
Nvidia CUDA : plus en pratique
Publié le 09/08/2007 par Damien Triolet



Exploiter les GeForce 8Exploiter un GPU comme une unité de calcul peut sembler très complexe. Il ne s'agit pas de diviser la tâche à exécuter en une poignée de threads comme cela est nécessaire pour tirer partie d'un CPU multicore. Il sera plutôt question de milliers de threads !
Autrement dit essayer d'exploiter un GPU n'a aucun sens si la tâche à réaliser n'est pas massivement parallèle. C'est pour cette raison que les GPU s'opposent plutôt aux supercalculateurs qu'aux CPU multicores. Une application qui tourne sur un super calculateur est forcément prévue pour être divisée en un nombre énorme de threads. Un GPU peut donc être vu comme un supercalculateur bon marché qui est dépouillé de toute leur structure complexe.
Le GPU, surtout chez Nvidia, conserve énormément de secrets puisque beaucoup de détails ne sont pas dévoilés, ce qui pourrait à priori laisser penser qu'on avance à l'aveuglette en essayant de développer un programme efficace pour ce type d'architecture. Bien que plus de détails seraient utiles dans certains cas, il ne faut pas oublier qu'un GPU est conçu dans l'optique de maximiser le débit de ses unités et par conséquent s'il est suffisamment alimenté il se charge tout seul d'exécuter le tout efficacement. Ce qui ne veut pas dire qu'avec plus de détails en tête il n'est pas possible de faire mieux, mais en se contentant au départ de connaître ce qui permet d'alimenter au mieux un GPU, il est possible d'obtenir des résultats satisfaisants. Ainsi il ne faut pas se dire qu'un GeForce 8800 dispose de 128 unités de calcul et donc qu'il a besoin de 128 threads pour être exploité. Il en faut bien plus, justement pour permettre au GPU de maximiser ses débits comme il le fait quand il travaille sur des milliers de pixels par exemple.

Lorsque l'on désire exploiter correctement un GPU de type GeForce 8 il faut structurer son programme et les données à traiter de manière à donner au GPU un nombre le plus élevé possible de threads tout en restant dans les limites du hardware qui sont :
- threads par SM : 768
- warps par SM : 24
- blocs par SM : 8
- threads par bloc : 512
- registres 32 bits par SM : 8192
- mémoire partagée par SM : 16 Ko
- constantes cachées par SM : 8 Ko
- textures 1D cachées par SM : 8 Ko
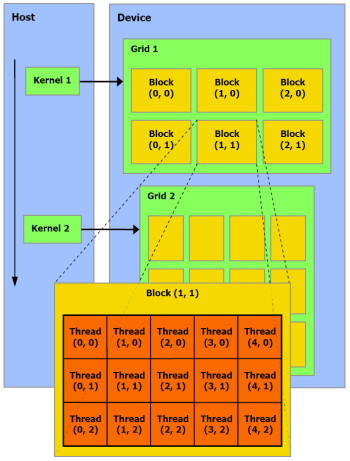
L'arrangement des threads en blocs et des blocs en grille de blocs (de 65536x65536x65536 blocs maximum) est à la charge du développeur. Un GPU de type GeForce peut ainsi exécuter un programme de maximum 2 millions d'instructions sur près de 150 billiards (10^15) de threads ! Ce ne sont bien entendu que des maximums.
Chaque multiprocesseur peut disposer de 768 threads, autrement dit pour les remplir au maximum il faudra par exemple utiliser 2 blocs de 384 threads (soit 2x 12 warps). 10 registres pourront alors être utilisés par thread et chaque bloc pourra utiliser 8 Ko de mémoire partagée. Si plus de registres sont nécessaires, il faudra alors diminuer le nombre de threads par SM ce qui aura pour conséquence de réduire potentiellement le rendement du multiprocesseur vu qu'il disposera de moins de possibilités de maximiser le débit de ses unités de calcul.

Il faut également que le programme à exécuter représente un nombre suffisant de blocs puisque un GeForce 8800 dispose de 16 multiprocesseurs. Dans l'exemple précédent qui utilise 2 blocs de 384 threads par multiprocesseur, il faudra donc au moins 32 de ces blocs pour alimenter toutes les unités de calcul du GPU. Cela représente près de 25 000 threads. Pour exploiter plusieurs GPUs il faudra encore multiplier ce nombre par celui des GPUs. Le mieux étant bien entendu d'en prévoir beaucoup plus pour pouvoir profiter des futurs GPUs qui disposeront de plus d'unités de calcul etc. Prévoir une centaine voire un millier de blocs de threads n'est donc pas un luxe.
Selon nous, le côté complexe qui est souvent donné à l'utilisation d'un GPU comme unité calcul provient avant tout du fait qu'on a du mal à visualiser comment faire tourner dessus un programme qui ne se parallélise pas bien. Mais c'est un faux problème et une perte de temps, cela ne sert à rien de chercher à faire tourner ce genre de chose sur un GPU.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...