
Les derniers contenus liés aux tags Vega 10 et HBM2
AMD lève le voile sur les RX Vega
AMD lance la Radeon Vega Frontier Edition
Radeon Vega Frontier Edition 16 Go: dispo fin juin
Architecture Vega 10 : AMD lève le voile
Vega 10: 4096 unités, 1.5 GHz, 8 Go de HBM2 ?
AMD lève le voile sur les RX Vega



Après un lancement un peu particulier d'une édition « Frontier » au second trimestre, AMD profite du Siggraph pour annoncer le « vrai » lancement de son nouveau GPU haut de gamme, Vega, en version destinée aux joueurs et portant le nom de RX Vega. Si un grand nombre de détails avaient été dévoilés précédemment par AMD, particulièrement sur l'architecture, de nouveaux détails ont été donnés, vous trouverez donc certains rappels au milieu des nouvelles informations.
Un très gros, et très dense GPU
Il aura fallu beaucoup de patience, mais AMD va enfin lancer son premier gros GPU 14nm, connu sous le nom de code Vega 10. Il s'agit effectivement d'un très gros GPU puisqu'il compte 12.5 milliards de transistors.
- GP100 : 15.3 milliards de transistors pour 610 mm²
- Vega : 12.5 milliards de transistors pour 486 mm²
- GP102 : 12.0 milliards de transistors pour 471 mm²
- Fiji : 8.9 milliards de transistors pour 598 mm²
- GM200 : 8.0 milliards de transistors pour 601 mm²
- GP104 : 7.2 milliards de transistors pour 314 mm²
- GK110 : 7.1 milliards de transistors pour 561 mm²
- Hawaii : 6.2 milliards de transistors pour 438 mm²
- Polaris 10 : 5.7 milliards de transistors pour 232 mm²
- GM204 : 5.2 milliards de transistors pour 398 mm²
- Tonga : 5.0 milliards de transistors pour 368 mm²
- GP106 : 4.4 milliards de transistors pour 200 mm²
- GK104 : 3.5 milliards de transistors pour 294 mm²
- GM206 : 2.9 milliards de transistors pour 228 mm²
- Pitcairn : 2.8 milliards de transistors pour 212 mm²
- GK106 : 2.5 milliards de transistors pour 214 mm²
- Bonaire : 2.1 milliards de transistors pour 158 mm²
Vega est donc légèrement plus gros que le GP102, utilisé chez Nvidia sur les GTX 1080 Ti (les GTX 1080 "classiques" utilisent le GP104, plus petit pour rappel).
- Vega : 25.7 millions de transistors par mm²
- GP102 : 25.4 millions de transistors par mm²
- GP100 : 25.1 millions de transistors par mm²
- Polaris 10 : 24.6 millions de transistors par mm²
- Tonga : 13.6 millions de transistors par mm²
- Pitcairn : 13.2 millions de transistors par mm²
- GP104 : 22.9 millions de transistors par mm²
- GM204 : 13.1 millions de transistors par mm²
- GM206 : 12.7 millions de transistors par mm²
Si l'on calcule la densité, on peut voir que Vega se place légèrement en tête du classement, ce qui n'est en soit pas très important. La densité est un peu meilleure que sur Polaris 10, mais l'écart est plutôt léger. Comme Polaris, Vega est fabriqué par GlobalFoundries sur leur process 14 LPP.
Mémoire HBM2
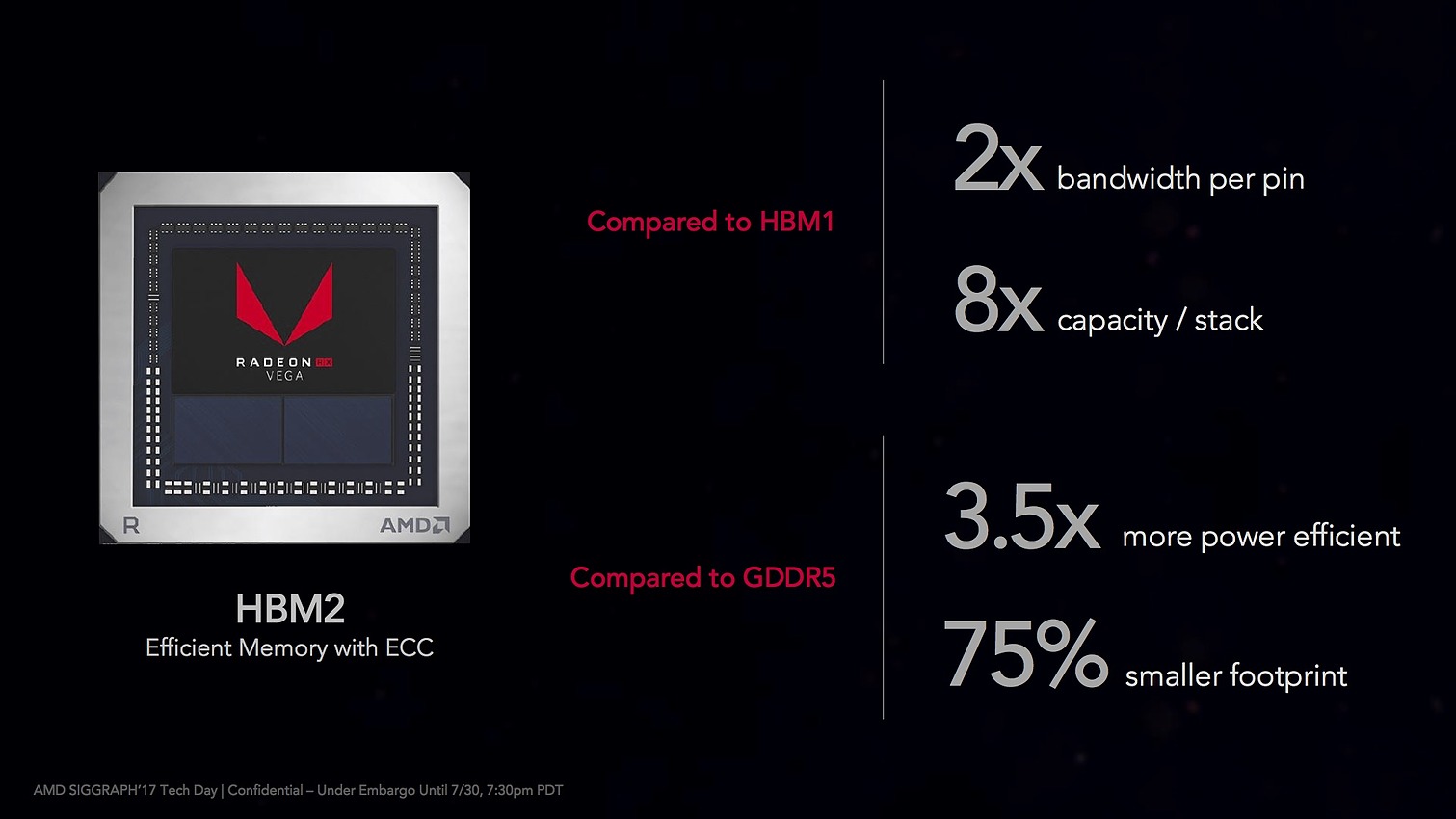
Sans surprise, c'est de la mémoire HBM2 qui accompagne Vega, deux puces de 4 Go sont placées à côté du die sur un interposer. La mémoire est interfacée en 2048 bits, ce qui permet d'obtenir une bande passante de 484 Go/s, soit exactement la même bande passante que l'on peut trouver sur une 1080 Ti (qui utilise de la GDDR5X).

A gauche Fiji, à droite Vega, les puces HBM2 sont significativement plus grosses
Contrairement à Fiji qui utilisait quatre puces pour un bus mémoire 4096 bits, on se limite à deux puces pour RX Vega.
64 CU et 4096 Stream processors
Si AMD n'a pas prononcé une fois l'acronyme GCN durant sa présentation, en pratique on retrouve bien une architecture similaire aux GPU précédents du constructeurs. On retrouve donc 64 Compute Unit, affublées d'un très marketing « Next Gen » pour 4096 unités de calculs (ce qu'AMD appelle Stream processors). C'est deux fois plus d'unités qu'une Radeon 470, mais autant que Fiji. De la même manière on retrouvera aussi 256 unités de textures et 64 ROPs.
A l'intérieur des CU AMD a procédé a de petites améliorations par rapport à Polaris avec de nouvelles instructions de texturing capables de stocker deux données 16 bits dans un registre 32 bits.




AMD illustrait cela avec une version spécifique de la démo Time Spy de 3D Mark ou l'application d'instructions 16 bits (AMD regroupe cela derrière le nom Rapid Packed Math) permet de voir des gains assez intéressants, dans le cas de la génération de bruit, le passage d'instructions INT32 à des INT16 permet un gain pratique de 25% de performances sur cet algorithme, et le passage en FP16 des FFT utilisées pour les effets de bloom permet un gain de 20% de performance sur cette partie du rendu. Reste à voir si les développeurs suivront, ce n'est pas la première fois qu'AMD met en avant le FP16 avec des résultats pratiques limités.
On notera que le jeu d'instruction interne gagne 40 nouvelles instructions, qui incluent aussi de nouvelles instructions pour les crypto-monnaies.
Une gestion mémoire « façon CPU »
Un des changements les plus originaux apporté par Vega concerne la gestion de la mémoire. De manière historique, la mémoire embarquée par les GPU doit être gérée manuellement par les développeurs (avec plus ou moins de facilité en fonction des API utilisées) qui doivent remplir (et faire de la place si nécessaire) eux même la mémoire graphique. Un système de fonctionnement très basique, et très différent de ce que l'on connaît sur les CPU.
Sans rentrer trop dans les détails, les CPU et les systèmes d'exploitation comme Windows utilisent ce que l'on appelle un système dit de pagination mémoire. Un programme n'accède jamais vraiment à la mémoire système de manière directe, il alloue de la mémoire sous la forme de blocs (des pages mémoires) qui utilisent un système d'adressage virtuel. En pratique, le programme ne sait pas à quel endroit exact ses données sont stockées, une possibilité exploitée par les systèmes d'exploitation avec la gestion de mémoire virtuelle qui permet d'étendre la quantité mémoire disponible en stockant des pages mémoires dans un fichier (sous Windows, le fameux pagefile.sys). Le système s'occupe alors lui même de stocker les pages les moins utilisées sur disque, et les pages les plus utilisées sont gardées en mémoire centrale.
Avec Vega, AMD s'est inspiré de cela en proposant un mode de fonctionnement alternatif baptisé HBCC (High Bandwidth Cache Controller). Pour s'en servir, on activera ce mode dans le driver d'AMD où l'on définira la taille de l'espace virtuel (par exemple, 32 Go).
Par la suite, un jeu qui se lancera se verra rapporté par le driver le fait que (dans notre exemple) 32 Go de mémoire sont disponible (au lieu de 8). Il pourra allouer comme à l'habitude sa mémoire, mais de manière transparente, le GPU va paginer la mémoire. Les pages pourront ainsi être placées au choix en HBM2, ou en mémoire système.




C'est le GPU (et son driver) qui gèrera ainsi la mémoire, la HBM2 étant vue comme un cache exclusif par rapport à l'espace virtuel. En pratique, cela permet de faire tourner des applications qui ont besoin de plus de mémoire que ce dont dispose la carte graphique, on est alors uniquement limité par la bande passante PCI Express lorsqu'il faut transférer des pages d'un endroit à l'autre (l'équivalent du swap).
Sur le papier, l'idée d'amener les GPU dans la modernité pour la gestion mémoire peut sembler intéressante. Le fait que les jeux doivent gérer eux même leur mémoire fait qu'en pratique, cette gestion est rarement fine, pour ne pas dire grossière. La majorité des données allouées sont rarement nécessaires en simultanée pour le rendu d'une frame et disposer d'un mécanisme de swap de ce type pourrait permettre, dans un temps long, de faire tourner des jeux avec des niveaux de textures plus élevés qui ne rentreraient pas dans les 8 Go présents sur la carte.
Cela reste cependant un avantage très théorique qui dépendra de la qualité de l'implémentation du système. Car le cout d'un échange de données entre la mémoire centrale et celle du GPU n'est pas nul et l'on risque de se retrouver, au delà de démonstrations savamment choisies avec des lags dues à ces transferts. Quelque chose de tout à fait acceptable dans un cas d'utilisation d'applications professionnelles ou un ralentissement vaut mieux qu'une impossibilité de fonctionner.
Si l'idée sur le fond nous semble bonne, nous resterons donc prudent sur ce qu'elle pourrait apporter en pratique pour la déclinaison « jeu » de Vega.
Un support DirectX 12 plus complet
Avec Vega, AMD améliore son support de DirectX 12 par rapport à Polaris :

Le premier sur lequel AMD n'a pas vraiment communiqué dans sa présentation est la gestion du standard swizzle, un mode spécifique d'alignement des données pour les textures qui permet d'améliorer la rapidité de certains algorithmes . La fonctionnalité n'est gérée que par Vega aujourd'hui.
L'autre changement concerne la rasterization, la transformation d'un triangle en pixels. DX12 ajoute le concept de conservative rasterization qui permet d'améliorer la manière dont cette transformation s'opère en ajoutant des règles plus claires sur les algorithmes utilisés pour éviter les incertitudes dans le rendu.
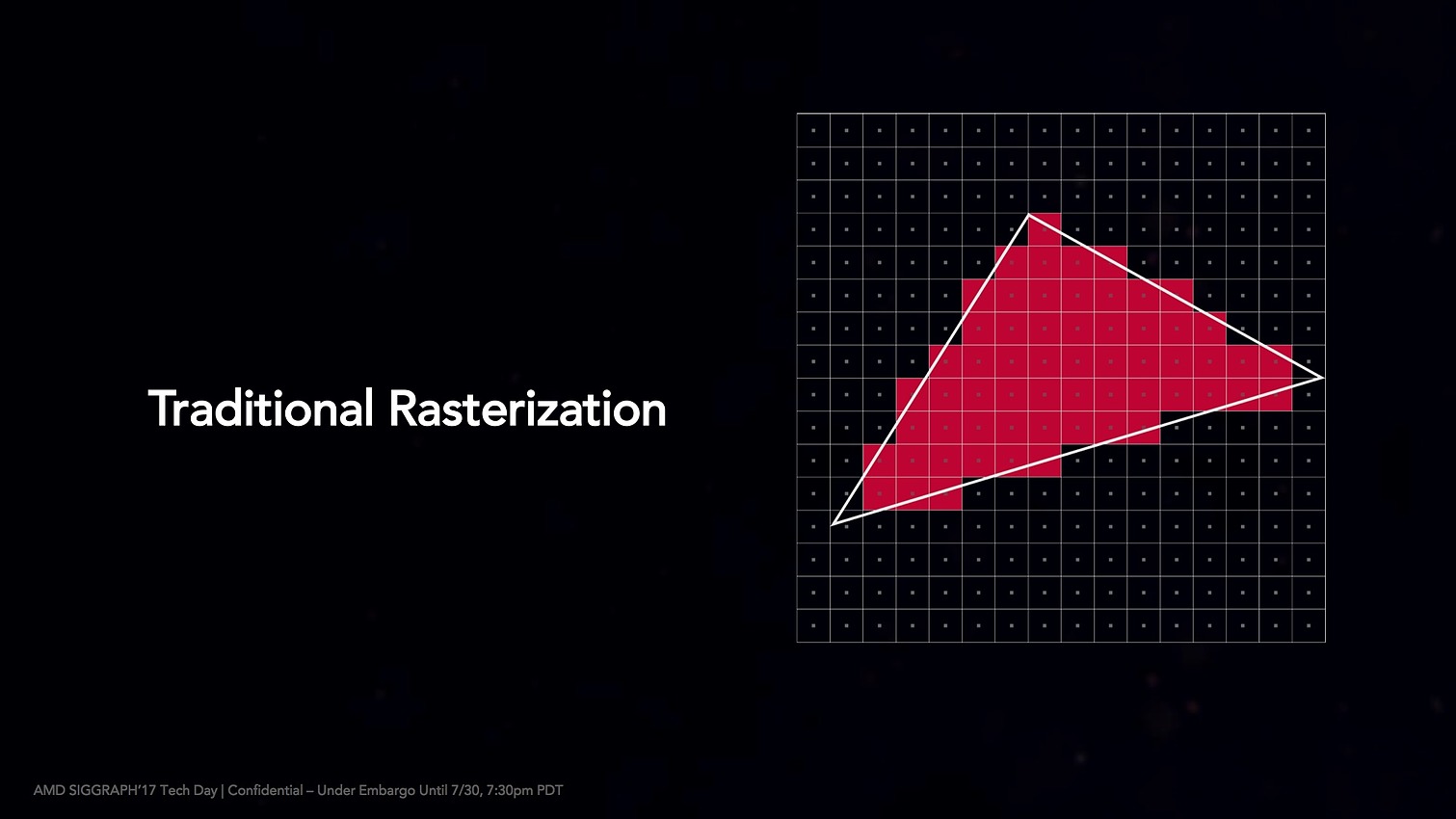


Pascal chez Nvidia supportait déjà les deux premiers tiers de cette fonctionnalité, le premier est surtout utile au tiled rendering, la génération de light maps et des shadow maps. Le second réduit un peu plus l'incertitude ce qui est surtout utile pour les rendus types voxel. Le troisième niveau que supporte Vega ajoute une variable dans le langage des shaders de DirectX (HLSL) qui permet de régler finement le niveau de sous estimation que l'on désire, une fonctionnalité qui permet d'optimiser l'occlusion.

Vega gère également de nouveaux types de shaders, baptisés primitive shaders qui peuvent remplacer les vertex/geometry shaders pour réaliser de nouveaux types de rendus plus efficaces avec la possibilité d'éliminer beaucoup plus efficacement des primitives. Là encore cela demandera un travail important aux développeurs ce qui fait qu'on peut douter qu'elle soit exploitée, mais AMD disposerait d'un path alternatif dans ses pilotes qui permettrait au cas par cas d'obtenir des gains.
Sorties vidéo améliorées

Au delà de l'architecture, la gestion des sorties vidéos a été améliorée, par rapport à Polaris on peut désormais piloter deux écrans 4K 120 Hz en simultanée. Pour les modes HDR, on passe de un à trois écrans 4K 60 Hz, et le support d'un écran 4K 120 Hz ou 5K 60 Hz.
D'autres petits détails ont aussi été améliorés, le décodage hardware H.264 par exemple fonctionne désormais pour les vidéo 4K 60 Hz (cette résolution n'était gérée que pour H.265 par Polaris). Du côté de la virtualisation, VCE (les fonctionnalités de décodage/encodage vidéo) sont désormais également disponibles dans les machines virtuelles.
RX Vega en pratique : trois cartes
Avec son GPU Vega 10, AMD va lancer trois versions destinées aux joueurs :

Le haut de gamme est représenté par les RX Vega 64, disponibles à la fois en version classique et watercoolée. Cette dernière dispose d'un TDP plus élevé, de 345W là où la version classique se contente d'un déjà bien elevé TDP de 295 watts. La différence entre les deux modèles tient dans les fréquences, les derniers MHz se payant très chers en matière de consommation.
En dessous on retrouvera les RX Vega 56 qui, comme leur nom l'indique, ne disposent que de 56 CU actifs et d'un TDP bien plus contenu de 210 watts. Il faut noter que les cartes disposent de deux bios et que les caractéristiques indiquées dans ce tableau sont, sauf erreurs, celles du mode le plus performant. Le second BIOS réduit le TDP de 15% ce qui ramènerait la version watercoolée à un beaucoup plus normal 300W.
Et les performances ?
Côté performance, nous n'avons pas encore pu tester les cartes mais les premiers chiffres montrés par AMD laissent penser que l'on se situe autour (voir un peu en dessous) d'une GTX 1080. Un niveau de performance qui, compte tenu du TDP annoncé et du nombre de transistors semble montrer un rendement qui ne progresse pas vraiment vis à vis de la concurrence.
Une stratégie tarifaire à base de bundles
Côté prix, AMD tente une stratégie un peu originale pour essayer de contrer le problème du mining mais qui ne satisfera pas forcément tout le monde. Il y aura deux types de cartes disponibles, d'abord les modèles « classiques » vendus nus, dont la disponibilité risque d'être limitée, et de l'autre, un système de « packs ».
Les prix annoncés par AMD sont donc pour les versions nues :
- Radeon RX Vega 64 : 499$
- Radeon RX Vega 56 : 399$
En parallèle on trouvera plusieurs packs :
- Radeon RX Vega 64 Aqua Pack (version watercooling) : 699$
- Radeon RX Vega 64 Black Pack : 599$
- Radeon RX Vega 56 Red Pack : 499$
Par rapport à la version nue, les versions « Pack » sont vendues 100$ plus cher. En contrepartie, elles incluront deux jeux (vraisemblablement Wolfenstein II et Prey) d'une valeur annoncée de 120$. L'achat d'une version Pack inclura également une réduction de 200$ dans le cas d'un achat simultanée avec un écran Samsung CF791 34 pouces, et de 100$ sur l'achat simultanée avec un Ryzen 7 et une carte mère X370.
Ces packs promotionnels seront disponibles, sous une forme ou sous une autre, chez certains revendeurs. Les modalités exactes restent à préciser et devraient varier selon les pays pour des raisons légales.
AMD voit dans ces packs une solution pour rendre disponibles plus de cartes pour les joueurs, même si nous sommes relativement circonspects sur cette raison. L'autre mesure prise par AMD - limiter l'achat à une carte par client chez les revendeurs - semble plus efficace pour contrer le problème.
AMD nous a indiqué qu'il s'attend à ce que et les packs, et les cartes nues soient disponibles simultanément au lancement, ce que l'on peut espérer. En pratique on notera que la version watercooling n'est disponible qu'en pack, et que le radiateur édition limité dont nous vous montrions les photos hier sera lui aussi réservé au Black Pack. Les modèles nus utiliseront un carter plus classique, noir, rappelant celui utilisé sur les 390X.
Notez que si les différents partenaires d'AMD devraient vendre ces cartes de référence sous leur marque, il faudra attendre au mieux la fin du troisième trimestre, ou le quatrième trimestre pour voir débarquer les modèles à refroidissement custom.
En ce qui concerne la date de lancement, AMD nous a indiqué que ces les Vega RX seraient disponibles pour le 14 août.
AMD lance la Radeon Vega Frontier Edition
Comme annoncé en mai lors d'une conférence destinée aux investisseurs, AMD lance officiellement ce jour la première carte basée sur son GPU Vega 10, les Radeon Vega Frontier Edition. Probablement fabriquée en petits volumes, elle va permettre à certains professionnels d'avoir un accès anticipé à la puce et de tenir la promesse faite aux investisseurs d'une sortie au cours du premier semestre !
Pour ces cartes, AMD a pu avoir accès à des puces de HBM2 de 8 Go chacune ce qui lui permet de disposer en associant deux sur l'interposer de 16 Go et d'une bande passante de 483 Go/s vu la fréquence de 945 MHz et le bus 2048-bits. La fréquence GPU maximale est de 1600 MHz, AMD met en avant une fréquence "typique" de 1382 MHz. En pointe AMD annonce 13.1 et 26.2 Tflops en FP16 et FP32, on est à des niveaux bien supérieurs à ce qu'offre Nvidia si ce n'est avec le GV100 bien plus cher.
C'est d'ailleurs du côté du deep learning qu'AMD axe une partie de sa communication, annonçant un score 33% plus élevé qu'une Tesla P100 sous Geekbench. Le constructeur évoque également des scores en la faveur de la nouvelle venue pour la visualisation 3D comparé à une GeForce Titan XP sous SPECViewperf 12.1, SPECapc Siemens NX 10 ou Cinebench, des domaines dans lesquels la Titan XP ne dispose pas de pilotes optimisés (malgré son prix) comme c'est le cas de la gamme Quadro. Au contraire la Radeon Vega FE propose des pilotes permettant de passer d'un mode Pro à un mode Gaming, ce qui active des optimisations spécifiques à l'un ou l'autre de ces usages.


Deux versions sont annoncées, la première est refroidie par une turbine et annoncée à 999$ pour une disponibilité mondiale immédiate... théorique, elle est en fait peu référencée et difficilement trouvable. La seconde dispose d'un watercooling AIO et arrivera au cours du troisième trimestre à 1499$ ! La version air dispose d'un TBP (Typical Board Power) "inférieur à 300W", sur la seconde ce chiffre monte à 375W ce qui devrait aider à maintenir une fréquence élevée. La Radeon Instinct MI25, purement destinée au calcul et qui arrivera en juillet, est à 300W mais disposera de fréquences plus limitées puisqu'elle affiche 12.3 et 24.6 Tflops en FP16 et FP32.


Quid de la Radeon "classique" ? Aux dernières nouvelles elle devrait enfin être annoncée lors du salon Siggraph qui ouvre ses portes le 30 juillet prochain, avec une disponibilité dans les semaines qui suivent.
Radeon Vega Frontier Edition 16 Go: dispo fin juin
La première Radeon Vega sera la Frontier Edition disponible avant fin juin. Cette version 16 Go sera cependant réservée à une niche professionnelle.

A l'occasion du Financial Day annuel d'AMD, Raja Koduri a bien entendu parlé de Vega, sa future génération de GPU qui prendra place dans des Radeon haut de gamme pour joueurs (Radeon RX), stations de travail (Radeon Pro) et serveurs (Radeon Instinct).
Après avoir fait le tour des marchés potentiels sur lesquels AMD va pouvoir revenir grâce à cette nouvelle génération de GPU, et après avoir rappelé les quelques points d'architectures dévoilés en janvier, Raja Koduri a voulu s'attarder sur l'apprentissage machine (ou deep learning) qui est un domaine prioritaire pour AMD. C'est d'autant plus le cas qu'il intéresse particulièrement les investisseurs présents dans l'auditoire.

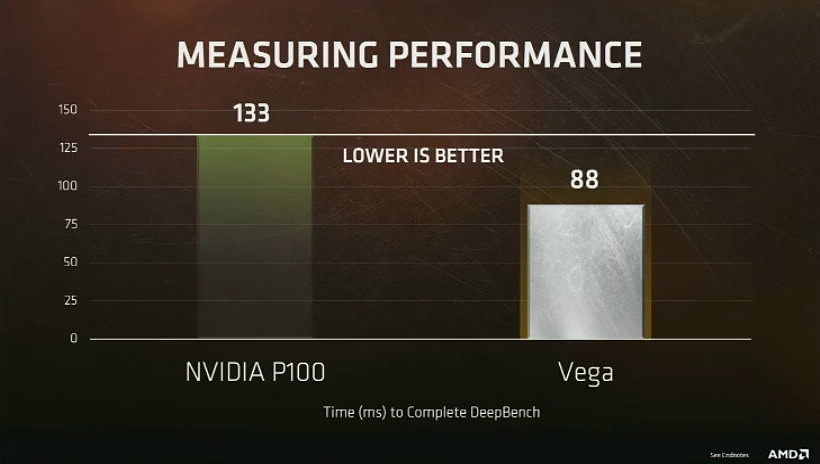
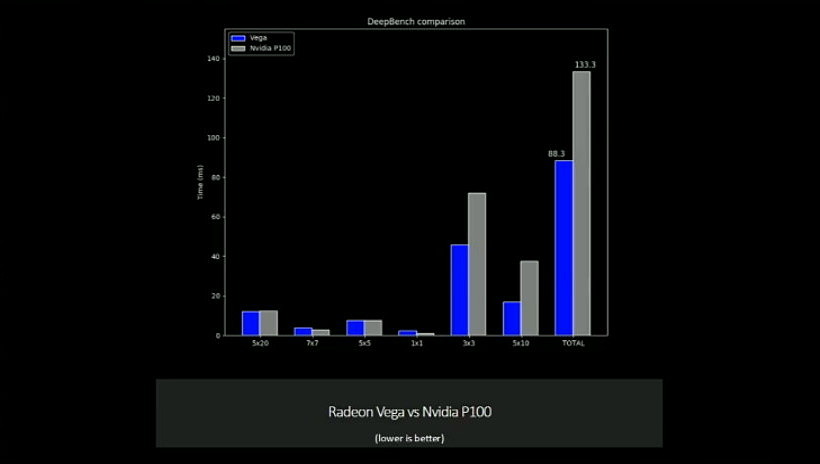
Nous avons droit à une première démonstration sous DeepBench avec un GPU Vega capable de surpasser le GP100 actuel de Nvidia de +/- 50%. Raja Koduri insiste cependant sur le fait que le but de la démonstration est avant tout de situer AMD sur la carte du deep learning et pas de se focaliser sur la confrontation avec Nvidia qui vient d'ailleurs d'annoncer le successeur du GP100. Par ailleurs, c'est toute une plateforme dédiée au deep learning que pourra offrir AMD avec Naples, Vega et son écosystème logiciel ROCm qui s'enrichit progressivement.
Est ensuite venu le moment de l'annonce d'une première déclinaison qui sera disponible fin juin : la Radeon Vega Frontier Edition 16 Go.




Contrairement à ce qui était attendu, ce n'est pas une carte graphique haut de gamme dédiée aux joueurs qui est ici annoncée par AMD. La Radeon Vega Fronter Edition, probablement fabriquée en petits volumes, va permettre à certains professionnels d'avoir un accès anticipé au GPU Vega 10 associé à 16 Go de mémoire HBM2. Viendront plus tard des Radeon Pro et Radeon Instinct (MI25) plus largement distribuée et qui profiteront d'un écosystème plus mûr. La Radeon Vega Frontier Edition s'inscrit dans la lignée de la Radeon Pro Duo (Fiji) et de la Radeon Pro SSG (avec SSD intégré), ou encore dans celle de la gamme Titan de Nvidia.

Quelques détails de plus ont été publiés par AMD dans la foulée. Nous pouvons ainsi découvrir que deux designs sont prévus, l'un a base de turbine, l'autre à base de watercooling. AMD communique ensuite un débit de pixels de 90 Gpixels/s, ce qui correspond à 64 ROP pour le GPU Vega 10, comme nous le supposions. Enfin, il est question d'une bande passante mémoire de 480 Go/s ce qui donnerait +/- 940 MHz pour la mémoire HBM2, ce qui se rapproche des 1 GHz attendus au départ et s'éloigne des récentes rumeurs qui faisaient plutôt état de 800 voire 700 MHz.

La seconde déclinaison annoncée aujourd'hui est la Radeon Pro Vega SSG qui sera également équipée de 16 Go de HBM2 auxquels AMD fait référence en tant que High Bandwidth Cache. Ce qui prend tout son sens ici puisque cette carte sera également équipée d'un SSD NVMe de 2 To. De quoi pouvoir conserver des datasets énormes à proximité du GPU. Restera évidemment à voir, au-delà des démonstrations d'AMD, avec quelle efficacité le tout sera piloté par le nouveau contrôleur du GPU Vega. Elle sera commercialisée dans quelques mois.
Les joueurs resteront bien évidemment sur leur faim puisqu'aucune annonce concrète n'a été effectuée par Raja Koduri concernant les déclinaisons grand public de Vega. Seront-telles disponibles fin juin également ou un peu plus tard ? Nous aurons peut-être quelques indices à ce sujet à l'occasion de la présentation d'AMD qui aura lieu dans 2 semaines au Computex.
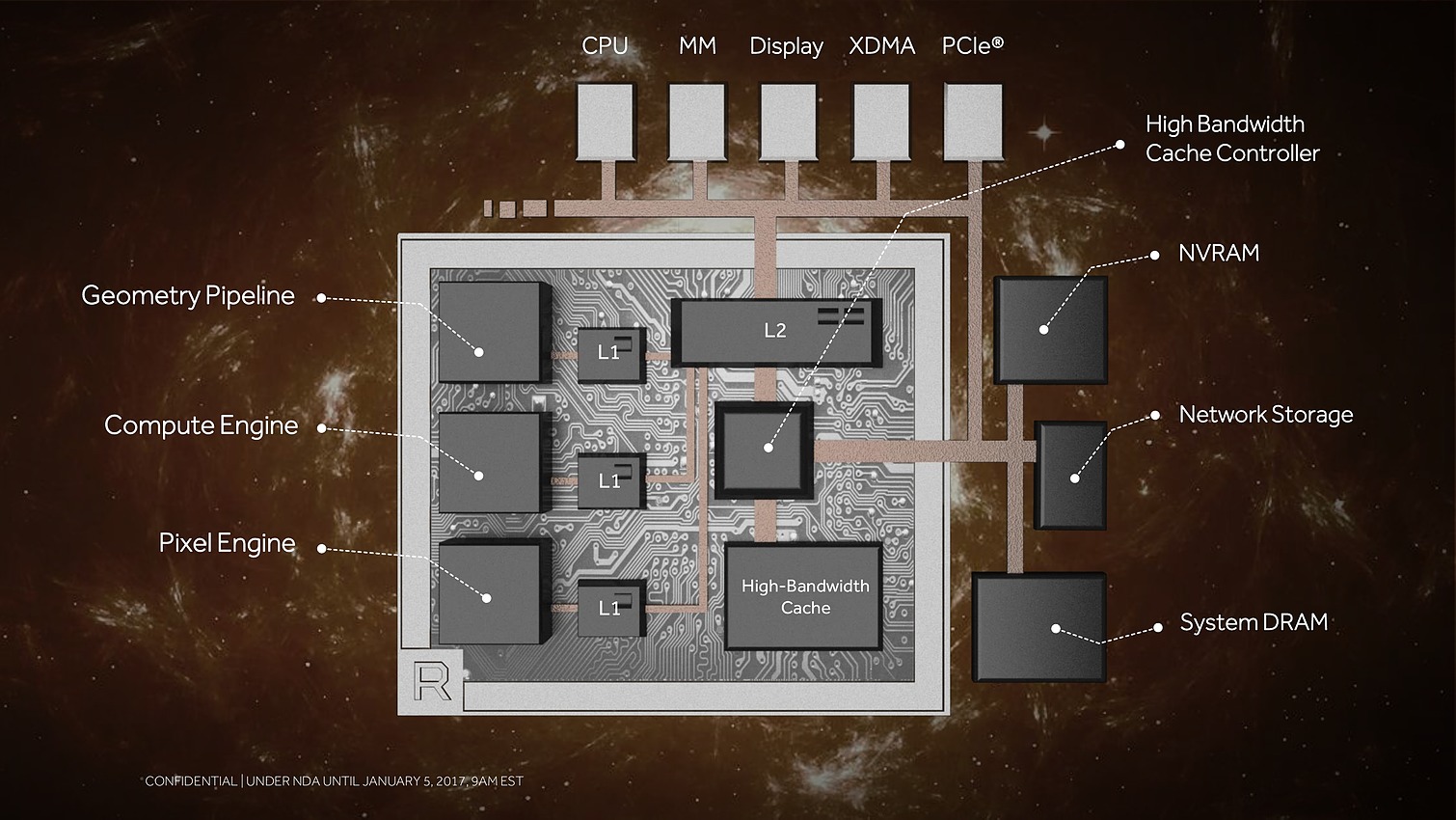
Architecture Vega 10 : AMD lève le voile
A l'occasion du CES, AMD nous en dit un petit peu plus sur le futur GPU Vega 10 et dévoile quelques points techniques de son architecture qui vont permettre d'améliorer le rendement en jeu et de monter en puissance dans le monde de l'intelligence artificielle.

Suivant la même formule que l'an passé avec Polaris, AMD a décidé de nous aider à patienter en dévoilant quelques éléments de sa nouvelle architecture GPU, dont le premier exemplaire, Vega 10, vise le haut de gamme et est annoncé pour le premier semestre 2017.
Au menu : une refonte du sous-système mémoire pour pouvoir prendre en charge une masse de données toujours plus imposantes, de nouveaux moteurs géométriques pour mieux traiter des décors plus riches, de nouveaux moteurs de rastérisation pour calculer moins de pixels inutiles et des unités de calcul plus efficaces pour donner un coup de boost à leurs performances.
A travers cette annonce, AMD explique avec quelques détails techniques comment ces évolutions ont été mises en place.

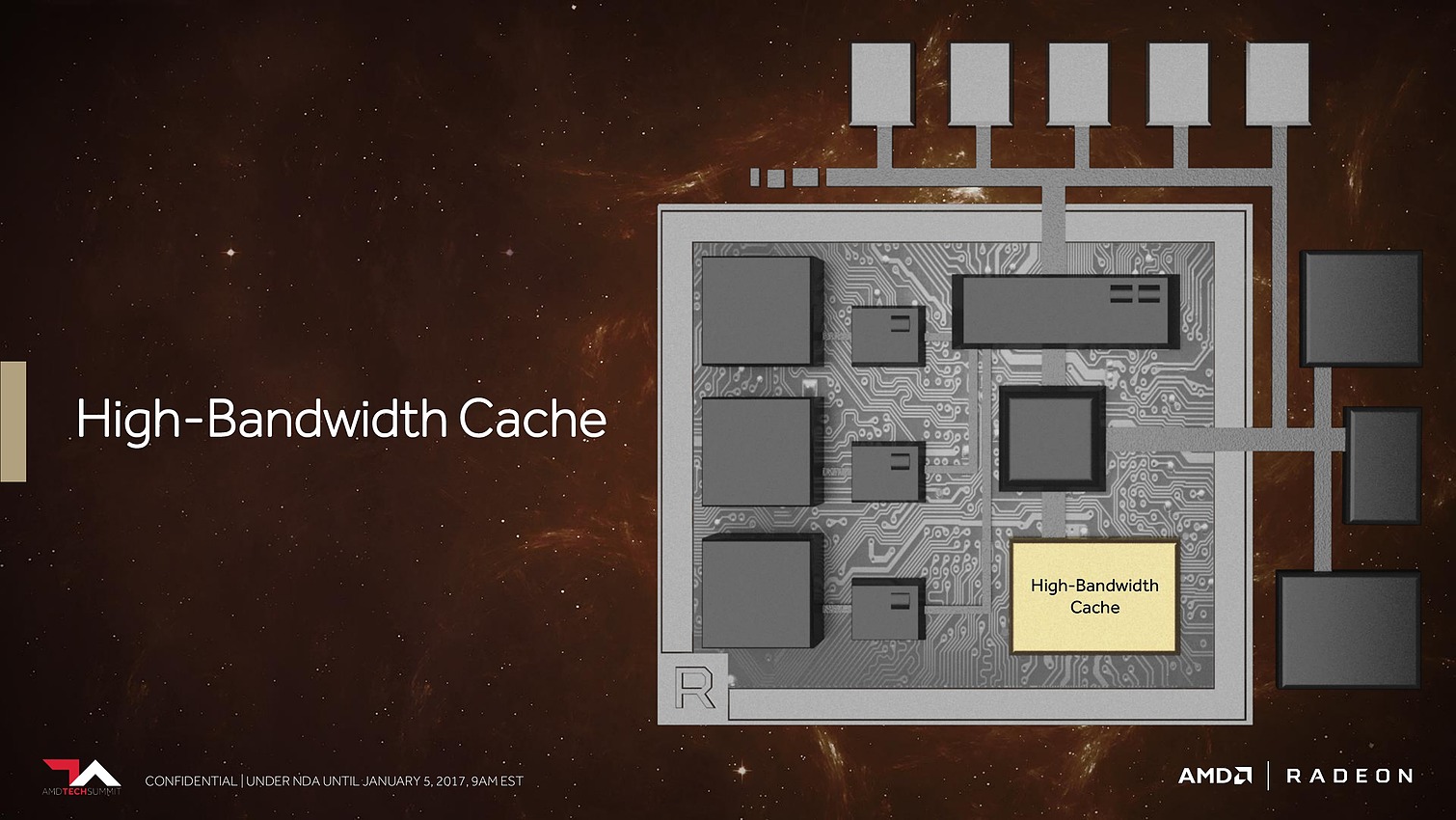


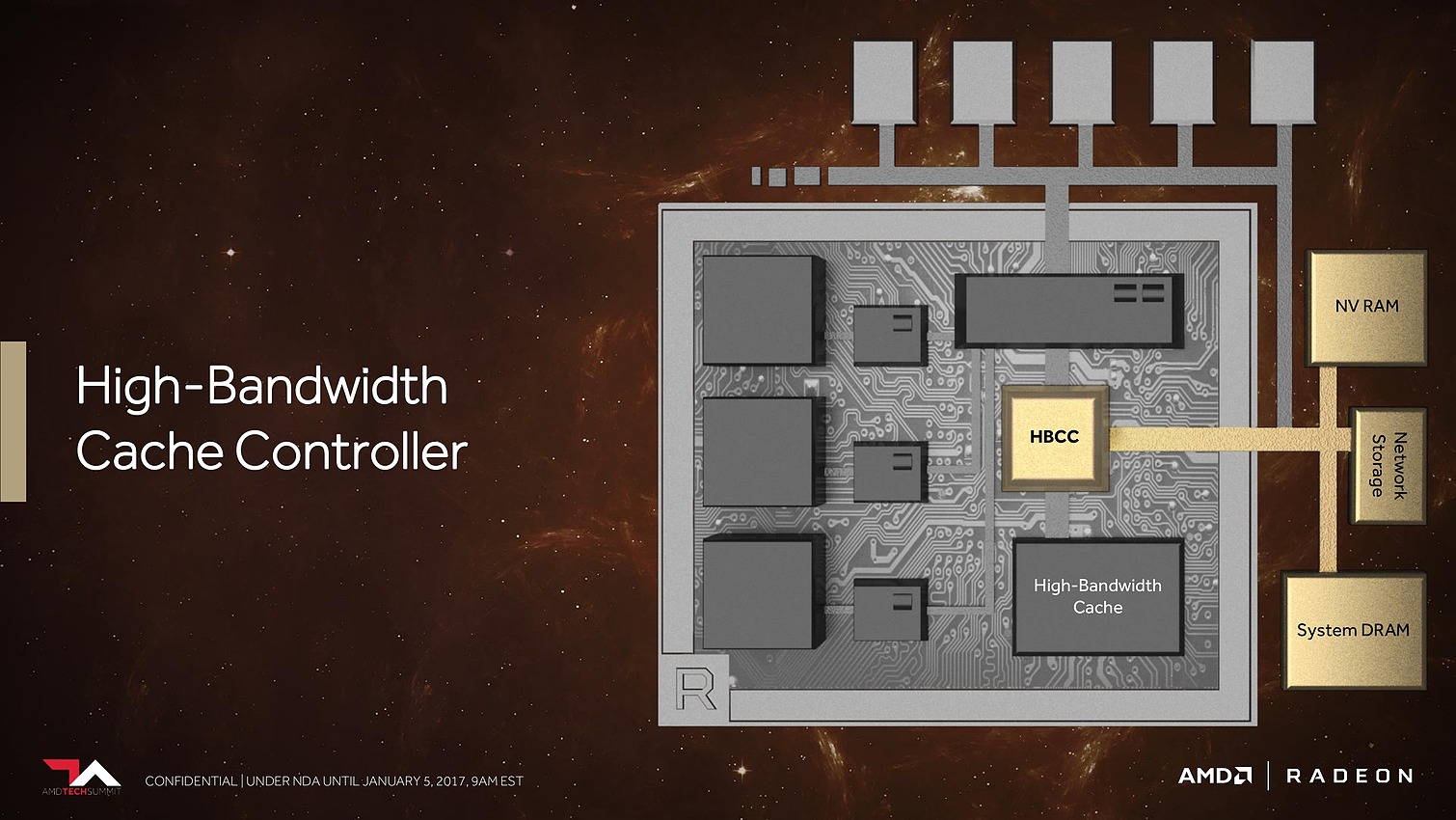


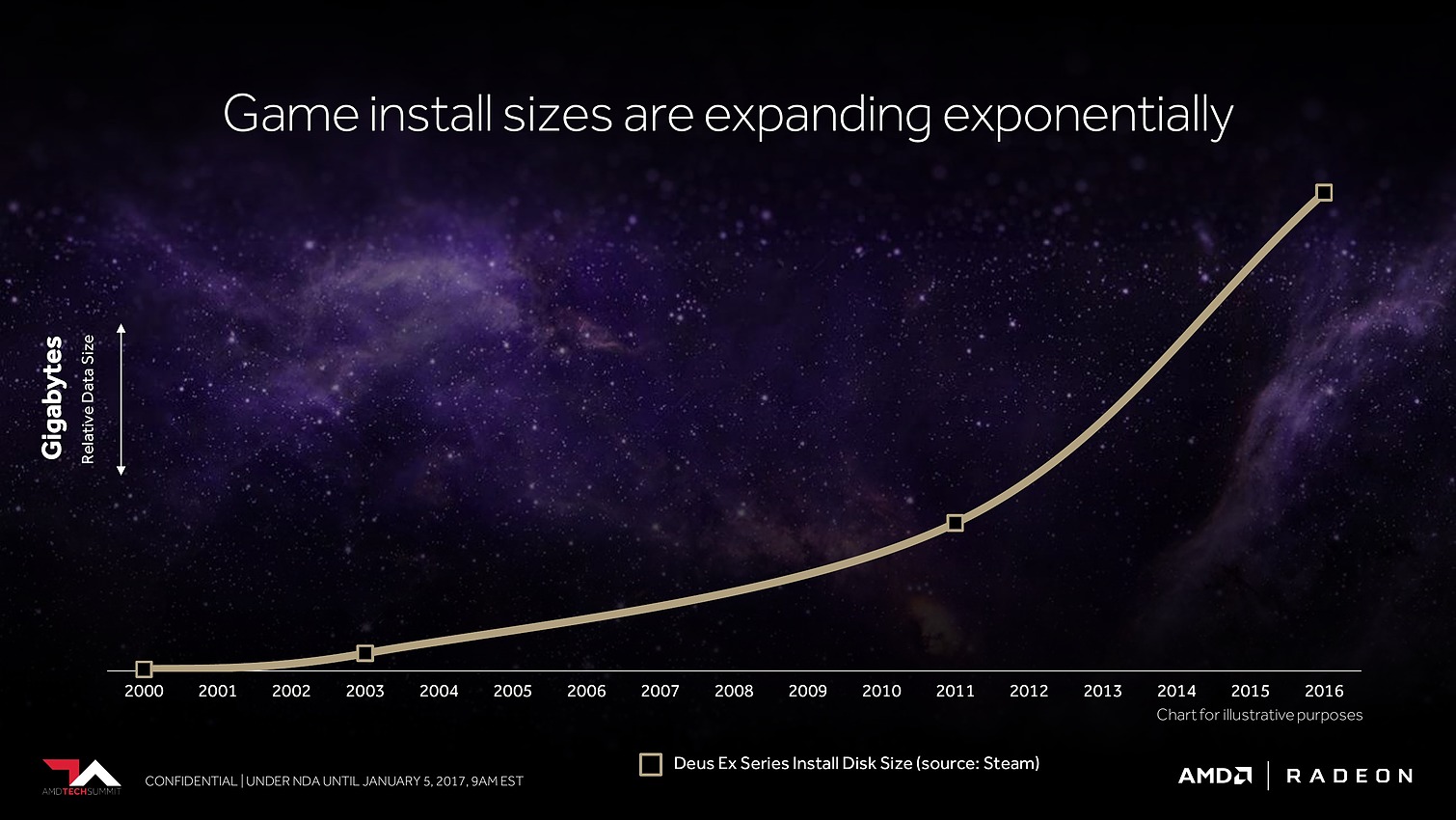
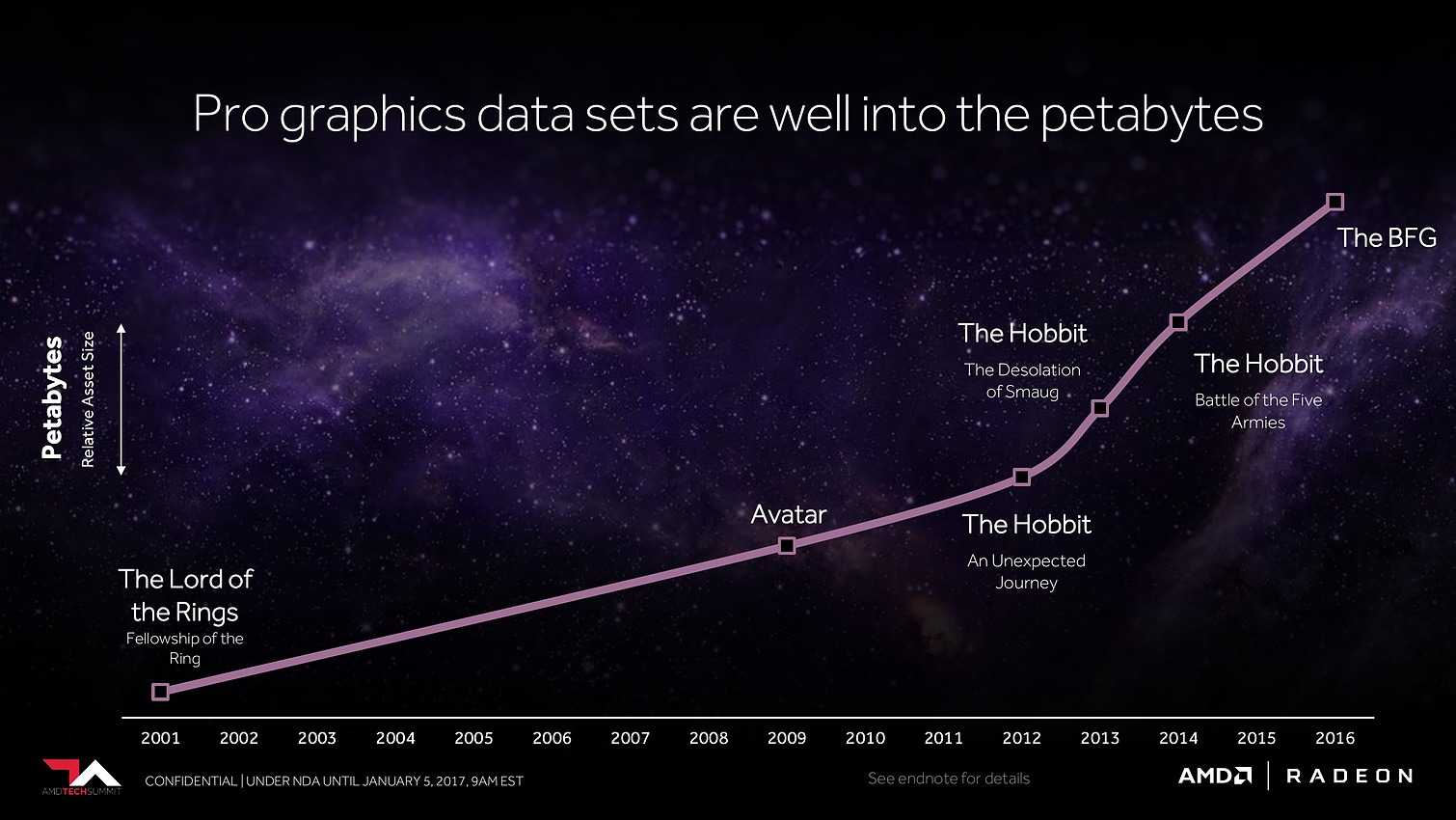
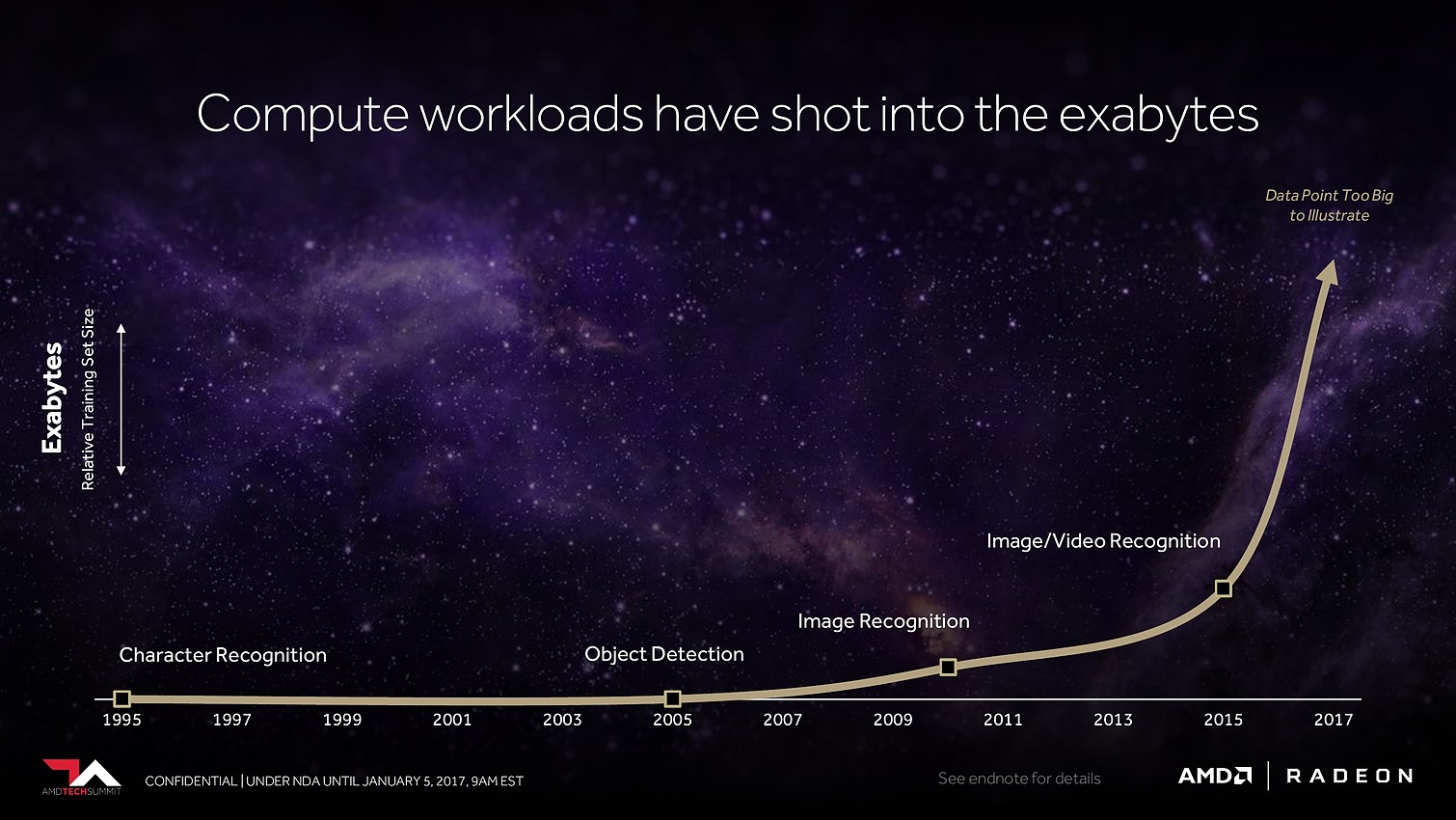
Avec Vega, AMD annonce avoir mis en place l'architecture mémoire pour GPU la plus avancée du marché, pour pouvoir répondre aux besoins actuels et futurs dans les domaines où la taille des data sets est en train d'exploser. Il serait déjà question de pétaoctets dans l'animation 3D voire même d'exaoctets dans le GPU computing et l'intelligence artificielle. Pour s'y attaquer, Vega est capable d'adresser jusqu'à 512 To grâce à un espace de mémoire virtuelle étendu (49-bit) qui va au-delà des 256 To du x64 (48-bit).
Bien entendu, le GPU Vega 10 ne recevra pas autant de mémoire dédiée. Il sera associé à 2 modules de mémoire HBM2 pour un bus combiné de 2048-bit. Sur base des premiers modules disponibles qui sont de type 4 Go (4-Hi), Vega 10 sera ainsi associé à 8 Go de HBM2, mais pourra passer à 16 Go quand les modules 8-Hi seront disponibles.
8 Go, voire 16 Go, c'est bien peu par rapport aux data sets auxquels AMD compte s'attaquer. Pour pouvoir s'y attaquer plus efficacement, AMD a revu le contrôleur mémoire qui s'appelle dorénavant High Bandwidth Cache Controller alors que la mémoire HBM2 est présentée comme un cache local (High Bandwidth Cache). Le HBCC a été conçu et optimisé pour piloter les mouvements de données à partir de l'énorme espace adressable. Qu'elles se situent dans la mémoire système, dans de la flash rattachée au GPU ou ailleurs sur le réseau, le but est faire en sorte qu'à chaque instant un maximum de données utiles se retrouvent dans la HBM2.
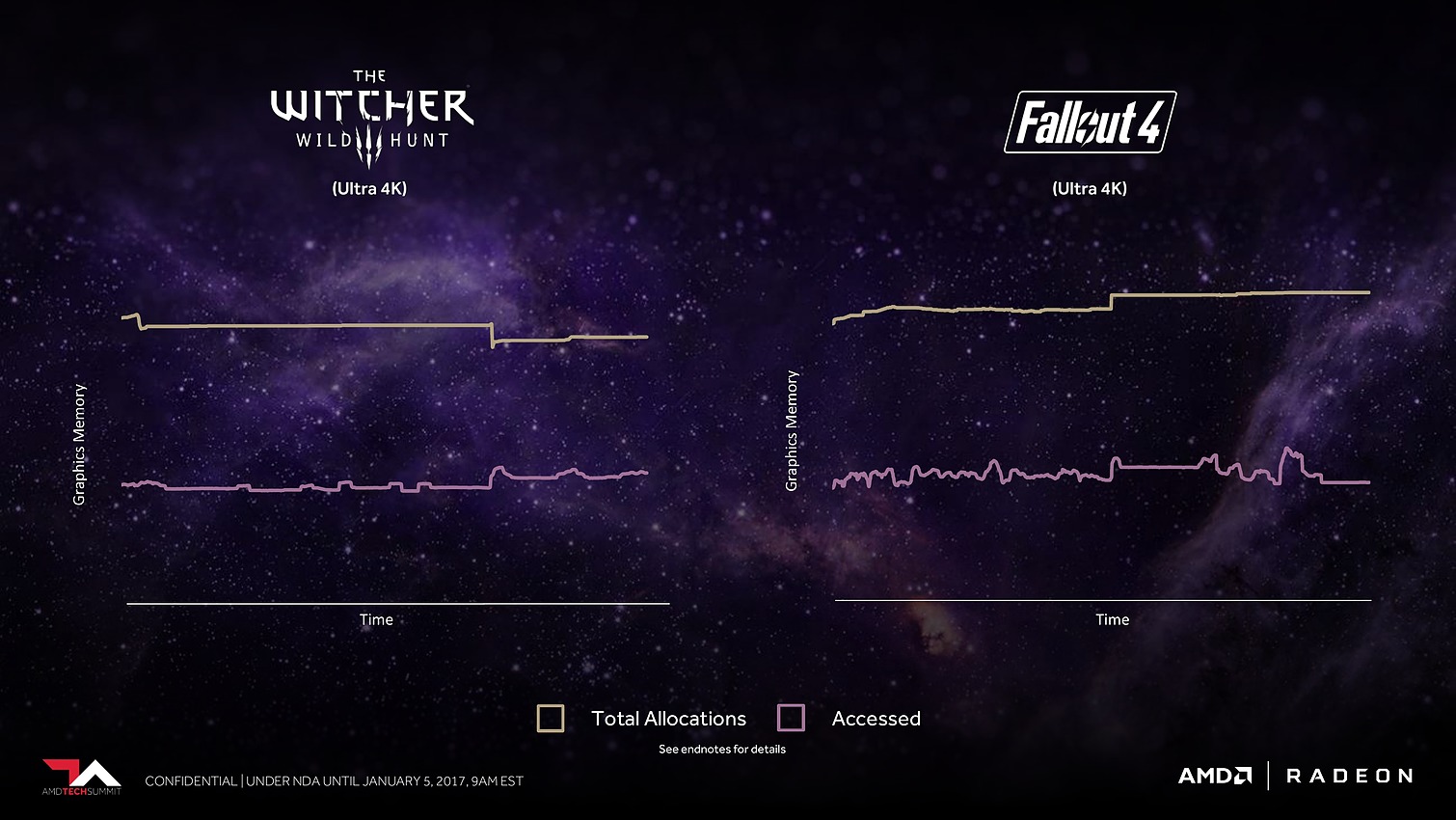
C'est évidemment principalement important dans le monde professionnel, mais AMD en parle également au niveau des jeux vidéo, probablement pour anticiper les critiques par rapport à une mémoire de "seulement" 8 Go contre 12 Go sur une Titan X de Nvidia. A ce sujet, AMD explique que pour chaque image générée moins de la moitié de la mémoire utilisée est réellement exploitée. Il y a donc des opportunités d'optimisation et le HBCC est annoncé comme capable de faire mieux que les contrôleurs et pilotes classiques.
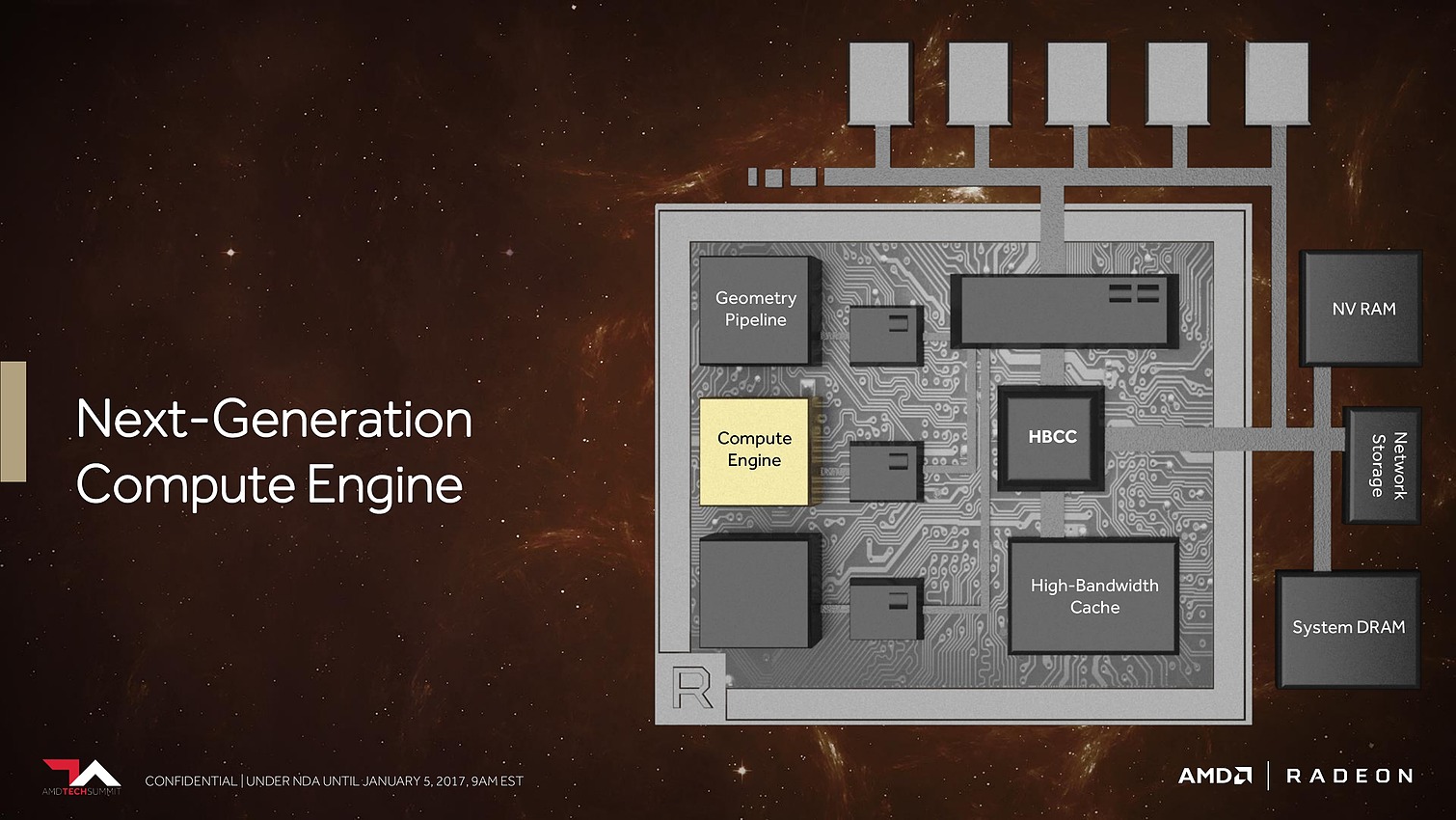



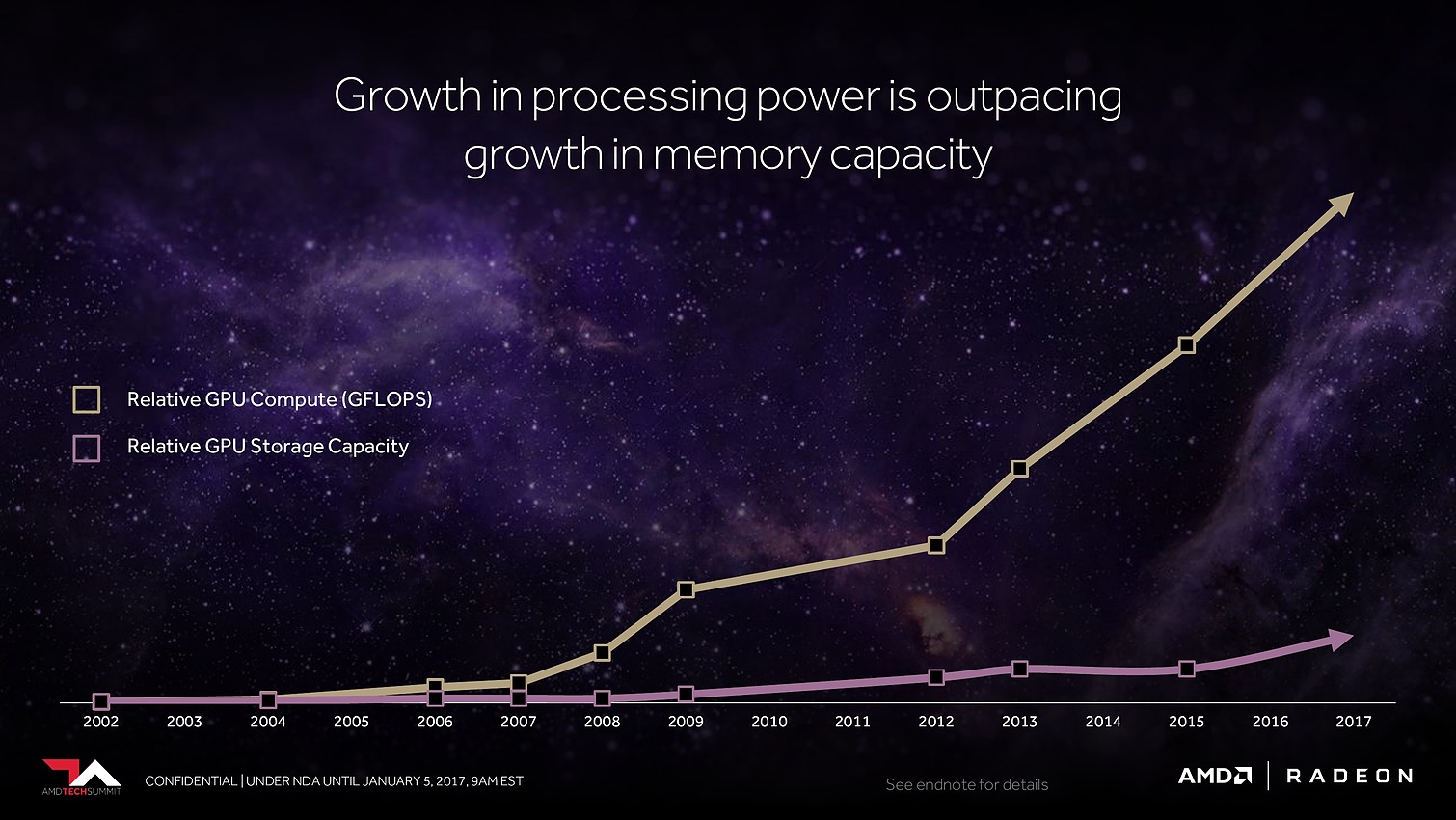
Ensuite, ce sont évidemment les unités de calcul qui vont recevoir quelques améliorations. AMD explique tout d'abord les avoir retravaillées pour autoriser une montée en fréquence significative, et réduire l'écart avec Nvidia sur ce point. Mais ce n'est pas tout et le taux d'IPC devrait également progresser. AMD en dit peu à ce niveau et s'est contenté de nous indiquer avoir élargi le cache d'instructions, ce qui boosterait notamment le débit d'opérations sur 3 opérandes. Reste évidemment à voir à quel niveau se situeront les gains en pratique pour ces Next-Gen Compute Units (NCU).
L'autre grosse nouveauté concernant les unités de calcul est le packed math qui représente le support natif de la démi précision ou FP16. Pour rappel, les GPU GCN 3 (Tonga/Fiji) et GCN4 (Polaris), supportent déjà le FP16 mais uniquement pour gagner de la place au niveau des registres, les opérations étant traitées par les unités de calcul FP32 à débit identique.
Avec Vega, chaque SIMD d'unité de calcul FP32 pourra travailler sur des vecteurs 2-way en FP16. C'est identique à ce que fait Nvidia sur le GP100 ou sur Tegra et cela permet de doubler la puissance de calcul en demi précision si le compilateur arrive à extraire des paires d'opérations à traiter en parallèle. AMD précise que si ce n'est pas le cas, des gains pourront malgré tout ressortir au niveau de la consommation énergétique, et que son approche permet de gérer indépendamment les parties hautes et basses des registres pour plus d'efficacité.
Enfin, AMD a ajouté le support du calcul en 8-bit mais il est spécifique au deep learning, comme le fait Nvidia sur GP102/104/106/107). Contrairement au FP16 il ne s'agit donc pas d'un support généralisé mais d'une ou de quelques instructions spécifiques telles que DP4A (produit scalaire avec accumulation).
Au final, AMD parle donc par NCU de 128 ops 32-bit par cycle (= 64 FMA FP32 comme sur tous les GPU GCN), 256 ops 16-bit par cycle (= 128 FMA FP16) et de 512 ops 8-bit par cycle (= 64 DP4A). Aucune information concernant le débit en FP64 qui est juste annoncé comme configurable.
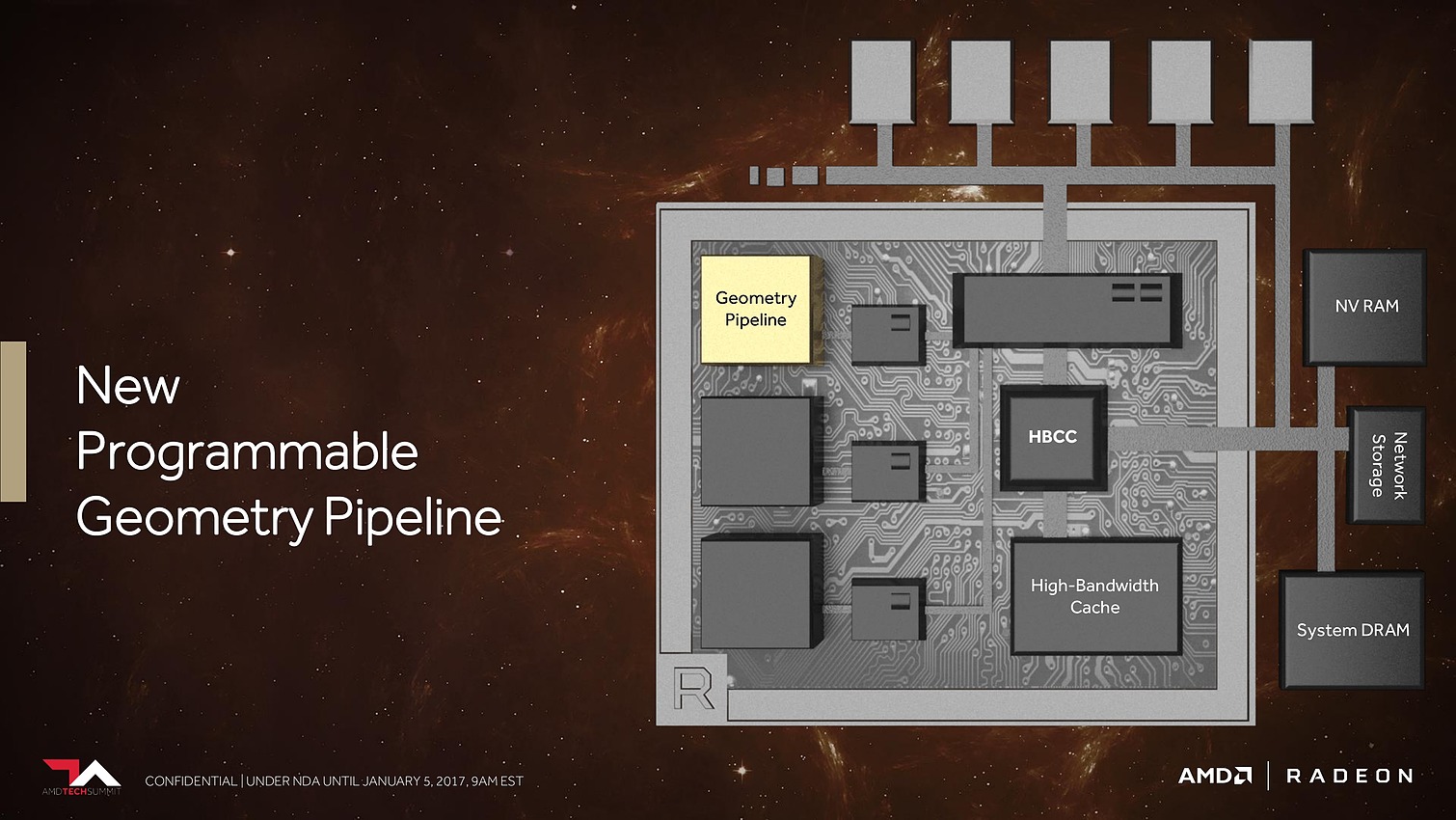

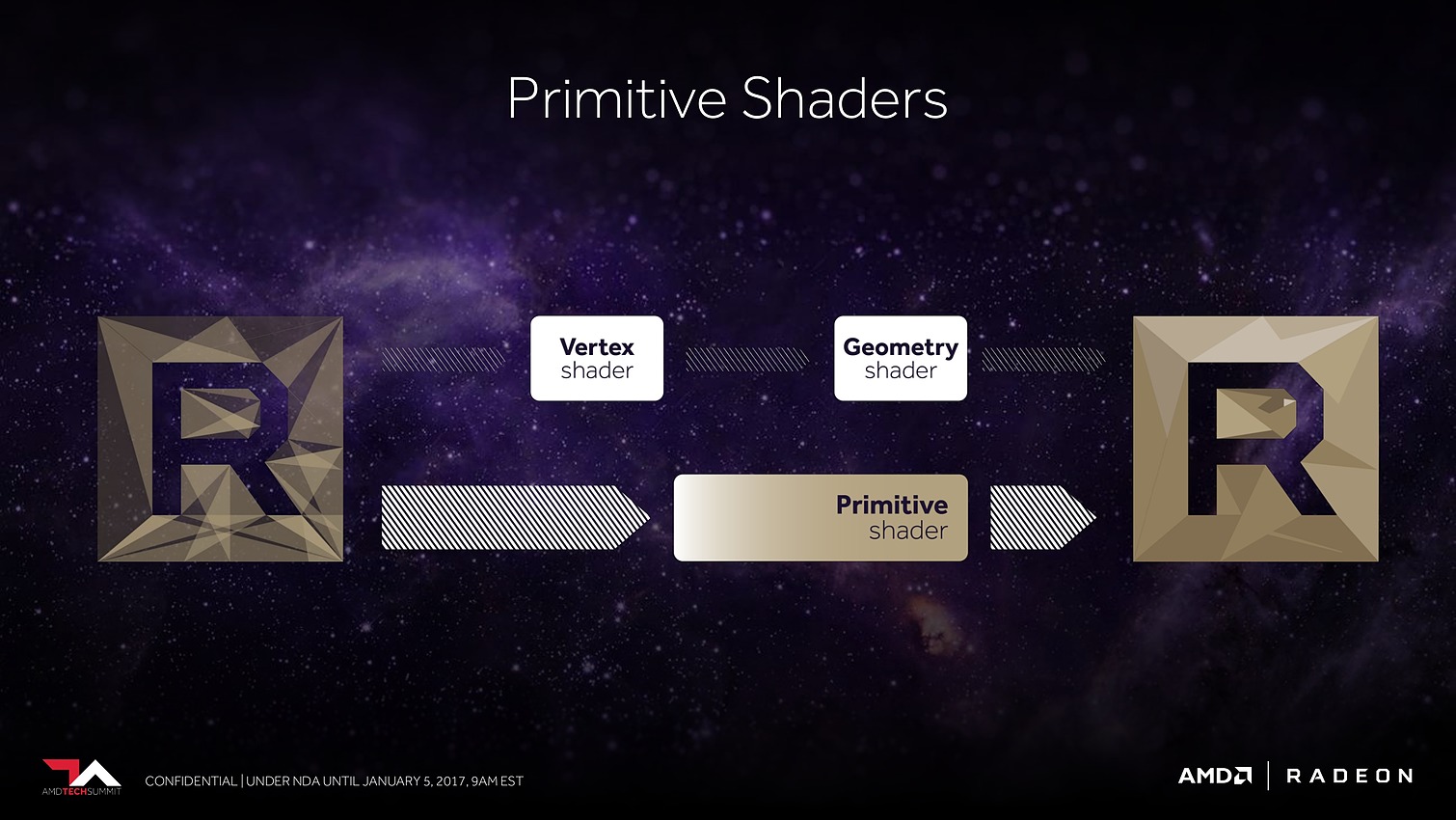
Plus spécifiquement pour le jeu vidéo cette fois, AMD a retravaillé ses moteurs géométriques sur 3 fronts. Tout d'abord leur débit va augmenter d'un facteur supérieur à 2x, AMD parle de 11 triangles par cycle avec 4 moteurs géométriques pour un GPU Vega, sans préciser s'il s'agit de Vega 10. Nous supposons qu'il s'agit ici du débit d'éjection des triangles qui tournent le dos à la caméra par exemple. Ce débit supérieur était jusqu'ici un des gros avantages des GPU Nvidia, qu'AMD devrait donc rattraper.
Ensuite, AMD proposera aux développeurs un nouveau type de shaders, les Primitive Shaders qui permettront de remplacer les Vertex Shaders et les Geometry Shaders. Nous ne savons pas exactement comment tout cela fonctionnera et sera exposé, mais cela devrait permettre de faciliter l'implémentation de pipelines de rendu personnalisés. AMD indique par ailleurs qu'ils permettront de booster le taux d'éjection des primitives mais nous ne savons pas si cela correspond au débit de 11 triangles par cycle noté ci-dessus ou si ce gain se fera en complément.
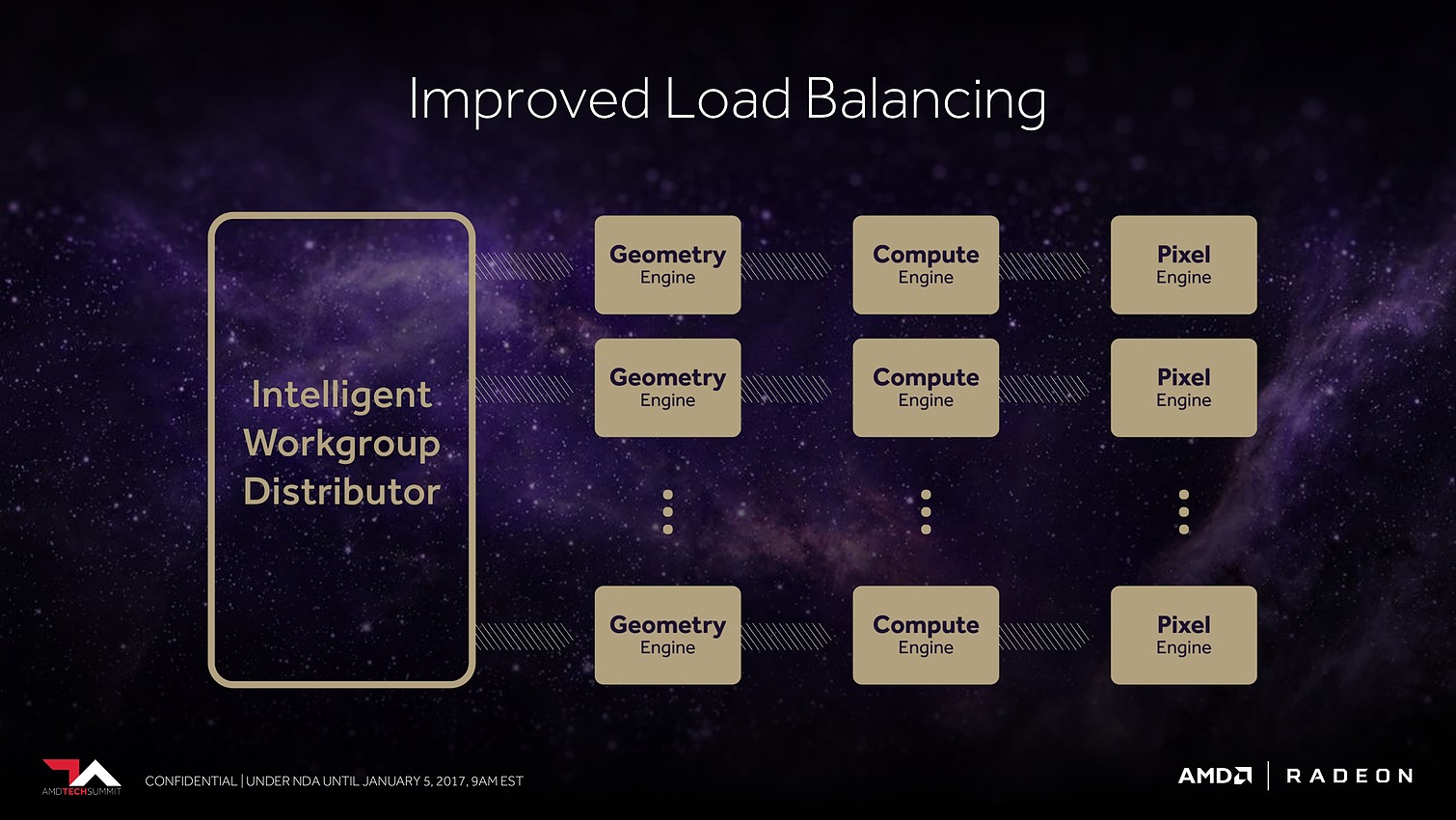
Enfin, suite à des retours constructifs de développeurs sur console, qui cherchaient à optimiser au maximum les performances, AMD s'est rendu compte que son algorithme de load balancing pouvait être amélioré pour mieux exploiter les ressources disponibles. Il a donc été revu.
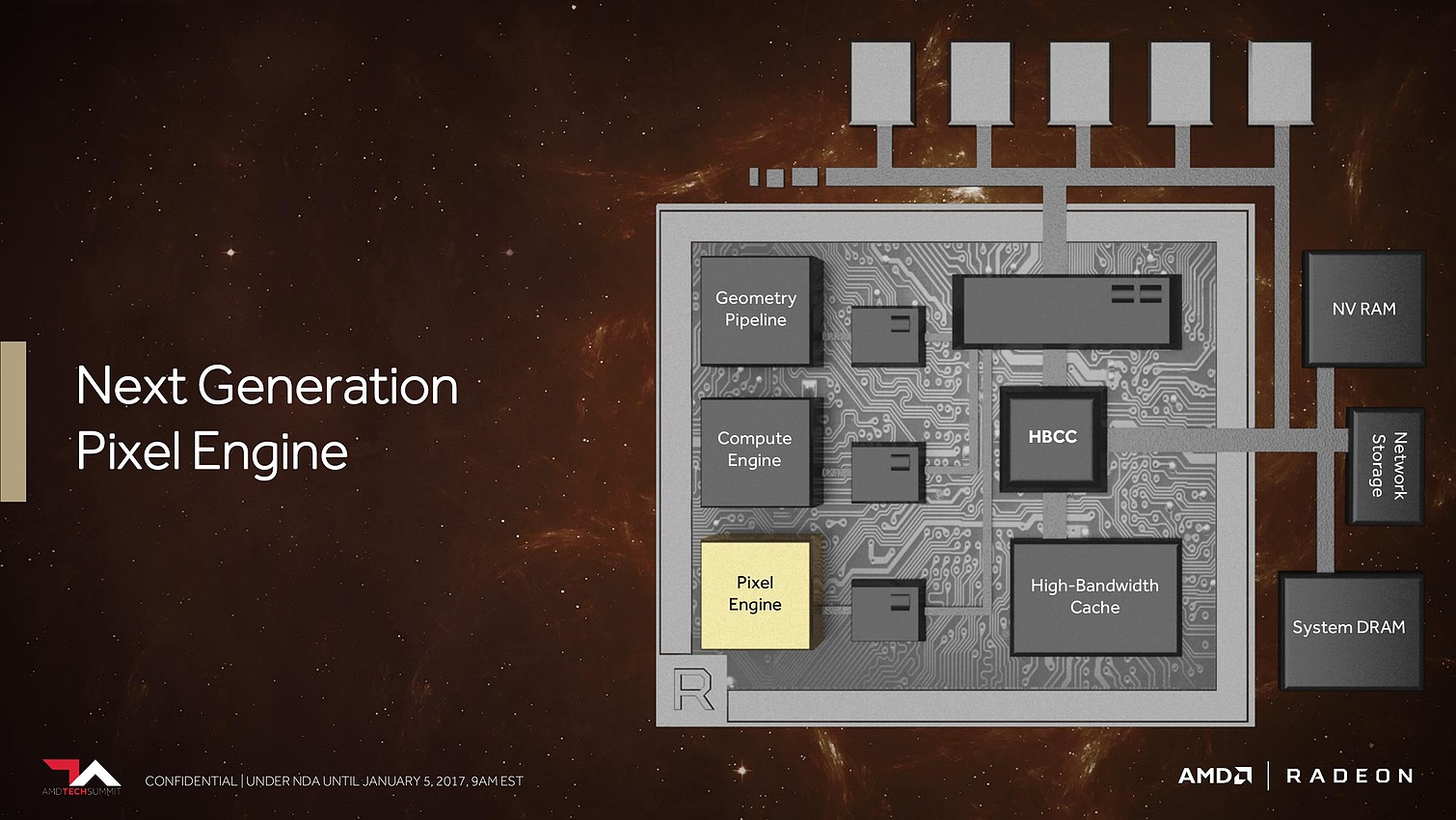

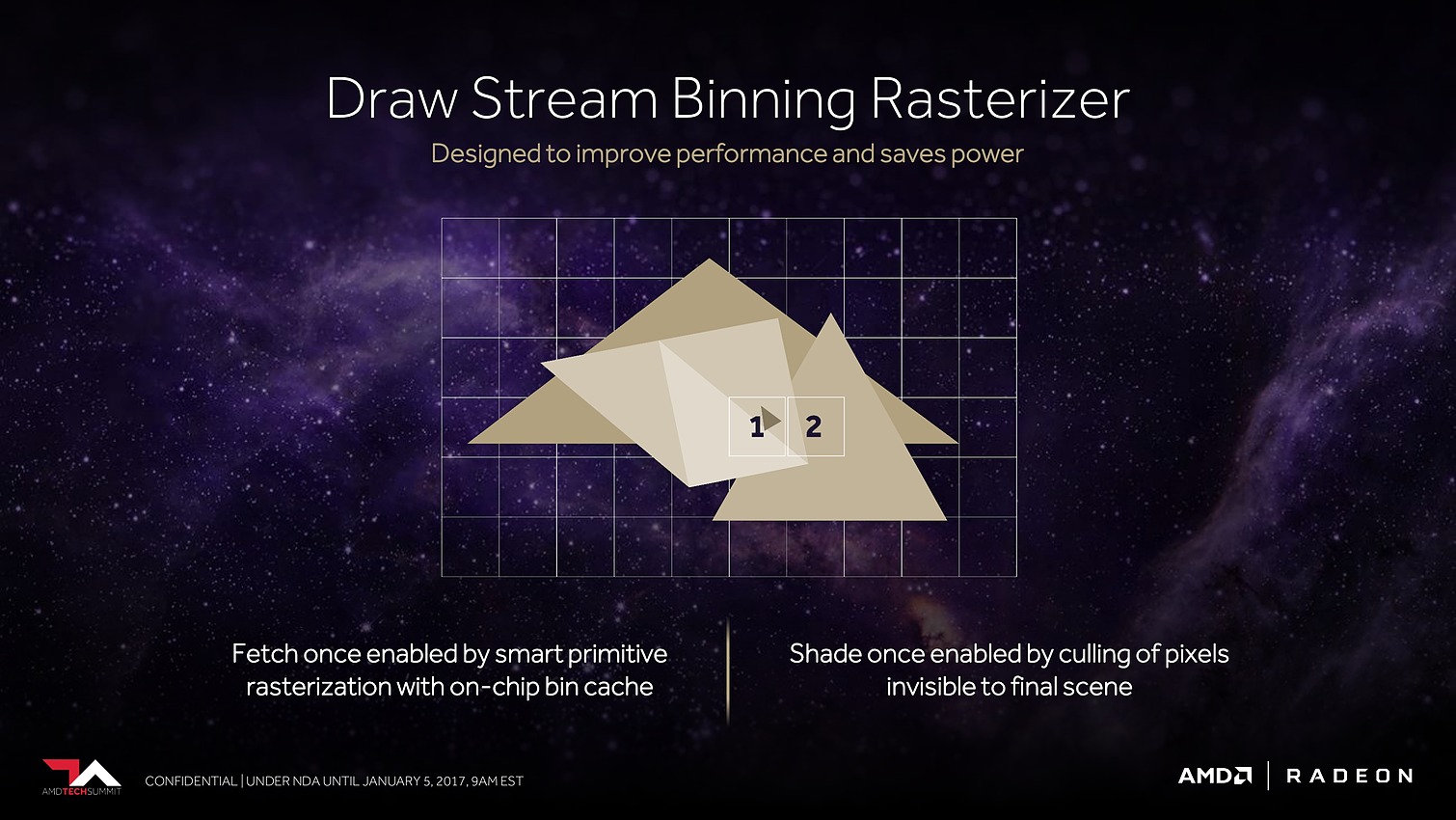

Le dernier point mis en avant par AMD concerne les pixels. Avec tout d'abord des moteurs de rastérisation revus. AMD parle de draw stream binning rasterizer. Derrière ce charabia technique se cache une approche similaire à celle exploitée par Nvidia sur les GPU Maxwell et Pascal. Elle consiste à faire une exploitation opportuniste du principe du tile renderingpour éviter de calculer trop de pixels masqués.
Il ne s'agit pas d'avoir recours à un rendu en 2 passes comme le font certains GPU mobiles pour appliquer fermement la technique, mais plutôt d'utiliser un petit buffer interne avant la rastérisation qui permet de traiter celle-ci quand l'information de couverture de plus de triangles est connue. Si ces informations permettent d'éviter de générer des pixels masqués, c'est tout bonus, si ce n'est pas le cas le traitement se fait de manière classique. D'où le côté opportuniste de la technique qui ne souffre pas des désavantages des approches des GPU mobiles.
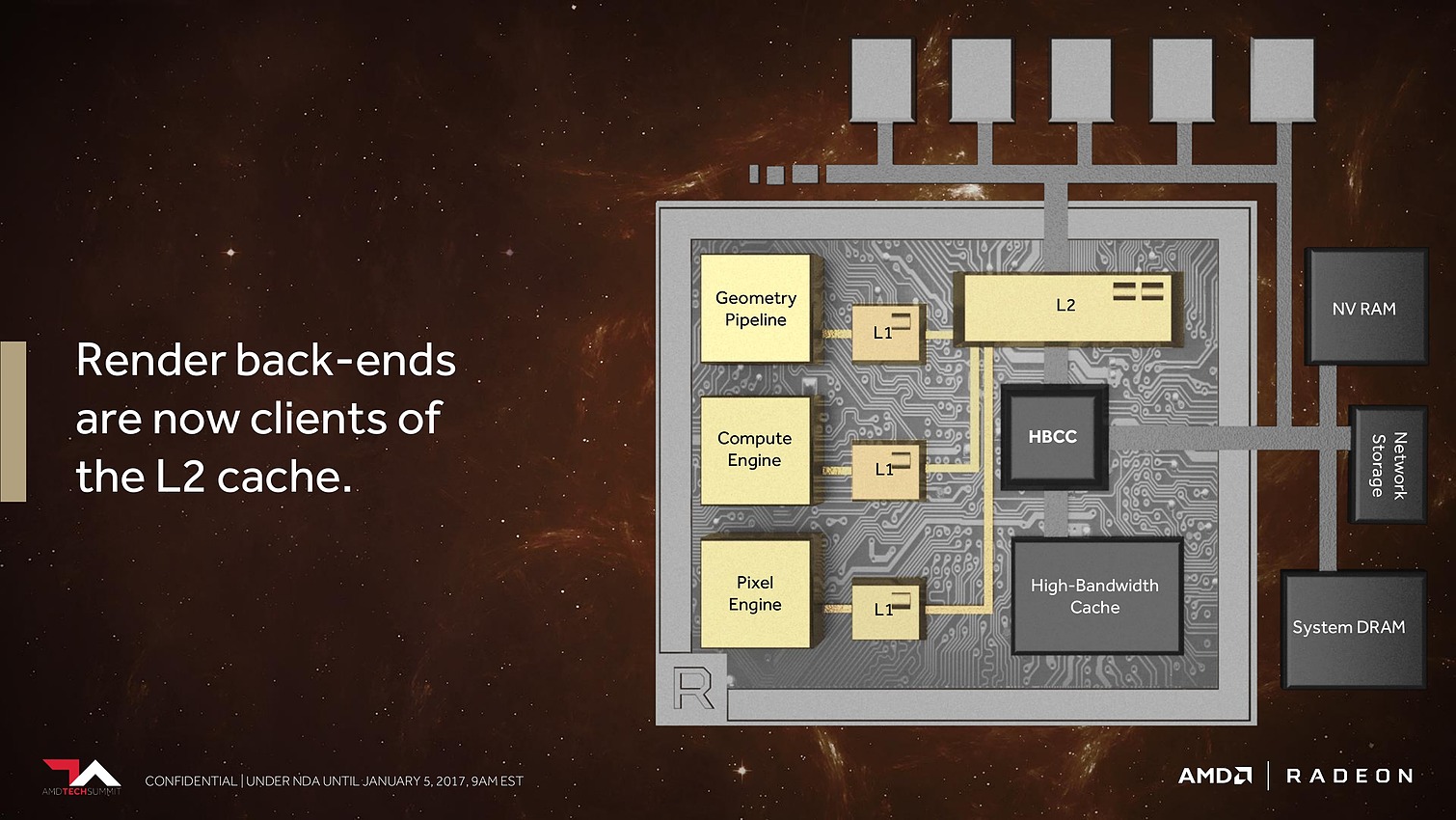
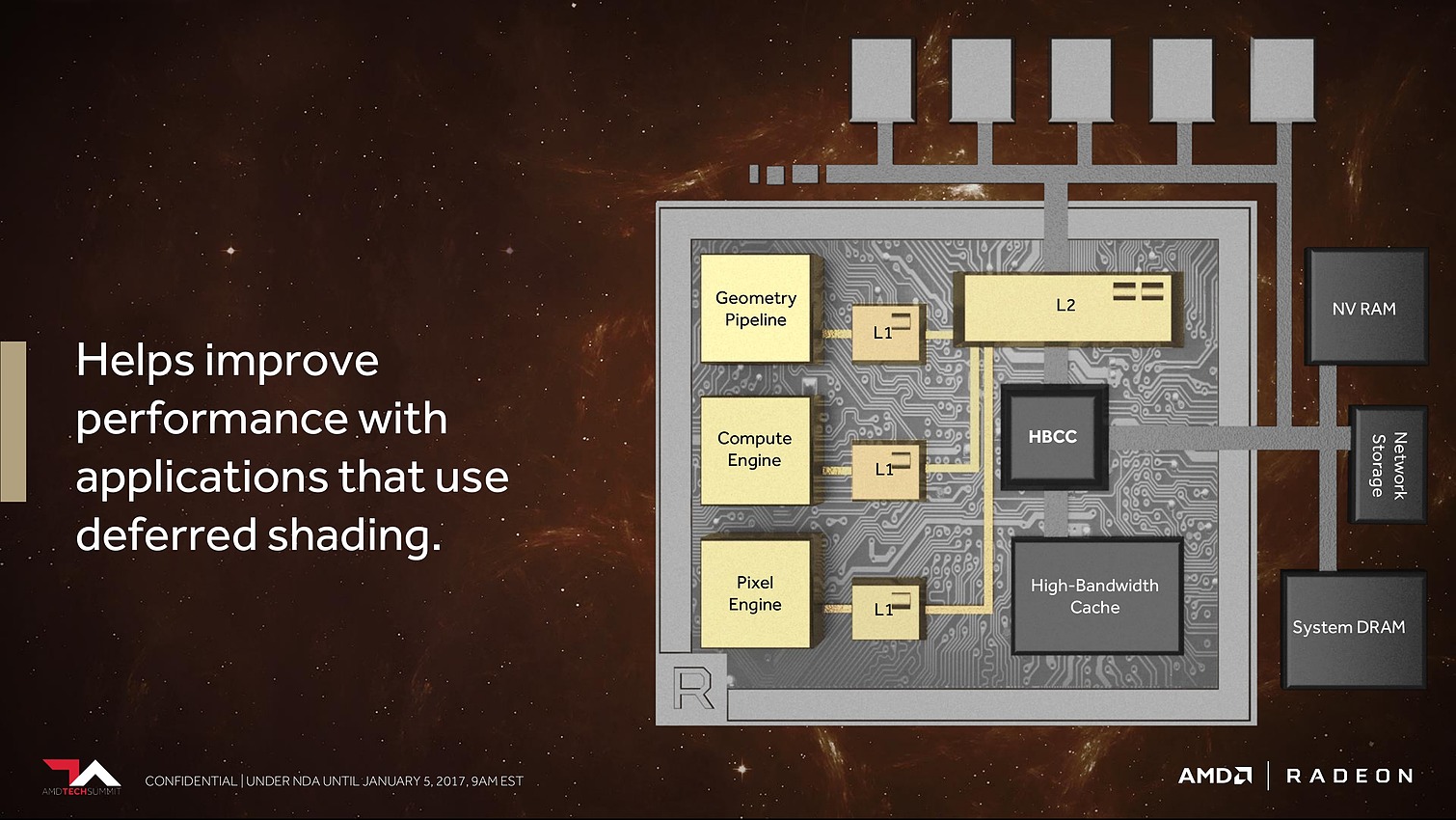
Les ROP ont eux aussi été revus. Leurs capacités exactes restent inconnues, mais au lieu d'exploiter de petits buffers spécifiques, ils deviennent des clients du gros cache L2. Selon AMD cela permet un gain appréciable dans les moteurs de type rendu différé qui sont devenus très courants dans les jeux vidéo.
Après ces quelques caractéristiques techniques de l'architecture Vega, intéressons-nous au GPU Vega 10 dans son ensemble. Physiquement tout d'abord puisque nous avons pu l'apercevoir brièvement dans les mains de Raja Koduri, responsable du groupe Radeon Technology (RTG) lors d'un évènement presse organisé par AMD le mois passé :

Nous pouvons apercevoir sur cette photo, prise rapidement au smartphone, un énorme die placé sur un interposer qui reçoit également 2 modules HBM2. Nous pouvons estimer la taille du die de Vega 10 entre 500 et 550 mm² (soit plus que les 471mm² du GP102, mais moins que les 610 mm² du GP100). C'est ce qui explique pourquoi AMD s'est contenté d'un bus 2048-bit, contrairement aux 4096-bit de Fiji dont les modules HBM1 prenaient beaucoup moins de place.
Pour pouvoir placer 4 modules HBM2 avec un gros die pour le GP100, Nvidia a de son côté recours à une double exposition très coûteuse, seule possibilité actuelle pour concevoir un interposer suffisamment grand pour recevoir l'ensemble. Avec Vega 10 AMD vise autant le marché professionnel que les joueurs et a donc opté pour une solution (un peu) plus raisonnable en termes de coûts de production.
Quelles pourraient être les spécifications complètes d'une Radeon basée sur le GPU Vega 10 ? Nous avons rassemblé dans le tableau qui suit nos suppositions actuelles basées sur les quelques éléments dévoilés par AMD, notamment lors de l'annonce de la Radeon Instinct MI25 :
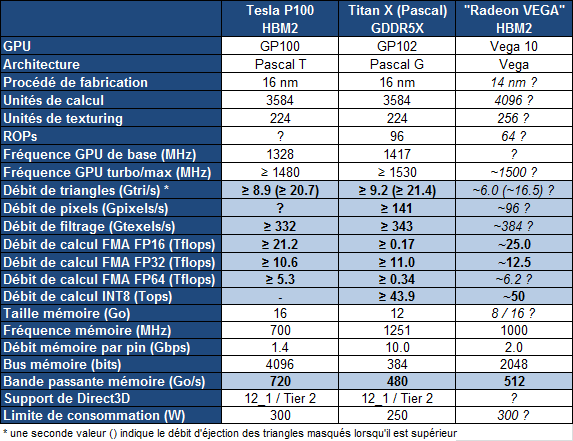
Reste bien entendu que pour pouvoir réellement concurrencer le GP102 (Titan X), et pas seulement se contenter de battre le GP104 (GTX 1080), il faudra que les avancées dévoilées aujourd'hui par AMD portent réellement leurs fruits en pratique.
Est-ce que le HBCC sera efficace dans le cadre du jeu vidéo si 8 Go deviennent insuffisants ? Est-ce que le FP16 sera exploité par certains jeux ? Est-ce que les développeurs seront intéressés par les Primitive Shaders ? Est-ce que le boost au niveau du débit des moteurs géométrique se retrouvera en pratique ? Quel sera le gain réel en terme d'IPC ? La nouvelle approche pour la rastérisation permettra-t-elle de rattraper Nvidia en terme d'efficacité ?
A l'heure actuelle, AMD ne nous fournit aucune information ou donnée pour permettre de quantifier ou de se faire une idée de ce que tout cela va apporter. Nous ne pouvons pas oublier que les avancées dévoilées de la même manière pour Polaris ont au final produit des résultats mitigés par rapport aux espérances suscitées (nous avons noté 8% de mieux en jeu entre GCN3 et GCN4). Avec Vega, nous avons par contre l'impression qu'AMD a enfin pris le recul nécessaire pour observer ce que Nvidia a fait de bien pour rendre plus efficaces ses dernières générations de GPU. De quoi s'engager dans une voie similaire avec Vega, ce qui laisse augurer de bonnes choses. Nous sommes évidemment impatients d'en savoir plus !
Vous pourrez retrouver l'intégralité de la présentation d'AMD ci-dessous :











Vega 10: 4096 unités, 1.5 GHz, 8 Go de HBM2 ?
Comme nous l'indiquions dans l'actualité consacrée aux Radeon Instinct, les premières informations officielles concernant Vega 10 sont de sortie. Pour rappel, il s'agit d'un futur GPU haut de gamme d'AMD basé sur une nouvelle architecture.
Parmi les informations dévoilées par AMD, notons l'exploitation de NCU (New Compute Units ?) avec support du packed math. Cette approche consiste à doubler la puissance de calcul en FP16 en modifiant les SIMD FP32 pour leur faire traiter des vecteurs 2D en FP16. C'est également ce que fait Nvidia avec le GP100 du Tesla P100 mais également sur ses derniers GPU intégrés aux SoC Tegra. Le FP16 peut être utile dans le cadre du GPU computing mais également dans celui du jeu vidéo lorsque la précision FP32 n'est pas nécessaire.
Les GPU Polaris n'offrent actuellement qu'un support limité du FP16 au niveau des registres, pour gagner de la place et de la bande passante à leur niveau. Avec Vega 10 tel que configuré sur la Radeon Instinct MI25, il sera en plus possible de doubler la puissance de calcul pour atteindre 25 Tflops en FP16 contre 12.5 Tflops en FP32. Un dernier chiffre qui représente plus du double d'une Radeon RX 480 et laisse penser que Vega 10 pourrait être équipé de 4096 unités de calcul et profiter d'une fréquence d'au moins 1.5 GHz.
AMD a également communiqué une consommation de <300W pour son accélérateur. Vega 10 sera donc à priori gourmand et nous pouvons supposer qu'AMD se retrouvera avec des options similaires à celles qui se sont présentées avec Fiji : pousser la limite de consommation pour maintenir autant que possible la fréquence maximale (Fury X), limiter la consommation pour maximiser le rendement énergétique et proposer un design compact (Nano) ou un compromis intermédiaire adapté à l'environnement compétitif du moment.
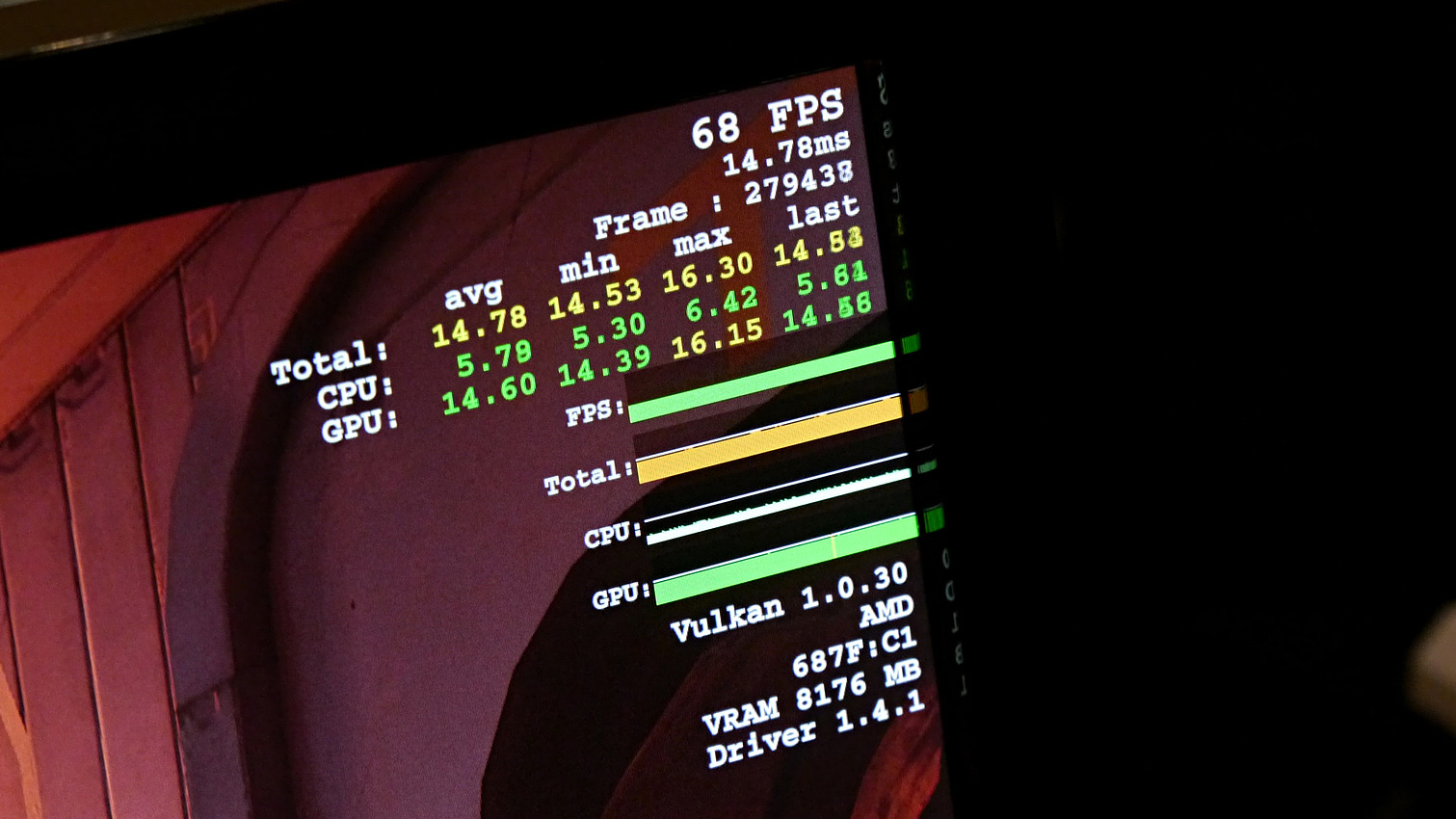
Mais une autre information qui était en principe sous embargo a été dévoilée par l'interface de Doom qui était en démonstration, comme l'ont constaté nos confrères allemands de Golem . Le prototype de Vega 10 exploité était équipé de 8 Go de mémoire.
Une information importante puisque les premiers modules HBM2 disponibles, et de toute évidence exploités ici par AMD, sont des modules 4Hi de 4 Go. En d'autres termes, Vega 10 exploiterait la HBM2 via un bus 2048-bit, ce qui correspondrait, avec un débit par pin de 2 Gbps, à une bande passante de 512 Go/s. Un chiffre identique à celui de Fiji et de sa mémoire HBM1 interfacée en 4096-bit.
Si une absence d'évolution sur ce point par rapport à Fiji peut sembler étrange, il y a probablement d'autres aspects à prendre en compte au niveau du sous-système mémoire de Vega 10. Par ailleurs il faut rappeler qu'une Radeon RX 480 se contente de 256 Go/s et que la Titan X plafonne à 480 Go/s. Attendez-vous à ce que plus d'informations soient communiquées d'ici quelques semaines.