
Actualités informatiques du 03-06-2015
- Computex: 4 GTX 980 Ti customs chez Zotac
- Computex: L'AMD Fiji et ses 4 Go de HBM en photo
- AMD lance les Carrizo
| Juin 2015 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | |||||
Computex: 4 GTX 980 Ti customs chez Zotac



Zotac n'a bien entendu pas négligé la récente GeForce GTX 980 Ti et expose au Computex quatre variantes personnalisées qui viendront remplacer sous peu la carte de référence.



Deux modèles exploitent un premier PCB personnalisé mais similaire à celui de référence au niveau de la charge qu'il peut encaisser. Nous retrouvons ainsi une GTX 980 Ti AMP! avec un large ventirad IceStorm équipé de 3 ventilateurs et profite d'un petit overclocking du GPU qui passe de 1000/1075 à 1051/1140 MHz.
La seconde carte est un modèle hybride, ArcticStorm, prévu pour s'intégrer dans un système de watercooling, mais qui conserve la ventilation pour refroidir le PCB, ce qui rend l'intérêt de la chose discutable. L'overclocking est cette fois moins important avec 1025/1114 MHz, Zotac expliquant que ce modèle était prévu pour un overclocking manuel plus que d'usine.
Les deux cartes recoivent une backplate et dans le cas de l'ArcticStorm, son design sera plutôt coloré, avec un look type surfeur pour rappeler le rapport à l'eau.



Zotac a ensuite conçu un second PCB plus musclé, bien que le fabricant n'ait pas pu nous communiquer de détails au niveau de la charge qu'il est capable d'encaisser, ce qui est probablement toujours en train d'être décidé/validé par Nvidia. Les GTX 980 Ti AMP! Omega et AMP! Extreme reprennent ce PCB et un énorme ventirad qui occupe 3 slots et dépasse en hauteur. Pour ce ventirad, Zotac indique avoir recours à des ventilateurs EKO FAN dont le design atypique des pales a été prévu pour diriger plus d'air en leur centre.
Ces deux modèles se distingueront au niveau des fréquences. Elles n'ont pas encore été déterminées pour la version Omega, mais l'Extreme, qui représentera le top de la famille, profitera d'un GPU cadencé à 1253/1355 MHz, ce qui représente un overclocking de 25% par rapport aux fréquences de référence. Par ailleurs, ce modèle Extreme reçoit un système de LED au niveau des 4 coins du ventirad. Les deux cartes recevront par contre bien la même backplate au design cette fois plus sobre.
Computex: L'AMD Fiji et ses 4 Go de HBM en photo
A la fin de sa conférence de presse traditionnelle à Taipei, Lise Su, CEO d'AMD, a sorti de sa poche le packaging du prochain GPU haut de gamme de la marque dont le nom de code est Fiji.

Ce packaging correspond à ce à quoi nous nous attendions et aux spéculations que nous avions formulées sur le forum sur base de morceaux d'illustrations discrètement disséminés sur le site d'AMD. A savoir :
- un packaging de 50x50mm
- un interposer de 26x32mm
- 4 puces HBM
- un GPU de 20x24mm (+/- 1mm)
Si nous n'en savons pas plus sur le GPU Fiji, en dehors de la confirmation que sa taille tournera autour de 500 mm², les derniers doutes quant à la quantité de mémoire embarquée se dissipent : ce sera 4 Go.
Jusqu'ici nous n'avions pas laissé tomber la possibilité qu'AMD puisse embarquer 8 modules HBM pour passer de 4 à 8 Go en adressant ceux-ci à travers 4 canaux de 2 Gb (soit en mode 512-bit) au lieu de 8 canaux de 1 Gb (mode 1024-bit). Une flexibilité pas bien compliquée à intégrer dans un module HBM tel que celui conçu par SK Hynix. Juste après la conférence d'AMD, nous avons pu poser la question directement à Joe Macri, CTO d'AMD et Chairman du sous-comité DRAM du JEDEC. Celui-ci nous a expliqué que bien qu'effectivement relativement simple à implémenter, cette possibilité n'a pas été prévue dans la HBM 1. Par contre AMD l'a proposée pour la HBM 2 et elle a alors été retenue pour cette mémoire qui arrivera l'an prochain.
Dans l'immédiat, Fiji devra donc se contenter de 4 Go. Joe Macri insiste à nouveau sur l'argument que ce ne serait pas un problème et que ses ingénieurs se seraient focalisés sur l'optimisation de l'occupation mémoire, un domaine qui avait été négligé jusqu'ici, la recherche de plus de bande passante entraînant généralement un large bus mémoire qui augmentait automatiquement la capacité.
Joe Macri nous a par ailleurs précisé que même si Fiji est un GPU haut de gamme, il entraîne malgré tout un volume considéré très important, ce qui rend déjà obligatoire d'arriver à un rendement élevé au niveau de la production ainsi que de maîtriser strictement les coûts. Ces deux points ne seraient donc plus de très grosses difficultés et l'utilisation de la HBM devrait exploser dès l'an prochain, que ce soit dans d'autres gammes de produits AMD, chez Nvidia ou même chez Intel dont la mémoire eDRAM spécifique de certaines de ses puces ne pourra rivaliser en termes de performances ou de coûts avec la HBM 2.
AMD a enfin indiqué officiellement avoir prévu d'en dévoiler plus sur les Radeon R300 et sur Fiji ce 16 juin, lors d'une conférence qui sera retransmise en direct depuis l'E3.
AMD lance les Carrizo
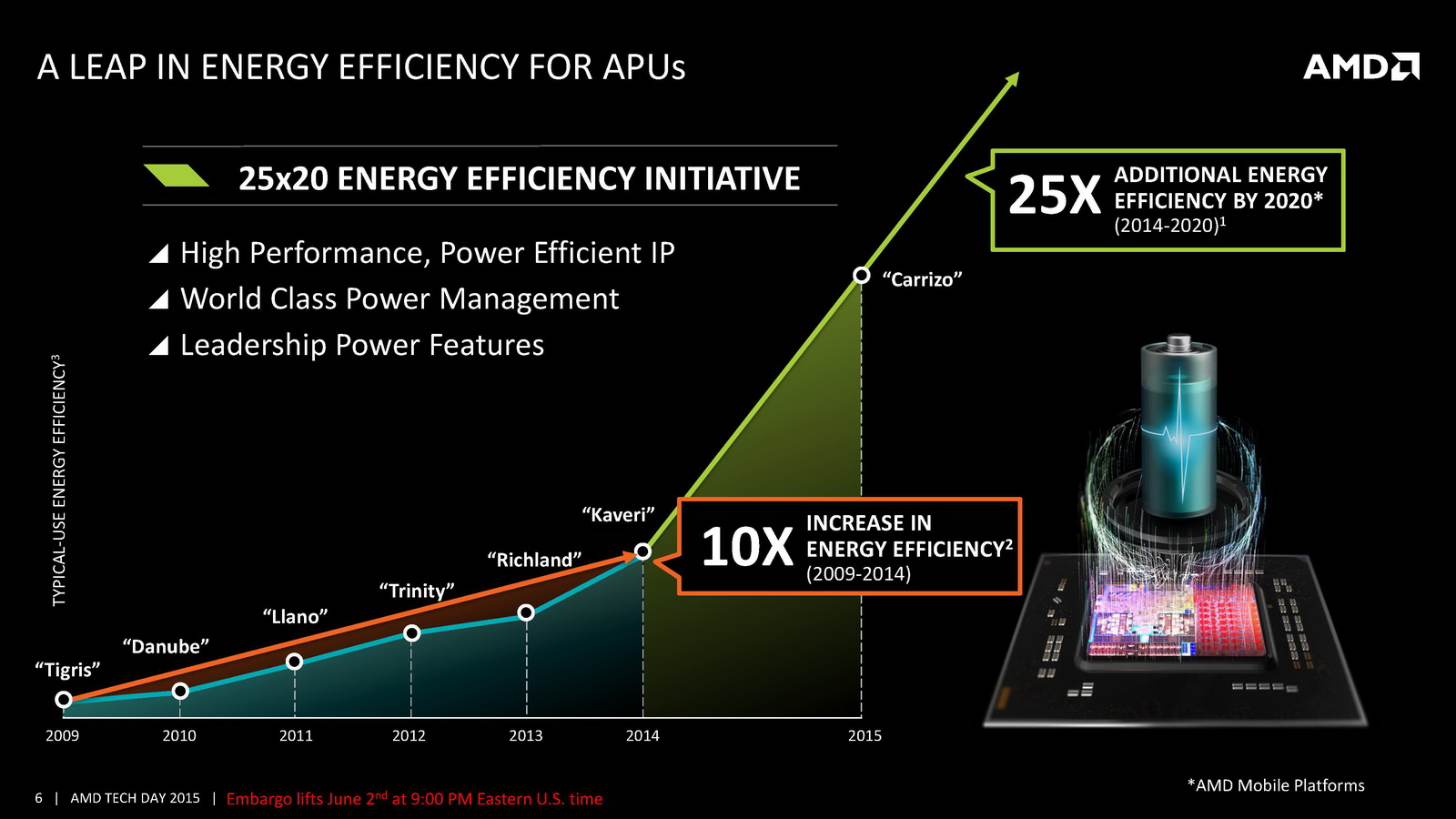
Après Intel, AMD profite du Computex pour lancer également une fournée de processeurs destinés aux plateformes mobiles, les Carrizo. Nous avons eu l'occasion de vous présenter à plusieurs reprises ces puces, AMD ayant dévoilé l'aspect technique le plus pointu en février lors de l'ISSCC (nous vous renvoyons à cette actualité pour les détails) ainsi qu'un peu plus de détails le mois dernier lors de sa conférence dédiée aux analystes financiers.
La magie du marketing veut que ces puces soient qualifiées de sixième génération, même si en pratique la manière dont AMD compte n'est pas très logique. Les motivations pour arriver exactement à 6 sont ailleurs
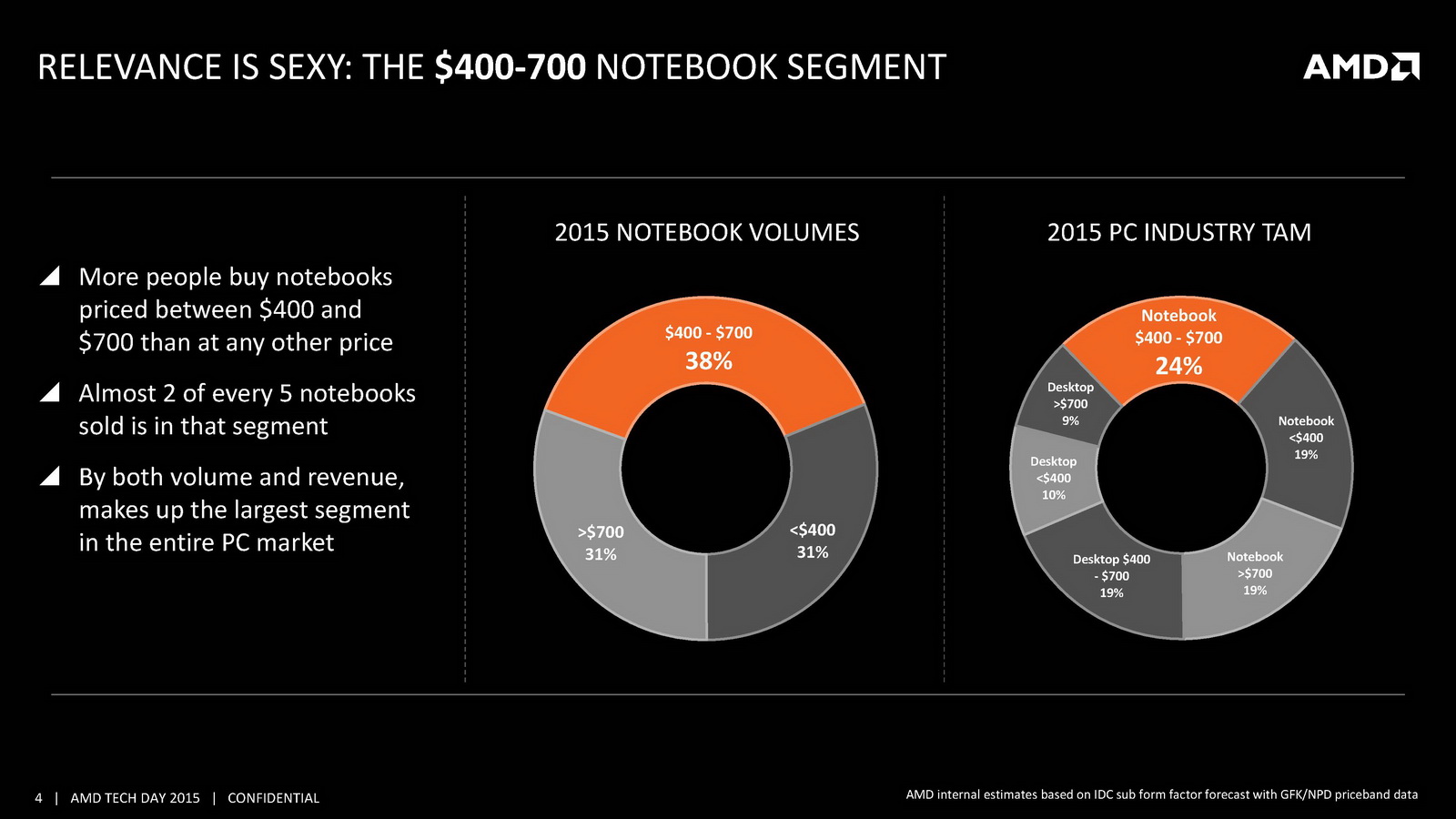
. Il s'agit de puces SoC (elles intègrent le chipset dans le die, tout comme les Kabini et au contraire des Kaveri qu'ils remplacent directement) fabriquées en 28nm et qui intègrent 3.1 milliards de transistors (dans une surface identique au Kaveri qui, fabriqués également en 28nm ne comptaient que 2.41 milliards de transistors). Si AMD ne parle pas directement du prix de ses puces portables (pas plus qu'Intel qui n'indique que des prix fantaisistes sur ces gammes), le constructeur indique viser des machines dont le prix évoluera entre 400 et 700 euros.























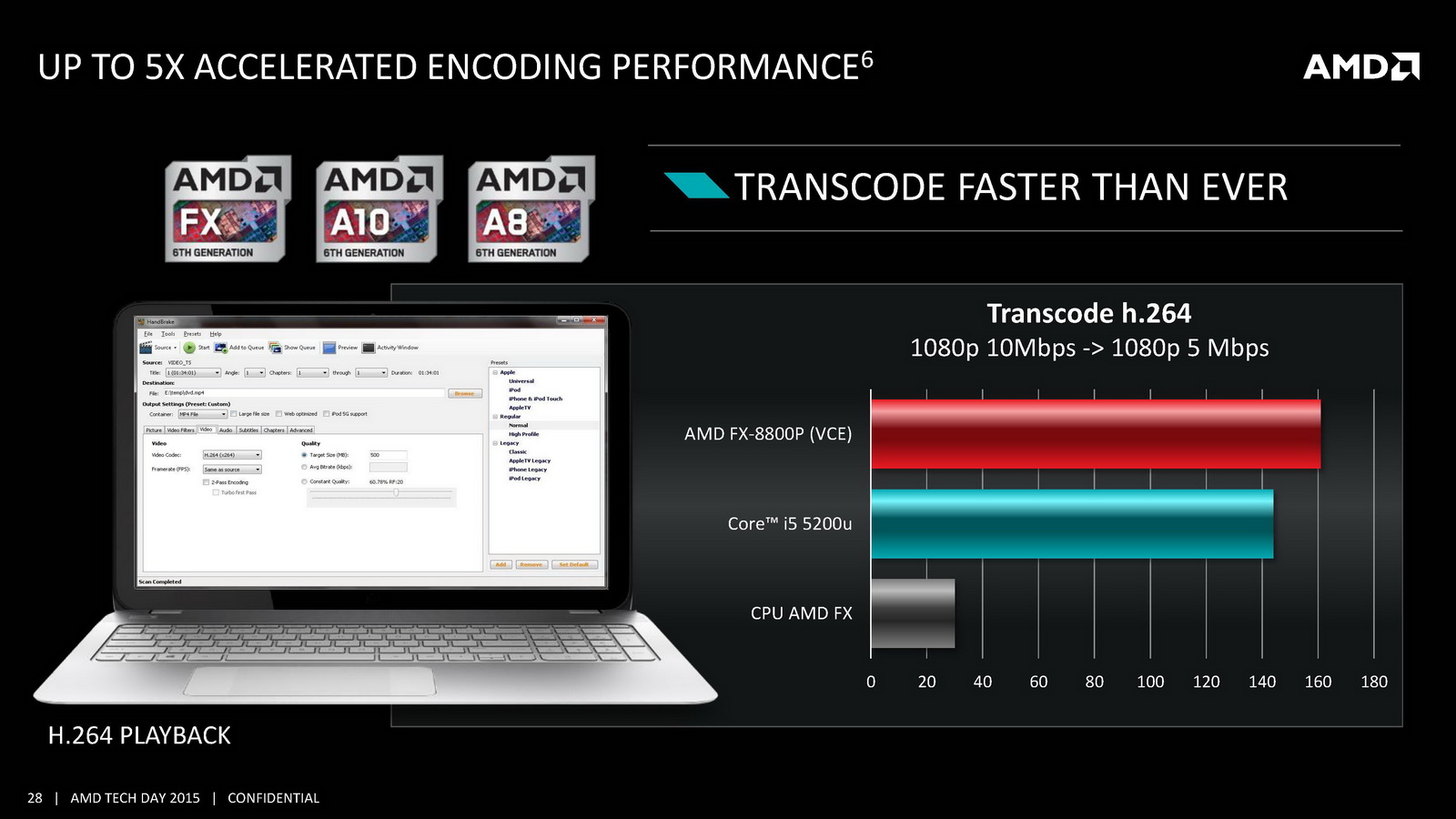


















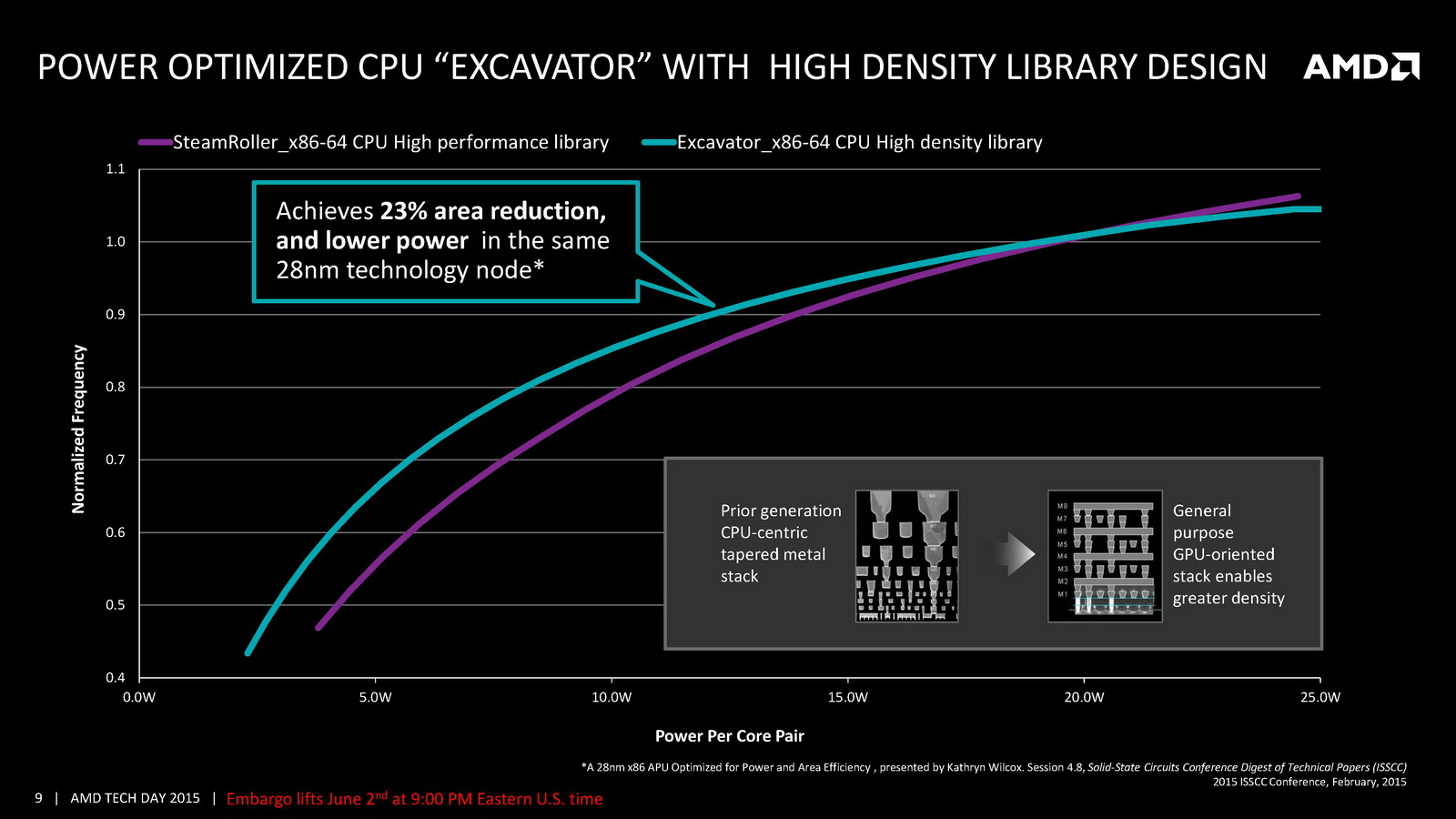
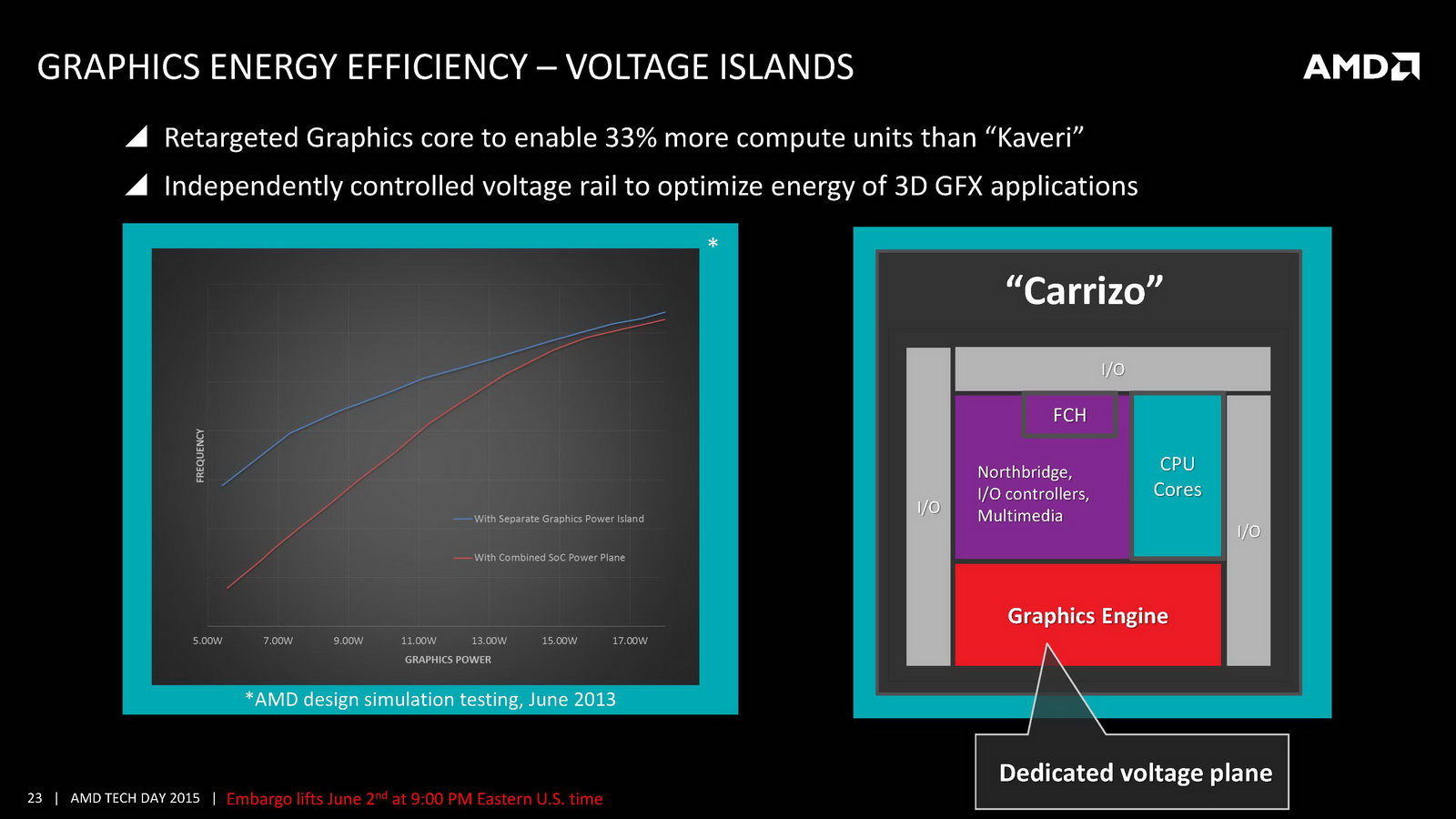
D'un point de vue technique on retrouve deux modules Excavator (pour quatre curs), des modules qui seront la dernière itération de ce concept introduit avec Bulldozer. Les modules Excavator augmentent leur nombre de transistors tout en réduisant leur superficie, un changement que l'on doit à l'adoption de bibliothèques dites « haute densité » et a l'utilisation d'outils plus modernes de la part du constructeur lors de la conception des puces. Des changements internes qui avaient déjà eu lieu pour les GPU et qui se répercuteront aussi sur les prochains designs de la marque.
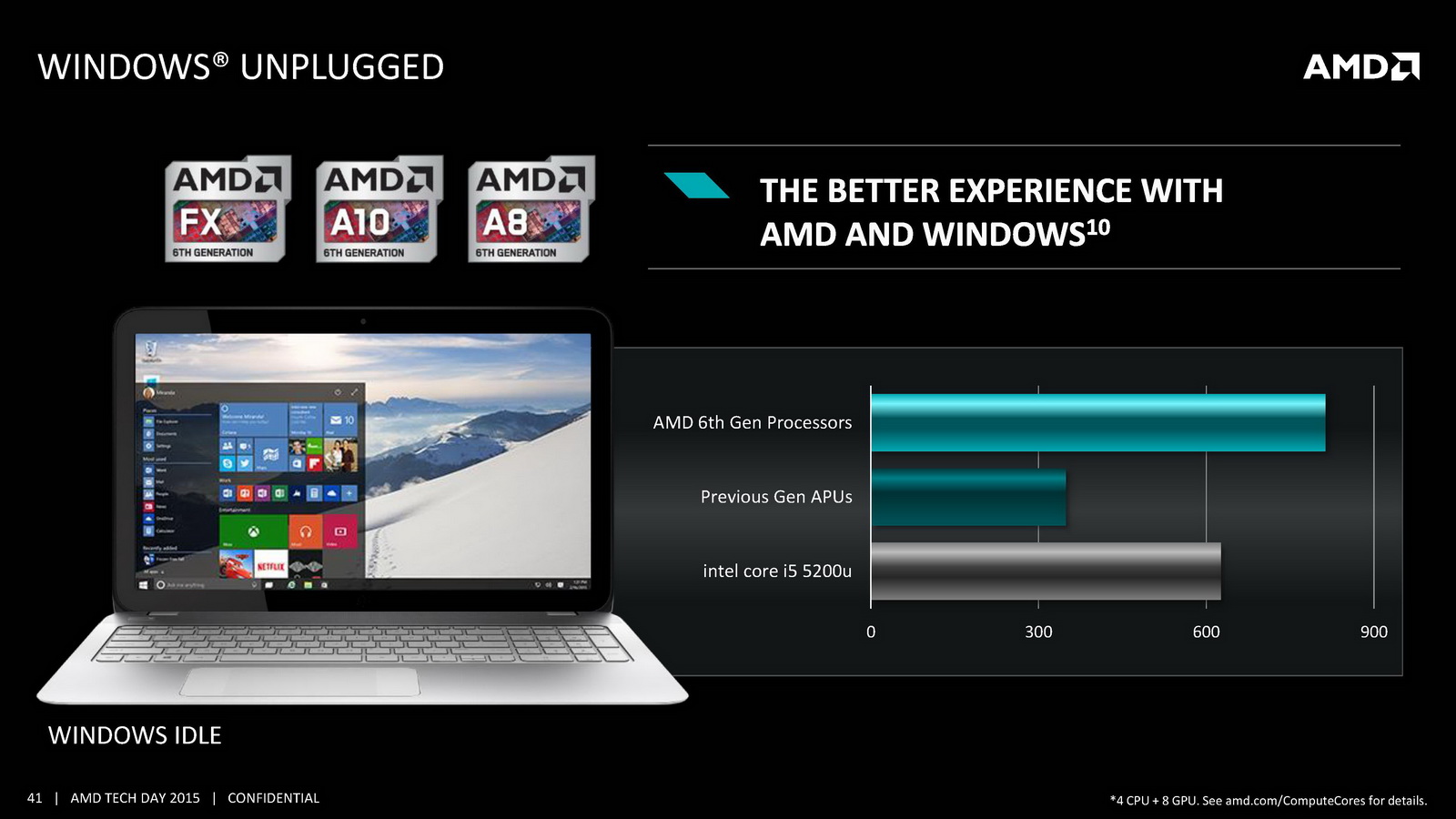
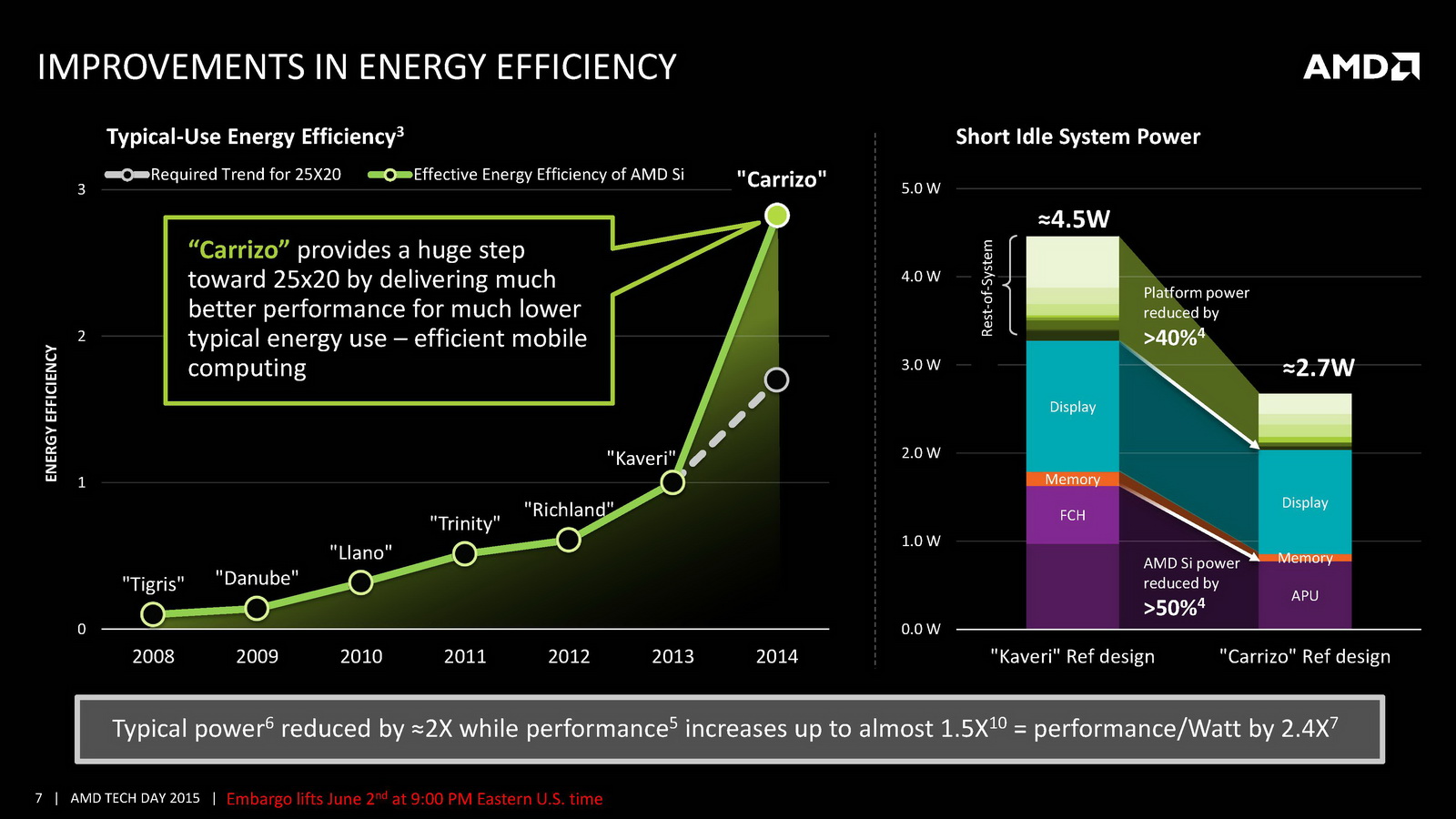
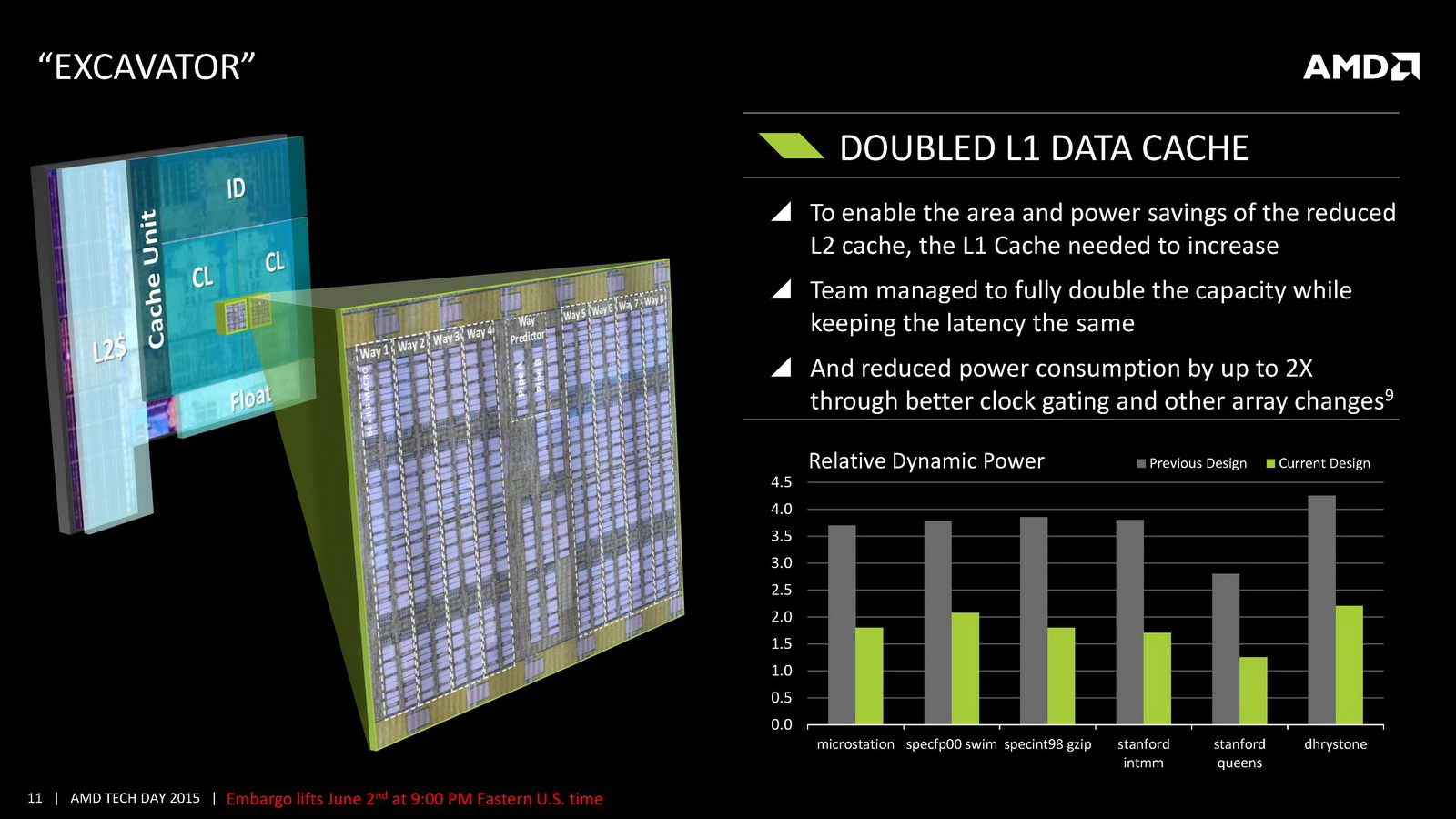
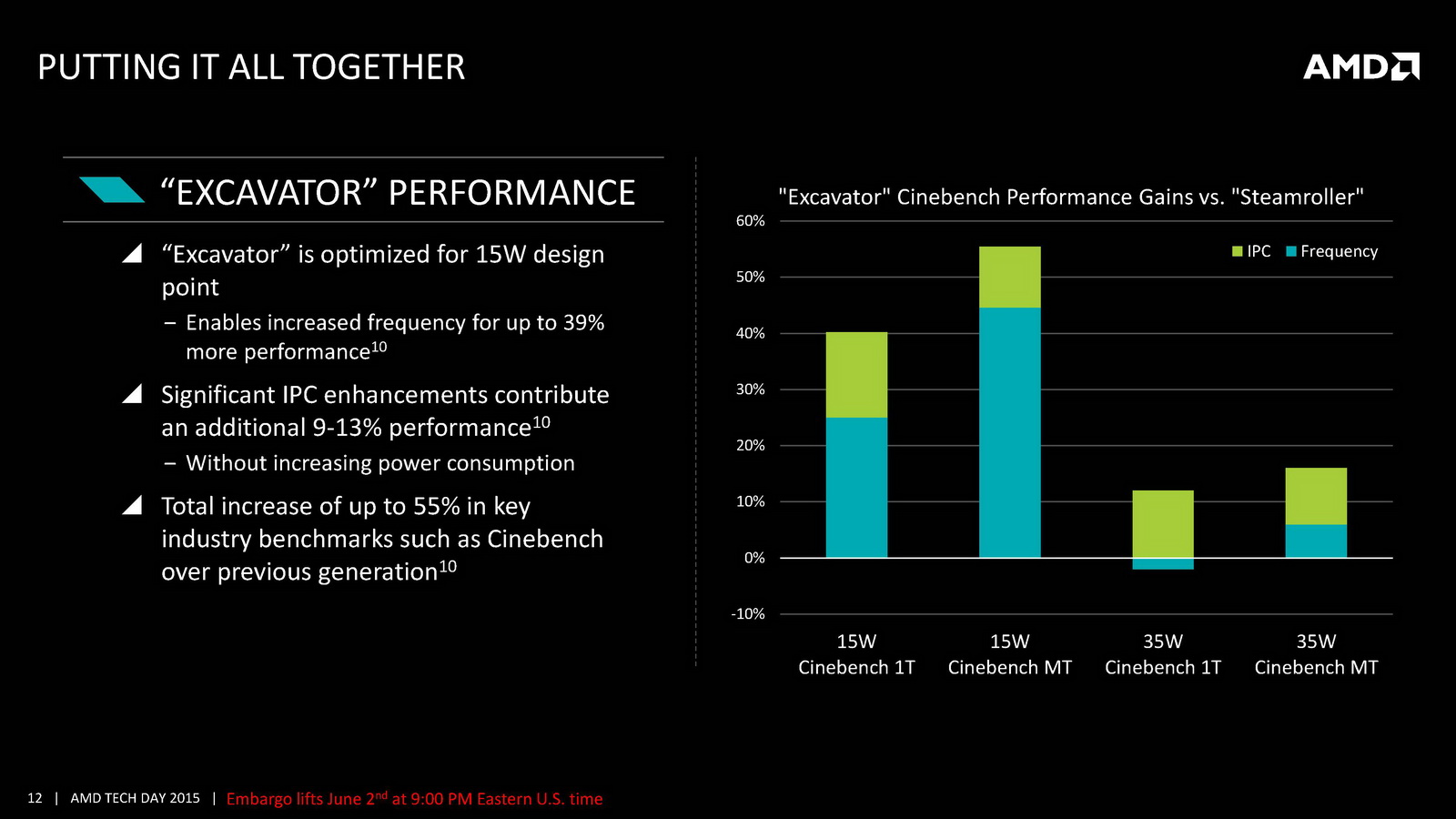
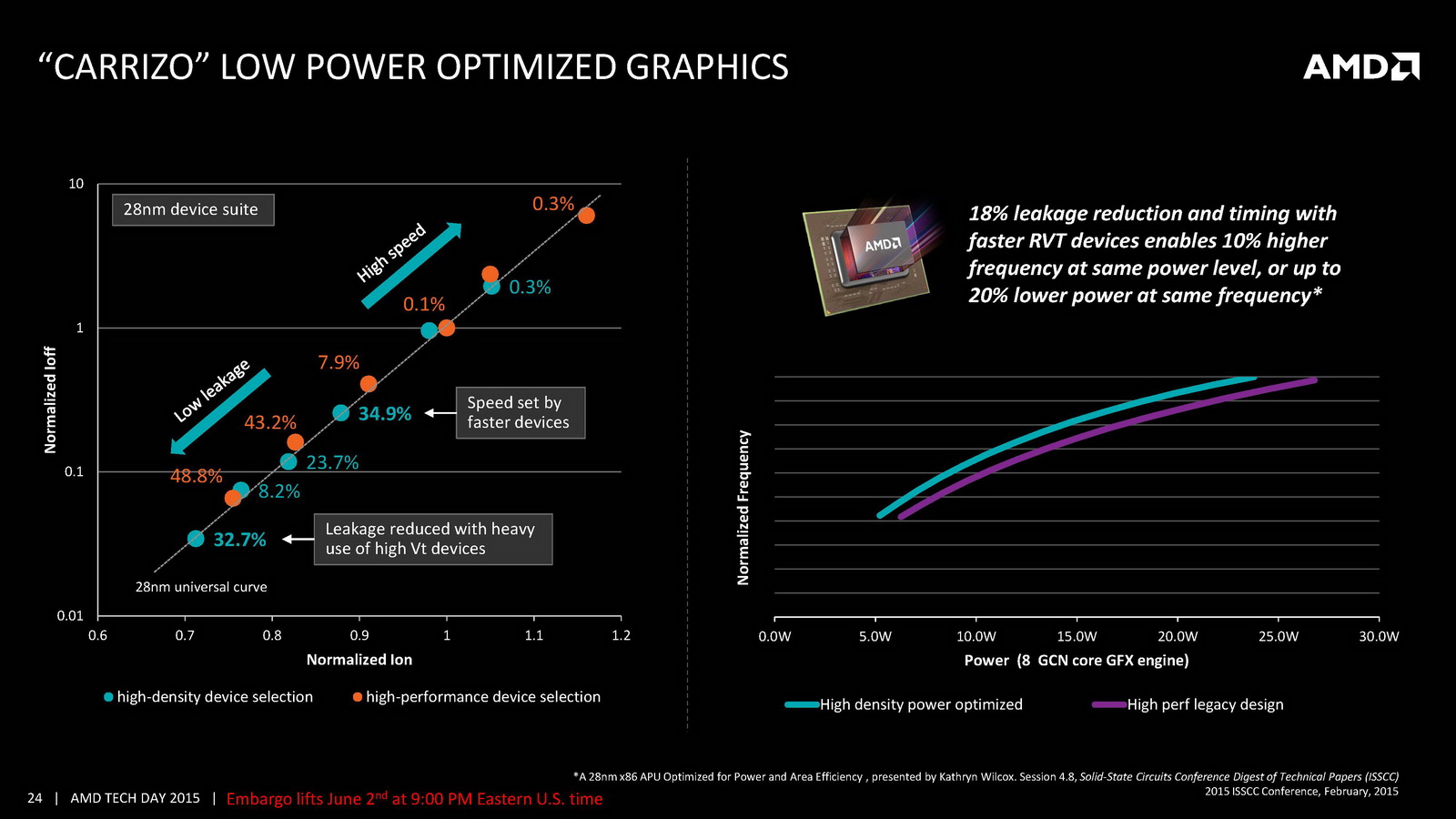
On notera deux autres changements marquants, un cache L1 deux fois plus grand et un cache L2 deux fois plus petit puisque l'on passe de 4 Mo sur Kaveri à seulement 2 Mo ! AMD indique cependant avoir amélioré l'IPC par plusieurs biais, car si le cache L1 est doublé, sa latence reste identique. On note également un buffer pour les branchements qui augmente de 50%. Au final, l'IPC peut compter pour entre 9 et 13% des gains de performances notés par rapport à Kaveri. Des gains qui s'ajoutent à ceux obtenus par la montée en fréquence, particulièrement dans les configurations 15 Watts qui gagnent beaucoup du passage aux bibliothèques hautes densités et optimisées pour la consommation. Enfin, il faut noter le support de l'AVX2 qui rajoute des instructions vectorielles 256 bits entières ainsi que le FMA. Une addition faite pour la compatibilité avant tout, les nouvelles instructions étant traitées en plusieurs passes par les unités existantes.
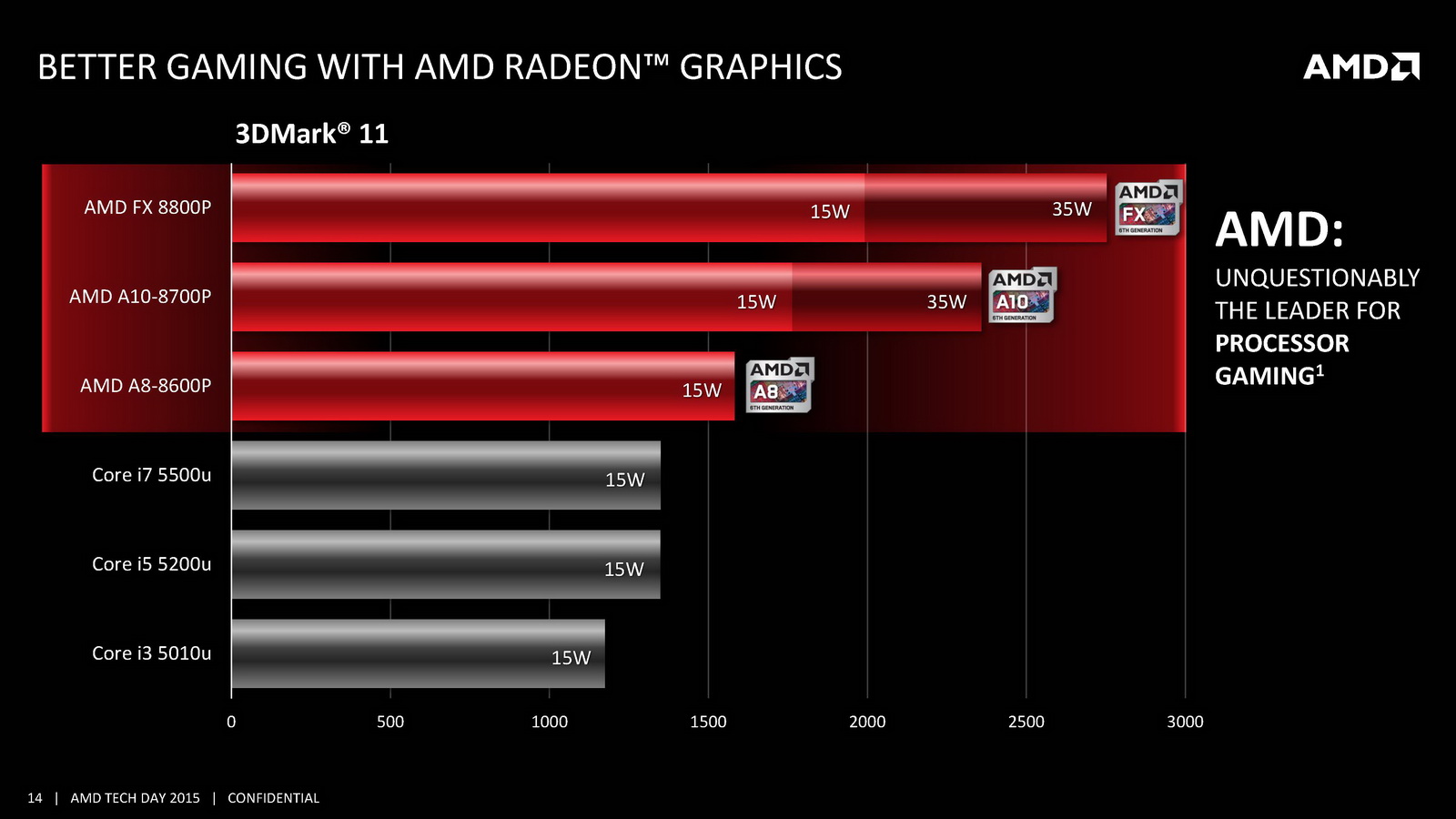
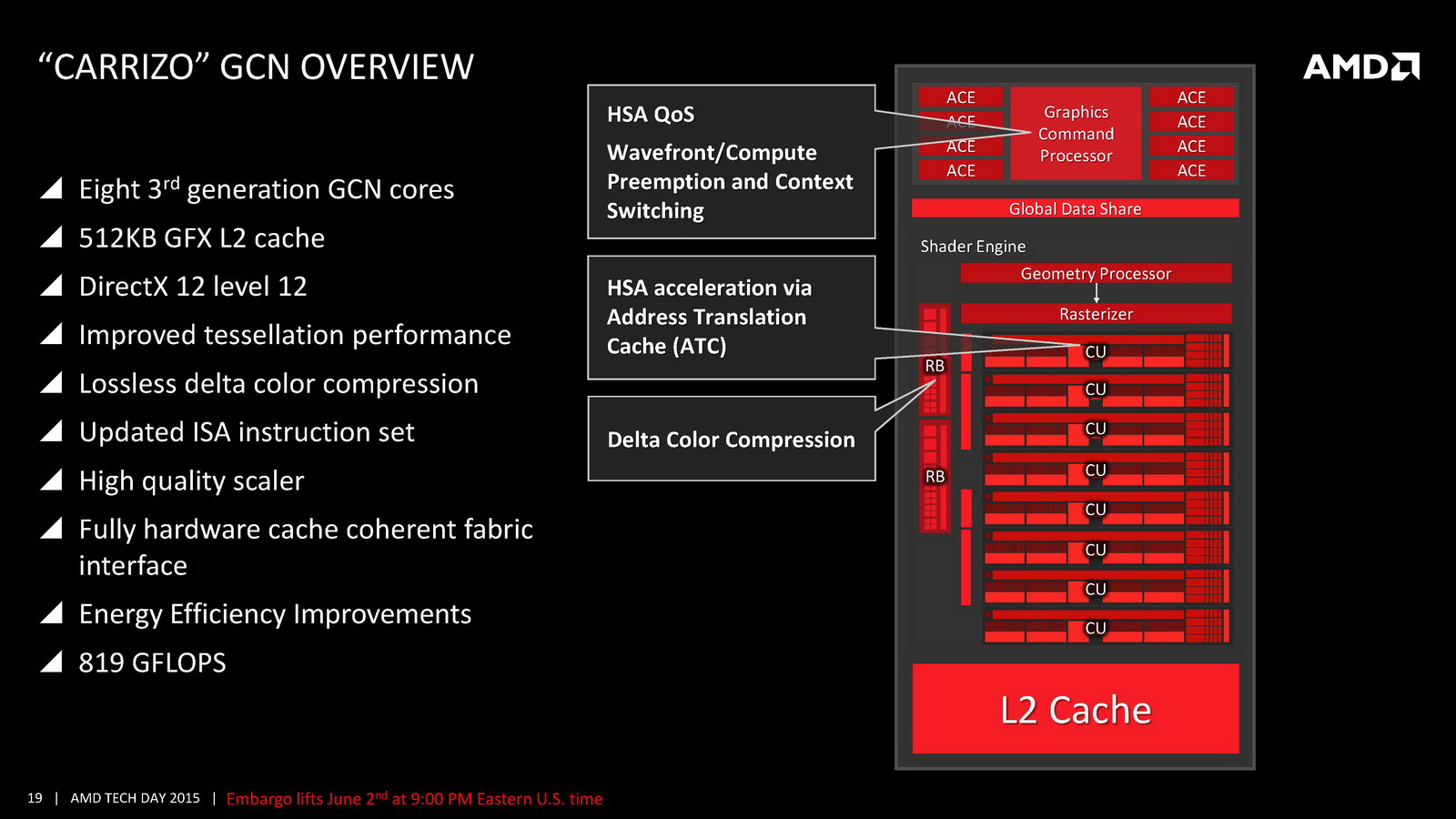
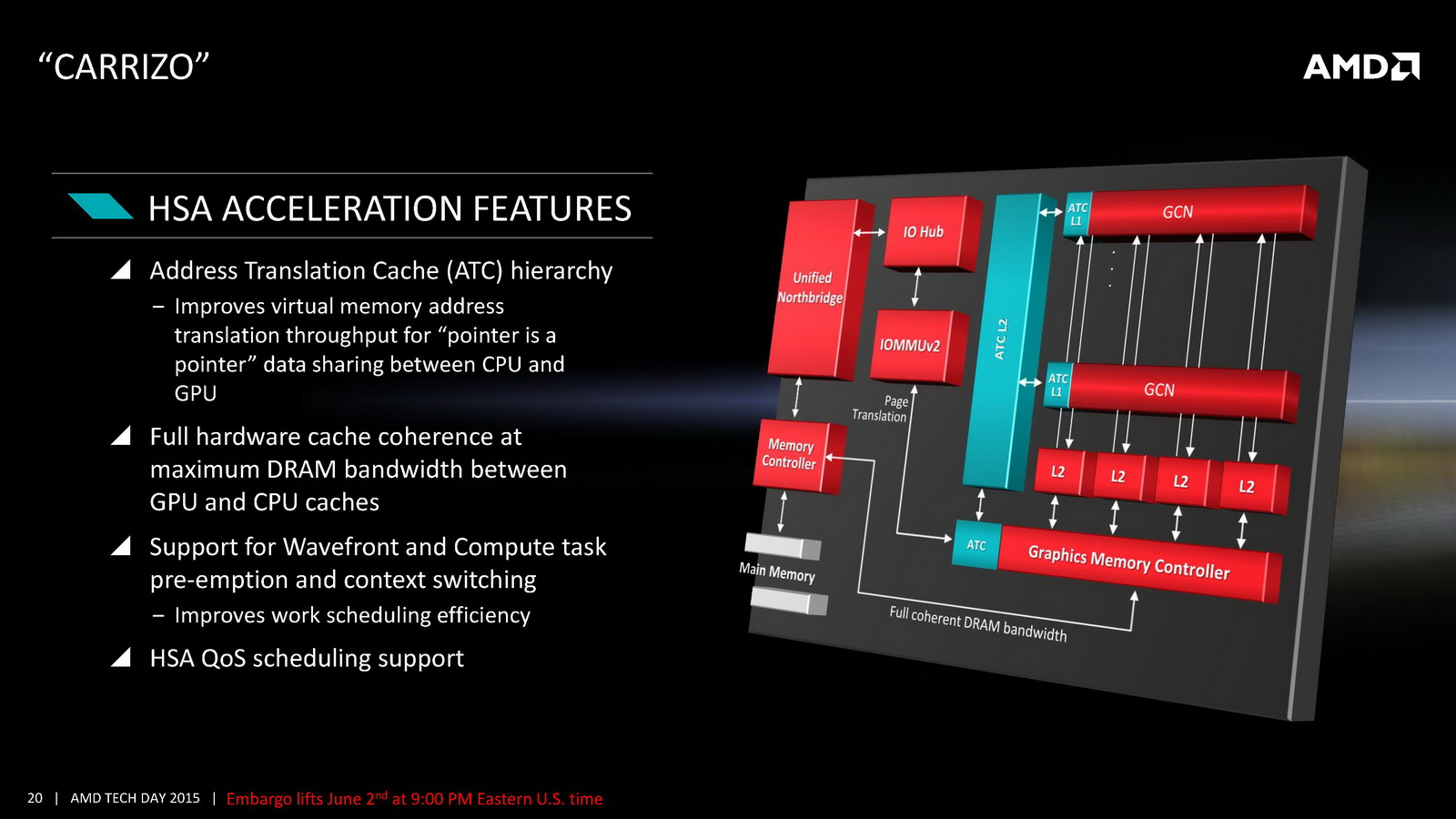
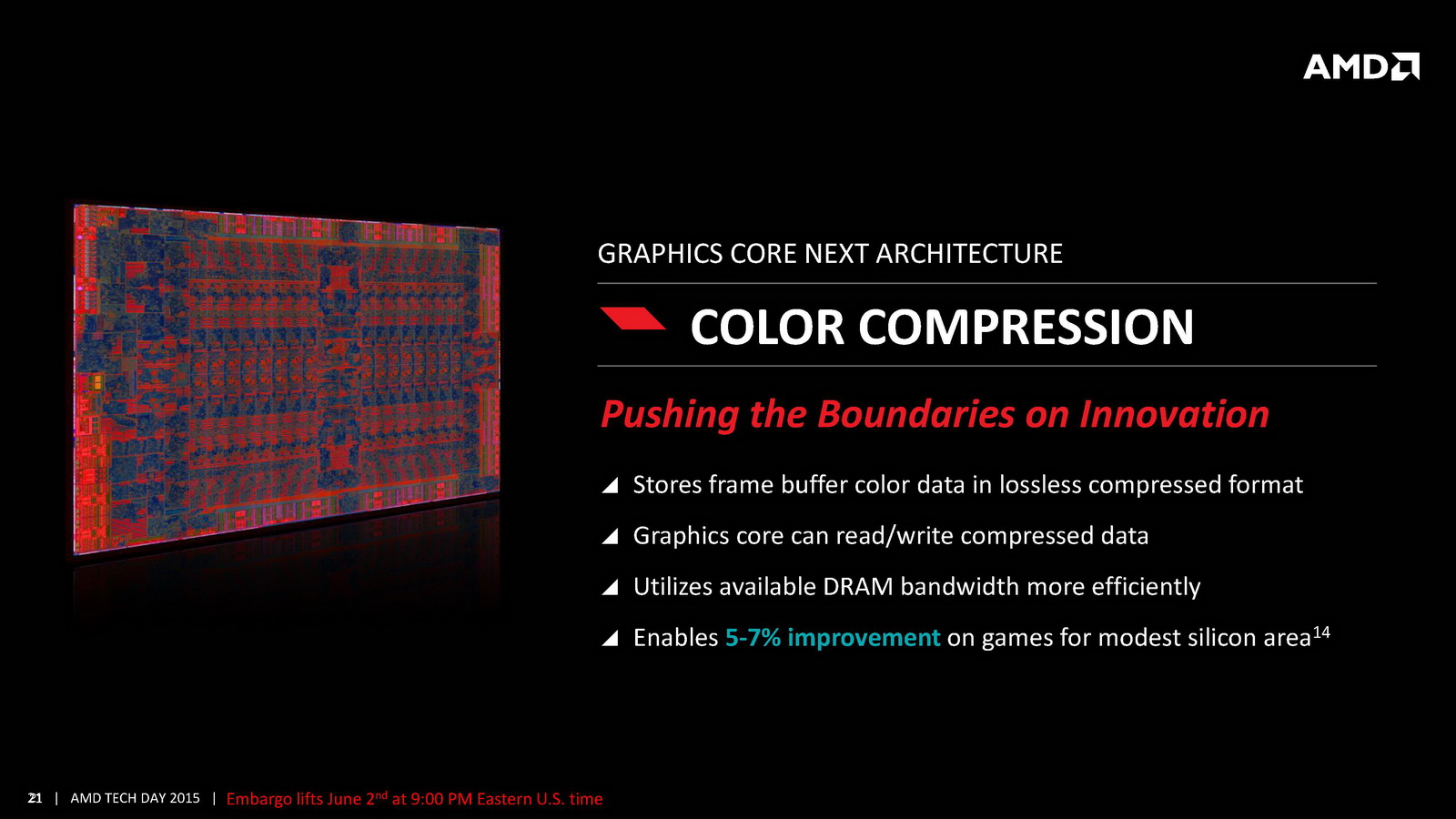
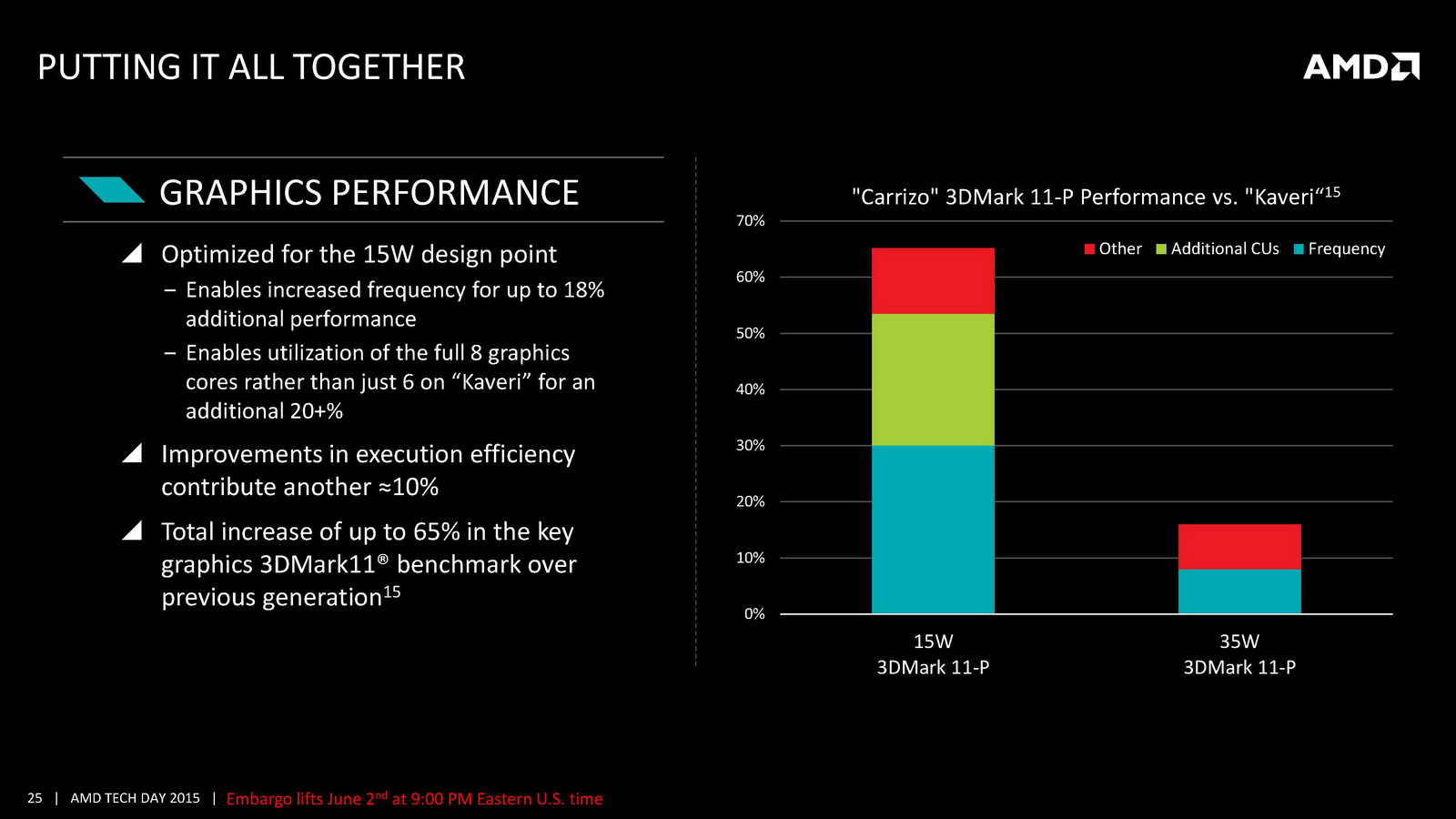
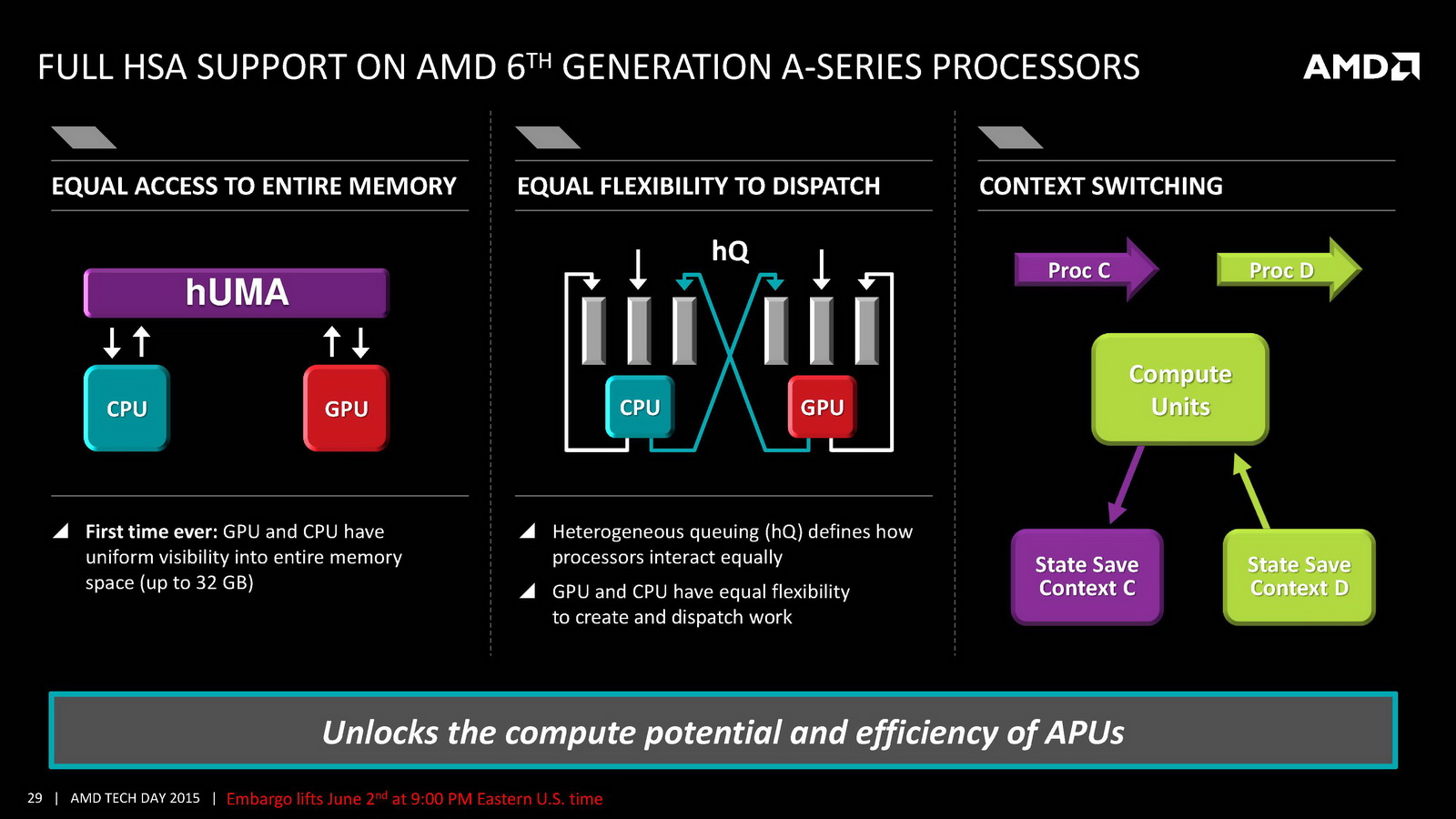
Côté GPU on retrouve dans Carrizo la dernière version de GCN avec 6 à 8 CU et 512 Ko de cache L2 dédié. AMD met en avant sa compatibilité DirectX 12 (level 12_0) ainsi que quelques petites optimisations de ci de là comme au niveau de la compression des couleurs. Le point le plus notable reste le support de HSA en version « 1.0 finale » pour la première fois (Kaveri était compatible avec la spécification 1.0 « provisional », la version finale ajoutant quelques changements sur les changements de contexte GPU nottament), même si comme toujours l'écosystème GPGPU reste spécifique, et globalement réduit. Au final ces améliorations permettent à AMD d'annoncer un peu plus de 15% de gains sous 3D Mark 11 en version 35 watts par rapport à Kaveri, et plus de 60% sur les versions 15 watts.









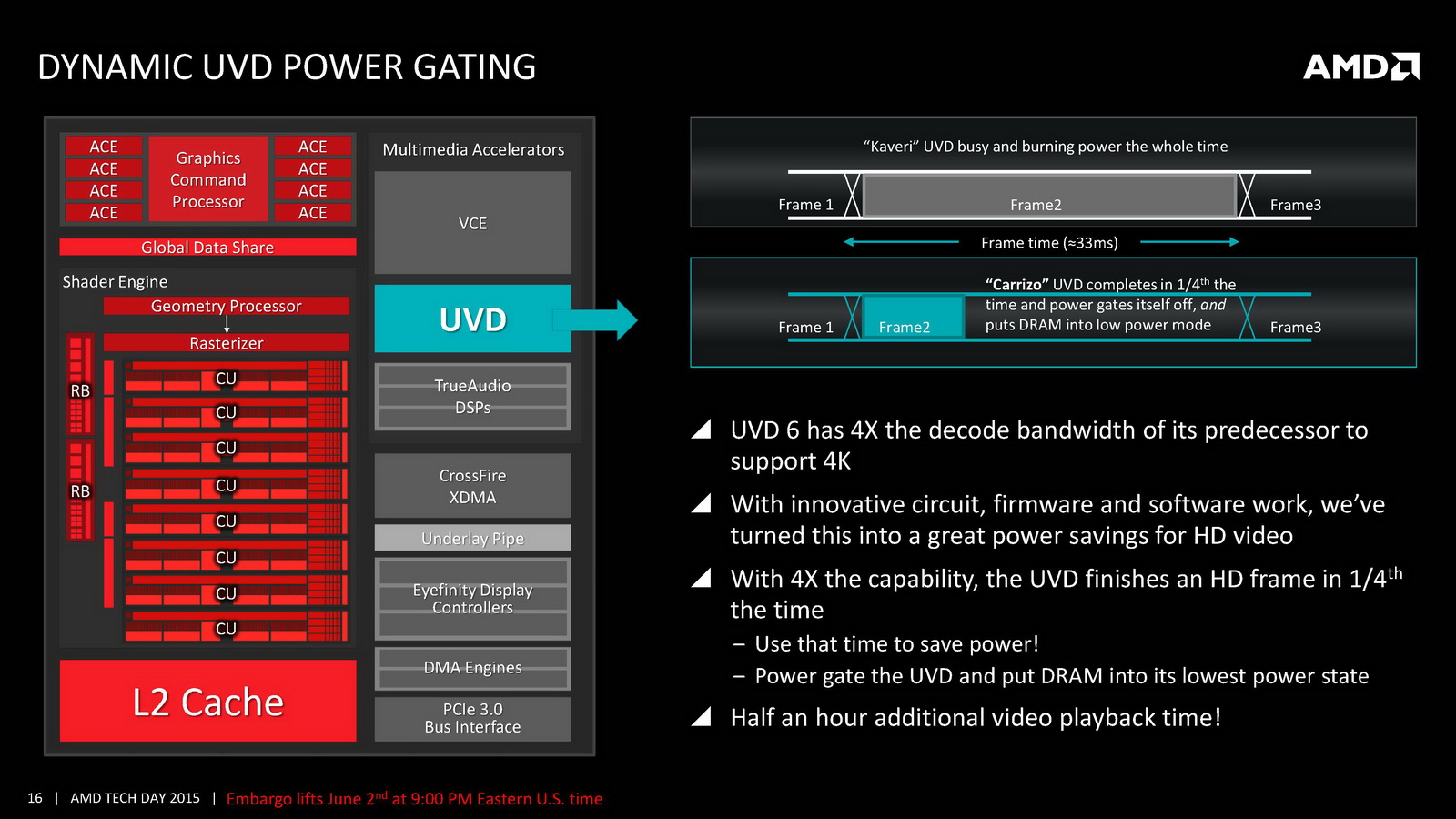
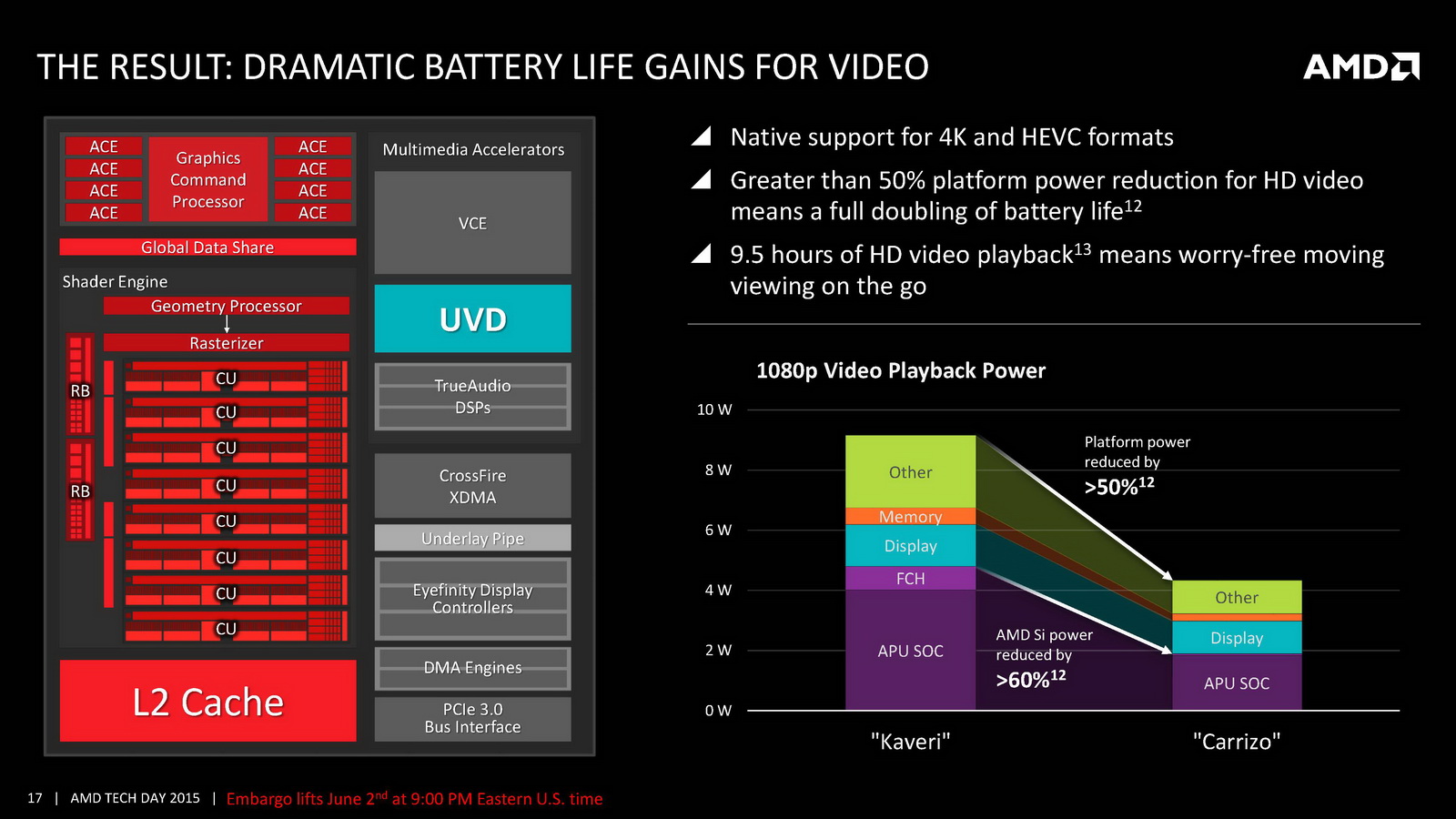



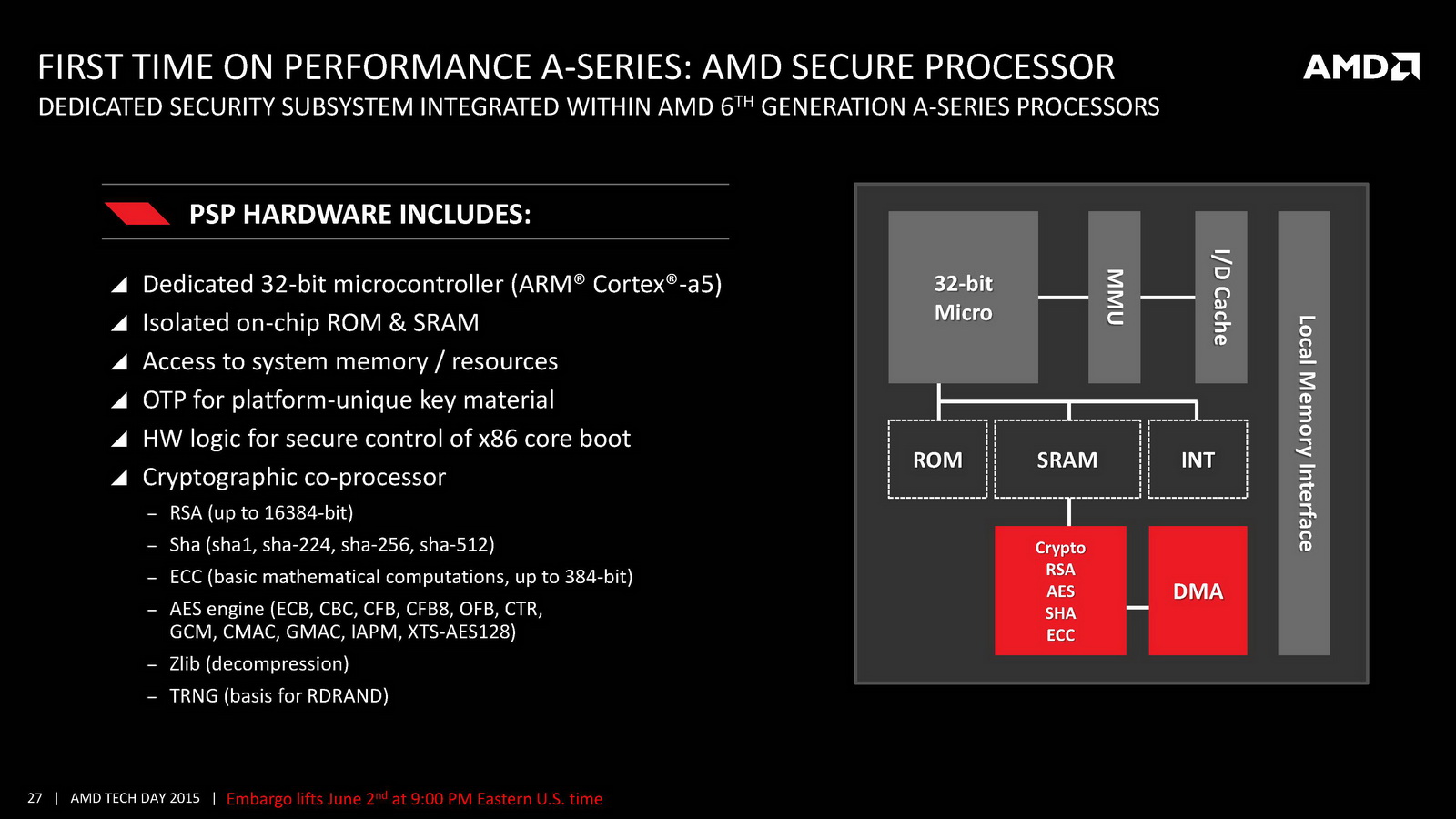







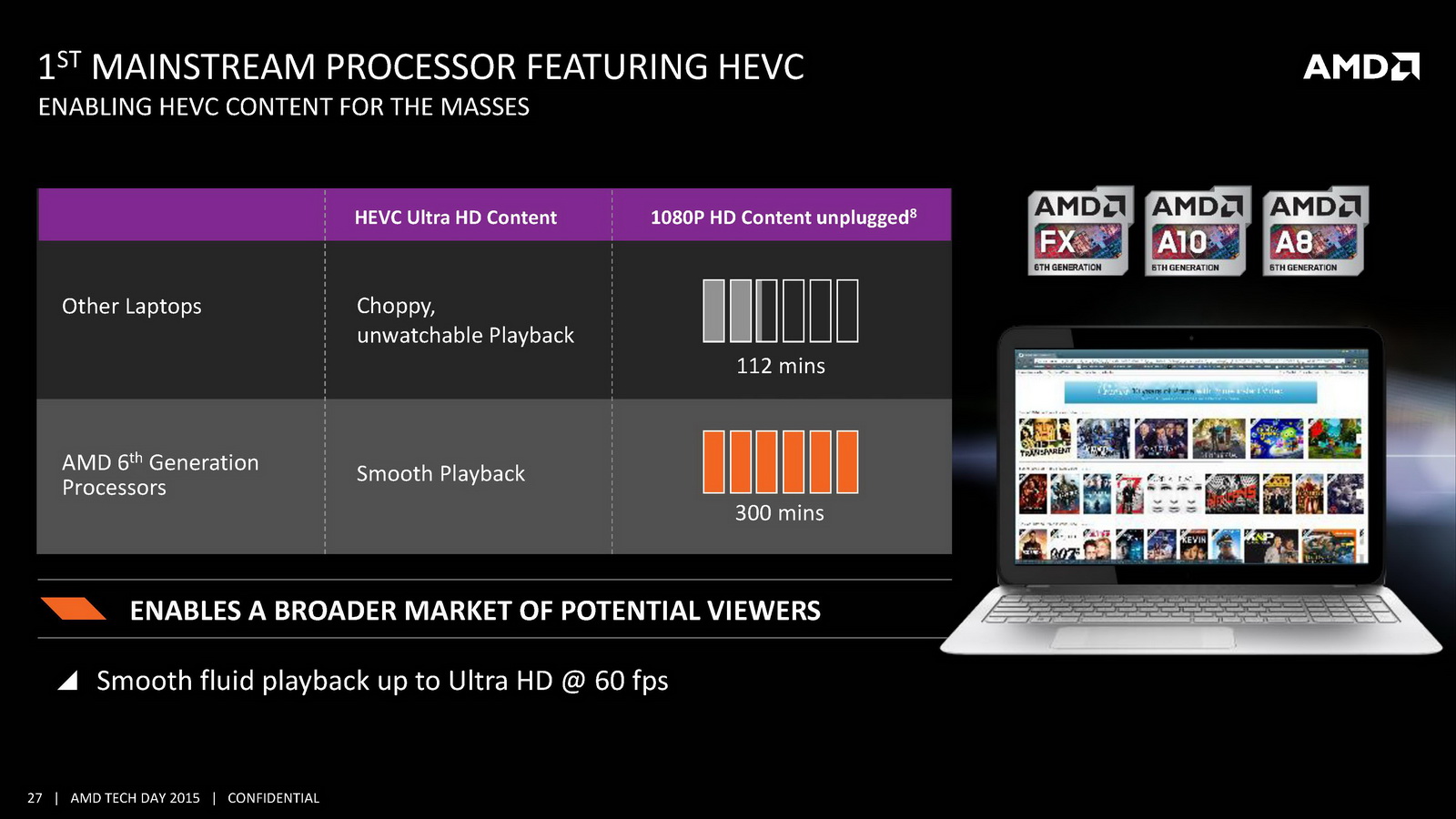
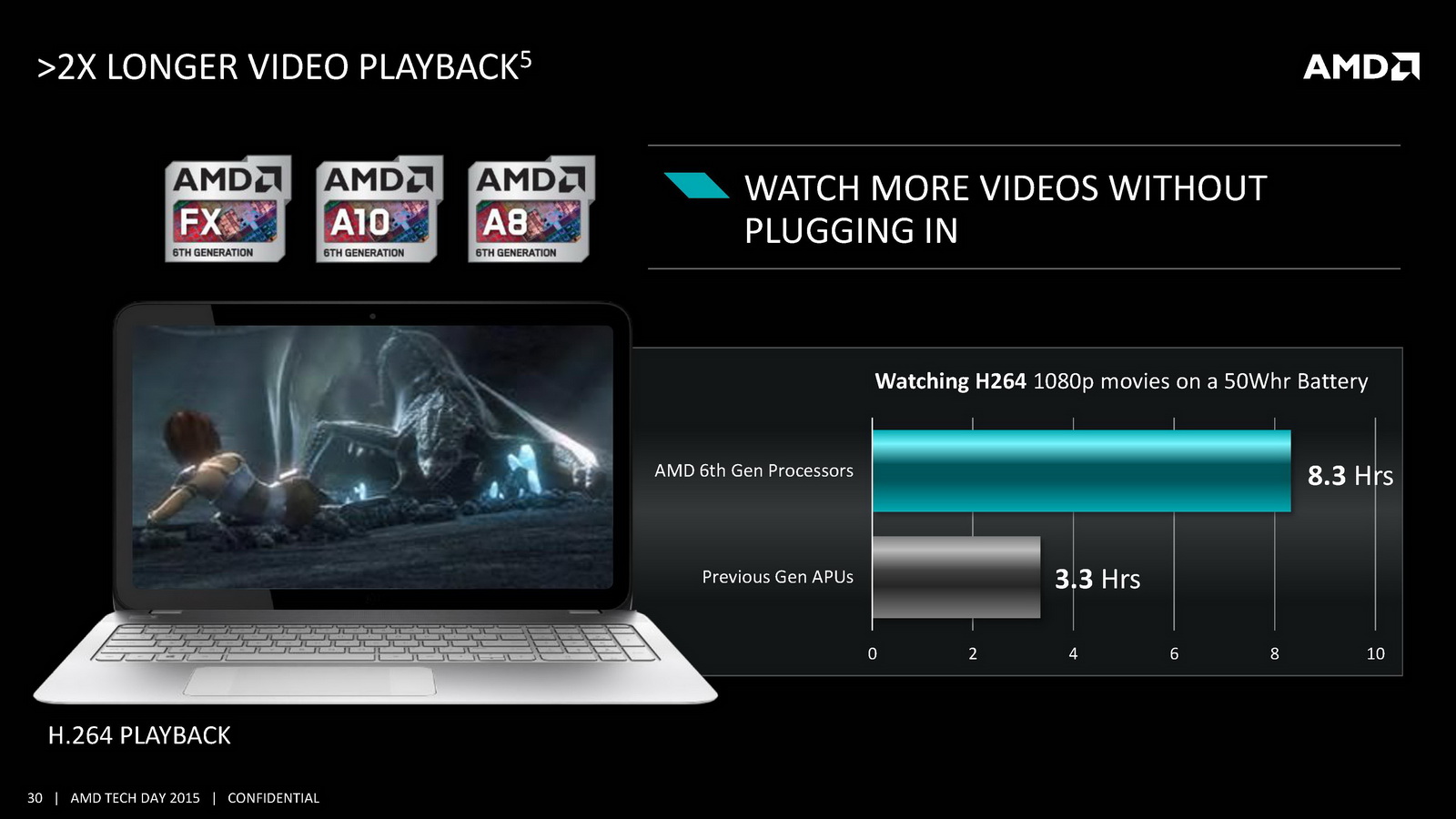
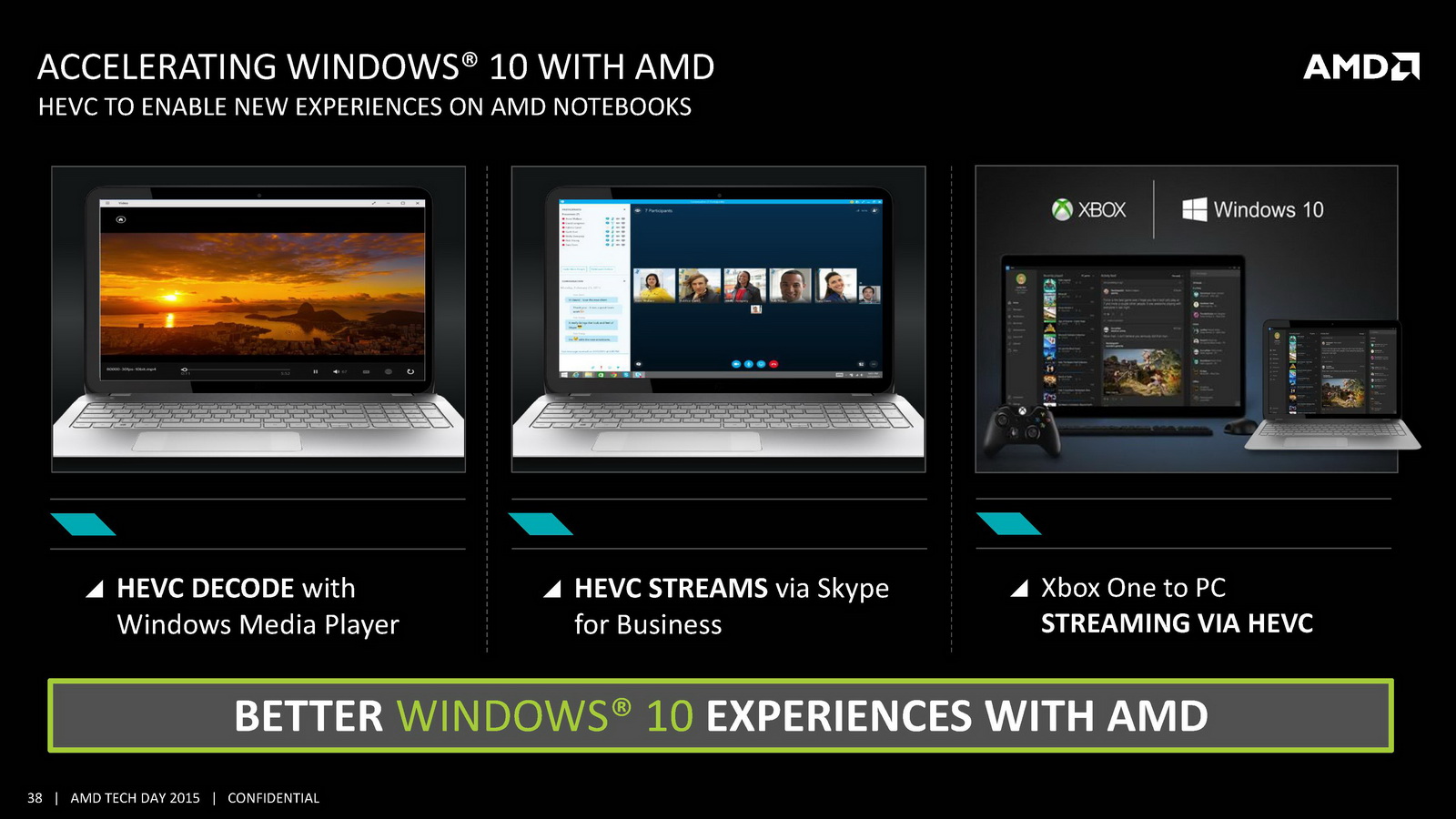
On notera d'autres changements au niveau de la lecture vidéo. On se souvient que lors de sa présentation aux analystes, AMD avait mis en avant un doublement du temps de lecture vidéo à batterie égale par rapport à son architecture précédente. Pour réaliser cela, AMD rajoute un path rapide pour la lecture vidéo qui permet d'éviter d'utiliser le GPU pour certaines tâches, notamment scaler l'image en plein écran ou pour d'autres taches de post-processing (désentrelacement, etc). AMD a donc ajouté un scaler dédié capable de fonctionner jusqu'en 4K. Son utilisation permet de gagner jusque 500mW en lecture vidéo comparativement à sa solution précédente, mais cela ne fonctionnera qu'avec certains lecteurs et si l'on n'utilise pas d'autres filtres de post processing. Interrogé sur la question des lecteurs capables d'utiliser cette technologie, AMD a pointé que le lecteur vidéo de Windows 10 gère la technologie, sans pouvoir nous en dire plus sur le type de changements à effectuer pour obtenir le support (un renderer particulier par exemple).
Au final, la gamme d'AMD est particulièrement étroite puisque seuls trois modèles sont lancés :
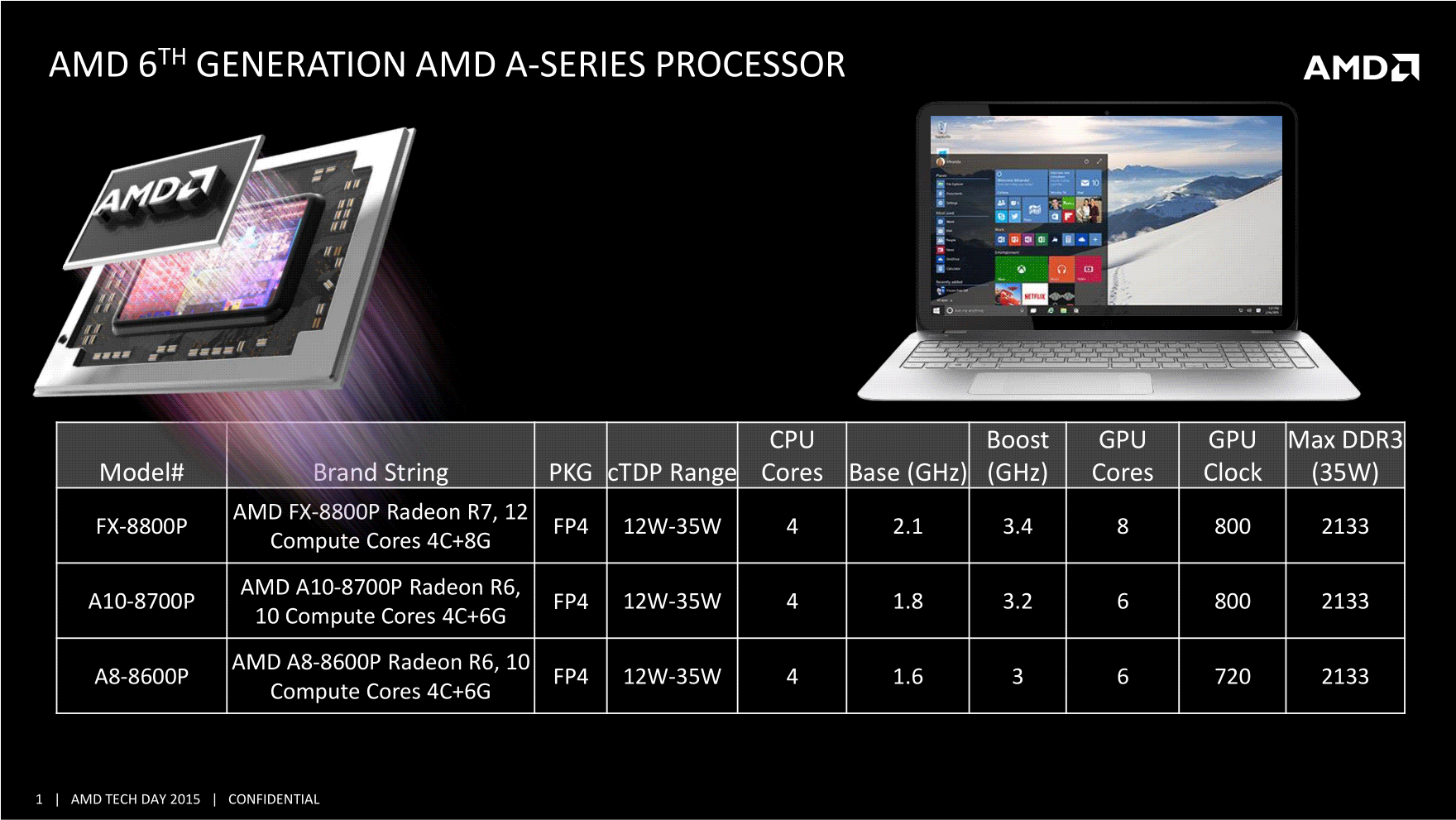
On retrouve ainsi un FX, un A10 et un A8 qui se différencient principalement par les fréquences. Seul le FX propose les 8 unités GPU là où les deux autres modèles n'en proposent que 6. On notera surtout que ces trois puces disposent d'un TDP configurable entre 12 et 35 watts. Un grand écart laissé, nous dit-on, pour offrir plus d'options aux partenaires OEM. En pratique on ne peut que craindre de ne pas pouvoir comparer des modèles utilisant pourtant des CPU identiques. D'aucuns diront qu'étant donné le peu de modèles de portables généralement disponibles utilisant des APU AMD, la comparaison ne sera pas forcément un problème, ou tout simplement une option ! La question du prix est également compliquée, pour des raisons techniques ou marketing, AMD se retrouve souvent relayé dans les gammes OEM dans le bas de gamme, ses puces mobiles les plus haut de gamme étant rarement choisies. La réduction de la gamme à trois puces est peut être une manière de tenter de pousser vers le haut les choix de ses partenaires, mais on ne sait pas si cela sera le cas. Le segment visé pour rappel entre 400 et 700 euros est plus haut qu'a l'habitude pour le constructeur et il est difficile, à la vue de ces spécifications, de comparer réellement à ce que proposera la concurrence, que ce soit Broadwell ou les futurs Skylake.
Au-delà des améliorations annoncées (le passage au format SoC, gains d'IPC, de fréquence), on ne peut pas s'empêcher de noter qu'il s'agit d'un des derniers tours de piste de nombre de technologies, à commencer par le 28 nm. « L'autre » 6eme génération de processeur, chez le concurrent, utilisera pour rappel le 14nm et il s'agira même de la seconde génération. Il s'agit aussi de la dernière version côté CPU des modules Bulldozer, une dernière itération qu'on nous promet comme plus efficace. Clairement, AMD tente de faire au mieux avec ce dont il dispose même si nombre de technologies utilisées sont en fin de vie. Et dans l'absolu il ne s'agira surement pas du vrai dernier tour de piste de ces technologies car si AMD annonce Zen pour 2016 (probablement au troisième trimestre), le constructeur a confirmé que ce seront les CPU Desktop les plus malmenés chez AMD ces dernières années qui profiteront en premier des nouveaux curs Zen. Une manière détournée de dire que les APU Zen n'arriveront qu'après. En 2017 ?