
NVIDIA GeForce 8800 GTX & 8800 GTS
Publié le 08/11/2006 (Mise à jour le 12/02/2007) par Damien Triolet



HistoriqueLe rendu 3D moderne, repose depuis le départ sur le texturing. Il y a 10 ans, les pixels affichés à lécran se voyaient simplement appliqué une texture de décoration. Au fil des années ce rendu 3D est devenu de plus en plus évolué, les shaders permettent dappliquer des fonctions mathématiques complexes sur les pixels et les textures ne sont plus de simples décorations mais des tables de données dont les usages sont très variés. Très souvent, un shader moderne va contenir plusieurs dizaines dinstructions mathématiques par accès aux textures. Dès lors on peut se dire que la gestion efficace de ces accès aux textures nest plus primordiale et quil vaut mieux se concentrer sur la puissance de calcul brute.

Ce nest malheureusement pas aussi simple pour plusieurs raisons. La première est quun accès à une texture est souvent associé à un filtrage de celle-ci. Or, lorsque celui-ci est de qualité, même sil ne requiert quune seule instruction, il peut prendre de nombreux cycles à sexécuter. Cependant, nous laisserons de côté ce point pour le moment puisquau niveau du cur de larchitecture, le second est beaucoup plus important. Ce second point concerne la latence de laccès aux textures.
Laccès à la mémoire de la carte graphique peut prendre plus de 100 cycles et sil fallait attendre ces 100 cycles pour passer à linstruction suivante, nous en serions toujours à lâge de pierre de la 3D. Le GPU est donc capable de précharger les données dans un petit cache pour que, la majorité du temps, la latence de laccès à la mémoire ne soit pas un problème. Lorsque les textures étaient de simples décorations, cette tâche était très facile puisque le GPU savait à lavance quelle zone de mémoire devait être préchargée. Mais avec lévolution des techniques de rendu, les textures peuvent contenir des données très variées et leur accès nest plus aussi clairement déterminé. Le GPU doit donc être capable de traiter des accès aux textures indéterminés sans faire payer le coût de la latence de la mémoire. Plusieurs solutions à ce problème existent.
Auparavant, la solution de Nvidia a été dutiliser un très long pipeline dans lequel plus de 100-150 étages étaient uniquement destinés à masquer cette latence. Par exemple les GeForce 7 disposent de 2 unités de calcul par pipeline de traitement des pixel shaders. La première des unités commande laccès aux textures, sensuit alors un très long "tunnel" dans lesquels les pixels dorment avant darriver à la seconde unité. Plus ce tunnel est long, plus il est probable que la donnée recherchée dans les textures soit arrivée à temps et donc quil ne soit pas nécessaire de bloquer le pipeline pour lattendre. Le débit optimal peut donc être conservé. En contrepartie il faut pouvoir remplir ce pipeline avec autant de pixels quil y a détages, ce qui a obligé Nvidia à traiter les pixels par grosse quantité.
Ce nétait pas un problème jusquà larrivée des branchements dans les shaders. Dans un GPU, le flux dinstructions est géré par paquet déléments (de pixels dans ce cas) et il nest pas possible quun élément reçoive une instruction différente quun autre. Dans le cas où le résultat dun branchement diverge entre les pixels dun même groupe le GPU doit exécuter les 2 branches pour tous les pixels avec un masque de manière à ne pas prendre en compte les instructions de la mauvaise branche. Mais elles sont traitées malgré tout ce qui est très mauvais pour les performances. Les GeForce 7900 et précédente, avec leur très long pipeline qui impose de travailler sur de gros groupes de pixels (+/- 1000 !), se retrouvent donc en difficulté. Un autre problème se présenté : la largeur du pipeline est fixe, tout comme sa longueur. Si le pipeline nest pas assez large pour un pixel, soit si par étage le pipeline de propose pas assez de registres temporaires, un pixel doit occuper plusieurs étages, réduisant ainsi le débit. Cest de là que provient la limitation des registres des GeForce FX; 6 et 7 bien que sur ces dernières Nvidia ait élargi le pipeline de manière à ce que la majorité des pixels aient assez de place dans un étage.
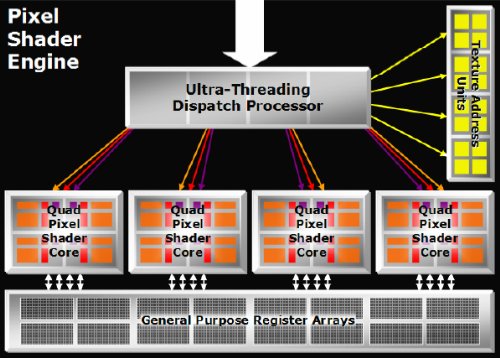
La solution dATI à tous ces problèmes a été, avec les Radeon X1000, de découpler les pipelines de traitement des pixel shaders des unités de texturing. Le long pipeline nest dès lors plus nécessaire puisque dautres possibilités pour masquer la latence du texturing apparaissent. Il devient possible de travailler sur de très petits groupes de pixels et dutiliser un nombre important de ces petits groupes, ou threads, pour obtenir le même résultat, sans les inconvénients. Dès quun petit groupe de pixels doit accéder à une texture, il sort de lunité de traitement des pixel shaders et passe dans la file dattente de lunité de texturing. Parallèlement, un autre groupe est traité par lunité de calcul des shaders. Dès quun groupe a reçu le résultat de laccès à la texture demandée, il change de file dattente et repasse dans celle des unités de calcul jusquà ce quil ait de nouveau besoin dune texture, et ainsi de suite. Pour masquer la latence efficacement il faut pouvoir placer en file dattente, ou au repos, un nombre important de threads et donc disposer dune mémoire cache qui peut les accueillir. Plus elle est grande, plus une grande latence peut être tolérée. Par contre cette fois la file dattente na plus une longueur fixe. Un nouveau thread est injecté dans le shader core uniquement si cela est nécessaire et bien entendu uniquement sil reste de la place dans la mémoire cache pour laccueillir.
Si la latence est faible, les threads passent rapidement dune unité à lautre et il nest pas nécessaire den injecter un grand nombre dans le cur de traitement des shaders. La mémoire cache qui les stocke est, elle, fixe bien entendu. Si elle est prévue pour contenir par exemple 128 threads mais que 32 suffisent à masquer la latence, 75% de la mémoire cache ne sert donc rien ? Nous en revenons au problème du nombre de registres temporaires. Le nombre qui en est utilisé est variable, ce qui veut dire que la taille des threads, en occupation mémoire est elle aussi variable. Vous laurez donc compris, ce type darchitecture permet de disposer dun nombre élevé de registres temporaires sans réduire le débit des unités lorsquil ny a pas une latence importante à masquer. Cette flexibilité permet au GPU dutiliser le meilleur compromis entre le nombre de registres accessibles à pleine vitesse et la latence masquée alors que le long pipeline propose un modèle fixe en dehors duquel les performances chutent directement.
Sommaire
1 - Le premier GPU DX10
2 - Historique
3 - Architecture GeForce 8
4 - ROPs, DirectX 10, CUDA, le G80
5 - Performances shaders et textures
6 - Performances branchements
7 - Filtrage des textures
8 - Antialiasing
9 - Les cartes, consommation
10 - GeForce 8800 GTS 320 Mo
11 - Drivers, CPU limited, le test
12 - Quake 4, F.E.A.R.
2 - Historique
3 - Architecture GeForce 8
4 - ROPs, DirectX 10, CUDA, le G80
5 - Performances shaders et textures
6 - Performances branchements
7 - Filtrage des textures
8 - Antialiasing
9 - Les cartes, consommation
10 - GeForce 8800 GTS 320 Mo
11 - Drivers, CPU limited, le test
12 - Quake 4, F.E.A.R.
13 - Half-Life 2 Lost Coast
14 - Far Cry
15 - Serious Sam 2
16 - Tomb Raider Legend
17 - Splinter Cell Chaos Theory
18 - Age of Empire III
19 - Oblivion
20 - Pacific Fighters, Colin McRae 05
21 - Need for Speed Carbon
22 - GeForce 8800 GTS : 320 vs 640 Mo
23 - Récapitulatif des performances
24 - Conclusion
14 - Far Cry
15 - Serious Sam 2
16 - Tomb Raider Legend
17 - Splinter Cell Chaos Theory
18 - Age of Empire III
19 - Oblivion
20 - Pacific Fighters, Colin McRae 05
21 - Need for Speed Carbon
22 - GeForce 8800 GTS : 320 vs 640 Mo
23 - Récapitulatif des performances
24 - Conclusion
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...