
Actualités informatiques du 25-11-2013
- Nvidia annonce la Tesla K40 et CUDA 6
- Intel fait un pas de plus vers le modèle foundry
- Intel donne quelques infos sur le 14nm
- WD Black² : SSD et HDD en un disque !
| Novembre 2013 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | |
Nvidia annonce la Tesla K40 et CUDA 6



La semaine passée, à l'occasion du SC13 (Supercomputing 2013), Nvidia a annoncé deux nouveautés liées au calcul haute performance : l'accélérateur Tesla K40 et la version 6 de CUDA.
Pour rappel, c'est la gamme Tesla qui a été la première à profiter du plus gros GPU de la famille Kepler, le GK110. Contrairement aux Quadro K6000 et GeForce GTX 780 Ti plus récentes, cette gamme Tesla n'accueillait cependant toujours pas de version complète du GK110, c'est-à-dire avec l'ensemble de ses unités d'exécution actives. Une configuration facilitée par l'arrivée de la révision B1 du GPU.
La Tesla K40 profite ainsi de 15 SMX, de 2880 unités de calcul FMA 32-bit et de 960 unités FMA 64-bit pour afficher une puissance de calcul en hausse de près de 10% par rapport à la Tesla K20X. Par ailleurs, comme pour le Quadro K6000, Nvidia profite de la disponibilité effective de la GDDR5 4 Gbits pour faire passer la mémoire dédiée de son accélérateur de 6 à 12 Go. Sa fréquence est par ailleurs revue à la hausse ce qui profite à la bande passante mémoire en hausse de 15%.

Si la fréquence GPU ne progresse que très peu pour la Tesla K40, c'est uniquement pour garantir que l'enveloppe thermique ne soit pas atteinte dans les tâches de type calcul, sachant que, contrairement aux GeForce, Nvidia ne propose pas de turbo pour ces cartes afin d'éviter que leurs performances soient variables. Par contre, pour la Tesla K40, Nvidia propose 2 modes avec des fréquences GPU différentes : optionnellement, il sera ainsi possible de passer le GPU de 745 à 810 ou 875 MHz. Il ne s'agit pas d'un overclocking dans le sens où ces fréquences sont validées par Nvidia, ni d'un turbo automatique, même si Nvidia place cette possibilité sous l'appellation GPU Boost, marque du turbo des GeForce... Si la personne qui exploite ces Tesla K40 constate qu'elles restent loin de leur TDP dans une certaine situation, elle aura la possibilité de passer à un de ces modes de fréquence supérieure. De quoi profiter 9% voire 17% de puissance supplémentaire.
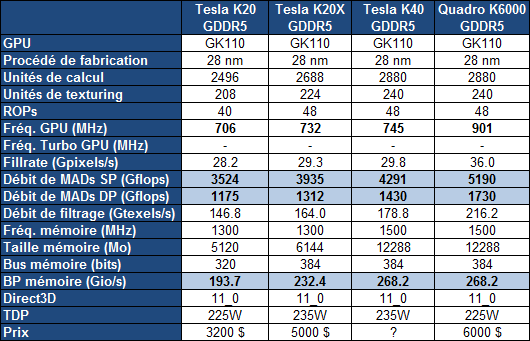
A noter que la Tesla K40 sera proposée autant avec un refroidissement actif, comme la K20, qu'avec un refroidissement passif en vue d'intégration dans un serveur, comme la K20X. Enfin, le PCI Express 3.0 est activé sur la K40 contrairement aux K20/X.
Nvidia ne communique pas au niveau de la tarification, mais elle devrait rester inférieure à celle de la Quadro K6000, probablement passer à 5000$ alors que les K20/X devraient voir leur tarif baisser. Il faut cependant garder en tête que sur ce marché de niche, les prix sont fortement variables, les grossistes n'hésitant pas à se réserver des marges conséquentes. Ainsi pour des tarifs annoncés par Nvidia de 3200$ et de 5000$ pour les K20 et K20X, en pratique, il fallait en général compter plutôt 4000$ et 7500$, la même chose en euros.
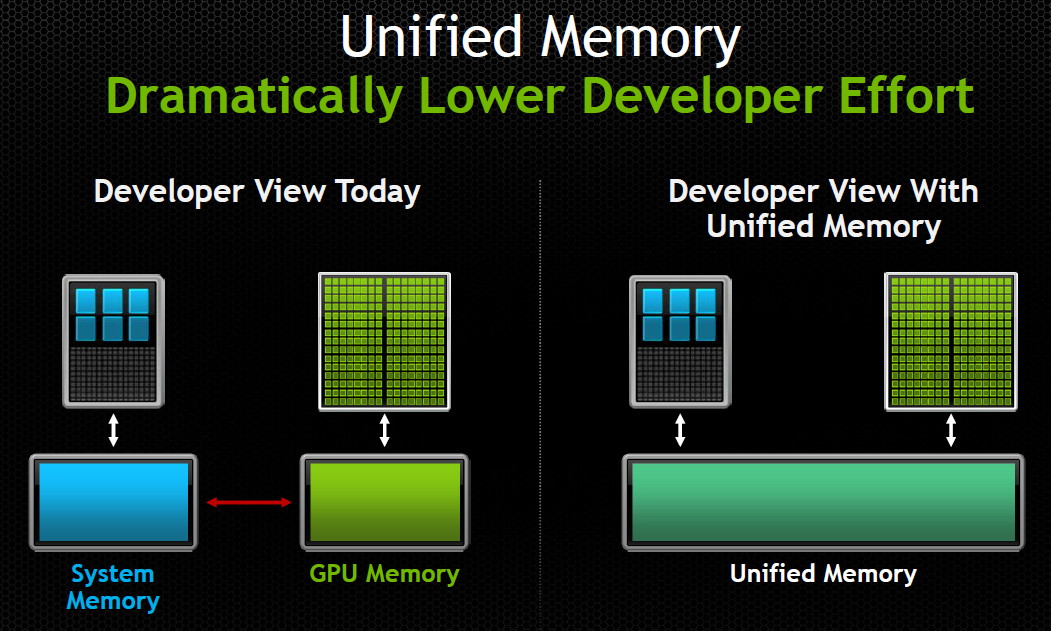
Parallèlement à l'arrivée de cette nouvelle Tesla, Nvidia a annoncé CUDA 6 qui apporte une nouveauté majeure et très attendue : la prise en charge d'une mémoire unifiée. Une fonctionnalité qui donne l'impression d'être annoncée et réannoncée régulièrement, AMD et Nvidia ayant régulièrement joué sur les mots à ce niveau. Pour rappel, depuis quelques temps, CUDA supporte un adressage de mémoire virtuelle unifié, qui facilite quelque peu le développement mais n'était qu'un premier pas. La mémoire unifiée, représente cette fois une abstraction totale de la gestion de la mémoire : il n'est plus nécessaire que le développeur gère les transferts de données de la mémoire centrale vers la mémoire de l'accélérateur.
Une gestion manuelle de la mémoire restera possible, étant donné qu'aussi bénéfique soit cette simplification, elle peut avoir un coût sur le plan des performances et de l'efficacité puisqu'il reviendra aux pilotes et/ou aux compilateurs d'essayer de placer automatiquement les données au bon endroit.

Confiant dans l'avenir, Nvidia termine par annoncer que l'ouverture par IBM, cet été, de sa plateforme serveur POWERn, va permettre d'y intégrer des accélérateurs Tesla dès 2014. Des accélérateurs qui seront ainsi exploités non plus uniquement sur x86 mais également sur architectures POWER et ARMv8.
Intel fait un pas de plus vers le modèle foundry
Au-delà des informations sur le 14nm, l'information principale à retenir de la journée dédiée aux investisseurs du constructeur était sans aucun doute le pas de plus effectué en direction d'une activité de fondeur pour des clients tiers. Nous en avons déjà largement parlé, Intel dispose d'une petite activité de fondeur pour des clients tiers, qui s'est cantonnée dans un premier temps à des produits type FPGA.
Une activité qui s'est étoffée il y a moins d'un mois de cela avec l'annonce de la fabrication en 14nm de SoC/FPGA pour Altera, qui léger comble, incluent en prime pour la partie SoC un Cortex-A53 ARMv8. Au-delà du fait qu'Intel produise un SoC ARM, en pratique les produits d'Altera ne rentrent pas du tout en compétition avec les produits d'Intel. Cela risque cependant de changer, Brian Krzanich lors de sa présentation a montré le slide suivant :

Intel pousse donc de plus en plus son activité de fondeur tiers, passant de « quelques client stratégiques et choisis » comme le décrivait Mark Bohr en 2012 à « n'importe quelle société capable d'utiliser notre process ».
Questionné durant les sessions de Q&A sur le sujet, William Holt a confirmé qu'Intel pourrait produire pour des sociétés tierces des puces qui rentrent directement en compétition avec des produits proposés par Intel. A la question de savoir si Intel pourrait produire un SoC ARM qui entrerait en compétition avec les SoC x86 du constructeur, il aura ajouté « we'd rather get paid twice than once », faisant allusion au fait qu'il est plus profitable pour Intel de vendre l'IP (x86) et la puce fabriquée que simplement vendre la fabrication de la puce.
Dans un second Q&A, Brian Krzanich, CEO d'Intel aura confirmé une fois de plus l'ouverture de l'activité Intel Custom Foundry à tous, répétant que si le constructeur avait par le passé été assez timide dans ses initiatives, l'annonce faite ce jour correspondait bien à un changement de stratégie sur le long terme. Brian Krzanich aura confirmé lui aussi que même si des produits pouvaient rentrer en compétition avec ses propres puces, il était dans l'intérêt des investisseurs qu'Intel ne ferme plus la porte à d'éventuels clients.
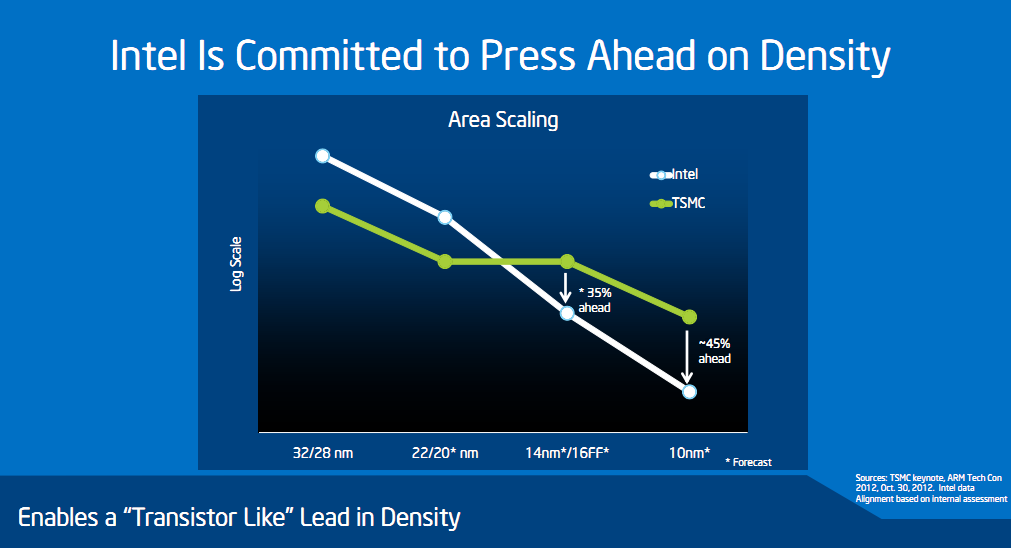
Une offensive nouvelle qui s'est traduite par quelques petites piques envoyées vers TSMC et la Common Platform. D'abord envers le process 16nm de TSMC dont nous vous avions déjà parlé. TSMC compte en effet lancer la production en volume du 20nm en février 2014, puis du 16nm en février 2015. Pour arriver à cette rapidité, TSMC a choisi de conserver des similarités entre les deux process. Si le 16nm de TSMC apportera bien des gains de performances et de consommation, il apportera des gains réduits d'amélioration de densité (TSMC indique que le 20nm offre une densité 1.9x supérieure à son process 28nm, et que le 16nm offre une densité de 2.0x par rapport au 28nm).
Ce premier graphique est donc partiellement vrai (la courbe verte devrait un peu baisser au milieu). L'avantage que l'on peut en tirer est un autre problème. La question de la densité peut être un problème dans le cas où l'on tente de créer d'énormes puces, le reste du temps il s'agit avant tout d'une question économique. Augmenter la densité permet de produire plus de puces sur un wafer et donc d'en réduire le cout, mais le passage d'un process à un autre se traduit en général également par une augmentation du coût du wafer. Sans plus de détails sur le process de TSMC (qui en dévoilera un peu plus en décembre lors de l'IEDM), il est difficile de quantifier l'intérêt économique des deux solutions.
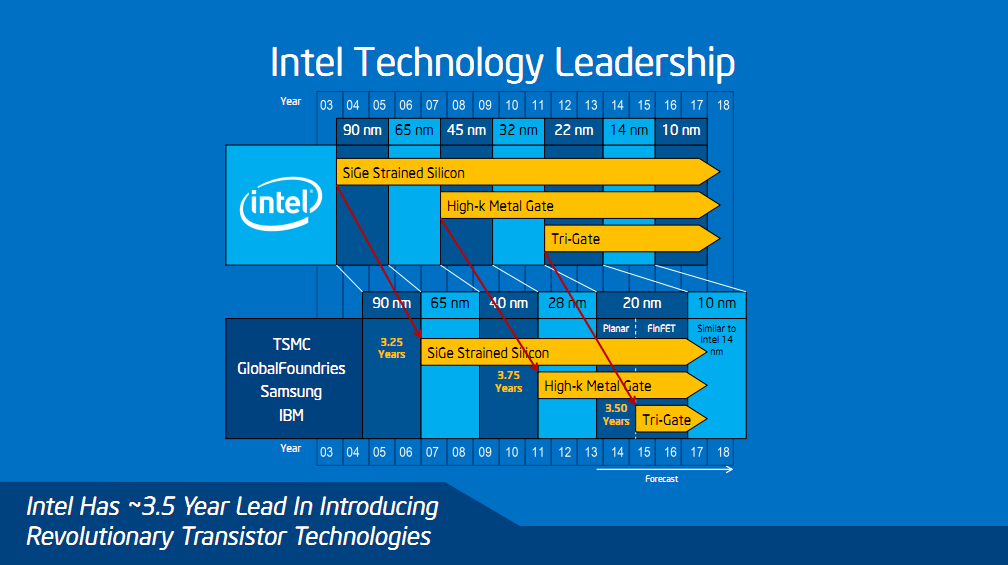
Intel profite de cette différence pour qualifier le 16nm de TSMC et de la Common Platform de 20nm FinFET. Un raccourci pas complètement honnête puisque, rappellons-le, le gate pitch (l'écart entre deux transistors) n'avait pas été réduit de manière aussi forte qu'a l'habitude entre le 32 et le 22nm chez Intel, comme nous l'avions mentionné ici. Dans tous les cas, la définition d'un process ne se fait pas par sa densité mais par ce que l'on appelle les feature size, la résolution à laquelle on peut dessiner (ce qu'on pourrait comparer en simplifiant par la taille d'une goutte d'encre sur une imprimante).
Intel donne quelques infos sur le 14nm
Intel tenait en fin de semaine dernière une journée dédiée aux analystes financiers, l'occasion pour nous de glaner quelques détails, plus particulièrement sur le 14nm qui était de manière fort surprenante massivement absent de l'Intel Developer Forum 2013.
En ce qui concerne le 14nm à proprement parlé, William Holt est revenu sur l'annonce du retard de Broadwell dont nous vous avions parlé précédemment. Pour rappel, Intel a indiqué qu'il décalerait le début de la production de ses puces 14nm d'un trimestre pour cause de yields plus faibles qu'attendus.
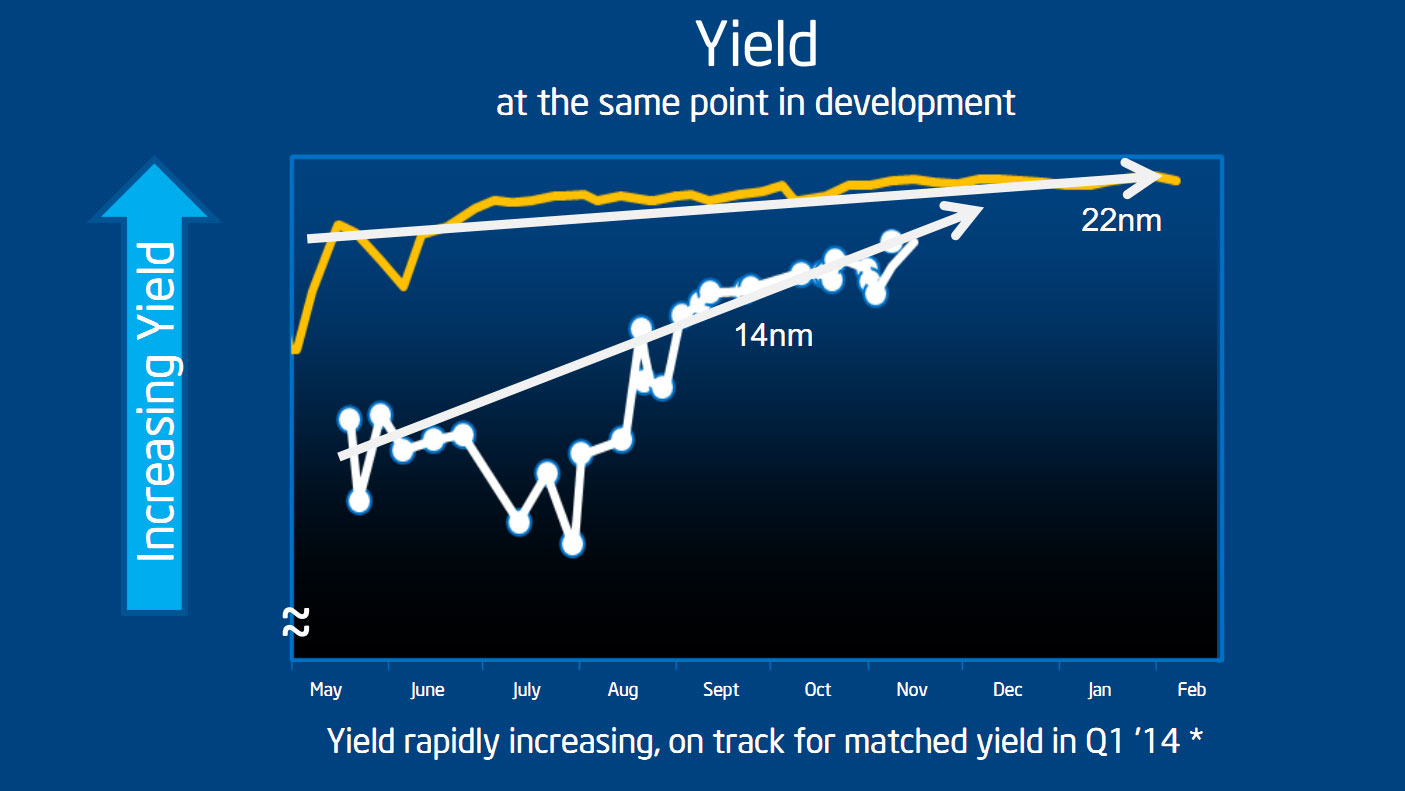
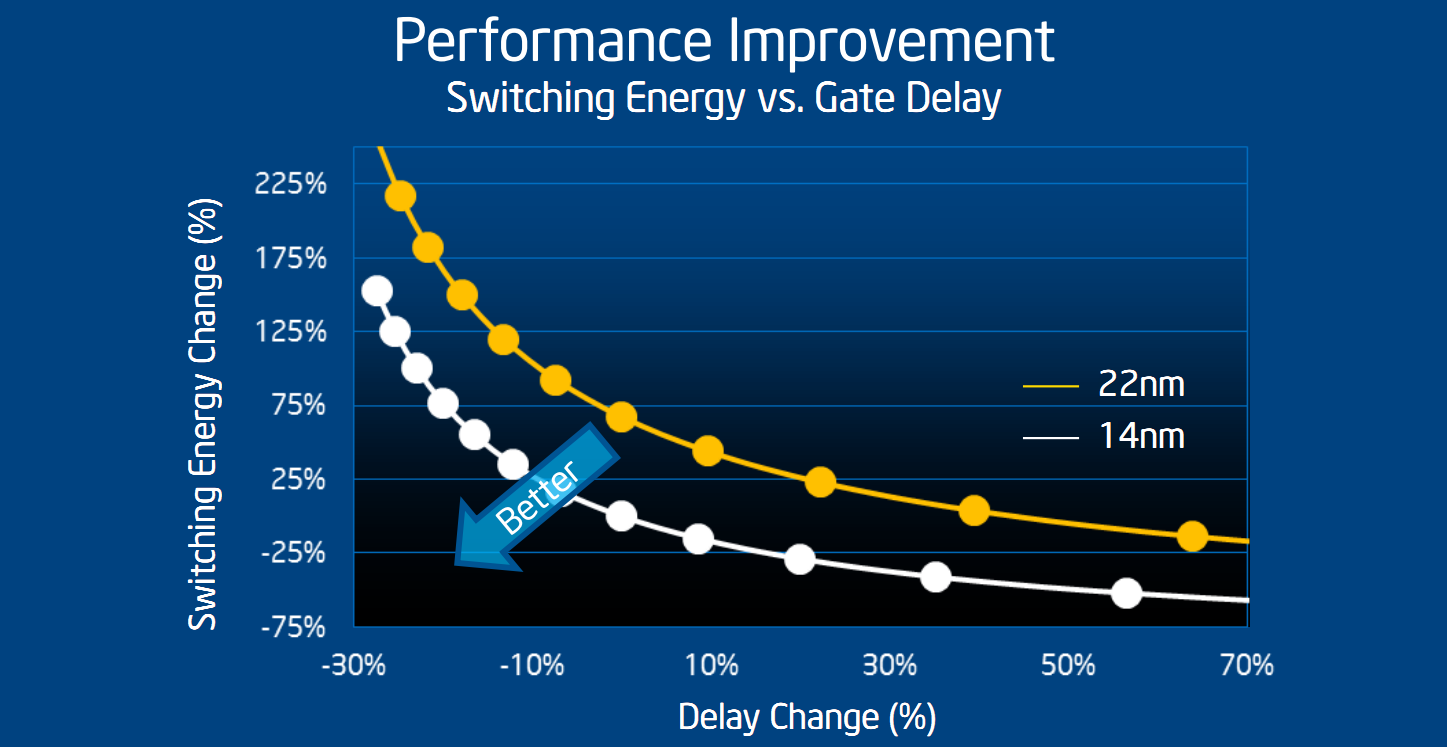
Intel a donné un peu plus d'informations sous la forme d'un graphique assez édifiant. Sur le graphique ci-dessus, Intel a dessiné l'évolution des yields (le pourcentage de puces produites « utilisables », une métrique qui n'est pas clairement définie et que William Holt indique pour vous donner son niveau de précision - comme « relativement similaire » pour les deux cas) sur deux ans à la fois pour le 22nm et pour le 14nm. Ces deux courbes montrent donc, en théorie, des yields à des niveaux de développement et d'avancement comparables, c'est comme cela en tout cas que les a présentées William Holt. Comme toujours sur ces graphiques forts sensibles, l'échelle n'est pas précisée, un point sur lequel nous allons revenir. Le commentaire d'Intel est que les yields étaient significativement en retard même si des progrès récents sur les derniers mois montrent que le 14nm (en blanc) se rapproche du 22nm avec pour but d'être au niveau du 22 nm au premier trimestre prochain.
Intel indique que le délai au-delà de la mise en production est surtout lié aux conséquences des faibles yields sur l'année précédente qui ont « diminué le nombre de bonnes unités » disponibles pour les différentes phases de tests, validation ou développements annexes (les drivers). Des propos que l'on peut comprendre pour le public visé (les investisseurs) qui préfèrent entendre que le problème est derrière plutôt que devant. Nous nous devons cependant de modérer quelque peu l'enthousiasme du constructeur.
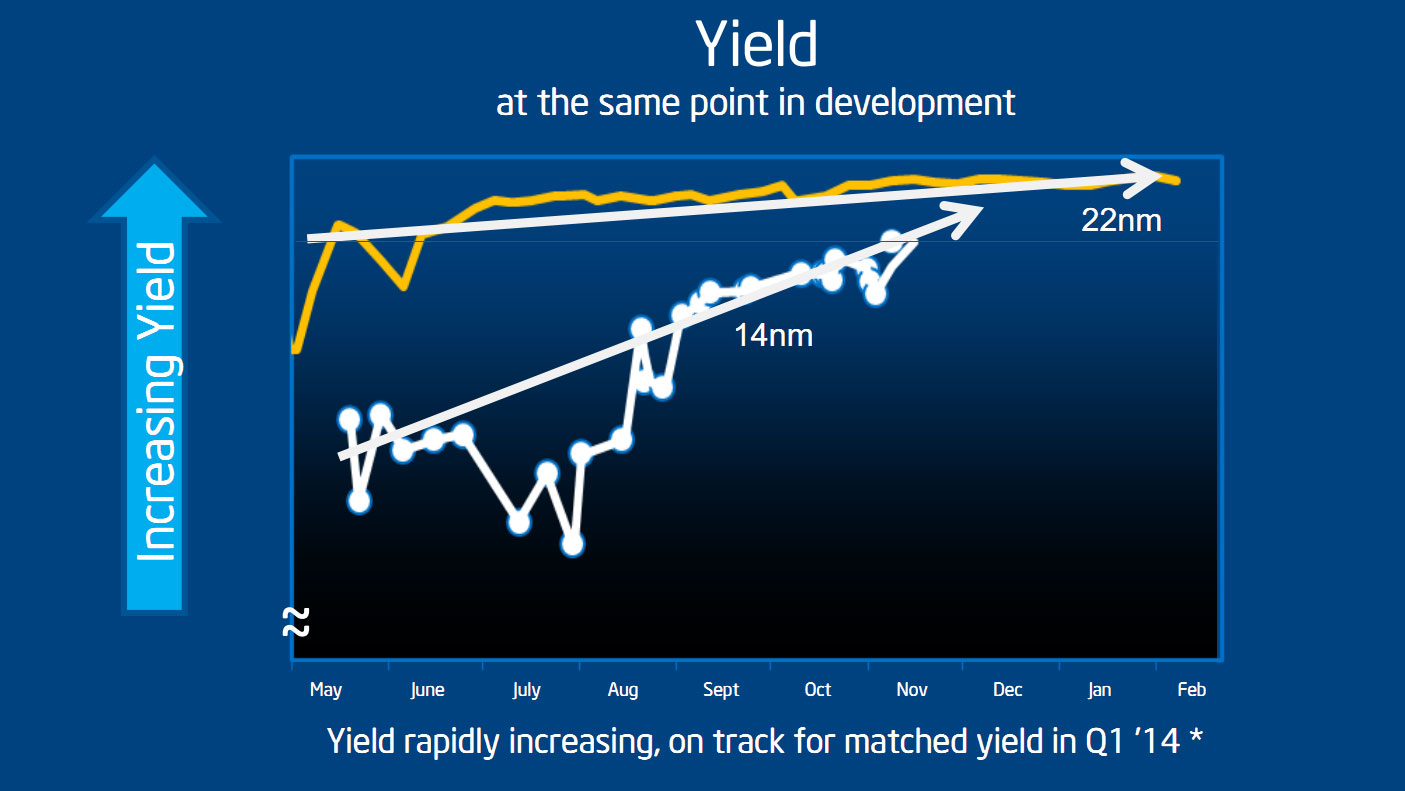
D'abord, nous avons tracé sur ce graphique en rouge le niveau du dernier point (indiqué comme un peu avant ou après la mi-novembre selon que l'on se fie au point ou à la ligne à laquelle il devrait être attaché ). Si l'on regarde précisément ou Intel en est aujourd'hui, les yields 14nm ont donc actuellement six mois de retard sur le 22nm, et non trois. La prédiction d'un rattrapage des yields pour le premier trimestre est donc avant tout basée sur la capacité d'Intel à rattraper ce qui ressemble à un tout petit gap sur cette échelle du graphique.
C'est l'autre point qui nous interpelle puisque pour rappel, la ligne jaune court de mai 2011 à février 2012, Ivy Bridge avait été lancé pour rappel en avril 2012. Or, si nous ne disposons pas d'un autre graphique de yields plus précis sur le 22 nm, Mark Bohr avait lors de l'IDF 2012 fourni le slide ci-dessous.
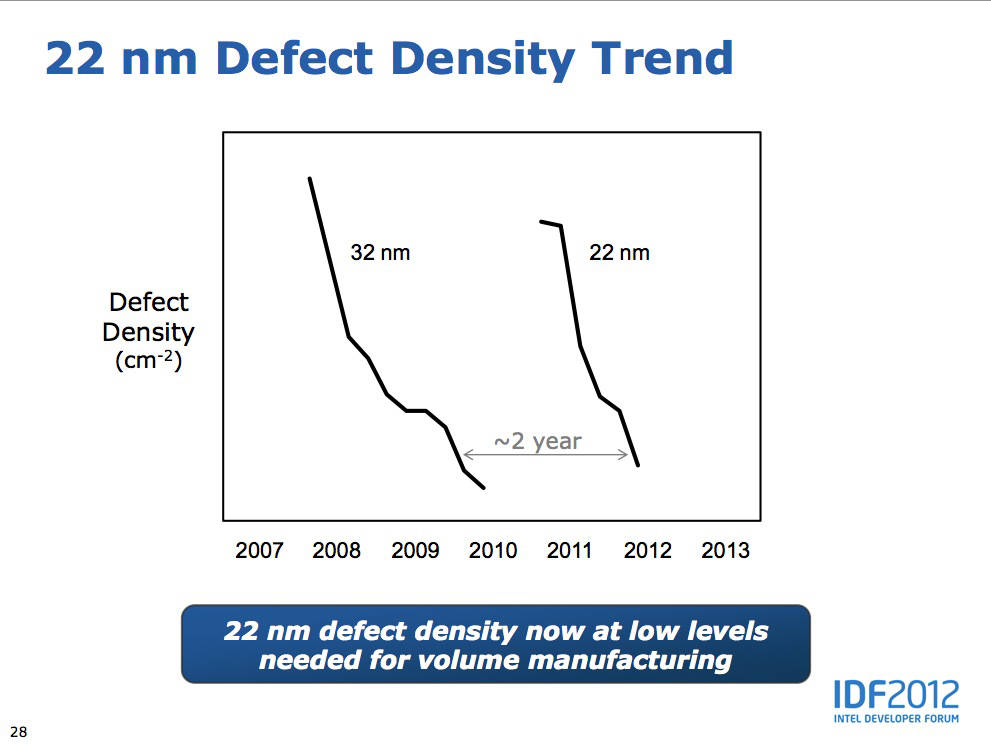
Ce slide mesure (avec une ambiguïté dans les échelles largement équivalente, pour ne pas dire supérieure !) la densité de défauts, ce qui n'est pas exactement l'inverse des yields même si les deux quantités sont inversement liées. Au minimum, on peut deviner qu'entre 2011 et 2012, l'évolution de la densité des défauts semble un peu plus dynamique que les yields très plats annoncés. Sans pouvoir en avoir la certitude, nous pensons que l'échelle du graphique de yields fournie par Intel est très compressée, diminuant quelque peu la réalité du travail restant à accomplir.
Cela ne remet bien entendu pas en cause la capacité d'Intel à lancer sa production ou ses futurs produits. Tant bien même que le rattrapage soit un peu plus long que prévu, le constructeur peut par exemple accepter de lancer la production avec des niveaux de yields un peu en dessous de ce qu'il attendait en rognant sur ses marges, ou lancer dans des volumes de production plus faibles le temps que le reste du travail (perpétuel) sur les yields se termine. Il faut également rappeler que Broadwell sera lancé de manière assez différente à ce qui s'était passé jusqu'ici chez Intel, dans un premier temps uniquement en format BGA pour les plateformes mobiles (qui sont toujours plus longues à adopter les nouvelles puces) puis, pour la fin d'année dans une version desktop qui cohabitera avec un Haswell Refresh en 22nm.
Ce changement des règles de lancement ne sera pas sans aider le constructeur et il serait fort intéressant de savoir en quelle mesure l'état du process 14 nm à influé sur la décision de ne pas lancer Broadwell en premier sur desktop comme à l'habitude. Une information qui avait filtré il y a un an de cela (soit six mois en amont du premier point de yield indiqué sur le graphique) et que l'on avait mise sur le compte de la volonté d'Intel de pousser sur la mobilité au détriment du desktop. Si la volonté sur la mobilité est bien entendu réelle, on aimerait savoir en quelle mesure l'état d'avancement du process 14nm a joué sur la décision.
Une chose est en tout cas certaine, si Intel n'a communiqué qu'il y a quelques semaines officiellement sur les problèmes de son 14nm, le constructeur était conscient de ces problèmes bien en amont. On notera que dans les questions/réponses, William Holt aura indiqué que si ce n'est pas la première fois qu'Intel rencontre des problèmes de yields de ce type, c'est la première fois depuis « un certain nombre de générations ».
On notera aussi un sous-entendu sur le multiple patterning, l'augmentation de son utilisation dans de plus en plus de couches des puces conduit à des interactions problématiques et complexes à débuguer. Officiellement Intel n'a pas vraiment dévoilé les différences entre le 22 et le 14nm, à part qu'il s'agira d'une seconde génération de tri-gate mais une augmentation du multiple patterning semble être au programme. On se souviendra que la Common Platform avait aussi fait ce choix (un peu contraint) dès le 20nm.
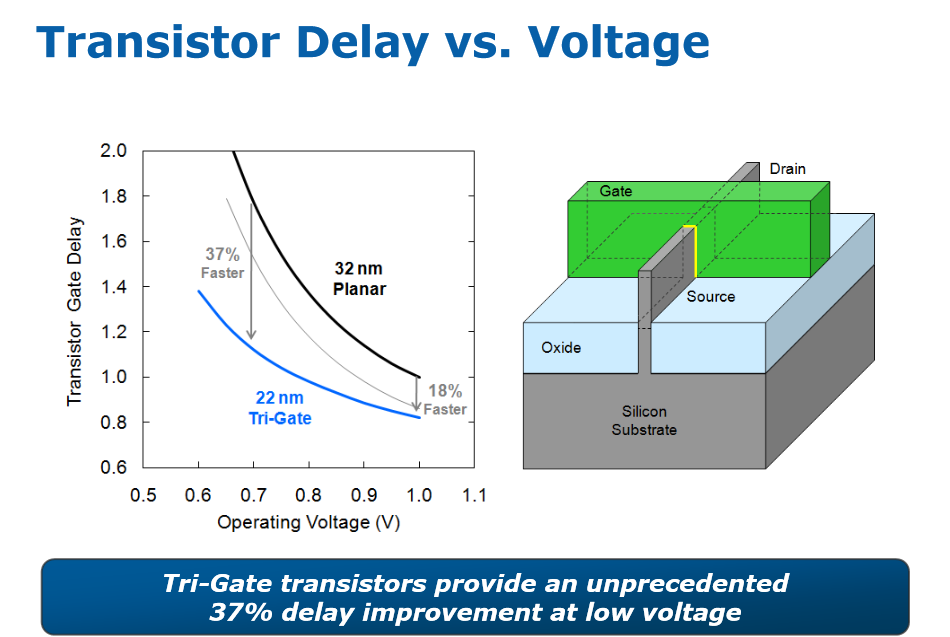
A gauche, une comparaison 32/22nm fournie par Intel à l'IDF 2011, à droite, le slide présenté par Intel comparant 22/14nm
Au-delà de tout ceci, Intel a également, par le biais d'un slide, donné un petit aperçu de ce qu'apporterait le 14nm. Là encore difficile d'en tirer quoique ce soit, à titre indicatif nous avons ajouté un graphique du même type comparant le 32 et le 22 nm. Attention cependant aux comparaisons hâtives. D'une, Intel a inversé les axes ce qui renverse quelque peu la donne et de deux, aucun point de référence n'est donné sur les axes, Intel se contentant d'indiquer des pourcentages. Difficile donc d'en tirer quoique ce soit si ce n'est que l'on attend un gain probablement un peu plus faible sur la vitesse des transistors qu'au passage 32-22 (les gros gains que l'on devine en bas à droite du second graphique sont à très faible tensions ils correspondent au haut à gauche du graphique de gauche, ce qui ne correspond pas forcément aux tensions qu'Intel utilisera en pratique).
WD Black² : SSD et HDD en un disque !
Western Digital annonce un nouveau produit innovant, le WD Black² (WD1001X06XDTL). Ce produit 2.5" d'une épaisseur de 9.5mm intègre en fait un disque dur 7mm 5400 tpm 1 To et un PCB intégrant un SSD 120 Go. Les deux sont interconnectés via une puce Marvell 88SM9642, le tout est connecté au PC via un seul port SATA.
Une fois le WD Black² connecté à la machine, seule la partie SSD est accessible dans un premier temps. Un pilote spécifique , disponible seulement pour Windows XP 32 bits, Vista, 7 , 8 et 8.1 est à installer pour pouvoir accéder au disque dur de 1 To. WD précise que le pilote n'est pas compatible avec les contrôleurs Nvidia et ASMedia.

La partie SSD est composée d'un contrôleur JMicron JMF667H associé à de la mémoire MLC 20nm et un cache DRAM 128 Mo. Les débits annoncés par WD sont de 350 Mo /s en lecture et 140 Mo /s en écriture pour ce SSD.
Le WD Black² est livré avec une clé USB intégrant le lien pour télécharger les pilotes (et probablement dans un second temps les pilotes), un adaptateur SATA vers USB 3.0 et une licence pour une édition spéciale d'Acronis True Image. Malheureusement le tout est annoncé à 299$, soit le prix d'un disque 1 To 2.5" et d'un SSD mSATA... 240/256 Go, et à peine moins cher qu'un SSD 2.5" 480/512 Go ! Une solution à réserver aux portables n'ayant donc qu'un emplacement 2.5", mais d'une hauteur de 9.5mm tout de même, ce qui réduit fortement la portée du produit, malgré une garantie de 5 ans.