
Nvidia CUDA : plus en pratique
Publié le 09/08/2007 par Damien Triolet



Et AMD ?Si vous avez un petit peu suivi l'actualité autour du stream computing, vous devez savoir qu'AMD a été le premier à en parler. Tout d'abord en annonçant un accès bas niveau (langage machine) à ses GPUs lors du lancement des Radeon X1800 en octobre 2005. Cet accès, appelé DPVM pour Data Parallel Virtual Machine et renommé en CTM pour Close To Metal, n'a été détaillé que près d'un an après, soit en août 2006.
Quelque mois après, lors de la concrétisation du rachat par AMD, les équipes d'ATI ont présenté quelques applications plus pratiques, une annonce qui tombait bien pour alimenter les discussions sur l'intérêt de ce rachat. Ces présentations ont été complétées par le lancement d'une version accélérée via Direct3D par les X1900 de Folding@home. Mais la CTM n'était toujours pas disponible et bien qu'ATI nous ait alors indiqué qu'une version CTM de Folding@home arriverait bientôt, nous n'en avons encore rien vu.
A la mi-novembre 2006, AMD a lancé le premier produit spécifique à ce marché avec le Stream Processor qui est une Radeon X1900 dépourvue de sorties vidéos. Reste que contrairement à ce qui nous a toujours été dit, à savoir que CTM concernait toutes les cartes graphiques grand public, le driver CTM n'est livré qu'aux seuls utilisateurs de ces cartes qui doivent être en contact direct avec les développeurs d'AMD puisqu'il est introuvable sur le site du fabricant. De quoi finir par freiner notre enthousiasme et par agacer puisqu'en dehors des effets d'annonce systématiques au lancement des cartes grand public (ou pour justifier le rachat d'AMD) nous n'avons pas vu grand-chose de concret
Du neuf avec les GPUs R6xx ?Avec le lancement des Radeon HD 2000, AMD est revenu sur le sujet en présentant toute une série d'évolutions. L'accès bas niveau CTM se verrait ainsi compléter par l'AMD Runtime qui est en quelque sorte l'équivalent du runtime de CUDA et est donc un accès plus haut niveau. La différence est que cet AMD Runtime pourrait exploiter aussi bien les CPU multicores que le ou les GPUs. Ensuite, la librairie de fonctions mathématiques d'AMD, ACML , optimisée pour ses CPUs, intègrerait des équivalents GPUs. Et enfin AMD proposerait des extensions aux langages C et C++ pour piloter le tout comme Nvidia le fait avec CUDA.
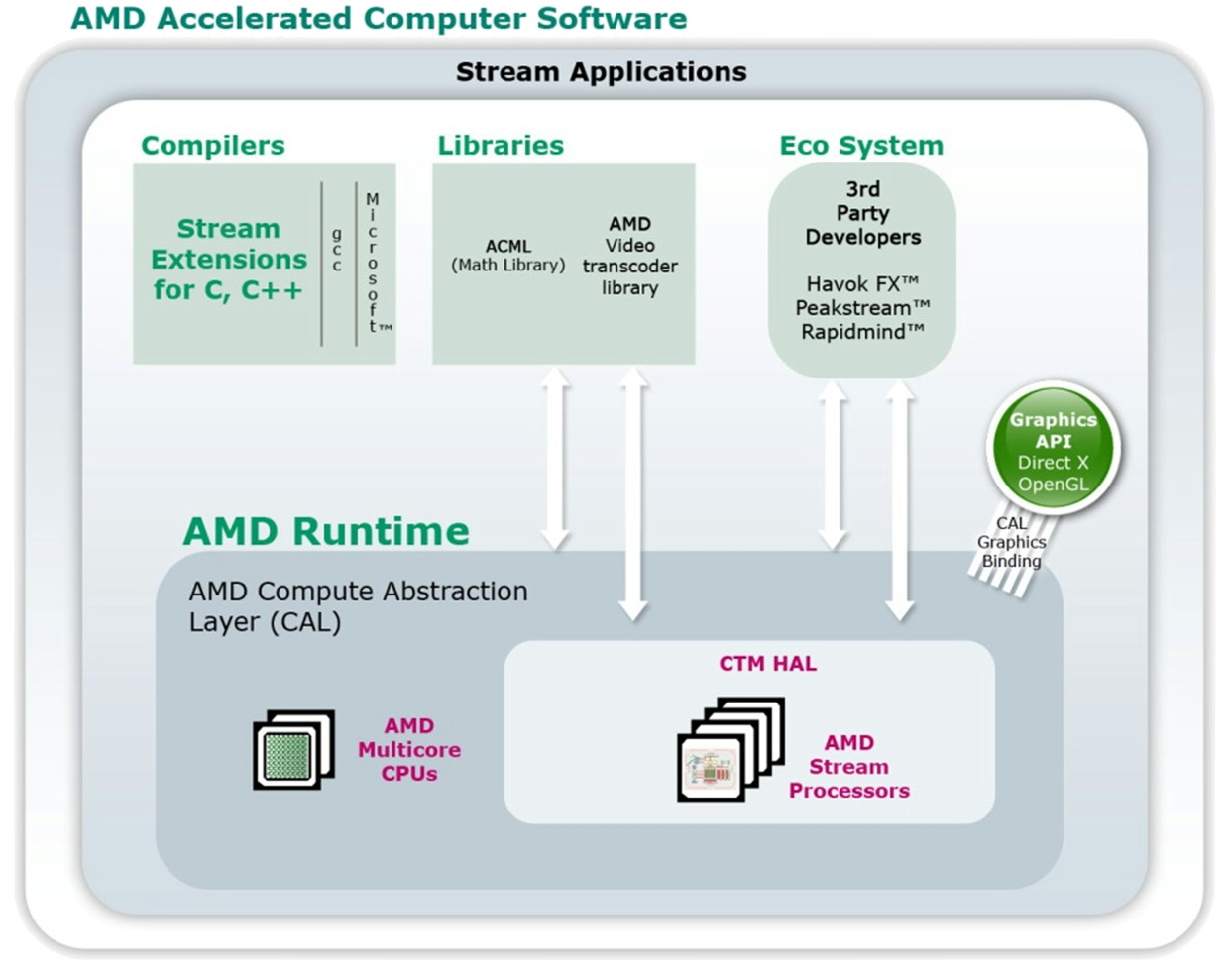
AMD semble donc emboîter le pas de Nvidia en passant à un mode d'utilisation de plus haut niveau. Pourtant AMD n'est pas avare de critiques envers CUDA présenté comme une solution "bonne à rien", c'est-à-dire trop complexe pour la plupart des développeurs et trop éloignée des spécificités exactes du GPU que pour pouvoir développer des librairies efficaces. Des critiques envers CUDA qui ne sont pas totalement fausses et on peut d'ailleurs supposer que cela a incité Nvidia à documenter le PTX.
Avec CUDA Nvidia a fait le choix de proposer rapidement quelque chose d'utilisable quitte à ne proposer que plus tard des possibilités d'optimisation supplémentaires. Alors qu'AMD a été d'abord vers un langage bas niveau très complexe avant de proposer plus. Ou tout du moins avant de proposer des documents marketing qui disent que le constructeur va proposer plus que ce que nous n'avons toujours pas vu. Après plus de 2 ans sans rien voir venir, nous attendrons donc de voir du concret avant d'aller plus loin, c'est d'ailleurs pour cette raison que nous avons utilisé le conditionnel pour présenter les nouveautés et ne l'avons fait que très brièvement.
Nous terminerons ce chapitre consacré à AMD par parler de l'architecture Radeon HD 2000 qui dispose de quelques avancées intéressantes dans le cadre d'une utilisation comme unité de calcul. Premièrement le Thread Generator est capable de générer des threads optimisés pour un traitement rapide (faible latence) ou optimisés pour maximiser le débit du GPU, ce qui permet en théorie de rendre plus efficaces certaines utilisations bien qu'AMD ne donne pas réellement de détails à ce niveau.
Ensuite l'architecture mémoire des Radeon HD 2000 est beaucoup plus avancée que celle des GeForce 8. Nous citerons d'une part un accès généraliste caché à la mémoire vidéo tant en lecture qu'en écriture alors que ces accès ne le sont pas avec les autres GPUs. Et d'autre part un moteur indépendant pour gérer les transferts PCI Express parallèlement au reste du GPU. Sur un GeForce 8, le GPU est bloqué durant ces transferts.
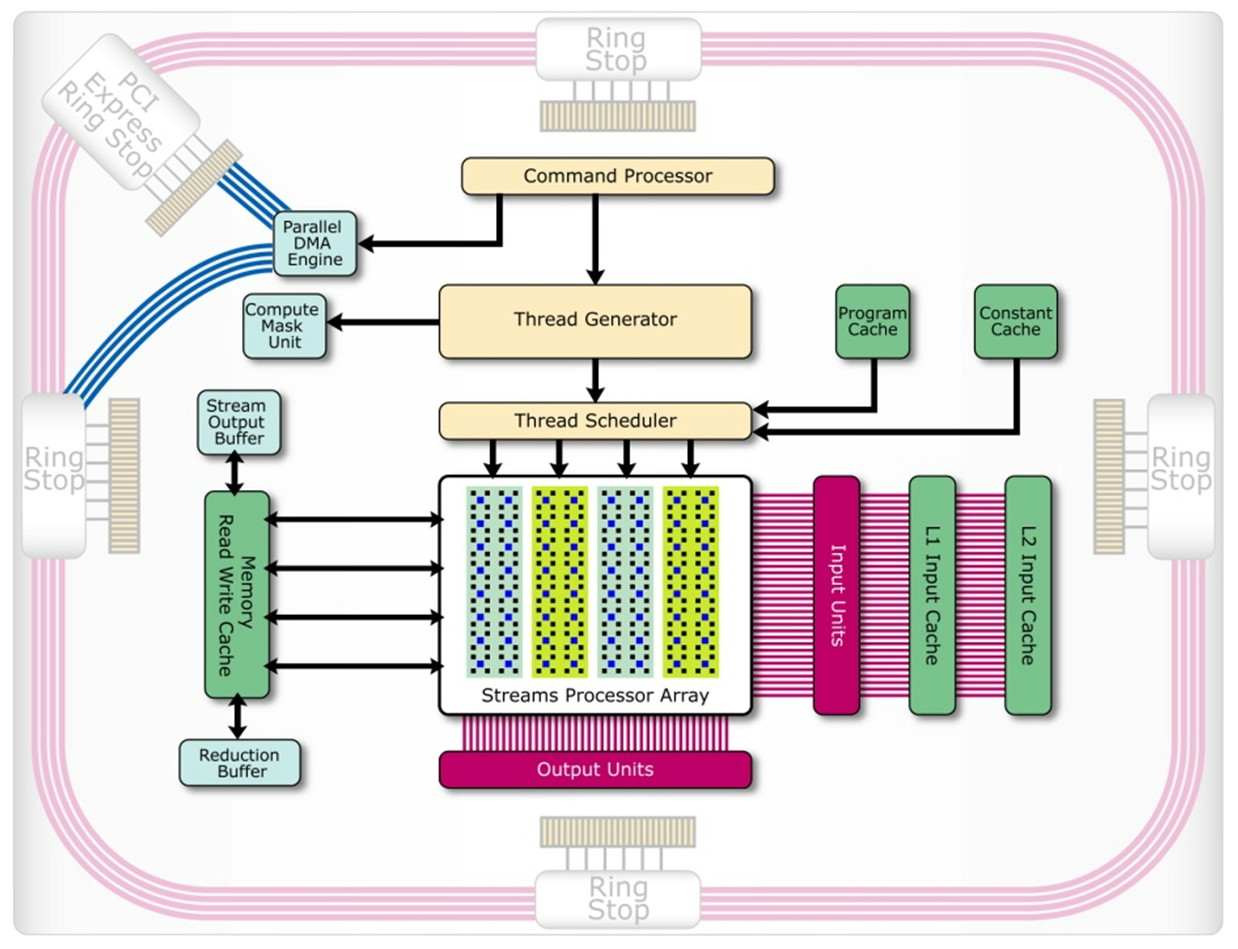
Les puces de génération R600 semblent donc bien armées pour le Sream Computing et pourraient permettre à AMD de prendre l'avantage sur Nvidia. Mais comme le dit si bien AMD, le matériel ce n'est que la moitié de l'histoire et l'autre moitié, on n'en a pas encore vu grand-chose
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...