
16 curs en action : Asus Z9PE-D8 WS et Intel Xeon E5-2687W
Publié le 09/05/2012 par Guillaume Louel



MESI, MOESI, MESIF, NUMA
Avec l'arrivée des processeurs multi-curs, le concept des ressources multiples et partagées a été largement intégré, aussi bien côté hardware que dans les systèmes d'exploitations. Dans un processeur moderne, on retrouve un seul contrôleur mémoire qui est utilisé par de multiples curs, avec entre les deux une hiérarchie de caches (pour stocker les données mémoire les plus utilisées), parfois uniques à chaque cur, parfois partagés, afin de créer un système qui permette à la fois de partager efficacement le contrôleur et de maximiser les performances. Et côté systèmes d'exploitation, si l'on dispose de multiples curs, tous partagent la même mémoire.
La question de la ressource partagée entraine cependant de nouveaux problèmes : que se passe-t-il si un cur veut accéder à une donnée mémoire utilisée par un autre cur ? Quelle "version" de la donnée est la bonne, celle stockée en RAM ou celle stockée dans le cache ?
Un peu de coordination devient rapidement nécessaire
Pour gérer ces conflits, des mécanismes ont été crées, le plus classique étant le protocole MESI qui permet de donner un état (Modified, Exclusive, Shared, Invalid) aux lignes de caches afin de permettre aux curs de se coordonner un minimum.
MESI
Utilisé jusque Nehalem par Intel, MESI est un protocole qui permet deux choses :
- Assurer la cohérence des caches entre eux et avec la mémoire
- Permettre un concept d'entraide entre les curs
Prenons l'exemple ou un cur A a besoin de lire une donnée en mémoire. Grace à MESI, il va se renseigner d'abord pour savoir si quelqu'un utilise ces données. Une requête est alors envoyée vers tous les autres curs. Si personne ne dispose de la donnée demandée, le contrôleur mémoire va alors aller chercher en mémoire la donnée demandée pour
Ainsi, si un cur A à besoin de lire une donnée en mémoire, il va se renseigner pour savoir si quelqu'un utilise ces données en envoyant une requête. Si personne ne dispose de la donnée elle sera récupérée en mémoire par le contrôleur puis renvoyé au cache qui la demandait. Cependant si un autre cur B avait déjà demandé cette donnée auparavant pour la lire, il aura placé lui aussi cette ligne de cache en état Exclusive. C'est là que l'entraide joue, le cur B va alors passer en état Shared pour indiquer qu'il n'est plus le seul à disposer de cette donnée, et il va envoyer la donnée directement au cur A (on parle de forward) qui devient alors lui aussi propriétaire de cette copie (on parle d'instance). Le système fonctionne particulièrement bien lorsque l'on a deux curs au maximum qui peuvent accéder à une même donnée. Si par contre une même donnée est en état Shared sur plusieurs curs, tous ces curs répondront à la requête ! Plusieurs réponses identiques transitent alors entre les curs, ce qui fait perdre de la bande passante pour rien. L'entraide, mal dirigée, peut avoir ses limites.
Pour notre second exemple, admettons la donnée recherchée par notre cur A ait non pas été lue par le cur B, mais qu'il l'ait lu, puis modifiée. En pratique, le cur B aura passé cette ligne de cache de l'état Exclusive à l'état Modified. Cet état est original puisqu'il indique que les données en mémoire principale ne sont plus bonnes (dirty) et que c'est ce cache qui devient le seul et unique détenteur de la vérité concernant ces données. Si notre cur A demande à ce moment cette donnée, le cur B va devoir, pour assurer la cohérence, effectuer un tas d'opérations :
- Envoyer ses modifications en mémoire centrale afin de synchroniser les changements (writeback)
- Changer l'état de la ligne de cache en mode Shared
- Envoyer la copie, à jour, au cur A (forward)
Ces opérations sont bien entendues couteuses, en premier lieu puisque l'on implique le contrôleur mémoire dans l'histoire !
MOESI
Pour corriger ces problèmes évoqués précédemment, plusieurs évolutions de MESI ont été crées. AMD de son côté à choisi le MOESI. Ce protocole change la donne sur les deux points évoqués au dessus, en introduisant un état Owned. Si l'on reprend notre premier cas, le cur B pourra passer du mode Exclusive au mode Owned avant d'envoyer la copie. Jusqu'ici, peu de différence, mais si par contre un troisième cur souhaite accéder à cette donnée, en MESI, les curs A et B enverront en simultanée la réponse. MOESI permet de limiter ceci : les curs en état Shared ne répondent pas aux requêtes ! Seul le cur en état Owned répondra, limitant le trafic.
Dans le second cas, notre cur B en état Modified, au lieu d'effectuer ses multiples opérations (writeback, changement en mode Shared, forward) passera simplement en mode Owned avant d'envoyer la donnée au cur A. On économise ici de la bande passante mémoire, ce qui est un gros progrès
MESIF
Depuis Nehalem, Intel a abandonné le MESI pour proposer le MESIF auquel il ajoute un nouvel état, Forwarding. Ainsi dans notre premier exemple, lorsque le coeur A réclame les données, le cur B passera du mode Exclusive au mode Forwarding. Dans ce cas précis, il agira comme le mode Owned de MOESI à savoir qu'il sera le seul à répondre aux requêtes pour limiter le trafic.
Dans le second cas cependant, le mode MESIF n'apporte rien. Si sur le papier MESIF est un modèle qui peut paraitre moins intéressant, comme toujours en informatique, tout est question de compromis : une implémentation MOESI peut être plus complexe à mettre au point qu'une implémentation MESIF.
Et dans un système multi CPU ?
Nous avons décrit ici une situation relativement simple ou l'on ne dispose que d'un seul processeur avec plusieurs curs, disposant d'un système de cache et d'un unique contrôleur mémoire. Mais quid d'un système multi CPU moderne ou chaque processeur dispose de son propre contrôleur, et donc de ses propres barrettes mémoires ?
On trouve deux possibilités. La plus simple, et pas forcément la plus intuitive consiste à dupliquer les données. A l'image du RAID pour les disques durs, chaque contrôleur mémoire stockera une copie des données. On divise donc la mémoire disponible par deux sur une plateforme bi socket. En cas de lecture, le cas est simple, les curs de chaque processeurs disposent d'une copie locale de la donnée qui les intéresse. En cas d'écriture, chaque changement doit être reporté simultanément dans tous les espaces mémoires.
NUMA
Le mode de fonctionnement le plus intéressant resterait la possibilité de pouvoir agréger la mémoire associée à chaque processeur en un grand espace mémoire commun qui pourra être utilisé comme tel par le système d'exploitation. D'un point de vue théorique, il suffit de donner la possibilité au processeur A d'utiliser la mémoire placée dans le processeur B. C'est à cela que servent les deux liens QPI intégrés dans le processeur. Dans le cas des SNB-E, ces liens sont cadencés à 4 GHz, ce qui signifie 32 Go/s de bande passante utile dans chaque sens.
Se pose cependant deux problèmes. Le premier est d'ordre pratique : l'espace mémoire vu par le système d'exploitation étant unique, comment doit-on répartir la mémoire entre les deux sockets ? La méthode traditionnelle consiste à enchevêtrer les banks mémoires. Cela veut dire qu'a tout moment, un programme aura la moitié de ses données présentes sur chacun des sockets, indépendamment du processeur ou il s'exécute.
L'autre possibilité est d'utiliser un protocole intelligent qui réclame la collaboration du système d'exploitation. C'est ce que l'on appelle NUMA, pour Non Uniform Memory Access. En mode NUMA, le système d'exploitation prend conscience du fait qu'il existe deux espaces mémoires logiques distincts, un peu à l'image de la manière dont le noyau prend en compte l'HyperThreading ou les architectures sous formes de module des AMD FX. Le système d'exploitation tentera alors d'allouer la mémoire dans le socket qui correspond au cur processeur qui exécute le thread censé utiliser la mémoire. Grace au protocole MESIF vu précédemment (ou MOESI chez AMD), dans le cas ou une application partage des données entre plusieurs threads, les transferts mémoires s'opèreront lorsque cela est nécessaire.
Sur le papier, le mode NUMA semble logiquement être le meilleur mais comme souvent les choses ne sont pas forcément si simple. Nous avons d'abord comparé la latence et la bande passante mémoire multithreadée via les logiciels RMMT et Aida64. Notez que pour ces tests théoriques, nous avons désactivé l'HyperThreading ainsi que quatre curs sur chaque processeur. La raison derrière cette limitation vient du fait que RMMT ne permet pas de gérer plus de huit threads en simultanée, un problème sur lequel nous reviendrons ultérieurement. Huit barrettes de 4 Go de mémoire DDR3 registered cadencée à 1066 (CAS7) sont installées pour ces tests :
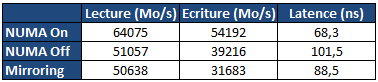
Pour rappel, en mode mirroring seuls 16 Go sont disponibles. En mode NUMA Off et NUMA On, les 32 Go sont disponibles, mais si NUMA est désactivé, l'espace mémoire est enchevêtré entre les deux sockets. On notera de manière assez logique que le mode Mirroring est le moins efficace en matière d'écritures mémoires. Chaque écriture réalisée est envoyée vers les deux contrôleurs mémoire en simultanée, saturant les 32 Go/s offerts par le bus QPI.
Si l'on désactive le mirroring, la bande passante en écriture remonte, on est toujours partiellement limité par le bus QPI, mais le fait que le contrôleur local ainsi que le contrôleur distant soient utilisés alternativement mitige les problèmes. Activer NUMA permet de maximiser les performances avec un gros gain aussi bien sur la lecture, l'écriture que la latence, chaque thread utilisant la mémoire locale du socket sur lequel il s'exécute.
Bien entendu les performances théoriques sont l'occasion de contres exemples pratiques ! Nous avons mesuré les performances sous 7-Zip, la valeur indiquée est un temps de compression en secondes :
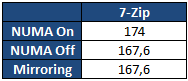
7-Zip est plus lent en mode NUMA. Il s'agit bien entendu d'un cas particulier. Ici, le logiciel utilise un dictionnaire de données commun entre tous ses threads et dont l'accès est partagé. NUMA dans ce cas peut engendrer une légère perte de performances, qui semble plus particulièrement liée au choix de l'utilisation du protocole de cohérence MESIF. Comme toujours en informatique tout est une question de compromis et si, pour une utilisation générale l'activation de NUMA est toujours conseillée, à l'image de l'HyperThreading dans certains cas, elle peut également être légèrement contreproductive. Selon le type d'applications utilisées, chacun pourra configurer les contrôleurs mémoire en fonction de ses besoins. Pour les tests qui suivent nous avons opté pour la configuration par défaut, et celle qui hors 7-Zip est systématiquement la plus efficace.
Sommaire
1 - Introduction
2 - SMP, Nehalem, QPI, quelques rappels
3 - MESI, MOESI, MESIF, NUMA
4 - Xeon E5-2687W
5 - Asus Z9PE-D8 WS
2 - SMP, Nehalem, QPI, quelques rappels
3 - MESI, MOESI, MESIF, NUMA
4 - Xeon E5-2687W
5 - Asus Z9PE-D8 WS
Vos réactions
Contenus relatifs
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 15/03: Microcode final pour Spectre chez I...
- [+] 31/08: Skylake-X LGA 2066 décliné en Xeon-...
- [+] 12/07: Intel lance ses Xeon Scalable
- [+] 04/05: La famille Xeon devient Scalable
- [+] 27/04: Xeon Platinum pour accompagner les ...
- [+] 29/03: Kaby Lake décliné en Xeon E3 v6
- [+] 14/02: Xeon E7-8894 v4, pour 200 MHz de pl...
- [+] 07/02: Intel : un Xeon Gold dans les tuyau...