
L'architecture Intel Nehalem
Publié le 17/09/2008 par Franck Delattre



Un nouveau bus processeurUn des défauts du Core 2 réside dans l'utilisation du bus processeur de conception ancienne. Si les plateformes mobiles et bureau s'en contentent plutôt bien, il n'en va pas de même dans le cadre d'une utilisation serveur, où le vieux FSB fait office de goulet d'étrangement dans l'interconnexion entre les sockets. Dans ce domaine, l'Opteron et son bus HyperTransport sont jusque là sans concurrence sérieuse. Nehalem abandonne le FSB pour un bus d'interconnexion plus moderne appelé QPI, pour Quick Path Interconnect. Ce nouveau bus point à point bidirectionnel partage de nombreuses caractéristiques avec le bus HyperTransport, et il ne s'en distingue pas fondamentalement dans le principe. Tout comme son concurrent, QPI offre une grande souplesse dans son implémentation, et les systèmes pourront intégrer autant de liens QPI que les besoins en bande passante le nécessitent.
Le bus QPI est annoncé avec des transferts de 4,8 à 6,4 GT/s (Giga-transferts par seconde). Avec une largeur de bus pouvant atteindre 20 bits, cela nous donne un débit maximal de 6,4 x 20 / 8 = 16 Go/s, soit 32 Go/s pour un lien bidirectionnel. Les premières implémentations de QPI sur Nehalem proposeront un lien à 25,6 Go/s, soit le double de ce que propose un FSB classique à 1600 MHz.
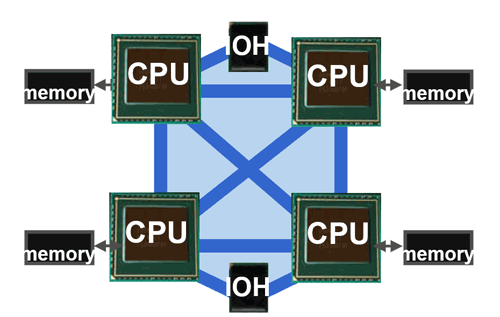
Les liens QPI, en bleu sur ce schéma, jouent le rôle d'interconnexions entre les processeurs, et également entre chaque processeur et un IOH (hub d'entrées-sorties, servant par exemple d'interface avec le bus PCI-Express). Sur cet exemple, chaque processeur est capable de gérer quatre liens QPI. Sur une machine mono-processeur, un seul lien QPI entre le processeur est l'IOH (en l'occurrence le X58) est bien entendu nécessaire.
Les améliorations apportées au noyauEn comparaison au Core 2, beaucoup des améliorations apportées par Nehalem ont été motivées par le support du SMT, et, de façon générale, par la nouvelle hiérarchie mémoire (les trois niveaux de cache et l'augmentation de bande passante mémoire disponible). Les noyaux de traitement obéissent à la même règle, et ce tout au long du pipeline dont les étapes ont été plus ou moins retouchées par rapport à ce qui existe sur Core 2.
Prédiction de branchement
A commencer par la prédiction de branchement, un des mécanismes qui, comme nous l'avons vu lors de notre étude du Core 2, a une influence des plus significatives sur les performances du pipeline de traitement. La prédiction de branchement a pour but d'éviter les coupures dans le flux de code, car celles-ci génèrent des états d'attente dans le pipeline et brisent ainsi son débit. Nehalem reprend les mécanismes déjà présents sur Core 2 : détecteur de boucles, gestion de branches directes et indirectes... La nouvelle architecture intègre en plus un second buffer d'adresses BTB (Branch Target Buffer), dont le rôle est de stocker un historique des adresses de destination effectivement prises ; si le premier BTB est destiné aux adresses « locales », le second vise les adresses plus éloignées que l'on peut trouver dans des applications plus lourdes (oui, comme les gestions de bases de données ...).
En plus de cela, Intel a ajouté un nouveau mécanisme qui repose sur le stockage des adresses de retour (et non pas sur les adresses de destination comme les BTB), et appelé RSB (Return Stack Buffer). A noter que chaque thread possède son propre RSB afin d'éviter tout conflit dans la gestion de ce buffer lorsque le SMT est activé.
Fusion
L'étape de décodage des instructions a également été revisitée. Rappelons que cette phase consiste à transformer les instructions x86 en micro-opérations élémentaires compréhensibles par le reste du pipeline de traitement. Nehalem conserve les quatre décodeurs déjà présents sur Core 2, mais améliore certains mécanismes inaugurés par son prédécesseur. La macro-fusion est une des nouveautés apportées par l'architecture Core 2 : il s'agit de détecter des couples prédéfinis d'instructions x86, tels que « comparaison + saut » (CMP + JCC), et de les transformer en une seule micro-opération. La technique permet à la fois d'augmenter la capacité de décodage et de réduire le nombre de micro-opérations générées, et ce d'autant plus que les occurrences de ces couples sont nombreuses. Nehalem ajoute de nouveaux couples d'instructions capables de « macro-fuser », et surtout permet la macro-fusion en mode 64 bits (ce qui n'est hélas pas le cas sur Core 2 qui ne bénéficie ainsi pas de tout son potentiel dès lors qu'il tourne sous un système d'exploitation 64 bits).
Sommaire
1 - Introduction
2 - Quad et SMT
3 - Contrôleur mémoire, TLB
4 - Hiérarchie des caches
5 - Bus QPI, le noyau
2 - Quad et SMT
3 - Contrôleur mémoire, TLB
4 - Hiérarchie des caches
5 - Bus QPI, le noyau
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !