
Nvidia Fermi : la révolution du GPU Computing
Publié le 01/10/2009 par Damien Triolet



Du G80 à FermiEn introduisant le G80 et les GeForce 8, Nvidia a ouvert la voie des architectures GPUs conçues dans loptique de faciliter le computing. Certes, le GPU Computing existait déjà auparavant, mais à travers le pipeline de rendu 3D. Nvidia a introduit un accès computing à son GPU, en plus du mode rendu classique et a introduit une mémoire partagée qui permet un niveau de communication entre les threads. Il aura fallu attendre les Radeon HD 4800, 2 ans après, pour voir AMD opérer une orientation similaire.
Le GPU Computing est destiné à accélérer les algorithmes massivement parallèles en profitant des nombreuses unités dexécution présentes au sein dun GPU. Ces algorithmes doivent être conçus de manière à se décomposer en une multitude de petits threads qui seront exécutés en parallèle, par groupes, sur le GPU. Nous parlons ici de milliers de threads, en contraste avec les quelques threads dun CPU. Une façon de penser et de programmer totalement différente donc qui a demandé à Nvidia de concevoir un langage adapté : C pour CUDA. Celui-ci a été écrit par Ian Buck, qui était déjà à lorigine de Brook GPU, un langage destiné à exploiter le pipeline de rendu 3D, et non directement le cur de calcul du GPU, ce qui le rendait plus rigide et moins performant.
Nous ne reviendrons pas sur le fonctionnement de larchitecture CUDA et sur C pour CUDA puisque nous avons déjà traité en long et en large ce domaine dans différents articles. Rappelons simplement quelle repose sur le principe de lexécution dun kernel (programme) sur une grille de blocs de threads, chacun des blocs disposant dune mémoire partagée spécifique à ses threads et ceux-ci étant exécutés par petits groupes de 32, les warps.
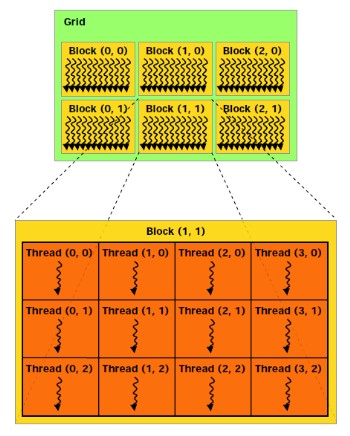
Depuis le G80, Nvidia a progressivement amélioré les capacités de ses GPUs pour tout ce qui concerne le calcul massivement parallèle. Tout dabord, les opérations atomiques ont fait leur apparition avec les dérivés du G80. Avec le GT200, Nvidia a été encore un petit peu plus loin en doublant le nombre de registres généraux, en passant le nombre maximal de threads par groupe de 768 à 1024 et en ajoutant le support, certes limité, du calcul en double précision.
Reste que tout cela ne représentait que des évolutions mineures de son architecture, quil nétait pas possible de modifier plus en profondeur à ce moment. Cest quelques temps seulement après larrivée du G80 que Nvidia a commencé à poser les bases de sa future architecture, ce qui lui a permis davoir une bonne idée des points à améliorer, au-delà des petites nouveautés intermédiaires :
- Plus de puissance de calcul en général
- Un support performant des doubles (FP64)
- Un sous-système mémoire plus efficace et protégé
- Une compatibilité C++
- Un meilleur rendement avec des petits kernels
Nvidia sest donc exécuté.
Sommaire
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...