
Kaveri : AMD A10-7850K et A10-7700K en test



L'attrait principal de Kaveri vient des changements architecturaux apportés. Après Richland et Trinity, AMD propose ici des nouveautés un peu partout, aussi bien côté processeur que pour la partie graphique.
Tout comme pour Trinity et Richland, AMD continue d'utiliser un dérivé de l'architecture Bulldozer qui avait été introduite à l'occasion des processeurs AMD FX en octobre 2011. Elle a subi un certain nombre de changements, Trinity/Richland utilisant la seconde itération de cette architecture, baptisée Piledriver. Aujourd'hui, AMD propose une troisième itération baptisée Steamroller. Nous avions déjà eu l'occasion de vous parler de cette architecture à l'été 2012 (Kaveri était alors encore prévu pour 2013).
Techniquement, AMD continue d'utiliser le concept de modules qui fait la particularité de ces architectures, même si Steamroller réalise quelques aménagements. Rappelons l'idée de base : AMD accole deux curs au sein d'un module et tente de mutualiser ce qui peut l'être. L'idée étant de réduire ainsi le nombre de transistors nécessaires pour obtenir des curs, ce qui réduit la place prise sur la puce (avec la possibilité de placer plus de modules) mais aussi potentiellement la consommation.
En contrepartie, chaque choix de mutualisation peut avoir un impact sur les performances. Techniquement, AMD avait choisi jusqu'ici d'utiliser de mutualiser trois choses :
- le « front-end » (la partie en amont du processeur qui décode les instructions avant de les envoyer aux unités d'exécutions) ainsi que le cache L1 d'instructions
- l'unité de calcule sur les nombres flottants
- le cache L2
Pour le reste, on retrouve des caches L1 de données séparés, ainsi que des unités d'exécution entières séparées. AMD annonçait ainsi qu'un module permet d'obtenir 80% des performances de deux curs complets.
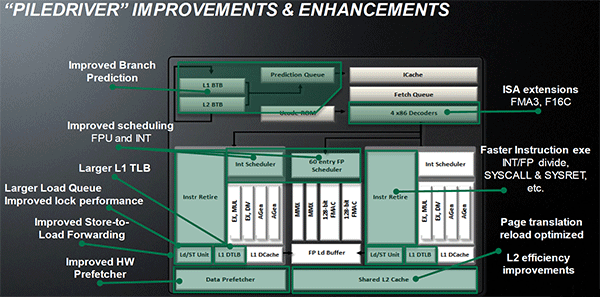
Si Piledriver avait été l'occasion de multiples petits changements, pour Steamroller AMD s'est intéressée plus particulièrement au front-end. Le premier changement évoqué par AMD concernait la taille du cache L1 d'instruction, qui passe de 64 à 96 Ko pour chaque module. L'autre changement important concerne un découplage dans le front end de la partie décodage d'instructions.

C'est un changement majeur puisque Steamroller dispose désormais de deux décodeurs séparés au lieu d'un, chaque décodeur pouvant accéder à ses propres unités entières, ou à l'unité d'exécution flottante partagée. Théoriquement, disposer de décodeurs séparés devrait améliorer les performances sur un thread, tout en améliorant assez significativement l'IPC. En pratique, on passe de quatre ops dispatchables par cycle (avec l'ancienne unité) à huit (quatre par « cur »). Cela se paye par contre du point de vue du nombre de transistors et de la consommation, un sujet sur lequel AMD ne communique pas précisément malheureusement. Que le constructeur le veuille ou non, découpler les décodeurs reste un retour en arrière par rapport aux ambitions initiales du concept des modules CMT. Il sera intéressant de voir en pratique si ce changement est pragmatique et s'il se concrétise par une amélioration notable des performances.
AMD a effectué également un certain nombre de modifications annexes en augmentant de ci de là des buffers et autres files d'attentes. C'est le cas par exemple des files d'attentes de lecture/écriture mémoire qui passent de 44 et 24 ops à 48 et 32 respectivement. De la même manière, le Branch Target Buffer de niveau 2 (un buffer utilisé dans le mécanisme de prédiction de branchements pour déterminer les adresses mémoires) voit lui aussi sa taille doubler de 5 à 10 Ko.
En pratique, nous avons pu observer quelques changements de comportement au niveau des caches entre Richland et Kaveri. Pour les tests suivants, nous avons cadencés les APU à 3.7 GHz en désactivant le Turbo, afin d'obtenir des résultats comparables. Ces scores sont relevés à l'aide du logiciel Aida64 :
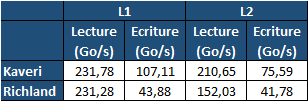
Côté L1, si l'on ne notera pas de changement en lecture, on note une amélioration très nette de la bande passante en écriture qui est plus que doublée. Du côté du cache L2, on note des gains des deux côtés avec +38% en lecture et +80% en écriture. Des changements potentiellement intéressants. Notez que la latence des caches n'évolue pas, on reste à 1.1 ns pour le L1, et environ 10ns pour le cache L2.
Kaveri est également l'occasion pour AMD de remettre à niveau la partie GPU de ses APU et l'on retrouve, à l'image de ce que nous avions vus pour Kabini l'année dernière, l'architecture GCN du constructeur.
Depuis les Radeon 9700 Pro, AMD utilisait une architecture VLIW, qui a évolué progressivement pour atteindre un niveau de flexibilité très élevé sur les dernières générations. VLIW, ou Very Long Instruction Word, consiste à exécuter des instructions complexes, qui sont en réalité l'assemblage d'une série d'instructions plus simples. Avec GCN, AMD remplace le VLIW par des unités SIMD (Single Instruction Multiple Data) capables d'exeucter des instructions sur 16 éléments en simultanée.

Il s'agit ici de la dernière version en date de GCN, celle que l'on retrouve dans les GPU Hawaii et dont nous vous avions parlé dans cet article. AMD indique avoir consacré 47% de la surface de Kaveri au GPU, ce qui se traduit en pratique par jusque huit Compute Unit. On notera également un peu plus en amont dans le GPU que les Asynchronous Compute Engine sont au nombre de 8, le même nombre que sur les R9 290. Il s'agit de files d'attentes pour les tâches non graphiques, augmenter leur nombre permet en théorie de fluidifier leur utilisation. Au nombre de deux dans la première itération de GCN, on trouvait quatre unités ACE dans Kabini pour aujourd'hui en trouver huit dans Kaveri.
On notera en parallèle qu'AMD indique avoir inclus de nouvelles versions de ses blocs UVD/VCE qui permettent respectivement de décoder et d'encoder des formats vidéos via des unités fixes. Au rang des nouveautés annoncées, on notera une meilleure résistance aux erreurs pour le décodage (particulièrement utile en cas de streaming) ainsi qu'une gestion des B-frames pour l'encodage H.264. Pour rappel, les B-frames sont des types d'images particulières dans un flux vidéo H.264 qui sont capables à la fois de faire référence à des images passées (le principe des P-frames) mais aussi des images à venir. Une nouveauté intéressante même si, comme nous nous en plaignons régulièrement, les logiciels d'encodage vidéo qui utilisent les blocs intégrés des processeurs sont souvent extrêmement limités dans leur capacité à exploiter les possibilités offertes par ces blocs. Pour plus de détails, nous vous renvoyons à cet article.
Avec Windows Vista, Microsoft a en quelque sorte mis à la retraite tous les accélérateurs audio matériel en imposant l'utilisation d'une pile audio et d'un mixer purement logiciel fourni par Microsoft. Si une technologie comme OpenAL résiste, en pratique les effets sonores restent aujourd'hui une affaire logicielle.
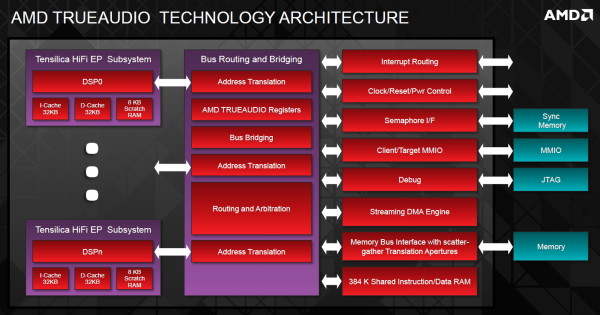
TrueAudio tente de changer la situation en proposant l'ajout de DSP directement dans ses GPU et APU utilisant des blocs HiFi EP de la société Tensilica .

Le nombre de blocs précis intégré dans Hawaii n'avait pas été précisé, et on n'en saura pas plus pour le nombre intégré dans les APU ce qui est fort dommage. En l'absence de plus d'informations, si vous souhaitez plus de détails sur le principe de TrueAudio, nous vous renvoyons vers cet article précédent.
Si sur le principe l'intégration de cette technologie est toujours une bonne chose, tenter d'imposer un standard audio supplémentaire et non compatible avec ce que peut proposer Intel ou Nvidia ne sera pas forcément aisé pour le constructeur qui devra convaincre de l'intérêt de cette solution. On imagine qu'AMD pourra s'appuyer sur sa position sur le marché des consoles Next Gen, même si le constructeur se refuse là encore à préciser si oui ou non, TrueAudio est disponible sur les APU des Playstation 4 et des Xbox One.
Un autre changement important concernant les APU Kaveri est le support du PCI Express 3.0. Les générations précédentes étaient en effet bridées en PCI Express 2.0 jusqu'ici.
De manière précise, seules les 16 lignes dédiées à un ou deux ports PCI Express graphique sont de type PCI Express 3.0. Kaveri comme les APU précédentes intègrent 8 lignes supplémentaires, quatre d'entre elles permettent de relier l'APU au chipset et quatre lignes GPP (General Purpose Ports) sont également disponibles. Dans les deux cas, ces lignes restent de type PCI Express 2.0.
 APU 3è génération
HSA et Compute Cores
APU 3è génération
HSA et Compute Cores

Steamroller : Bulldozer V3
Tout comme pour Trinity et Richland, AMD continue d'utiliser un dérivé de l'architecture Bulldozer qui avait été introduite à l'occasion des processeurs AMD FX en octobre 2011. Elle a subi un certain nombre de changements, Trinity/Richland utilisant la seconde itération de cette architecture, baptisée Piledriver. Aujourd'hui, AMD propose une troisième itération baptisée Steamroller. Nous avions déjà eu l'occasion de vous parler de cette architecture à l'été 2012 (Kaveri était alors encore prévu pour 2013).
Techniquement, AMD continue d'utiliser le concept de modules qui fait la particularité de ces architectures, même si Steamroller réalise quelques aménagements. Rappelons l'idée de base : AMD accole deux curs au sein d'un module et tente de mutualiser ce qui peut l'être. L'idée étant de réduire ainsi le nombre de transistors nécessaires pour obtenir des curs, ce qui réduit la place prise sur la puce (avec la possibilité de placer plus de modules) mais aussi potentiellement la consommation.
En contrepartie, chaque choix de mutualisation peut avoir un impact sur les performances. Techniquement, AMD avait choisi jusqu'ici d'utiliser de mutualiser trois choses :
- le « front-end » (la partie en amont du processeur qui décode les instructions avant de les envoyer aux unités d'exécutions) ainsi que le cache L1 d'instructions
- l'unité de calcule sur les nombres flottants
- le cache L2
Pour le reste, on retrouve des caches L1 de données séparés, ainsi que des unités d'exécution entières séparées. AMD annonçait ainsi qu'un module permet d'obtenir 80% des performances de deux curs complets.
Si Piledriver avait été l'occasion de multiples petits changements, pour Steamroller AMD s'est intéressée plus particulièrement au front-end. Le premier changement évoqué par AMD concernait la taille du cache L1 d'instruction, qui passe de 64 à 96 Ko pour chaque module. L'autre changement important concerne un découplage dans le front end de la partie décodage d'instructions.

C'est un changement majeur puisque Steamroller dispose désormais de deux décodeurs séparés au lieu d'un, chaque décodeur pouvant accéder à ses propres unités entières, ou à l'unité d'exécution flottante partagée. Théoriquement, disposer de décodeurs séparés devrait améliorer les performances sur un thread, tout en améliorant assez significativement l'IPC. En pratique, on passe de quatre ops dispatchables par cycle (avec l'ancienne unité) à huit (quatre par « cur »). Cela se paye par contre du point de vue du nombre de transistors et de la consommation, un sujet sur lequel AMD ne communique pas précisément malheureusement. Que le constructeur le veuille ou non, découpler les décodeurs reste un retour en arrière par rapport aux ambitions initiales du concept des modules CMT. Il sera intéressant de voir en pratique si ce changement est pragmatique et s'il se concrétise par une amélioration notable des performances.
AMD a effectué également un certain nombre de modifications annexes en augmentant de ci de là des buffers et autres files d'attentes. C'est le cas par exemple des files d'attentes de lecture/écriture mémoire qui passent de 44 et 24 ops à 48 et 32 respectivement. De la même manière, le Branch Target Buffer de niveau 2 (un buffer utilisé dans le mécanisme de prédiction de branchements pour déterminer les adresses mémoires) voit lui aussi sa taille doubler de 5 à 10 Ko.
En pratique, nous avons pu observer quelques changements de comportement au niveau des caches entre Richland et Kaveri. Pour les tests suivants, nous avons cadencés les APU à 3.7 GHz en désactivant le Turbo, afin d'obtenir des résultats comparables. Ces scores sont relevés à l'aide du logiciel Aida64 :
Côté L1, si l'on ne notera pas de changement en lecture, on note une amélioration très nette de la bande passante en écriture qui est plus que doublée. Du côté du cache L2, on note des gains des deux côtés avec +38% en lecture et +80% en écriture. Des changements potentiellement intéressants. Notez que la latence des caches n'évolue pas, on reste à 1.1 ns pour le L1, et environ 10ns pour le cache L2.
GCN
Kaveri est également l'occasion pour AMD de remettre à niveau la partie GPU de ses APU et l'on retrouve, à l'image de ce que nous avions vus pour Kabini l'année dernière, l'architecture GCN du constructeur.
Depuis les Radeon 9700 Pro, AMD utilisait une architecture VLIW, qui a évolué progressivement pour atteindre un niveau de flexibilité très élevé sur les dernières générations. VLIW, ou Very Long Instruction Word, consiste à exécuter des instructions complexes, qui sont en réalité l'assemblage d'une série d'instructions plus simples. Avec GCN, AMD remplace le VLIW par des unités SIMD (Single Instruction Multiple Data) capables d'exeucter des instructions sur 16 éléments en simultanée.

Il s'agit ici de la dernière version en date de GCN, celle que l'on retrouve dans les GPU Hawaii et dont nous vous avions parlé dans cet article. AMD indique avoir consacré 47% de la surface de Kaveri au GPU, ce qui se traduit en pratique par jusque huit Compute Unit. On notera également un peu plus en amont dans le GPU que les Asynchronous Compute Engine sont au nombre de 8, le même nombre que sur les R9 290. Il s'agit de files d'attentes pour les tâches non graphiques, augmenter leur nombre permet en théorie de fluidifier leur utilisation. Au nombre de deux dans la première itération de GCN, on trouvait quatre unités ACE dans Kabini pour aujourd'hui en trouver huit dans Kaveri.
On notera en parallèle qu'AMD indique avoir inclus de nouvelles versions de ses blocs UVD/VCE qui permettent respectivement de décoder et d'encoder des formats vidéos via des unités fixes. Au rang des nouveautés annoncées, on notera une meilleure résistance aux erreurs pour le décodage (particulièrement utile en cas de streaming) ainsi qu'une gestion des B-frames pour l'encodage H.264. Pour rappel, les B-frames sont des types d'images particulières dans un flux vidéo H.264 qui sont capables à la fois de faire référence à des images passées (le principe des P-frames) mais aussi des images à venir. Une nouveauté intéressante même si, comme nous nous en plaignons régulièrement, les logiciels d'encodage vidéo qui utilisent les blocs intégrés des processeurs sont souvent extrêmement limités dans leur capacité à exploiter les possibilités offertes par ces blocs. Pour plus de détails, nous vous renvoyons à cet article.
TrueAudio
Avec Windows Vista, Microsoft a en quelque sorte mis à la retraite tous les accélérateurs audio matériel en imposant l'utilisation d'une pile audio et d'un mixer purement logiciel fourni par Microsoft. Si une technologie comme OpenAL résiste, en pratique les effets sonores restent aujourd'hui une affaire logicielle.
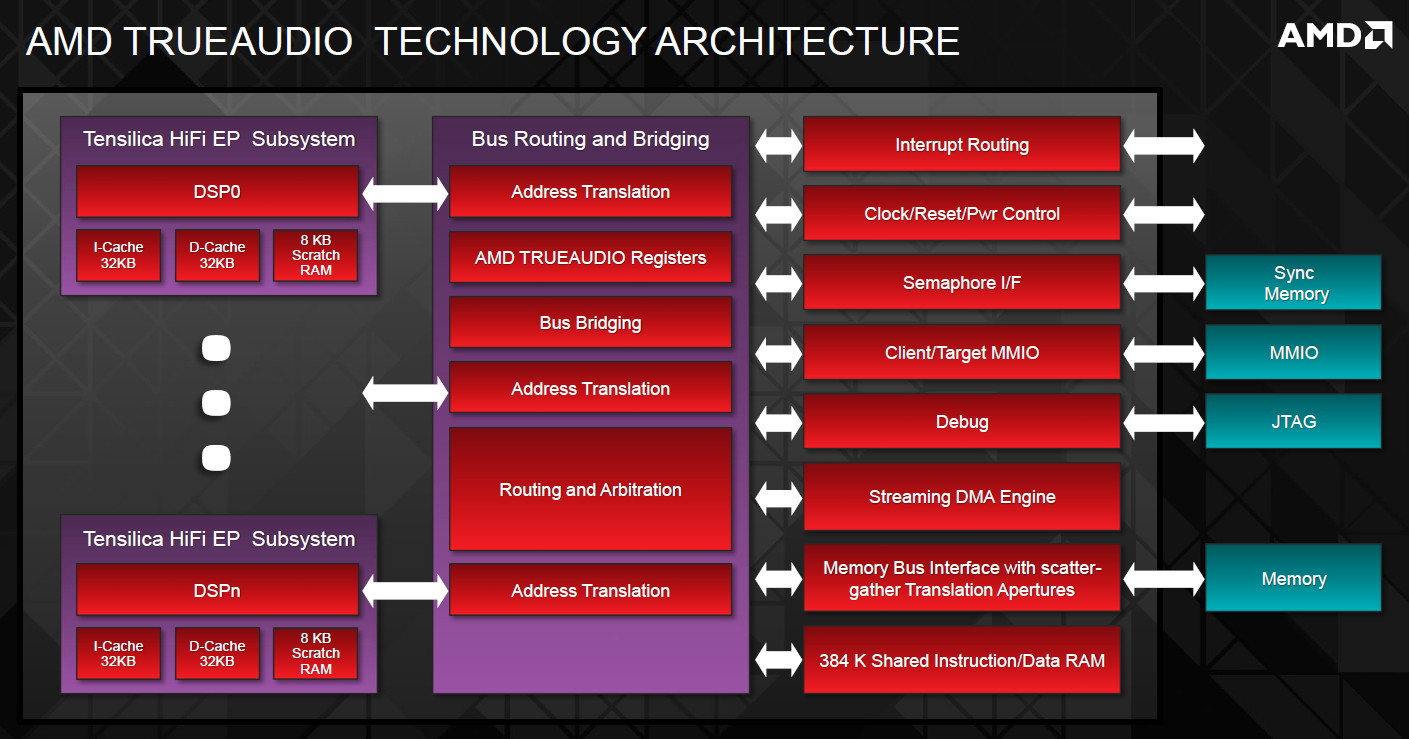
TrueAudio tente de changer la situation en proposant l'ajout de DSP directement dans ses GPU et APU utilisant des blocs HiFi EP de la société Tensilica .

Le nombre de blocs précis intégré dans Hawaii n'avait pas été précisé, et on n'en saura pas plus pour le nombre intégré dans les APU ce qui est fort dommage. En l'absence de plus d'informations, si vous souhaitez plus de détails sur le principe de TrueAudio, nous vous renvoyons vers cet article précédent.
Si sur le principe l'intégration de cette technologie est toujours une bonne chose, tenter d'imposer un standard audio supplémentaire et non compatible avec ce que peut proposer Intel ou Nvidia ne sera pas forcément aisé pour le constructeur qui devra convaincre de l'intérêt de cette solution. On imagine qu'AMD pourra s'appuyer sur sa position sur le marché des consoles Next Gen, même si le constructeur se refuse là encore à préciser si oui ou non, TrueAudio est disponible sur les APU des Playstation 4 et des Xbox One.
PCI Express 3.0
Un autre changement important concernant les APU Kaveri est le support du PCI Express 3.0. Les générations précédentes étaient en effet bridées en PCI Express 2.0 jusqu'ici.
De manière précise, seules les 16 lignes dédiées à un ou deux ports PCI Express graphique sont de type PCI Express 3.0. Kaveri comme les APU précédentes intègrent 8 lignes supplémentaires, quatre d'entre elles permettent de relier l'APU au chipset et quatre lignes GPP (General Purpose Ports) sont également disponibles. Dans les deux cas, ces lignes restent de type PCI Express 2.0.
Sommaire
Vos réactions
Contenus relatifs
- [+] 17/03: AMD baisse ses prix AM3+/FM2+
- [+] 06/04: AMD pré-annonce Bristol Ridge
- [+] 02/02: Excavator FM2+ et nouveaux ventirad...
- [+] 11/01: AMD A10-7890K pour fêter les 2 ans ...
- [+] 20/07: AMD lance l'A8-7670K
- [+] 28/05: AMD lance l'A10-7870K, le premier '...
- [+] 13/05: AMD baisse les prix des Kaveri
- [+] 17/03: Godavari confirmé par ASRock
- [+] 28/01: AMD A10-8850K Godavari, un A10-7850...
- [+] 15/01: Pas d'AMD Carrizo en FM2+ ?!