
Nvidia Fermi : la révolution du GPU Computing
Publié le 01/10/2009 par Damien Triolet



Parallel DataCacheLe sous-système mémoire de Fermi a été entièrement revu. Dans le GT200 et les GPUs précédents, Nvidia ne disposait pas de véritables caches L1 et L2. Il sagissait en réalité de texture caches dédiés uniquement à laccès aux textures. Les opérations de type Load / Store ne bénéficiaient daucun cache, contrairement à ce qui se fait chez AMD depuis le RV770.
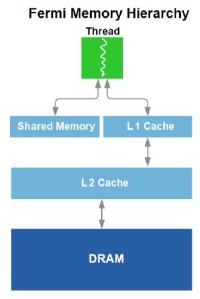 Nvidia se devait donc de revoir sa structure de caches et dabandonner les textures caches au profit de caches L1 et L2 plus généralistes. Chaque multiprocesseur de Fermi dispose donc dun cache L1 programmable qui va servir autant de L1 que de mémoire partagée. Ce cache de 64 Ko va fonctionner avec 48 Ko pour lun et 16 Ko pour lautre, au cas par cas. 64 Ko en mode L1 ou en mode mémoire partagée ou encore 32 Ko et 32 Ko ne sont pas permis, nous ne savons pas pourquoi, Nvidia nayant pas voulu détailler ce point. La mémoire partagée des GPUs Nvidia actuels est limitée à 16 Ko. Avec de tels codes, il sera donc possible soit de profiter de 48 Ko de L1, soit de se limiter à 16 Ko de L1 et de disposer de plus de groupes de threads (chacun ayant besoin de sa propre mémoire partagée) dans le multiprocesseur pour mieux masquer les latences. Cest également le cas avec DirectX 11 qui requiert la possibilité dutiliser une mémoire partagée de 32 Ko, mais cest bien entendu un maximum. Si un développeur nen utilise que 16 ou 24 Ko, ce sont 3 ou 2 groupes de threads qui pourront résider dans le multiprocesseur. Notez que la configuration du L1 sera décidée par le compilateur et non par le développeur.
Nvidia se devait donc de revoir sa structure de caches et dabandonner les textures caches au profit de caches L1 et L2 plus généralistes. Chaque multiprocesseur de Fermi dispose donc dun cache L1 programmable qui va servir autant de L1 que de mémoire partagée. Ce cache de 64 Ko va fonctionner avec 48 Ko pour lun et 16 Ko pour lautre, au cas par cas. 64 Ko en mode L1 ou en mode mémoire partagée ou encore 32 Ko et 32 Ko ne sont pas permis, nous ne savons pas pourquoi, Nvidia nayant pas voulu détailler ce point. La mémoire partagée des GPUs Nvidia actuels est limitée à 16 Ko. Avec de tels codes, il sera donc possible soit de profiter de 48 Ko de L1, soit de se limiter à 16 Ko de L1 et de disposer de plus de groupes de threads (chacun ayant besoin de sa propre mémoire partagée) dans le multiprocesseur pour mieux masquer les latences. Cest également le cas avec DirectX 11 qui requiert la possibilité dutiliser une mémoire partagée de 32 Ko, mais cest bien entendu un maximum. Si un développeur nen utilise que 16 ou 24 Ko, ce sont 3 ou 2 groupes de threads qui pourront résider dans le multiprocesseur. Notez que la configuration du L1 sera décidée par le compilateur et non par le développeur.Après ce cache L1 programmable, se trouve un cache L2 cohérent et unifié de 128 Ko par contrôleur mémoire, soit de 768 Ko au total. Pour comparaison, Cypress se contente ici de 512 Ko. Les opérations Load/Store passeront par ces 2 caches avant de se résoudre à aller voir en mémoire vidéo. Lavantage est bien entendu de pouvoir récupérer ces données plus rapidement si elles sont en cache, mais pas uniquement. Cette structure permet également déviter les problèmes de lecture après écriture puisquil est très couteux de gérer cela dune manière sûre quand ces 2 opérations se font via des canaux différents.
Un autre avantage de cette structure de caches est de pouvoir réduire lincidence sur les performances dun dépassement du nombre de registres disponibles en interne. Auparavant les registres supplémentaires devaient résider en mémoire vidéo, avec une latence en complet décalage avec le rôle dun registre. Dorénavant, ces registres pourront être cachés.
Le cache L2, en combinaison avec un nombre plus élevé dunités dédiées, va permettre daccélérer le traitement des opérations atomiques qui protègent une zone mémoire le temps quun thread puisse la lire, la modifier et écrire le résultat. Avec le cache L2, il est maintenant possible de traiter des opérations atomiques qui se succèdent sur une même zone mémoire en opérant les modifications dans le cache L2 sans faire des aller-retours vers la mémoire vidéo. Nvidia parle de gains allant de 5x à 20x, mais sans préciser dans quelles conditions ils peuvent être obtenus.
Enfin, Nvidia a ajouté une fonction très attendue dans le monde professionnel : lECC. Ce support permet de détecter les erreurs dans les différentes mémoires et éventuellement de les corriger. Nous ne connaissons pas limplémentation exacte quen a faite Nvidia puisque le fabricant a préféré éviter de rentrer dans ces détails. Nous savons par contre que les registres, les caches L1 et L2 sont protégés au même titre que la mémoire vidéo GDDR5 ou DDR3. La première nexiste cependant pas encore en version ECC mais sera une mémoire de choix pour Fermi puisquen plus doffrir nettement plus de bande passante que la DDR3, avec laquelle Fermi risque dêtre à létroit, elle sécurise également le transfert des données. Notez que nous parlons ici de DDR3 et non de GDDR3, la première étant la seule compatible avec lECC.
Sommaire
5 - Parallel DataCache
6 - 16 multiprocesseurs musclés
7 - IEEE754-2008 et puissance de calcul
8 - Conclusion
6 - 16 multiprocesseurs musclés
7 - IEEE754-2008 et puissance de calcul
8 - Conclusion
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...