
ATI Radeon HD 2900 XT
Publié le 15/05/2007 par Damien Triolet



Performances branchementsLune des principales nouveautés qui a été introduite avec les Pixel Shaders 3.0 est le branchement dynamique dans les pixel shaders. Cela permet de rendre lécriture de certains shaders plus naturelle et daugmenter lefficacité dautres shaders en évitant de calculer une partie de ceux-ci sur les pixels qui nen ont pas besoin. Par exemple pourquoi appliquer le filtrage très coûteux de ladoucissement de bordure dune ombre si le pixel est au milieu de lombre ? Un branchement dynamique permet de détecter si le pixel en a besoin ou pas.
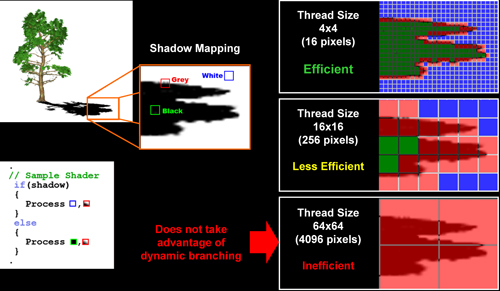
Mais tout nest pas si rose puisque ceux-ci ne sont efficaces que dans des cas bien précis. Les branchements ont une réputation d'être difficile à gérer, c'est particulièrement le cas dans les CPU qui doivent prédire le résultat du branchement à l'avance pour masquer la latence du calcul de celui-ci. Dans un GPU, les pixels sont traités par groupes de dizaines, de centaines voire de milliers de pixels, ce qui permet de masquer automatiquement cette latence. Le problème des CPUs n'existe donc pas réellement. Par contre un autre problème se pose. Lors dun branchement, tous les pixels doivent prendre la même branche sans quoi les 2 branches doivent être calculées pour tous les pixels, avec des masques pour nécrire que le résultat de la branche requise pour chaque pixel.
Nous avons développé un petit test qui nous permet de modifier la granularité du branchement, c'est-à-dire le nombre moyen de pixels consécutifs qui vont prendre une même branche. Nous spécifions la branche à prendre par colonne de pixels, une colonne sur 2 doit afficher un shader complexe et l'autre peut passer cette partie du rendu. Des triangles de taille moyenne en mouvement sont affichés à l'écran et traversent ces zones qui utilisent différentes branches, ce qui implique que tant les triangles et leur position que la taille de la colonne influent sur l'efficacité du branchement ce qui est proche d'une situation réelle.
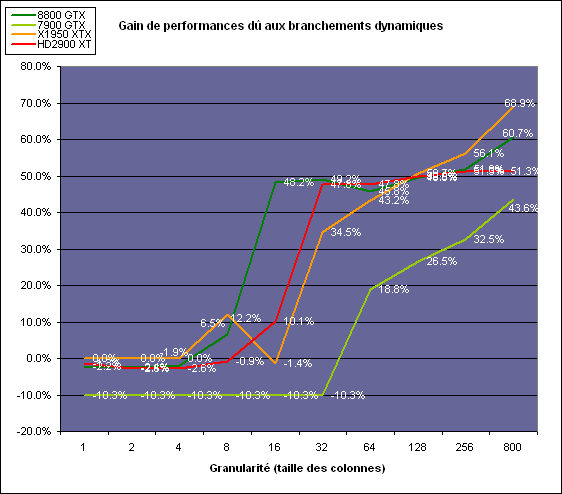
Avec des colonnes étroites, les GPUs ne peuvent pas profiter du branchement pour éviter la partie complexe sur la moitié des pixels, mais par contre doivent traiter les instructions de branchement, ce qui fait baisser les performances au lieu de les augmenter. Tout du moins sur les GeForce 7. Les Radeon et les GeForce 8 disposent d'une unité dédiée aux branchements qui travaille en parallèle des pipelines de pixel shading et de texturing ce qui masque le coût des instructions de branchement. La Radeon X1950 semble cependant la seule à masquer complètement la latence des branchements.
Le GPU le plus efficace à ce jour pour traiter ces opérations et le Radeon X1800, le Radeon X1900 étant un peu moins bon et le Radeon HD 2900 encore un peu moins bon. La taille des threads de pixels sur le GeForce 8800 est de 32 pixels contre 48 pour le Radeon X1950 et 64 pour le Radeon HD 2900, ce qui permet à la puce de Nvidia de prendre les devants. Nous précisons threads de pixels puisque dans le cas de threads de vertices, la granularité est de 16 vertices chez Nvidia. Notez que les Radeon X19x0 produisent des résultats moins prédictibles que les autres GPUs sur ce test (le résultat étrange avec une colonne de 16 pixels en témoigne). Nous supposons que cela est dû à une manière complexe de l'architecture de distribuer les pixels aux shader cores qui entraînerait une baisse d'efficacité dans certaines conditions. Globalement le Radeon HD 2900 se comporte donc comme le GeForce 8800, son efficacité étant cependant reculée d'un cran à cause de la taille des groupes de pixels traités.
Nous avons ensuite exécuté un second test lié aux branchements dynamiques. Cette fois nous avons rendu une fractale d'une manière classique et ensuite à base de branchements. Cet algorithme utilise un nombre élevé d'itérations identiques qui dans le shader classique se retrouvent les une à la suite des autres. Dans le shader à base de branchements, nous avons utilisé une boucle autour de 2 itérations avec un test qui vérifie si le calcul d'itérations supplémentaires est utile ou pas. Si il n'est pas utile nous sortons de la boucle en laissant tomber les itérations qui ne sont pas nécessaires.

Avant de comparer les performances avec et sans branchements, il est intéressant de s'attarder aux résultats brutes. Ce shader est en effet constitué principalement d'opérations vec2 et profite donc d'une architecture plus flexible au niveau de ses unités de calcul. Le fonctionnement scalaire des GeForce 8 permet d'atteindre ici de très hautes performances. Le Radeon HD affiche ici des performances nettement supérieures à celles du Radeon X1950 mais cela n'est pas dû à son "architecture scalaire", en effet le gain correspond uniquement à l'augmentation de la fréquence et des unités de calcul vectorielles (de 48 à 64).
Concernant les branchements, le Radeon HD 2900 est ici peu efficace et semble moins bien masquer le coût des nombreuses opérations de branchement que son prédécesseur et que le GeForce 8800.
Sommaire
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...