
Actualités informatiques du 17-11-2011
- Hynix et Micron victorieux contre Rambus
- ASUS Rampage IV Formula
- Nvidia, PGI et Cray dévoilent OpenACC
- Intel présente Knights Corner et ses 50+ coeurs
| Novembre 2011 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
Hynix et Micron victorieux contre Rambus



 La société Rambus vient de perdre un procès important contre les fabricants de mémoire Micron et Hynix. Lancé en 2004, cette procédure antitrust visait à l'époque quatre acteurs du marché de la SDRAM : Samsung, Infineon, Hynix et Micron. Ces sociétés étaient accusées par Rambus d'avoir conspiré pour éliminer la mémoire RDRAM du marché, notamment en limitant la production et en augmentant les prix, à la faveur du standard SDRAM. Samsung et Infineon avaient trouvé un accord à l'amiable avec Rambus (contre 800 et 150 millions de dollars), tandis que Micron et Hynix ont préféré aller jusqu'au procès. Rambus indiquait que la perte de ventes subie atteignait 3.95 milliards de dollars.
La société Rambus vient de perdre un procès important contre les fabricants de mémoire Micron et Hynix. Lancé en 2004, cette procédure antitrust visait à l'époque quatre acteurs du marché de la SDRAM : Samsung, Infineon, Hynix et Micron. Ces sociétés étaient accusées par Rambus d'avoir conspiré pour éliminer la mémoire RDRAM du marché, notamment en limitant la production et en augmentant les prix, à la faveur du standard SDRAM. Samsung et Infineon avaient trouvé un accord à l'amiable avec Rambus (contre 800 et 150 millions de dollars), tandis que Micron et Hynix ont préféré aller jusqu'au procès. Rambus indiquait que la perte de ventes subie atteignait 3.95 milliards de dollars.
Le procès a été l'occasion de quelques éclaircissements sur l'utilisation de la mémoire RDRAM qui avait débuté en 1999 avec le chipset i820 dédié aux Pentium III. Un manager d'Intel aurait en effet témoigné qu'un accord complexe les liait à Rambus à l'époque et qu'une clause dans le contrat autorisait Rambus à bloquer les livraisons de processeurs (!) si certaines conditions de promotion marketing de la part d'Intel n'étaient pas réunies. Un attachement à cette clause de la part de Rambus aurait envenimé ses relations avec Intel et serait - sur un plan non technique - la véritable raison du non succès de la RDRAM.

Outre l'importance des dommages espérés par Rambus, cette défaite reste un événement rare pour la société qui jouissait jusqu'ici d'une certaine vista auprès des tribunaux, malgré le fait que la FTC et la commission européenne aient reconnu que la société avait trompé les membres du JEDEC (un consortium développant de manière ouverte les standards mémoire, auquel Rambus avait participé avant de le quitter) en déposant des brevets sur des technologies qui seraient adoptées dans le standard SDRAM, sans pour autant en avoir informé les autres membres du comité de standardisation comme le prévoyaient pourtant les statuts du consortium.
L'action de Rambus aura baissé de près de 61% après cette annonce. La société dispose encore de procès en cours pour l'utilisation des brevets dont nous parlions plus haut auprès de Micron et Hynix, mais également Nvidia qui reste l'un des rares acteurs majeurs du marché à avoir refusé de prendre un accord de licence avec Rambus (AMD en avait signé un en 2006).
ASUS Rampage IV Formula
Non content d'avoir déjà sorti 6 cartes mères X79 Express ASUSTeK en lance une 7ème, la Rampage IV Formula, qui devrait être disponible courant décembre.

Par rapport à l'Extreme, elle conserve l'étage d'alimentation processeur Extreme Engine Digi+ II à 8+3 phases, mais le nombre de DIMM passe de 8 à 4 et le nombre de PCI-Express x16 de 5 à 4 (en x16/x8/x16 avec 3 cartes et x16/x8/x8/x8 avec 4 cartes), ce qui devrait suffire dans 99,9% des cas.
Les options spéciales destinées à l'overclocking telles que les connecteurs pour thermocouple, les résistances variable pour l'overclocking GPU ou l'OC Key sont logiquement absentes mais l'adaptateur pour ventirad LGA 1366 X-Socket reste de la partie.
La partie réseau reste confiée à une puce Intel alors que la carte est pourvue de 6 USB 3 (dont 2 via un connecteur interne), 2 eSATA et 2 SATA 6G additionnelles en sus des 2 gérés par le X79 Express. ASUS annonce avoir particulièrement soignée la partie audio de la carte dénommée SupremeFX III.

Derrière cette dénomination on retrouve un codec HD Audio classique, a priori de chez Analog Digital, accompagné de la suite logicielle X-Fi MB2 et dont l'intégration a été particulièrement soignée afin d'éviter au maximum les interférences. Cela passe par une isolation de la partie audio au niveau du PCB, des condensateurs plus grande capacité et des prises jack plaquées or. Ceci permet à ASUS d'annoncer un rapport signal bruit qui atteindrait les 110 dB en pratique, contre 98 dB annoncés pour un design classique.
Il faut noter qu'une Rampage IV Gene, au format Micro ATX, est également prévu pour début 2012. Nous avons mis à jour notre focus sur les cartes X79 Express pour tenir compte de cette nouveauté.
Nvidia, PGI et Cray dévoilent OpenACC
Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
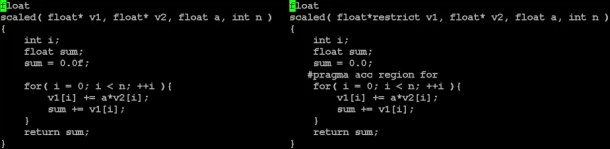
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .
Intel présente Knights Corner et ses 50+ coeurs
C'est dans le cadre d'une conférence dédiée au High Performance Computing, la SC11 qui se tenait cette semaine à Seattle qu'Intel a effectué une première présentation de sa puce MIC (Many Integrated Cores) Knights Corner.
Il s'agit du descendant direct du projet Larrabee qui devait avoir le double emploi d'être un GPU et un accélérateur de calcul. L'architecture de Larrabee reposait sur de multiples curs (32) reliés par un ring bus et composés chacun d'une unité x86 à laquelle était accolée une unité SIMD 512 bits.

Knights Corner avait été annoncé il y a un peu plus d'un an de cela par Intel comme un processeur prévu pour 2012 et équipé de 50 curs et gravé en 22 nm (Tri-Gate, voir notre présentation). Le communiqué de presse d'Intel confirme ces caractéristiques, indiquant cependant qu'il s'agira de "plus de 50 curs" sans préciser combien.
Intel a annoncé un premier chiffre de performances d'au moins un TeraFlop pour Knights Corner, en calcul virgule flottante double précision sous DGEMM (multiplications de matrices présentes dans la bibliothèque BLAS, utilisée notoirement par LINPACK/LAPACK), soit quasiment plus du double des performances maximales théoriques - qui sont loin d'êtres atteintes en pratique - des GPU actuels (515 GFlops pour Fermi/GF110 en version Tesla, 676 pour Cayman). Intel mettant en avant en plus la flexibilité de son architecture, due à l'utilisation d'un cur x86 généraliste (dérivé d'un Pentium P54C) pour piloter son unité SIMD, même s'il faudra attendre de voir la qualité des outils en pratique.

Le die Aubrey Isle des premiers Larrabee
Quelques détails ont également été confirmés comme le fait que Knights Corner, à l'image de Larrabee en son temps, fonctionne comme un système indépendant de l'hôte en faisant tourner son propre système d'exploitation (un noyau Linux) qui peut ainsi être adressé comme un nud à part entière dans une architecture HPC (les "programmes" Larrabee utilisent un couple de deux exécutables séparés, un pour l'hôte, un pour la carte).
Si Intel a bel et bien confirmé que Knights Corner serait le premier produit commercial issu de son architecture MIC, la date de 2012 évoquée précédemment n'a pas été confirmée officiellement.