
La GDC 2016 de San Francisco avec Hardware.fr

La GDC de San Francisco, Game Developers Conference, est le plus gros événement annuel dédié à l'univers du développement des jeux vidéo. Fabricants de processeurs graphiques ou de périphériques divers, fournisseurs d'API ou de middlewares et spécialistes de l'aspect business du jeu vidéo s'y retrouvent pour présenter leurs solutions.
Comme les années précédentes, nous avons fait le déplacement pour y suivre principalement les développements au niveau des API graphiques et du matériel PC.
GDC: Vers de nouveaux types de shaders ?
GDC: Async Compute : ce qu'en dit Nvidia
GDC: Async Compute et AotS : des détails
GDC: Futuremark en dit plus sur VRMark
GDC: Basemark et Crytek annoncent VRScore
GDC: Vulkan trop compliqué ? Imagination a une solution
GDC: Imagination: encore plus de ray tracing
GDC: D3D12, multi-GPU et frame pipelining
GDC: VR: Nvidia Multi-Res Shading en pratique
GDC: Zotac MAGNUS EN980 avec GTX 980 et watercooling
GDC: Vulkan trop compliqué ? Imagination a une solution



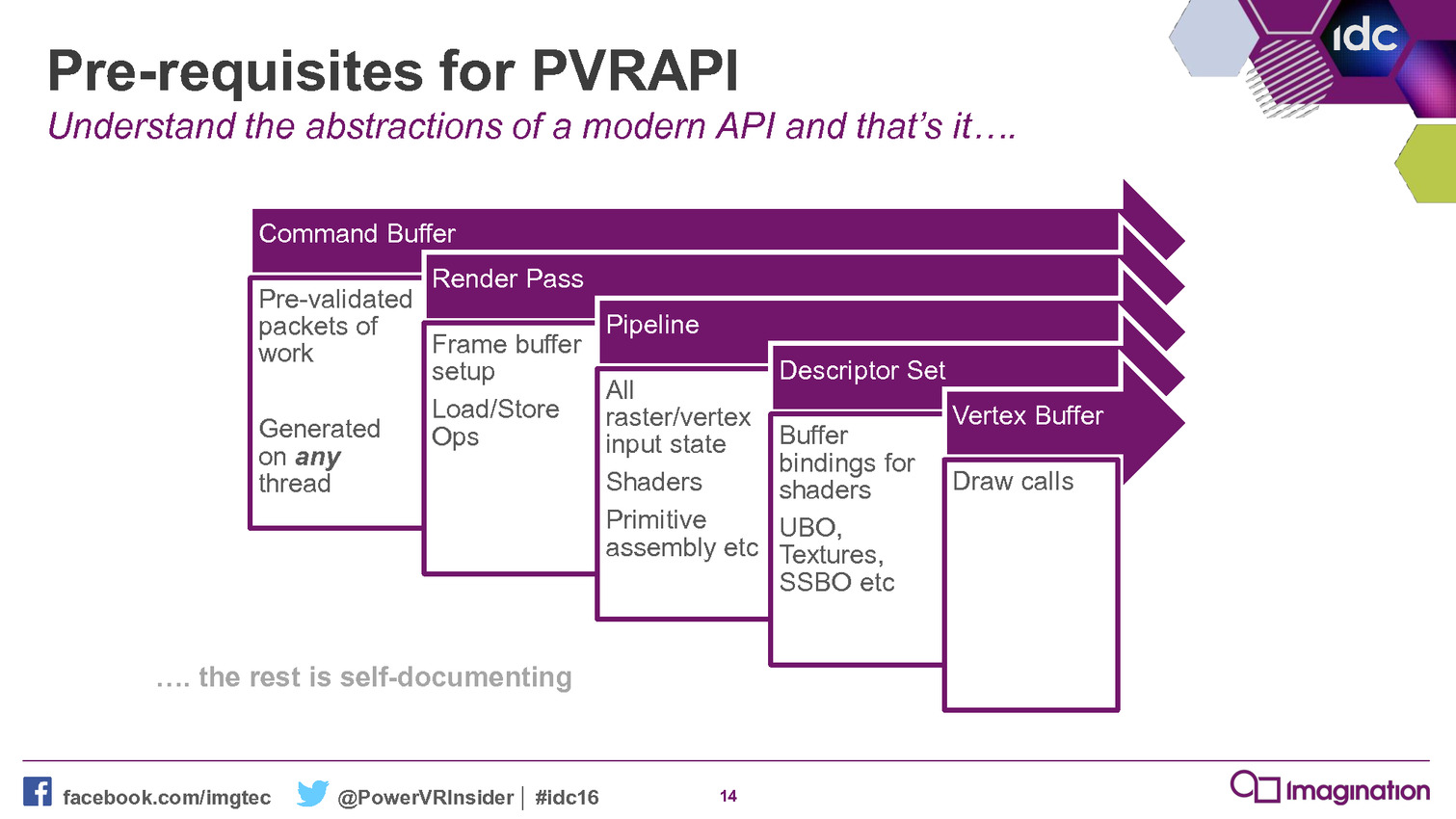
Maîtriser les API de plus bas niveau telles que Direct3D 12 et Vulkan représente un challenge pour les développeurs, celles-ci ajoutant à leur travail un niveau de complexité supplémentaire. Mais à travers son nouveau framework, Imagination va essayer de leur simplifier la tâche.

A l'occasion de la GDC 2016, Imagination a rendu disponible la version 4.1 de son SDK et à l'intérieur de celui-ci un nouvel outil a fait son apparition : le PowerVR Framework. Il représente une couche intermédiaire entre un moteur graphique et une API moderne.
Le niveau de complexité des API de plus bas niveau, que ce soit Direct3D 12 ou Vulkan, va amplifier le besoin de middlewares et de moteurs de jeu prêts à l'emploi. Mais il y a malgré tout encore pas mal de développeurs qui préfèrent mettre en place leur propre solution et pourraient profiter d'un accès simplifié aux nouvelles API. C'est en partant de ce constat qu'Imagination a développé le PowerVR Framework.

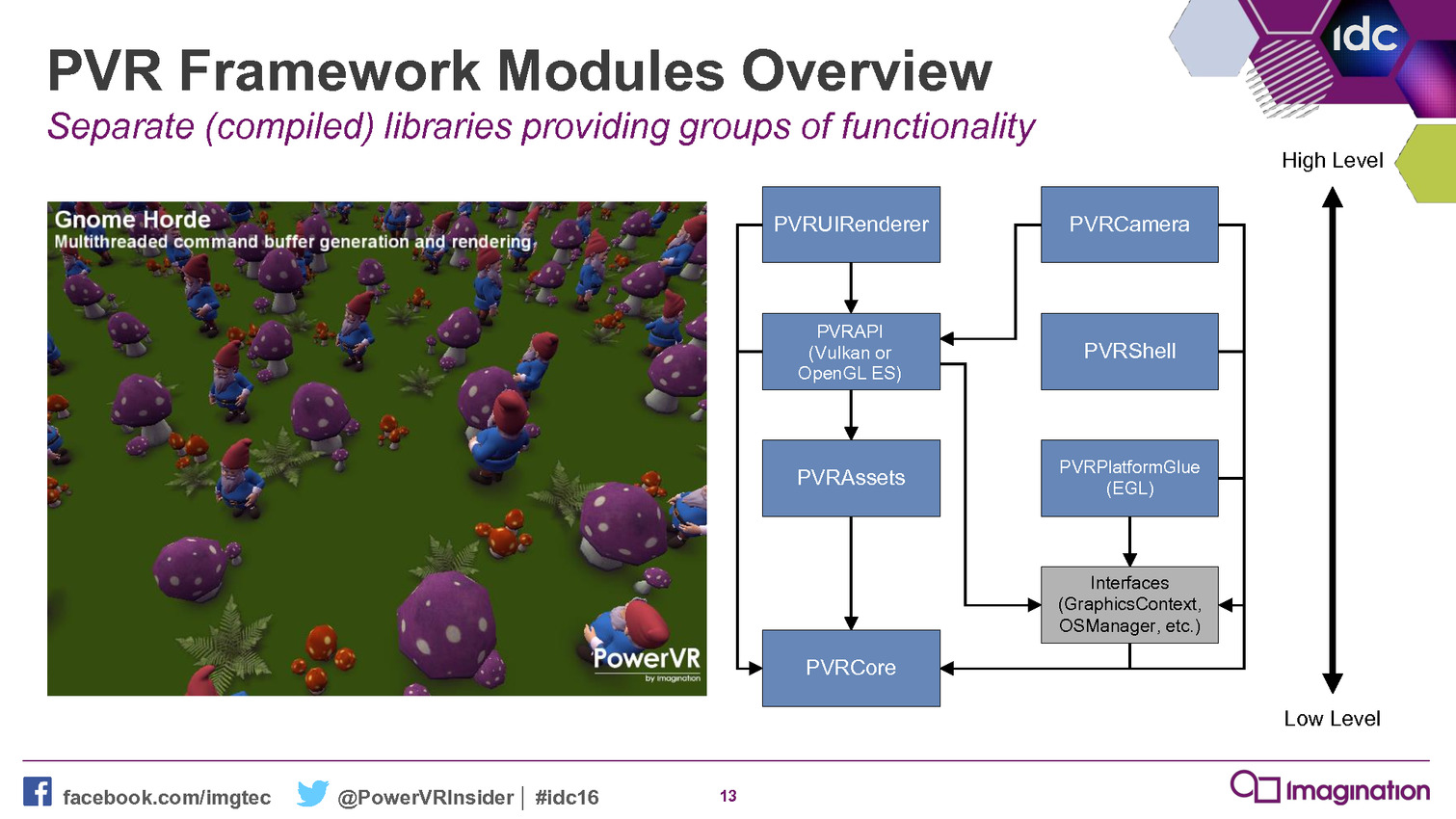
Le but est simple : aider les développeurs. Pour cela, ce framework est basé sur un ensemble de bibliothèques statiques qui vont permettre de simplifier les tâches courantes telles que la création des objets, les transferts de données, la gestion du multi-threading etc. Il représente une réintroduction d'un certain niveau d'abstraction là où il n'impacte pas la flexibilité et les performances.

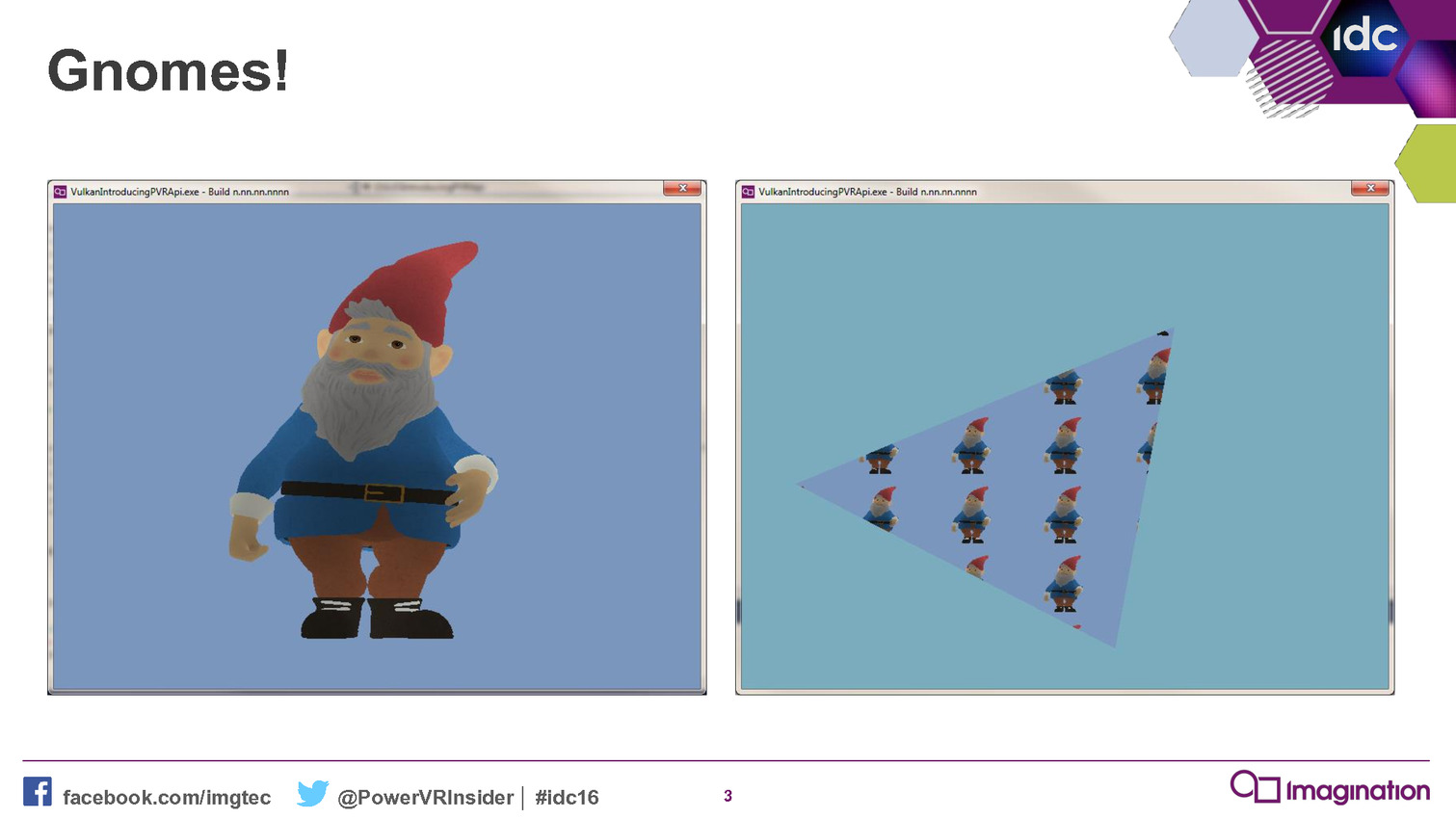
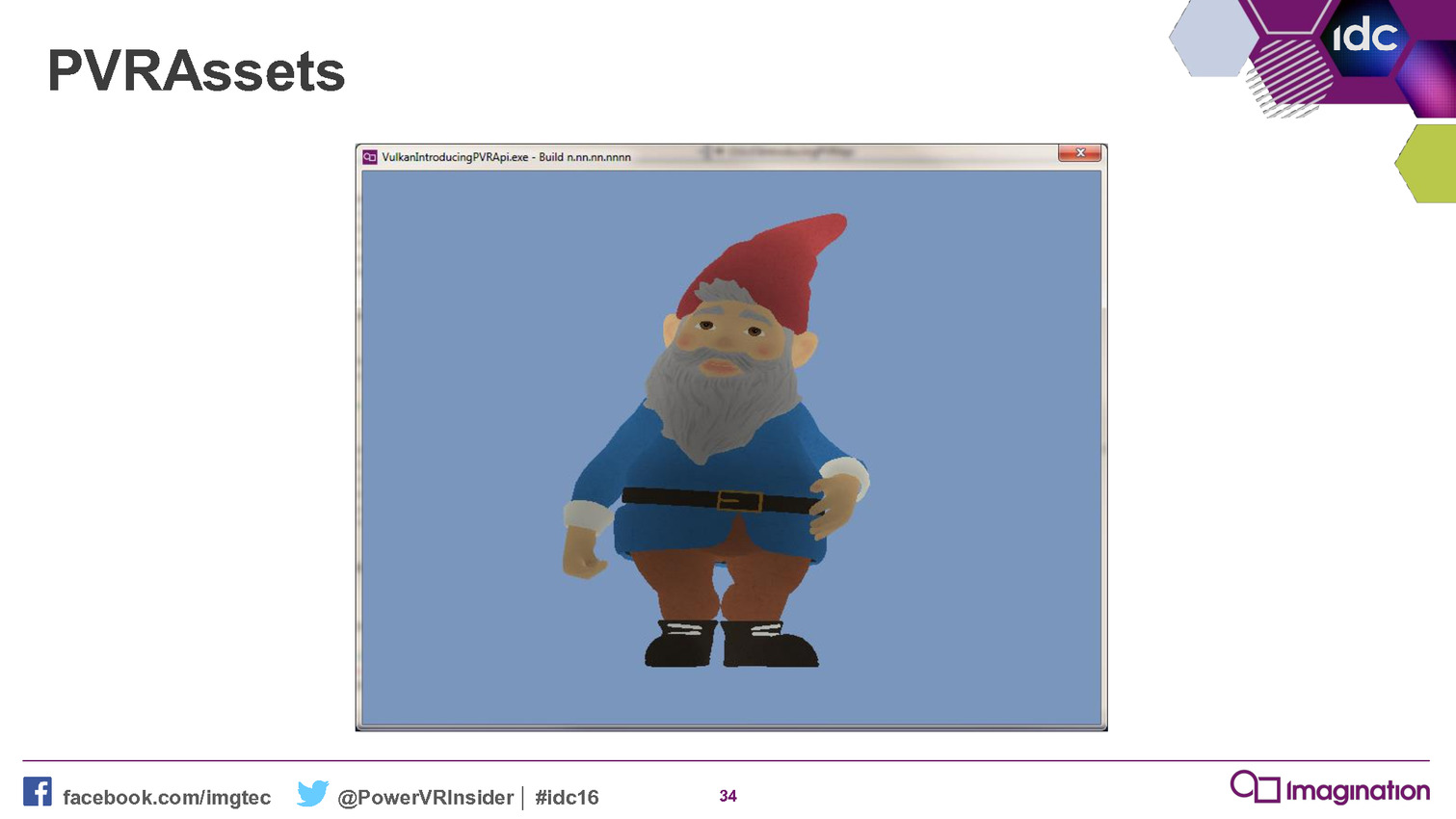
A titre d'exemple, Imagination nous explique que sa démonstration Gnome comprenait à l'origine plusieurs milliers de lignes de code qui ont pu être résumées en centaines de lignes en les réécrivant contre ce nouveau framework. De quoi rendre le code plus abordable et plus facile à maintenir, deux arguments qui ne devraient pas laisser les développeurs indifférents.
Ce framework permet également de supporter plus facilement différentes API et différents types de plateformes. Il peut ainsi viser autant OpenGL ES que Vulkan. Par ailleurs, en plus d'un back-end pour les GPU PowerVR, il en propose actuellement deux autres pour les GPU AMD et Nvidia. Suivant les retours des développeurs, Imagination n'est pas contre l'ajout de back-ends supplémentaires pour les GPU Qualcomm et ARM. L'objectif principal étant que les développeurs exploitent cet outil qui permet de tirer plus aisément le meilleur de ses GPU.
Il n'est par contre pas prévu de l'étendre pour supporter Direct3D 12, les GPU PowerVR n'ayant actuellement pas de présence sur la plateforme Windows. Mais compte tenu des difficultés rencontrées par les développeurs, Imagination s'attend à ce que quelqu'un d'autre propose un outil similaire, peut-être directement Microsoft.
Mise à jour de 19h30: Nvidia nous indique avoir sorti discrètement le mois passé un outil qui a des objectifs similaires : l'API open source Vulkan C++ . Il s'agit également d'une couche intermédiaire qui permet de passer l'API Vulkan C classique vers une approche de type C++ plus simple à manipuler.
Vous pourrez retrouver l'intégralité de la présentation d'Imagination ci-dessous :




























GDC: Imagination: encore plus de ray tracing
Comme nous l'expliquions à l'occasion du CES, Imagination mise beaucoup sur sa technologie d'accélération matérielle du ray tracing et a fait fabriquer son propre GPU, le PowerVR GR6500 pour la mettre en avant. A la GDC, de nouvelles démonstrations étaient présentées.
La première démonstration proposée par Imagination met en avant ce que pourrait apporter un tel GPU dans le monde mobile. Rappelons que le PowerVR GR6500, nom de code Wizard, est un petit GPU de catégorie mobile (4 clusters) mais équipé des modules optionnels dédiés au ray tracing capables de lancer jusqu'à 300 millions de rayons par seconde à 600 MHz.
A travers un rendu hybride, basé sur la rastérisation mais avec quelques touches de ray tracing, il est possible d'améliorer la qualité de certains aspects du rendu avec un coût annoncé comme nettement plus faible que via les méthodes traditionnelles qui sont inadaptées pour de petits GPU. C'est le cas des ombres douces et des réflexions spéculaires illustrées dans cette vidéo :
Imagination explique qu'il est relativement aisé d'implémenter de tels effets accélérés par sa technologie de ray tracing via ses extensions OpenGL ES. Pour aller plus loin et montrer tout l'étendue des possibilités, la seconde démonstration est basée intégralement sur un rendu à base de ray tracing :
Pour faire tourner une telle scène en temps réel, qui représente plus de 2 milliards de lancés de rayons par seconde, plus de puissance est bien entendu nécessaire et Imagination exploite plusieurs GR6500 en parallèle. Dans sa vision, ce type de complexité de rendu est ce que pourrait permettre un éventuel GPU PowerVR de classe "desktop", 8 à 16x plus performant qu'un GR6500 (32 clusters et plus haute fréquence).
Avec cette technologie, Imagination est actuellement ouvert à toutes sortes d'options et ne s'en cache pas. Mais si la porte n'est pas fermée à un GPU de type desktop, c'est avant tout une console de premier plan qui est visée. Mais est-ce bien réaliste ?
Nous avons posé la question à l'actuel fournisseur des consoles de Microsoft, Nintendo et Sony. Cette possibilité est rapidement balayée du revers de la main, probablement avec un brin d'arrogance, par AMD qui compte bien conserver ce marché et ne surtout pas laisser penser à ses investisseurs qu'il pourrait en être autrement.
Imagination admet de son côté que ce n'est pas simple de trouver sa place dans une console mais estime avoir de solides arguments. Et surtout être également ouvert à la possibilité de ne pas fournir un GPU complet mais uniquement sa technologie de ray tracing. Celle-ci pourrait alors être greffée à un autre GPU. Une implémentation qui n'est pas triviale et qui demanderait probablement une longue année de collaboration si un fabricant de console imposait ce choix. Mais c'est une option qui semble être envisagée sérieusement.

La carte PCI Express équipée du GR6500.
En attendant, Imagination indique avoir été surpris par la forte demande de la part des développeurs pour son kit de développement et sa carte PCI Express équipée du GR6500. Elle est actuellement en rupture mais une production supplémentaire qui se compterait cette fois en milliers de cartes vient d'être décidée. Gagner le support d'un maximum de développeurs est un premier pas important.
GDC: D3D12, multi-GPU et frame pipelining
Lors de la journée de la GDC consacrée aux tutoriaux liés à DirectX 12, organisée par AMD et Nvidia, c'est ce dernier qui s'est chargé de présenter la partie multi-GPU et de distiller des conseils d'utilisation réalistes pour le nouveau mode explicite. Les combinaisons exotiques laissées de côté, c'est le frame pipelining sur base d'une configuration de GPU identiques qui est mis en avant.
L'an passé, Microsoft a annoncé avoir intégré à DirectX 12 un support explicite très flexible pour le multi-GPU. Pour rappel, la nouvelle API conserve tout d'abord un mode implicite, similaire au SLI et CrossFire sous DirectX 11. Avec ce mode les pilotes sont censés se charger en toute transparence de donner vie au multi-GPU via le mode AFR.
Mais comme l'explique Nvidia, entre la théorie et la pratique il y a un gouffre et dans de plus en plus de cas le multi-GPU ne fonctionne pas, ou avec de très faibles performances, notamment quand des techniques de rendu dites "temporelles" sont exploitées. Celles-ci englobent toute approche qui a besoin de données issues d'images précédentes pour en calculer une nouvelle, par exemple certains filtres d'antialiasing. Vu que ces images précédentes ont été calculées par un autre GPU, ces données ne sont pas facilement accessibles.
Pour résoudre ce type de problème, et bien d'autres, DirectX 12 supporte une gestion explicite du multi-GPU. Cette fois il ne fonctionne plus automatiquement et il revient aux développeurs de prévoir leur moteur pour qu'il prenne conscience du nombre de GPU et les contrôle explicitement. Plusieurs possibilités existent alors.
Celle qui a fait le plus parler d'elle est le mode explicite non-lié (unlinked) qui permet d'associer tout type de GPU, de marques différentes, de génération différente et de niveau de performances différent. C'est le mode qu'a choisi d'implémenter Oxide dans Ashes of the Singularity, probablement pour pousser le plus loin possible ses expérimentations avec la nouvelle API, mais ce n'est pas celui qui va intéresser la majorité des développeurs, celui-ci impliquant la prise en compte de trop nombreuses combinaisons. Le multi-GPU est une niche du marché PC, ce qui implique que ce n'est pas sur ce point que les développeurs veulent investir le plus de temps en implémentation et en validation.

Reste alors le mode explicite à noeud lié (linked node), un noeud représentant un ensemble de GPU activé au niveau des pilotes. Autant AMD que Nvidia exposent un tel noeud dès que le CrossFire ou le SLI sont enclenchés dans leurs panneaux de contrôle. Attention, cela ne veut pas dire que le multi-GPU fonctionnera automatiquement ! Tout le contrôle reste dans les mains des développeurs mais ils ont alors l'assurance d'avoir affaire à des GPU identiques ou similaires, ce qui simplifie leur travail. Tout du moins pour le moment puisqu'il n'est pas impensable qu'AMD et Nvidia autorisent des noeuds hétérogènes dans le futur.
Ce mode explicite lié donne également accès à un lien dédié éventuel, soit au point SLI dans le cas des GPU Nvidia, AMD ayant abandonné le lien CrossFire au profit exclusif du PCI Express. Cet accès spécial n'est cependant exploité que si le multi-GPU implémenté est de type AFR. Le reste des transferts se fait via le bus PCI Express mais directement de GPU à GPU.
Les développeurs pilotent le multi-GPU à travers le multi engine, cette même fonctionnalité présente au coeur de DirectX 12 et qui permet de booster les performances à travers l'exécution concomitante de files de commandes (Async Compute). Il suffit de dédoubler la ou les files de commandes pour alimenter deux GPU.

D'ailleurs, pour maximiser les performances, il est important d'avoir recours à une file dédiée de type copy pour organiser les transferts entre GPU. De quoi effectuer ces opérations en parallèle du rendu 3D et en masquer le coût. Si les GPU Nvidia ont du mal avec les files graphics et compute, ils n'ont par contre pas de problème pour traiter simultanément des files graphics et copy, tout du moins dans le cas des GPU Maxwell 2 qui disposent de deux moteurs de transferts DMA. A ce point, nous ne savons pas si les GPU précédents qui s'en contentent d'un seul pourraient être affectés.

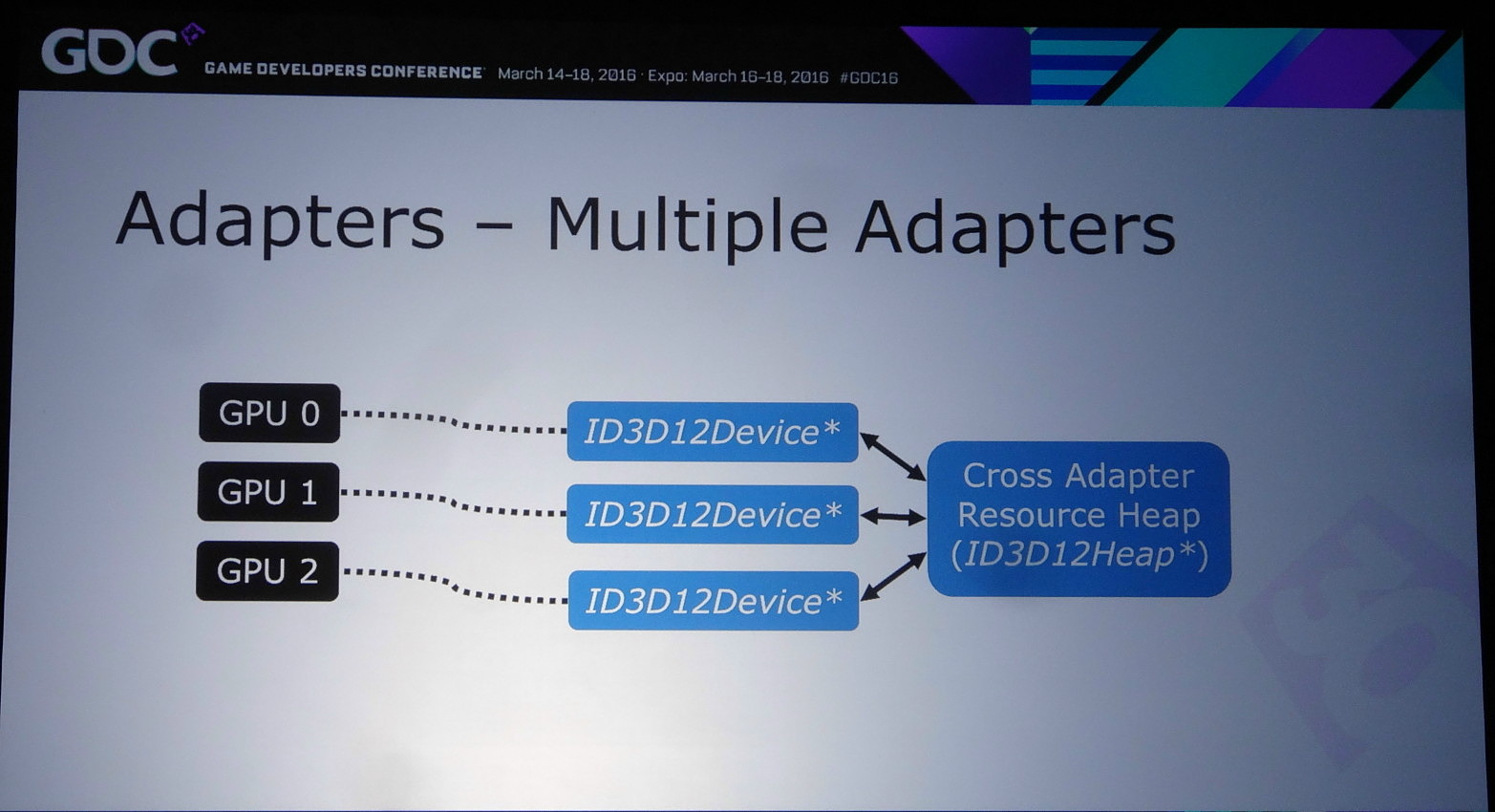
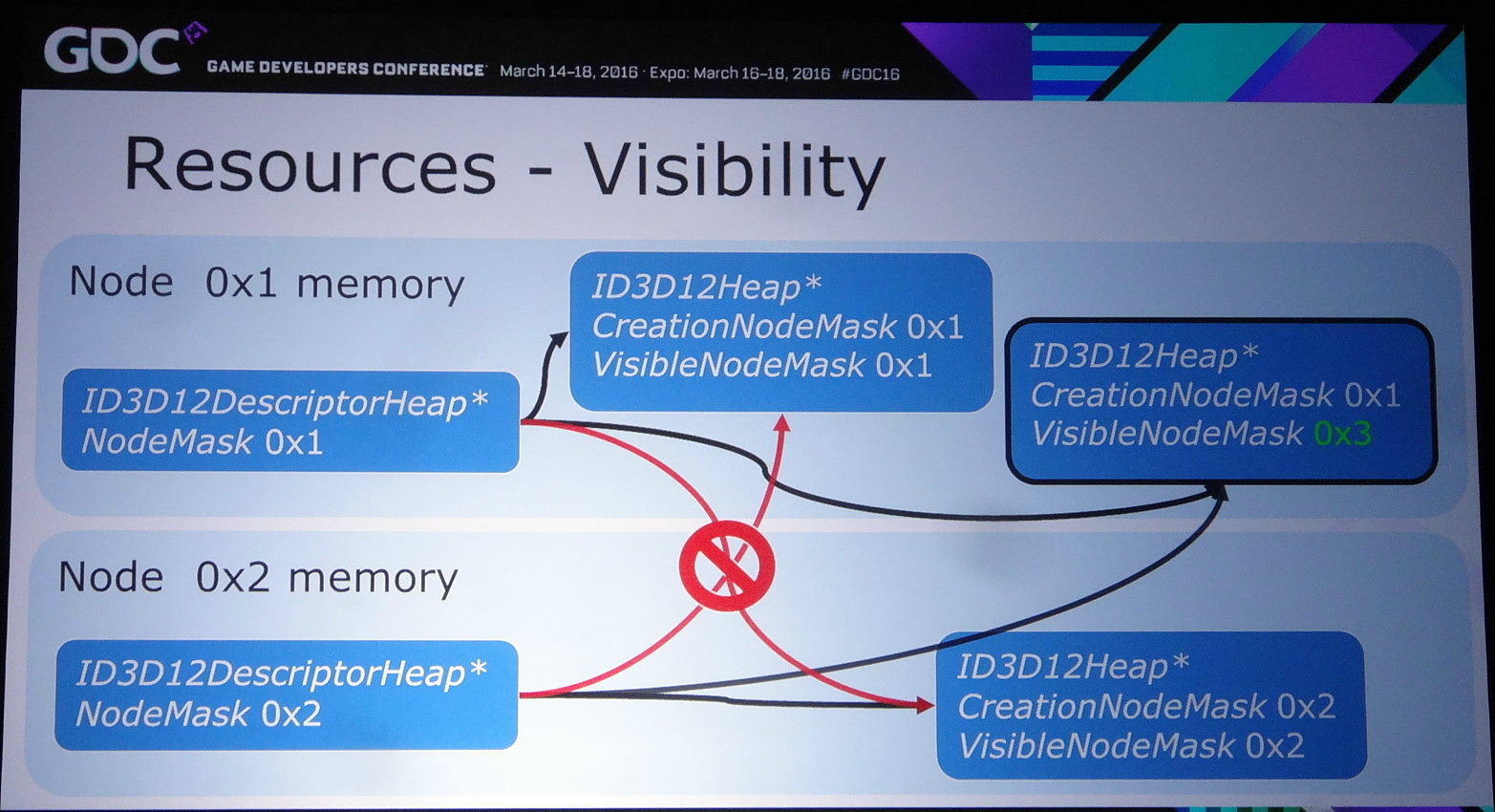
Nvidia rappelle ensuite qu'il existe différents tiers pour le partage de ressources à l'intérieur d'un noeud. Ce niveau de support est exposé à travers D3D12_CROSS_NODE_SHARING_TIER. Deux niveaux sont possibles : le tiers 1 ne supporte que les copies entre GPU alors que le tiers 2 autorise les accès à certaines ressources présentes dans la mémoire d'un autre GPU. Un dernier mode, le tiers 1 émulé est également proposé et consiste à implémenter dans les pilotes un mécanisme de transfert lorsque la copie directe de GPU à GPU n'est pas supportée.
Nous avons vérifié rapidement quel était le niveau de support proposé par AMD et Nvidia. Sur les GeForce Maxwell 2 il est de type tiers 2 alors qu'AMD se contente du tiers 1 sur GCN 1.1 et 1.2 (Hawaii et Fiji). Nvidia précise cependant que si les accès autorisés par le tiers 2 peuvent sembler pratiques, dans bien des cas il sera plus efficace d'effectuer une copie complète et de se contenter des fonctions du tiers 1.
Si exploiter le mode explicite lié peut permettre de faire de l'AFR (alternate frame rendering) avec un peu plus de flexibilité qu'en mode implicite, son intérêt réside surtout dans la possibilité d'implémenter d'autres modes de rendu, notamment pour résoudre les problèmes liés aux techniques qui font appel à une composante temporelle.
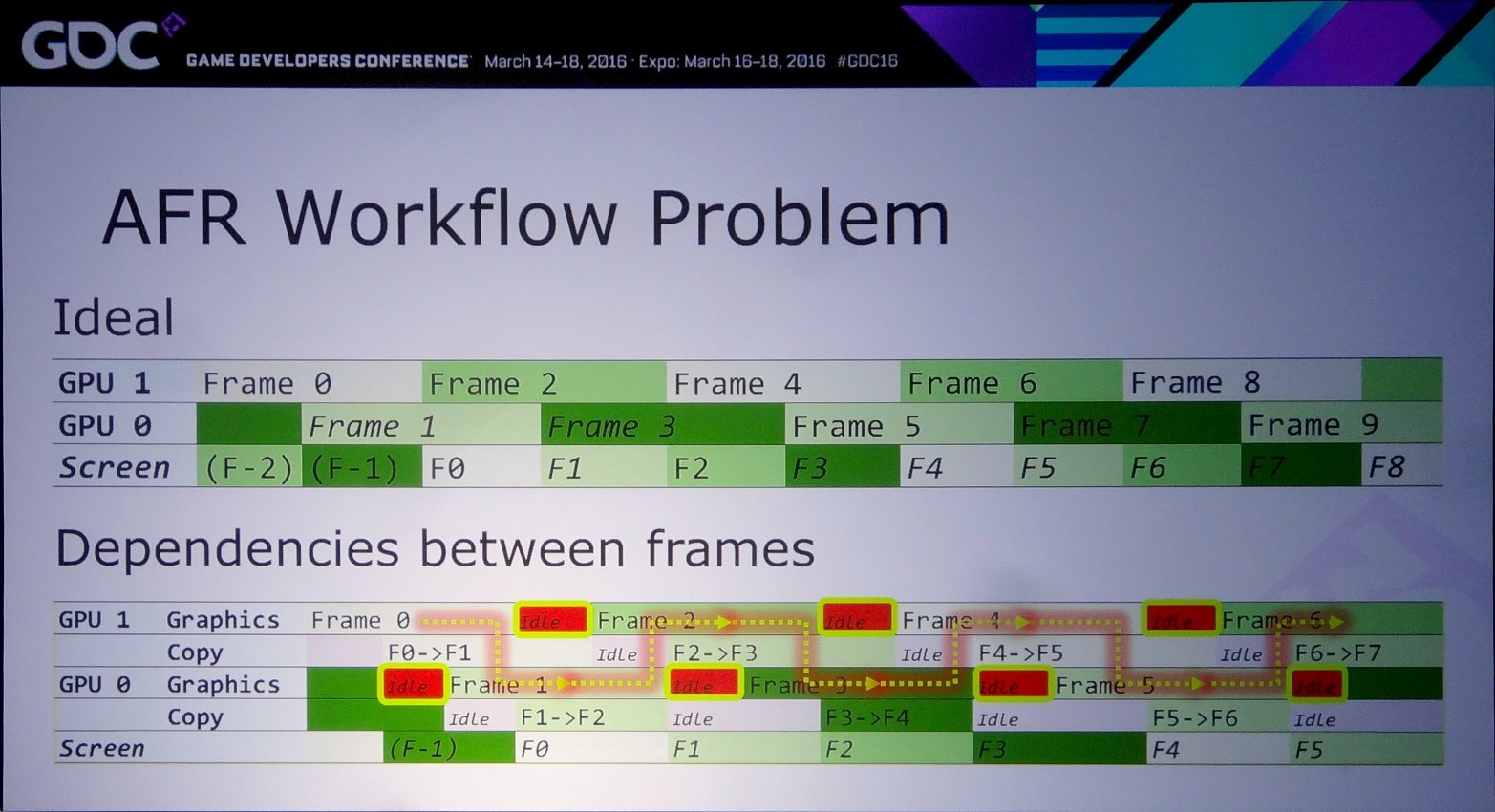

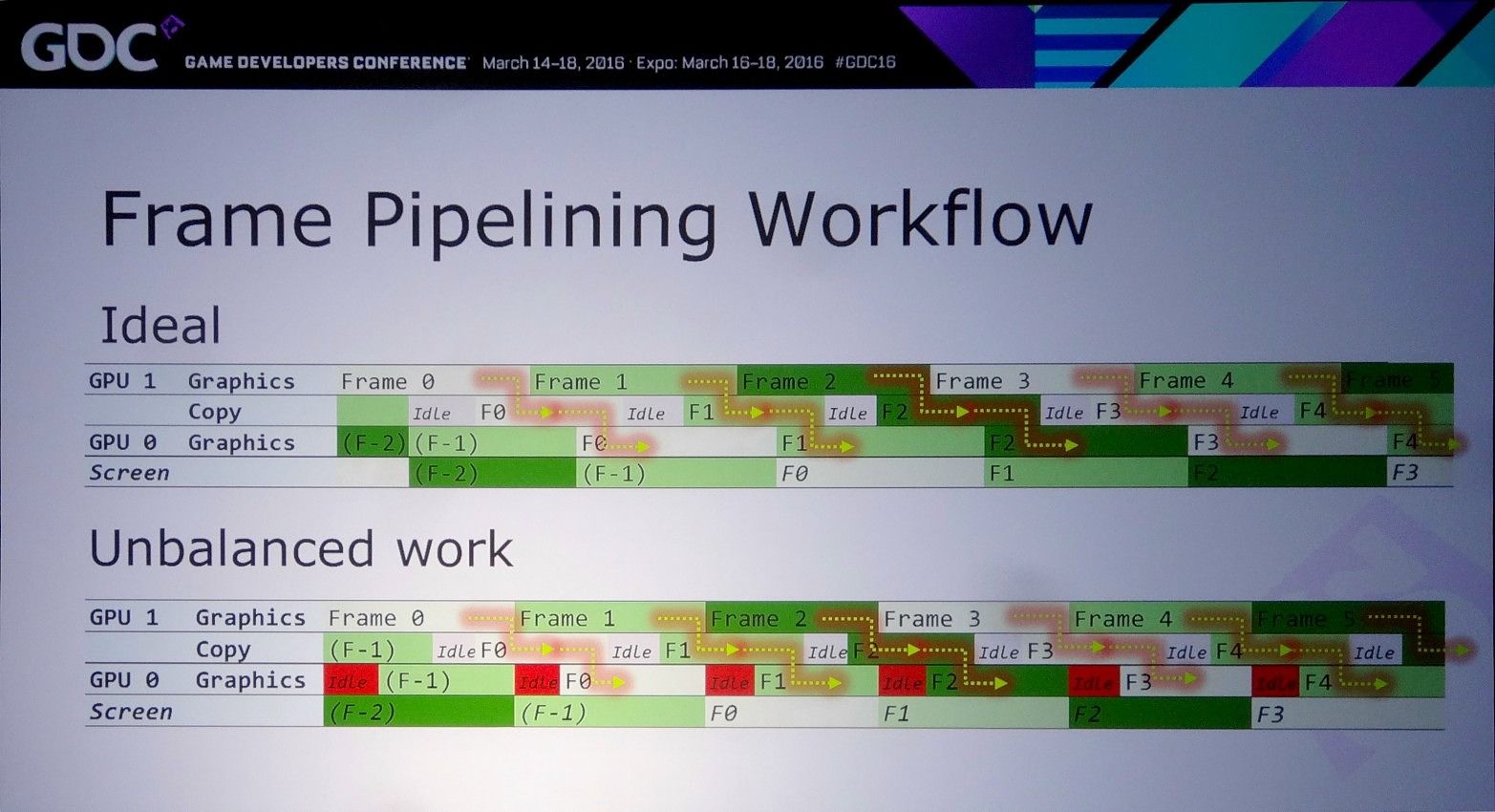
La solution à ces problème est appelée frame pipelining par Nvidia. Elle consiste à débuter le rendu d'une image sur un GPU et à transférer ces premiers éléments au second GPU en vue de la finalisation du rendu. Les GPU et leurs moteurs de copies travaillent alors à la chaine, d'où le nom de cette approche. Il est alors possible de prendre en charge sans problème un antialiasing temporel par exemple.
Pour mettre en place le frame pipelining, il faut parvenir à scinder son rendu en deux phases qui représentent une charge à peu près similaire et à un niveau qui permette de limiter les données à transférer. Il ne faut en effet pas oublier qu'un transfert de 64 Mo à travers un bus PCIe 3.0 8x prend au moins 8 ms, en général un peu plus en pratique. Pour éviter de transférer trop de données il peut alors être censé de dédoubler sur chaque GPU le calcul de certains éléments.
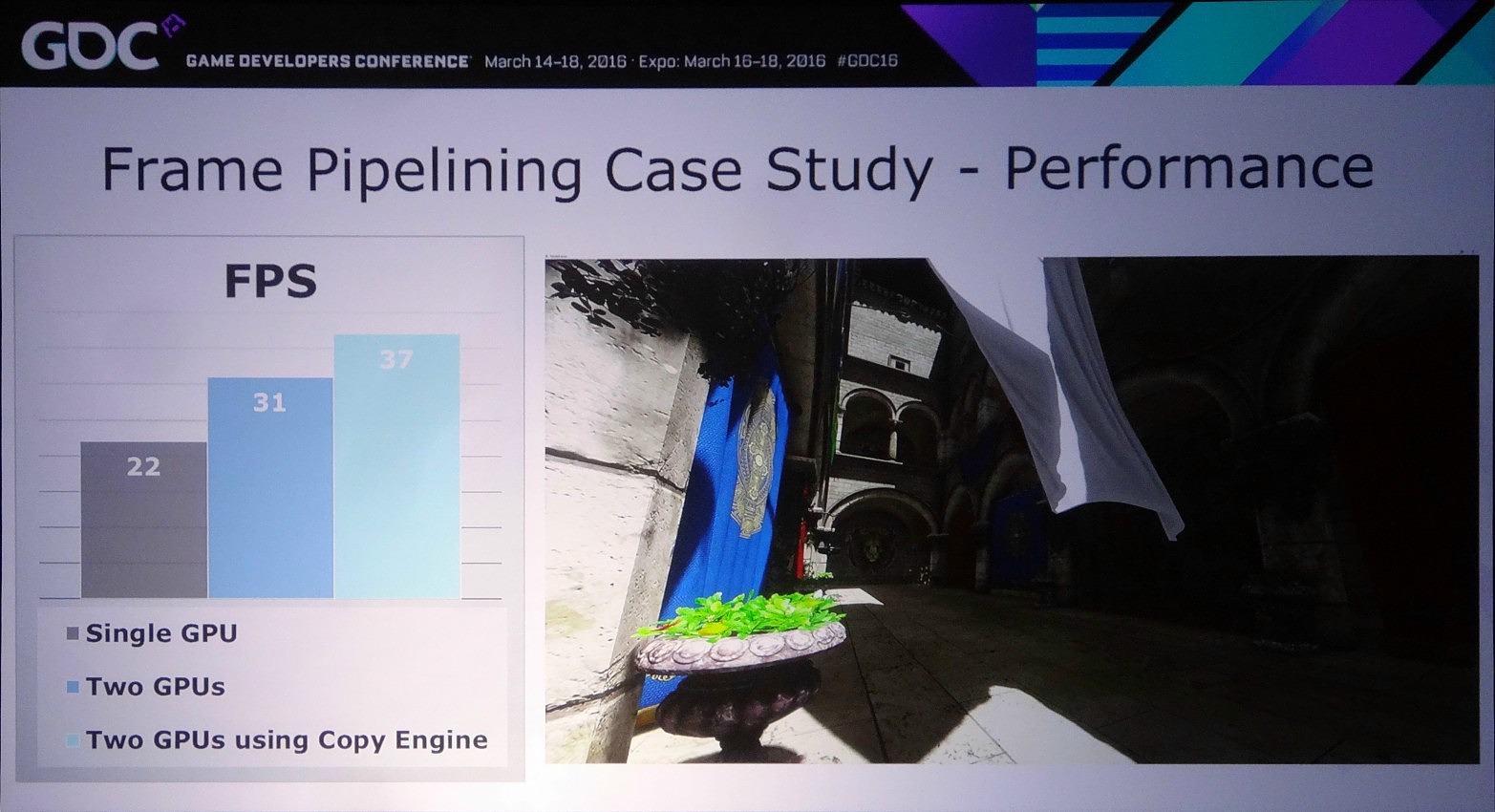

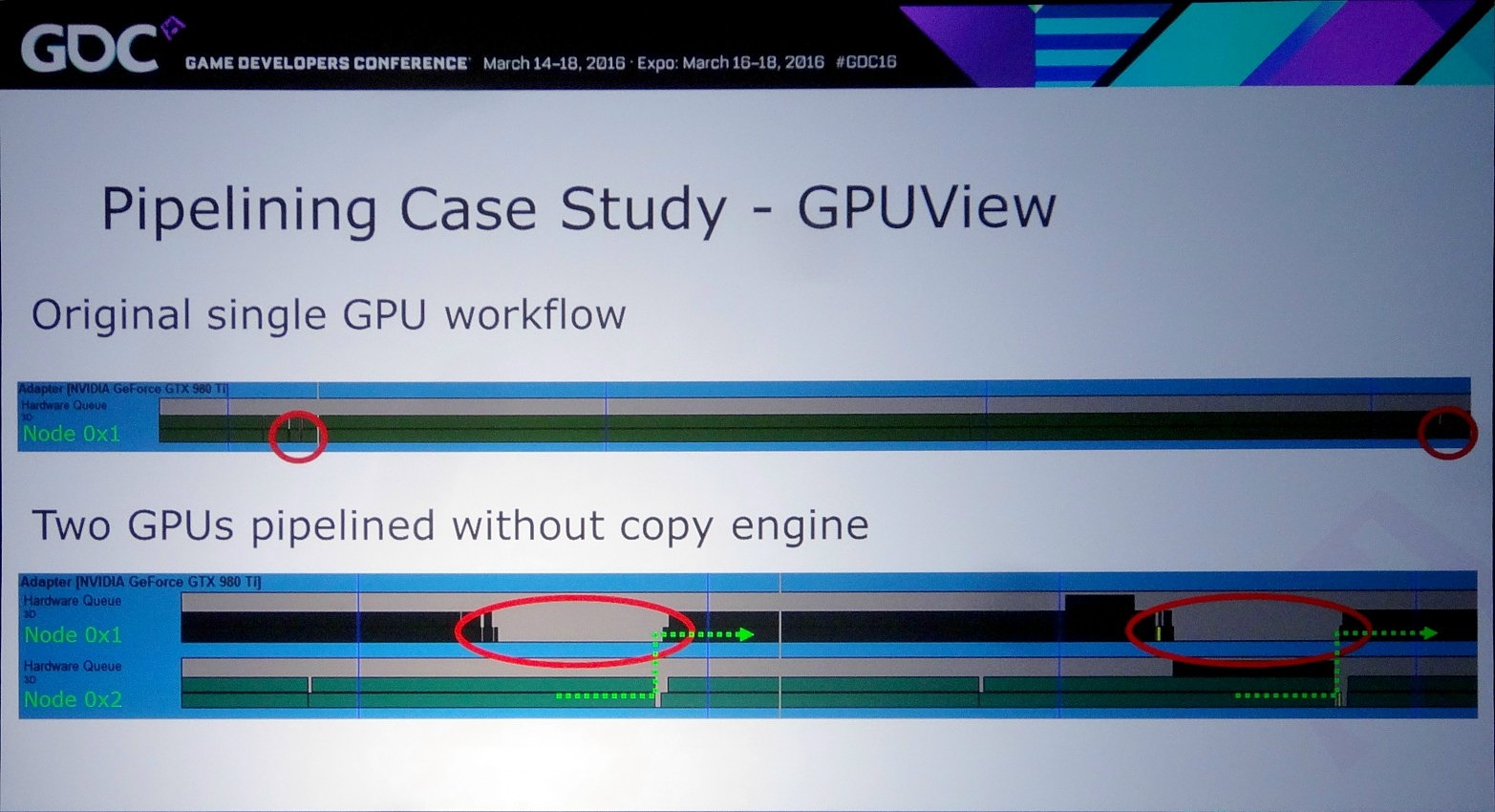
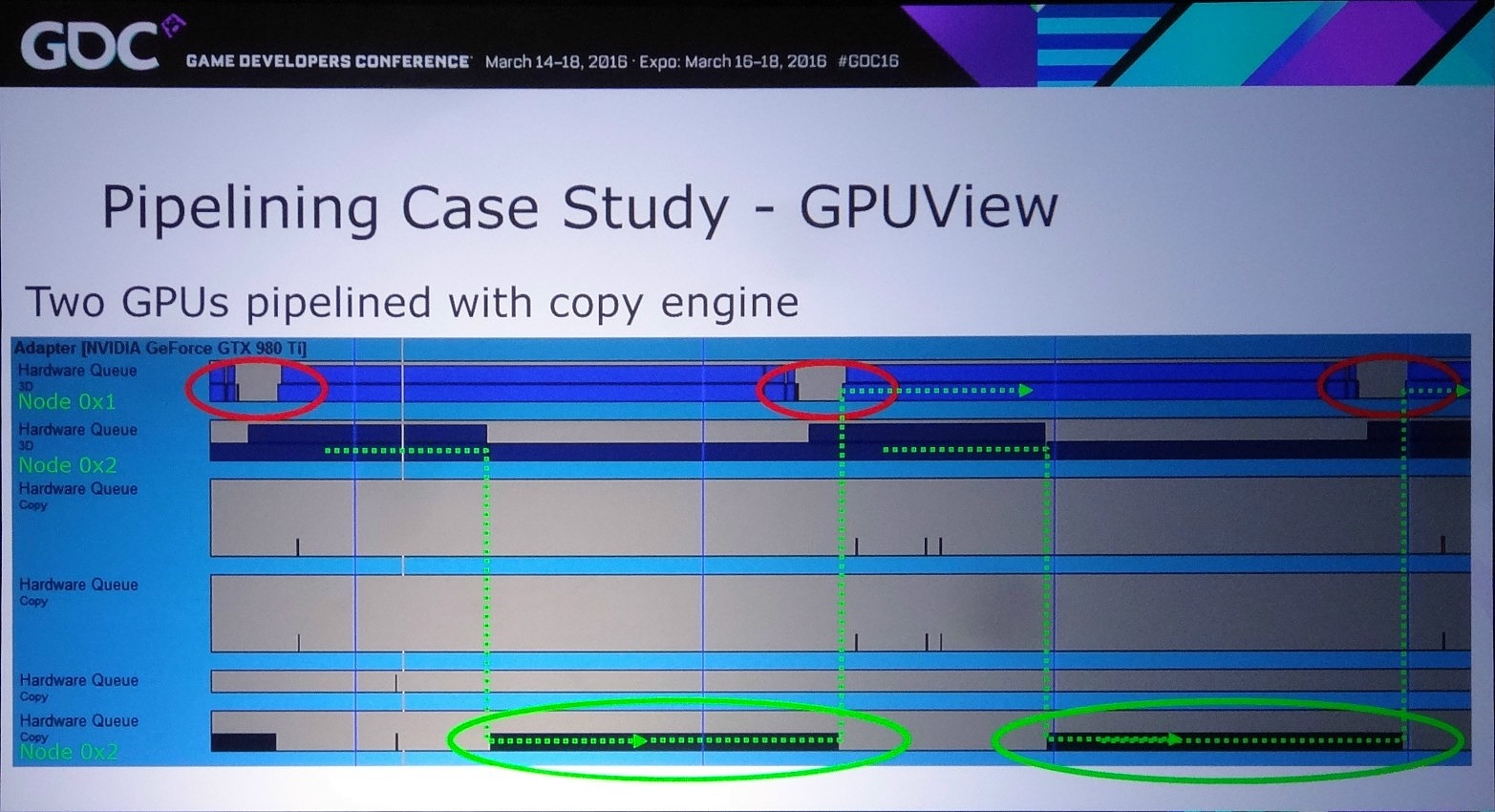
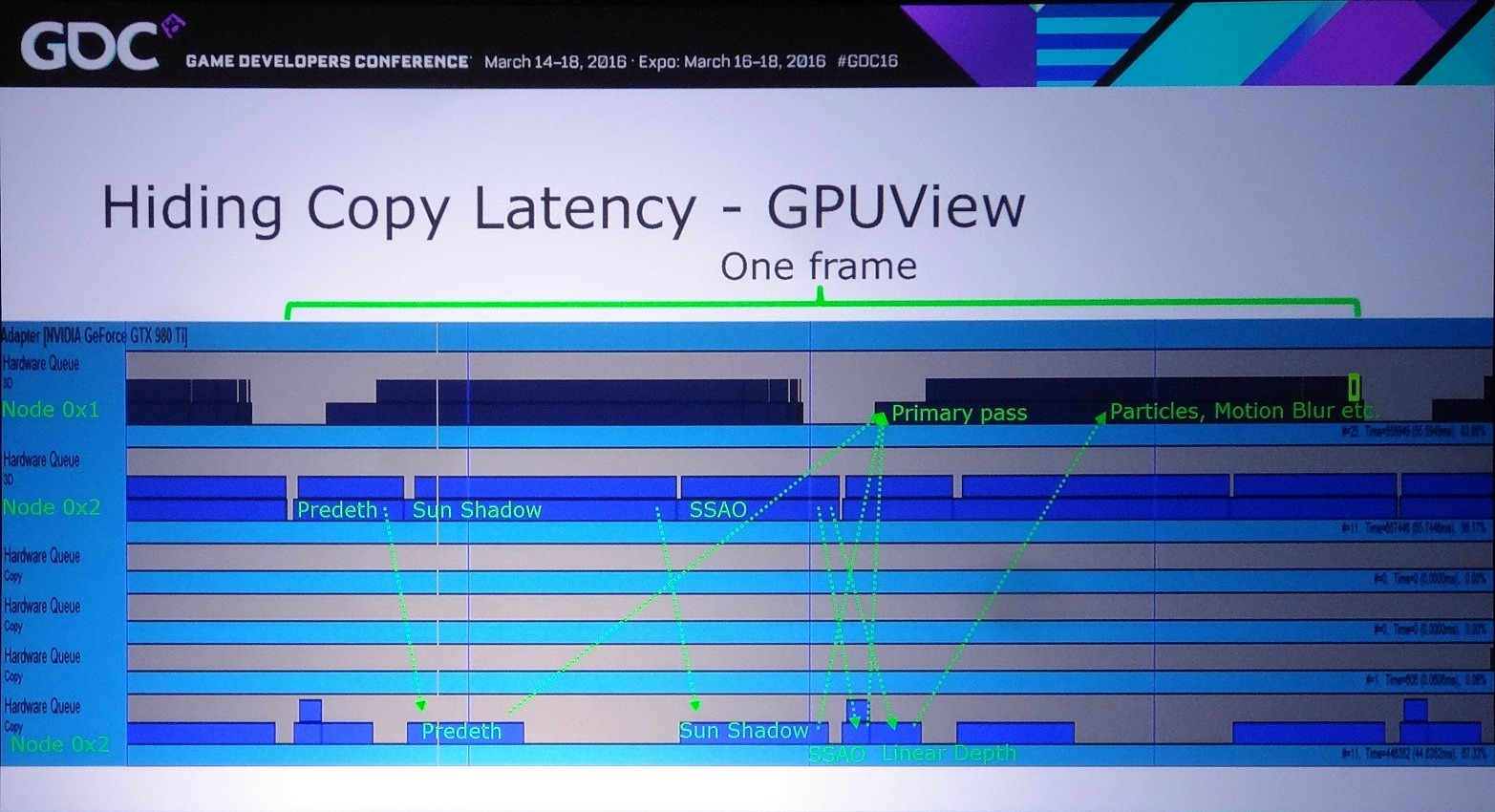
Dans l'exemple pris par Nvidia, le bi-GPU implémenté via le frame pipelining permet à la base de passer de 22 à 31 fps (+41%) et de monter à 37 fps (+68%) en exploitant le copy engine. Cet exemple est cependant un stress test en haute résolution (2160p) qui implique le transfert de la shadow map, du depth buffer et du SSAO, ce qui représente 87.3 Mo et prend à peu près 15 ms en PCIe 3.0 8x. Un temps de transfert qui limite le nombre de fps à +/- 60.
Le problème restant avec cette approche concerne la latence qui augmente à peu près comme en mode AFR. Le GPU1 effectue tout son travail, les données sont transférées puis le GPU effectue son travail. A 60 fps, et par rapport à un gros GPU de puissance équivalente, cela implique un triplement de la latence (de 16.7 ms à près de 50 ms). Heureusement, la partie liée au transfert de cette latence supplémentaire peut être masquée, exactement comme le fait Oxide pour le mode Async Compute d'AotS. Il suffit de décomposer le rendu en plus petits groupes de commandes et de transférer progressivement les éléments entre les GPU à travers le copy engine.
Reste bien entendu à voir ce que feront les développeurs de tout cela et à quel point AMD et Nvidia pourront les aider. Même si implémenter le frame pipelining en prenant en compte uniquement des ensembles de GPU similaires est plus simple que d'autres modes de rendus avec des combinaisons exotiques, cela représente un travail supplémentaire que tous n'accepteront probablement pas de prendre en charge. Et nous ne parlons mêmes pas des modes tri-GPU et quadri-GPU dont le support exigerait des développements complémentaires spécifiques
Vous pourrez retrouver l'intégralité de la présentation de Nvidia ci-dessous :





























GDC: VR: Nvidia Multi-Res Shading en pratique
Nous avons profité de la GDC pour revenir sur une technique introduite par Nvidia il y a quelques mois pour booster les performances de la réalité virtuelle. Baptisée Multi-Resolution Shading, elle consiste à réduire la résolution au niveau des zones visuelles périphériques et donc le nombre de pixels réellement rendus. Un subterfuge plutôt convainquant en pratique.




Pour pouvoir afficher une image sur un casque de réalité virtuelle, elle doit être déformée pour permettre, avec la lentille, de proposer l'angle de vue correct. Ce procédé, appelé warping et illustré ci-dessus, implique que seul le centre de l'image conserve la pleine résolution. Les zones périphériques représentent au final moins de pixels que le GPU n'en a calculés. En d'autres termes, elles reçoivent automatiquement une dose plus ou moins élevée de supersampling alors que ce n'est pas là que se pose notre regard. Un gaspillage de ressources que Nvidia tente de réduire avec le Multi-Res Shading.

La démonstration de Nvidia permet d'activer et désactiver le Multi-Res Shading à loisir, de quoi pouvoir essayer de discerner les différences éventuelles. Et force est de constater que même en ayant conscience de l'activation de cette optimisation il est difficile d'en discerner les effets. Il faut savoir exactement où regarder et déplacer le regard vers les coins de l'image (ce que nous ne sommes pas censés faire avec un casque de VR) pour observer une légère différence.
Comme vous pouvez l'observer sur les illustrations ci-dessus, Nvidia a recours à 9 viewports de résolutions différentes. Par exemple, la résolution peut être réduite à 1/2 sur les côtés et à 1/4 dans les coins. Mais si le principe est simple, l'exécution est un peu plus complexe et profite du multi-projection engine des GPU Maxwell 2 pour projeter rapidement, en une seule passe, tous les triangles dans chacun des 9 viewports. Sans cette capacité matérielle (également exploitée pour le VXGI et le VXAO), le coût sur les performances serait important à prohibitif suivant la complexité de la scène. AMD nous a d'ailleurs confirmé que cette technique n'était pas réaliste pour ses GPU, tout en précisant essayer d'obtenir un résultat similaire via d'autres approches.
Le Multi-Res Shasing est proposé par Nvidia aux développeurs à travers le SDK VR Works mais a également été implémenté dans l'Unreal Engine il y a quelques mois et, à l'occasion de la GDC, Unity a suivi le mouvement en annonçant son intégration, avec le reste de la suite VR de Nvidia.
GDC: Zotac MAGNUS EN980 avec GTX 980 et watercooling
Zotac était présent à la GDC sur le stand de Valve pour exposer sa Steam Machine, mais également pour présenter un prototype du MAGNUS EN980, son futur mini-PC haut de gamme. Plus volumineux que les autres mini-PC de la marque (+/- 22x20x13cm), il est également bien plus véloce, notamment pour pouvoir prendre en charge la VR.





Le MAGNUS EN980 embarque en effet un Core i5-6400 mais surtout, comme son nom l'indique, une GeForce GTX 980 mobile. Pas une GTX 980M mais bien une GTX 980 mobile qui correspond à une GeForce GTX 980 desktop mais au format MXM et avec une limite de consommation plus stricte.
Pour refroidir l'ensemble CPU et GPU, Zotac a recours à un système de watercooling spécifiquement conçu pour le format du boîtier dont la partie supérieure accueille le radiateur et le ventilateur de 120mm. Ce système de watercooling est toujours à l'état de prototype et reste l'élément sur lequel Zotac a le plus de travail à effectuer. Zotac nous a par ailleurs précisé viser une limite de consommation de 150 à 175W pour la carte graphique, qui pourrait donc être très proche des 180W de la GTX 980 de bureau.
Zotac envisage également plusieurs options à d'autres niveaux, par exemple le nombre de ports USB en façade (actuellement 2 ports dont un type C) ou encore le type de mémoire supporté. Par ailleurs, le prototype est à base de DDR3L, meilleure marché, mais la DDR4 n'est pas encore exclue à ce point.
Ce mini PC sera commercialisé en tant que barebone et pourra accueillir un disque ou SSD ou format 2.5" ainsi qu'un SSD au format M.2. La tarification sera à priori haut de gamme et Zotac prévoit de présenter la version finale du MAGNUS EN980 lors du Computex qui se tiendra à Taipei du 31 mai au 4 juin.