
Les contenus liés aux tags Nvidia et Tesla
Afficher sous forme de : Titre | FluxComputex : serveur Tesla chez Supermicro
Computex : Nvidia mise sur GPU Computing
Nvidia détaille sa stratégie
Nvidia lance Tesla
GTC: Nvidia lève le voile sur le GK110

Sans le nommer directement, Jen-Hsun Huang, le CEO de Nvidia, vient de dévoiler les premières informations au sujet du "gros" GPU Kepler, le GK110. Nous avons tout d'abord la confirmation qu'il s'agit bien d'un énorme GPU de pas moins de 7.1 milliards de transistors fabriqués en 28nm, un nouveau record. Certains doutes subsistaient par rapport à ce chiffre puisqu'il correspond presqu'exactement à deux GPU GK104, la configuration de la nouvelle carte Tesla K10, mais ce n'est qu'une coïncidence.
GTC oblige, c'est avant tout son intérêt pour le monde professionnel et particulièrement pour le calcul haute performance qui est mis en avant par Nvidia. Deux nouvelles technologies importantes font leur apparition dans ce GPU. Tout d'abord Hyper-Q qui permet d'utiliser jusqu'à 32 queues d'exécution pour alimenter le GPU, contrairement à une seule auparavant. Une limitation qui empêchait dans bien des cas la pleine exploitation de toute la capacité de calcul des GPU.

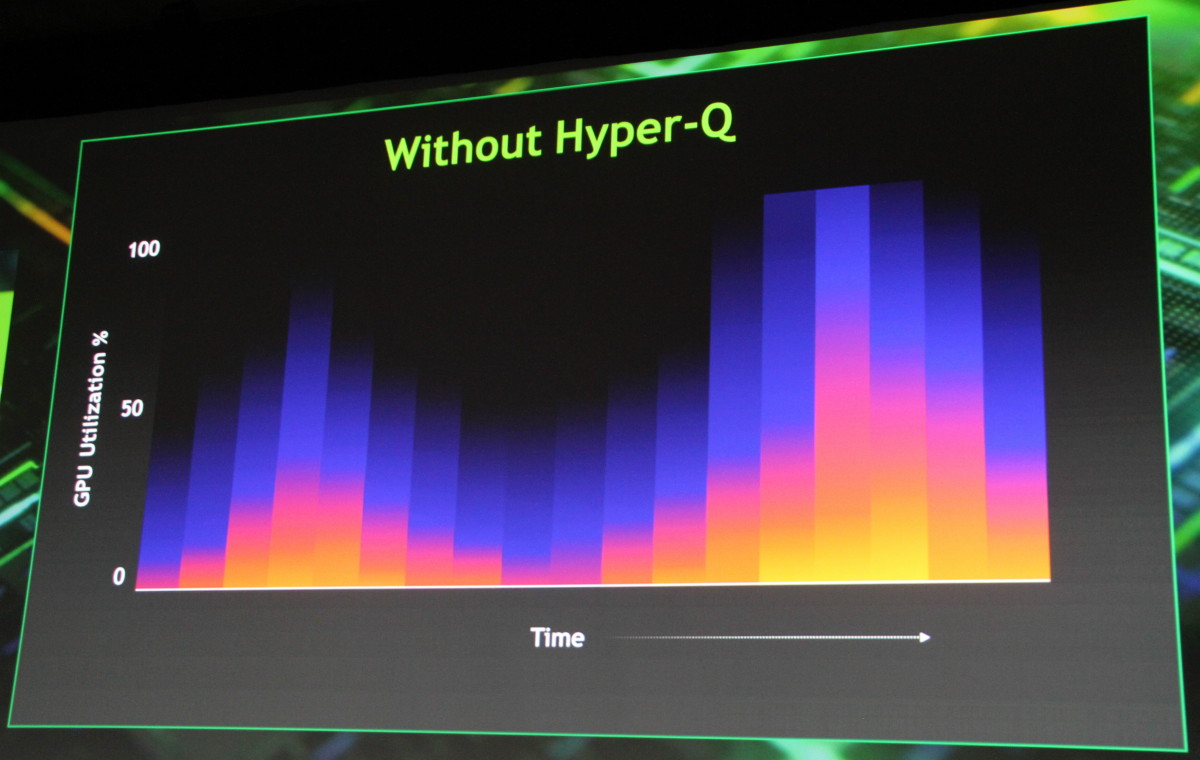
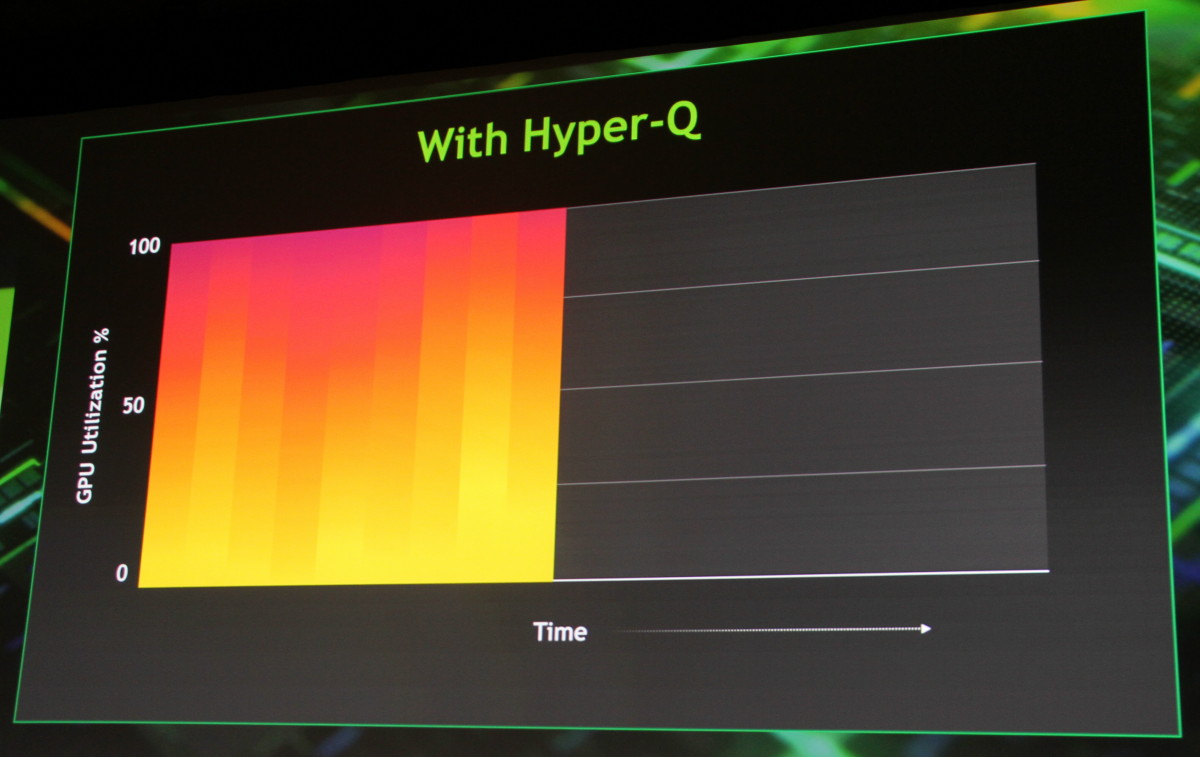
Hyper-Q permet de maximiser le rendement du GPU et de réduire le temps d'exécution.
La seconde innovation se nomme Dynamic Parallelism et vient également apporter une réponse à un problème d'efficacité actuelle. Le travail à exécuter sur le GPU est en général segmenté, et chacun des segments est initié par le CPU. Entre chacun de ceux-ci, le GPU rend ainsi la main au CPU qui reçoit les résultats d'une fonction, et dans certains cas renvoie ces mêmes résultats au GPU pour lancer une seconde fonction qui en est dépendante. L'inefficacité est évidente. Dynamic Parallelism représente la capacité du GK110 à auto-générer de nouvelles tâches, de quoi éviter ces allers-retours entre le CPU et le GPU.

Cette nouvelle flexibilité dans l'exécution des tâches va faciliter le travail des développeurs d'une part en proposant plus simplement un rendement élevé et d'autre part en leur permettant d'écrire leurs programmes d'une façon plus naturelle.

Enfin, Nvidia a dévoilé une photo du die du GK110, certes retravaillée artistiquement mais qui permet de se faire quelques idées sur les spécifications de ce GPU. On peut tout d'abord observer la présence de 15 SMX et d'un contrôleur mémoire de 6x 64 bits, soit 384 bits. Nvidia nous a confirmé ces spécifications et précisé que les SMX du GK110 seront également équipés de 192 unités de calcul, comme pour le GK104. Leur nombre total sera donc de 2880 et là aussi il s'agit d'un nouveau record, même si Nvidia précise qu'il n'y aura en principe pas de dérivé Tesla équipé d'une version complète de ce GPU, profiter d'un certain niveau de redondance étant nécessaire avec un GPU d'une telle taille, plus de 500mm². La première carte Tesla K20 basée sur le GK110 sera probablement limitée à 13 SMX et 2496 unités de calcul.
Nvidia nous a indiqué que l'organisation des registres et de la mémoire partagée avait été revue, et que la puissance de calcul en double précision était très élevée, mais il faudra patienter encore un jour ou deux avant d'avoir plus de détails sur le sous-système mémoire du GK110.
Sur le plan graphique, nous pouvons supposer que chaque SMX conserve 16 unités de texturing et que leur nombre total dans ce GPU est de 240. L'organisation des SMX en 5 groupes de 3 nous laisse penser que le GK110 serait capable de traiter jusqu'à 7.5 triangles par cycle mais de n'en rendre que 5 ou 6 par cycle (suivant l'implémentation pour laquelle a opté Nvidia), contre 4 et 4 pour le GK104. Enfin, de toute évidence il disposera de 48 ROP.
Ce futur GPU sera tout d'abord introduit à la fin de l'année en tant que Tesla K20 mais ne débarquera pas en tant que GeForce avant début 2013. Il sera bien entendu intéressant d'observer la consommation d'un tel monstre, même si Nvidia se veut rassurant en précisant que la carte Tesla K20 est prévue avec un TDP classique de "seulement" 225W !
Nvidia Maximus: Quadro et Tesla s'associent
A l'occasion du SC11 (Supercomputing 2011), Nvidia présente la plateforme Maximus qui permet de combiner une carte Quadro, orientée graphisme professionnel, et une carte Tesla, orientée calcul massivement parallèle, dans un même système. Jusqu'ici ce n'était pas possible, principalement pour des raisons commerciales et pour disposer de la puissance d'un tel système, il fallait acquérir 2 Quadro à prix plein.

Dans la gamme Nvidia, les Quadro représentent le sommet absolu, c'est-à-dire qu'elles ont accès à toutes les fonctionnalités des GPUs et des pilotes contrairement aux GeForce et aux Tesla, moins chères et pour lesquelles plusieurs limitations sont en place, notamment au niveau des optimisations qui concernent les logiciels graphiques professionnels. Impossible dès lors de combiner une Quadro avec une carte de rang inférieur, ce qui reviendrait à l'upgrader au rang de la Quadro ou à brider cette dernière. Deux solutions inacceptables commercialement.
La plateforme Maximus vient résoudre ce problème pour faciliter la commercialisation des cartes Tesla tout en conservant la poule aux ufs d'or que représente la gamme Quadro. Pour cela, les pilotes Tesla et Quadro ont été fusionnés pour permettre la prise en charge dans un même système des deux variantes tout en conservant leurs spécificités, c'est-à-dire que l'accélérateur Tesla n'aura pas accès aux fonctionnalités supplémentaires des Quadro.


Quadro 6000, à gauche, et Tesla C2075, à droite, sont presqu'identiques, si ce n'est au niveau du prix deux fois plus élevé pour la première.
Par défaut, les nouveaux pilotes redirigeront toutes les tâches de type compute (CUDA, OpenCL ) vers la carte Tesla, si elle est présente bien entendu, la Quadro se chargeant uniquement du rendu 3D et de l'affichage. Si une Quadro seule peut s'occuper de l'affichage, de la 3D et du calcul CUDA, cela peut lui faire perdre beaucoup de temps en changements d'état, une limitation importante de l'architecture actuelle des GPUs Nvidia. Qui plus est, l'affichage perd alors en réactivité, ce qui est désagréable à l'usage. Faire traiter la partie compute par une carte dédiée permet de gagner en efficacité et de conserver un affichage fluide en permanence.
Cette plateforme peut également permettre de faire quelques économies quand peu de puissance graphique est nécessaire, en adaptant chaque élément du couple Quadro / Tesla. Ainsi, opter pour une Quadro d'entrée de gamme permettra de ne pas souffrir des limitations imposées aux autres cartes dans les pilotes pour les logiciels professionnels (dans certains cas les performances ne dépendent que de ces pilotes et pas du GPU!), et l'accompagner d'un accélérateur Tesla permettra de disposer d'une puissance de calcul importante sans nuire au confort du système.
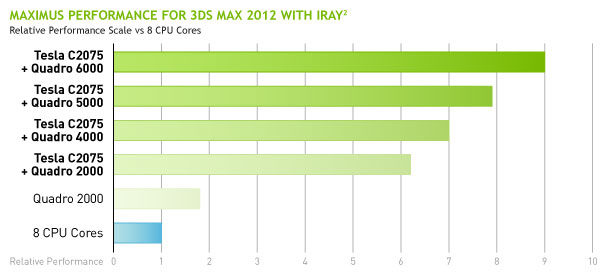
Par exemple une Quadro 6000 6 Go haut de gamme coûte près de 4500 alors qu'un accélérateur Tesla C2075 6 Go similaire ne coûte "que" 2300 et qu'une petite Quadro 600 se négocie pour moins de 200. Maximus permet ainsi de réduire de moitié l'investissement nécessaire pour profiter d'un environnement Quadro et de la puissance de calcul Tesla. Si ce type d'utilisation ne représente qu'une petite niche actuellement, Nvidia espère avec cette approche séduire un plus grand nombre de professionnels, comptant sur l'arrivée de plus en plus de logiciels capables d'exploiter les accélérateurs massivement parallèle tels que Tesla.
Bien qu'il soit toujours possible de définir manuellement le GPU qui sera chargé d'exécuter chaque tâche compute, Maximus dispose actuellement de profils optimisés pour une poignée d'applications, une liste qui devrait s'étendre progressivement :
- Adobe Premiere Pro CS5.5.2
- Autodesk 3ds Max 2012 avec iRay
- Dassault Systèmes CATIA V5/V6 avec SIMULIA Abaqus 6.11-1 ou plus récent
- Dassault Systèmes CATIA V6 Live Rendering avec iRay
- MathWorks MATLAB R2011b avec MATLAB Parallel Computing Toolbox
- SolidWorks 2010 ou plus recent avec ANSYS Mechanical 13.0 SP2 / 14.0
- PTC Creo Parametric 1.0 m010 ou PTC Pro/Engineer 5.0 avec ANSYS Mechanical 13.0 SP2 / 14.0
Computex: serveurs avec GPUs chez Supermicro



Supermicro exposait sur le salon plusieurs systèmes optimisés pour le GPU computing tant du côté dAMD que de Nvidia. Le spécialiste du serveur explique proposer les deux solutions à ses clients mais ne pas les mettre au point directement et simplement certifier la compatibilité de ces serveurs avec certains modèles proposés par AMD et Nvidia. Cest le cas des Tesla C2050 et C2070 basées sur le GF100. Du côté dAMD ce sont des FirePro V8800 qui étaient utilisées dans les systèmes puisque les cartes FireStream équivalentes et optimisées pour le format des serveurs manquent toujours à lappel.

Interrogé sur le succès de ces solutions, Supermicro nous a indiqué quil était toujours très réduit étant donné que le GPU computing reste encore globalement à létat de recherche et développement. Les logiciels compatibles, optimisés et à létat de production sont encore rares ce qui limite grossièrement le marché aux développeurs et aux universités. Supermicro estime cependant que ce type de serveurs pourrait connaître un succès de plus en plus grand et compte donc continuer à suivre le GPU computing de près. Notre interlocuteur nous a ensuite précisé avec un grand sourire que les marges énormes sur ce type de serveur et le coût relativement réduit en développement (il nest pas nécessaire de concevoir les cartes accélératrices et la densité nest pas réellement travaillée) font que peu importe si ce marché explose réellement un jour, le simple fait dalimenter son développement est déjà très rentable.
Tesla 20 et Fermi : plus de détails
Un membre du forum de notre confère italien Hardware Upgrade est tombé sur le document BD-04983-001_v01 de Nvidia qui contient les spécifications des cartes Tesla C2050 et C2070. Un fichier type que nous avons lhabitude de parcourir pour chaque modèle mais qui en principe nest pas public et est fourni uniquement aux partenaires de Nvidia via des échanges privés ou son extranet. Il mentionne les spécifications de base des cartes ainsi que leurs propriétés physiques.
Etant donné que Nvidia essaye de maintenir le hype sur Fermi en laissant filer tantôt un détail, tantôt une photo, nous pouvons supposer que ce fichier nest pas apparu par accident. Dans sa situation, continuer à faire parler de son futur GPU est le but principal. Ceci étant dit, ce document nous apporte une information importante qui confirme ce que nous pensons depuis quelques temps.
Lors de lannonce des cartes Tesla 20, nous avions pointé du doigt la faible fréquence que la puissance de calcul avancée par Nvidia impliquait. Cétait bien entendu en supposant que toutes les unités du GPU seraient fonctionnelles, ce qui nous est par la suite apparu de moins en moins probable. Daprès les nouvelles informations, 2 cores ou partitions de 32 « cores » sur les 16 que contient le GPU seront désactivées. Les cartes Tesla C2050 et C2070 disposeront donc en réalité de 448 cores actifs cadencés entre 1.25 et 1.4 GHz.
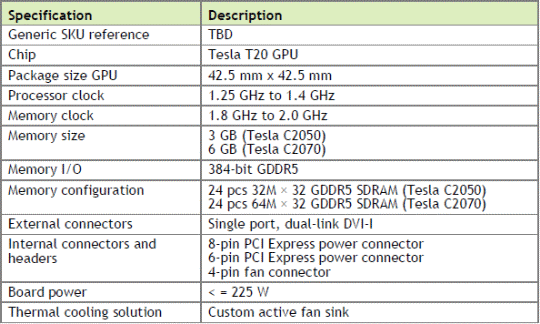
Si nous mettons en relation ces nouvelles données par rapport aux chiffres précédents, à savoir entre 520 et 630 Gflops en double précision, nous obtenons 1.16 et 1.4 GHz. La fourchette est similaire mais légèrement différente, ce qui peut sexpliquer par la date différente de lévaluation des fréquences ou par une puissance de calcul quelque peu réduite quand la protection ECC est activée. Nvidia donne également des informations sur la mémoire et parle de 1.8 à 2 GHz pour la GDDR5, ce que nous supposons correspondre à la fréquence denvoi des données, soit 900 à 1 GHz pour lenvoi des commandes, pour une bande passante de 160 à 179 Go/s.
Vous noterez par ailleurs que Nvidia ne place pas de mémoire supplémentaire pour stocker les données de parité et que le bus nest pas élargi pour la prendre en compte, comme cest le cas pour la mémoire système des serveurs. Autrement dit, lactivation de lECC va réduire la bande passante et lespace mémoire réellement disponible. Nvidia parle de 2.625 et 5.25 Go au lieu de 3 et 6 Go respectivement pour les cartes Tesla C2050 et C2070. Cela représente un coût de 1/8ème qui sera identique au niveau de la bande passante. Vous remarquerez que le coût en général de la mémoire ECC est de 1/9ème puisquun bit supplémentaire de parité est stocké pour 8 bits de données. Nous supposons que cest le même principe pour Fermi, mais qui doit par contre gérer lECC avec un bus qui nest pas élargi à 9/8ème quand cette technologie est activée. Etant donné quil utilise des contrôleurs mémoire 64 bits avec un prefetch de 8 bits, soit des accès de 512 bits, nous pouvons imaginer que lECC prend place dans cette structure. Ainsi, sur les 512 bits, 448 seraient réservés aux données, 56 pour la parité et 8 bits seraient perdus. Reste à savoir si le coût du calcul et du contrôle de la parité est important, faible ou nul, sil est traité par des unités dédiées dans le contrôleur mémoire où via les cores

Au final, nous avons donc 448 « cores », à 1.25/1.4 GHz et de la mémoire GDDR5 à 1.8/2.0 GHz. Pas très impressionnant diront certains. Sur le plan de la puissance de calcul, les Radeon HD 5870 font mieux et nont pas un gros désavantage en bande passante mémoire malgré leur bus plus petit. Mais il faut garder en tête quil sagit ici des cartes Tesla, pas des GeForce, pour lesquelles le niveau de tolérance est beaucoup plus strict et le câblage de la mémoire est rendu plus complexe puisquil faut placer le double de puces pour supporter 3 Go et 6 Go. Un élément dinquiétude légitime concerne les 2 partitions désactivées alors que nous aurions pu penser que Nvidia utiliserait les meilleurs exemplaires de Fermi, cest-à-dire complètement fonctionnels pour les cartes Tesla. Ce nest quà moitié étonnant selon nous, puisque nous avons déjà observé de grosses castrations sur les Quadro et que lintérêt de Fermi pour ce marché viendra bien plus de ses avancées architecturales et de ce quelles impliquent au niveau logiciel que de sa puissance de calcul. Passer de 16 à 14 partitions ne réduit donc pas lintérêt du produit.
Que se passera-t-il pour la version GeForce ? Tout est possible et va dépendre de la qualité de la production et des performances de Fermi par rapport à loffre actuelle dAMD. Si Nvidia peut le faire et en a besoin pour battre AMD, il est évident quune GeForce équipée dun Fermi complètement fonctionnel verra le jour. Elle pourra également profiter dune GDDR5 plus rapide et dune bande passante mémoire en hausse dau moins 20%.
Lélément le plus inquiétant dans tout cela concerne la consommation de Fermi. Les cartes Tesla C2050 et C2070 sont annoncées avec un TDP de 225 watts. Les GeForce feront léconomie de la moitié des modules mémoire, mais consommeront probablement au final plus à cause de fréquences en hausse et déventuellement 2 partitions actives en plus. La consommation risque donc dêtre un élément important dans la détermination des spécifications des GeForce Fermi.
Notez pour finir que si le consensus actuel semble être établi sur une disponibilité pour mars, nous estimons toujours de notre côté quelle devrait intervenir plus tôt, bien que probablement avec une disponibilité limitée. Selon nos informations la révision qui sera utilisée pour la production est prête et cest plutôt le côté logiciel qui doit maintenant être finalisé, sujet sur lequel certaines de nos sources se veulent rassurantes alors que dautres indiquent quil y a encore du pain sur la planche. Une chose est sûre, les développeurs de Nvidia ne vont pas prendre 2 semaines de congés pendant les fêtes comme cest le cas chez AMD !
Nvidia dévoile des Tesla 20 avec Fermi
A loccasion du salon SuperComputing 2009 qui se tient à Portland, Nvidia a décidé de lever le voile sur les premières cartes à exploiter sa future architecture Fermi. Pour rappel il sagit du nom de code de la déclinaison haut de gamme de la nouvelle architecture GPU de Nvidia que nous vous avions présentée il y a un peu plus dun mois et qui apporte de nombreuses avancées importantes pour la transition du GPU vers une unité de calcul massivement parallèle flexible et efficace.

Salon SuperComputing oblige, ce sont les versions Tesla de Fermi qui sont dévoilées aujourdhui avec pas moins de 4 produits : Tesla C2050, Tesla C2070, Tesla S2050 et Tesla S2070. Comme avec les gammes précédentes, les versions C représentent une carte seule alors que les versions S correspondent aux racks 1U équipés de pas moins de 4 cartes C.
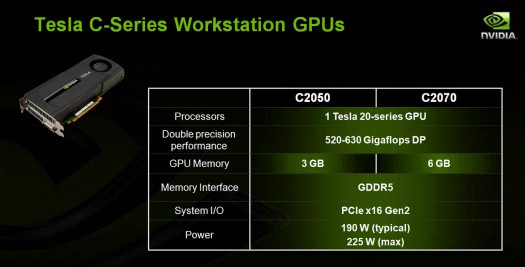

Bien que les produits et leur tarification soient annoncés, les spécifications exactes nont pas encore été dévoilées par Nvidia, les produits nétant en réalité pas encore prêts. Si nous savons maintenant que les version 50 seront équipées de 3 Go contre 6 Go pour les versions 70, les fréquences tant du GPU que de la GDDR5 restent inconnues. Le fabricant attend probablement que les tests sur la dernière révision de la puce soient terminés pour fixer les fréquences finales. Nvidia donne cependant une fourchette de puissance de calcul en double précision avec 520 à 630 Gflops, ce qui correspond à une fréquence pour les unités de calcul de 1 à 1.2 GHz, ce qui nous a surpris puisque cest relativement faible. Pour rappel, dans notre analyse de Fermi, nous avions pris pour exemple une fréquence pour les unités de calcul de 1.6 GHz en estimant être relativement conservateurs.
Cette fréquence faible, malgré la gravure en 40 nanomètres, permet cependant à Fermi de se démarquer considérablement des cartes Tesla actuelles en double précision, son architecture étant particulièrement bien fournie à ce niveau. Par contre, du coup, Nvidia ne parle pas de la puissance de calcul en simple précision qui sera comprise entre 1040 à 1260 Gflops contre 933 Gflops pour les cartes Tesla C1060 et 1036 Gflops pour les GPUs du système Tesla S1070. Des chiffres qui sont alors tout sauf impressionnants sur le papier, dautant plus par rapport au GPU haut de gamme dAMD, Cypress, qui affiche 544 Gflops en double précision et 2720 Gflops en simple précision.


Mais il faut rappeler que Fermi dispose dune architecture nettement plus évoluée, notamment au niveau du sous-système mémoire et que la puissance de calcul des cartes Tesla actuelles est quelque peu surévaluée, Nvidia ayant décidé, pour afficher des chiffres 50% plus élevés, dinclure certaines unités de calcul qui ne sont que partiellement exploitables en pratique. Lun dans lautre, les Tesla série 20 apporteront donc un gain conséquent en simple précision également, bien que cela ne saute pas aux yeux au niveau des chiffres officiels. Reste que par rapport à loffre AMD, et en ignorant la couche logicielle plus avancée chez Nvidia, il est difficile de tirer des conclusions sur base de ces chiffres sans avoir pu voir ce dont est capable Fermi en pratique.
Faut-il sinquièter de cette fréquence relativement faible ? Elle pourrait en effet témoigner dun souci au niveau de la production de cette puce très complexe qui représente pas moins de 3 milliards de transistors. Il est également possible que Nvidia ait décidé de réserver les GPUs qui tiennent les plus hautes fréquences aux GeForce, ce serait cependant étonnant puisque la gamme Tesla exploite en général les meilleurs échantillons pour garantir une fiabilité optimale.
La raison pourrait donc plutôt provenir de la consommation de la carte et de son déploiement dans les plateformes existantes. Nvidia annonce une consommation maximale de 225W (consommation typique de 190W) pour une carte Tesla C2070 et une consommation maximale de 1200W (consommation typique de 900W) pour un système Tesla S2070. Pour info une carte Tesla C1060 est annoncée avec une consommation maximale de 190W et un système Tesla S1070 à 800W (consommation typique de 700W). Une gourmandise qui pourrait rendre la montée en fréquence difficile, dautant plus que Nvidia doit vouloir réutiliser les plateformes actuelles pour éviter de devoir en redévelopper et revalider de nouvelles et ainsi perdre beaucoup de temps alors que la stratégie semble être de commercialiser les dérivés Tesla au plus vite, soit au second trimestre 2010.
Enfin, il est également possible que larchitecture Fermi soit tout simplement suffisamment efficace que pour pouvoir se contenter de fréquences réduites, dautant plus que son exploitation plus aisée suffira à convaincre de nombreux développeurs, nous navons aucuns doutes à ce sujet. Reste bien entendu à voir ce que Nvidia nous réserve du côté des GeForce : quelles seront les fréquences et les spécificités graphiques de cette architecture ?