
Les derniers contenus liés aux tags GPGPU et GTC
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
GTC: Plus de détails sur le GK110
GTC: Tesla passe à Kepler avec les K10 et K20
GTC: Nsight évolue, s'ouvre à Linux et Mac OS
GTC: GTC 2012: la semaine du GPU computing
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...



Comme prévu, Jen-Hsun Huang, le CEO de Nvidia, a levé un coin du voile concernant le premier produit Pascal, l'accélérateur Tesla P100. Au menu : 15 milliards de transistors, 10 Tflops, HBM2, 4 Mo de L2

Le Tesla P100 est un nouvel accélérateur dédié au calcul massivement parallèle qui embarque un GPU GP100, auquel nous faisions référence précédemment en tant que Pascal, nom de code de son architecture. Il s'agit bel et bien d'un nouveau monstre de puissance. Pour cette première utilisation de procédé de fabrication 16nm FinFET Plus, Nvidia n'a pas eu peur de concevoir un énorme GPU et le GP100 intègre pas moins de 15.3 milliards de transistors répartis sur 610 mm². A comparer aux 8 milliards de transistors de l'actuel GM200 qui mesure également 600 mm².
De quoi pouvoir pousser la puissance de calcul vers le haut mais surtout intégrer de nouvelles fonctionnalités avant tout dédiées au monde du HPC telles que la connectique NVLink qui offre une bande passante combinée de 160 Go/s.



Le Tesla P100 se présente sous la forme d'un module au format mezzanine qui revient à superposer 2 PCB, avec un ou plusieurs connecteurs entre ceux-ci. Sur le Tesla P100 il s'agit de 2 connecteurs de 400 broches qui vont permettre de proposer la connectique NVLink. Ce format facilite également l'intégration dans les serveurs et la mise en place d'un refroidissement performant ce qui permet à Nvidia de pousser le TDP à 300W.

Concernant la puissance brute du Tesla P100, Nvidia annonce 10.6 Tflops avec GPU Boost en FP32, la précision classique, un gain de 60% par rapport aux 6.6 Tflops de la Titan X. L'architecture Pascal dans cette implémentation supporte également la double précision en demi-vitesse, soit 5.3 Tflops, un nouveau bond en avant par rapport au record actuel : 2.6 Tflops pour le GPU Hawaii d'AMD des FirePro W9100 et S9170. Dans l'autre sens, Pascal supporte également la demi-précision, le FP16, et peut alors monter à 21.2 Tflops.
A quelle configuration de GPU pourrait correspondre tout cela ? Au départ, nous supposions que le nombre d'unités de calcul passerait de 3072 sur le GM200 à 4608 sur le P100, réparties dans 36 blocs d'unités de calcul (SMP ?), ce qui aurait permis assez facilement d'augmenter à peu près toutes les capacités brutes du GPU de 50%. Il n'en est cependant rien et les changements sont plus profonds au niveau de l'architecture. Il s'agit ainsi pour le Tesla P100 de 3584 unités de calcul réparties dans 56 blocs de 64, mais le GP100 continent physiquement 60 de ces blocs.
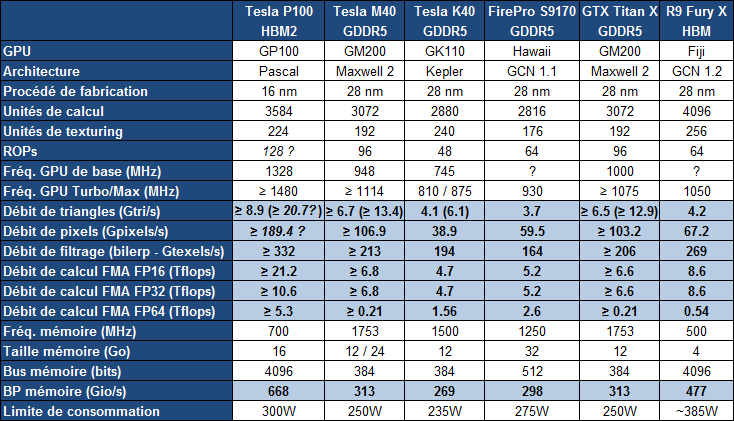
Le gain de puissance de calcul brute provient ainsi principalement d'une hausse de la fréquence du GPU (+/- 1.5 GHz) alors que le GPU computing devrait profiter de cette organisation en plus petits blocs d'unités de calcul, mais également des autres évolutions de l'architecture Pascal, pour gagner en efficacité.
Sur ce point, Nvidia se contente de parler d'une augmentation de la taille du fichier registre. Au total le GM200 embarque +/- 6 Mo de registres, ce qui correspond à 256 Ko par SMM ou encore à 512 registres 32-bit par unités de calcul. Le GP100 passe à 15 Mo de registres, ce qui implique une augmentation de 100%, soit 256 Ko par SMP ou encore 1024 registres 32-bit par unité de calcul. De quoi permettre de maintenir un meilleur taux d'occupation des unités de calcul, particulièrement en double précision.
Le cache L2 passe de son côté de 3 à 4 Mo alors que l'interface mémoire est large de 4096-bit en HBM2. Nvidia annonce une bande passante de 720 Go/s pour les 16 Go de mémoire HBM2 CoWoS, le nom donné par TSMC à sa technologie 2.5D, similaire à celle employée par AMD pour son GPU Fiji.
Ce passage à la mémoire HBM2, associé à NVLink, à la puissance de calcul en hausse et au support de la précision FP16 permet au Tesla P100 d'afficher une progression conséquente sur différents plans par rapport à ses prédécesseurs.
Jen-Hsun Huang a terminé le chapitre consacré à Pascal en déclarant que la production en volume avait débuté et que son propre serveur basé sur le Tesla P100 serait commercialisé à partir du mois de juin. Il est probablement raisonnable de s'attendre à une nouvelle GeForce Titan d'ici là, mais sera-t-elle basée sur le GP100 ?
GTC: Plus de détails sur le GK110
Lors d'une session technique sur l'architecture du GK110, nous avons pu apprendre quelques détails de plus à son sujet par rapport aux premières informations d'hier. Des détails bien entendu concentrés sur la partie compute de ce GPU. Tout d'abord, Nvidia propose cette fois un schéma de l'architecture qui montre sans ambiguïté que le GK110 est composé de 15 SMX de 192 unités de calcul, soit un total de 2880, et d'un bus mémoire de 384 bits.

On apprend par ailleurs que le cache L2 passe à 256 Ko par contrôleur mémoire 64 bits, soit un total de 1.5 Mo contre 768 Ko pour le GF1x0 et 512 Ko pour le GK104. Tout comme pour le GK104, chaque portion de cache L2 affiche une bande passante doublée par rapport à la génération Fermi.
Les blocs fondamentaux d'unités de calcul, appelés SMX dans la génération Kepler, sont similiaires pour le GK110 ceux du GK104 :

Le nombre d'unités de calcul simple précision est identique, tout comme le nombre d'unités dédiées aux fonctions spéciales, aux lectures/écritures, au texturing Les caches sont également identiques que ce soit les registres, le L1/mémoire partagée, les caches dédiés aux texturing.
La seule différence fondamentale réside dans la multiplication des unités de calcul en double précision qui passent de 8 pour le GK104 à 64 pour le GK110. Alors que le premier est 24x plus lent dans ce mode qu'en simple précision, le GK110 n'y sera que 3x plus lent. Couplé à l'augmentation du nombre de SMX, cela nous donne un GK110 capable de traiter 15x plus de ces instructions par cycle ! Par rapport au GF1x0 il s'agit d'un gain direct de 87.5% à fréquence égale.
Dans le GK110, tout comme dans le GK104, chaque SMX est alimenté par 4 schedulers, chacun capable d'émettre 2 instructions. Toutes les unités d'exécution ne sont cependant pas accessibles à tous les schedulers et un SMX est en pratique séparé en 2 parties symétriques à l'intérieur desquelles une paire de schedulers se partage les différentes unités. Chaque scheduler dispose de son propre lot de registres : 16384 registres de 32 bits (512 registres généraux de 32x32 bits en réalité). Par ailleurs chaque scheduler dispose d'un bloc dédié de 4 unités de texturing accompagnées d'un cache de 12 Ko.
Contrairement à ce à quoi nous nous attendions, l'ensemble cache L1 / mémoire partagée n'évolue pas dans le GK110 par rapport au GK104 et reste proportionnellement inférieur à ce qui était proposé sur la génération Fermi. Nvidia introduit par contre trois petites évolutions qui peuvent entraîner des gains importants :
Tout d'abord, chaque thread peut se voir attribuer jusqu'à 256 registres contre 64 auparavant. Quel intérêt quand le nombre de registres physiques n'augmente pas ? Il s'agit de donner plus de flexibilité au développeur et surtout au compilateur pour jongler entre le nombre de thread en vol et la quantité de registres allouée à chacun pour maximiser les performances. C'est particulièrement important dans le cas des calculs en double précision qui consomment le double de registres et qui étaient auparavant limités à 32 registres par thread. Passer à 128 permet des gains impressionnants dans certains cas selon Nvidia.

Ensuite, la seconde petite évolution consiste à autoriser l'accès direct aux caches dédiés au texturing. Auparavant il était possible d'en profiter manuellement en bricolant un accès à travers les unités de texturing, mais ce n'était pas pratique. Avec le GK110, ces caches de 12 Ko peuvent être exploités directement depuis les SMX mais uniquement dans le cas d'accès à des données en lecture seule. Ils ont l'avantage de disposer d'un accès royal au sous-système mémoire du GPU, de souffrir moins en cas de cache miss et de mieux supporter les accès non alignés. C'est le compilateur (via une directive) qui se charge d'y avoir recours lorsque c'est utile.
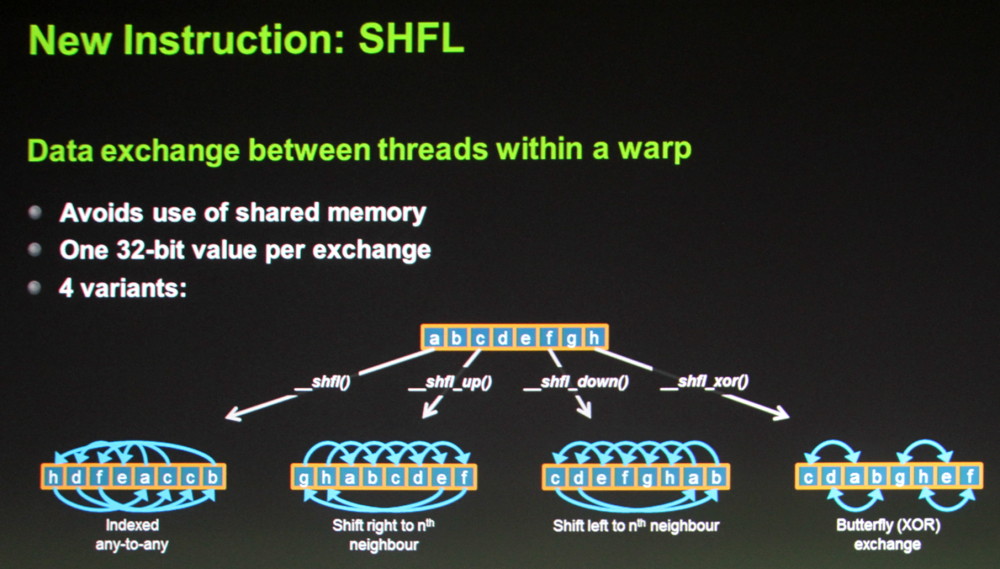
Enfin, une nouvelle instruction fait son apparition : SHFL. Elle permet un échange de donnée de 32 bits par thread à l'intérieur d'un warp (bloc de 32 threads). Son utilité est similaire à celle de la mémoire partagée et cette instruction vient donc en quelque sorte compenser sa quantité relativement faible, proportionnellement au nombre d'unités de calcul. Dans le cas d'un échange de données simple il sera donc possible d'une part de gagner du temps (un transfert direct à la place d'une écriture puis d'une lecture) et d'autre part d'économiser la mémoire partagée.
D'autres petits détails évoluent également tels que l'ajout des quelques instructions atomiques manquantes en 64 bits (min/max et opérations logiques) et une réduction de 66% du surcoût lié à la mémoire ECC.
Au final, avec la génération Kepler, Nvidia a bien pris une direction différente de celle de la génération Fermi. Le gros GPU Fermi, le GF100/110, disposait d'une organisation interne différente de celle des autres GPU de la famille, de manière à augmenter la logique de contrôle au détriment de la densité des unités de calcul et du rendement énergétique.
Avec le GK110, Nvidia n'a pas voulu faire de compromis sur ce dernier point ou plutôt devrions nous dire "n'a pas pu". Il s'agit dorénavant de faire un maximum dans une enveloppe thermique qui n'est plus extensible. C'est la raison pour laquelle le GK110 reprend la même organisation interne que celle du GK104, en dehors de la capacité de calcul en double précision qui a été revue nettement à la hausse.
Ainsi, Nvidia n'a pas cherché à complexifier son architecture pour soutenir les performances en GPU computing et s'est attaché à essayer de faire un maximum avec les ressources disponibles en se contentant d'évolutions mineures mais qui peuvent avoir un impact énorme. C'est également la raison pour laquelle le processeur de commandes a été revu pour permettre de maximiser l'utilisation du GPU avec les technologies Hyper-Q et Dynamic Parallelism que nous avons décrites brièvement hier et sur lesquelles nous reviendront dès que possible avec quelques détails de plus.
GTC: Tesla passe à Kepler avec les K10 et K20

Nvidia vient de dévoiler deux nouvelles cartes Tesla basées sur l'architecture Kepler. La première, dénommée K10 est en quelque sorte une version Tesla serveur de la GeForce GTX 690. Il s'agit donc d'une carte équipée de 2 GPU GK104 et d'un switch PCI Express 3.0 PLX. Par rapport à la GeForce GTX 690, les fréquences ont bien entendu été revues à la baisse et passent d'une fourchette de 915 à plus de 1100 Mhz (suivant le niveau de turbo) à 745 MHz pour le GPU et de 1500 à 1250 MHz pour la mémoire.
Nvidia semble ainsi avoir laissé de côté GPU Boost, probablement parce que la variabilité qui y est liée n'est pas compatible avec le monde professionnel. La base de la technologie, qui permet de contrôler dynamiquement la fréquence pour maintenir un certain TDP est par contre de toute évidence de la partie, ce qui permet à Nvidia de proposer un TDP relativement faible qui tourne autour de 225-235W, contre 300W pour la GeForce GTX 690.
La K10 est équipée de 4 Go de mémoire GDDR5 par GPU, soit 8 Go au total, et supporte l'ECC, d'une manière similaire à ce qui se fait sur les précédentes cartes Tesla : une partie de la mémoire est utilisée pour stocker les données de parité, ce qui réduit l'espace mémoire disponible ainsi que la bande passante pratique. La puissance de calcul en double précision reste par contre extrêmement faible, tout comme certaines opérations logique ou sur les entiers, le GPU GK104 étant très limité à ce niveau. En d'autres termes, la carte K10 affiche une puissance de calcul en simple précision flottante énorme, de 4577 Gflops et sera donc destinée à ce type de calculs uniquement. En double précision le débit tombe à 190 Gflops.
La seconde carte Kepler annoncée aujourd'hui, la K20 est la plus intéressante des deux puisqu'elle embarquera un GPU GK110 au sujet duquel Nvidia vient de donner les premières informations. Peu de détails sur la K20 sont communiqués à ce jour, ses spécifications ne seront fixées que plus tard dans l'année puisqu'elle est prévue pour le dernier trimestre 2012. Il est cependant probable qu'elle soit équipée d'un GK110 partiellement castré avec 13 blocs d'unités de calcul actifs sur les 15 disponibles pour un total de 2496 de ces unités de calcul. Nvidia indique par ailleurs que ses performances en double précision seront triplées par rapport à la génération actuelle et supérieures à 1 Tflops, ce qui en fera une carte bien plus polyvalente pour le calcul, d'autant plus que son GPU apporte plusieurs innovations importantes pour faciliter son exploitation avec un maximum d'efficacité.

La carte K20 devrait être accompagnée de 6 Go de mémoire GDDR5 et sera disponible avec un TDP de 225W, ce qui est plutôt impressionnant compte tenu de la complexité de ce GPU. Il est probable que Nvidia profite du fait qu'en général les blocs du GPU dédiés au graphique ne seront pas utilisés pour pouvoir compresser le TDP. Nvidia nous précise cependant que si un intégrateur dispose d'une plateforme certifiée pour un TDP plus élevé, la carte K20 pourra s'y adapter pour profiter de la marge supplémentaire. Elle sera par ailleurs disponible en version workstation en plus de la version serveur.
GTC: Nsight évolue, s'ouvre à Linux et Mac OS
Nvidia profite de la GTC pour dévoiler deux nouvelles versions de Nsight, son environnement de développement intégré (IDE) dédié autant au graphique qu'au GPU computing.
Tout d'abord Parallel Nsight est renommé en Nsight Visual Studio Edition et passe en version 2.2. Parmi les nouveautés, citons enfin le support de DirectX 9 (précédemment Nsight était limité à DirectX 10 et 11), le support de l'architecture Kepler, le débogage des kernels optimisés SASS/PTX (Source and ASSembly / Parallel Thread eXecution) et le débogage CUDA en local sur une machine équipée d'un seul GPU (qui est donc également en charge de l'affichage).
Ensuite Nvidia lance Nsight Eclipse Edition qui est destinée à la plateforme de développement ouverte du même nom, initiée par IBM il y a une dizaine d'années. De quoi permettre à Nsight d'être exploité sur Linux ou Mac OS et de faciliter l'utilisation du GPU computing sur ces systèmes d'exploitation.
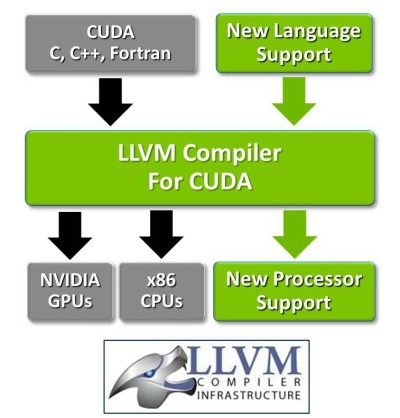
Si ses solutions propriétaires restent bien à l'ordre du jour, il est intéressant d'observer que Nvidia se tourne ainsi de plus en plus vers l'open source. Ainsi, dans le même courant, Nvidia a annoncé la semaine passée le support de l'architecture CUDA par LLVM, un compilateur open source modulaire très répandu qui permettra aux développeurs d'exploiter les GPU à travers de nombreux langages de programmation. Un support dont la mise en place a été facilitée par le remplacement, il y a quelques mois, de la base du compilateur CUDA de Nvidia (limité au C, C++ et Fortran) par des modules LLVM.
GTC: GTC 2012: la semaine du GPU computing
Nvidia organise en ce moment à San José l'édition 2012 de la GPU Technology Conference (GTC), un évènement centré sur le GPU computing : supercalculateurs, langages destinés à la programmation massivement parallèle, cloud computing pour les jeux vidéo...
Nous serons sur place toute la semaine pour couvrir ce forum technologique durant lequel nous nous attendons à recevoir de nombreuses informations sur CUDA 5, d'éventuels dérivés Tesla basés sur le GPU GK104 des GeForce GTX 670/680/690, mais surtout sur le GK110, le futur gros GPU de la famille Kepler.

Les grandes lignes de ces nouveautés devraient être dévoilées ce mardi durant la keynote d'ouverture de Jen-Hsun Huang, le CEO de Nvidia, et abordées plus en détail par la suite. Si le sujet vous intéresse, notez que cette keynote sera retransmise en direct depuis le site officiel de la GTC à partir de 19h30 heure française.