
L'architecture AMD Bulldozer
Publié le 13/05/2011 par Franck Delattre



CMT technology (Cluster Multi-threading)Bulldozer chamboule quelque peu la définition de core, telle qu'elle est implémentée sur les architectures x86 actuelles. La nouvelle architecture d'AMD repose sur une « brique » de base appelée module et qui regroupe deux cores. Au sein du module, les deux cores partagent un certain nombre de leurs composants :
- l'étage « front-end » qui regroupe l'unité de fetch (chargement) et de décodage des instructions, ainsi que le cache L1 d'instructions qui est alimenté par ces unités ;
- l'unité de calcul sur les nombres flottants ;
- le cache L2.
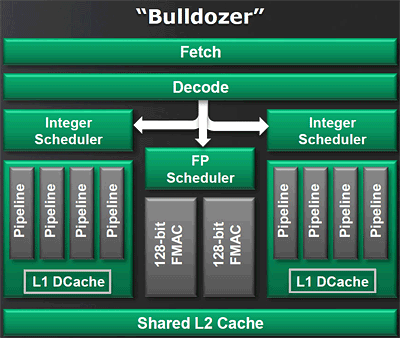
Si le partage d'un cache L2 entre les cores n'est pas une nouveauté, il en va différemment de celui d'unités jusque là propres à chaque core. Le choix des unités partagées semble judicieux : les unités qui composent le front-end sont complexes et consomment beaucoup de transistors et d'énergie. N'en utiliser qu'une seule partagée permet de réduire ces deux effets. Quant à la FPU, elle est couramment sollicitée à un taux inférieur à 50%, ce qui rend pertinent son partage par deux cores. Au final, un module est beaucoup moins gros et consommateur d'énergie que deux cores complets, tout en maintenant un niveau de performance proche. AMD avance les chiffres de 50% d'économie en surface sur la puce pour 80% des performances de deux cores complets.
Un processeur « Bulldozer » sera donc composé de plusieurs de ces modules, d'un contrôleur mémoire, d'un contrôleur de bus, et pour certains modèles d'un cache L3. Le discours commercial d'AMD ne portera pas sur les modules mais bien sur le nombre de cores. Ainsi, la version 8-cores de Bulldozer sera composée de 4 modules, et Windows y verra 8 unités logiques.
Si on y regarde de près, on peut voir le module Bulldozer comme un « super core » 4-way, partiellement coupé en deux, et ce afin de traiter deux threads en parallèle. La voie suivie par AMD se distingue nettement de celle prise par Intel qui a préféré conserver des « super cores » 4-way hyper-threadés (SMT). Difficile de dire quelle méthode est la meilleure, et cela dépend certainement du type d'application. SMT présente l'avantage d'une grande modularité (un seul thread peut bénéficier de 100% des performances du core), et permet une utilisation optimale du moteur OOO. CMT opère un partage plus marqué des ressources pour chaque thread, et marque ainsi le pas en terme de modularité. AMD note qu'un thread tournant seul sur un module bénéficie de la totalité des ressources partagées certes, mais la moitié des ressources dédiées reste inexploitée.
Sommaire
Vos réactions
Contenus relatifs
- [+] 17/03: AMD baisse ses prix AM3+/FM2+
- [+] 14/03: Bundle AMD pour les FX-6 et FX-8
- [+] 25/11: AMD dégaine ses offres de fin d'ann...
- [+] 04/10: AMD lance les Bristol Ridge Pro
- [+] 24/08: Deus Ex en bundle... avec les AMD F...
- [+] 19/05: Total War : Warhammer offert par AM...
- [+] 02/02: Excavator FM2+ et nouveaux ventirad...
- [+] 15/12: AMD FX-6330 = FX-6300 + 100 MHz
- [+] 01/10: Perfs avec 2, 4, 6 et 8 curs : 4 j...
- [+] 10/09: AMD FX-8370E, un FX 8 curs 95 watt...