
Les contenus liés aux tags AMD et GCN
Afficher sous forme de : Titre | FluxDossier : AMD Radeon HD 7950 en test



Avec 3 semaines de retard, AMD lance enfin la Radeon HD 7950. Au menu : quelques unités de moins que la Radeon HD 7970 mais la promesse de capacités d'overclocking conséquentes. De quoi enterrer la GeForce GTX 580 ?
[+] Lire la suite

CES: 1GHz pour Pitcairn et la Radeon HD 7870?
Si AMD se refuse à rentrer dans les détails concernant les spécifications des deux autres GPU de la famille GCN, Pitcairn (Radeon HD 7800) et Cap Verde (Radeon HD 7700), nous avons pu les observer en action dans leur version mobile, qui devrait arriver dans le courant du printemps. AMD nous a malgré tout affirmé que la fréquence de Pitcairn serait supérieure à celle de Tahiti et de la Radeon HD 7970, ce qui laisse bien entendu penser que la barrière de 1 GHz pourrait être atteinte pour la première fois par un GPU de série.

AMD nous précise pouvoir monter plus facilement en fréquence avec Pitcairn étant donné que TSMC a peaufiné progressivement son procédé de fabrication de manière à réduire les courants de fuite par rapport à ce qui a été constaté sur les premiers lots de GPU Tahiti. AMD nous indique à son sujet que s'il dispose d'une large marge d'overclocking ce n'est pas par hasard mais dû à l'enveloppe thermique de 250W qui a limité la marge de manuvre pour les fréquences de référence. Nous ne serions donc pas étonnés de voir AMD proposer une évolution de la Radeon HD 7970 avec des fréquences plus élevées d'ici quelques mois, profitant des améliorations liées à la production pour compliquer la vie de Kepler !
Notez enfin qu'AMD indique que la marge d'overclocking de la Radeon HD 7950 sera également conséquente, mais garde toujours ses spécifications confidentielles.
Dossier : AMD Radeon HD 7970 & CrossFireX en test : 28nm et GCN
Tout juste avant Noël, AMD lève le voile sur la Radeon HD 7970. Au menu : l'architecture GCN fabriquée en 28nm, DirectX 11.1, le PCI Express 3.0 et bien sûr la promesse de performances en hausse !
[+] Lire la suite

Radeon HD 7000 en décembre ?
Nos confrères allemands de Heise font aujourd'hui l'écho d'une rumeur sur les prochains GPU d'AMD fabriqués en 28nm : AMD souhaiterait lancer ses premiers GPU en 28nm dans la seconde semaine de décembre, possiblement le 6 décembre prochain.
AMD avait déjà effectué une démonstration, en marge de l'IDF en septembre dernier d'un GPU mobile fonctionnel fabriqué en 28nm. On ne sait pas cependant si ce lancement visera les segments mobiles (peu probable) ou desktop, s'il s'agira d'une puce d'entrée, milieu ou haut de gamme, et encore moins si elles utiliseront l'actuelle architecture VLIW ou l'architecture GCN. Lors de l'AMD Fusion Developers Summit en juin dernier, Eric Demers avait indiqué que la firme espérait lancer ses GPUs basés sur la nouvelle architecture GCN avant la fin de l'année, si le procédé de fabrication en 28nm de TSMC suivait.
AFDS: Retour sur le futur GPU d'AMD

Lors du dernier keynote de l'AFDS, Eric Demers, Chief Technology Officer pour la partie GPU chez AMD, est revenu sur la future architecture GPU qui a été présentée avec de très nombreux détails cette semaine, de manière à en mettre en avant les grandes lignes d'une manière simplifiée. Il a également été confirmé qu'AMD espérait lancer cette architecture à la fin de l'année, si le procédé de fabrication 28nm n'entrave pas ces plans.
Eric a rappelé que l'évolution des GPUs ATI/AMD nous a fait passer d'une architecture au comportement vec4 + 1 vers une architecture vec5 à partir des Radeon HD 2900 puis enfin vers une architecture vec4 avec les Radeon HD 6900 qui sera déclinée dans de futurs GPUs milieu et bas de gamme ainsi que dans Trinity. Ces choix architecturaux s'expliquent par la présence de nombreuses opérations vec4 mais aussi scalaires dans le rendu graphique qui reste la tâche principale des GPUs. La flexibilité des unités de calcul de type MIMD/VLIW des derniers GPUs a permis de se passer du canal scalaire et de laisser le compilateur se charger de mixer toutes les opérations dans les 5 ou 4 canaux disponibles.
Avec sa future architecture, AMD a voulu conserver une organisation similaire. Si le modèle VLIW est abandonné, les blocs fondamentaux de ces GPUs vont garder ces 4 canaux, non pas pour exécuter des opérations vec4 mais pour conserver un ratio similaire et vu comme le plus adapté pour le graphique. Les tâches de type "compute" devenant de plus en plus importantes et affichant souvent une utilisation moindre des unités vec5 ou vec4, il fallait revenir à un modèle scalaire du point de vue du programmeur.
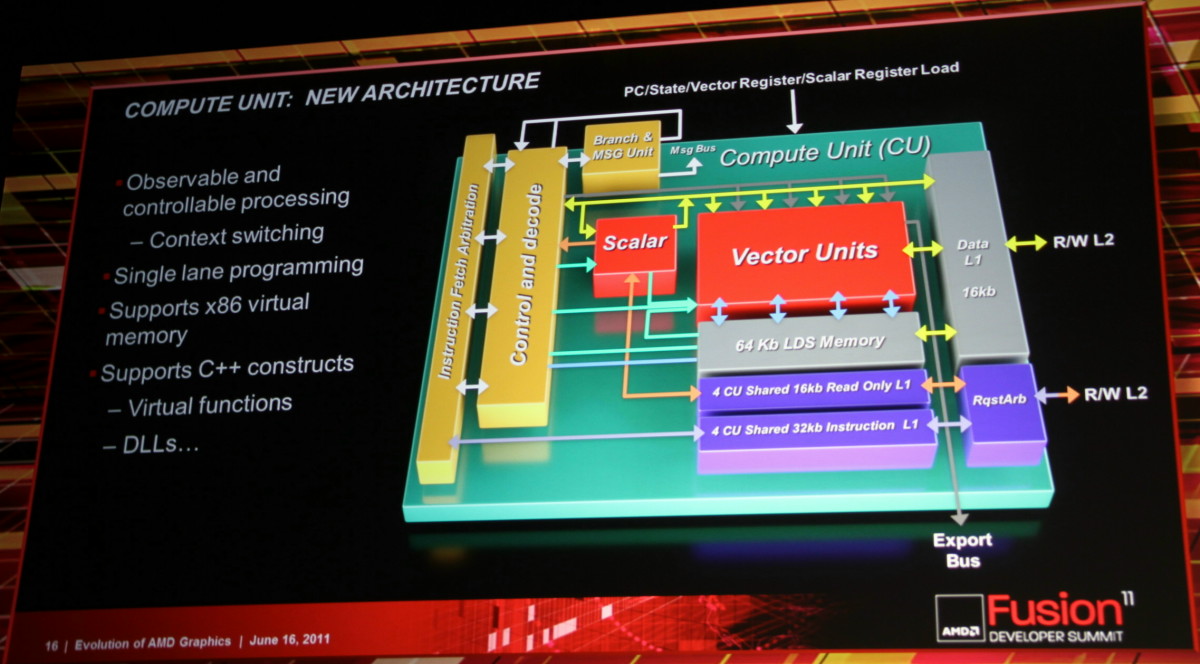
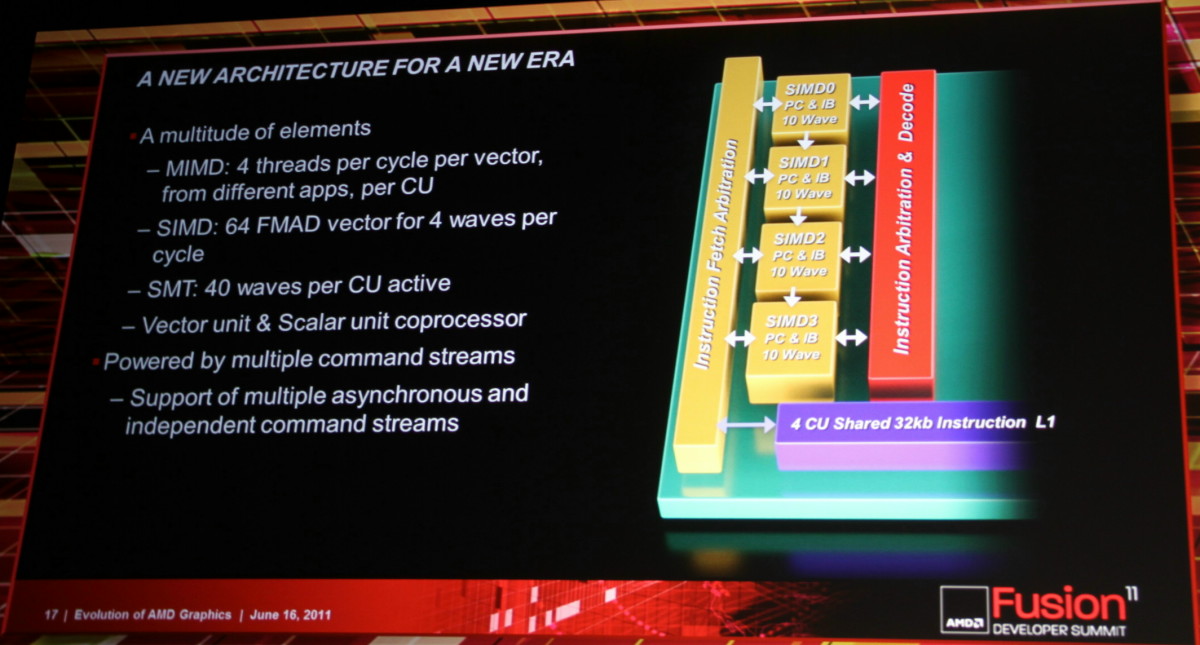

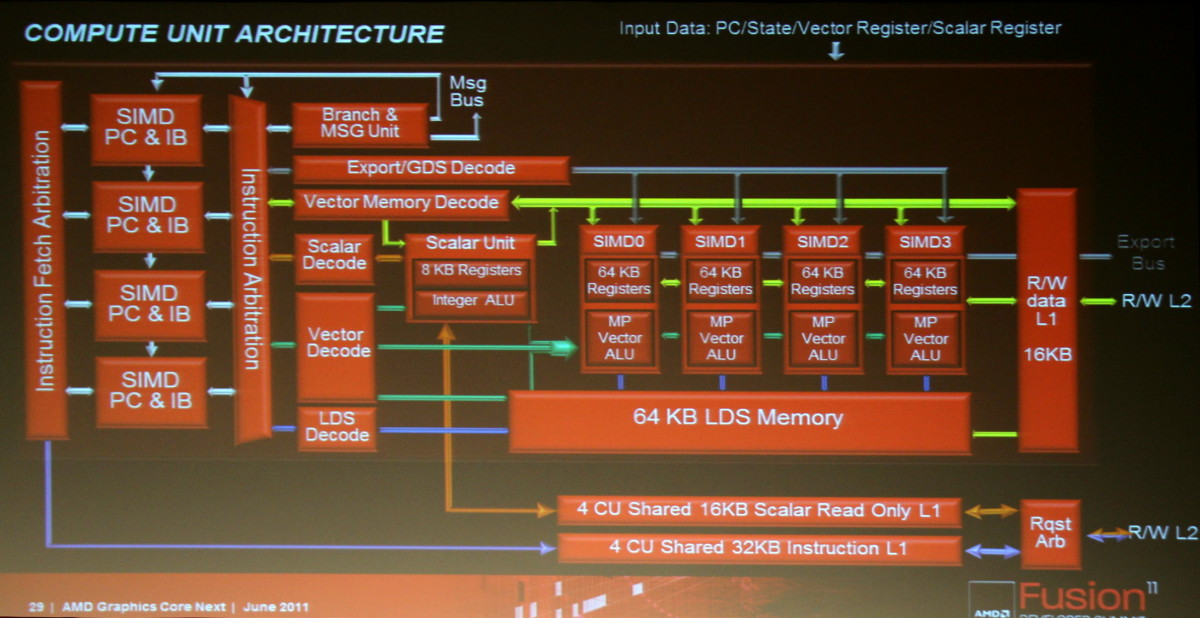
L'architecture proposée par AMD permet de combiner ces deux aspects en plaçant dans chaque Compute Unit non pas une grosse unité MIMD mais 4 plus petites unités SIMD indépendantes. Par ailleurs, AMD leur adjoint une unité scalaire qui sera destinée à éviter de monopoliser la puissance de calcul vectorielle par des opérations simples. Comme pour les blocs fondamentaux des GPUs actuels, chaque CU recevra 4 unités de texturing. Une CU est donc, sur le plan des unités d'exécution, très proche de ce qu'AMD appelle actuellement les SIMDs. C'est au niveau de l'exploitation de ces unités d'exécution que le changement est radical. Le GPU Cayman des Radeon HD 6900 peut d'ailleurs être vu comme une étape intermédiaire vers cette nouvelle architecture. Un côté hybride/prototype qui explique probablement son efficacité discutable.
Un autre aspect important de la nouvelle architecture est le multitâche puisque ces nouveaux GPUs seront capables de gérer différentes commandes simultanément ainsi que la priorité à donner à chacune d'elles. Tout ceci se passera au niveau du GPU et non au niveau du système d'exploitation.
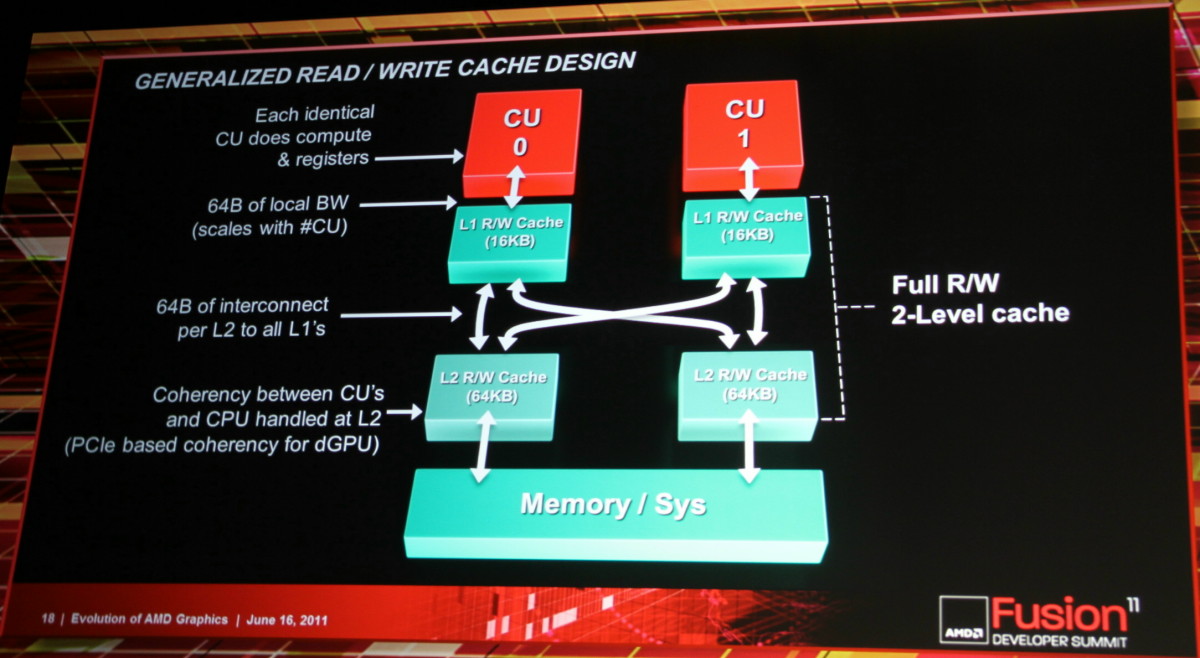
Le cache L2 utilisable en lecture et en écriture est la troisième grosse évolution. Il permet également l'existence d'un espace cohérent entre toutes les CUs ainsi qu'avec le CPU, que ce soit à l'intérieur d'un APU ou avec une carte graphique dédiée.
Ce cache L2 généralisé, le fonctionnement scalaire des unités de calcul, le support de l'espace mémoire virtuel x86 et du C++ vont faire exploser l'intérêt du GPU computing. Notez cependant que sur certains de ces points, AMD ne fait que rattraper le retard pris sur Nvidia.



Une interrogation importante que nous avons par rapport à cette nouvelle architecture est son efficacité énergétique. Comme nous avons pu le voir avec les Radeon HD 6970, elle était quelque peu en baisse. Augmenter le rendement d'une Compute Unit va donc faire progresser sa consommation relative. Si le procédé de fabrication 28nm permettra d'en faire baisser la consommation absolue, la question reste importante.
Nous avons pu nous entretenir avec Eric Demers à ce sujet et selon lui il s'agit d'un faux problème. Dans l'architecture actuelle, quand certaines lignes des unités vec4 ou vec5 ne sont pas utilisées, elles restent alimentées. Leur consommation est moindre que quand elles sont exploitées, mais elles gaspillent malgré tout beaucoup d'énergie. Ce gaspillage va disparaître avec la future architecture. En d'autres termes, nous nous approcherons probablement plus souvent de la consommation maximale des Compute Units, mais leur rendement énergétique serait dans tous les cas supérieur.
Enfin, nous avons demandé au CTO d'AMD s'il envisageait d'inclure à l'avenir dans les GPUs plus de CUs que ne le permet le TDP, tout en sachant qu'ils ne pourraient pas tous être exploités en rendu 3D (limités par PowerTune par exemple), mais en supposant qu'ils pourraient l'être dans le mode compute qui n'exploite pas certaines parties du GPU très gourmandes telles que les unités de texturing. Eric Demers nous a répondu qu'AMD envisageait effectivement cela et qu'une telle possibilité pourrait éventuellement être retenue à l'avenir, si les simulations le justifiaient, notamment pour un GPU qui viserait le HPC.