
Nvidia Fermi : la révolution du GPU Computing
Publié le 01/10/2009 par Damien Triolet



IEEE754-2008Les SIMDs de Fermi ne reposent plus sur une instruction de type MAD (multiply add) mais sur une instruction de type FMA (fused multiply add). La différence se situe au niveau de la précision. MAD se comporte réellement comme une multiplication flottante suivie dune addition flottante, cest-à-dire que le résultat est arrondi à chaque étape. FMA par contre conserve la précision intermédiaire et neffectue larrondi quà la fin.
Fermi, tout comme Cypress, supporte complètement la norme IEEE754-2008 et donc les nombres dénormalisés et les 4 modes darrondis. Par contre une grosse différente entre Cypress et Fermi est que ce dernier nest plus capable de traiter les MADs classiques tant en simple quen double précision. Nvidia nous a indiqué, par défaut, remplacer tous les MADs par des FMAs. Cette solution ne produit cependant pas un résultat équivalent, même si plus précis, ce qui peut être source de problèmes. Il sera cependant possible de préciser lors de la compilation de ne pas utiliser le FMA mais de scinder les MADs en MULs + ADDs, une solution qui sera presque identique. Pour obtenir un résultat parfaitement identique il faudra cependant se passer du MAD sur les architectures actuelles et du FMA sur la nouvelle.
De son côté, Cypress est capable de traiter autant les MADs que les FMAs, en simple et en double et à la même vitesse, ce qui est probablement facilité par son émulation des doubles à partir des unités FP32 et des produits partiels. Nvidia nous a indiqué que labandon du MAD a été décidée par rapport au coût très important quil aurait nécessité par rapport à son architecture.
Lutilisation de linstruction FMA permet daccélérer certaines fonctions comme les divisions et les racines carrées. Nvidia nous a indiqué quil fournira une nouvelle bibliothèque de fonctions mathématiques qui sera utilisée automatiquement lors de la compilation pour Fermi et exploitera linstruction FMA pour les accélérer. Du côté dAMD, Cypress utilise déjà linstruction FMA en double précision pour accélérer les divisions (DIV) et les racines carrées (SQRT).
Puissance de calcul maximaleNous avons mis en graphique la puissance de calcul maximale des différentes architectures avec quelques instructions courantes. Pour Fermi nous avons pris en compte un MAD séparé en MUL + ADD et une fréquence conservative de 1600 MHz pour les unités de calcul. Nous avons ajouté, pour information, la puissance de calcul maximale autorisées par les unités SSE dun Core i7 975.
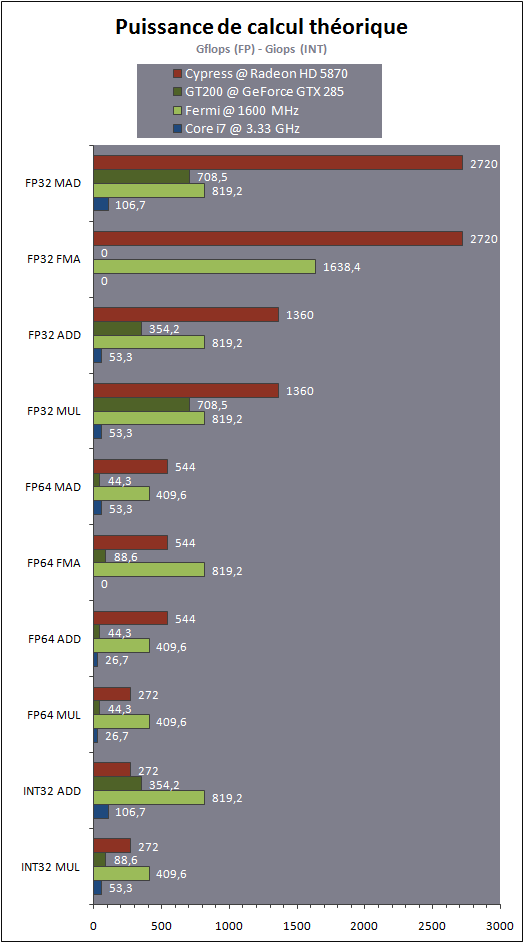
Par rapport à la génération précédente, les gains apportés par Fermi sont énormes, surtout en double précision.
Si Cypress affiche une puissance de calcul supérieure en simple précision flottante, il faut garder en tête quil est plus difficile de latteindre en pratique compte tenu de son architecture. En double précision, Fermi prend la tête avec 50% de puissance supplémentaire, sauf avec les additions. Etant donné quun seul MUL, MAD ou FMA est traité par cycle il ny a dans ces cas-là pas de perte defficacité liée à larchitecture vectorielle.
Sommaire
5 - Parallel DataCache
6 - 16 multiprocesseurs musclés
7 - IEEE754-2008 et puissance de calcul
8 - Conclusion
6 - 16 multiprocesseurs musclés
7 - IEEE754-2008 et puissance de calcul
8 - Conclusion
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...