommation, cela permet d'augmenter les performances des applications qui n'utilisent que le GPU et très peu le CPU. Seule conséquence négative, une légère augmentation de la latence du L3.
Intel effectue plusieurs autres améliorations en rajoutant en séparant en deux les accès données et instructions dans le LLC pour améliorer la bande passante. Le débit théorique des LLC et du bus n'augmente pas, mais leur efficacité augmente. Notez enfin qu'en bout de chaine, le contrôleur mémoire (qui accède en dernier recours à la mémoire quand les caches ne proposent pas l'information demandée) a été optimisé pour mieux gérer les écritures simultanées avec un meilleur découplage des accès.
Sommaire
1 - Introduction
2 - Les améliorations du jeu d'instruction x86 : TSX et AVX2
3 - Les améliorations de l'architecture CPU
4 - Les améliorations côté GPU
5 - LGA 1150, Régulateur de tension intégré
6 - Overclocking plus libre sur K, plus strict par ailleurs
7 - Chipsets Intel Serie 8, Lynx Point et Lynx Point-LP
8 - Les gammes Haswell
9 - Core i7-4770K, i5-4670K, i5-4430 et cartes mères
10 - Bug de l'USB 3.0 sur C1, compatibilité des alimentations
11 - Consommation, efficacité énergétique
12 - Températures, overclocking et undervolting
13 - HD Graphics 4600 : Consommation, Overclocking, Jeux
2 - Les améliorations du jeu d'instruction x86 : TSX et AVX2
3 - Les améliorations de l'architecture CPU
4 - Les améliorations côté GPU
5 - LGA 1150, Régulateur de tension intégré
6 - Overclocking plus libre sur K, plus strict par ailleurs
7 - Chipsets Intel Serie 8, Lynx Point et Lynx Point-LP
8 - Les gammes Haswell
9 - Core i7-4770K, i5-4670K, i5-4430 et cartes mères
10 - Bug de l'USB 3.0 sur C1, compatibilité des alimentations
11 - Consommation, efficacité énergétique
12 - Températures, overclocking et undervolting
13 - HD Graphics 4600 : Consommation, Overclocking, Jeux
14 - HD Graphics 4600 : OpenCL, Quicksync
15 - Protocole CPU, Rendu 3D : Mental Ray et V-Ray
16 - CPU Compilation : Visual Studio et MinGW/GCC
17 - CPU Compression : 7-zip et WinRAR
18 - CPU Encodage : x264 et Rovi H.264
19 - CPU Traitement photo : Lightroom et Bibble
20 - CPU IA d'échecs : Houdini et Fritz
21 - CPU Jeux 3D : Crysis 2 et Arma II : OA
22 - CPU Jeux 3D : Rise of Flight et F1 2012
23 - CPU Jeux 3D : Total War Shogun 2 et Skyrim
24 - CPU Jeux 3D : Starcraft II et Anno 2070
25 - Gains et Moyennes CPU
26 - Conclusion
15 - Protocole CPU, Rendu 3D : Mental Ray et V-Ray
16 - CPU Compilation : Visual Studio et MinGW/GCC
17 - CPU Compression : 7-zip et WinRAR
18 - CPU Encodage : x264 et Rovi H.264
19 - CPU Traitement photo : Lightroom et Bibble
20 - CPU IA d'échecs : Houdini et Fritz
21 - CPU Jeux 3D : Crysis 2 et Arma II : OA
22 - CPU Jeux 3D : Rise of Flight et F1 2012
23 - CPU Jeux 3D : Total War Shogun 2 et Skyrim
24 - CPU Jeux 3D : Starcraft II et Anno 2070
25 - Gains et Moyennes CPU
26 - Conclusion
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 03/04: Intel lance la 2ème vague de sa 8èm...
- [+] 07/02: Windows 10, Meltdown et Spectre : q...
- [+] 05/10: Intel Core i7-8700K, Core i5-8600K,...
- [+] 12/09: Core i7-7820X : Un Skylake-X mieux ...
- [+] 07/09: Les Skylake en fin de vie chez Inte...
- [+] 23/08: Coffee Lake incompatible avec les L...
- [+] 29/06: Intel Core i9-7900X et Core i7-7740...
- [+] 03/01: Core i5-7600K et i7-7700K : pour qu...