
Nvidia CUDA : plus en pratique
Publié le 09/08/2007 par Damien Triolet



CUDA évolueIl est maintenant évident que CUDA n'a pas simplement été une annonce de Nvidia de manière à remplir les documents marketing et/ou à voir si le marché y prête un intérêt, mais bien d'une stratégie à long terme basée sur le sentiment qu'un marché des accélérateurs est en train de se former et devrait grandir rapidement dans les années à venir.
L'équipe qui s'occupe de CUDA travaille donc d'arrache pied pour faire évoluer le langage, améliorer le compilateur, rendre l'utilisation plus flexible etc. Depuis la version 0.8 beta du mois de février, les versions 0.9beta et finalement 1.0 ont permis à CUDA de rendre viable l'utilisation des GPUs comme coprocesseurs. Plus de flexibilité et une meilleure robustesse étaient nécessaires bien que la version 0.8 était déjà très prometteuse. Ces évolutions régulières permettent également d'augmenter le capital confiance dont commence à bénéficier CUDA.
2 évolutions principales sont à retenir. La première est le fonctionnement asynchrone de CUDA. Comme nous l'expliquions dans notre précédent article, la version 0.8 souffrait d'une grosse limitation puisque une fois que le CPU avait envoyé le travail au GPU, il était bloqué le temps que celui-ci envoie les résultats. Le CPU et le GPU ne pouvaient donc pas travailler en même temps. Un gros frein aux performances. Un autre problème se posait dans le cas d'un système de calcul équipé de plusieurs GPUs. Il fallait un core de CPU par GPU pour pouvoir profiter de ceux-ci. Pas très efficace ni pratique.
Nvidia le savait bien entendu et ce fonctionnement synchrone des premières versions de CUDA avait probablement été utilisé pour faciliter la mise en place rapide d'une version fonctionnelle de CUDA sans devoir se soucier des points délicats. Avec CUDA 0.9 et donc 1.0, ce problème disparaît et le CPU est libéré une fois qu'il a envoyé le programme à exécuter au GPU (sauf quand l'accès aux textures est utilisé). Dans le cas de l'exploitation de nombreux GPUs, il reste cependant nécessaire de créer un thread CPU par GPU puisque CUDA n'autorise pas le pilotage de 2 GPUs à partir d'un même thread. Ce n'est cependant pas un gros problème. Notez qu'une fonction est présente de manière à forcer un fonctionnement synchrone si cela s'avérait nécessaire.
La seconde nouveauté principale sur le plan fonctionnel est l'apparition de fonctions atomiques. Une fonction atomique est une fonction qui va lire une donnée en mémoire, s'en servir dans une opération et écrire le résultat, sans qu'un autre accès à cet espace mémoire ne soit autorisé tant que l'opération n'est pas bouclée. Cela permet d'éviter ou tout du moins de réduire certains problèmes courants tels un thread qui essayerait de lire une valeur dont on ne sait pas si elle a déjà été modifiée ou pas.
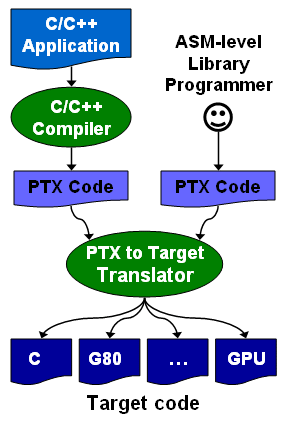
Enfin, avec CUDA 1.0, Nvidia distribue une documentation du PTX (Parallel Thread eXecution) qui est un langage assembleur intermédiaire entre le code de haut niveau et le code envoyé au GPU. Le PTX était déjà utilisé et les développeurs pouvaient y accéder, mais il n'était pas documenté. Probablement parce que le comportement des différents niveaux de compilations n'était pas encore défini clairement. Le PTX peut être utilisé pour optimiser certains algorithmes ou librairies ou tout simplement pour débuguer le code.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...