
Les contenus liés au tag AMD
Afficher sous forme de : Titre | FluxAFDS: OpenCL gagne du terrain ?
AFDS: AMD Fusion 11 Developer Summit
Focus: AMD lance les A-Series Mobile
Gamme AMD A-Series mobile
Gamme AMD A-Series desktop
AFDS: L'architecture des futurs GPUs AMD!



La première journée du Fusion Summit s'est terminée par une session surprenante durant laquelle Michael Mantor, Senior Fellow Architect, et Mike Houston, Fellow Architect, ont dévoilé la future architecture GPU d'AMD avec de très nombreux détails, ne laissant que quelques éléments spécifiques au rendu 3D de côté.

Michael Mantor, AMD Senior Fellow Architect.
AMD travaille sur cette nouvelle architecture depuis près de 5 ans déjà et a pour objectif principal d'en simplifier le modèle de programmation pour convaincre un maximum de développeurs de se pencher sur la puissance de calcul offerte par les GPUs. Il s'agit également de la première architecture a avoir été influencée en profondeur par l'intégration d'ATI dans AMD et par le projet Fusion.

Cette architecture marque ainsi une rupture significative par rapport aux GPUs actuels en se débarrassant du modèle VLIW, qui repose sur l'exécution simultanée de plusieurs instructions indépendantes, au profit d'un fonctionnement scalaire du point de vue du programmeur. Le front-end, les processeurs de commandes et la structure des caches ont par ailleurs été entièrement revus pour proposer un mode compute plus performant et plus flexible ainsi que pour traiter efficacement le multitâche qui va devenir de plus en plus importants pour les GPUs.
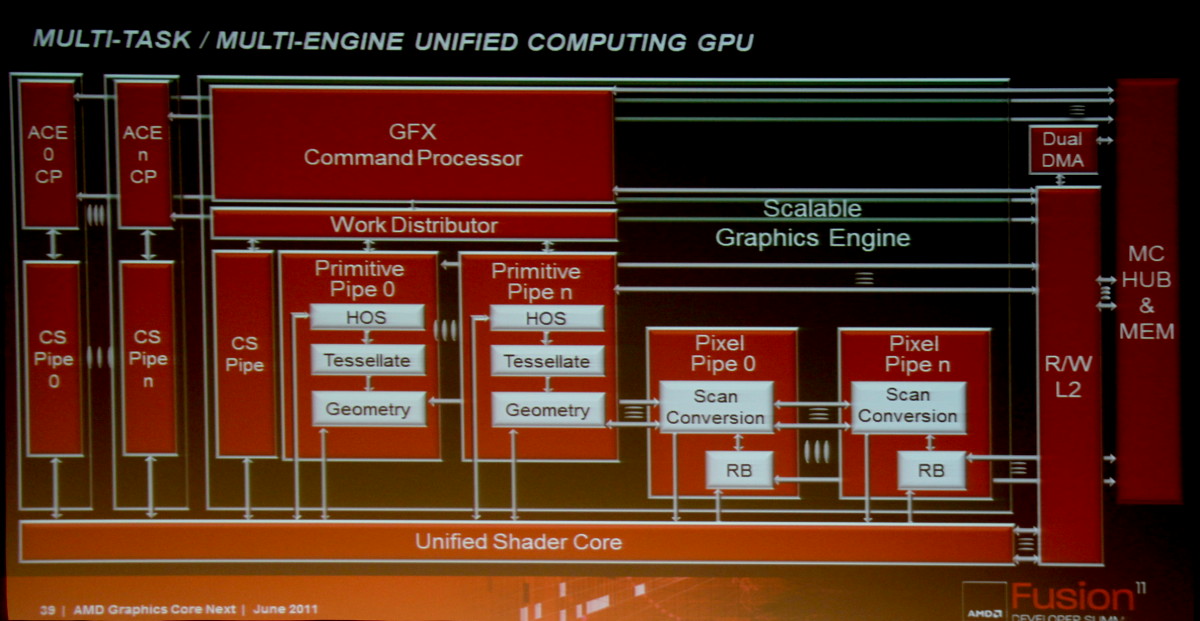
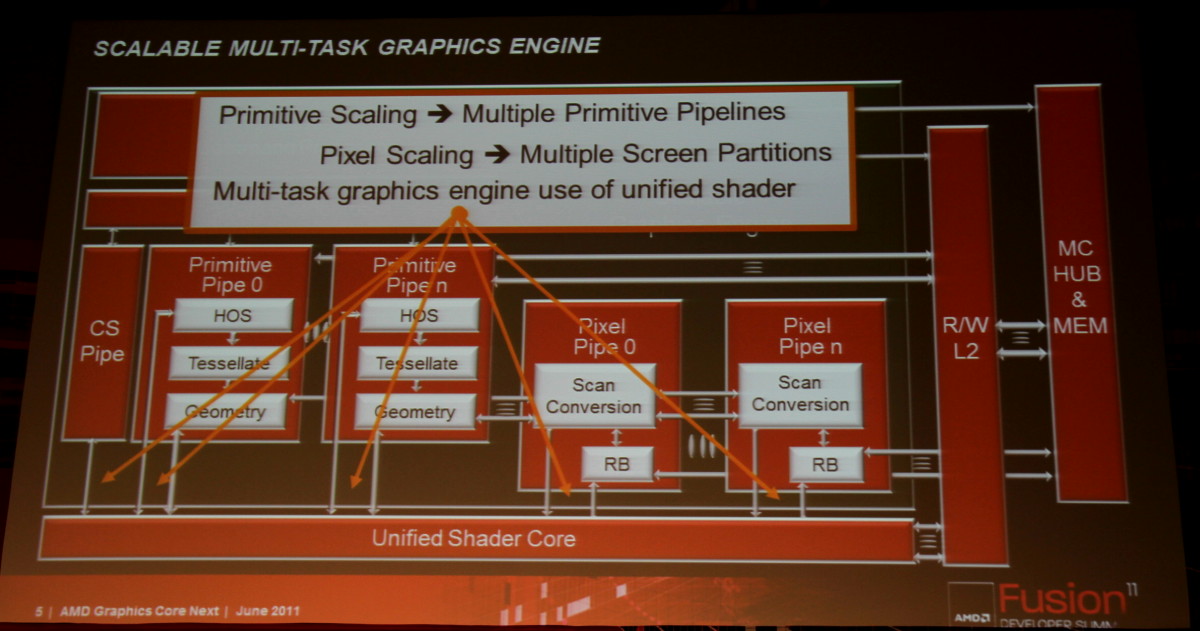
Des Asynchronous Compute Engines (ACE) font ainsi leur apparition pour prendre en charge les tâches compute sans passer par la partie graphique. Cette dernière n'est cependant pas en reste puisque les unités de gestion de la géométrie et des pixels sont parallélisées, ce qui profitera à la tessellation. Contrairement à l'approche de Nvidia, la prise en charge de la géométrie n'est pas distribuée au niveau des blocs d'unités de calcul, mais reste découplée de celles-ci.
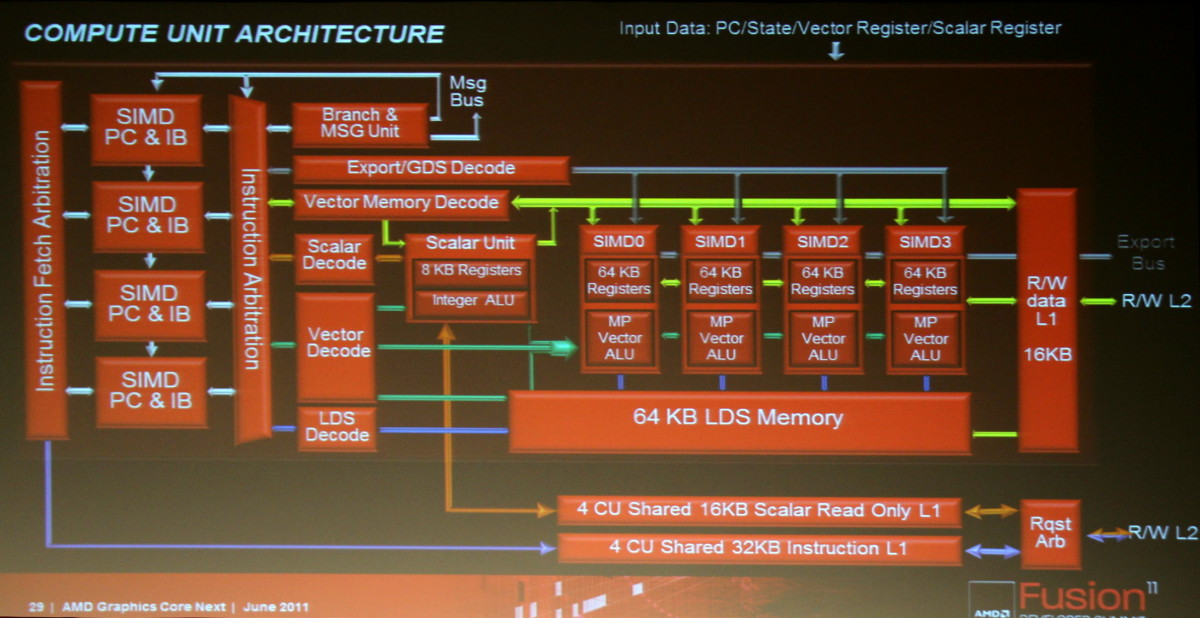
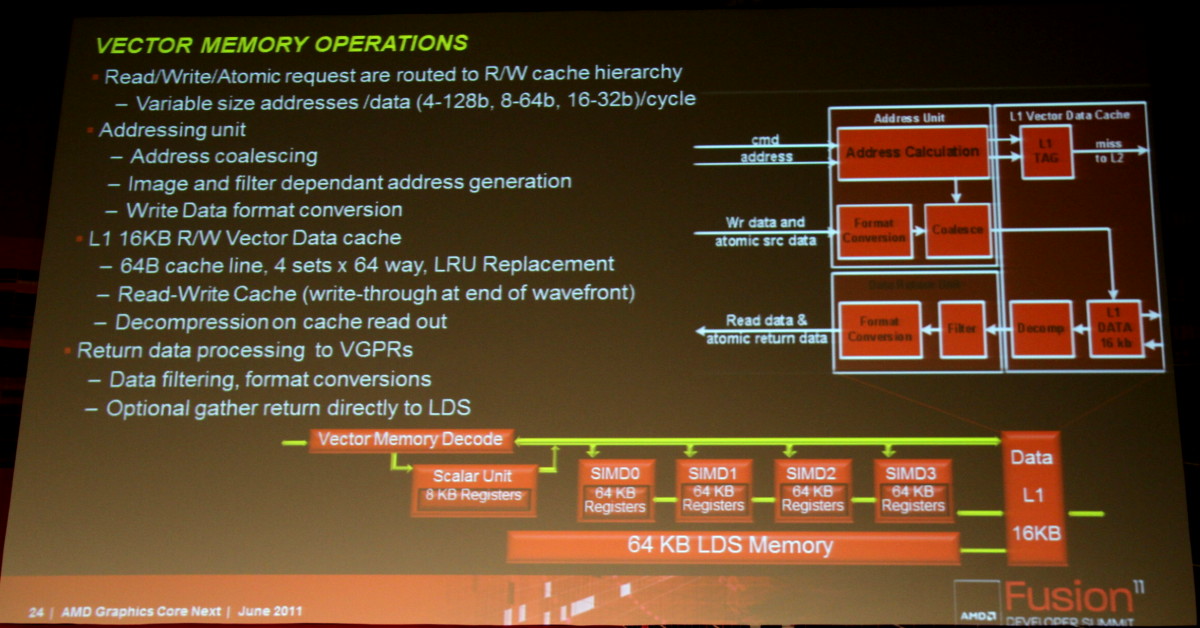
Les SIMDs actuels disparaissent au profit de Compute Units. Chaque CU dispose dorénavant d'une unité scalaire et de 4 petits SIMDs indépendants similaires à ceux des GPUs Nvidia. Grossièrement, un SIMD de Cayman peut exécuter une instruction vec4 sur 16 éléments à chaque cycle alors que chaque CU est capable d'exécuter 4 instructions sur 16 éléments issus de 4 groupes différents plus une instruction scalaire. La puissance de calcul d'une CU est donc similaire à celle d'un SIMD actuel mais devrait gagner nettement en efficacité.
AMD n'a pas voulu préciser quand cette architecture devrait être introduite et s'est contenté d'indiquer que le GPU de Trinity ne serait pas basé sur celle-ci mais bien sur l'architecture vec4 des Radeon HD 6900. Les bruits de couloir nous font cependant état d'une arrivée prévue dès cette année, voire même d'une démonstration du GPU qui l'inaugurera lors du keynote de clôture du Fusion Summit !
Il ne faudrait donc attendre que quelques mois pour voir ce qu'apportera en pratique cette nouvelle architecture prometteuse sur le papier. Si elle facilitera à terme l'optimisation du compilateur GPU, elle demandera cependant un effort important aux équipes chargées des pilotes compte tenu de la rupture avec les GPUs actuels. Concernant le coût de cette nouvelle architecture, AMD nous a indiqué qu'il n'était que légèrement plus élevé que celui des architectures actuelles, certaines parties étant plus complexe mais d'autres simplifiées. Elle ne devrait donc pas être un frein à l'augmentation du nombre d'unités de calcul.
Notez que cette architecture proposera plus de modularité qu'auparavant puisqu'en plus du nombre de CUs, AMD pourra faire varier le nombre d'ACEs, le nombre de pipelines dédiées à la géométrie ou aux pixels, la puissance de calcul en double précision (de 1/2 à 1/16) De toute évidence, la première implémentation devrait être un GPU haut de gamme avec au moins 30 CUs, plusieurs ACEs et un calcul en double précision à demi-vitesse.
Voici donc les grandes lignes de cette future architecture, sur laquelle nous essaierons de revenir plus en détails après le Fusion Summit.
Nous avons publié quelques informations de plus dans une seconde actualité et voici tous les détails dévoilés par AMD sur cette architecture :




















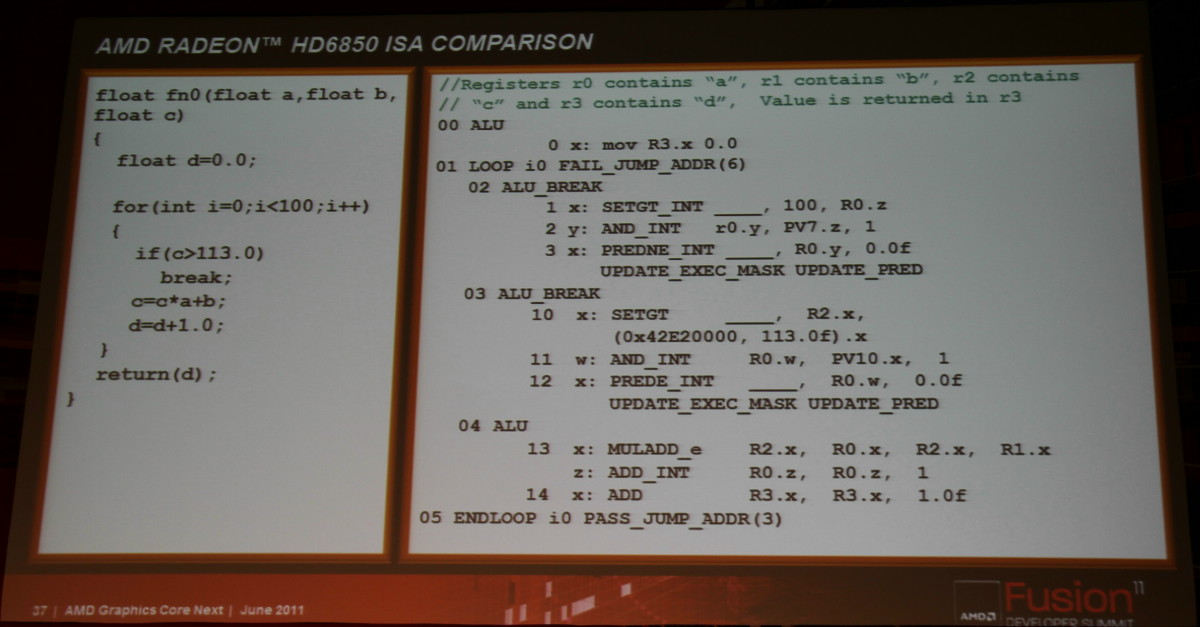
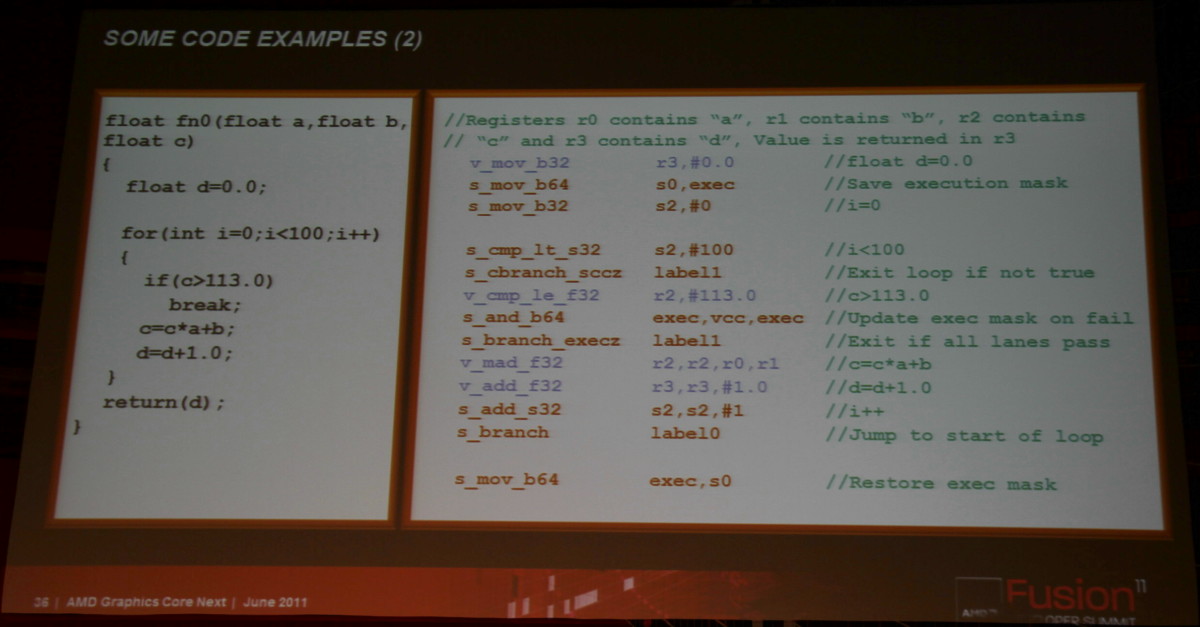
Ainsi que deux exemples de code généré pour l'architecture actuelle d'une part et pour cette nouvelle architecture d'autre part :


AFDS: +50% pour Trinity et 10 Tflops en 2020
AMD profite de l'ouverture de son forum technologique pour annoncer dans les grandes lignes les objectifs concernant les produits Fusion à venir. Comme vous le savez probablement déjà, Llano sera remplacé en 2012 par Trinity, qui reposera sur des cores Bulldozer et sur un GPU plus costaud. Concernant celui-ci, AMD vient d'annoncer qu'il afficherait une puissance de calcul en hausse de plus de 50%, ce qui signifie qu'il intègrera probablement 640 unités de calcul contre 400 pour Llano.

Au Computex, AMD avait présenté un exemplaire de Trinity de manière à démontrer que cet APU existait déjà à l'état de prototype. La société va cette fois plus loin puisque nous avons pu avoir une démonstration d'une version mobile de Trinity, certes limitées à de la lecture vidéo, mais qui confirme que ce composant est déjà à l'état fonctionnel chez AMD.
Rick Bergmann, SVP et General Manager du Products Group d'AMD, termine en indiquant que l'objectif est de pouvoir proposer un APU avec une puissance de calcul de 10 Tflops à l'horizon 2020, ce qui correspond à la puissance de calcul d'un couple de 2 Radeon HD 6990, soit à 4 GPUs haut de gamme actuels !

Un Turbo montant à 1 GHz pour les AMD FX ?
Nos confrères turcs préférés continuent sur leur lancée en publiant un nouveau slide évoquant le mode Turbo des AMD FX. A l'image des APU Llano (voir notre section sur la gestion d'énergie), AMD a implémenté un power gating pour chaque cur (plus exactement, on l'imagine, par module) permettant de les désactiver complètement lorsqu'ils sont inactifs. Le power gating et le Turbo pourraient d'ailleurs être, selon certains documents que nous avons pu voir, la fonctionnalité réservée aux cartes mères AM3+ qu'AMD évoquait cryptiquement dans une de nos actualités précédentes vis à vis de la compatibilité des FX sur les cartes mères AM3.
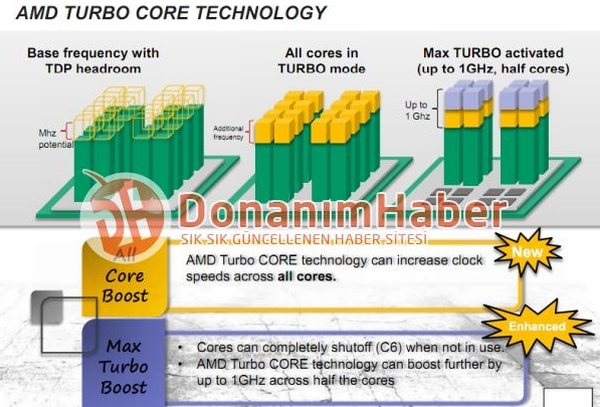
A l'image de ce que fait Intel avec Nehalem, les FX disposeront d'une fréquence de base qui sert plus de référence qu'autre chose puisque même avec tous les curs actifs, un FX verra ses curs accélérés via le mode Turbo tant que l'on reste dans les contraintes thermiques imposées. Le mode Turbo atteindrait son potentiel maximal lorsqu'au moins la moitié des curs serait désactivé. Le chiffre de 1 GHz est alors avancé, mais il faut le prendre avec circonspection : il indique simplement l'écart entre la fréquence de référence et la fréquence Turbo maximale. En baissant la fréquence de référence par rapport à celle du Turbo autorisé lorsque tous les curs sont actifs, il est possible simplement d'agrandir cet écart.
Fin de vie programmée pour les Phenom II X6
Nos confrères de DonanimHaber continuent de publier des slides issus de la roadmap d'AMD avec aujourd'hui un point sur le futur des processeurs Phenom II X6. On y apprend que le constructeur placera en fin de vie l'intégralité de ses puces hexacore d'ici à la fin de l'année.
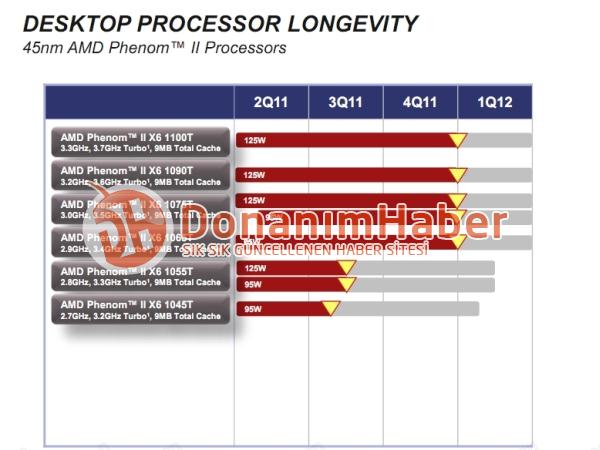
Un mouvement qui laisse penser que la compatibilité, encore assez mal définie des puces Zambezi sur les plateformes AM3 actuelles est possiblement relativement large et non limitée à quelques modèles. L'absence de mot sur la fin de vie programmée des Phenom II X4 nous laisse penser cependant que ces derniers seront peut être maintenus plus longtemps pour assurer la longévité de la plateforme AM3.
Preview de l'AMD A8-3850
AMD a autorisé auprès de nos confrères d'Anandtech une publication de quelques chiffres de performances d'un des processeurs de bureau Llano, l'A8-3850 (le plus haut de gamme), pourtant encore sous NDA et dont le lancement ne devrait pas avoir lieu avant le mois de juillet. Comme nous l'expliquions un peu plus tôt, les APU A-Series d'AMD mélangent côté CPU l'architecture d'un Athlon II à celle, côté GPU, d'une Radeon HD 5570.

L'APU A8-3850 dans les doigts d'Anand...
Bien que (heureusement ) réduite, cette preview nous montre que, comme nous l'attendions, l'A8-3850 est, à fréquence égale, légèrement plus rapide que son équivalent en Athlon II X4, le 635, on notera pour les cas les plus favorables un bond en avant de 7.9% dans Cinebench R10 en version monothreadée et 7.4% en version multithreadée. Dans un test d'encodage vidéo via x264, le gain est plus réduit, à 2.9%. La présence d'un Mo de cache par core au lieu de 512 Ko fait le gros de la différence.
Côté GPU, la perte est plus significative, là encore sans surprise à cause de l'absence de mémoire dédiée à la partie graphique qui se contente d'utiliser la mémoire système. Face à une Radeon HD 5570 DDR3 cadencée à 650 MHz, contre 600 MHz pour la partie GPU de l'APU, en 1280 par 1024 on perd 29% de performances dans Crysis Warhead ou Dirt 2, et 31% dans Mass Effect 2, le niveau de performances étant plus proche de celui de la Radeon HD 6450.