
L'architecture Intel Nehalem
Publié le 17/09/2008 par Franck Delattre



La nouvelle hiérarchie de caches
Le maintien de la cohérence des données manipulées par chacun des cores dans une une architecture monolithique passe par un cache partagé entre les différents cores. Le Core 2 intégre ainsi un large cache L2 partagé entre deux cores. L'implémentation quadruple cores du Core 2 a recours au bus processeur pour maintenir cette cohérence, ce qui n'est pas optimal au niveau de la performance.
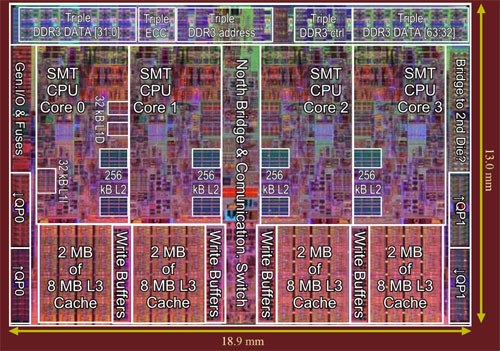
Il est donc presque naturel de trouver sur Nehalem un gros cache partagé entre les quatre cores. Seulement, les choses sont sensiblement plus compliquées avec quatre cores qu'avec deux. En effet, un cache ne peut répondre aux requêtes de quatre cores qui le sollicitent de façon intensive sans importants ralentissements ... sauf à améliorer les caractéristiques techniques de ce cache, mais au prix d'une complexification en dehors du cadre d'un processeur grand public. La solution économique consiste donc à réduire le nombre de requêtes arrivant à ce cache partagé, et pour ce faire Intel a inséré un petit cache de 256 Ko entre les L1 de chaque core et le cache partagé. Ces quatre caches de 256 Ko ne prennent pas beaucoup de place sur la puce et leur faible taille est un gage de rapidité. En contrepartie, une telle taille ne permet pas des taux de succès records, mais ce n'est pas le but recherché : si chaque L2 offre un taux de succès de seulement 50% (ce qui est pessimiste), une requête sur deux n'atteint pas le cache partagé, et tout se passe comme si les requêtes ne parvenaient que de deux cores parmi les quatre. Et avec seulement deux cores, on sait déjà que ça marche convenablement.
Les L1
Les caches de premier niveau L1 de chaque core du Nehalem gardent les mêmes caractéristiques de taille que ceux du Core 2 : 32 Ko pour les données et 32 Ko pour les instructions. L'abandon de la micro-TLB que nous avons évoqué dans le paragraphe précédent s'est hélas traduit par une légère augmentation du temps d'accès aux L1. Le L1 de données voit ainsi sa latence passer à 4 cycles (3 sur Core 2). Pour le L1 dédié aux instructions, Intel a préféré favoriser la latence au détriment de l'associativité. En effet, la gestion des voies d'un cache prend du temps, et ce d'autant plus que le nombre de voies est élevé. En réduisant l'associativité du cache L1 d'instructions de 8 à 4 voies, celui-ci est en mesure de garder une latence de 3 cycles, comme sur Core 2, et ce malgré l'absence de la micro-TLB. Pourquoi ce choix ? Car un cache d'instructions est plus sensible à la latence qu'un cache de données. La latence d'accès à ce dernier peut être (au moins partiellement) compensée par le travail du moteur OOO qui réordonne les instructions afin de masquer les latences (et celui du Nehalem a été sensiblement amélioré), alors que chaque accès au cache d'instructions subit directement les effets d'une latence élevée, en particulier les accès effectués par les mécanismes de prédiction de branchement. Le L1 d'instructions a ainsi moins à perdre en diminuant son associativité qu'en augmentant sa latence. Affaire de compromis !
Pour finir, les L1 du Nehalem sont capables de prendre en charge d'avantage d'échecs de cache en parallèle que le Core 2. Cette augmentation est permise par le gain de bande passante offert par le contrôleur mémoire intégré : un échec de cache signifie un accès mémoire, et le temps moyen entre deux requêtes mémoire diminue. Cette augmentation se montre particulièrement intéressante pour le SMT, car deux threads génèrent davantage d'échecs de caches qu'un seul.
Caches inclusifs
La hiérarchie de caches du Nehalem fait immanquablement penser à celle du Phenom. Mais la ressemblance s'arrête au nombre de niveaux, car les caches ne fonctionnent pas de la même façon sur les deux architectures. A commencer par le fait que le cache L3 partagé du Nehalem a une relation inclusive avec tous les autres niveaux de cache, ce qui signifie qu'il contient une copie du contenu des caches L1 et L2. Cette caractéristique le distingue du choix effectué par AMD sur le Phenom dont le L3 a une relation pseudo-exclusive avec les autres niveaux de cache (une donnée ne peut pas se trouver dans deux niveaux de caches en même temps, bien que le préfixe « pseudo » signifie qu'il existe quelques exceptions à cette règle).
Une relation de cache de type inclusif se caractérise de façon générale par des performances supérieures, mais au détriment de la taille totale de cache utile (du fait des redondances de certaines données dans deux niveaux successifs). Sur une architecture multi-cores, la relation inclusive amplifie ce défaut : sur les 8 Mo du L3, plus d'un Mo est occupé par les copies des caches L1 et L2. Mais elle présente également l'avantage de moins perturber les caches privés L1 et L2. Pourquoi ? car en cas d'échec du cache L3 (L3 miss), on est certain que cette donnée n'est pas dans les caches privés de chacun des cores (sinon elle se trouverait dans le L3 du fait de la relation inclusive), ce qui permet d'éviter la vérification et de déclencher immédiatement une requête de lecture en mémoire. Les choses se compliquent en cas de succès du cache L3 (L3 hit), car alors il faut vérifier si la donnée est déjà présente dans un des caches privés, ce qui nécessite de vérifier tous les caches de chaque core. Cette étape nécessaire dans la cohérence des caches est appelée « cache snooping », et peut se montrer une source importante de ralentissement. Pour pallier au problème, le Nehalem possède, pour chaque ligne du cache L3, un drapeau indiquant dans le cache privé de quel(s) core(s) la donnée est présente. Si le gain de temps est appréciable, le stockage des drapeaux alourdit un peu la structure du cache L3.
Les premiers tests de latence ont révélé une moyenne de 40 cycles processeur pour le cache L3 des modèles actuels de Nehalem (4 cycles pour le L1, et environ 10 cycles pour le L2). Une telle valeur s'explique en partie par le fait que le cache L3 fonctionne dans un domaine de fréquence (et également de tension) différent de celui du reste du processeur, et ce au même titre que toute la partie « uncore » du Nehalem. Ainsi, sur la version à 2,93 GHz du processeur, le L3 fonctionne à 2,66 GHz. Cela fausse un peu la mesure de latence, exprimée en cycles processeur, donc à 2,93 GHz. Cette séparation des domaines de fréquence et de tension apporte plus de souplesse dans le design du processeur, et évite notamment de devoir aligner la fréquence globale du processeur sur les éléments les plus lents. En outre, cela permet de mieux contrôler la dissipation thermique globale du socket, ce qui, nous le verrons plus tard, revêt sur le Nehalem une importance toute particulière.
En terme de souplesse, la taille du L3 du Nehalem est facilement adaptable en fonction du cahier des charges de chaque version du processeur, et également des évolutions de fabrication. Le passage en gravure 32 nm s'accompagnera probablement d'un cache L3 de 12 Mo, comme cela a été le cas sur Core 2.
Sommaire
1 - Introduction
2 - Quad et SMT
3 - Contrôleur mémoire, TLB
4 - Hiérarchie des caches
5 - Bus QPI, le noyau
2 - Quad et SMT
3 - Contrôleur mémoire, TLB
4 - Hiérarchie des caches
5 - Bus QPI, le noyau
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !