| |
| |
| AMD Radeon HD 7970 & CrossFireX en test : 28nm et GCN Cartes Graphiques Publié le Samedi 24 Décembre 2011 par Damien Triolet URL: /articles/848-1/amd-radeon-hd-7970-crossfirex-test-28nm-gcn.html Page 1 - Introduction Tout juste avant Noël, AMD a décidé de lever le voile sur la Radeon HD 7970 qui débarquera dans le commerce le 9 janvier, accompagnée de la Radeon HD 7950. Au menu : une nouvelle architecture, le support des technologies les plus récentes et bien entendu la promesse de performances en hausse pour enfin battre la GeForce GTX 580 de Nvidia. C'est ce que nous allons vérifier en passant au crible le comportement de la Radeon HD 7970, seule et en CrossFire X !  Les technologies de 2012AMD a pris l'habitude en ce qui concerne ses GPU de ne jamais tarder à profiter des dernières technologies de fabrications ainsi que des derniers standards dont l'intégration est inévitablement amenée à se généraliser. C'est une fois de plus le cas avec les Radeon HD 7000 tout du moins pour une partie d'entre elles. Les Radeon HD 7900, 7800 et 7700 vont ainsi remplacer les Radeon HD 6900, 6800 et 6700 avec de nouveaux GPU issus de la famille Southern Islands : Tahiti, Pitcairn et Cap Verde. L'entrée de gamme consistera par contre en grande partie, voire totalement, en une série de renommages des modèles actuels. S'il est probablement pertinent pour AMD de focaliser ses ressources sur le développement de GPU milieu et haut de gamme, ainsi que des APU, cela ne justifie pas pour autant un renommage qui revient à tromper certains consommateurs pour en tirer un avantage commercial. Si nous précisons "certains", c'est parce que le renommage pourrait ne concerner que l'OEM, tromper le néophyte qui achète un PC complet étant visiblement établi comme normal Une confusion d'autant plus problématique que les nouveautés apportées par Southern Islands sont légion.  Ces nouveaux GPU, et donc Tahiti qui équipe les Radeon HD 7900, sont fabriqués chez TSMC en 28 nanomètres. Par rapport au procédé de fabrication précédent, le 40nm, il permet de doubler la densité des transistors, de quoi pouvoir ajouter plus d'unités de calcul et de nouvelles fonctions à taille égale. Attention cependant, la consommation ne se réduit malheureusement pas dans les mêmes proportions que la surface occupée. Plus que jamais elle devient ainsi le paramètre principal à considérer lors du design de la puce. Tahiti introduit également le support de Direct3D 11.1, qui se généralisera en 2012. Prévue pour Windows 8, mais avec un probable support sur Windows 7, cette nouvelle API est une évolution mineure, qui est avant tout destinée à intégrer quelques demandes des développeurs et à faciliter son utilisation sur une large gamme de GPU, ce qui est nécessaire avec l'ouverture de Windows au monde ARM. La compatibilité avec le matériel DirectX 11, 10.1, 10 et 9 reste assurée. Sur le plan graphique le support complet de Direct3D 11.1 facilite l'intégration avec l'API vidéo DXVA, il permet d'utiliser les ressources flexibles des compute shaders (UAV) avec tous les types de shaders (seuls les pixels shaders peuvent les partager dans Direct3D 11), de contrôler la rastérisation, d'appliquer des opérations logiques sur les buffers de rendu, de déboguer les shaders, et de supporter une version standard de la 3D stéréo. OpenCL 1.2 n'a pas été oublié avec un support complet, ce qui inclut l'intégration avec DirectX 11 et les flux vidéo et un support du multitâche au niveau du GPU. Le standard PCI Express 3.0 est également supporté et permet de doubler la bande passante pratique entre le GPU et le CPU, à condition de disposer d'une plateforme X79, la seule à le supporter à l'heure actuelle. Enfin, Tahiti ouvre la voie à une nouvelle architecture : GCN ou Graphics Core Next. Page 2 - Tahiti : 2048 unités de calcul et bus 384 bits Tahiti : 2048 unités de calcul, 32 ROP et bus mémoire 384 bitsComme tous les GPU actuels, Tahiti et ses petits frères organisent leurs unités d'exécution en blocs fondamentaux qui englobent des unités de calcul, du cache, des unités de texturing, de la logique de gestion etc. Précédemment, AMD nommait ces blocs SIMD, ce qui était peu clair puisqu'il s'agit également du nom des unités de calcul vectorielles. Avec GCN AMD parle dorénavant de Compute Unit (CU). Par soucis de clarté, nous utiliserons également ce terme pour parler des blocs fondamentaux des GPU Radeon actuels et nous réserverons le terme SIMD à sa définition première : une unité de calcul vectorielle. Du côté des GeForce, ces blocs se nomment pour rappel Shader Multiprocessors (SM). 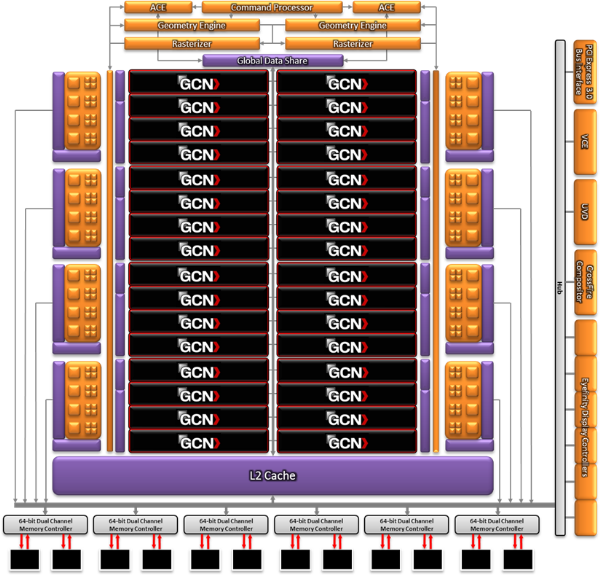 Première évolution pour Tahiti (HD 7900) par rapport à Cayman (HD 6900), le nombre de CU passe de 24 à 32 tout en conservant le même débit de calcul et de texturing. Un gain de 33% qui porte le nombre d'unités de calcul de 1536 (384 vec4) à 2048 et de texturing de 96 à 128, ce qui profitera directement aux performances. Des CU qui optent également pour un fonctionnement de type scalaire, plus efficace (voir page suivante), comme c'est le cas chez Nvidia depuis les GeForce 8. Les unités de texturing n'évoluent pas et traitent toujours le filtrage des textures HDR 64 bits (FP16) à demi vitesse et HDR 128 bits (FP32) à une vitesse réduite à un quart. La qualité du filtrage évolue par contre légèrement pour réduire quelque peu le fourmillement, une petite différence que nous avons pu constater. AMD a également ajouté un support matériel des Partially Resident Textures (PRT), qui correspond grossièrement au MegaTexturing utilisé par l'id Tech5 de John Carmack. Actuellement exposée via une extension OpenGL propriétaire, cette accélération des PRT permettra d'accélérer les moteurs qui y feront appel mais aura du mal à trouver son public si AMD ne parvient pas à l'exposer via Direct3D.  Pour alimenter ces nouveaux CU, AMD fait évoluer le bus mémoire de 256 à 384 bits, ce qui représente un gain de bande passante de 50% à mémoire identique. Le nombre de ROP est cependant découplé de la taille du bus mémoire, une possibilité que nous avions déjà pu apercevoir avec la Radeon HD 6790. AMD a ainsi opté pour ne pas augmenter leur nombre, qui reste figé à 32. Conséquence : le fillrate n'évolue pas. Il était déjà plutôt élevé auparavant, ce n'est donc pas un gros problème, d'autant plus que pour écrire plus de 32 pixels en mémoire, il faut encore pouvoir en générer plus ! C'est d'ailleurs le problème des GeForce GTX 400 et 500. La GeForce GTX 580 est par exemple capable d'enregistrer 48 pixels en mémoire par cycle mais ne peut en générer que 32, ce qui n'est utile que pour accélérer l'antialiasing de type multisample. 32 ROP peuvent-ils profiter d'un bus mémoire de 384 bits ? Pas toujours, mais ils ne sont pas les seuls à consommer de la bande passante mémoire, les textures en ont également besoin. Dans certains cas par contre, 32 ROP sont limités par un bus de 256 bits, c'est le cas lors du mélange des couleurs et en HDR 64 et 128 bits. Ces modes profiteront ainsi pleinement du bus étendu. Tout comme Cayman, Tahiti est capable de traiter 2 triangles par cycle, avec ou sans tessellation, contre 4 pour le GF100/110 de Nvidia. Cette non évolution est cependant compensée par quelques petites optimisations pour augmenter les performances lorsqu'un niveau élevé de tessellation est utilisé : de plus gros caches, moins de pénalités lorsqu'il faut utiliser la mémoire vidéo comme tampon et un recours à la réutilisation des vertices déjà traités (triangles voisins) aussi souvent que possible. Des gains qui peuvent monter à 4x par rapport à Cayman selon AMD. Implémenter ces unités supplémentaires ainsi que toutes les évolutions de l'architecture fait exploser le nombre de transistors qui passe de 2.64 pour Cayman à 4.31 milliards pour Tahiti. Grâce au 28 nanomètres, ce dernier est cependant légèrement plus petit avec 352 mm² contre 389 mm² pour Cayman. Notez qu'AMD se refuse pour l'instant à préciser quelle variante du procédé de fabrication en 28 nm est utilisée. Page 3 - GCN : l'abandon du VLIW GCN : l'abandon du VLIWDepuis les Radeon 9700 Pro, AMD utilise une architecture VLIW, qui a évolué progressivement pour atteindre un niveau de flexibilité très élevé sur les dernières générations. VLIW, ou Very Long Instruction Word, consiste à exécuter des instructions complexes, qui sont en réalité l'assemblage d'une série d'instructions plus simples. C'est ce que nous décrivions comme comportement vectoriel pour les Radeon (vec4 ou vec5), en opposition au comportement scalaire des GeForce : pour chaque pixel, par exemple, 5 instructions pouvaient être exécutées de front. Un modèle issu de l'évolution naturelle des GPU dont la tâche de base consiste à calculer des couleurs (4 composantes : rouge, vert, bleu et transparence) et des coordonnées (3 ou 4 composantes). Exécuter 5 instructions de front permettait de profiter du parallélisme naturel entre ces composantes en laissant un peu de place pour les quelques opérations scalaires à traiter. Cypress, le GPU d'une Radeon HD 5800, embarque des CU qui contiennent chacun une grosse unité de calcul SIMD capable d'exécuter chaque cycle 5 instructions de front sur 16 éléments (pixels, vertices, threads ). Avec Cayman, le GPU des Radeon HD 6900, AMD a simplifié quelque peu ce modèle pour revenir à une unité SIMD plus efficace qui exécute 4 instructions de front, toujours sur 16 éléments. Pour Tahiti et les autres GPU GCN, cette grosse unité est éclatée et devient 4 petites unités SIMD chacune capables d'exécuter une instruction sur 16 éléments. 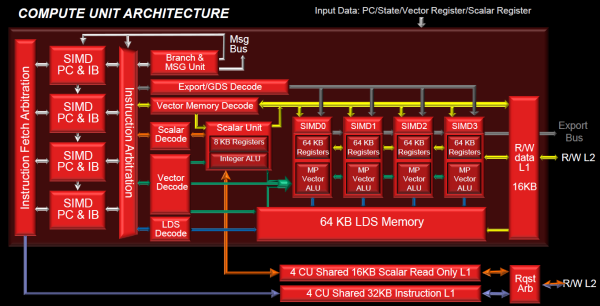 En réalité la grosse unité SIMD de Cayman et les 4 petites unités SIMD de Tahiti sont probablement identiques, seule la manière de les alimenter étant réellement différente. Du côté des Radeon, tous les éléments à traiter sont organisés en groupes de 64, appelés wavefront. Des groupes qui sont plus gros que la longueur des unités SIMD (16) pour simplifier le travail des schedulers et s'accomoder plus facilement de la latence des unités de calcul. Dans le cas de Cayman, un de ces groupes sera donc traité en 4 cycles avec jusqu'à 4 instructions en parallèle. Pour Tahiti, c'est une seule instruction mais sur 4 wavefronts qui sera traitée tous les 4 cycles. Tahiti doit donc pouvoir jongler avec beaucoup plus d'éléments en même temps : au moins 256. Un chiffre à comparer à 128 et non 64 pour Cayman : avec une latence de 8 cycles pour les unités de calcul, chaque CU de Cayman doit jongler en permanence avec 2 wavefronts. Avec Tahiti et GCN AMD a ramené la latence des unités de calcul à 4 cycles pour éviter de faire exploser le nombre d'éléments en vol requis pour utiliser toutes les unités de calcul. Ils sont au final doublés, ce qui reste raisonnable.  Notez enfin une petite subtilité : si Cayman peut exécuter directement une instruction sur toutes ses unités de calcul, ce n'est pas le cas pour Tahiti. Le scheduler présent dans chaque CU peut ordonner l'exécution d'une instruction à une seule SIMD par cycle. Au démarrage, la seconde SIMD perd ainsi 1 cycle, la troisième 2 cycles et la quatrième 3 cycles, ce qui représente une perte de 192 flops. Un chiffre qui est cependant négligeable lorsque les programmes à exécuter sont longs et qui est compensé par la latence plus faible. En pratique, quelle différence ? Voici quelques exemples, comparant l'architecture VLIW 4 des Radeon HD 6900 (8 cycles de latence, vec4) à l'architecture GCN des Radeon HD 7900 (4 cycles de latence + 3 cycles de "démarrage", scalaire), en supposant que chaque CU est alimenté avec 2 / 4 / 8 groupes de 64 éléments à traiter : 1 instruction scalaire à exécuter : CU VLIW 4 : 16 / 24 / 40 cycles CU GCN : 11 / 11 / 15 cycles 100 instructions scalaires à exécuter : CU VLIW 4 : 408 / 808 / 1608 cycles CU GCN : 207 / 207 / 407 cycles 1 instruction vec3 à exécuter : CU VLIW 4 : 16 / 24 / 40 cycles CU GCN : 19 / 19 / 31 cycles 100 instructions vec3 à exécuter : CU VLIW 4 : 408 / 808 / 1608 cycles CU GCN : 607 / 607 / 1207 cycles 1 instruction vec4 à exécuter : CU VLIW 4 : 16 / 24 / 40 cycles CU GCN : 23 / 23 / 39 cycles 100 instructions vec4 à exécuter : CU VLIW 4 : 408 / 808 / 1608 cycles CU GCN : 807 / 807 / 1607 cycles Lorsque les CU de l'architecture GCN sont alimentés avec au moins 256 éléments ils sont ainsi toujours plus performants que les CU VLIW 4, avec une différence insignifiante lorsque 4 instructions peuvent être traitées en parallèle mais qui peut monter à près de 4x avec des instructions scalaires exécutées en série ! Lors du rendu 3D nous nous situons en moyenne quelque part entre les résultats en vec3 et vec4. Il faut dire que le compilateur d'AMD est particulièrement performant pour extraire ce parallélisme compte tenu de l'expérience acquise depuis toutes ces années. Sous-alimentée en éléments à traiter, les CU GCN peuvent par contre être moins performantes.  L'intérêt de cette nouvelle organisation se retrouvera principalement du côté compute où le code peut se prêter moins bien à la vectorisation que le rendu 3D. Ce dernier en profitera cependant progressivement, son évolution faisant qu'il se détache de plus en plus du traitement des couleurs et de positions qui se vectorisent facilement. GCN permettra également à AMD de passer moins de temps à travailler son compilateur et d'affecter ces ressources à d'autres optimisations. AMD a également ajouté dans chaque CU une unité de calcul scalaire qui pourra être exploitée pour traiter des opérations qui ne doivent pas obligatoirement être exécutées pour chaque élément d'un groupe via les SIMD, ce qui peut par exemple servir à optimiser certains branchements. Cette unité ne sera pas exposée directement dans les langages graphiques, mais pourra être exploitée par le compilateur. Une unité dédiée à traiter les branchements en eux-mêmes reste présente, étendue pour gérer les messages liés au débogage. Page 4 - GCN : des caches et 2 ACE pour le GPU computing GCN : des caches et 2 ACE pour le GPU computingSi le graphique est resté au cur du développement de GCN, le GPU computing a également pris beaucoup d'importance. Pour éviter qu'il ne reste cantonné qu'à quelques utilisations très spécifiques, il convient pour AMD et Nvidia de continuer à faciliter l'exploitation de leurs GPU. Avec Fermi, Nvidia a apporté de nombreuses évolutions dans ce sens et avec GCN c'est au tour d'AMD de faire de même. Tahiti inaugure ainsi une nouvelle structure de caches en lecture/écriture. Le texture cache des précédentes générations évolue vers un cache L1 de 16 Ko qui peut être utilisé aussi bien par les unités de texturing que par les SIMD. Chaque unité scalaire dispose par ailleurs de son propre cache L1 de 4 Ko. Ce dernier est cependant implémenté en tant que cache de 16 Ko partagé entre 4 Compute Unit. Un compromis qui a été fait pour réduire le coût de son implémentation. Tahiti dispose donc au total de 40 caches L1 de 16 Ko. Ils sont connectés avec un accès de 64 octets par cycle au cache L2 partitionné en morceaux de 128 Ko intégrés dans chacun de 6 contrôleurs mémoire. Ce cache L2 devient cohérent et traite les opérations atomiques beaucoup plus efficacement qu'auparavant. 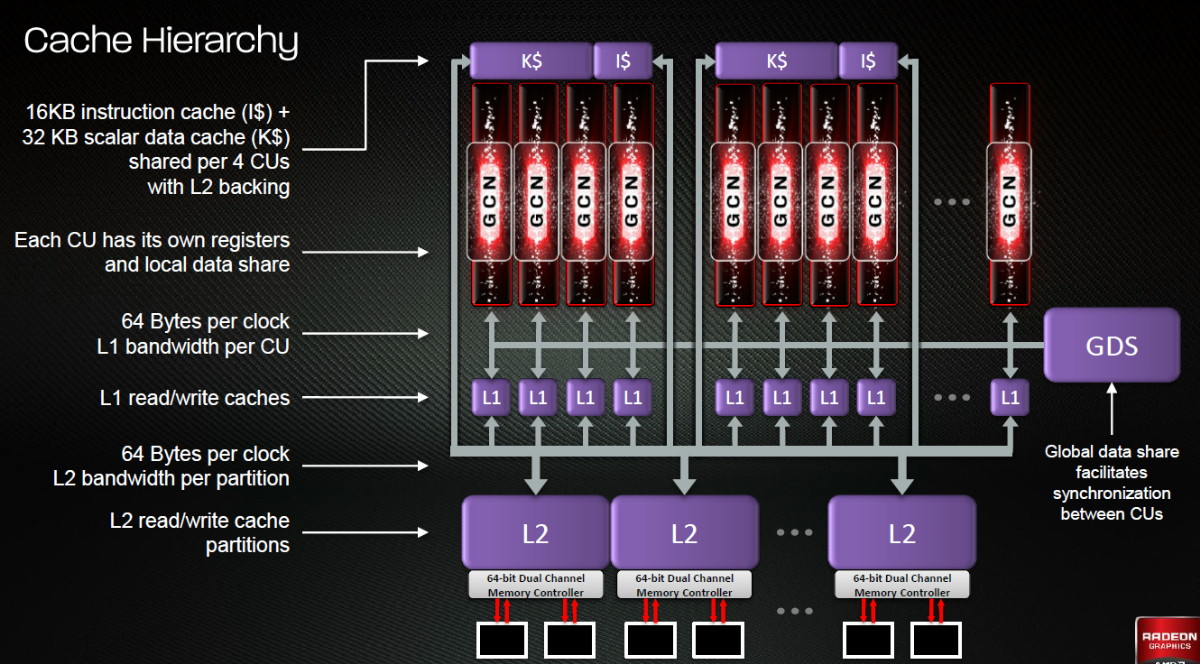 La mémoire partagée de chaque CU, Local Data Share, évolue elle aussi pour passer de 32 à 64 Ko. Pour rappel elle est destinée à partager des informations à l'intérieur d'un bloc d'éléments à traiter et les spécifications de Direct3D 11 exigent 32 Ko au minimum. Cette mémoire dispose d'un accès en lecture direct au L1 de sa Compute Unit, ce qui permet de la charger avec des données sans passer par les SIMD. Performances et consommation en tirent bénéfice. Les registres généraux dédiés aux SIMDs de chaque CU n'évoluent par contre pas en nombre : 256 registres vectoriels de 2048 bits (64x 32 bits). L'unité scalaire dispose en plus de 256 registres de 32 bits dédiés. Toujours sur le plan du sous-système mémoire, AMD a également implémenté une protection ECC, pour la SRAM (L1, L2 et registres) ainsi que pour la mémoire vidéo. L'implémentation est probablement similaire à celle de Nvidia, c'est-à-dire qu'elle consiste à réserver une partie de la mémoire pour stocker les données ECC qui vont donc également réduire la bande passante mémoire disponible en pratique.  Après le cache généralisé en lecture/écriture, AMD s'est attaqué à un autre problème qui touche le GPU Computing : le multitâche et l'overhead. Pour cela, Tahiti intègre 3 processeurs de commandes. Le principal, non représenté sur ce schéma, est capable de traiter toutes les tâches, graphique et compute. A côté de celui-ci prennent place 2 ACE pour Asynchronous Compute Engines qui sont limités aux tâches compute. Avec un système évolué de contrôle des ressources, des priorités et de la synchronisation, ils sont capables de gérer simultanément plusieurs contextes. De quoi permettre par exemple d'utiliser efficacement le GPU computing et la 3D en même temps. A l'avenir il est également possible qu'AMD dévie le traitement des Compute Shaders de DirectX 11 du processeur de commande principal vers les ACE, mais ce n'est pas encore le cas actuellement. Une optimisation possible pour 3DMark 11 ? Pour alimenter tous ces processeurs de commande, et comme l'a déjà fait Nvidia, AMD a ajouté un second moteur DMA pour gérer la communication de et vers le CPU. Page 5 - Video Codec Engine et HDMI 1.4a 3 GHz Video Codec Engine et HDMI 1.4a 3 GHzLa famille Southern Islands introduit deux nouveautés au niveau de la connectique. La première est le support du HDMI 1.4a 3 GHz qui autorise, enfin, le transport de flux vidéo 3D en 1080p à 60 Hz, alors qu'il est actuellement limité à 30 Hz, voire à 24 Hz par il. Pour pouvoir en profiter, il faudra cependant disposer d'un écran qui en est capable, ce qui à notre connaissance n'est pas encore le cas. Cette norme HDMI optionnelle permet également de piloter un écran 4k, comme le permet le DisplayPort 1.2. La seconde nouveauté réside dans la gestion d'un flux audio indépendant pour chaque sortie vidéo, ce qui permet d'alimenter en son plusieurs écrans ou que le son suive l'image lorsqu'elle passe d'un écran à un autre. Pour améliorer l'efficacité de l'encodage vidéo sur ses GPU, AMD a intégré un Video Codec Engine qui permet un encodage d'un flux HD 1080p à plus de 60 images par seconde. Une unité fixe qui augmente l'efficacité énergétique du GPU. 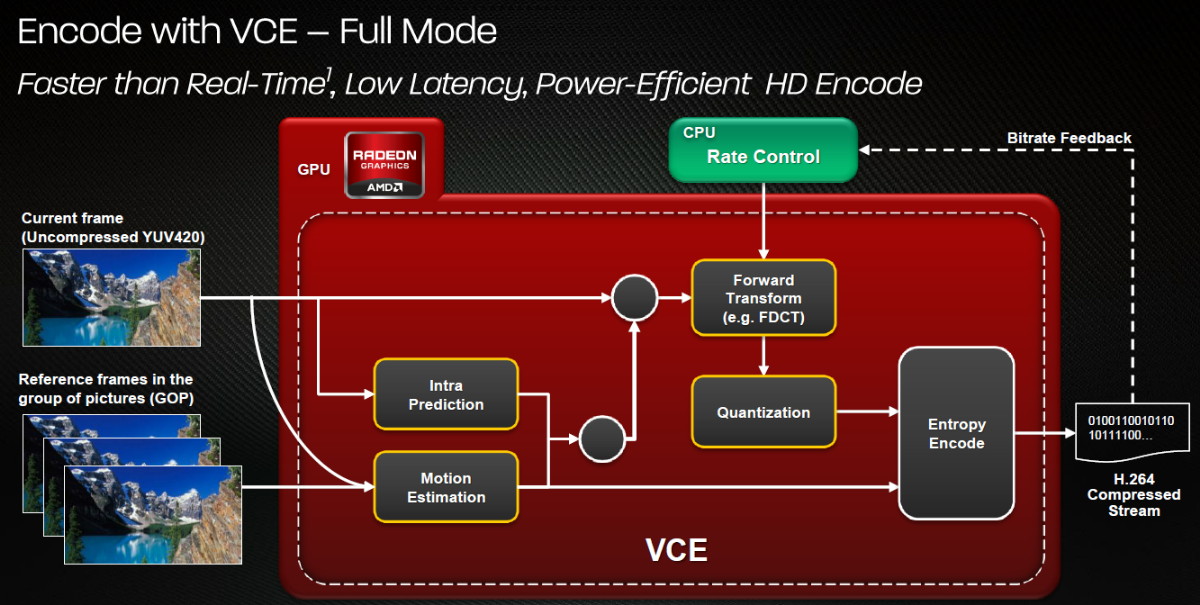 Elle peut être utilisée d'une manière complète ou partielle. Dans ce second cas le VCE se contente du codage entropique et les autres étapes, plus simples à paralléliser, sont exécutées par les unités de calcul du GPU. Sur un modèle haut de gamme cela permet d'augmenter significativement les performances, mais ce ne sera pas spécialement le cas sur un plus petit GPU. AMD ne proposera cependant pas directement d'encodeur capable de tirer parti du VCE, il faudra donc attendre de voir ce que feront les développeurs de ce type d'outils et s'ils permettront de relever quelque peu le niveau en terme de qualité. Enfin, une dernière petite nouveauté, l'ajout dans les unités de calcul du support de l'instruction QSAD, une variante de SAD, somme de différences absolues, qui y combine des opérations d'alignement. Elle est très utile à différents traitement d'images (détection de mouvement, conversion 2D/3D) pour lesquels elle permet de gagner en performances et de réduire la consommation. Elle sera exploitée par la version 2.0 de Steady Video, l'algorithme de stabilisation d'image d'AMD.  Page 6 - PowerTune et ZeroCore Power PowerTune et ZeroCore PowerTahiti reprend bien entendu le support de la technologie PowerTune introduite avec Cayman. Pour rappel, celle-ci correspond en quelque sorte au Turbo d'un CPU : profiter au maximum de l'enveloppe thermique disponible. Petite différence tout de même, le GPU part du principe qu'à moins que ses capteurs ne lui indiquent le contraire il peut toujours fonctionner à sa fréquence maximale. C'est donc sur cette fréquence uniquement que communique AMD, même si elle n'est pas garantie. Sans une technologie telle que PowerTune, pour garantir la fiabilité des cartes graphiques, elles devraient voir leurs fréquences réduites significativement, jusqu'à 30% selon AMD. Sans technologie similaire, Nvidia est actuellement dans l'obligation de bricoler une alternative logicielle approximative pour ses GeForce GTX 500 et qui consiste à surveiller la consommation en entrée. 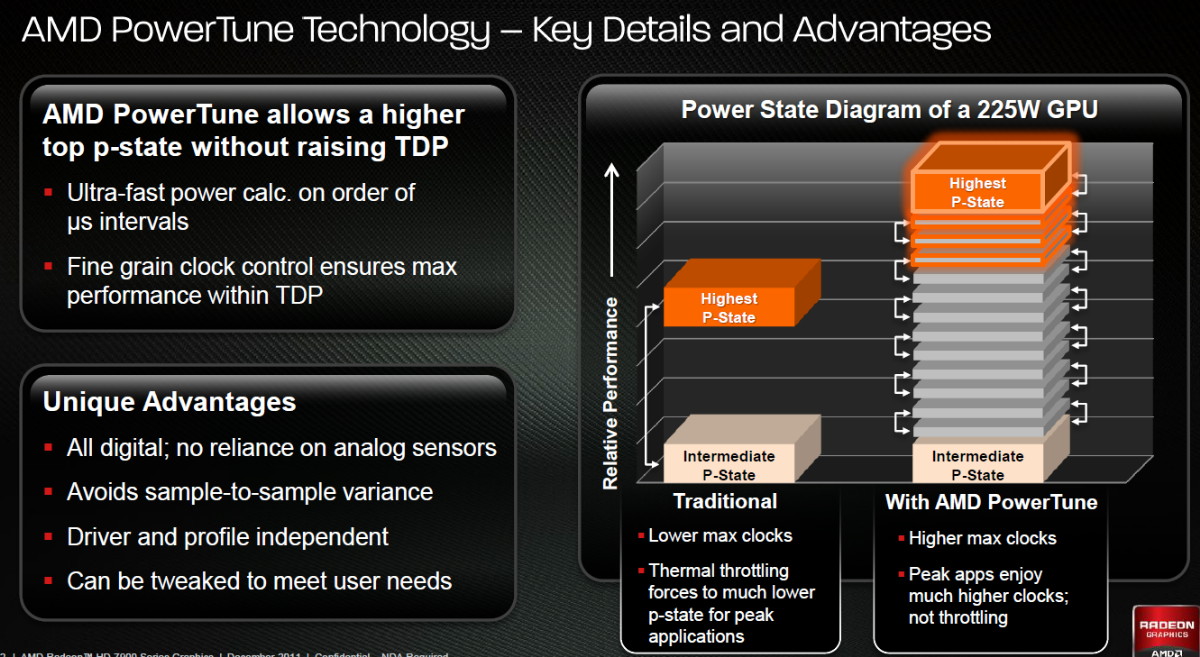 PowerTune se base sur une multitude de capteurs de charge présents dans les différents blocs du GPU qui met en relation ces relevés avec une table de correspondance de niveau de consommation. Ainsi, PowerTune ne consiste pas à mesurer celle-ci mais à estimer aussi précisément que possible si, dans le pire des cas, le GPU va dépasser la limite autorisée. AMD fixe ce qu'est ce pire des cas : un échantillon qui souffre de courants de fuite élevé et qui tourne à température élevée. Un GPU dont la consommation maximale est fixée à 250W ne va pas spécialement être limité lorsqu'il atteint 250W, il le sera plus tôt, lorsque le plus mauvais des échantillons produit aurait atteint 250W dans les mêmes conditions. Cela permet d'assurer un comportement identique pour toutes les cartes graphiques. La Radeon HD 7970, tout comme la Radeon HD 6970, est limitée à 250W. Ses capteurs sont cependant plus nombreux ce qui permet au GPU d'estimer plus précisément sa consommation et d'éviter de réduire sa fréquence lorsque ce n'est pas réellement nécessaire. Le panneau de contrôle Overdrive permet toujours de modifier cette limite de -20% à +20%. Avec Tahiti et la Radeon HD 7970, AMD introduit une nouvelle technologie : ZeroCore Power. Celle-ci fait rentrer le GPU dans une veille profonde dès qu'il ne doit plus gérer d'affichage, typiquement quand l'écran passe en veille. A ce moment la carte graphique consomme moins de 3W selon AMD, ce que nous avons pu confirmer puisque nous avons mesuré 1.8W seulement. Le ventilateur est alors éteint. 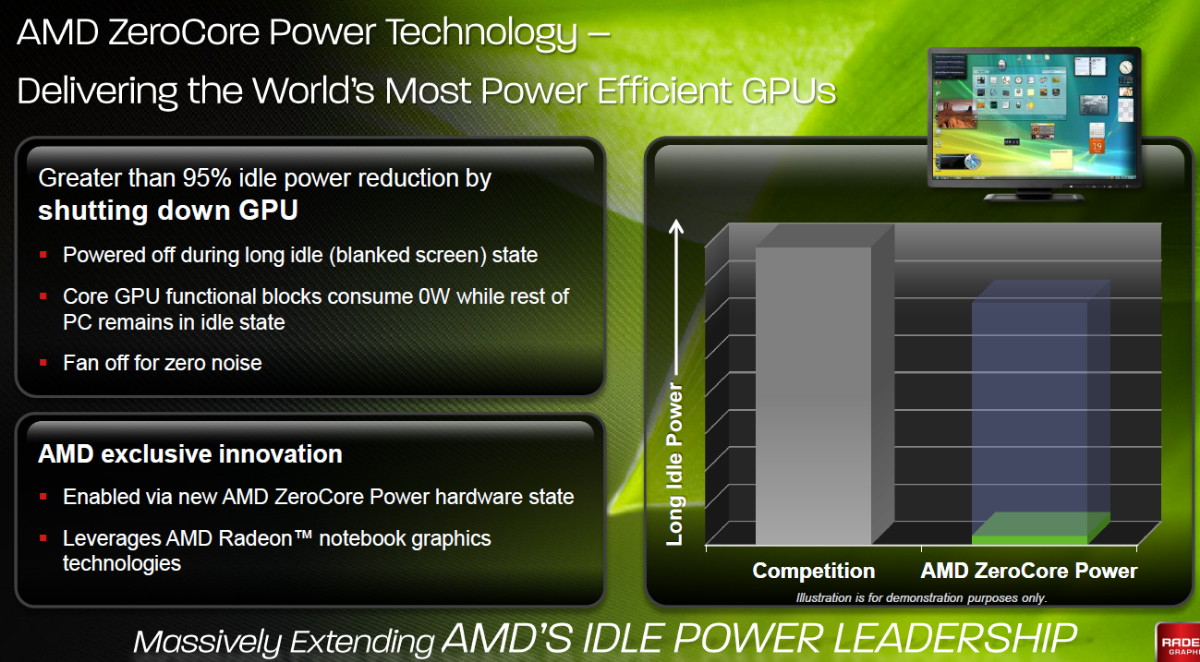 ZeroCore Power est utile lorsqu'un système n'est pas constamment utilisé mais doit rester allumé. C'est par exemple le cas d'un HTPC dédié autant au jeu qu'au stockage de fichiers et pour lequel cette technologie permettra de réduire significativement la consommation. Un autre exemple pourrait venir d'un supercalculateur équipé de GPU. Lorsque ceux-ci ne sont pas exploités, ils peuvent passer en veille profonde. Enfin, ZeroCore Power sera utile aux systèmes multi-GPU puisqu'il va beaucoup plus loin que le mode Ultra Low Power State des GPU précédents, qui ne réduit leur consommation que de quelques watts lorsqu'ils ne sont pas sollicités. Page 7 - Spécifications, Radeon HD 7970 de référence, overclocking Spécifications 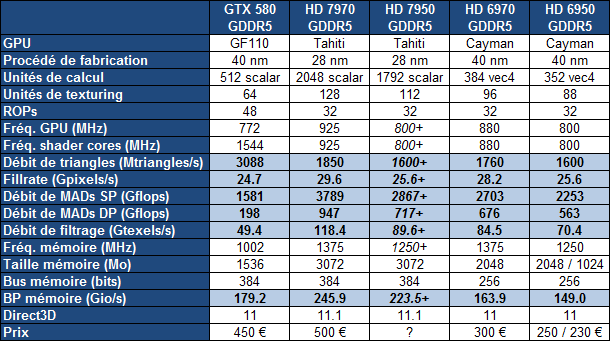 Les puissances de calcul et de texturing de la Radeon HD 7970 augmentent de 40% par rapport à la Radeon HD 6970, alors que la bande passante mémoire progresse de 50%. En ce qui concerne la Radeon HD 7950, AMD n'a pas encore fixé ses fréquences et se contente d'indiquer que la mémoire sera cadencée à au moins 1250 MHz, ce qui correspond à de la GDDR5 5 Gbps. La Radeon HD 7970 de référencePour ce test, AMD nous a fourni une Radeon HD 7970 de référence :      La Radeon HD 7970 reprend le format de la Radeon HD 6970 : double slot et 27.5cm de long. Son système de refroidissement est similaire mais évolue légèrement. La turbine dispose de pales plus longues pour augmenter le débit d'air et le bloc chambre à vapeur / radiateur est allongé de 1.5cm vers la connectique. Son extrémité est alors très proche de la grille d'extraction de l'air chaud qui est également adaptée pour couvrir toute la hauteur d'un slot PCI. Il n'y a ainsi plus besoin de rejeter une partie de cet air chaud dans le boîtier par le dessus de la carte. Un des deux ports DVI doit alors disparaître, le second restant accompagné d'une sortie HDMI et de 2 sorties mini-DisplayPort. Un adaptateur HDMI vers DVI sera fourni avec les cartes. Le GPU est entouré d'une structure métallique destinée à la protéger et à garantir la rigidité du packaging. Malheureusement cette structure est légèrement plus épaisse que le die ce qui signifie que les systèmes de refroidissement alternatifs devront être adaptés pour être compatibles. Soyez donc très prudents si vous décidez de remplacer celui d'origine ! Probablement pour réduire les coûts, AMD a laissé tomber la plaque qui recouvrait l'arrière des Radeon HD 6970 et 6950 2 Go. Le design du carter qui recouvre le système de refroidissement a par contre été redessiné et est nettement plus esthétique que celui des Radeon HD 6900, au look plutôt austère et à la sensation cheap. Nous ne sommes en général pas fans des designs brillants, mais dans le cas présent, la réalisation est soignée et les matériaux de qualité, ce qui rend l'ensemble très réussi. Le PCB est globalement assez proche de celui de la Radeon HD 6970 mais l'étage d'alimentation a été revu pour monter en puissance, toujours avec 6 phases pour le GPU, mais avec des composants de meilleure qualité. Cette montée en puissance n'est en réalité pas nécessaire et l'une des 6 phases reste vacante. Le design permettra par contre au fabricant qui le désire de produire un modèle overclocké qui dispose de plus de réserve. Il sera également possible de passer de connecteurs d'alimentation 8+6 broches à 2x 8 broches. Deux connecteurs CrossFire X sont toujours disponibles pour assurer un support du tri et du quad-GPU, tout comme le switch qui permet de revenir sur un bios d'origine protégé en écriture. OverclockingLe GPU de notre exemplaire s'est montré plutôt coopératif face à l'overclocking et nous avons pu passer de 925 à 1075 MHz. Un gain de 16% plutôt inhabituel sur les GPU haut de gamme. Nous avons bien entendu vérifié que PowerTune ne réduisait pas les fréquences par derrière en mesurant les performances dans plusieurs jeux (dans Furmark où c'est le cas nous pouvions monter à "1125 MHz"). A la fréquence de 1075 MHz, nous avons observé un gain de 10% dans Battlefield 3 et de 14% dans Anno 2070. Page 8 - PowerTune : influence sur les performances PowerTune : influence sur les performancesLa technologie PowerTune limite-t-elle les performances de la Radeon HD 7970 dans les jeux ? Pour répondre à cette question, nous avons augmenté sa limite de 20% pour passer de 250W à 300W. Nous avons également voulu savoir si la Radeon HD7970 était en pratique très proche ou pas de sa limite. Pour cela nous avons vérifié les performances en réduisant celle-ci de 10% (225W) et puis de 20% (200W). 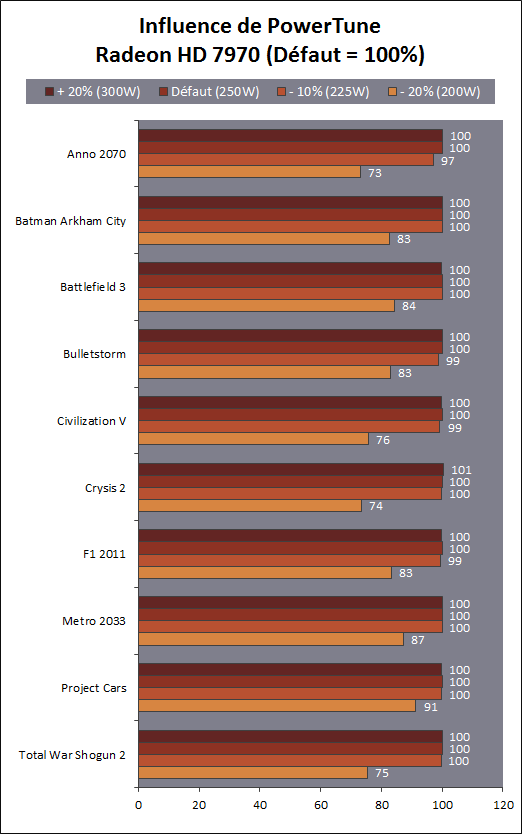 Maintenez la souris sur le graphe pour afficher les résultats en fps. Comme vous pouvez l'observer, augmenter la limite de 20% ne change rien aux performances. Nous n'avons observé un petit gain que dans Crysis 2, mais très faible : 0.5%. En la réduisant de 10%, la différence est également négligeable, avec une seule perte quelque peu significative de 2.5% dans Anno 2070 qui est très gourmand avec les options poussées au maximum. La baisse devient par contre plus importante à -20%, PowerTune devant s'enclencher bien plus souvent, avec un impact sur les performances qui est alors plus élevé que la réduction de l'enveloppe thermique. Par défaut, la limite de 250W imposée par PowerTune semble bien adaptée aux fréquences de référence. Elle pourra par contre bien entendu brider les performances lors d'un gros overclocking, qu'il est conseillé d'accompagner d'une augmentation de l'enveloppe thermique. Page 9 - Consommation et performances/watt ConsommationNous avons bien entendu utilisé le protocole de test qui nous permet de mesurer la consommation de la carte graphique seule. Nous avons effectué ces mesures au repos sur le bureau Windows 7 ainsi qu'en veille écran de manière à observer l'intérêt de ZeroCore Power : 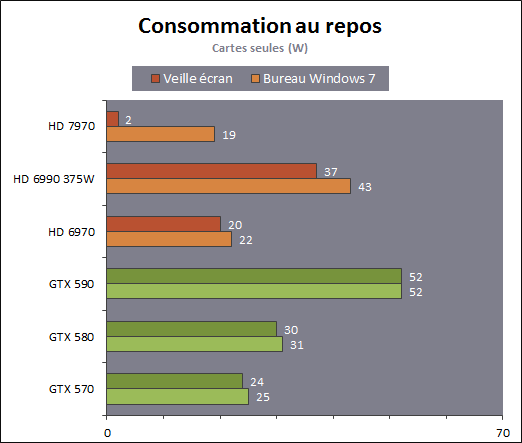 Au repos, sur le bureau Windows 7, la Radeon HD 7970 réduit quelque peu la consommation par rapport à la Radeon HD 6970. La différence est par contre énorme lorsque l'écran passe en veille. Nous mesurons ensuite la consommation au bout de quelques minutes de charge sous 3D Mark 06 et sous Furmark. Notez que nous utilisons une version de Furmark non-détectée par le mécanisme de limitation de la consommation dans les stress tests mis en place par Nvidia dans les pilotes pour les GeForce GTX 500. Nous avons également ajouté des mesures dans Anno 2070 qui est le jeu qui semble rapprocher le plus la Radeon HD 7970 de la limite fixée par PowerTune : 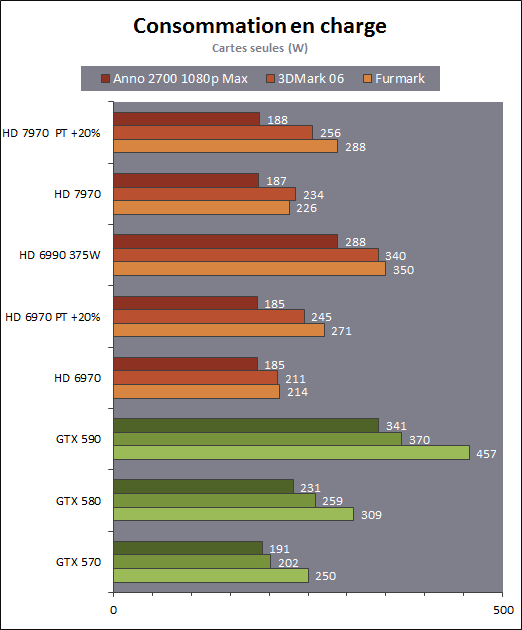 Sous 3DMark et Furmark, la Radeon HD 7970 consomme 10 à 20W de plus que la Radeon HD 6970, ce qui est probablement dû à l'estimation plus fine qui est faite par PowerTune, qui s'enclenche pour les deux cartes et autant dans 3DMark06 que dans Furmark. Dans Anno 2070 par contre la consommation est similaire entre ces 2 Radeon, de quoi augmenter très nettement le rapport performance par watt de la première, ce que nous avons mis en graphique en retenant des fps par 100W pour qu'il soit plus lisible : 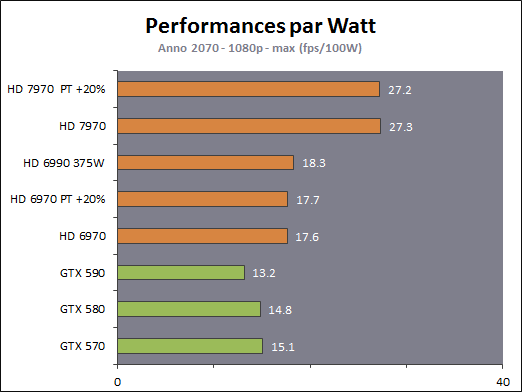 La Radeon HD 7970 affiche ici un bond en avant très important sur le plan de l'efficacité énergétique, qui est 55% supérieure à celle de la Radeon HD 6970 et presque deux fois plus élevée que celle des GeForce GTX 500 ! Notons cependant que chaque jeu représente un cas particulier et que les Radeon sont un petit peu mieux positionnées que la moyenne dans ce jeu. Page 10 - Nuisances sonores et température GPU Nuisances sonoresNous plaçons les cartes dans un boîtier Cooler Master RC-690 II Advanced et mesurons le bruit d'une part au repos et d'autre part en charge. Un SSD est utilisé et tous les ventilateurs du boîtier ainsi que celui du CPU sont coupés pour la mesure. Le sonomètre est placé à 60cm du boîtier fermé et le niveau de bruit ambiant se situe +/- à 21 dBA. 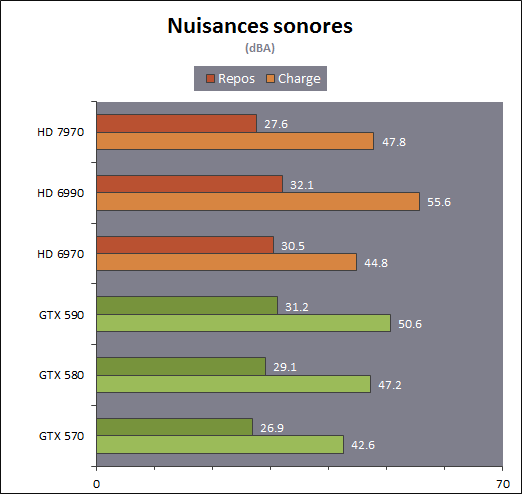 Par rapport à la Radeon HD 6970, la Radeon HD 7970 réduit les nuisances sonores au repos, mais elles augmentent en charge pour dépasser légèrement celles d'une GeForce GTX 580. Comme nous allons le voir, cela provient probablement de la calibration du système de refroidissement. TempératuresToujours placées dans le même boîtier, nous avons relevé la température du GPU rapportée par la sonde interne : 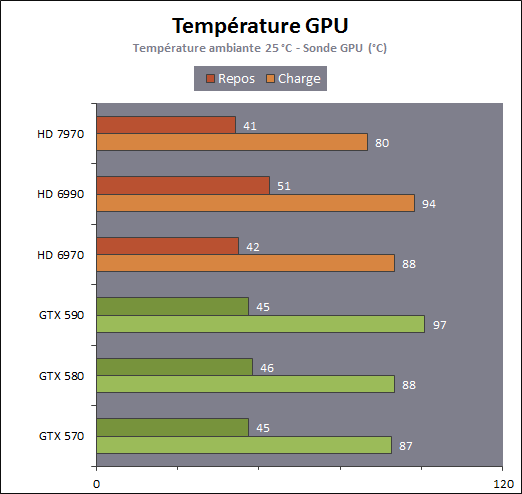 Le système de refroidissement de la Radeon HD 7970 est en effet calibré pour maintenir le GPU à une température plus faible que les autres cartes de référence : 80 °C. Il s'agit peut-être d'une erreur de calibration, mais il est également possible que les GPU fabriqués en 28 nanomètres soient moins conciliants avec de trop hautes températures. Page 11 - Thermographie infrarouge Thermographie infrarougePour ce test, nous avons repris notre nouveau protocole dont une version beta avait été introduite pour notre comparatif de GeForce GTX 580. Nous l'avons légèrement corrigé en remplaçant l'ensemble des ventilateurs d'origine du boîtier Cooler Master RC-690 II Advanced par des modèles Noctua : un NF-P14 FLX en aspiration et deux NF-S12B en extraction. Au repos ils tournent à 600 RPM alors qu'en charge le 140mm passe à 780 RPM et les 120mm à 990 RPM. Une modification qui améliore le rapport refroidissement/bruit mais qui permet surtout de se débarrasser du bruit mécanique des ventilateurs d'origine. Si ce bruit ne modifiait pas spécialement la pression sonore obtenue lors des mesures, il rendait difficile l'appréciation à l'oreille des nuisances sonores, ce qui est nécessaire quand le ventilateur de la carte graphique produit lui aussi un bruit mécanique ou quand sa vitesse varie. Nous en avons profité pour intégrer une mesure du bruit lorsque le ventilateur de la carte graphique tourne à sa vitesse maximale. Voici tout d'abord un récapitulatif de tous les relevés : 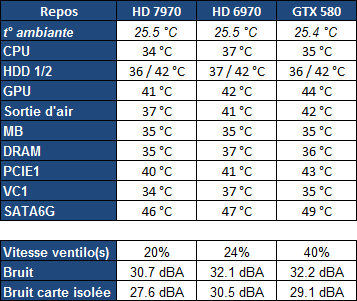 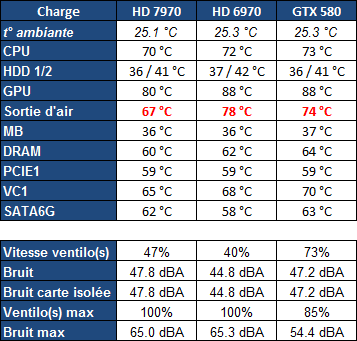 Les températures internes sont légèrement plus faibles avec la Radeon HD 7970 qui a supprimé presque totalement la petite part d'air chaud qui était auparavant expulsé dans le boîtier via le dessus de la carte. En charge elle est plus bruyante, ce qui est lié au débit plus important de sa turbine. Si elle tourne à 47% de sa vitesse maximale, cela correspond à 2500 RPM, exactement comme pour celle de la Radeon HD 6970 à 40%. Voici enfin, ce que tout cela donne à travers l'imagerie thermique : 
La Radeon HD 7970 est bien refroidie, avec un étage d'alimentation qui ne s'échauffe pas excessivement. Notez que dans le cas de la Radeon HD 6970, ce dernier est masqué par la plaque qui recouvre l'arrière de la carte. 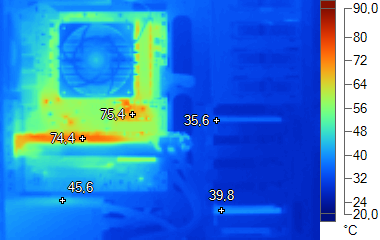
La Radeon HD 7970 rejette moins d'air chaud à l'intérieur du boîtier que la Radeon HD 6970 et que la GeForce GTX 580, ce qui peut s'observer sur ces images, surtout par rapport à la GeForce GTX 580. Page 12 - Performances théoriques : pixels Performances texturingNous avons mesuré les performances lors de l'accès à des textures de différents formats en filtrage bilinéaire : en 32 bits classique (8x INT8), en 64 bits "HDR" (4x FP16), en 128 bits (4x FP32), en profondeur de 32 bits (D32F) et en 32 bits RGB9E5, un format HDR introduit par DirectX 10 qui permet de stocker des textures HDR en 32 bits avec quelques compromis. 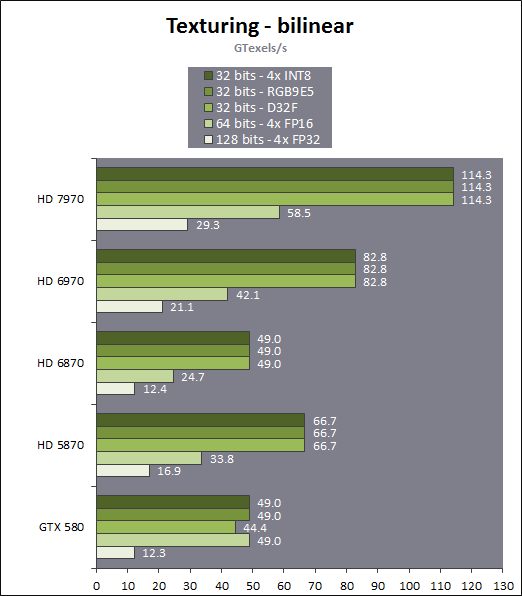 Les GeForce GTX 500 sont capables de filtrer les textures FP16/11/10 et RGB9E à pleine vitesse mais les Radeon HD 6900 ainsi que la Radeon HD 7970 disposent d'une puissance de filtrage tellement supérieure, que même si elles doivent filtrer les textures FP16 à demi-vitesse, elles affichent des débits proches des GeForce. Notez que nous devons augmenter la limite de consommation des Radeon HD 6900 au maximum sans quoi les fréquences se réduisent dans ce test. De base, ces Radeon semblent donc incapables de profiter pleinement de toute leur puissance de texturing ! Bonne nouvelle, ce n'est plus le cas pour la Radeon HD 7970. FillrateNous avons mesuré le fillrate sans et puis avec blending, et ce avec différents formats de données : 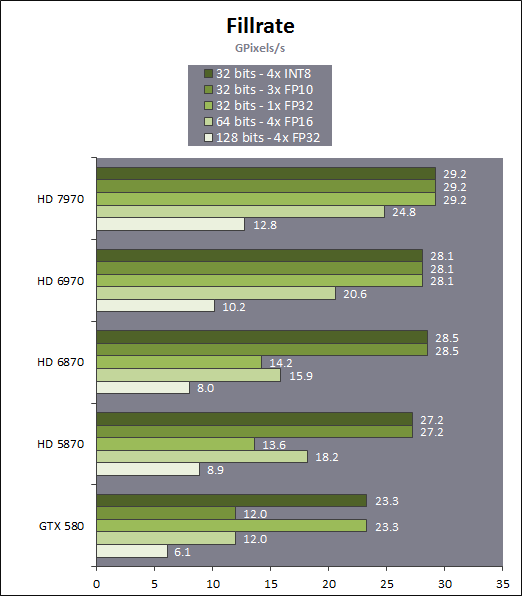 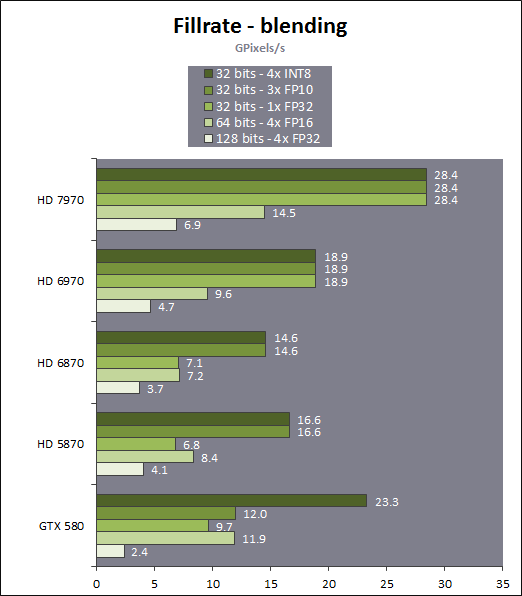 En terme de fillrate, les Radeon ont un avantage sur la GeForce GTX 580, surtout en FP10, format traité à pleine vitesse alors que sur les GeForce il passe à demi vitesse. Compte tenu de la limitation des GeForce au niveau des datapaths entre les SMs et les ROPs, il est dommage que Nvidia n'ait pas donné à ses GPUs la possibilité de profiter des formats FP10 et FP11. Si les GeForce et les Radeon sont capables de traiter le FP32 simple canal à pleine vitesse sans blending, seules ces dernières conservent ce débit avec blending. Grâce à son bus mémoire de 384 bits, et à la bande passante supplémentaire relative au nombre de ROP, la Radeon HD 7970 affiche une nette progression avec blending. Ce bus mémoire n'est donc pas inutile ! Page 13 - Performances théoriques : géométrie Débit de trianglesEtant donné les différences architecturales des GPUs récents au niveau du traitement de la géométrie, nous nous sommes évidemment penchés de plus près sur le sujet. Tout d'abord nous avons observé les débits de triangles dans deux cas de figure : quand tous les triangles sont affichés et quand ils sont tous rejetés (parce qu'ils tournent le dos à la caméra) : 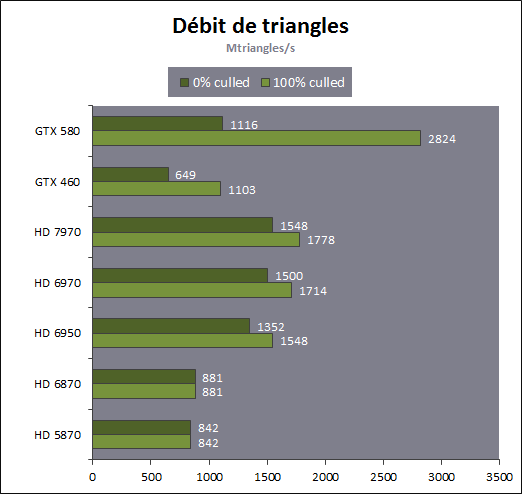 Si les Radeon HD 7900 et 6900 sont bel et bien capables de traiter 2 triangles par cycle, la GeForce GTX 580 conserve l'avantage avec 4 triangles par cycle. Quand les triangles doivent être rendus, ses performances sont par contre réduites, Nvidia les bridant pour différencier les Quadro des GeForce. Ensuite nous avons effectué un test similaire mais en utilisant la tessellation : 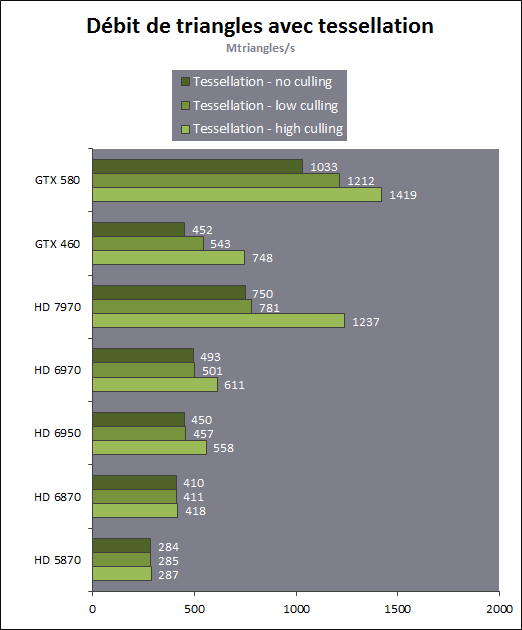 Alors que la Radeon HD 7970 ne se démarque pas réellement de la Radeon HD 6970 sans tessellation, ses performances augmentent significativement avec, même si la GeForce GTX 580 conserve toujours un avantage. L'architecture des Radeons fait qu'elles peuvent être engorgées par la quantité de données générées, ce qui réduit drastiquement leur débit dans ce cas. Le doublement de la taille du buffer dédié à l'unité de tessellation dans le GPU des Radeon HD 6800 leur permet d'être significativement plus performantes que les Radeon HD 5800, la parallélisation du traitement géométrique permet aux Radeon HD 6900 de revenir un peu sur les GeForce et la Radeon HD 7970 réduit encore l'écart. La GeForce GTX 580 profite pour sa part d'une architecture distribuée avec une prise en charge de la géométrie au niveau des unités de calcul, ce qui évite la centralisation de l'amplification géométrique et l'engorgement qui peut en découler. Page 14 - Protocole de test Mise à jour du 24 décembreCompte tenu du lancement quelque peu précipité par rapport au timing initialement prévu, il nous a été impossible de traiter au départ tous les points que nous avions prévus. Nous avons cependant mis à jour le dossier avec : - des photos thermiques de la Radeon HD 7970 et tous les résultats qui les accompagnent - des mesures de performances dans les jeux avec PowerTune en +20%, -10% et -20% - des mesures de consommation dans un jeu (Anno 2070) et en veille écran - un graphe de performances par watt Nous évaluons également la possibilité d'intégrer quelques tests autour du PCI Express 3.0 et du GPU computing, ce dernier point étant relativement complexe tant il est difficile d'obtenir des résultats pertinents. Une application peut ainsi être nettement plus rapide sur une architecture que sur une autre simplement à cause d'un détail spécifique au code en question. Pour le PCI Express 3.0 les premiers résultats montrent qu'en x16 l'impact est infime sauf dans quelques cas de GPU computing : son intérêt sera surtout sur les plates-formes fonctionnant en x8/x8 en CrossFire, voir en x8/x4/x4 comme le permet le futur chipset Z77. Le testPour ce test, nous avons revu notre protocole de manière à inclure de nouveaux jeux : Anno 2070, Batman Arkham City, Battlefield 3, F1 2011 et Total War Shogun 2. Nous y avons également ajouté Project Cars, un jeu en cours de développement et qui n'a pas encore été optimisé pleinement. Il ne sera donc pas intégré à l'indice, mais il sera intéressant d'observer les performances des différentes cartes dans le temps. Nous avons décidé de ne plus utiliser le niveau de MSAA (4x et 8x), comme critère principal pour segmenter nos résultats. De nombreux jeux au rendu différé proposent d'autres formes d'antialiasing, la plus courante étant le FXAA développé par Nvidia. Cela n'a donc plus de sens d'organiser un indice autour d'un certain niveau d'antialiasing, ce qui nous permettait par le passé de juger de l'efficacité du MSAA qui peut varier suivant l'implémentation. En 1920x1080, nous avons dès lors exécuté les tests d'une part avec un niveau de qualité très élevée, ce qui inclus d'office un minimum d'antialiasing (soit du MSAA 4x, soit du FXAA/MLAA/AAA) et d'autres part avec un niveau de qualité extrême. Les tests ont également été effectués en 2560x1600 et en résolution surround 5760x1080 en qualité très élevée. Nous n'affichons plus les décimales dans les résultats de performances dans les jeux pour rendre les graphiques plus lisibles. Ces décimales sont néanmoins bien notées et prises en compte pour le calcul de l'indice. Si vous êtes observateurs vous remarquerez que c'est également le cas pour la taille des barres dans les graphes. Les Radeon ont été testée avec les pilotes beta 8.921.2-111215a et les GeForce avec les pilotes 290.36. Configuration de testIntel Core i7 980X (HT et Turbo désactivés) Asus Rampage III Extreme 6 Go DDR3 1333 Corsair Windows 7 64 bits Pilotes GeForce 290.36 Catalyst beta 8.921.2.111215a Page 15 - Benchmark : Anno 2070 Anno 2070  Anno 2070 reprend une évolution du moteur d'Anno 1404 qui intègre un support de DirectX 11. Nous utilisons d'une part le mode de qualité très élevé proposé par le jeu et d'autre part, en 1920x1080, nous poussons au maximum le filtrage anisotrope et le post processing, qui devient alors très gourmand. Nous effectuons un déplacement sur une carte et mesurons les performances avec fraps. 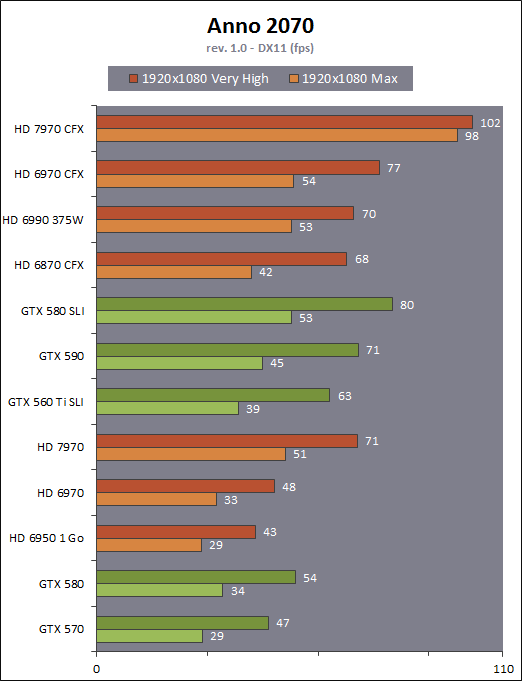 La Radeon HD 7970 apprécie particulièrement ce premier jeu avec un gain de 47% en qualité très élevée qui monte à 57% en qualité maximale sur la Radeon HD 6970. Une avance qui est également très importante sur la GeForce GTX 580. Les Radeon HD 7970 en CrossFire X sont également très efficace avec un gain beaucoup plus important que du côté des Radeon HD 6970. 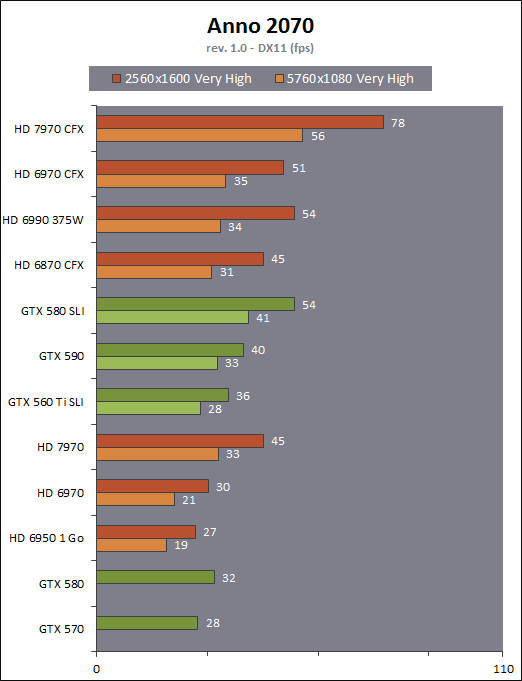 En hautes résolutions, les résultats restent excellents. Page 16 - Benchmark : Batman Arkham City Batman Arkham City  Batman Arkham City est mis au point avec une version récente de l'Unreal Engine 3 qui supporte DirectX 11. Bien que ce mode ait souffert d'un gros bug dans la version d'origine du jeu, un patch 1.1 a corrigé cela. Nous utilisons le benchmark intégré. Toutes les options sont poussées au maximum, ce qui inclut un niveau de tessellation extrême sur une partie des scènes testées. Les performances sont mesurées d'une part avec FXAA et d'autre part avec MSAA 8x. Nous avons par ailleurs ajouté les performances obtenues avec les effets GPU PhysX activés.  Si le gain apporté par la Radeon HD 7970 est important en mode FXAA, ce n'est pas le cas en MSAA 8x, où il se limite à 16% sur la Radeon HD 6970 et 10% sur la GeForce GTX 580. Vous remarquerez que CrossFire X ne fonctionne pas correctement dans ce jeu qui est pourtant un titre majeur. Les GeForce sont logiquement devant lorsque les effets GPU PhysX sont activés, mais l'avance reste faible compte tenu du fait qu'ils ne sont pas utilisés dans toute la scène de test. Là où c'est le cas les GeForce parviennent à maintenant 40 fps, là où les Radeon plongent sous 20 fps. 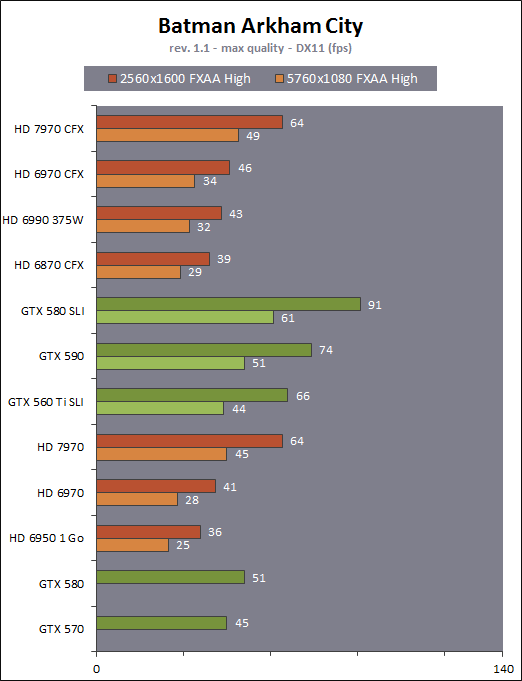 En haute résolution la Radeon HD 7970 apporte un gain qui peut monter jusqu'à 61% sur la Radeon HD 6970. Page 17 - Benchmark : Battlefield 3 Battlefield 3  Battlefield 3 repose sur le Frosbite 2, probablement la moteur graphique le plus avancé à ce jour. De type rendu différé, il supporte la tessellation et calcule l'éclairage via un compute shader. Nous testons les modes High et Ultra et relevons les performances avec Fraps, sur un parcours bien défini. 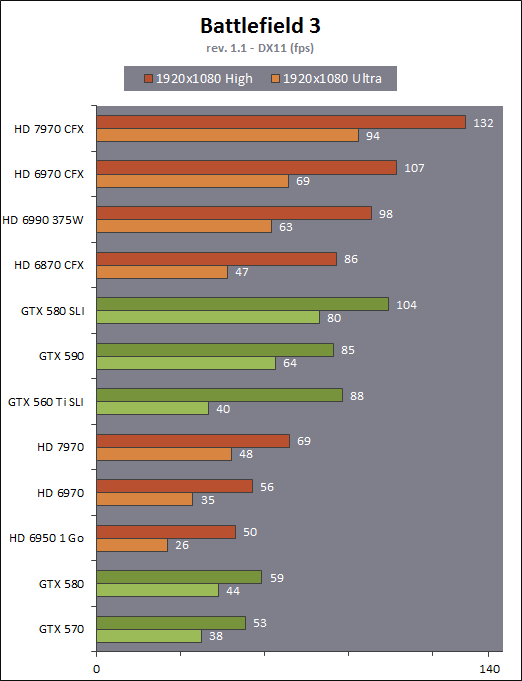 Le gain apporté par la Radeon HD 7970 est de 24% en mode High alors qu'il est de 40% en mode Ultra. Notez que dans ce mode les cartes équipées de seulement 1 Go de mémoire souffrent de très grosses saccades. 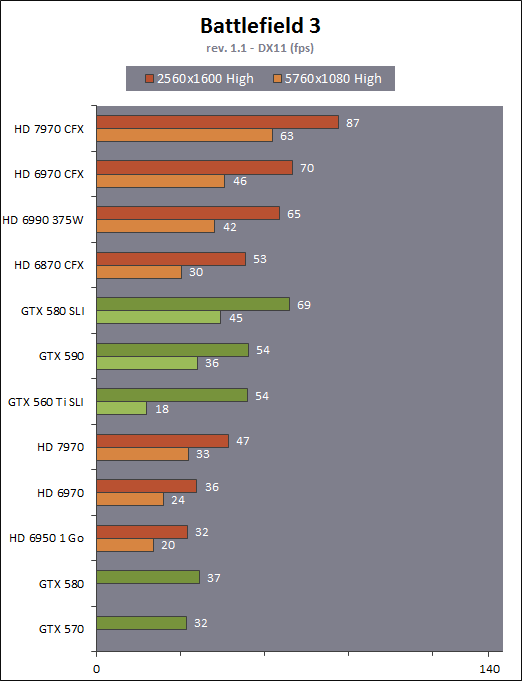 En surround, un système CrossFire X à base de Radeon HD 7970 permet de jouer très confortablement à Battlefield 3. Page 18 - Benchmark : Bulletstorm Bulletstorm  Bulletstorm se contente de DirectX 9, mais propose un rendu plutôt sympathique, basé sur la version 3.5 de l'Unreal Engine. Toutes les options graphiques sont poussées au maximum (high) et nous mesurons les performances avec Fraps. 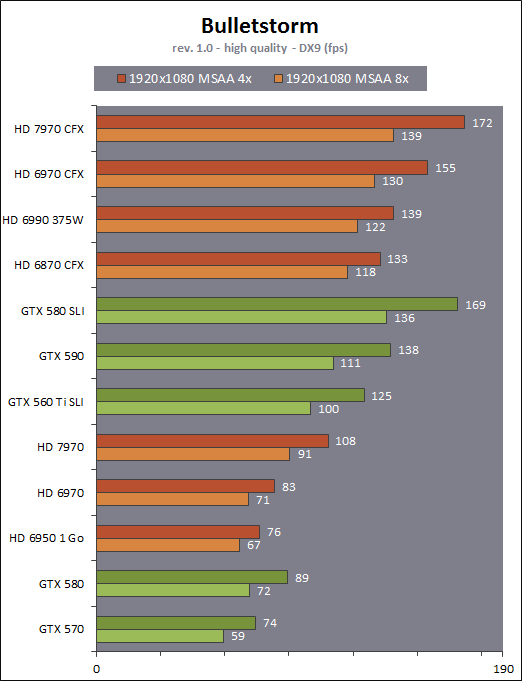 Le gain apporté par la Radeon HD 7970 est cette fois un petit peu plus faible. 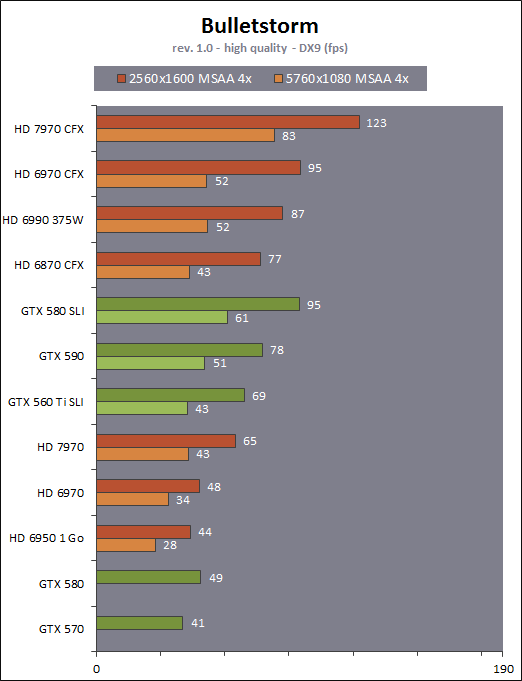 Il atteint malgré tout 35% en 2560x1600, un gain qui rend cette résolution jouable. Page 19 - Benchmark : Civilization V Civilization V  Plutôt réussi visuellement, Civilization V exploite DirectX 11 d'une part pour améliorer la qualité et optimiser les performances du rendu des terrains grâce à la tessellation et d'autre part implémente une compression spéciale des textures grâce aux compute shader, compression qui permet de garder en mémoire les scènes de tous les leaders. Cette seconde utilisation de DirectX 11 ne nous concerne cependant pas ici puisque nous utilisons le benchmark intégré sur une carte de jeu. Nous zoomons légèrement de manière à réduire la limitation CPU qui est très forte dans ce jeu. Tous les détails sont poussés à leur maximum et nous mesurons les performances avec ombres et réflexions. Le dernier patch est installé. 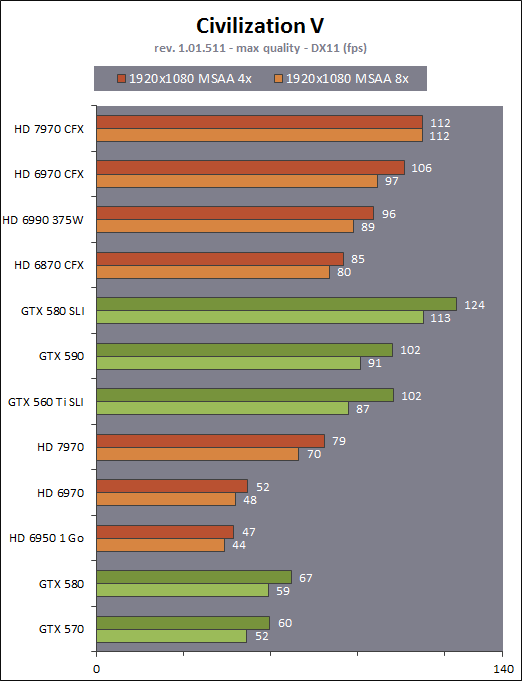 La Radeon HD 7970 gagne ici 50% de performances sur la Radeon HD 6970. De quoi passer devant la GeForce GTX 580 qui disposait d'une avance importante dans ce jeu. 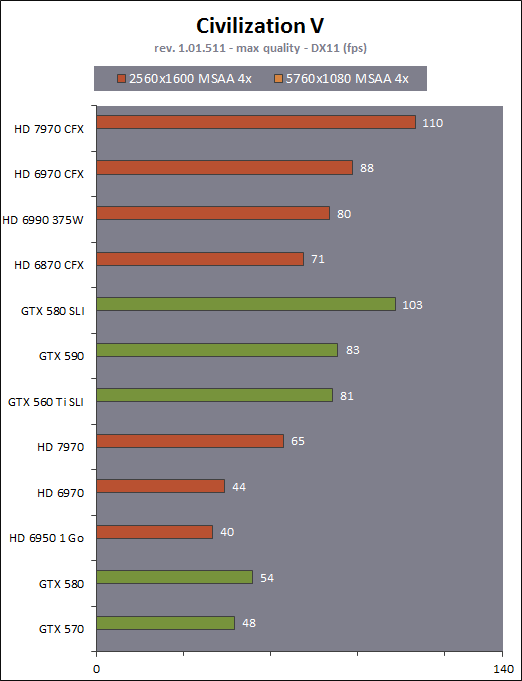 Civilization V supporte le surround, mais ce n'est malheureusement pas le cas de son benchmark. Page 20 - Benchmark : Crysis 2 Crysis 2  Crysis 2 reprend une évolution du moteur de Crysis Warhead optimisée pour être relativement moins gourmande mais y ajoute, via un patch, un support de DirectX 11 dont le coût peut être assez important. C'est par exemple le cas de la tessellation, implémentée en collaboration avec Nvidia d'une manière abusive, dans le but de faire plonger les performances sur les Radeon. Nous avions dévoilé cette entourloupe ici. Si nous présentons les résultats obtenus avec tessellation à titre informatif, puisqu'ils permettent d'observer l'évolution à ce niveau apportée par la Radeon HD 7970, nous n'utilisons que des résultats sans tessellation dans le calcul de l'indice. Nous mesurons les performances avec Fraps sur la version 1.9 du jeu. 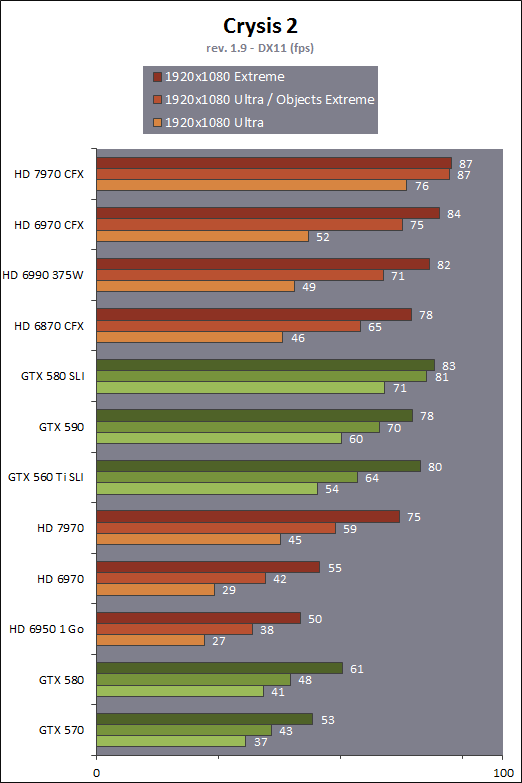 Plus les options graphiques sont élevées, plus le gain apporté par la Radeon HD 7970 est important. Il monte à 56% quand la tessellation abusive est activée. 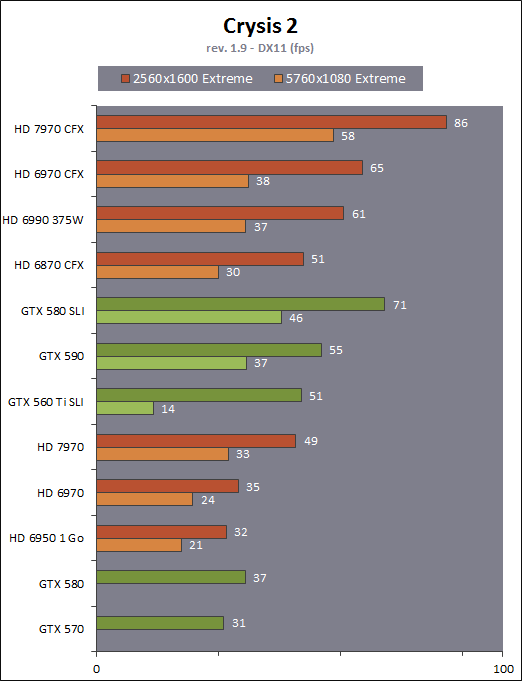 Les deux Radeon HD 7970 en CrossFire X permettent de jouer à Crysis 2 très confortablement en surround, même avec un niveau de détails graphiques important. Page 21 - Benchmark : F1 2011 F1 2011  Dernier né chez Codemaster, F1 2011 reprend une évolution légère du moteur de F1 2010 et de DiRT 3, qui conserve le support de DirectX 11. Pour mesurer les performances, nous poussons toutes les options graphiques à leur maximum et utilisons l'outil de test intégré sur le circuit de Spa-Francorchamps avec une seule F1. 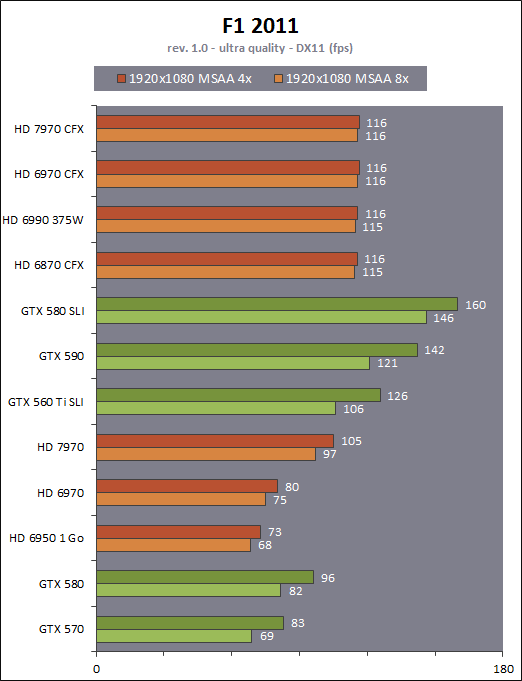 En 1920x1080, le gain est de 30%. Vous remarquerez que les solutions AMD sont limitées par le CPU bien plus tôt que les solutions Nvidia. 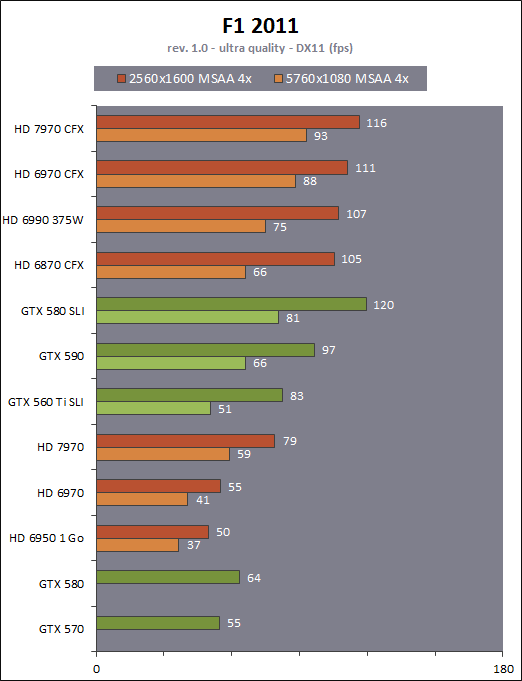 En très hautes résolutions, le gain atteint 45%. Page 22 - Benchmark : Metro 2033 Metro 2033  Toujours l'un des jeux les plus lourds, Metro 2033 met à genoux toutes les cartes graphiques récentes. Il supporte GPU PhysX, mais uniquement pour générer des particules lors des impacts, un effet plutôt discret que nous n'avons donc pas activé pour les tests. En mode DirectX 11, il affiche des performances identiques au mode DirectX 10 mais propose 2 options supplémentaires : la tessellation pour les personnages et un effet de champ (Depth of Field) très évolué et très gourmand. Nous l'avons testé en mode DirectX 11, avec une qualité très élevée et la tessellation activée. 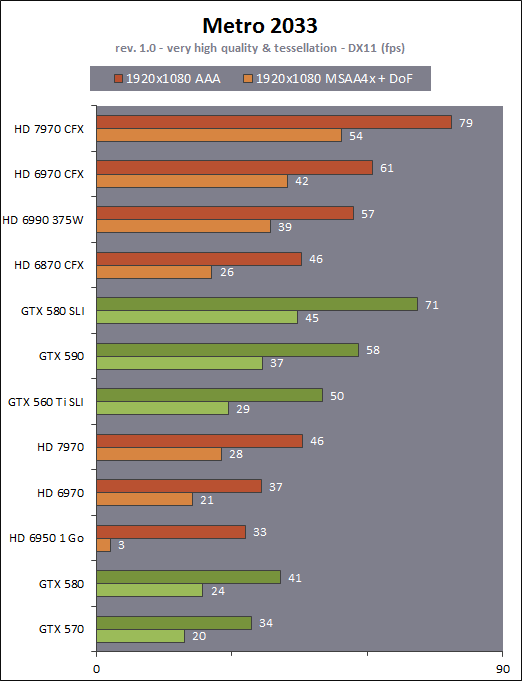 En 1920x1080, le gain varie entre 25 et 30% par rapport à la Radeon HD 6970 mais est très réduit par rapport à la GeForce GTX 580. 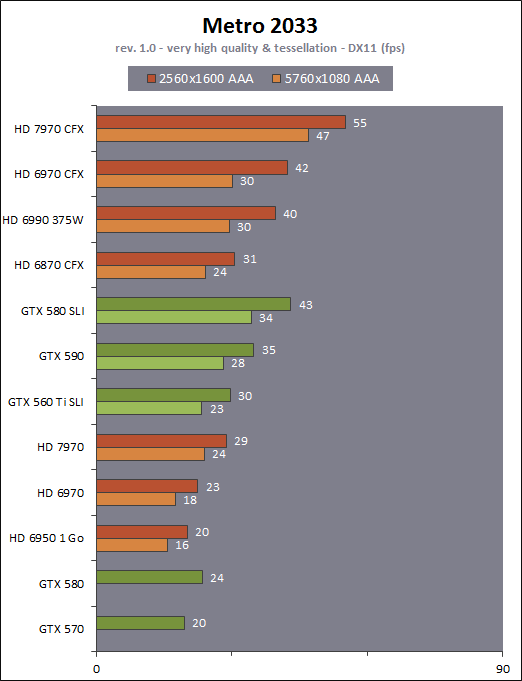 La Radeon HD 7970 profite ici d'un gain quelque peu plus important, mais pour jouer dans ces conditions, il faudra opter pour un système CrossFire X. Page 23 - Benchmark : Project Cars Project Cars  Project Cars est un jeu de course automobile en cours de développement . Un système de beta participative permet d'accéder aux builds régulières et d'interagir avec les développeurs de Slightlymad Studios (à l'origine des Need For Speed Shift). Si nous n'intégrerons pas ces résultats dans le calcul de l'indice final, il est malgré tout intéressant d'observer comment se comportent différent cartes graphiques dans un jeu en développement. Son moteur au rendu différé supporte DirectX 11 et c'est ce mode que nous avons testé en poussant toutes les options au maximum. 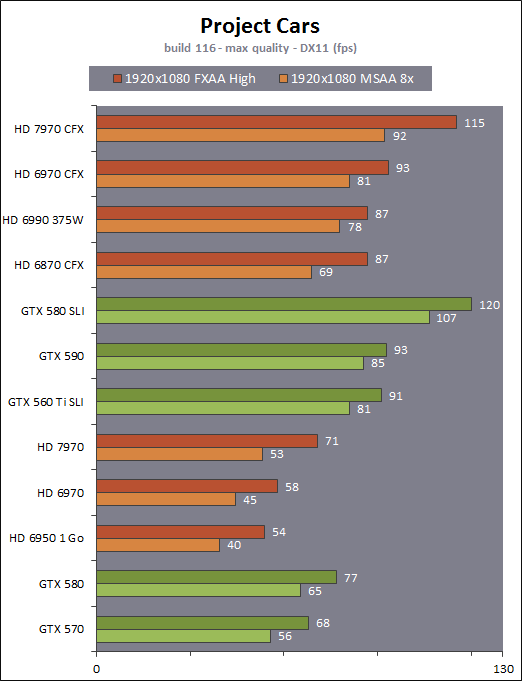 Les GeForce s'en tire ici beaucoup mieux que les Radeon. Notez qu'en CrossFire et en SLI des petits bugs sont encore visibles dans les réflexions. 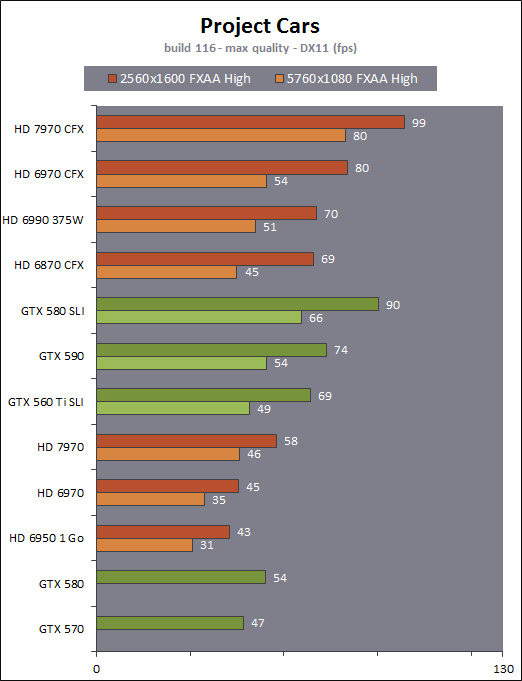 En hautes résolutions, les Radeon relèvent la tête. Page 24 - Benchmark : Total War Shogun 2 Total War Shogun 2  Total War Shogun 2 a reçu un patch DirectX 11, développé en collaboration avec AMD. Il apporte entre autre un support de la tessellation et un effet de profondeur de champ de meilleure qualité. Nous l'avons testé en mode DirectX 11, avec une qualité maximale. 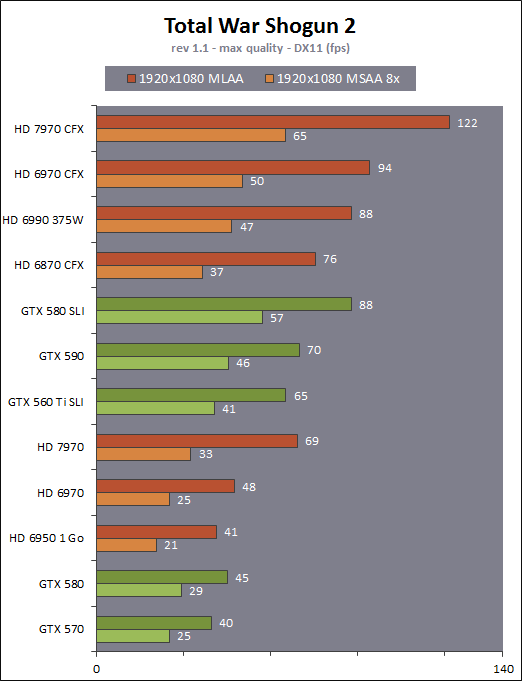 La Radeon HD 7970 affiche ici un gain impressionnant sur la GeForce GTX 580 : +53%. Comme quoi travailler avec les développeurs ça paye... sauf en MSAA 8x, où les résultats sont par contre moins bons : +12% seulement. 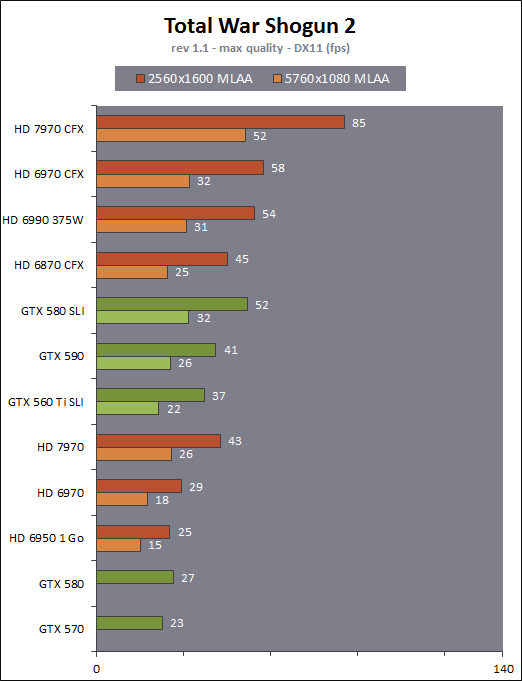 En 2560x1600 l'avantage de la Radeon HD 7970 sur la GeForce GTX 580 atteint 62%. Page 25 - Récapitulatif des performances RécapitulatifBien que les résultats de chaque jeu aient tous un intérêt, nous avons calculé un indice de performances en nous basant sur l'ensemble de résultats et en attachant une importance particulière à donner le même poids à chacun des jeux. Les résultats de Batman Arkham City avec GPU PhysX, de Crysis 2 avec tessellation et de Project Cars ne sont pas pris en compte dans l'indice. Nous avons attribué un indice de 100 à la Radeon HD 6970 en 1920x1080 : 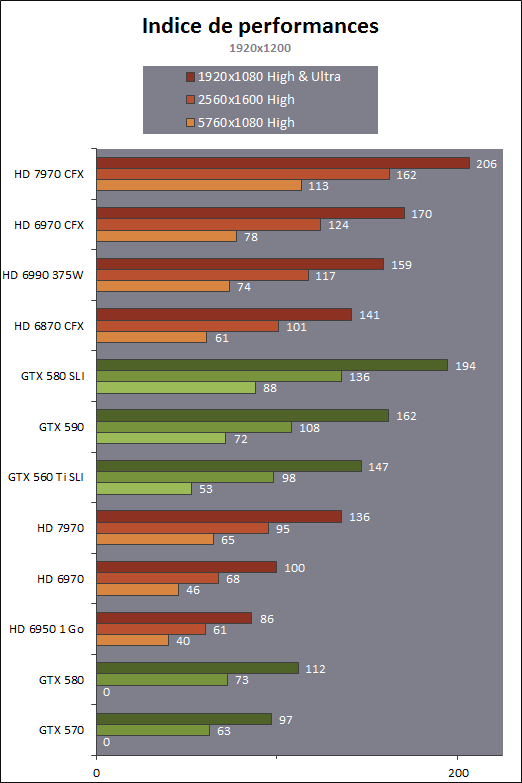 Maintenez la souris sur le graphe pour classer les cartes par performances en 1920x1080. La Radeon HD 7970 nous apporte un gain moyen de 36 à 43% sur la Radeon HD 6970, suivant la résolution. Par rapport à la GeForce GTX 580, il est de 22% en 1920x1080 et de 31% en 2560x1600. Ce n'est pas suffisant pour devancer la GeForce GTX 590 et la Radeon HD 6990, ni les systèmes multi-GPU milieu de gamme : les Radeon HD 6870 et les GeForce GTX 560 Ti. Ces solutions n'ont cependant qu'une faible avance, qui ne justifie pas selon nous les embarras du multi-GPU. Elles souffrent qui plus est de ralentissement dans certains jeux, leur mémoire de 1 Go étant insuffisante. Quant aux Radeon HD 7970 en CrossFire X, elles prennent fort logiquement la tête, même si elles sont impactées par une forte limitation CPU dans F1 2011 ainsi que par un profil CrossFire X non fonctionnel pour Batman Arkham City. Lors de tous ces tests, nous avons remarqué une tendance avec les Radeon : elles tendent à souffrir plus que les GeForce lorsque les moteurs au rendus différés utilisent du MSAA. Exploiter ce type d'antialiasing dans un moteur au rendu différé est complexe, vous pourrez en retrouver un exemple dans notre dossier Comprendre le rendu 3D étape par étape avec 3DMark 11. Si nous ne voyons pas de raisons techniques à cela, nous supposons qu'AMD a réduit ses efforts d'optimisations, préférant mettre en avant les antialiasings effectués en post-traitement, tels que le FXAA ou le MLAA, plus simples à supporter. Page 26 - Conclusion ConclusionAvec une nouvelle architecture, le passage à une finesse de gravure de 28 nanomètres et à plus de 4 milliards de transistors le GPU Tahiti et la Radeon HD 7970 ont suscité bien des attentes. AMD est-il parvenu à faire aussi bien que lors du lancement du GPU Cypress et de la Radeon HD 5870 ? Question délicate qui suscitera sans aucun doute le débat puisque les gains de performances sont inférieurs et les nouvelles fonctionnalités moins tape-à-l'il. Avec un gain moyen de 45 à 50% sur le précédent GPU, l'introduction d'une nouvelle API majeure, DirectX 11, et de fonctionnalités inédites telles qu'Eyefinity, la Radeon HD 5870 a marqué les esprits. De son côté, la Radeon HD 7970 affiche un gain de performances moyen de 35 à plus de 40% sur la Radeon HD 6970 qui la précédait. Un gain très honnête, d'autant plus qu'il peut dépasser 50% dans certains jeux tels que Crysis 2 ou Batman Arkham City. Une carte graphique qui sera ainsi idéale pour jouer en très haute résolution ou en 1080p avec les jeux les plus gourmands et un niveau de qualité extrême. AMD n'a par ailleurs négligé aucune nouvelle technologie : DirectX 11.1, OpenCL 1.2, PCI Express 3.0, HDMI 1.4a 3 GHz Rien de majeur certes, mais tout y est, y compris des évolutions probablement coûteuses mais importantes pour l'envol du GPU computing et dont il restera à observer les bénéfices. Nouvelle architecture oblige, il est également raisonnable de supposer qu'elle dispose encore d'une marge de progression non-négligeable, que ce soit du côté du compilateur ou directement des développeurs qui ont optimisé leur code en prévision de l'architecture des précédentes Radeon, ce qui peut maintenant être contre-productif.  Aidé par le passage au 28 nanomètres et par la technologie PowerTune, qui a gagné en finesse, AMD est parvenu à intégrer tout ceci en restant dans une même enveloppe thermique de 250W. Une non-évolution qui est dans ce cas une très bonne nouvelle, d'autant plus qu'AMD a réduit la consommation au repos, surtout quand l'écran est en veille, à tel point que la carte graphique consomme alors moins de 2W. Un gros avantage pour les systèmes allumés en permanence et qui ont besoin ponctuellement de beaucoup de puissance graphique, tel qu'un HTPC qui combine serveur de fichiers et plateforme de jeu. Reste bien entendu à voir quelle sera la réponse de Nvidia, mais surtout quand elle arrivera. Nous ne prenons pas trop de risques en supposant que le futur GPU haut de gamme de Nvidia, Kepler, devancera Tahiti sur le plan des performances. Mais quand arrivera-t-il ? Dans 2 mois ? Dans 3 mois ? Dans 6 mois ? Explosera-t-il une nouvelle fois le record de consommation ? Ou sera-t-il capable d'améliorer significativement son efficacité énergétique comme le laisse entendre Nvidia ? Rattrapera-t-il le retard pris au niveau de la gestion des sorties vidéo ? Nous ne le savons pas. En attendant, AMD profite d'une voie royale pour la Radeon HD 7970 qui prend sur la GeForce GTX 580 une avance technologique sur de nombreux fronts, en plus des performances en hausse de 20 à 30%. Une domination qui se reflète dans la tarification : 500. C'est cher mais logique, d'autant plus que les volumes au lancement seront limités. Il est d'ailleurs inutile d'aller de ce pas chez votre revendeur préféré, la disponibilité n'est prévue que pour le 9 janvier, date à laquelle nous pourrons également vous proposer le test de la Radeon HD 7950. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |