
Les contenus liés aux tags Kepler et GTC
Afficher sous forme de : Titre | FluxGTC: Nvidia lève le voile sur le GK110
GTC: GTC 2012: la semaine du GPU computing
Nvidia GK110: 7 milliards de transistors à la GTC?
GTC: CUDA on ARM: Kayla, Tegra 3 et GK208



Nvidia l'a enfin confirmé, CUDA arrivera enfin dans les SoC Tegra avec Logan. Cela ne veut pas dire pour autant que CUDA sur plateforme ARM doit attendre. Il s'agit d'un point important de la stratégie de Nvidia pour son futur autant dans le monde professionnel que grand public. C'est la raison pour laquelle, depuis quelques temps déjà, Nvidia s'est associé à SECO pour proposer un kit de développement dénommé CARMA. Pour 529, la plateforme propose un connecteur Q7 qui reçoit un SoC Tegra 3 (T30 à 1.3 GHz) et un connecteur MXM sur lequel prend place une Quadro 1000M de génération Fermi (GF108 avec 96 cores).

Tout cela va évoluer à partir du mois de mai, d'une part avec une couche logicielle qui supportera Ubuntu 12.04 et CUDA 5.0, et d'autre part avec la plateforme KAYLA, toujours développée en partenariat avec SECO, et qui existera en 2 versions : connecteur MXM ou PCI Express (câblés en 4x dans les 2 cas). Si nous aurions pu supposer que le SoC passerait en version Tegra 4, c'est bel et bien le Tegra 3 T30 qui reste exploité pour la simple et bonne raison que ses successeurs ne disposent plus de liens PCI Express. La différence (unique ?) entre les 2 cartes concerne les GPU supportés. La version PCI Express en supporte un large choix et la version MXM est annoncée être équipée d'un GPU Kepler de next generation.
Nvidia indique à ce sujet que ce GPU dispose de 2 SMX (384 cores), supporte les compute capabilities 3.5 (Dynamic Parallelism etc.) et est très proche du niveau de fonctionnalité du futur SoC Logan. Nous apprenons ainsi que le GPU de cette plateforme et celui de Logan disposent d'un processeur de commande plus évolué que sur les premiers GPU de la génération Kepler, dérivé de celui du GK110 (Tesla K20 et GTX Titan).
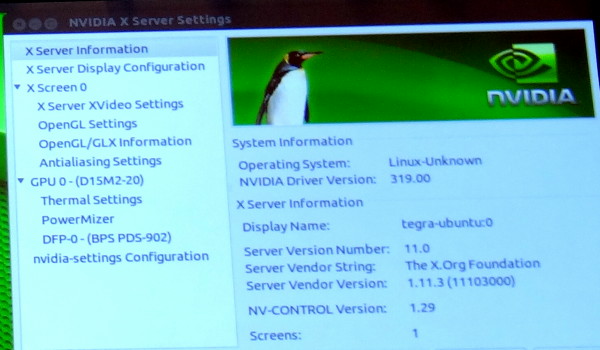
De toute évidence ce GPU est ainsi le GK208 qui prendra place dans les GeForce 700 d'entrée de gamme. Une supposition renforcée par un panneau de contrôle des pilotes Linux que Nvidia a malencontreusement oublié de masquer pendant quelques secondes et qui fait référence à un nom de code produit : D15M2-20. Cela correspond à la famille GeForce 700 desktop (D12 = GeForce 400, D13 = GeForce 500, D14 = GeForce 600 ).

Cette plateforme CUDA on ARM continuera bien entendu à évoluer, tout d'abord avec CUDA 5.5 qui intégrera un compilateur CUDA pour l'architecture ARM, et plus tard avec l'arrivée de Logan et de Parker.
Correction du 01/07/2013: le nom du GPU que nous pensions être GK117 est en réalité GK208.
GTC: GeForce GRID: jouer depuis le cloud
Avec la famille de GPU Kepler, Nvidia vise un nouveau marché : cloud computing. Nous vous avons déjà parlé du pan professionnel de cette stratégie avec VGX dédié à la virtualisation et nous abordons aujourd'hui l'autre partie : le cloud gaming.

Jouer à travers le cloud revient à transformer n'importe quel périphérique connecté en une combinaison écran / contrôleur de jeu. Toutes les informations de contrôle sont envoyées vers un serveur distant sur lequel le jeu va en réalité tourner. Chaque image calculée par ce serveur est renvoyée vers le client à travers un flux H.264. Les avantages sont multiples : plus besoin d'une puissance de calcul importante du côté du joueur, plus besoin de mettre à jour son matériel pour les nouveaux jeux, possibilité de jouer facilement depuis n'importe quel endroit et périphérique. De quoi révolutionner le petit monde du jeu vidéo.
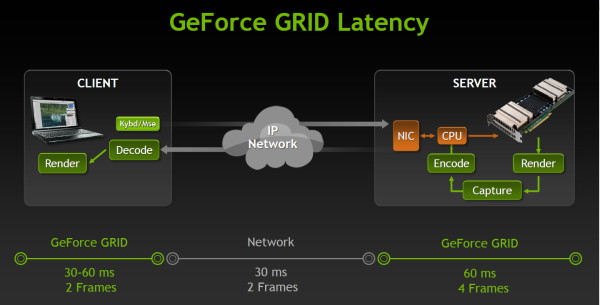
En contrepartie, cela demande une infrastructure importante du côté des fournisseurs de service et surtout, jouer depuis le cloud augmente significativement la latence. Deux points noirs auxquels Nvidia indique s'attaquer avec GeForce GRID.
Au niveau de l'infrastructure, il faut savoir qu'en règle générale, actuellement, il faut un système/serveur par joueur connecté. Nvidia donne ainsi un exemple actuel de plateforme dédiée au cloud gaming pour laquelle chaque baie accueille 28 serveurs (1 CPU + un GPU) et permet donc de gérer jusqu'à 28 flux de jeu. GeForce GRID permet de faire grimper cette densité en intégrant 4 GPU par serveur. Avec 21 de ces serveurs par baie il est ainsi possible de supporter jusqu'à 84 flux de jeu. Ce n'est pas tout puisque cette approche permet selon Nvidia de faire baisser la consommation typique de 150 à 75W par flux de jeu, un exemple probablement d'un jeu pas trop lourd rendu en 720p.
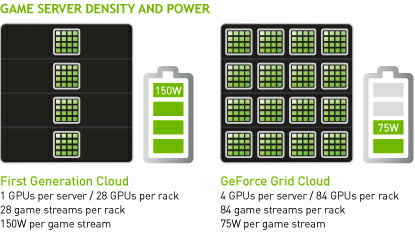
Comment cela est-il possible ? Tout d'abord au niveau matériel, Nvidia commercialise une carte GeForce GRID qui est en réalité identique à la Tesla K10. Il s'agit d'une version serveur de la GeForce GTX 690, avec des fréquences revues à la baisse pour tenir dans un TDP de 250W, configurable en 225W si nécessaire. Une seule de ces cartes peut ainsi gérer 2 flux de jeu. Nvidia propose d'en placer une seconde dans chaque serveur et probablement d'utiliser sa couche logicielle de virtualisation pour gérer efficacement jusqu'à 4 flux. La présence d'un encodeur H.264 dédié dans les GPU Kepler permet par ailleurs à GeForce GRID de gérer d'un bout à l'autre la récupération des images dans le framebuffer et leur encodage dans un flux H.264, déchargeant totalement le système de cette tâche et libérant le ou les CPU pour gérer ces flux de jeu supplémentaires.

Et pour la latence ? Nvidia nous donne ici aussi un exemple : 166ms pour une console, 286ms pour le cloud gaming actuel et 161ms pour GeForce GRID, en précisant que la latence typique d'un PC récent dans ce cas serait de 75ms.
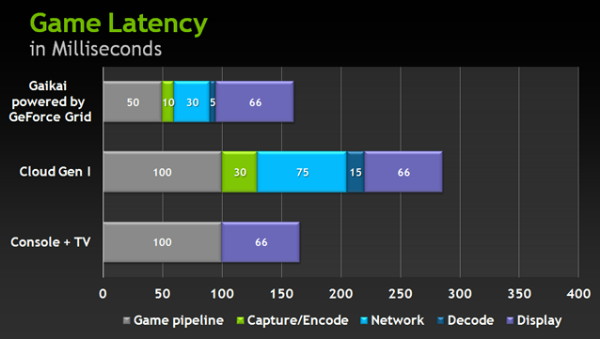
GeForce GRID gagne sur 3 points : le rendu, l'encodage et le réseau. Pour le rendu, Nvidia suppose qu'avec son GPU, les fournisseurs de service vont traiter les jeux à 60fps au lieu de 30fps, ce qui fait gagner 50ms de latence. Concernant l'encodage il passerait de 30 à 10ms alors que le décodage serait lui aussi plus rapide sur un composant Tegra.
Enfin, le réseau deviendrait lui aussi beaucoup plus rapide. En creusant un peu, Nvidia précise cependant ne rien pouvoir faire à ce niveau, mais supposer que GeForce GRID grâce à sa densité plus élevée et son attrait supérieur par rapport au cloud gaming actuel, va inciter les fournisseurs à mettre en place de plus en plus de serveurs. En d'autres termes, Nvidia présume que la probabilité d'en trouver un près de chez vous va augmenter et que la latence sera ainsi réduite.
Derrière ces affirmations se cache en réalité le fait que la latence du réseau est un problème et que Nvidia ne peut rien y faire actuellement, mais espère qu'elle se réduira à l'avenir. Ce ne sont cependant que des projections. Nvidia indique explorer d'autres voies telles que d'inciter les fabricants de TV à proposer une entrée ethernet à faible latence d'affichage, celle-ci étant en général relativement très élevée sur les TV, notamment à cause des différents traitements d'image.
Lors d'une démonstration sur TV, un autre problème saute aux yeux : la qualité de l'encodage H.264. Comme nous l'avons expliqué dans cet article dédié, NVENC, l'encodeur matériel de Kepler, s'il est très rapide, ne brille pas spécialement par sa qualité en comparaison de solutions CPU. Dans une scène de combat très rapide cela donne rapidement une bouillie de pixel passable sur un smartphone mais indigne d'un grand écran.
Vous l'aurez compris, nous ne sommes pas encore convaincus par le cloud gaming, en dehors du jeu occasionnel sur petit écran. Latence et qualité sont encore loin de pouvoir concurrencer ce bon vieux PC et Nvidia doit utiliser quelques artifices pour mettre en avant sa solution GeForce GRID : comparaison à des consoles qui commencent à dater et suppositions sur une amélioration future de la latence des réseaux.
Les mauvaises langues diront que faute d'avoir pu obtenir une place dans une des futures consoles pour l'un de ses GPU, Nvidia tente une autre approche pour ne pas être exclu de votre TV. D'autres, plus optimistes, insisteront sur le fait qu'il ne s'agit que d'un premier pas, qui a l'intérêt de trouver un nouveau débouché pour les GPU haut de gamme qui en ont bien besoin. De quoi pérenniser leur existence sur PC ?
Pour vous faire une idée sur le cloug gaming actuel, Gaikai propose gratuitement l'accès à des démos de quelques jeux PC, exécutées sur ses serveurs (classiques, sans GeForce GRID) et visualisées à travers un plugin pour votre navigateur internet. Le but étant à terme de proposer des jeux complets et de migrer vers des solutions plus efficaces telles que ce que promet Nvidia avec GeForce GRID.
GTC: Plus de détails sur le GK110
Lors d'une session technique sur l'architecture du GK110, nous avons pu apprendre quelques détails de plus à son sujet par rapport aux premières informations d'hier. Des détails bien entendu concentrés sur la partie compute de ce GPU. Tout d'abord, Nvidia propose cette fois un schéma de l'architecture qui montre sans ambiguïté que le GK110 est composé de 15 SMX de 192 unités de calcul, soit un total de 2880, et d'un bus mémoire de 384 bits.

On apprend par ailleurs que le cache L2 passe à 256 Ko par contrôleur mémoire 64 bits, soit un total de 1.5 Mo contre 768 Ko pour le GF1x0 et 512 Ko pour le GK104. Tout comme pour le GK104, chaque portion de cache L2 affiche une bande passante doublée par rapport à la génération Fermi.
Les blocs fondamentaux d'unités de calcul, appelés SMX dans la génération Kepler, sont similiaires pour le GK110 ceux du GK104 :

Le nombre d'unités de calcul simple précision est identique, tout comme le nombre d'unités dédiées aux fonctions spéciales, aux lectures/écritures, au texturing Les caches sont également identiques que ce soit les registres, le L1/mémoire partagée, les caches dédiés aux texturing.
La seule différence fondamentale réside dans la multiplication des unités de calcul en double précision qui passent de 8 pour le GK104 à 64 pour le GK110. Alors que le premier est 24x plus lent dans ce mode qu'en simple précision, le GK110 n'y sera que 3x plus lent. Couplé à l'augmentation du nombre de SMX, cela nous donne un GK110 capable de traiter 15x plus de ces instructions par cycle ! Par rapport au GF1x0 il s'agit d'un gain direct de 87.5% à fréquence égale.
Dans le GK110, tout comme dans le GK104, chaque SMX est alimenté par 4 schedulers, chacun capable d'émettre 2 instructions. Toutes les unités d'exécution ne sont cependant pas accessibles à tous les schedulers et un SMX est en pratique séparé en 2 parties symétriques à l'intérieur desquelles une paire de schedulers se partage les différentes unités. Chaque scheduler dispose de son propre lot de registres : 16384 registres de 32 bits (512 registres généraux de 32x32 bits en réalité). Par ailleurs chaque scheduler dispose d'un bloc dédié de 4 unités de texturing accompagnées d'un cache de 12 Ko.
Contrairement à ce à quoi nous nous attendions, l'ensemble cache L1 / mémoire partagée n'évolue pas dans le GK110 par rapport au GK104 et reste proportionnellement inférieur à ce qui était proposé sur la génération Fermi. Nvidia introduit par contre trois petites évolutions qui peuvent entraîner des gains importants :
Tout d'abord, chaque thread peut se voir attribuer jusqu'à 256 registres contre 64 auparavant. Quel intérêt quand le nombre de registres physiques n'augmente pas ? Il s'agit de donner plus de flexibilité au développeur et surtout au compilateur pour jongler entre le nombre de thread en vol et la quantité de registres allouée à chacun pour maximiser les performances. C'est particulièrement important dans le cas des calculs en double précision qui consomment le double de registres et qui étaient auparavant limités à 32 registres par thread. Passer à 128 permet des gains impressionnants dans certains cas selon Nvidia.

Ensuite, la seconde petite évolution consiste à autoriser l'accès direct aux caches dédiés au texturing. Auparavant il était possible d'en profiter manuellement en bricolant un accès à travers les unités de texturing, mais ce n'était pas pratique. Avec le GK110, ces caches de 12 Ko peuvent être exploités directement depuis les SMX mais uniquement dans le cas d'accès à des données en lecture seule. Ils ont l'avantage de disposer d'un accès royal au sous-système mémoire du GPU, de souffrir moins en cas de cache miss et de mieux supporter les accès non alignés. C'est le compilateur (via une directive) qui se charge d'y avoir recours lorsque c'est utile.
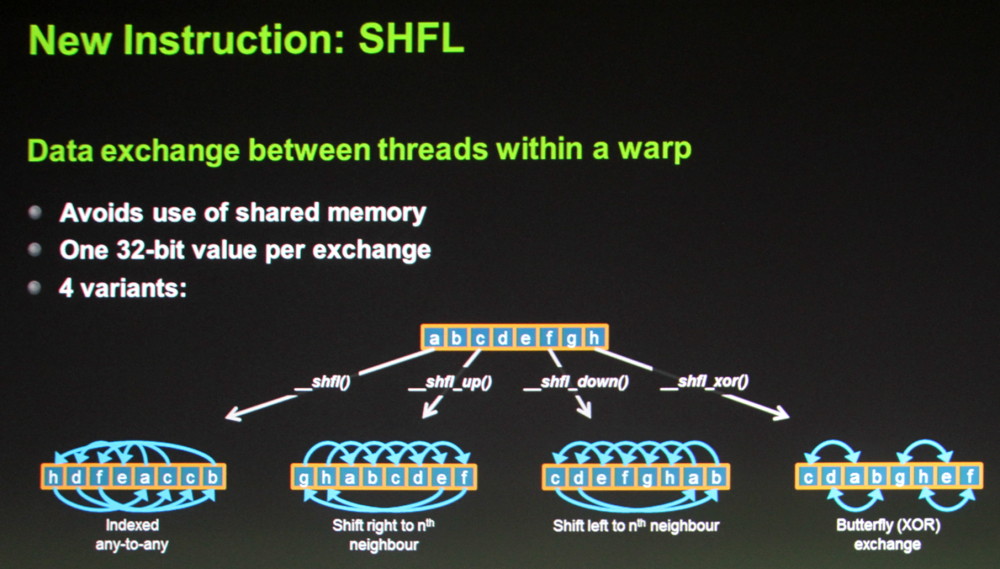
Enfin, une nouvelle instruction fait son apparition : SHFL. Elle permet un échange de donnée de 32 bits par thread à l'intérieur d'un warp (bloc de 32 threads). Son utilité est similaire à celle de la mémoire partagée et cette instruction vient donc en quelque sorte compenser sa quantité relativement faible, proportionnellement au nombre d'unités de calcul. Dans le cas d'un échange de données simple il sera donc possible d'une part de gagner du temps (un transfert direct à la place d'une écriture puis d'une lecture) et d'autre part d'économiser la mémoire partagée.
D'autres petits détails évoluent également tels que l'ajout des quelques instructions atomiques manquantes en 64 bits (min/max et opérations logiques) et une réduction de 66% du surcoût lié à la mémoire ECC.
Au final, avec la génération Kepler, Nvidia a bien pris une direction différente de celle de la génération Fermi. Le gros GPU Fermi, le GF100/110, disposait d'une organisation interne différente de celle des autres GPU de la famille, de manière à augmenter la logique de contrôle au détriment de la densité des unités de calcul et du rendement énergétique.
Avec le GK110, Nvidia n'a pas voulu faire de compromis sur ce dernier point ou plutôt devrions nous dire "n'a pas pu". Il s'agit dorénavant de faire un maximum dans une enveloppe thermique qui n'est plus extensible. C'est la raison pour laquelle le GK110 reprend la même organisation interne que celle du GK104, en dehors de la capacité de calcul en double précision qui a été revue nettement à la hausse.
Ainsi, Nvidia n'a pas cherché à complexifier son architecture pour soutenir les performances en GPU computing et s'est attaché à essayer de faire un maximum avec les ressources disponibles en se contentant d'évolutions mineures mais qui peuvent avoir un impact énorme. C'est également la raison pour laquelle le processeur de commandes a été revu pour permettre de maximiser l'utilisation du GPU avec les technologies Hyper-Q et Dynamic Parallelism que nous avons décrites brièvement hier et sur lesquelles nous reviendront dès que possible avec quelques détails de plus.
GTC: VGX: la virtualisation sur GPU pour les pro
Avec les GPU de la famille Kepler, Nvidia a apporté plusieurs petites évolutions qui permettent de les virtualiser. Si les infrastructures de bureaux virtuels (VDI) commencent à gagner en popularité dans le monde de l'entreprise, elles souffrent actuellement de limitations importantes, le rendu des bureaux devant être traité par les CPU.
Pour permettre à ces VDI d'offrir une expérience de meilleure qualité, avec un bureau Windows accéléré, du multimédia voire un peu de 3D, Nvidia dévoile une nouvelle solution dénommée VGX qui permet d'ajouter des GPU virtualisés dans les serveurs.
VGX repose 3 composantes principales. Tout d'abord l'Hypervisor qui gère le partage des ressources GPU entre de nombreux utilisateurs et permet à une machine virtuelle de communiquer directement avec le ou les GPU.
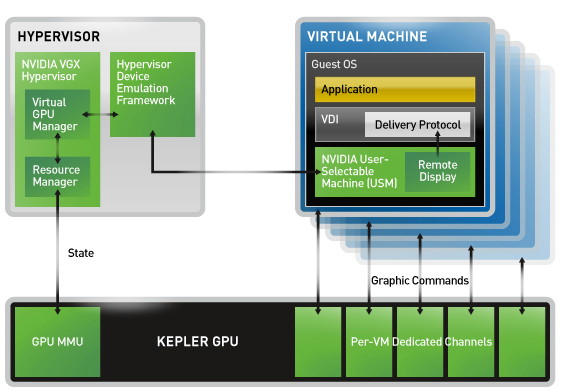
Ensuite nous retrouvons bien entendu le côté matériel avec un produit développé spécifiquement pour ce marché : la carte VGX. Elle embarque pas moins de 4 GPU, que nous supposons être des GK107 castrés avec seulement la moitié de leurs unités de calcul actives. Cela représente 192 unités de calcul par GPU pour un total de 768. Elles sont cadencées à 850 MHz ce qui donne une puissance de calcul totale de 1.3 Tflops. Ce n'est pas énorme mais la puissance de calcul n'est pas le but ici. Nvidia profite par contre des 4 processeurs de commandes de ces GPU, qui sont chacun capables de gérer 32 accès concurrents, avec quelques limitations en pratique. De quoi permettre à Nvidia d'annoncer la prise en charge de pas moins de 100 utilisateurs pour sa carte VGX.

Chaque GPU est accompagné de 4 Go de mémoire DDR3, soit 16 Go au total, et la carte se contente d'un TDP de 150W et d'une longueur de 27cm. C'est plutôt raisonnable au vu des caractéristiques et il est évident que l'efficacité énergétique de l'architecture Kepler permet à Nvidia d'attaquer plus facilement ces nouveaux marchés.
Enfin, la dernière composante se nomme USM pour User-Selectable Machines. Grossièrement il s'agit d'un système de licence qui permet d'activer certaines fonctionnalités qui sont disponibles dans les familles traditionnelles de produits professionnels Nvidia. VGX avec NVS USM permet de profiter des optimisations pour certaines applications business, de la suite multi-écran nView et de l'accélération des applications CUDA qui étrangement n'est pas activée sur la version basique. VGX avec Quadro USM active toutes les fonctionnalités logicielles réservées aux Quadro. Nvidia indique qu'il est possible d'offrir à chaque utilisateur un niveau de fonctionnalité spécifique mais ne donne aucune information sur le modèle commercial.
La solution VGX profite par ailleurs de NVENC, l'encodeur H.264 présent dans tous les GPU Kepler, ce qui a l'avantage de décharger les CPU de cette tâche mais également de réduire la latence, rendu et encodage étant traités directement par le GPU.
Nvidia indique travailler notamment avec Citrix pour intégrer VGX dans leur VDI et, en guise de démonstration, se reposait sur un cas pratique d'Industrial Light & Magic, qui a régulièrement besoin de rencontrer les réalisateurs pour parler des scènes en préparation et devait précédemment se contenter de quelques supports visuels fixes lors de ces réunions. Une solution telle que VGX leur permet de manipuler à distance et en temps réel les projets en cours, de quoi pouvoir répondre directement aux demandes d'un réalisateur, qui désirerait par exemple observer la scène sous un angle spécifique, ou avoir une idée de ce que donnerait une modification.
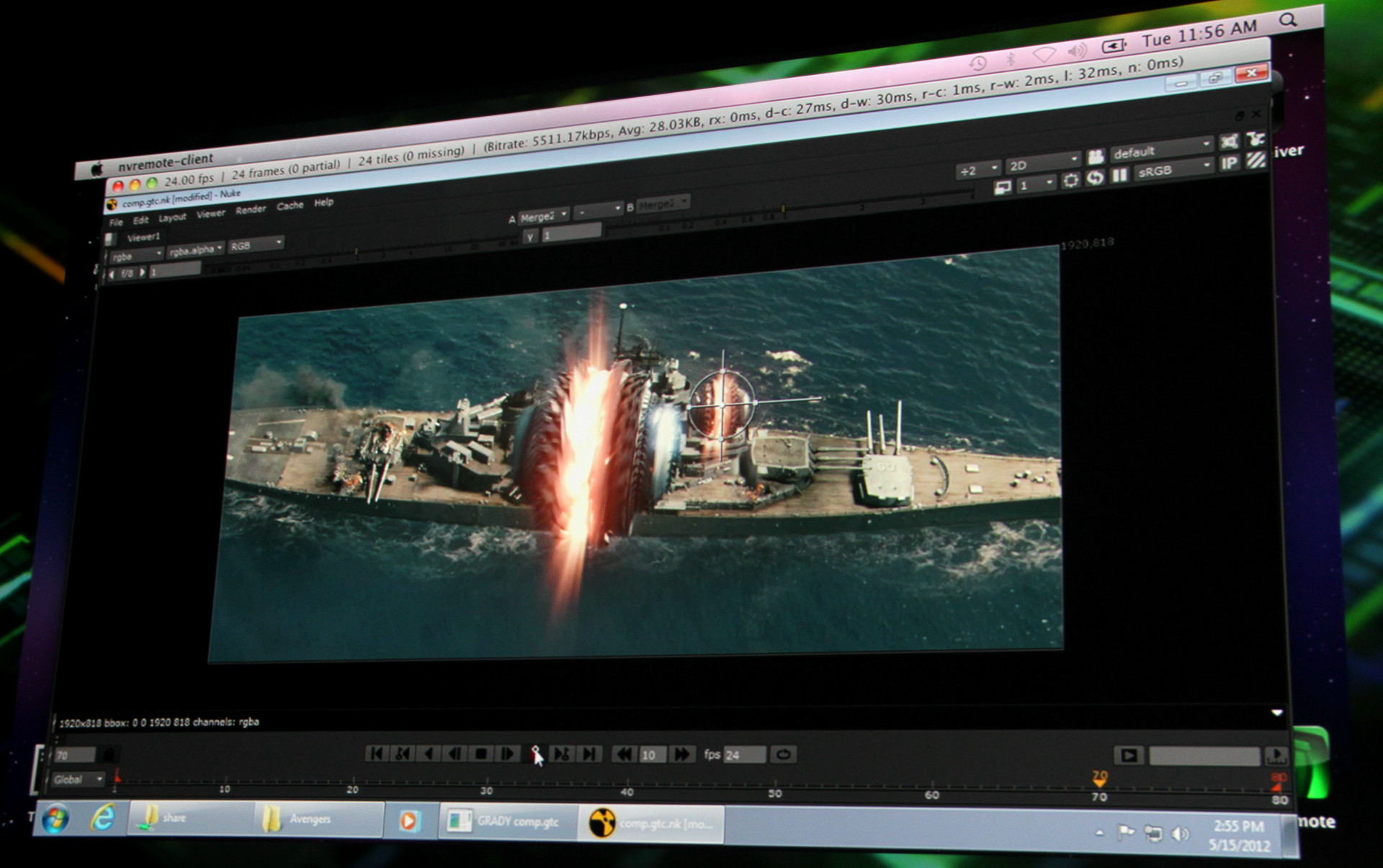
Depuis son MacBook Air, le responsable d'ILM peut modifier facilement une scène, le tout étant traité à distance sur les serveurs de la société. Dans cet exemple vous pouvez observer l'ajout d'un shredder dans une scène de destruction de Battleship.
GTC: Tesla passe à Kepler avec les K10 et K20

Nvidia vient de dévoiler deux nouvelles cartes Tesla basées sur l'architecture Kepler. La première, dénommée K10 est en quelque sorte une version Tesla serveur de la GeForce GTX 690. Il s'agit donc d'une carte équipée de 2 GPU GK104 et d'un switch PCI Express 3.0 PLX. Par rapport à la GeForce GTX 690, les fréquences ont bien entendu été revues à la baisse et passent d'une fourchette de 915 à plus de 1100 Mhz (suivant le niveau de turbo) à 745 MHz pour le GPU et de 1500 à 1250 MHz pour la mémoire.
Nvidia semble ainsi avoir laissé de côté GPU Boost, probablement parce que la variabilité qui y est liée n'est pas compatible avec le monde professionnel. La base de la technologie, qui permet de contrôler dynamiquement la fréquence pour maintenir un certain TDP est par contre de toute évidence de la partie, ce qui permet à Nvidia de proposer un TDP relativement faible qui tourne autour de 225-235W, contre 300W pour la GeForce GTX 690.
La K10 est équipée de 4 Go de mémoire GDDR5 par GPU, soit 8 Go au total, et supporte l'ECC, d'une manière similaire à ce qui se fait sur les précédentes cartes Tesla : une partie de la mémoire est utilisée pour stocker les données de parité, ce qui réduit l'espace mémoire disponible ainsi que la bande passante pratique. La puissance de calcul en double précision reste par contre extrêmement faible, tout comme certaines opérations logique ou sur les entiers, le GPU GK104 étant très limité à ce niveau. En d'autres termes, la carte K10 affiche une puissance de calcul en simple précision flottante énorme, de 4577 Gflops et sera donc destinée à ce type de calculs uniquement. En double précision le débit tombe à 190 Gflops.
La seconde carte Kepler annoncée aujourd'hui, la K20 est la plus intéressante des deux puisqu'elle embarquera un GPU GK110 au sujet duquel Nvidia vient de donner les premières informations. Peu de détails sur la K20 sont communiqués à ce jour, ses spécifications ne seront fixées que plus tard dans l'année puisqu'elle est prévue pour le dernier trimestre 2012. Il est cependant probable qu'elle soit équipée d'un GK110 partiellement castré avec 13 blocs d'unités de calcul actifs sur les 15 disponibles pour un total de 2496 de ces unités de calcul. Nvidia indique par ailleurs que ses performances en double précision seront triplées par rapport à la génération actuelle et supérieures à 1 Tflops, ce qui en fera une carte bien plus polyvalente pour le calcul, d'autant plus que son GPU apporte plusieurs innovations importantes pour faciliter son exploitation avec un maximum d'efficacité.

La carte K20 devrait être accompagnée de 6 Go de mémoire GDDR5 et sera disponible avec un TDP de 225W, ce qui est plutôt impressionnant compte tenu de la complexité de ce GPU. Il est probable que Nvidia profite du fait qu'en général les blocs du GPU dédiés au graphique ne seront pas utilisés pour pouvoir compresser le TDP. Nvidia nous précise cependant que si un intégrateur dispose d'une plateforme certifiée pour un TDP plus élevé, la carte K20 pourra s'y adapter pour profiter de la marge supplémentaire. Elle sera par ailleurs disponible en version workstation en plus de la version serveur.