
Les contenus liés aux tags Nvidia et GPGPU
Afficher sous forme de : Titre | FluxTesla 20 et Fermi : plus de détails
Nvidia dévoile des Tesla 20 avec Fermi
Dossier: Nvidia Fermi : la révolution du GPU Computing
Computex : serveur Tesla chez Supermicro
Computex : Nvidia mise sur GPU Computing
Nvidia, PGI et Cray dévoilent OpenACC
Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
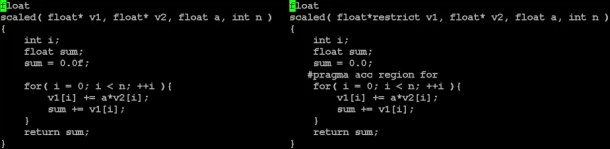
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .
Focus : Nvidia annonce CUDA 4.0
Pour fêter les 4 ans d’anniversaire de CUDA, Nvidia vient de lever le voile sur la version 4.0 du kit de développement qui permet de profiter de la puissance de calcul des GPUs dans de nombreux domaines. C’est en effet début février 2007 que Nvidia nous fournissait la première version bêta de son kit de développement, avant d’en sortir une version 1.0 au mois de juin de la même année.
Si, à l’origine, CUDA représentait le nom de l’architecture introduite par Nvidia pour faciliter...
[+] Lire la suite

NVIDIA 1er au Top 500



Après avoir atteint la 2nd place lors du dernier classement des supercalculateurs TOP 500 lors de la dernière mise à jour de Juin, NVIDIA et la Chine devraient prendre la première place du prochain classement grâce à un score de 2,507 Petaflops obtenu par Tianhe-1A.

Basé sur 7 168 GPU Tesla M2050 et 14 336 CPU, ce supercalculateur bat largement le précédent record de 1,759 Petaflops détenu par le Cray XT5-HE. Il sagit en fait dune mise à jour du Tianhe-1 qui était basé sur 5120 GPU de Radeon 4870 X2 et qui était 7è au précédent classement avec 563,1 Teraflops.
NVIDIA met en avant la consommation lefficacité énergétique du Tianhe-1A, qui ne consomme "que" 4,04 Megawatts, là ou un système 100% CPU consommerait 3 fois plus pour arriver à un niveau de performance similaire.
Focus : Le futur de Nvidia : Kepler et Maxwell
Tout juste une semaine après Intel et l’IDF, c’est à Nvidia d’organiser son évènement avec la GPU Technology Conference de San José. Lors de cette conférence, centrée sur le GPU computing et le graphisme professionnel, Nvidia a dévoilé une roadmap, fait très inhabituel dans le monde du GPU mais qui permet de donner un horizon technologique à la société.
Après l’architecture Tesla (GT200, GeForce 200, ~Quadro x800, Tesla 10) et l’architecture Fermi (GF100,...
[+] Lire la suite

Computex: serveurs avec GPUs chez Supermicro
Supermicro exposait sur le salon plusieurs systèmes optimisés pour le GPU computing tant du côté dAMD que de Nvidia. Le spécialiste du serveur explique proposer les deux solutions à ses clients mais ne pas les mettre au point directement et simplement certifier la compatibilité de ces serveurs avec certains modèles proposés par AMD et Nvidia. Cest le cas des Tesla C2050 et C2070 basées sur le GF100. Du côté dAMD ce sont des FirePro V8800 qui étaient utilisées dans les systèmes puisque les cartes FireStream équivalentes et optimisées pour le format des serveurs manquent toujours à lappel.

Interrogé sur le succès de ces solutions, Supermicro nous a indiqué quil était toujours très réduit étant donné que le GPU computing reste encore globalement à létat de recherche et développement. Les logiciels compatibles, optimisés et à létat de production sont encore rares ce qui limite grossièrement le marché aux développeurs et aux universités. Supermicro estime cependant que ce type de serveurs pourrait connaître un succès de plus en plus grand et compte donc continuer à suivre le GPU computing de près. Notre interlocuteur nous a ensuite précisé avec un grand sourire que les marges énormes sur ce type de serveur et le coût relativement réduit en développement (il nest pas nécessaire de concevoir les cartes accélératrices et la densité nest pas réellement travaillée) font que peu importe si ce marché explose réellement un jour, le simple fait dalimenter son développement est déjà très rentable.