
Actualités cartes graphiques
Résultats Nvidia : +48% avec Nintendo et les datacenter
GTX 1080 Ti aux hormones chez KFA2
Pilotes Radeon 17.5.1
Pilotes GeForce 382.05 pour Prey et Battlezone
Les Radeon RX 580 et RX 570 d'Asus, MSI et Sapphire en test : Polaris acte 2
X370 et B350 en ROG Strix chez ASUS



ASUS vient de lancer deux nouvelles cartes mères AM4, les premières sous la gamme ROG Strix. La ROG Strix X370-F Gaming est assez proche sur le papier de la Prime X370-Pro, elle propose ainsi 6 phases pour l'alimentation des CCX, deux ports PCIe x16 Gen3 connectés à l'AM4 (en x8/x8 avec deux cartes), 8 SATA, un M.2 PCIe/SATA ou encore 2 ports USB 3.1 dont l'un est de Type-C cette-fois. On notera au passage côté USB que ASUS utilise désormais la dénomination USB 3.1 Gen1 et USB 3.1 Gen2 pour qualifier les ports USB 3.x à respectivement 5 et 10 Gbps, au lieu de USB 3.0 et USB 3.1 jusqu'alors. Bien qu'officielle cette dénomination n'est à notre sens pas la plus claire.



L'audio est pris en charge par un codec Realtek ALC1220 accompagné d'amplificateurs pour casque et d'un blindage, alors que la puce réseau Gigabit Intel I211-AT se voit affublé d'une protection contre les surintensités plus importante. La carte intègre également, à l'instar de la Crosshair, un générateur de fréquence externe facilitant l'overclocking par le bus. L'éclairage RGB est de la partie, avec 2 connecteurs pour synchroniser des éléments externes.



Cette fonctionnalité est également présente sur la ROG Strix B350-F Gaming. L'étage d'alimentation est un peu réduit, et compte a priori 5 phases pour le CCX. Cette fois le générateur de fréquence externe disparait et, B350 oblige, un seul port PCIe x16 Gen3 est connecté à l'AM4 ce qui rend impossible le SLI. Seuls 4 SATA sont présents, tous issus du B350. ASUS aurait pu en mettre 6 en utilisant le contrôleur SATA de Ryzen mais sur les cartes qui le font tous les ports SATA ne sont pas utilisables si le port M.2 est utilisé. A noter qu'AMD nous avait pourtant confirmé que le B350 pouvait supporter directement 6 SATA, une parole qui peut être mis en doute puisqu'aucune carte mère ne l'implémente.

Pour le reste cette B350 partage avec la X370 les parties audio et réseau, l'USB 3.1 Gen2 est cette-fois directement géré par le chipset et sous la forme de deux ports Type A. La ROG Strix X370-F Gaming arrivera début juin à 235 , il faudra compter 145 pour la ROG Strix B350-F Gaming qui débarquera fin mai.
Nvidia lance la GeForce GT 1030
Relativement discrètement, Nvidia vient de débuter la commercialisation d'une nouvelle déclinaison dans la famille GeForce 10 : la GeForce GT 1030. Une carte graphique d'entrée de gamme qui va venir se positionner face à la récente Radeon RX 550 d'AMD.
Bien qu'il ait souvent peu d'intérêt pour l'utilisateur final, le marché des cartes graphiques d'entrée de gamme reste important pour AMD et Nvidia puisqu'il permet de faire du volume dans la durée avec des produits qui restent au catalogue bien plus longtemps que le reste de la gamme.
Nvidia se devait donc de réagir à la Radeon RX 550 d'AMD, basée sur Polaris 12, un nouveau GPU 14nm. La GeForce GT 1030 va ainsi succéder aux vieillissantes GeForce GT 700 (Kepler) avec un nouveau GPU de génération Pascal : le GP108. Comme le GP107 et contrairement aux plus grosses puces de la famille, celui-ci est fabriqué en 14nm par Samsung.
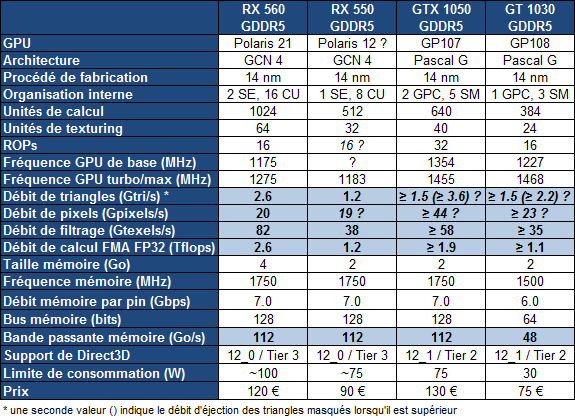
Grossièrement, le GP108 est un demi GP107 avec 3 SM (384 unités de calcul) et un bus mémoire de 64-bit. La GT 1030 affiche une puissance similaire à celle de la RX 550 mais profite d'une architecture plus efficace. Par contre sa bande passante est nettement inférieure puisqu'elle doit se contenter d'un bus de 64-bit.

Là où la solution de Nvidia se démarque c'est évidemment au niveau de la consommation qui tombe à 30W et permet de généraliser le refroidissement passif avec des radiateurs compacts. Cela se ressent aussi au niveau de la note puisque la GT 1030 se trouve à 75 contre 90 pour la RX 550.
Evidemment, de telles cartes graphiques n'ont à peu près aucun intérêt pour les joueurs. Elles vont permettre la mise à jour d'anciens systèmes vers une connectique d'affichage et des moteurs vidéos modernes (HDMI 2.1, DP 1.3/1.4, HEVC ), mais également aux OEM d'apposer un sticker Radeon ou GeForce sur des machines d'entrée de gamme.
Ces GPU auront un peu plus d'intérêt dans le monde mobile et devraient y débarquer sous peu. Nvidia aura l'avantage de la consommation alors qu'AMD aura plus de facilités à attirer le chaland avec une mémoire vidéo plus importante.
Radeon Vega Frontier Edition 16 Go: dispo fin juin
La première Radeon Vega sera la Frontier Edition disponible avant fin juin. Cette version 16 Go sera cependant réservée à une niche professionnelle.

A l'occasion du Financial Day annuel d'AMD, Raja Koduri a bien entendu parlé de Vega, sa future génération de GPU qui prendra place dans des Radeon haut de gamme pour joueurs (Radeon RX), stations de travail (Radeon Pro) et serveurs (Radeon Instinct).
Après avoir fait le tour des marchés potentiels sur lesquels AMD va pouvoir revenir grâce à cette nouvelle génération de GPU, et après avoir rappelé les quelques points d'architectures dévoilés en janvier, Raja Koduri a voulu s'attarder sur l'apprentissage machine (ou deep learning) qui est un domaine prioritaire pour AMD. C'est d'autant plus le cas qu'il intéresse particulièrement les investisseurs présents dans l'auditoire.

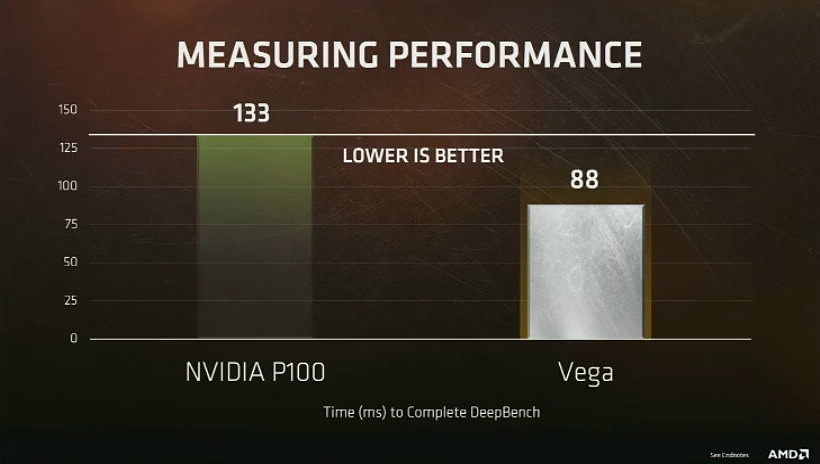
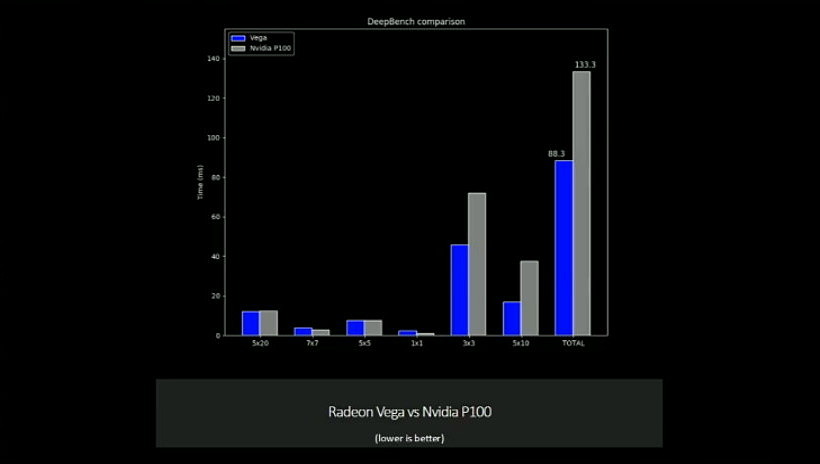
Nous avons droit à une première démonstration sous DeepBench avec un GPU Vega capable de surpasser le GP100 actuel de Nvidia de +/- 50%. Raja Koduri insiste cependant sur le fait que le but de la démonstration est avant tout de situer AMD sur la carte du deep learning et pas de se focaliser sur la confrontation avec Nvidia qui vient d'ailleurs d'annoncer le successeur du GP100. Par ailleurs, c'est toute une plateforme dédiée au deep learning que pourra offrir AMD avec Naples, Vega et son écosystème logiciel ROCm qui s'enrichit progressivement.
Est ensuite venu le moment de l'annonce d'une première déclinaison qui sera disponible fin juin : la Radeon Vega Frontier Edition 16 Go.




Contrairement à ce qui était attendu, ce n'est pas une carte graphique haut de gamme dédiée aux joueurs qui est ici annoncée par AMD. La Radeon Vega Fronter Edition, probablement fabriquée en petits volumes, va permettre à certains professionnels d'avoir un accès anticipé au GPU Vega 10 associé à 16 Go de mémoire HBM2. Viendront plus tard des Radeon Pro et Radeon Instinct (MI25) plus largement distribuée et qui profiteront d'un écosystème plus mûr. La Radeon Vega Frontier Edition s'inscrit dans la lignée de la Radeon Pro Duo (Fiji) et de la Radeon Pro SSG (avec SSD intégré), ou encore dans celle de la gamme Titan de Nvidia.

Quelques détails de plus ont été publiés par AMD dans la foulée. Nous pouvons ainsi découvrir que deux designs sont prévus, l'un a base de turbine, l'autre à base de watercooling. AMD communique ensuite un débit de pixels de 90 Gpixels/s, ce qui correspond à 64 ROP pour le GPU Vega 10, comme nous le supposions. Enfin, il est question d'une bande passante mémoire de 480 Go/s ce qui donnerait +/- 940 MHz pour la mémoire HBM2, ce qui se rapproche des 1 GHz attendus au départ et s'éloigne des récentes rumeurs qui faisaient plutôt état de 800 voire 700 MHz.

La seconde déclinaison annoncée aujourd'hui est la Radeon Pro Vega SSG qui sera également équipée de 16 Go de HBM2 auxquels AMD fait référence en tant que High Bandwidth Cache. Ce qui prend tout son sens ici puisque cette carte sera également équipée d'un SSD NVMe de 2 To. De quoi pouvoir conserver des datasets énormes à proximité du GPU. Restera évidemment à voir, au-delà des démonstrations d'AMD, avec quelle efficacité le tout sera piloté par le nouveau contrôleur du GPU Vega. Elle sera commercialisée dans quelques mois.
Les joueurs resteront bien évidemment sur leur faim puisqu'aucune annonce concrète n'a été effectuée par Raja Koduri concernant les déclinaisons grand public de Vega. Seront-telles disponibles fin juin également ou un peu plus tard ? Nous aurons peut-être quelques indices à ce sujet à l'occasion de la présentation d'AMD qui aura lieu dans 2 semaines au Computex.
Un (dernier ?) retard pour la HBM2 SK Hynix
SK Hynix a mis à jour en début de mois son catalogue de mémoire , avec quelques informations concernant la HBM2 et la GDDR6. Comme lors de la mise à jour de janvier la HBM2 n'est plus annoncée qu'en version 1,6 Gbps soit 204,8 Go /s par module de 4 Go 1024-bit. A l'époque la disponibilité était annoncée pour le premier trimestre, il est désormais fait mention de ce second trimestre, ce qui n'a peut-être pas aidé le calendrier du lancement de Vega. Rappelons qu'en juillet dernier, SK Hynix prévoyait une disponibilité de sa HBM2 pour le troisième trimestre 2016 !

La GDDR6 annoncée il y a peu par le constructeur est présente, mais alors que le communiqué d'avril faisait état d'un débit de 16 Gbps il n'est cette-fois question que de versions 14 et 12 Gbps. La tension est de 1,35V, comme les GDDR5 jusqu'à 6 Gbps alors que celles allant jusqu'à 8 sont à 1,55V chez les constructeur. La disponibilité de ces puces 1 Go 32-bit est annoncée pour fin 2017. En avril SK Hynix précisait que sa GDDR6 16 Gbps serait produite pour un lancement de GPU prévu début 2018.
La bande passante finale dépend bien entendu du nombre de puces utilisés. En HBM2, si on utilise 2 modules comme sur Vega on atteint 409,6 Go/s, le double si on peut se permettre comme sur un GV100 d'aller jusqu'à 4 modules. En GDDR6 14 Gbps, avec un bus 256-bit et 8 puces on atteint 448 Go/s, et 672 Go/s avec 12 puces en 384-bit. La bande passante n'est bien entendu pas le seul critère à prendre en compte puisqu'au-delà de son encombrement réduit la HBM est censée être moins énergivore à même débit.
Enfin la GDDR5 ne semble pas avoir dit son dernier mot chez SK Hynix des puces 9 et 10 Gbps sont annoncés dans ce catalogue pour le quatrième trimestre. On reste toutefois sous la vitesse de la GDDR5X Micron utilisée sur les GTX 1080 Ti et certaines GTX 1080 qui est à 11 Gbps.
Nvidia dévoile le GV100: 15 Tflops, 900 Go/s
Nvidia profite de sa GPU Technology Conference pour dévoiler quelques détails sur le GV100, le premier GPU de la génération Volta qui sera dédié au monde du calcul et en particulier de l'intelligence artificielle.

Comme c'est à peu près le cas chaque année, le CEO de Nvidia Jen Hsun Huang vient de profiter de la GTC pour dévoiler les grandes lignes du premier GPU de sa future génération Volta. Ce sera un monstre clairement orienté vers l'intelligence artificielle, un débouché qui monte en puissance pour les GPU Nvidia.
Le GV100 est le successeur direct du GP100 et reprend un format similaire : il s'agit d'une puce énorme placée sur un interposer avec 4 modules HBM2. Grossièrement c'est la même chose en mieux : plus gros et plus évolué.
Plus gros tout d'abord avec un GV100 qui profite de la gravure en 12 nm FFN de TSMC (personnalisé pour Nvidia) pour passer à 21.1 milliards de transistors, plus de 30% de plus que les 15.3 milliards du GP100. Malgré le passage au 12 nm, la densité ne progresse presque pas et le GV100 est énorme avec 815 mm² contre 610 mm² pour le GP100. Le 12 nm permet ici avant tout de pouvoir monter en puissance à consommation similaire.

Tout comme le GP100, le GV100 utilise des "demi SM" par rapport aux GPU grand public. Leur nombre passe de 60 à 84, ce qui représente 5376 unités de calcul. Ils restent répartis dans 6 blocs principaux, les GPC, ce qui laisse penser que Nvidia a tout misé sur un gain de puissance de calcul, sans trop toucher au débit de triangles ou de pixels qui étaient déjà à un niveau très élevé sur GP100.
Comme sur le GP100, ces SM sont capables de traiter différents niveau de précision : FP16 (x2), FP32 et FP64 (/2). Par ailleurs, Nvidia a ajouté quelques instructions spécifiques au deep learning et y fait référence en tant que tensor cores. Ils permettent aux algorithmes qui y feront appel de doubler la mise par rapport aux instructions 8-bits (produit scalaire avec accumulation) des GPU Pascal (sauf GP100) et du futur Vega d'AMD. A voir évidemment dans quelle mesure les différents algorithmes de deep learning pourront profiter de ces nouvelles instructions.
Nvidia en a profité pour améliorer le sous-système mémoire qui sera plus flexible pour demander moins d'efforts d'optimisation de la part des développeurs. Le cache L2 passe de 4 à 6 Mo et de la HBM2 Samsung plus rapide est exploitée mais qui restera au départ limitée à 4 Go par module soit 16 Go au total. Par ailleurs, le GV100 profite de 6 liens NV-Link de seconde génération (25 Go/s dans chaque direction) pour offrir une interface qui peut monter à 300 Go/s.

Le premier accélérateur qui profitera du GV100 est comme nous pouvions nous y attendre le Tesla GV100 qui sera initialement proposé dans un format de type mezzanine. Un tel module sera bien entendu gourmand mais Nvidia parle d'une enveloppe thermique maximale qui reste à 300W. Par ailleurs, deux modes énergétique seront proposé : Maximum Performance et Maximum Efficiency. Le premier autorise le GV100 à profiter de toute son enveloppe de 300W alors que le second limite probablement la tension maximale pour maintenir le GPU au meilleur rendement possible, ce qui a évidemment du sens pour de très gros serveurs.
Sur le Tesla GV100, le GPU sera amputé de quelques unités de calcul, pour faciliter la production seuls 80 des 84 SM seront actifs. Voici ce que cela donne :
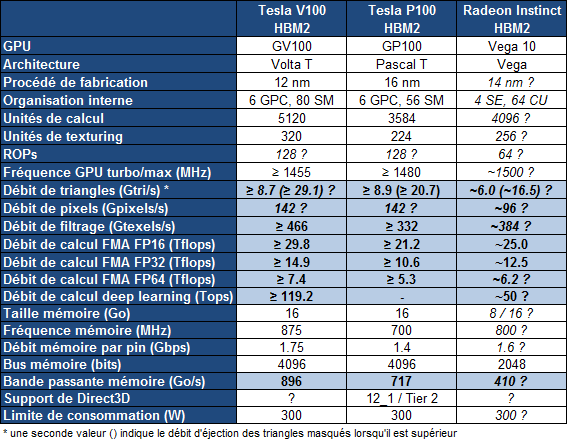
Le Tesla GV100 augmente la puissance brute de 40% par rapport au Tesla GP100, mais ses différentes optimisations feraient progresser les performances en pratique de +/- 60% dans le cadre du deep learning selon Nvidia. La bande passante mémoire progresse un peu moins avec "seulement" +25%, mais le cache L2 plus important et diverses améliorations compensent quelque peu cela.
Le GV100 devrait devancer assez facilement le Vega 10 d'AMD, mais ce dernier devrait être commercialisé en version Radeon Instinct à un tarif nettement moindre que le Tesla GV100 et en principe plus tôt. Nvidia parle de son côté du troisième trimestre et de 150.000$ pour les premiers serveurs DGX-1 équipés en GV100 et de la fin de l'année pour les accélérateurs au format PCI Express. Nvidia proposera évidemment d'ici-là des versions mises à jour de ses logiciels, compilateurs et autres librairies dédiées au deep learning.