
Les derniers contenus liés au tag OpenCL
AFDS: AMD dévoile la FSA pour OpenCL
AFDS: OpenCL gagne du terrain ?
AFDS: AMD Fusion 11 Developer Summit
Dossier: OpenCL : le GPU Computing enfin démocratisé ?
OpenCL: prochain standard GPGPU?
GDC: Khronos annonce OpenCL 2.1



Parallèlement à l'annonce de Vulkan, le groupe Khronos fait évoluer légèrement OpenCL avec l'annonce des spécifications provisoires de la version 2.1 de cette API dédiée au GPU computing. La principale nouveauté est l'ajout d'un nouveau langage pour les kernels : à côté d'OpenCL C prendra désormais place OpenCL C++.
Ce langage correspond à un subset de C++14, amputé de quelques fonctionnalités, et permettra de faciliter le travail des développeurs, en leur permettant d'ignorer certains détails de bas niveau, tout en gardant une efficacité suffisamment élevée.

Alors que compiler vers un langage intermédiaire, SPIR, était possible optionnellement depuis quelques temps avec OpenCL 2.0, le langage intermédiaire SPIR-V, partagé avec Vulkan, rentre dans les spécifications "core" d'OpenCL 2.1. OpenCL C++ est d'ailleurs prévu pour passer exclusivement par SPIR-V.
De petites fonctionnalités font également leur apparition ou rentrent dans les spécifications "core", c'est par exemple le cas des requêtes concernant les "subgroups", qui exposent l'organisation matérielle du threading (warps chez Nvidia, wavefronts chez AMD etc.) et permettent des optimisations plus fines.
A noter que si Intel et AMD louent les avantages d'OpenCL 2.1 dans la communication officielle, Nvidia reste aux abonnés absents et tient donc le cap sur sa stratégie qui consiste à se concentrer sur son écosystème propriétaire CUDA.







AMD FirePro W9100 : 2.6 Tflops DP, 16 Go
Alors qu'AMD a décidé de monter en puissance au niveau de sa gamme de cartes graphiques professionnelles FirePro, nous y attendions bien entendu l'arrivée d'une déclinaison à base de son dernier GPU Hawaii. C'est désormais chose faite avec la FirePro W9100.

La FirePro W9100 intègre comme prévu une version complète du GPU Hawaii, dont la totalité des unités de calcul sont actives. Par rapport à la Radeon R9 290X, seule la fréquence GPU est en légère baisse de manière à contenir à 275W alors que la mémoire embarquée passe à 16 Go de GDDR5, un nouveau record pour une carte de série.
AMD avait conservé secret un détail de son GPU Hawaii très important dans le monde professionnel : son débit de calcul en double précision. Précédemment, les Radeon haut de gamme profitaient du débit maximal dont était capable le GPU, par exemple 1/4 du débit simple précision pour le GPU Tahiti, pour la Radeon HD 7970 comme pour la FirePro W9000. Avec la Radeon R9 290X, AMD nous avait expliqué que le débit en double précision avait été artificiellement limité à 1/8ème.
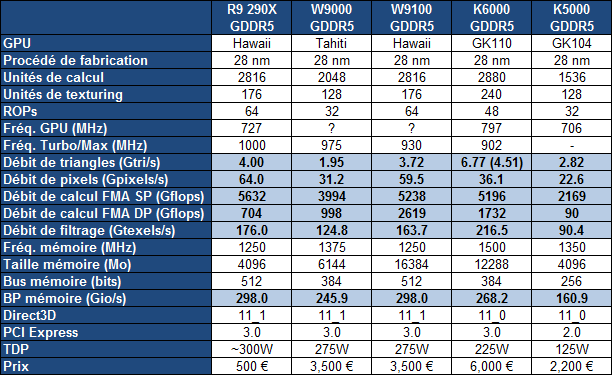
Nous apprenons aujourd'hui que son nouveau GPU est en fait capable d'un débit équivalent à la moitié de la simple précision, ce qui autorise un nouveau record en la matière : 2.6 Tflops en FMA 64-bit. Cette puissance de calcul associée à une prise en charge très performante des opérations logiques et sur les entiers permet à la FirePro W9100 de largement dominer la concurrence sur le plan du calcul massivement parallèle. Avec un framebuffer de 16 Go, elle pourra par ailleurs travailler sur de larges sets de données.
Au niveau logiciel, AMD met en avant un pilote OpenGL professionnel mais surtout le support d'OpenCL 1.2 et d'OpenCL 2.0, dès que celui-ci sera disponible. De son côté, Nvidia traîne des pieds face au support de ces API standardisées, préférant pousser une approche propriétaire avec CUDA. C'est ce qui permet aux Quadro de profiter d'un avantage exclusif dans les applications qui ont fait le choix de son API ou d'un module qui y fait appel tel que le moteur de rendu Iray.
Avec des équipes largement plus importantes, Nvidia essaye de proposer sur le marché professionnel des solutions de plus en plus complètes et spécifiques, maîtrisant le matériel, l'API et le middleware. De son côté, AMD doit se contenter de proposer un accélérateur le plus performant possible pour les applications qui reposent sur des technologies ouvertes et jouer sur le rapport prestation/prix.

Sur le papier la FirePro W9100 semble plutôt bien s'en tirer face à ses concurrentes qui sont les Quadro K5000 (2200) et K6000 (6000). Si AMD s'attaque à ces 2 cartes Nvidia, c'est parce que la position tarifaire de 3500 (3999$) de la FirePro W9100 la situe entre celles-ci. A noter cependant qu'AMD a tendance à annoncer des prix assez agressifs sur un marché où les revendeurs ont tendance à pousser de très grosses marges, il est donc probable qu'en pratique la FirePro W9100 se négocie plutôt à 4000 en Europe.
Rappelons qu'en Europe, AMD fait dorénavant confiance à Sapphire pour la distribution de sa gamme FirePro, tout comme Nvidia se repose sur PNY.
Nvidia rachète PGI, The Portland Group
Afin de renforcer sa position et sa crédibilité dans le monde du HPC, le calcul massivement parallèle, Nvidia vient de racheter The Portland Group (PGI) qui était jusqu'alors propriété de STMicroelectronics. Depuis 1989, PGI conçoit des outils et compilateurs C, C++ et Fortran dédiés aux supercalculateurs. C'est naturellement que la société avait sauté le pas vers le GPGPU notamment en travaillant en étroite collaboration avec Nvidia pour lequel il a développé la version Fortran de CUDA.
PGI s'est ensuite associé à CAPS, Cray et Nvidia pour développer le standard OpenACC, un langage de programmation de haut niveau qui permet d'exploiter les accélérateurs massivement parallèles relativement facilement à l'aide de directives. Présent sur toutes les architectures, PGI propose également un compilateur OpenCL optimisé pour les micro-serveurs à base de CPU multicores d'architecture ARM.
Une acquisition qui est donc logique pour Nvidia, que ce soit en vue de ce dernier point (le développement de son premier core ARM 64-bit est en cours de finalisation) ou pour le GPGPU en général. Tout comme c'était le cas à l'intérieur du groupe STMicroelectronics, PGI va rester une entité indépendante supervisée par Nvidia, tout du moins dans un premier temps. Reste bien entendu à voir si le support des architectures concurrentes restera maintenu dans le temps.

Jeff Herbst, NVIDIA VP of Business Development, Doug Miles, PGI Director et Ian Buck, NVIDIA General Manager of GPU Computing Software.
Dans l'immédiat, Nvidia va pouvoir profiter de synergies dans le développement de compilateurs destinés à l'architecture CUDA. Comme l'indique Ian Buck, General Manager of GPU Computing Software chez Nvidia (et accessoirement le développeur qui a écrit la première version de C pour CUDA), derrière le succès de tout processeur se cache l'équipe de développement des compilateurs. Avec PGI, nul doute que celle de Nvidia se retrouvera renforcée.
Adobe Creative Suite 6 passe à l'OpenCL
Deux billets de blogs d'AMD (ici et là ) nous annoncent que la Creative Suite en version 6 d'Adobe, annoncée officiellement lundi , proposera pour la première fois une utilisation d'OpenCL dans certains de ses logiciels, ainsi qu'une utilisation accrue d'OpenGL (déjà utilisable précédemment pour le moteur de rendu de Photoshop par exemple).
Le premier blog cite deux exemples sous Photoshop (parmi un "fantastique nombre" non précisé) d'accélérations. Tout d'abord une nouvelle galerie d'effets de flous dont le calcul est accélérée par OpenCL. Côté performances, AMD indique que l'activation de l'OpenCL sur un APU A8-3530MX (processeur mobile quatre curs cadencé à 1.9 GHz) permet de réduire le temps de rendu de 394 à 51 secondes. Le second exemple cité sous Photoshop CS6 concerne l'effet "Liquify" qui profite lui du mode de rendu OpenGL. Sur la même plateforme qu'évoquée précédemment le temps de rendu passe de 86.6 à 15.6 secondes.
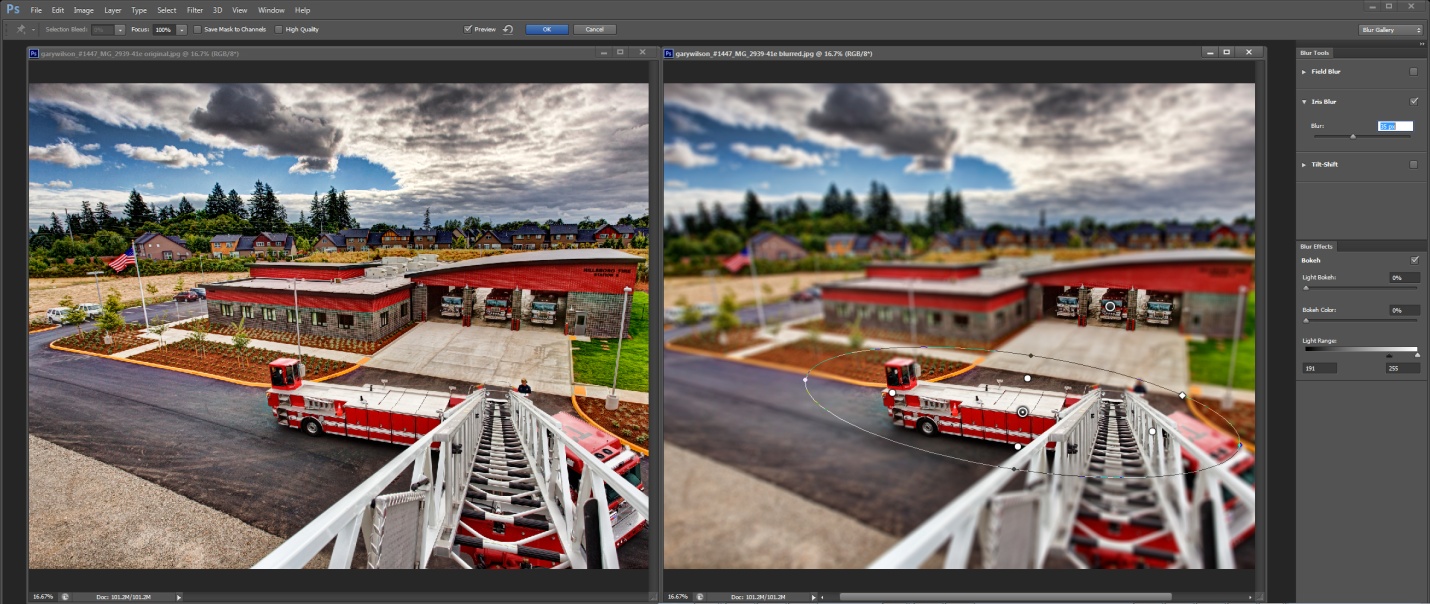
Le second blog cite un cas un peu particulier d'accélération OpenCL sous Premiere. Cependant en y regardant de plus près, l'exemple cible spécifiquement la version Mac de Premiere et plus précisément l'export H.264 dont le temps de rendu sur un MacBook Pro 15" passerait de 3 minutes 39 secondes à une minute et 4 secondes en mode OpenCL via la Radeon HD 6750M intégrée à la machine. On rappellera qu'Adobe proposait déjà sous Windows une accélération GPU CUDA de son moteur de rendu Mercury Engine , mais qui ne touchait pas l'encodeur H.264 présent dans le logiciel. Le billet d'AMD laisse penser qu'il s'agit de l'accélération du moteur de rendu, et non de l'encodage lui-même, qui propose l'accélération OpenCL. Il sera bon de voir si cette fonctionnalité sera également portée sur la version PC et si elle fonctionnera sur les autres GPU.
Un point que l'on pourra vérifier d'ici 30 jours, délai de disponibilité effectif annoncé pour CS6, tout comme l'étendu réelle de l'utilisation d'OpenCL. Le modèle de développement itératif de Photoshop et des autres outils Adobe fait qu'assez souvent, les nouveautés technologiques (jeux d'instructions particuliers comme Altivec ou SSE, support du multi-core, etc) ont souvent été implémentées de manière isolée dans certains filtres ou certaines fonctionnalités.
MAJ : Adobe à indiqué sur son forum que le support OpenCL sous Premiere serait bel et bien limité à la plateforme Mac (merci a fir3ball12).
Nvidia, PGI et Cray dévoilent OpenACC
Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
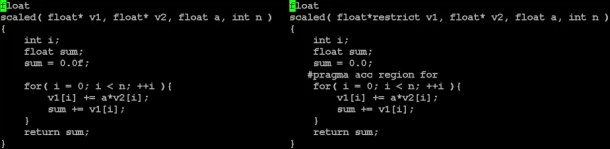
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .