
Actualité informatique du 17-05-2012
Archives
| Mai 2012 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 | |||
GTC: Plus de détails sur le GK110
Publié le 17/05/2012 à 04:40 par Damien Triolet



Lors d'une session technique sur l'architecture du GK110, nous avons pu apprendre quelques détails de plus à son sujet par rapport aux premières informations d'hier. Des détails bien entendu concentrés sur la partie compute de ce GPU. Tout d'abord, Nvidia propose cette fois un schéma de l'architecture qui montre sans ambiguïté que le GK110 est composé de 15 SMX de 192 unités de calcul, soit un total de 2880, et d'un bus mémoire de 384 bits.

On apprend par ailleurs que le cache L2 passe à 256 Ko par contrôleur mémoire 64 bits, soit un total de 1.5 Mo contre 768 Ko pour le GF1x0 et 512 Ko pour le GK104. Tout comme pour le GK104, chaque portion de cache L2 affiche une bande passante doublée par rapport à la génération Fermi.
Les blocs fondamentaux d'unités de calcul, appelés SMX dans la génération Kepler, sont similiaires pour le GK110 ceux du GK104 :

Le nombre d'unités de calcul simple précision est identique, tout comme le nombre d'unités dédiées aux fonctions spéciales, aux lectures/écritures, au texturing Les caches sont également identiques que ce soit les registres, le L1/mémoire partagée, les caches dédiés aux texturing.
La seule différence fondamentale réside dans la multiplication des unités de calcul en double précision qui passent de 8 pour le GK104 à 64 pour le GK110. Alors que le premier est 24x plus lent dans ce mode qu'en simple précision, le GK110 n'y sera que 3x plus lent. Couplé à l'augmentation du nombre de SMX, cela nous donne un GK110 capable de traiter 15x plus de ces instructions par cycle ! Par rapport au GF1x0 il s'agit d'un gain direct de 87.5% à fréquence égale.
Dans le GK110, tout comme dans le GK104, chaque SMX est alimenté par 4 schedulers, chacun capable d'émettre 2 instructions. Toutes les unités d'exécution ne sont cependant pas accessibles à tous les schedulers et un SMX est en pratique séparé en 2 parties symétriques à l'intérieur desquelles une paire de schedulers se partage les différentes unités. Chaque scheduler dispose de son propre lot de registres : 16384 registres de 32 bits (512 registres généraux de 32x32 bits en réalité). Par ailleurs chaque scheduler dispose d'un bloc dédié de 4 unités de texturing accompagnées d'un cache de 12 Ko.
Contrairement à ce à quoi nous nous attendions, l'ensemble cache L1 / mémoire partagée n'évolue pas dans le GK110 par rapport au GK104 et reste proportionnellement inférieur à ce qui était proposé sur la génération Fermi. Nvidia introduit par contre trois petites évolutions qui peuvent entraîner des gains importants :
Tout d'abord, chaque thread peut se voir attribuer jusqu'à 256 registres contre 64 auparavant. Quel intérêt quand le nombre de registres physiques n'augmente pas ? Il s'agit de donner plus de flexibilité au développeur et surtout au compilateur pour jongler entre le nombre de thread en vol et la quantité de registres allouée à chacun pour maximiser les performances. C'est particulièrement important dans le cas des calculs en double précision qui consomment le double de registres et qui étaient auparavant limités à 32 registres par thread. Passer à 128 permet des gains impressionnants dans certains cas selon Nvidia.

Ensuite, la seconde petite évolution consiste à autoriser l'accès direct aux caches dédiés au texturing. Auparavant il était possible d'en profiter manuellement en bricolant un accès à travers les unités de texturing, mais ce n'était pas pratique. Avec le GK110, ces caches de 12 Ko peuvent être exploités directement depuis les SMX mais uniquement dans le cas d'accès à des données en lecture seule. Ils ont l'avantage de disposer d'un accès royal au sous-système mémoire du GPU, de souffrir moins en cas de cache miss et de mieux supporter les accès non alignés. C'est le compilateur (via une directive) qui se charge d'y avoir recours lorsque c'est utile.
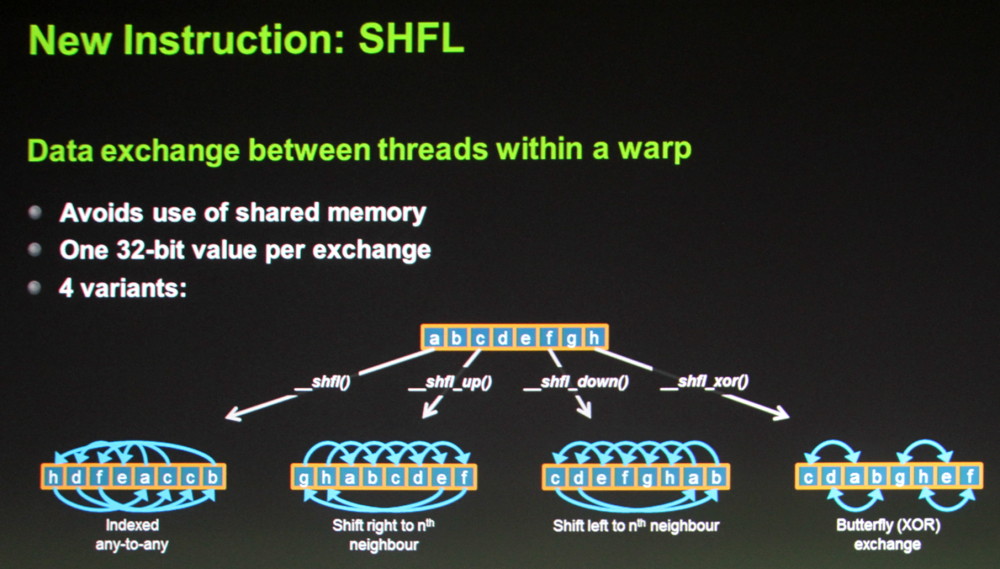
Enfin, une nouvelle instruction fait son apparition : SHFL. Elle permet un échange de donnée de 32 bits par thread à l'intérieur d'un warp (bloc de 32 threads). Son utilité est similaire à celle de la mémoire partagée et cette instruction vient donc en quelque sorte compenser sa quantité relativement faible, proportionnellement au nombre d'unités de calcul. Dans le cas d'un échange de données simple il sera donc possible d'une part de gagner du temps (un transfert direct à la place d'une écriture puis d'une lecture) et d'autre part d'économiser la mémoire partagée.
D'autres petits détails évoluent également tels que l'ajout des quelques instructions atomiques manquantes en 64 bits (min/max et opérations logiques) et une réduction de 66% du surcoût lié à la mémoire ECC.
Au final, avec la génération Kepler, Nvidia a bien pris une direction différente de celle de la génération Fermi. Le gros GPU Fermi, le GF100/110, disposait d'une organisation interne différente de celle des autres GPU de la famille, de manière à augmenter la logique de contrôle au détriment de la densité des unités de calcul et du rendement énergétique.
Avec le GK110, Nvidia n'a pas voulu faire de compromis sur ce dernier point ou plutôt devrions nous dire "n'a pas pu". Il s'agit dorénavant de faire un maximum dans une enveloppe thermique qui n'est plus extensible. C'est la raison pour laquelle le GK110 reprend la même organisation interne que celle du GK104, en dehors de la capacité de calcul en double précision qui a été revue nettement à la hausse.
Ainsi, Nvidia n'a pas cherché à complexifier son architecture pour soutenir les performances en GPU computing et s'est attaché à essayer de faire un maximum avec les ressources disponibles en se contentant d'évolutions mineures mais qui peuvent avoir un impact énorme. C'est également la raison pour laquelle le processeur de commandes a été revu pour permettre de maximiser l'utilisation du GPU avec les technologies Hyper-Q et Dynamic Parallelism que nous avons décrites brièvement hier et sur lesquelles nous reviendront dès que possible avec quelques détails de plus.