Les contenus liés au tag AMD
Afficher sous forme de : Titre | FluxAFDS: L'architecture des futurs GPUs AMD!
AFDS: +50% pour Trinity et 10 Tflops en 2020
Un Turbo montant à 1 GHz pour les AMD FX ?
Fin de vie programmée pour les Phenom II X6
Preview de l'AMD A8-3850
12 cartes mères Llano pour Gigabyte



Après avoir été extrêmement actif sur le marché des cartes mères Z68, Gigabyte prépare une gamme de cartes mères très étendue pour les futurs APU A-Series en version desktop. Si nous avions pu voir deux modèles au Computex, la gamme de cartes mères Llano comportera 12 membres.

Gigabyte ne détaille pas encore les différences entre les modèles et parle simplement de la GA-A75UD4H.

Comme nous l'avions vu au Computex, la carte est compatible CrossfireX et intègrera une sortie Dual-DVI nécessaire pour piloter les écrans 2560x1600 et 3D.
AFDS: Retour sur le futur GPU d'AMD

Lors du dernier keynote de l'AFDS, Eric Demers, Chief Technology Officer pour la partie GPU chez AMD, est revenu sur la future architecture GPU qui a été présentée avec de très nombreux détails cette semaine, de manière à en mettre en avant les grandes lignes d'une manière simplifiée. Il a également été confirmé qu'AMD espérait lancer cette architecture à la fin de l'année, si le procédé de fabrication 28nm n'entrave pas ces plans.
Eric a rappelé que l'évolution des GPUs ATI/AMD nous a fait passer d'une architecture au comportement vec4 + 1 vers une architecture vec5 à partir des Radeon HD 2900 puis enfin vers une architecture vec4 avec les Radeon HD 6900 qui sera déclinée dans de futurs GPUs milieu et bas de gamme ainsi que dans Trinity. Ces choix architecturaux s'expliquent par la présence de nombreuses opérations vec4 mais aussi scalaires dans le rendu graphique qui reste la tâche principale des GPUs. La flexibilité des unités de calcul de type MIMD/VLIW des derniers GPUs a permis de se passer du canal scalaire et de laisser le compilateur se charger de mixer toutes les opérations dans les 5 ou 4 canaux disponibles.
Avec sa future architecture, AMD a voulu conserver une organisation similaire. Si le modèle VLIW est abandonné, les blocs fondamentaux de ces GPUs vont garder ces 4 canaux, non pas pour exécuter des opérations vec4 mais pour conserver un ratio similaire et vu comme le plus adapté pour le graphique. Les tâches de type "compute" devenant de plus en plus importantes et affichant souvent une utilisation moindre des unités vec5 ou vec4, il fallait revenir à un modèle scalaire du point de vue du programmeur.
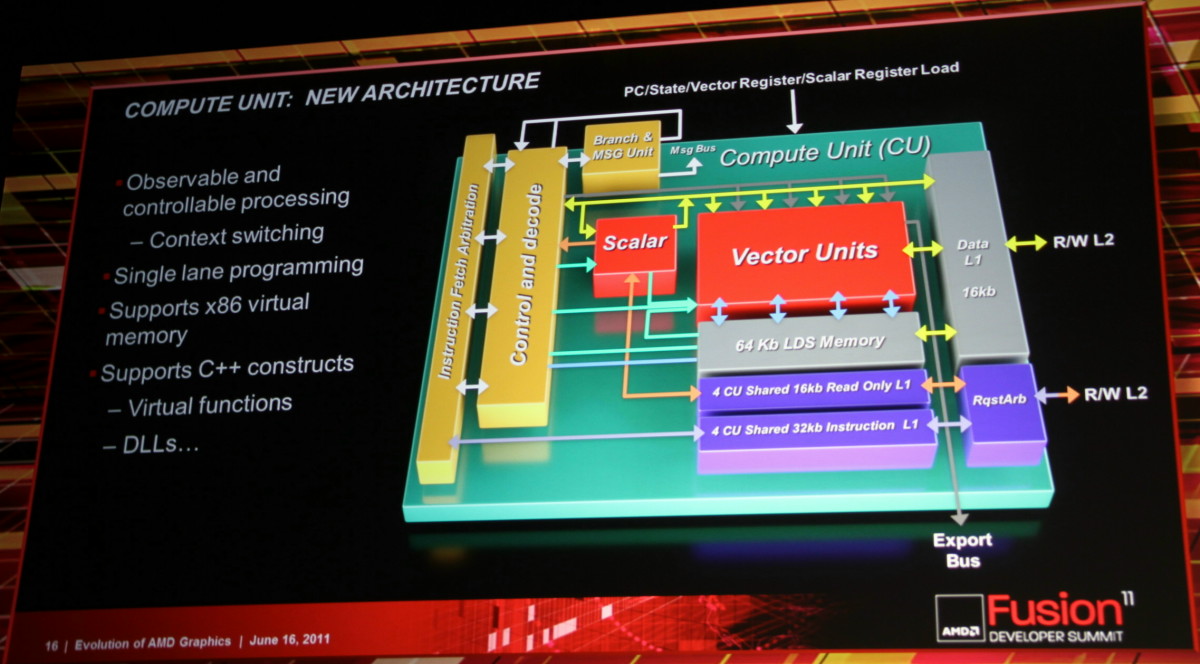
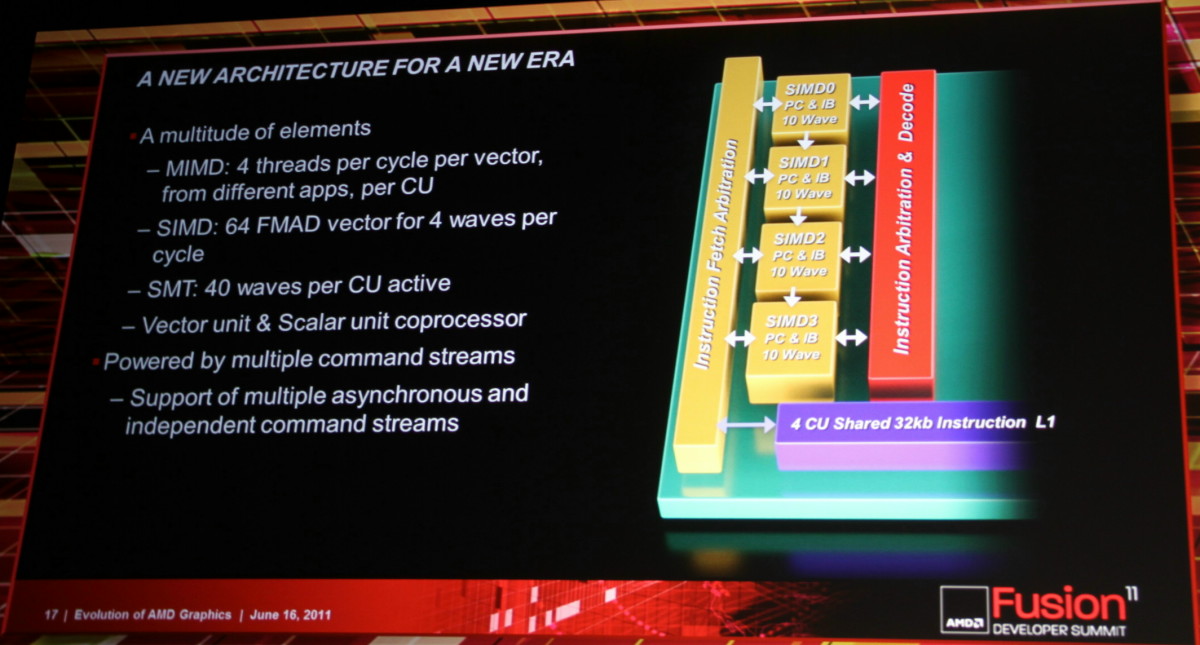

L'architecture proposée par AMD permet de combiner ces deux aspects en plaçant dans chaque Compute Unit non pas une grosse unité MIMD mais 4 plus petites unités SIMD indépendantes. Par ailleurs, AMD leur adjoint une unité scalaire qui sera destinée à éviter de monopoliser la puissance de calcul vectorielle par des opérations simples. Comme pour les blocs fondamentaux des GPUs actuels, chaque CU recevra 4 unités de texturing. Une CU est donc, sur le plan des unités d'exécution, très proche de ce qu'AMD appelle actuellement les SIMDs. C'est au niveau de l'exploitation de ces unités d'exécution que le changement est radical. Le GPU Cayman des Radeon HD 6900 peut d'ailleurs être vu comme une étape intermédiaire vers cette nouvelle architecture. Un côté hybride/prototype qui explique probablement son efficacité discutable.
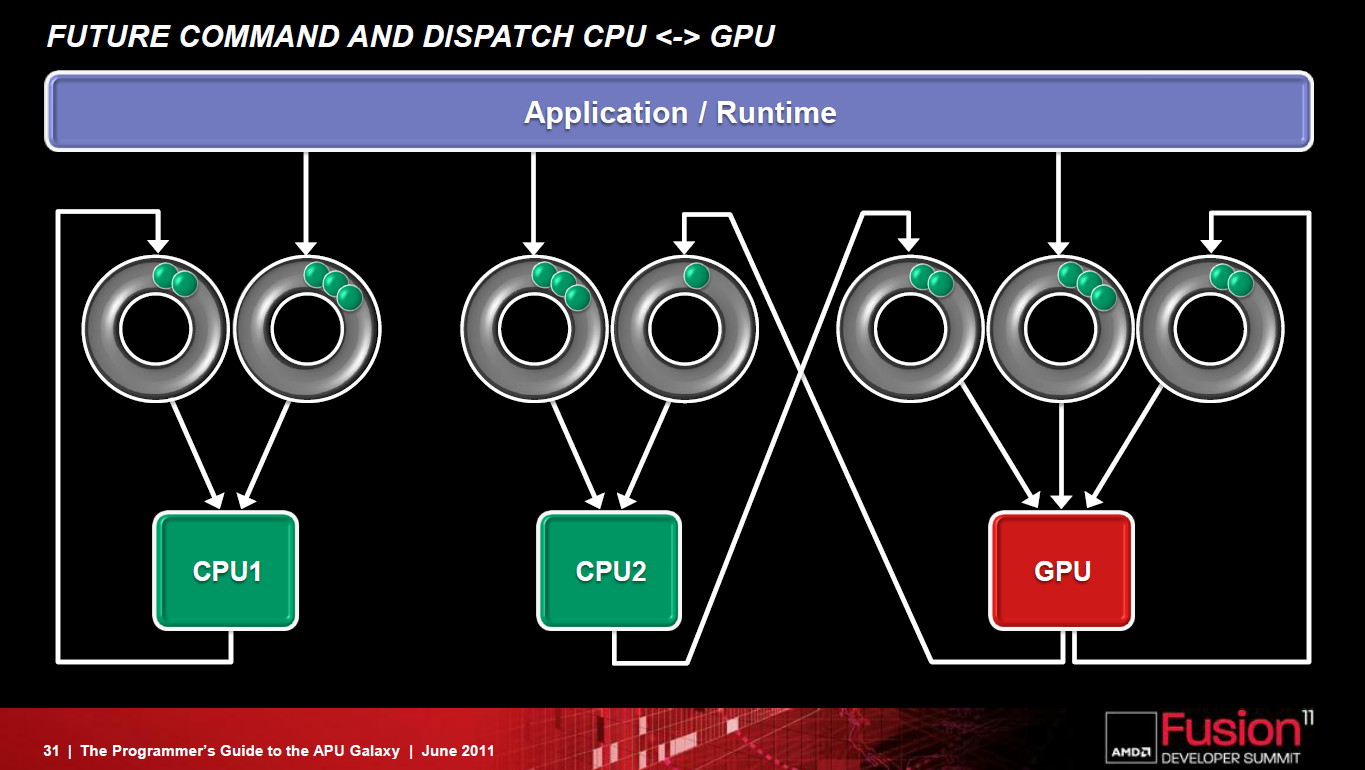
Un autre aspect important de la nouvelle architecture est le multitâche puisque ces nouveaux GPUs seront capables de gérer différentes commandes simultanément ainsi que la priorité à donner à chacune d'elles. Tout ceci se passera au niveau du GPU et non au niveau du système d'exploitation.
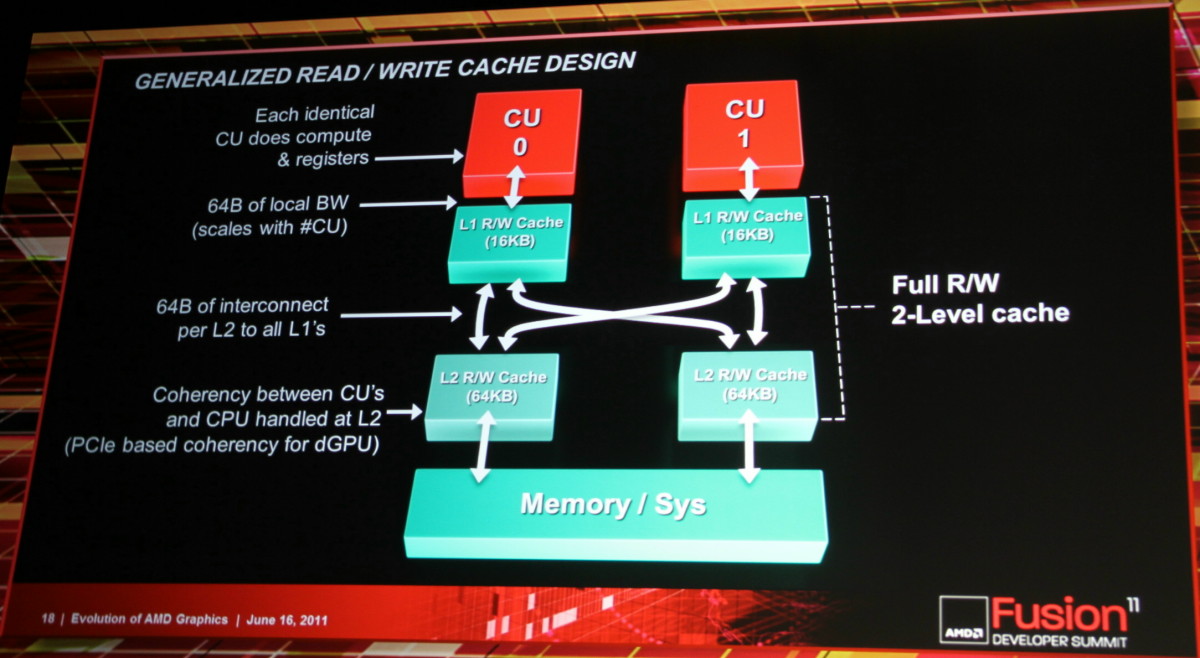
Le cache L2 utilisable en lecture et en écriture est la troisième grosse évolution. Il permet également l'existence d'un espace cohérent entre toutes les CUs ainsi qu'avec le CPU, que ce soit à l'intérieur d'un APU ou avec une carte graphique dédiée.
Ce cache L2 généralisé, le fonctionnement scalaire des unités de calcul, le support de l'espace mémoire virtuel x86 et du C++ vont faire exploser l'intérêt du GPU computing. Notez cependant que sur certains de ces points, AMD ne fait que rattraper le retard pris sur Nvidia.



Une interrogation importante que nous avons par rapport à cette nouvelle architecture est son efficacité énergétique. Comme nous avons pu le voir avec les Radeon HD 6970, elle était quelque peu en baisse. Augmenter le rendement d'une Compute Unit va donc faire progresser sa consommation relative. Si le procédé de fabrication 28nm permettra d'en faire baisser la consommation absolue, la question reste importante.
Nous avons pu nous entretenir avec Eric Demers à ce sujet et selon lui il s'agit d'un faux problème. Dans l'architecture actuelle, quand certaines lignes des unités vec4 ou vec5 ne sont pas utilisées, elles restent alimentées. Leur consommation est moindre que quand elles sont exploitées, mais elles gaspillent malgré tout beaucoup d'énergie. Ce gaspillage va disparaître avec la future architecture. En d'autres termes, nous nous approcherons probablement plus souvent de la consommation maximale des Compute Units, mais leur rendement énergétique serait dans tous les cas supérieur.
Enfin, nous avons demandé au CTO d'AMD s'il envisageait d'inclure à l'avenir dans les GPUs plus de CUs que ne le permet le TDP, tout en sachant qu'ils ne pourraient pas tous être exploités en rendu 3D (limités par PowerTune par exemple), mais en supposant qu'ils pourraient l'être dans le mode compute qui n'exploite pas certaines parties du GPU très gourmandes telles que les unités de texturing. Eric Demers nous a répondu qu'AMD envisageait effectivement cela et qu'une telle possibilité pourrait éventuellement être retenue à l'avenir, si les simulations le justifiaient, notamment pour un GPU qui viserait le HPC.
AFDS: Le GPU de Trinity dérivé des HD 6900
Lors de la présentation de sa future architecture, AMD a accidentellement divulgué un détail important sur le GPU de sa future APU Trinity : il sera dérivé de l'architecture des Radeon HD 6900. Pour rappel, cette architecture repose sur des unités de calcul vec4 au lieu de vec5 au rendement par unité de surface quelque peu plus élevé, ce qui facilite l'augmentation de leur nombre.

Un prototype de portable équipé de Trinity.
Si nous supposions il y a quelques jours que le GPU de Trinity pourrait intégrer 640 "cores" nous estimions alors qu'il s'agirait de 128 unités de calcul vec5. Etant donné l'utilisation confirmée d'unités vec4, s'il est possible que Trinity en intègre 160, nous estimons dorénavant plus probable qu'il s'agisse de 128 unités vec4 soit de 512 "cores", ce qui devrait suffire à proposer un gain de 50% au niveau de la partie GPU.
AMD Catalyst 11.6
La version de juin des pilotes graphiques d'AMD vient d'être mise en ligne sur le site du constructeur. Il s'agit des premiers pilotes dédiées aux APU Llano, ils implémentent entre autre la fonctionnalité Steady Video dont nous parlions dans notre preview sur les APU A-Series du constructeur. Comme nous le redoutions, la fonctionnalité est grisée sur un PC équipé d'une Radeon et semble réservée uniquement aux APU.
Pour le reste les pilotes apportent un décodage XviD accéléré dans les applications Microsoft type Media Center et corrigent un certain nombre de bugs concernant Crossfire dans F1 2010, The Witcher 2, Riddick 2, Cars 2, Civilization V et Lego : PotC.
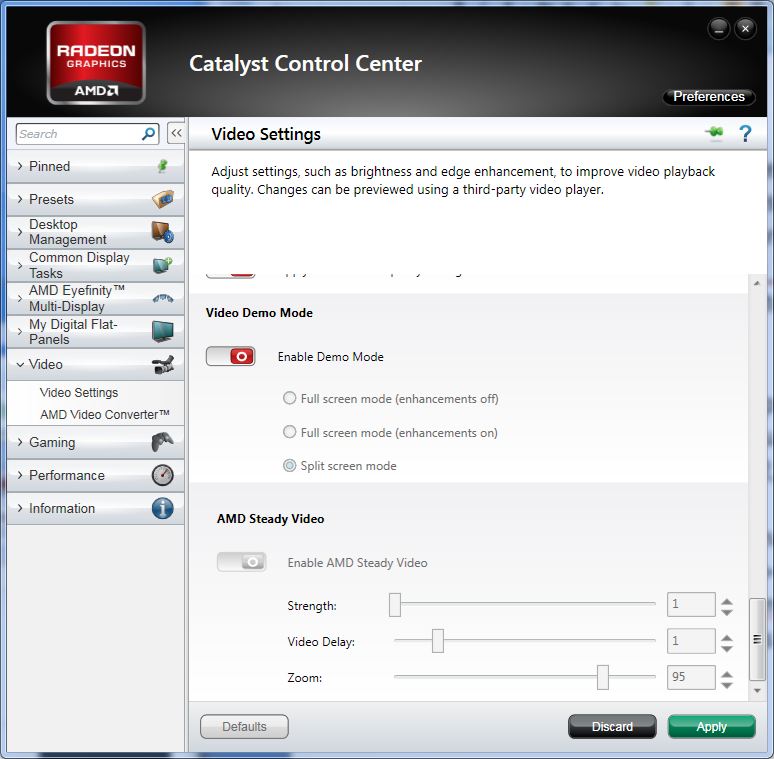
Quelques gains de performances sont également ajoutés pour les HD 6000 allant jusque :
- +7% dans Crysis
- +8% dans F1 2010 en mode DirectX 11
- +5% dans FarCry 2
- +8% dabs HAWX
- +10% dans Unigine OpenGL
Vous pourrez retrouver ces pilotes en téléchargement sur le site d'AMD .
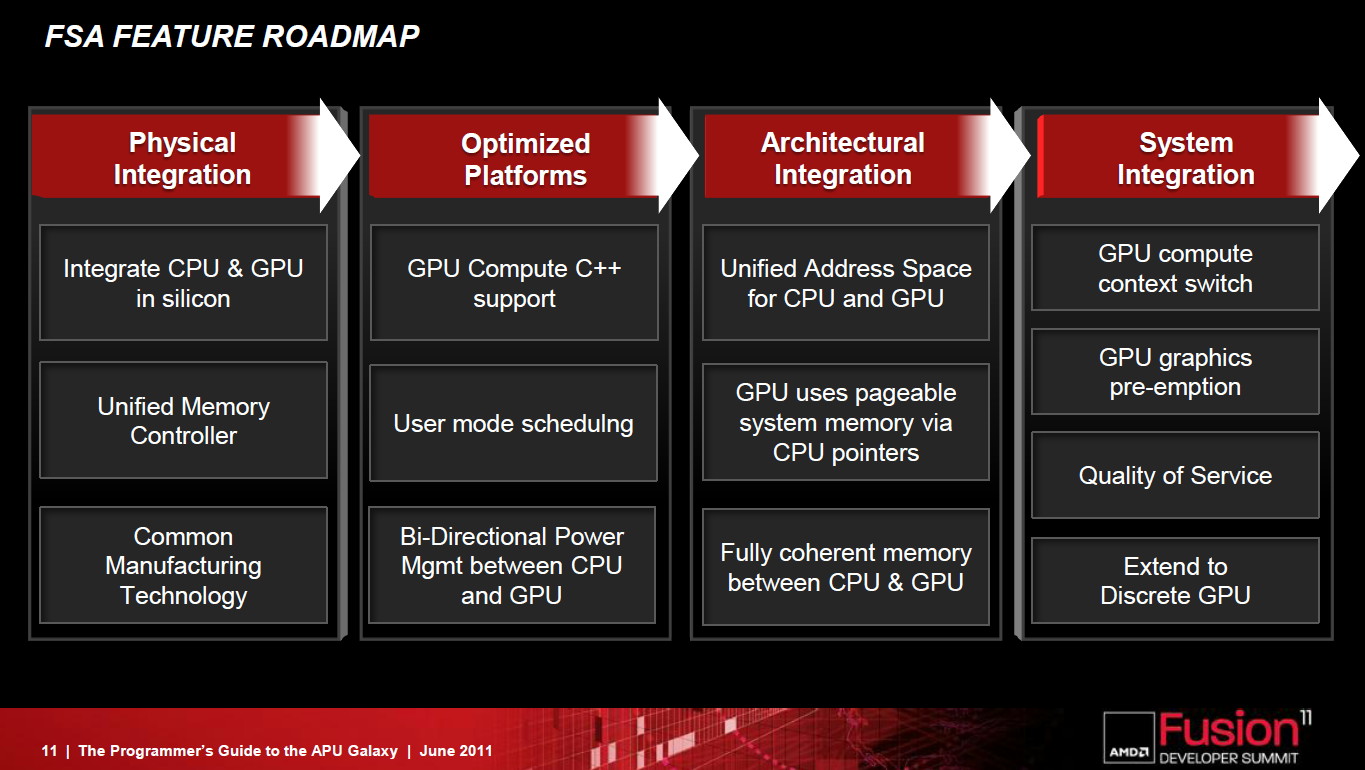
AFDS: AMD dévoile la FSA pour OpenCL
Ce qui est probablement l'annonce la plus importante de l'AFDS a été quelque peu éclipsée hier compte tenu des détails dévoilés sur la future architecture des GPUs AMD : la FSA.

Phil Rogers, AMD Corporate Fellow, dévoile les évolutions à venir dans le calcul hétérogène.
Un frein à l'utilisation du GPU computing réside dans l'overhead énorme lié à son exploitation, un point qu'AMD entend bien faire disparaître avec la Fusion System Architecture, une combinaison hardware et software destinée à simplifier le GPU computing et son utilisation combinée avec les cores CPUs.
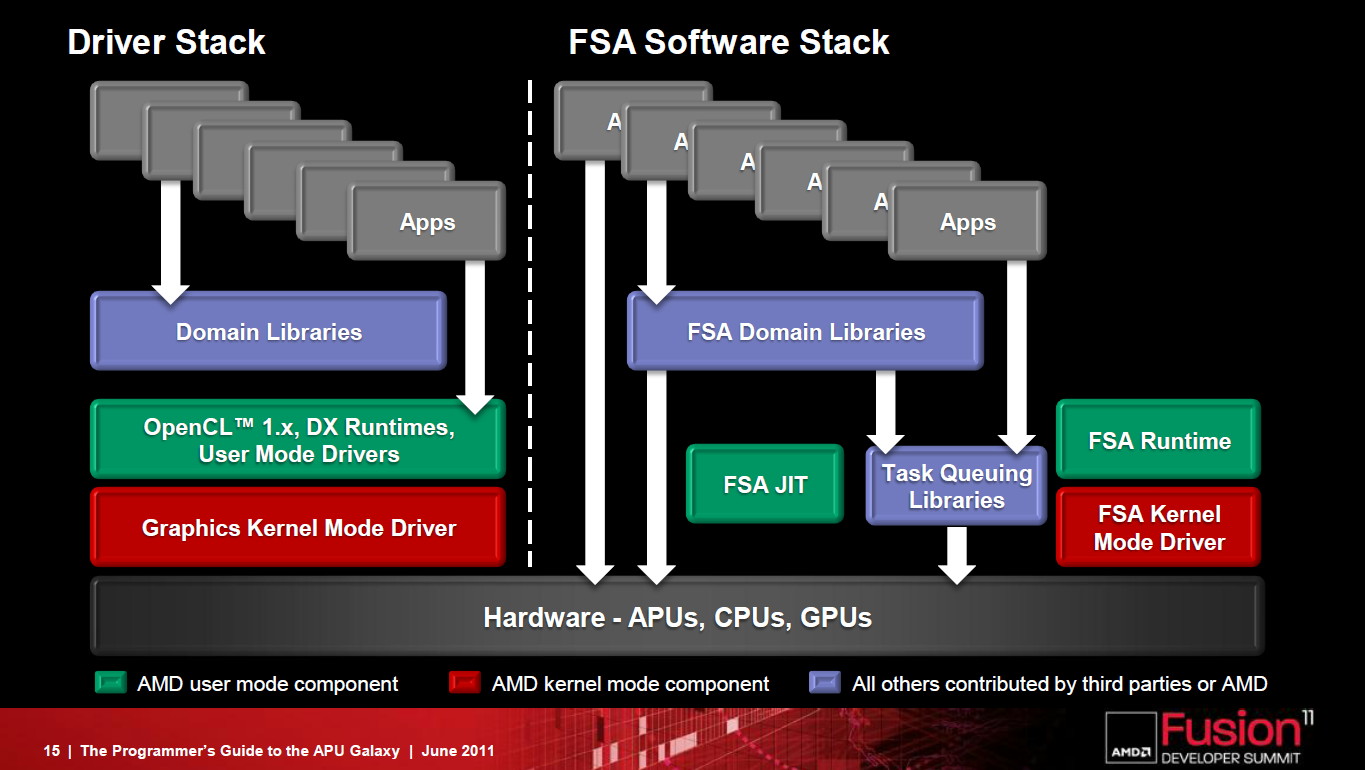
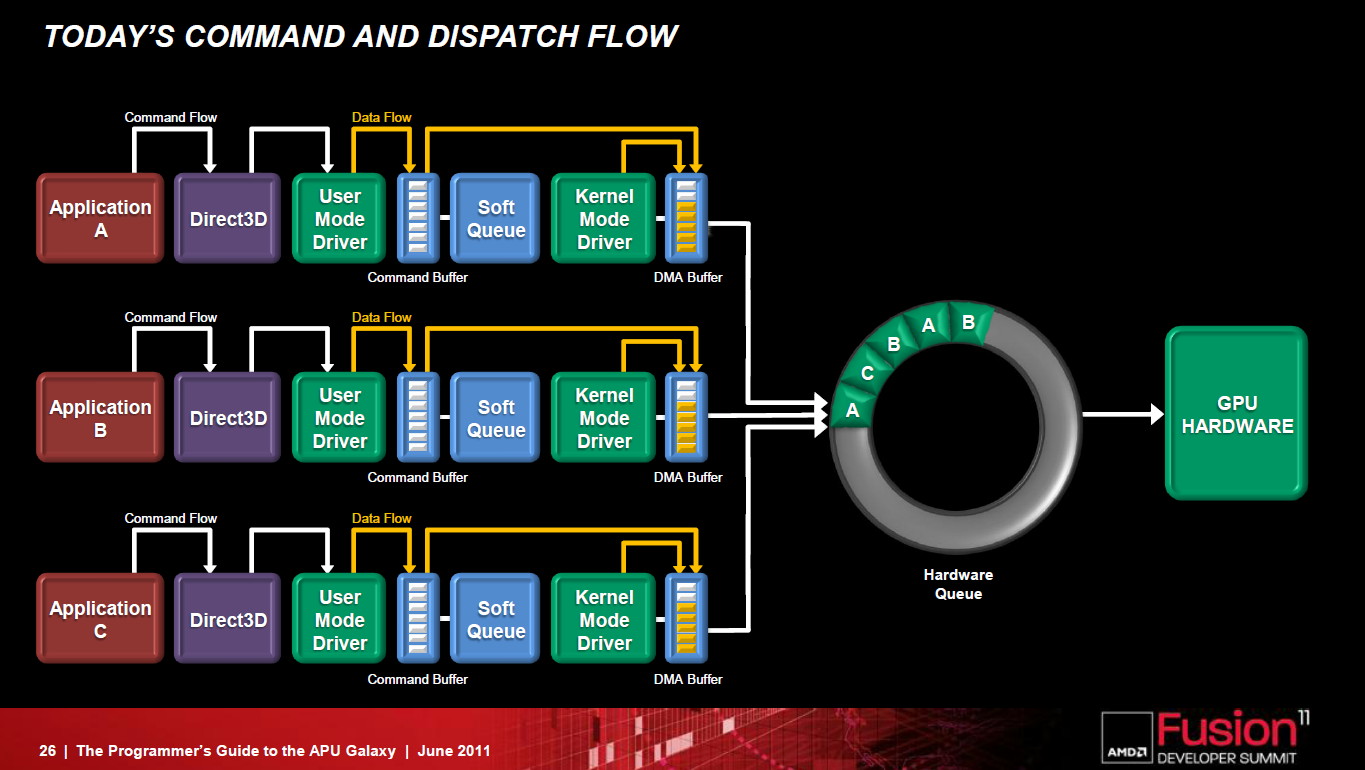

La FSA fait disparaître la lourdeur de la plateforme GPU compute actuelle.
Comme son nom l'indique, la FSA est avant tout pensée pour les APUs dans lesquels cores CPU et GPU sont proches l'un de l'autre, ce qui implique une communication simplifiée entre eux et une gestion d'un espace mémoire unifié plus simple à mettre en place. AMD compte cependant faire profiter les GPUs présents sur les cartes graphiques de tout ceci, grâce au PCI Express 3.0 qui offrira une bande passante supérieure ainsi qu'un espace unifié cohérent.

Cores CPU et GPU travaillent main dans la main plus efficacement grâce à la FSA.
La FSA n'est pas une nouvelle API mais une plateforme optimisée pour OpenCL et destinée à remettre à plat l'utilisation du GPU computing. Latence réduite, fin des copies de données inutiles entre les espaces CPU et GPU, pointeurs partagés entre CPU et GPU, possibilité d'un accès bas niveau au hardware pour des librairies hyper optimisées, modèle de queues hardware repris du SMP
L'arrivée complète de la FSA se fera dans les 3 ans selon AMD, dont une partie (le dispatching optimisé) introduite en principe cette année avec la nouvelle architecture GPU dévoilée à l'AFDS également. AMD entend rendre la FSA ouverte à la concurrence, reste à voir si cet appel trouvera un écho chez Intel et Nvidia !
Dans tous les cas il est intéressant d'observer qu'AMD, vu comme plutôt passif dans le domaine du GPU computing ces dernières années, à décidé de prendre à bras le corps les challenges que représentent son exploitation. Il faut dire que le fabricant n'a pas d'autre choix, les APUs ayant un besoin criant de telles évolutions pour montrer tout leur intérêt. La documentation complète de la FSA devrait être publiée avant la fin de l'année de manière à permettre aux développeurs de s'y préparer.